Chrestomathy included
An unofficial publication, community edition (not by the LLG)
Version geklojban-1.2.16, Generated 2024-10-13
Table of Contents
- 1. Lojban as we mangle it in Lojbanistan: about this book
- 2. A quick tour of Lojban grammar, with diagrams
-
- 2.1. The concept of the bridi
- 2.2. Pronunciation
- 2.3. Words that can act as sumti
- 2.4. Some words used to indicate selbri relations
- 2.5. Some simple Lojban bridi
- 2.6. Variant bridi structure
- 2.7. Varying the order of sumti
- 2.8. The basic structure of longer utterances
- 2.9. tanru
- 2.10. Description sumti
- 2.11. Examples of brivla
- 2.12. The sumti di'u and la'e di'u
- 2.13. Possession
- 2.14. Vocatives and commands
- 2.15. Questions
- 2.16. Indicators
- 2.17. Tenses
- 2.18. Lojban grammatical terms
- 3. The hills are alive with the sounds of Lojban
-
- 3.1. Orthography
- 3.2. Basic phonetics
- 3.3. The special Lojban characters
- 3.4. Diphthongs and syllabic consonants
- 3.5. Vowel pairs
- 3.6. Consonant clusters
- 3.7. Initial consonant pairs
- 3.8. Buffering of consonant clusters
- 3.9. Syllabication and stress
- 3.10. IPA for English speakers
- 3.11. English analogues for Lojban diphthongs
- 3.12. Oddball orthographies
- 4. The shape of words to come: Lojban morphology
-
- 4.1. Introductory
- 4.2. cmavo
- 4.3. brivla
- 4.4. gismu
- 4.5. lujvo
- 4.6. rafsi
- 4.7. fu'ivla
- 4.8. cmevla
- 4.9. Rules for inserting pauses
- 4.10. Considerations for making lujvo
- 4.11. The lujvo-making algorithm
- 4.12. The lujvo scoring algorithm
- 4.13. lujvo-making examples
- 4.14. The gismu creation algorithm
- 4.15. Cultural and other non-algorithmic gismu
- 4.16. rafsi fu'ivla: a proposal
- 5. “Pretty little girls' school”: the structure of Lojban selbri
-
- 5.1. Lojban content words: brivla
- 5.2. Simple tanru
- 5.3. Three-part tanru grouping with bo
- 5.4. Complex tanru grouping
- 5.5. Complex tanru with ke and ke'e
- 5.6. Logical connection within tanru
- 5.7. Linked sumti: be - bei - be'o
- 5.8. Inversion of tanru: co
- 5.9. Other kinds of simple selbri
- 5.10. selbri based on sumti: me
- 5.11. Conversion of simple selbri
- 5.12. Scalar negation of selbri
- 5.13. Tenses and bridi negation
- 5.14. Some types of asymmetrical tanru
- 5.15. Some types of symmetrical tanru
- 5.16. “Pretty little girls' school” : forty ways to say it
- 6. To speak of many things: the Lojban sumti
-
- 6.1. The five kinds of simple sumti
- 6.2. The three basic description types
- 6.3. Individuals and masses
- 6.4. Masses and sets
- 6.5. Descriptors for typical objects
- 6.6. Quantified sumti
- 6.7. Quantified descriptions
- 6.8. Indefinite descriptions
- 6.9. sumti-based descriptions
- 6.10. sumti qualifiers
- 6.11. The syntax of vocative phrases
- 6.12. Lojban names
- 6.13. Pro-sumti summary
- 6.14. Quotation summary
- 6.15. Number summary
- 7. Brevity is the soul of language: pro-sumti and pro-bridi
-
- 7.1. What are pro-sumti and pro-bridi? What are they for?
- 7.2. Personal pro-sumti: the mi-series
- 7.3. Demonstrative pro-sumti: the ti-series
- 7.4. Utterance pro-sumti: the di'u-series
- 7.5. Assignable pro-sumti and pro-bridi: the ko'a-series and the broda-series
- 7.6. Anaphoric pro-sumti and pro-bridi: the ri-series and the go'i-series
- 7.7. Indefinite pro-sumti and pro-bridi: the zo'e-series and the co'e-series
- 7.8. Reflexive and reciprocal pro-sumti: the vo'a-series
- 7.9. sumti and bridi questions: ma and mo
- 7.10. Relativized pro-sumti: ke'a
- 7.11. Abstraction focus pro-sumti: ce'u
- 7.12. Bound variable pro-sumti and pro-bridi: the da-series and the bu'a-series
- 7.13. Pro-sumti and pro-bridi cancelling
- 7.14. The identity predicate: du
- 7.15. lujvo based on pro-sumti
- 7.16. KOhA cmavo by series
- 7.17. GOhA and other pro-bridi by series
- 7.18. Other cmavo discussed in this chapter
- 8. Relative clauses, which make sumti even more complicated
-
- 8.1. What are you pointing at?
- 8.2. Incidental relative clauses
- 8.3. Relative phrases
- 8.4. Multiple relative clauses: zi'e
- 8.5. Non-veridical relative clauses: voi
- 8.6. Relative clauses and descriptors
- 8.7. Possessive sumti
- 8.8. Relative clauses and complex sumti: vu'o
- 8.9. Relative clauses in vocative phrases
- 8.10. Relative clauses within relative clauses
- 8.11. Index of relative clause cmavo
- 9. To Boston via the Road go I, with an excursion into the land of modals
-
- 9.1. Introductory
- 9.2. Standard bridi form: cu
- 9.3. Tagging places: FA
- 9.4. Conversion: SE
- 9.5. Modal places: FIhO, FEhU
- 9.6. Modal tags: BAI
- 9.7. Modal sentence connection: the causals
- 9.8. Other modal connections
- 9.9. Modal selbri
- 9.10. Modal relative phrases; Comparison
- 9.11. Mixed modal connection
- 9.12. Modal conversion: JAI
- 9.13. Modal negation
- 9.14. Sticky modals
- 9.15. Logical and non-logical connection of modals
- 9.16. CV'V cmavo of selma'o BAI with irregular forms
- 9.17. Complete table of BAI cmavo with rough English equivalents
- 10. Imaginary journeys: the Lojban space/time tense system
-
- 10.1. Introductory
- 10.2. Spatial tenses: FAhA and VA
- 10.3. Compound spatial tenses
- 10.4. Temporal tenses: PU and ZI
- 10.5. Interval sizes: VEhA and ZEhA
- 10.6. Vague intervals and non-specific tenses
- 10.7. Dimensionality: VIhA
- 10.8. Movement in space: MOhI
- 10.9. Interval properties: TAhE and roi
- 10.10. Event contours: ZAhO and re'u
- 10.11. Space interval modifiers: FEhE
- 10.12. Tenses as sumtcita
- 10.13. Sticky and multiple tenses: KI
- 10.14. Story time
- 10.15. Tenses in subordinate bridi
- 10.16. Tense relations between sentences
- 10.17. Tensed logical connectives
- 10.18. Tense negation
- 10.19. Actuality, potentiality, capability: CAhA
- 10.20. Logical and non-logical connections between tenses
- 10.21. Sub-events
- 10.22. Conversion of sumtcita: JAI
- 10.23. Tenses versus modals
- 10.24. Tense questions: cu'e
- 10.25. Explicit magnitudes
- 10.26. Finally (an exercise for the much-tried reader)
- 10.27. Summary of tense selma'o
- 10.28. List of spatial directions and direction-like relations
- 11. Events, qualities, quantities, and other vague words: on Lojban abstraction
-
- 11.1. The syntax of abstraction
- 11.2. Event abstraction
- 11.3. Types of event abstractions
- 11.4. Property abstractions
- 11.5. Amount abstractions
- 11.6. Truth-value abstraction: jei
- 11.7. Predication/sentence abstraction
- 11.8. Indirect questions
- 11.9. Minor abstraction types
- 11.10. Lojban sumti raising
- 11.11. Event-type abstractors and event contour tenses
- 11.12. Abstractor connection
- 11.13. Table of abstractors
- 12. Dog house and white house: determining lujvo place structures
-
- 12.1. Why have lujvo?
- 12.2. The meaning of tanru: a necessary detour
- 12.3. The meaning of lujvo
- 12.4. Selecting places
- 12.5. Symmetrical and asymmetrical lujvo
- 12.6. Dependent places
- 12.7. Ordering lujvo places.
- 12.8. lujvo with more than two parts.
- 12.9. Eliding SE rafsi from seltau
- 12.10. Eliding SE rafsi from tertau
- 12.11. Eliding KE and KEhE rafsi from lujvo
- 12.12. Abstract lujvo
- 12.13. Implicit-abstraction lujvo
- 12.14. Anomalous lujvo
- 12.15. Comparatives and superlatives
- 12.16. Notes on gismu place structures
- 13. Oooh! Arrgh! Ugh! Yecch! Attitudinal and emotional indicators
-
- 13.1. What are attitudinal indicators?
- 13.2. Pure emotion indicators
- 13.3. Propositional attitude indicators
- 13.4. Attitudes as scales
- 13.5. The space of emotions
- 13.6. Emotional categories
- 13.7. Attitudinal modifiers
- 13.8. Compound indicators
- 13.9. The uses of indicators
- 13.10. Attitude questions; empathy; attitude contours
- 13.11. Evidentials
- 13.12. Discursives
- 13.13. Miscellaneous indicators
- 13.14. Vocative scales
- 13.15. A sample dialogue
- 13.16. Tentative conclusion
- 14. If wishes were horses: the Lojban connective system
-
- 14.1. Logical connection and truth tables
- 14.2. The four basic vowels
- 14.3. The six types of logical connectives
- 14.4. Logical connection of bridi
- 14.5. Forethought bridi connection
- 14.6. sumti connection
- 14.7. More than two propositions
- 14.8. Grouping of afterthought connectives
- 14.9. Compound bridi
- 14.10. Multiple compound bridi
- 14.11. Termset logical connection
- 14.12. Logical connection within tanru
- 14.13. Truth questions and connective questions
- 14.14. Non-logical connectives
- 14.15. More about non-logical connectives
- 14.16. Interval connectives and forethought non-logical connection
- 14.17. Logical and non-logical connectives within mekso
- 14.18. Tenses, modals, and logical connection
- 14.19. Abstractor connection and connection within abstractions
- 14.20. Constructs and appropriate connectives
- 14.21. Truth functions and corresponding logical connectives
- 14.22. Rules for making logical and non-logical connectives
- 14.23. Locations of other tables
- 15. “No” problems: on Lojban negation
-
- 15.1. Introductory
- 15.2. bridi negation
- 15.3. Scalar negation
- 15.4. selbri and tanru negation
- 15.5. Expressing scales in selbri negation
- 15.6. sumti negation
- 15.7. Negation of minor grammatical constructs
- 15.8. Truth questions
- 15.9. Affirmations
- 15.10. Metalinguistic negation forms
- 15.11. Summary – are all possible questions about negation now answered?
- 16. “Who did you pass on the road? Nobody”: Lojban and logic
-
- 16.1. What's wrong with this picture?
- 16.2. Existential claims, prenexes, and variables
- 16.3. Universal claims
- 16.4. Restricted claims: da poi
- 16.5. Dropping the prenex
- 16.6. Variables with generalized quantifiers
- 16.7. Grouping of quantifiers
- 16.8. The problem of “any”
- 16.9. Negation boundaries
- 16.10. bridi negation and logical connectives
- 16.11. Using naku outside a prenex
- 16.12. Logical connectives and DeMorgan's law
- 16.13. selbri variables
- 16.14. A few notes on variables
- 16.15. Conclusion
- 17. As easy as A-B-C? The Lojban letteral system and its uses
-
- 17.1. What's a letteral, anyway?
- 17.2. A to Z in Lojban, plus one
- 17.3. Upper and lower cases
- 17.4. The universal bu
- 17.5. Alien alphabets
- 17.6. Accent marks and compound lerfu words
- 17.7. Punctuation marks
- 17.8. What about Chinese characters?
- 17.9. lerfu words as pro-sumti
- 17.10. References to lerfu
- 17.11. Mathematical uses of lerfu strings
- 17.12. Acronyms
- 17.13. Computerized character codes
- 17.14. List of all auxiliary lerfu-word cmavo
- 17.15. Proposed lerfu words – introduction
- 17.16. Proposed lerfu words for the Greek alphabet
- 17.17. Proposed lerfu words for the Cyrillic alphabet
- 17.18. Proposed lerfu words for the Hebrew alphabet
- 17.19. Proposed lerfu words for some accent marks and multiple letters
- 17.20. Proposed lerfu words for radio communication
- 18. lojbau mekso: mathematical expressions in Lojban
-
- 18.1. Introductory
- 18.2. Lojban numbers
- 18.3. Signs and numerical punctuation
- 18.4. Special numbers
- 18.5. Simple infix expressions and equations
- 18.6. Forethought operators (Polish notation, functions)
- 18.7. Other useful selbri for mekso bridi
- 18.8. Indefinite numbers
- 18.9. Approximation and inexact numbers
- 18.10. Non-decimal and compound bases
- 18.11. Special mekso selbri
- 18.12. Number questions
- 18.13. Subscripts
- 18.14. Infix operators revisited
- 18.15. Vectors and matrices
- 18.16. Reverse Polish notation
- 18.17. Logical and non-logical connectives within mekso
- 18.18. Using Lojban resources within mekso
- 18.19. Other uses of mekso
- 18.20. Explicit operator precedence
- 18.21. Miscellany
- 18.22. Four score and seven: a mekso problem
- 18.23. mekso selma'o summary
- 18.24. Complete table of VUhU cmavo, with operand structures
- 18.25. Complete table of PA cmavo: digits, punctuation, and other numbers
- 18.26. Table of MOI cmavo, with associated rafsi and place structures
- 19. Putting it all together: notes on the structure of Lojban texts
-
- 19.1. Introductory
- 19.2. Sentences: I
- 19.3. Paragraphs: NIhO
- 19.4. Topic-comment sentences: ZOhU
- 19.5. Questions and answers
- 19.6. Subscripts: XI
- 19.7. Utterance ordinals: MAI
- 19.8. Attitude scope markers: FUhE/FUhO
- 19.9. Quotations: LU, LIhU, LOhU, LEhU
- 19.10. More on quotations: ZO, ZOI
- 19.11. Contrastive emphasis: BAhE
- 19.12. Parenthesis and metalinguistic commentary: TO, TOI, SEI
- 19.13. Erasure: SI, SA, SU
- 19.14. Hesitation: Y
- 19.15. No more to say: FAhO
- 19.16. List of cmavo interactions
- 19.17. List of elidable terminators
- 20. A catalogue of selma'o
- 21. Formal grammars
- Chrestomathy
- Lojban Words Glossary
- Lojban Words Index
- General Index
Lojban (pronounced “LOZH-bahn”) is a constructed language. Previous versions of the language were called “Loglan” by Dr. James Cooke Brown, who founded the Loglan Project and started the development of the language in 1955. The goals for the language were first described in the open literature in the article “Loglan” , published in Scientific American , June, 1960. Made well-known by that article and by occasional references in science fiction (most notably in Robert Heinlein's novel The Moon Is A Harsh Mistress) and computer publications, Loglan and Lojban have been built over four decades by dozens of workers and hundreds of supporters, led since 1987 by The Logical Language Group (who are the publishers of this book).
There are thousands of artificial languages (of which Esperanto is the best-known), but Loglan/Lojban has been engineered to make it unique in several ways. The following are the main features of Lojban:
-
Lojban is designed to be used by people in communication with each other, and possibly in the future with computers.
-
Lojban is designed to be neutral between cultures.
-
Lojban grammar is based on the principles of predicate logic.
-
Lojban has an unambiguous yet flexible grammar.
-
Lojban has phonetic spelling, and unambiguously resolves its sounds into words.
-
Lojban is simple compared to natural languages; it is easy to learn.
-
Lojban's 1300 root words can be easily combined to form a vocabulary of millions of words.
-
Lojban is regular; the rules of the language are without exceptions.
-
Lojban attempts to remove restrictions on creative and clear thought and communication.
-
Lojban has a variety of uses, ranging from the creative to the scientific, from the theoretical to the practical.
-
Lojban has been demonstrated in translation and in original works of prose and poetry.
This book is what is called a “reference grammar”. It attempts to expound the whole Lojban language, or at least as much of it as is understood at present. Lojban is a rich language with many features, and an attempt has been made to discover the functions of those features. The word “discover” is used advisedly; Lojban was not “invented” by any one person or committee. Often, grammatical features were introduced into the language long before their usage was fully understood. Sometimes they were introduced for one reason, only to prove more useful for other reasons not recognized at the time.
By intention, this book is complete in description but not in explanation. For every rule in the formal Lojban grammar (given in Chapter 21), there is a bit of explanation and an example somewhere in the book, and often a great deal more than a bit. In essence, Chapter 2 gives a brief overview of the language, Chapter 21 gives the formal structure of the language, and the chapters in between put semantic flesh on those formal bones. I hope that eventually more grammatical material founded on (or even correcting) the explanations in this book will become available.
Nevertheless, the publication of this book is, in one sense, the completion of a long period of language evolution. With the exception of a possible revision of the language that will not even be considered until five years from publication date, and any revisions of this book needed to correct outright errors, the language described in this book will not be changing by deliberate act of its creators any more. Instead, language change will take place in the form of new vocabulary – Lojban does not yet have nearly the vocabulary it needs to be a fully usable language of the modern world, as Chapter 12 explains – and through the irregular natural processes of drift and (who knows?) native-speaker evolution. (Teach your children Lojban!) You can learn the language described here with assurance that (unlike previous versions of Lojban and Loglan, as well as most other artificial languages) it will not be subject to further fiddling by language-meisters.
It is probably worth mentioning that this book was written somewhat piecemeal. Each chapter began life as an explication of a specific Lojban topic; only later did these begin to clump together into a larger structure of words and ideas. Therefore, there are perhaps not as many cross-references as there should be. However, I have attempted to make the index as comprehensive as possible.
Each chapter has a descriptive title, often involving some play on words; this is an attempt to make the chapters more memorable. The title of Chapter 1 (which you are now reading), for example, is an allusion to the book English As We Speak It In Ireland , by P. W. Joyce, which is a sort of informal reference grammar of Hiberno-English. “Lojbanistan” is both an imaginary country where Lojban is the native language, and a term for the actual community of Lojban-speakers, scattered over the world. Why “mangle” ? As yet, nobody in the real Lojbanistan speaks the language at all well, by the standards of the imaginary Lojbanistan; that is one of the circumstances this book is meant to help remedy.
Each chapter is broken into numbered sections; each section contains a mixture of expository text, numbered examples, and possibly tables.
The reader will notice a certain similarity in the examples used throughout the book. One chapter after another rings the changes on the self-same sentences:
will become wearisomely familiar before Chapter 21 is reached. This method is deliberate; I have tried to use simple and (eventually) familiar examples wherever possible, to avoid obscuring new grammatical points with new vocabulary. Of course, this is not the method of a textbook, but this book is not a textbook (although people have learned Lojban from it and its predecessors). Rather, it is intended both for self-learning (of course, at present would-be Lojban teachers must be self-learners) and to serve as a reference in the usual sense, for looking up obscure points about the language.
It is useful to talk further about Example 1.1 for what it illustrates about examples in this book. Examples usually occupy three lines. The first of these is in Lojban (in italics), the second in a word-by-word literal translation of the Lojban into English (in boldface), and the third in colloquial English. The second and third lines are sometimes called the “literal translation” and the “colloquial translation” respectively. Sometimes, when clarity is not sacrificed thereby, one or both are omitted. If there is more than one Lojban sentence, it generally means that they have the same meaning.
Words are sometimes surrounded by square brackets. In Lojban texts, these enclose optional grammatical particles that may (in the context of the particular example) be either omitted or included. In literal translations, they enclose words that are used as conventional translations of specific Lojban words, but don't have exactly the meanings or uses that the English word would suggest. In Chapter 3 , square brackets surround phonetic representations in the International Phonetic Alphabet.
Many of the tables, especially those placed at the head of various sections, are in three columns. The first column contains Lojban words discussed in that section; the second column contains the grammatical category (represented by an UPPER CASE Lojban word) to which the word belongs, and the third column contains a brief English gloss, not necessarily or typically a full explanation. Other tables are explained in context.
A few Lojban words are used in this book as technical terms. All of these are explained in Chapter 2 , except for a few used only in single chapters, which are explained in the introductory sections of those chapters.
It is necessary to add, alas, that the examples used in this book do not refer to any existing person, place, or institution, and that any such resemblance is entirely coincidental and unintentional, and not intended to give offense.
When definitions and place structures of gismu, and especially of lujvo, are given in this book, they may differ from those given in the English-Lojban dictionary (which, as of this writing, is not yet published). If so, the information given in the dictionary supersedes whatever is given here.
Although the bulk of this book was written for the Logical Language Group (LLG) by John Cowan, who is represented by the occasional authorial “I” , certain chapters were first written by others and then heavily edited by me to fit into this book.
In particular: Chapter 2 is a fusion of originally separate documents, one by Athelstan, and one by Nora Tansky LeChevalier and Bob LeChevalier; Chapter 3 and Chapter 4 were originally written by Bob LeChevalier with contributions by Chuck Barton; Chapter 12 was originally written (in much longer form) by Nick Nicholas; the dialogue near the end of Chapter 13 was contributed by Nora Tansky LeChevalier; Chapter 15 and parts of Chapter 16 were originally by Bob LeChevalier. The BNF grammar, which is also in Chapter 21 , was originally written by me, then rewritten by Clark Nelson, and finally touched up by me again.
The research into natural languages from which parts of Chapter 5 draw their material was performed by Ivan Derzhanski. LLG acknowledges his kind permission to use the fruits of his research.
The pictures in this book were drawn by Nora Tansky LeChevalier, except for the picture appearing in Chapter 4 , which is by Sylvia Rutiser Rissell.
The index was made by Nora Tansky LeChevalier.
I would like to thank the following people for their detailed reviews, suggestions, comments, and early detection of my embarrassing errors in Lojban, logic, English, and cross-references: Nick Nicholas, Mark Shoulson, Veijo Vilva, Colin Fine, And Rosta, Jorge Llambias, Iain Alexander, Paulo S. L. M. Barreto, Robert J. Chassell, Gale Cowan, Karen Stein, Ivan Derzhanski, Jim Carter, Irene Gates, Bob LeChevalier, John Parks-Clifford (also known as “pc”), and Nora Tansky LeChevalier.
Nick Nicholas (NSN) would like to thank the following Lojbanists: Mark Shoulson, Veijo Vilva, Colin Fine, And Rosta, and Iain Alexander for their suggestions and comments; John Cowan, for his extensive comments, his exemplary trailblazing of Lojban grammar, and for solving the manskapi dilemma for NSN; Jorge Llambias, for his even more extensive comments, and for forcing NSN to think more than he was inclined to; Bob LeChevalier, for his skeptical overview of the issue, his encouragement, and for scouring all Lojban text his computer has been burdened with for lujvo; Nora Tansky LeChevalier, for writing the program converting old rafsi text to new rafsi text, and sparing NSN from embarrassing errors; and Jim Carter, for his dogged persistence in analyzing lujvo algorithmically, which inspired this research, and for first identifying the three lujvo classes.
Of course, the entire Loglan Project owes a considerable debt to James Cooke Brown as the language inventor, and also to several earlier contributors to the development of the language. Especially noteworthy are Doug Landauer, Jeff Prothero, Scott Layson, Jeff Taylor, and Bob McIvor. Final responsibility for the remaining errors and infelicities is solely mine.
The founding document for the Loglan Project, of which this book is one of the products, is Loglan 1: A Logical Language by James Cooke Brown (4th ed. 1989, The Loglan Institute, Gainesville, Florida, U.S.A.). The language described therein is not Lojban, but is very close to it and may be considered an ancestral version. It is regrettably necessary to state that nothing in this book has been approved by Dr. Brown, and that the very existence of Lojban is disapproved of by him.
The logic of Lojban, such as it is, owes a good deal to the American philosopher W. v.O. Quine, especially Word and Object (1960, M.I.T. Press). Much of Quine's philosophical writings, especially on observation sentences, reads like a literal translation from Lojban.
The theory of negation expounded in Chapter 15 is derived from a reading of Laurence Horn's work A Natural History of Negation.
Of course, neither Brown nor Quine nor Horn is in any way responsible for the uses or misuses I have made of their works.
Depending on just when you are reading this book, there may be three other books about Lojban available: a textbook, a Lojban/English dictionary, and a book containing general information about Lojban. You can probably get these books, if they have been published, from the same place where you got this book. In addition, other books not yet foreseen may also exist.
The following examples list the Lojban caption, with a translation, for the picture at the head of each chapter. If a chapter's picture has no caption, “(none)” is specified instead.
| Chapter 1 |
Greetings, O Lojban! Greetings, all-of you |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Chapter 2 |
(none) |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Chapter 3 |
[a sequence of arbitrary Lojban words] |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Chapter 4 |
Lojbanic-blocks |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Chapter 5 |
(none) |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Chapter 6 |
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Chapter 7 |
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Chapter 8 |
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Chapter 9 |
(none) |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Chapter 10 |
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Chapter 11 |
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Chapter 12 |
(none) |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Chapter 13 |
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Chapter 14 |
(none) |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Chapter 15 |
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Chapter 16 |
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Chapter 17 |
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Chapter 18 |
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Chapter 19 |
(none) |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Chapter 20 |
(none) |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Chapter 21 |
(none) |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Copyright © 1997 by The Logical Language Group, Inc. All Rights Reserved.
Permission is granted to make and distribute verbatim copies of this book, either in electronic or in printed form, provided the copyright notice and this permission notice are preserved on all copies.
Permission is granted to copy and distribute modified versions of this book, provided that the modifications are clearly marked as such, and provided that the entire resulting derived work is distributed under the terms of a permission notice identical to this one.
Permission is granted to copy and distribute translations of this book into another language, under the above conditions for modified versions, except that this permission notice may be stated in a translation that has been approved by the Logical Language Group, rather than in English.
The contents of Chapter 21 are in the public domain.
For information, contact: The Logical Language Group, 2904 Beau Lane, Fairfax VA 22031-1303 USA. Telephone: 703-385-0273. Email address: llg-board@lojban.org. Web Address: http://www.lojban.org.
This chapter gives diagrammed examples of basic Lojban sentence structures. The most general pattern is covered first, followed by successive variations on the basic components of the Lojban sentence. There are many more capabilities not covered in this chapter, but covered in detail in later chapters, so this chapter is a “quick tour” of the material later covered more slowly throughout the book. It also introduces most of the Lojban words used to discuss Lojban grammar.
Let us consider John and Sam and three statements about them:
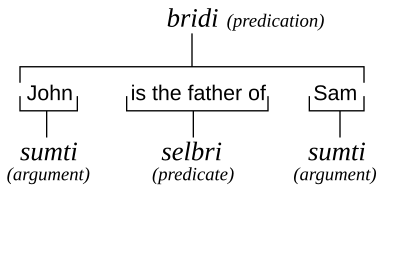
These examples all describe relationships between John and Sam. However, in English, we use the noun “father” to describe a static relationship in Example 2.1, the verb “hits” to describe an active relationship in Example 2.2, and the adjective “taller” to describe an attributive relationship in Example 2.3. In Lojban we make no such grammatical distinctions; these three sentences, when expressed in Lojban, are structurally identical. The same part of speech is used to represent the relationship. In formal logic this whole structure is called a “predication”; in Lojban it is called a bridi, and the central part of speech is the selbri. Logicians refer to the things thus related as “arguments”, while Lojbanists call them sumti. These Lojban terms will be used for the rest of the book.
In a relationship, there are a definite number of things being related. In English, for example, “give” has three places: the donor, the recipient and the gift. For example:
and
mean two different things because the relative positions of “John” and “Sam” have been switched. Further,
seems strange to us merely because the places are being filled by unorthodox arguments. The relationship expressed by “give” has not changed.
In Lojban, each selbri has a specified number and type of arguments, known collectively as its “place structure”. The simplest kind of selbri consists of a single root word, called a gismu, and the definition in a dictionary gives the place structure explicitly. The primary task of constructing a Lojban sentence, after choosing the relationship itself, is deciding what you will use to fill in the sumti places.
This book uses the Lojban terms bridi, sumti, and selbri, because it is best to come to understand them independently of the English associations of the corresponding words, which are only roughly similar in meaning anyhow.
The Lojban examples in this chapter (but not in the rest of the book) use boldface (as well as the usual italics) for selbri, to help you to tell them apart.
Detailed pronunciation and spelling rules are given in Chapter 3, but what follows will keep the reader from going too far astray while digesting this chapter.
Lojban has six recognized vowels: a, e, i, o, u and y. The first five are roughly pronounced as “a” as in “father”, e as in “let”, i as in “machine”, o as in “dome” and u as in “flute”. y is pronounced as the sound called “schwa”, that is, as the unstressed “a” as in “about” or “around”.
Twelve consonants in Lojban are pronounced more or less as their counterparts are in English: b, d, f, k, l, m, n, p, r, t, v and z. The letter c, on the other hand is pronounced as the “sh” in “hush”, while j is its voiced counterpart, the sound of the “s” in “pleasure”. g is always pronounced as it is in “gift”, never as in “giant”. s is as in “sell”, never as in “rose”. The sound of x is not found in English in normal words. It is found as “ch” in Scottish “loch”, as “j” in Spanish “junta”, and as „ch“ in German „Bach“; it also appears in the English interjection “yecchh!”. It gets easier to say as you practice it. The letter r can be trilled, but doesn't have to be.
The Lojban diphthongs ai, ei, oi, and au are pronounced much as in the English words “sigh”, “say”, “boy”, and “how”. Other Lojban diphthongs begin with an i pronounced like English “y” (for example, io is pronounced “yo”) or else with a u pronounced like English “w” (for example, ua is pronounced “wa”).
Lojban also has three “semi-letters”; the period, the comma and the apostrophe. The period represents a glottal stop or a pause; it is a required stoppage of the flow of air in the speech stream. The apostrophe sounds just like the English letter “h”. Unlike a regular consonant, it is not found at the beginning or end of a word, nor is it found adjacent to a consonant; it is only found between two vowels. The comma has no sound associated with it, and is used to separate syllables that might ordinarily run together. It is not used in this chapter.
Stress falls on the next to the last syllable of all words, unless that vowel is y, which is never stressed; in such words the third-to-last syllable is stressed. If a word only has one syllable, then that syllable is not stressed.
All Lojban words are pronounced as they are spelled: there are no silent letters.
Here is a short table of single words used as sumti. This table provides examples only, not the entire set of such words, which may be found in Section 7.16.
|
mi |
I/me, we/us |
|
do |
you |
|
ti |
this, these |
|
ta |
that, those |
|
tu |
that far away, those far away |
|
zo'e |
unspecified value (used when a sumti is unimportant or obvious) |
Lojban sumti are not specific as to number (singular or plural), nor gender (masculine/feminine/neutral). Such distinctions can be optionally added by methods that are beyond the scope of this chapter.
The cmavo ti, ta, and tu refer to whatever the speaker is pointing at, and should not be used to refer to things that cannot in principle be pointed at.
Names may also be used as sumti, provided they are preceded with the word la:
Other Lojban spelling versions are possible for names from other languages, and there are restrictions on which letters may appear in Lojban names: see Section 6.12 for more information.
Here is a short table of some words used as Lojban selbri in this chapter:
| vecnu | x1 (seller) sells x2 (goods) to x3 (buyer) for x4 (price) |
| tavla | x1 (talker) talks to x2 (audience) about x3 (topic) in language x4 |
| sutra | x1 (agent) is fast at doing x2 (action) |
| blari'o | x1 (object/light source) is blue-green |
| melbi | x1 (object/idea) is beautiful to x2 (observer) by standard x3 |
| cutci | x1 is a shoe/boot for x2 (foot) made of x3 (material) |
| bajra | x1 runs on x2 (surface) using x3 (limbs) in manner x4 (gait) |
| klama | x1 goes/comes to x2 (destination) from x3 (origin point) via x4 (route) using x5 (means of transportation) |
| pluka | x1 pleases/is pleasing to x2 (experiencer) under conditions x3 |
| gerku | x1 is a dog of breed x2 |
| kurji | x1 takes care of x2 |
| kanro | x1 is healthy by standard x2 |
| stali | x1 stays/remains with x2 |
| zarci | x1 is a market/store/shop selling x2 (products) operated by x3 (storekeeper) |
Each selbri (relation) has a specific rule that defines the role of each sumti in the bridi, based on its position. In the table above, that order was expressed by labeling the sumti positions as x1, x2, x3, x4, and x5.
Like the table in Section 2.3, this table is far from complete: in fact, no complete table can exist, because Lojban allows new words to be created (in specified ways) whenever a speaker or writer finds the existing supply of words inadequate. This notion is a basic difference between Lojban (and some other languages such as German and Chinese) and English; in English, most people are very leery of using words that “aren't in the dictionary”. Lojbanists are encouraged to invent new words; doing so is a major way of participating in the development of the language. Chapter 4 explains how to make new words, and Chapter 12 explains how to give them appropriate meanings.
Let's look at a simple Lojban bridi. The place structure of the gismu tavla is
where the “x” es with following numbers represent the various arguments that could be inserted at the given positions in the English sentence. For example:
has “John” in the x1 place, “Sam” in the x2 place, “engineering” in the x3 place, and “Lojban” in the x4 place, and could be paraphrased:
Talking is going on, with speaker John and listener Sam and subject matter engineering and language Lojban.
The Lojban bridi corresponding to Example 2.7 will have the form
The word cu serves as a separator between any preceding sumti and the selbri. It can often be omitted, as in the following examples.
(In Example 2.13 the word ly. is a so-called letteral for the Lojban letter “l” and refers to something labelled “l”, most likely the language “Lojban” as its first letter is “l”).
When there are one or more occurrences of the cmavo zo'e at the end of a bridi, they may be omitted, a process called “ellipsis”. Example 2.11 and Example 2.12 may be expressed thus:
Note that Example 2.13 is not subject to ellipsis by this direct method, as the zo'e in it is not at the end of the bridi.
|
mi |
[cu] |
vecnu |
ti |
ta |
zo'e |
|
seller-x1 |
- |
sells |
goods-sold-x2 |
buyer-x3 |
price-x4 |
|
I |
- |
sell |
this |
to that |
for some price. |
|
I sell this-thing/these-things to that-buyer/those-buyers. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
(the price is obvious or unimportant) |
Example 2.16 has one sumti (the x1) before the selbri. It is also possible to put more than one sumti before the selbri, without changing the order of sumti:
|
mi |
ti |
[cu] |
vecnu |
ta |
|
seller-x1 |
goods-sold-x2 |
- |
sells |
buyer-x3 |
|
I |
this |
- |
sell |
to that. |
|
(translates as stilted or poetic English) |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
I this thing do sell to that buyer. |
|
mi |
ti |
ta |
[cu] |
vecnu |
|
seller-x1 |
goods-sold-x2 |
buyer-x3 |
- |
sells |
|
I |
this |
to that |
- |
sell |
|
(translates as stilted or poetic English) |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
I this thing to that buyer do sell. |
Example 2.16 through Example 2.18 mean the same thing. Usually, placing more than one sumti before the selbri is done for style or for emphasis on the sumti that are out-of-place from their normal position. (Native speakers of languages other than English may prefer such orders.)
If there are no sumti before the selbri, then it is understood that the x1 sumti value is equivalent to zo'e; i.e. unimportant or obvious, and therefore not given. Any sumti after the selbri start counting from x2.
|
ta |
[cu] |
melbi |
|
|
object/idea-x1 |
- |
is-beautiful |
(to someone by some standard) |
|
That/Those |
- |
is/are beautiful. |
|
That is beautiful. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Those are beautiful. |
when the x1 is omitted, becomes:
Omitting the x1 adds emphasis to the selbri relation, which has become first in the sentence. This kind of sentence is termed an observative, because it is often used when someone first observes or takes note of the relationship, and wishes to quickly communicate it to someone else. Commonly understood English observatives include “Smoke!” upon seeing smoke or smelling the odor, or “Car!” to a person crossing the street who might be in danger. Any Lojban selbri can be used as an observative if no sumti appear before the selbri.
The word cu does not occur in an observative; cu is a separator, and there must be a sumti before the selbri that needs to be kept separate for cu to be used. With no sumti preceding the selbri, cu is not permitted. Short words like cu which serve grammatical functions are called cmavo in Lojban.
For one reason or another you may want to change the order, placing one particular sumti at the front of the bridi. The cmavo se, when placed before the last word of the selbri, will switch the meanings of the first and second sumti places. So
has the same meaning as
The cmavo te, when used in the same location, switches the meanings of the first and the third sumti places.
has the same meaning as
Note that only the first and third sumti have switched places; the second sumti has remained in the second place.
The cmavo ve and xe switch the first and fourth sumti places, and the first and fifth sumti places, respectively. These changes in the order of places are known as “conversions”, and the se, te, ve, and xe cmavo are said to convert the selbri.
More than one of these operators may be used on a given selbri at one time, and in such a case they are evaluated from left to right. However, in practice they are used one at a time, as there are better tools for complex manipulation of the sumti places. See Section 9.4 for details.
The effect is similar to what in English is called the “passive voice”. In Lojban, the converted selbri has a new place structure that is renumbered to reflect the place reversal, thus having effects when such a conversion is used in combination with other constructs such as le selbri [ku] (see Section 2.10).
People don't always say just one sentence. Lojban has a specific structure for talk or writing that is longer than one sentence. The entirety of a given speech event or written text is called an utterance. The sentences (usually, but not always, bridi) in an utterance are separated by the cmavo ni'o and .i. These correspond to a brief pause (or nothing at all) in spoken English, and the various punctuation marks like period, question mark, and exclamation mark in written English. These separators prevent the sumti at the beginning of the next sentence from being mistaken for a trailing sumti of the previous sentence.
The cmavo ni'o separates paragraphs (covering different topics of discussion). In a long text or utterance, the topical structure of the text may be indicated by multiple ni'o s, with perhaps ni'oni'oni'o used to indicate a chapter, ni'oni'o to indicate a section, and a single ni'o to indicate a subtopic corresponding to a single English paragraph.
The cmavo .i separates sentences. It is sometimes compounded with words that modify the exact meaning (the semantics) of the sentence in the context of the utterance. (The cmavo xu, discussed in Section 2.15, is one such word – it turns the sentence from a statement to a question about truth.) When more than one person is talking, a new speaker will usually omit the .i even though she/he may be continuing on the same topic.
It is still O.K. for a new speaker to say the .i before continuing; indeed, it is encouraged for maximum clarity (since it is possible that the second speaker might merely be adding words onto the end of the first speaker's sentence). A good translation for .i is the “and” used in run-on sentences when people are talking informally: “I did this, and then I did that, and ..., and ...”.
When two gismu are adjacent, the first one modifies the second, and the selbri takes its place structure from the rightmost word. Such combinations of gismu are called tanru. For example,
has the place structure
x1 is a fast type-of talker to x2 about x3 in language x4
x1 talks fast to x2 about x3 in language x4
When three or more gismu are in a row, the first modifies the second, and that combined meaning modifies the third, and that combined meaning modifies the fourth, and so on. For example
has the place structure
That is, it is a shoe that is worn by a fast talker rather than a shoe that is fast and is also worn by a talker.
Note especially the use of “type-of” as a mechanism for connecting the English translations of the two or more gismu; this convention helps the learner understand each tanru in its context. Creative interpretations are also possible, however:
most probably refers to shoes suitable for runners, but might be interpreted in some imaginative instances as “shoes that run (by themselves?)”. In general, however, the meaning of a tanru is determined by the literal meaning of its components, and not by any connotations or figurative meanings. Thus
would not necessarily imply any trickery or deception, unlike the English idiom, and a
must always be a moth or a butterfly.
The place structure of a tanru is always that of the final component of the tanru. Thus, the following has the place structure of klama:
With the conversion se klama as the final component of the tanru, the place structure of the entire selbri is that of se klama: the x1 place is the destination, and the x2 place is the one who goes:
The following example shows that there is more to conversion than merely switching places, though:
|
la tam. |
[cu] |
melbi tavla |
la meris. |
|
Tom |
- |
beautifully-talks |
to Mary. |
|
Tom |
- |
is a beautiful-talker |
to Mary. |
has the place structure of tavla, but note the two distinct interpretations.
Now, using conversion, we can modify the place structure order:
|
la meris. |
[cu] |
melbi se tavla |
la tam. |
|
Mary |
- |
is beautifully-talked-to |
by Tom. |
|
Mary |
- |
is a beautiful-audience |
for Tom. |
and we see that the modification has been changed so as to focus on Mary's role in the bridi relationship, leading to a different set of possible interpretations.
Note that there is no place structure change if the modifying term is converted, and so less drastic variation in possible meanings:
and we see that the manner in which Tom is seen as beautiful by Mary changes, but Tom is still the one perceived as beautiful, and Mary, the observer of beauty.
Often we wish to talk about things other than the speaker, the listener and things we can point to. Let's say I want to talk about a talker other than mi. What I want to talk about would naturally fit into the first place of tavla. Lojban, it turns out, has an operator that pulls this first place out of a selbri and converts it to a sumti called a “description sumti”. The description sumti le tavla ku means “the talker”, and may be used wherever any sumti may be used.
For example,
means the same as
where “the talker” is presumably someone other than me, though not necessarily.
Similarly le sutra tavla ku is “the fast talker”, and le sutra te tavla ku is “the fast subject of talk” or “the subject of fast talk”. Which of these related meanings is understood will depend on the context in which the expression is used. The most plausible interpretation within the context will generally be assumed by a listener to be the intended one.
In many cases the word ku may be omitted. In particular, it is never necessary in a description at the end of a sentence, so:
means exactly the same thing as Example 2.38.
There is a problem when we want to say “The fast one is talking.” The “obvious” translation le sutra tavla turns out to mean “the fast talker”, and has no selbri at all. To solve this problem we can use the word cu, which so far has always been optional, in front of the selbri.
The word cu has no meaning, and exists only to mark the beginning of the selbri within the bridi, separating it from a previous sumti. It comes before any other part of the selbri, including other cmavo like se or te. Thus:
Consider the following more complex example, with two description sumti.
The sumti le vecnu contains the selbri vecnu, which has the “seller” in the x1 place, and uses it in this sentence to describe a particular “seller” that the speaker has in mind (one that he or she probably expects the listener will also know about). Similarly, the speaker has a particular blue-green thing in mind, which is described using le to mark blari'o, a selbri whose first sumti is something blue-green.
It is safe to omit both occurrences of ku in Example 2.45, and it is also safe to omit the cu.
The simplest form of selbri is an individual word. A word which may by itself express a selbri relation is called a brivla. The three types of brivla are gismu (root words), lujvo (compounds), and fu'ivla (borrowings from other languages). All have identical grammatical uses. So far, most of our selbri have been gismu or tanru built from gismu.
|
mi |
[cu] |
klama |
ti |
zo'e |
zo'e |
ta |
|
Go-er |
- |
goes |
destination |
origin |
route |
means. |
|
I go here (to this) using that means (from somewhere via some route). |
Some cmavo may also serve as selbri, acting as variables that stand for another selbri. The most commonly used of these is go'i, which represents the main bridi of the previous Lojban sentence, with any new sumti or other sentence features being expressed replacing the previously expressed ones. Thus, in this context:
In English, I might say “The dog is beautiful”, and you might reply “This pleases me.” How do you know what “this” refers to? Lojban uses different expressions to convey the possible meanings of the English:
The following three sentences all might translate as “This pleases me.”
|
di'u |
[cu] |
pluka |
mi |
|
This (the last sentence) pleases me (perhaps because it is grammatical or sounds nice). |
|
la'e di'u |
[cu] |
pluka |
mi |
|
This (the meaning of the last sentence; i.e. that the dog is beautiful) pleases me. |
Example 2.53 uses one sumti to point to or refer to another by inference. It is common to write la'edi'u as a single word; it is used more often than di'u by itself.
“Possession” refers to the concept of specifying an object by saying who it belongs to (or with). A full explanation of Lojban possession is given in Chapter 8. A simple means of expressing possession, however, is to place a sumti representing the possessor of an object within the description sumti that refers to the object: specifically, between the le and the selbri of the description:
In Lojban, possession doesn't necessarily mean ownership: one may “possess” a chair simply by sitting on it, even though it actually belongs to someone else. English uses possession casually in the same way, but also uses it to refer to actual ownership or even more intimate relationships: “my arm” doesn't mean “some arm I own” but rather “the arm that is part of my body”. Lojban has methods of specifying all these different kinds of possession precisely and easily.
You may call someone's attention to the fact that you are addressing them by using doi followed by their name. The sentence
means “Oh, John, I'm talking to you”. It also has the effect of setting the value of do; do now refers to “John” until it is changed in some way in the conversation. Note that Example 2.55 is not a bridi, but it is a legitimate Lojban sentence nevertheless; it is known as a “vocative phrase”.
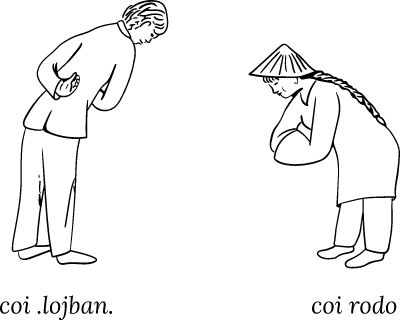
Other cmavo can be used instead of doi in a vocative phrase, with a different significance. For example, the cmavo coi means “hello” and co'o means “good-bye”. Either word may stand alone, they may follow one another, or either may be followed by a Lojbanized name surrounded by pauses.
Commands are expressed in Lojban by a simple variation of the main bridi structure. If you say
you are simply making a statement of fact. In order to issue a command in Lojban, substitute the word ko for do. The bridi
instructs the listener to do whatever is necessary to make Example 2.58 true; it means “Talk!” Other examples:
The ko need not be in the x1 place, but rather can occur anywhere a sumti is allowed, leading to possible Lojban commands that are very unlike English commands:
The cmavo ko can fill any appropriate sumti place, and can be used as often as is appropriate for the selbri:
and
both mean “You take care of you” and “Be taken care of by you”, or to put it colloquially, “Take care of yourself”.
There are many kinds of questions in Lojban: full explanations appear in Section 19.5 and in various other chapters throughout the book. In this chapter, we will introduce three kinds: sumti questions, selbri questions, and yes/no questions.
The cmavo ma is used to create a sumti question: it indicates that the speaker wishes to know the sumti which should be placed at the location of the ma to make the bridi true. It can be translated as “Who?” or “What?” in most cases, but also serves for “When?”, “Where?”, and “Why?” when used in sumti places that express time, location, or cause. For example:
The listener can reply by simply stating a sumti:
Like ko, ma can occur in any position where a sumti is allowed, not just in the first position:
A ma can also appear in multiple sumti positions in one sentence, in effect asking several questions at once.
The two separate ma positions ask two separate questions, and can therefore be answered with different values in each sumti place.
The cmavo mo is the selbri analogue of ma. It asks the respondent to provide a selbri that would be a true relation if inserted in place of the mo:
A mo may be used anywhere a brivla or other selbri might. Keep this in mind for later examples. Unfortunately, by itself, mo is a very non-specific question. The response to the question in Example 2.68 could be:
or:
Clearly, mo requires some cooperation between the speaker and the respondent to ensure that the right question is being answered. If context doesn't make the question specific enough, the speaker must ask the question more specifically using a more complex construction such as a tanru (see Section 2.9).
It is perfectly permissible for the respondent to fill in other unspecified places in responding to a mo question. Thus, the respondent in Example 2.70 could have also specified an audience, a topic, and/or a language in the response.
Finally, we must consider questions that can be answered “Yes” or “No”, such as
Like all yes-or-no questions in English, Example 2.71 may be reformulated as
In Lojban we have a word that asks precisely that question in precisely the same way. The cmavo xu, when placed in front of a bridi, asks whether that bridi is true as stated. So
is the Lojban translation of Example 2.71.
The answer “Yes” may be given by simply restating the bridi without the xu question word. Lojban has a shorthand for doing this with the word go'i, mentioned in Section 2.11. Instead of a negative answer, the bridi may be restated in such a way as to make it true. If this can be done by substituting sumti, it may be done with go'i as well. For example:
can be answered with
or
(Note that do to the questioner is mi to the respondent.)
or
or
A general negative answer may be given by na go'i. na may be placed before any selbri (but after the cu). It is equivalent to stating “It is not true that ...” before the bridi. It does not imply that anything else is true or untrue, only that that specific bridi is not true. More details on negative statements are available in Chapter 15.
Different cultures express emotions and attitudes with a variety of intonations and gestures that are not usually included in written language. Some of these are available in some languages as interjections (i.e. “Aha!”, “Oh no!”, “Ouch!”, “Aahh!”, etc.), but they vary greatly from culture to culture.
Lojban has a group of cmavo known as “attitudinal indicators” which specifically covers this type of commentary on spoken statements. They are both written and spoken, but require no specific intonation or gestures. Grammatically they are very simple: one or more attitudinals at the beginning of a bridi apply to the entire bridi; anywhere else in the bridi they apply to the word immediately to the left. For example:
|
mi |
[cu] |
klama |
le melbi |
|
I |
- |
go |
to-the beautiful-thing |
|
.ui |
[ku] |
|
and I am happy because it is the beautiful thing I'm going to |
- |
Not all indicators indicate attitudes. Discursives, another group of cmavo with the same grammatical rules as attitudinal indicators, allow free expression of certain kinds of commentary about the main utterances. Using discursives allows a clear separation of these so-called “metalinguistic” features from the underlying statements and logical structure. By comparison, the English words “but” and “also”, which discursively indicate contrast or an added weight of example, are logically equivalent to “and”, which does not have a discursive content. The average English-speaker does not think about, and may not even realize, the paradoxical idea that “but” basically means “and”.
Another group of indicators are called “evidentials”. Evidentials show the speaker's relationship to the statement, specifically how the speaker came to make the statement. These include za'a (I directly observe the relationship), pe'i (I believe that the relationship holds), ru'a (I postulate the relationship), and others. Many American Indian languages use this kind of words.
In English, every verb is tagged for the grammatical category called tense: past, present, or future. The sentence
necessarily happens at some time in the past, whereas
is necessarily happening right now.
serves as a translation of either Example 2.87 or Example 2.88, and of many other possible English sentences as well. It is not marked for tense, and can refer to an event in the past, the present or the future. This rule does not mean that Lojban has no way of representing the time of an event. A close translation of Example 2.87 would be:
where the tag pu forces the sentence to refer to a time in the past. Similarly,
necessarily refers to the present, because of the tag ca. Tags used in this way always appear at the very beginning of the selbri, just after the cu, and they may make a cu unnecessary, since tags cannot be absorbed into tanru. Such tags serve as an equivalent to English tenses and adverbs. In Lojban, tense information is completely optional. If unspecified, the appropriate tense is picked up from context.
Lojban also extends the notion of “tense” to refer not only to time but to space. The following example uses the tag vu to specify that the event it describes happens far away from the speaker:
In addition, tense tags (either for time or space) can be prefixed to the selbri of a description, producing a tensed sumti:
(Since Lojban tense is optional, we don't know when he or she talks.)
Tensed sumti with space tags correspond roughly to the English use of “this” or “that” as adjectives, as in the following example, which uses the tag vi meaning “nearby”:
Do not confuse the use of vi in Example 2.94 with the cmavo ti, which also means “this”, but in the sense of “this thing”.
Furthermore, a tense tag can appear both on the selbri and within a description, as in the following example (where ba is the tag for future time):
|
le ca vi tavla |
[ku] |
[cu] |
ba vu tavla |
|
The [present] here talker |
- |
- |
[future] there talks. |
|
The one who is talking here will talk there. |
Here is a review of the Lojban grammatical terms used in this chapter, plus some others used throughout this book. Only terms that are themselves Lojban words are included: there are of course many expressions like “indicator” in Chapter 16 that are not explained here. See the Index for further help with these.
| bridi | predication; the basic unit of Lojban expression; the main kind of Lojban sentence; a claim that some objects stand in some relationship, or that some single object has some property. |
| sumti | argument; words identifying something which stands in a specified relationship to something else, or which has a specified property. See Chapter 6. |
| selbri | logical predicate; the core of a bridi; the word or words specifying the relationship between the objects referred to by the sumti. See Chapter 5. |
| cmavo | one of the Lojban parts of speech; a short word; a structural word; a word used for its grammatical function. |
| brivla | one of the Lojban parts of speech; a content word; a predicate word; can function as a selbri; is a gismu, a lujvo, or a fu'ivla. See Chapter 4. |
| gismu | a root word; a kind of brivla; has associated rafsi. See Chapter 4. |
| lujvo | a compound word; a kind of brivla; may or may not appear in a dictionary; does not have associated rafsi. See Chapter 4 and Chapter 12. |
| fu'ivla | a borrowed word; a kind of brivla; may or may not appear in a dictionary; copied in a modified form from some non-Lojban language; usually refers to some aspect of culture or the natural world; does not have associated rafsi. See Chapter 4. |
| rafsi | a word fragment; one or more is associated with each gismu; can be assembled according to rules in order to make lujvo; not a valid word by itself. See Chapter 4. |
| tanru | a group of two or more brivla, possibly with associated cmavo, that form a selbri; always divisible into two parts, with the first part modifying the meaning of the second part (which is taken to be basic). See Chapter 5. |
| selma'o | a group of cmavo that have the same grammatical use (can appear interchangeably in sentences, as far as the grammar is concerned) but differ in meaning or other usage. See Chapter 20. |
Lojban is designed so that any properly spoken Lojban utterance can be uniquely transcribed in writing, and any properly written Lojban can be spoken so as to be uniquely reproduced by another person. As a consequence, the standard Lojban orthography must assign to each distinct sound, or phoneme, a unique letter or symbol. Each letter or symbol has only one sound or, more accurately, a limited range of sounds that are permitted pronunciations for that phoneme. Some symbols indicate stress (speech emphasis) and pause, which are also essential to Lojban word recognition. In addition, everything that is represented in other languages by punctuation (when written) or by tone of voice (when spoken) is represented in Lojban by words. These two properties together are known technically as “audio-visual isomorphism”.
Lojban uses a variant of the Latin (Roman) alphabet, consisting of the following letters and symbols:
| ' | , | . | a | b | c | d | e | f | g | i | j | k |
| l | m | n | o | p | r | s | t | u | v | x | y | z |
omitting the letters “h” , “q” , and “w”.
The alphabetic order given above is that of the ASCII coded character set, widely used in computers. By making Lojban alphabetical order the same as ASCII, computerized sorting and searching of Lojban text is facilitated.
Capital letters are used only to represent non-standard stress, which can appear only in the representation of Lojbanized names. Thus the English name “Josephine” , as normally pronounced, is Lojbanized as .DJOsefin. , pronounced ['ʔdʒosɛfinʔ]. (See Section 3.2 for an explanation of the symbols within square brackets.) Technically, it is sufficient to capitalize the vowel letter, in this case O , but it is easier on the reader to capitalize the whole syllable.
Without the capitalization, the ordinary rules of Lojban stress would cause the se syllable to be stressed. Lojbanized names are meant to represent the pronunciation of names from other languages with as little distortion as may be; as such, they are exempt from many of the regular rules of Lojban phonology, as will appear in the rest of this chapter.
Lojban pronunciations are defined using the International Phonetic Alphabet, or IPA, a standard method of transcribing pronunciations. By convention, IPA transcriptions are always within square brackets: for example, the word “cat” is pronounced (in General American pronunciation) [kæt]. Section 3.10 contains a brief explanation of the IPA characters used in this chapter, with their nearest analogues in English, and will be especially useful to those not familiar with the technical terms used in describing speech sounds.
The standard pronunciations and permitted variants of the Lojban letters are listed in the table below. The descriptions have deliberately been made a bit ambiguous to cover variations in pronunciation by speakers of different native languages and dialects. In all cases except r the first IPA symbol shown represents the preferred pronunciation; for r , all of the variations (and any other rhotic sound) are equally acceptable.
| Letter | IPA | X-SAMPA | Description |
| ' | [h] | [h] | an unvoiced glottal spirant |
| , | . | . | the syllable separator |
| . | [ʔ] | [?] | a glottal stop or a pause |
| a | [a] , [ɑ] | [a] , [A] | an open vowel |
| b | [b] | [b] | a voiced bilabial stop |
| c | [ʃ] , [ʂ] | [S] , [s`] | a voiceless postalveolar fricative |
| d | [d] | [d] | a voiced dental/alveolar stop |
| e | [ɛ] , [e] | [E] , [e] | a front mid vowel |
| f | [f] , [ɸ] | [f] , [p\] | an unvoiced labial fricative |
| g | [ɡ] | [g] | a voiced velar stop |
| i | [i] | [i] | a front close vowel |
| j | [ʒ] , [ʐ] | [Z] , [z`] | a voiced postalveolar fricative |
| k | [k] | [k] | an unvoiced velar stop |
| l | [l] , [l̩] | [l] , [l=] | a voiced lateral approximant (may be syllabic) |
| m | [m] , [m̩] | [m] , [m=] | a voiced bilabial nasal (may be syllabic) |
| n | [n] , [n̩] , [ŋ] , [ŋ̍] | [n] , [n=] , [N] , [N=] | a voiced dental or velar nasal (may be syllabic) |
| o | [o] , [ɔ] | [o] , [O] | a back mid vowel |
| p | [p] | [p] | an unvoiced bilabial stop |
| r | [r] , [ɹ] , [ɾ] , [ʀ] , [r̩] , [ɹ̩] , [ʀ̩] | [r] , [r\] , [4] , [R\] , [r=] , [r\=] , [R\=] | a rhotic sound |
| s | [s] | [s] | an unvoiced alveolar sibilant |
| t | [t] | [t] | an unvoiced dental/alveolar stop |
| u | [u] | [u] | a back close vowel |
| v | [v] , [β] | [v] , [B] | a voiced labial fricative |
| x | [x] | [x] | an unvoiced velar fricative |
| y | [ə] | [@] | a central mid vowel |
| z | [z] | [z] | a voiced alveolar sibilant |
The Lojban sounds must be clearly pronounced so that they are not mistaken for each other. Voicing and placement of the tongue are the key factors in correct pronunciation, but other subtle differences will develop between consonants in a Lojban-speaking community. At this point these are the only mandatory rules on the range of sounds.
Note in particular that Lojban vowels can be pronounced with either rounded or unrounded lips; typically o and u are rounded and the others are not, as in English, but this is not a requirement; some people round y as well. Lojban consonants can be aspirated or unaspirated. Palatalizing of consonants, as found in Russian and other languages, is not generally acceptable in pronunciation, though a following i may cause it.
The sounds represented by the letters c , g , j , s , and x require special attention for speakers of English, either because they are ambiguous in the orthography of English ( c , g , s), or because they are strikingly different in Lojban ( c , j , x). The English “c” represents three different sounds, [k] in “cat” and [s] in “cent” , as well as the [ʃ] of “ocean”. Similarly, English “g” can represent [ɡ] as in “go” , [dʒ] as in “gentle” , and [ʒ] as in the second "g" in “garage” (in some pronunciations). English “s” can be either [s] as in “cats” , [z] as in “cards” , [ʃ] as in “tension” , or [ʒ] as in “measure”. The sound of Lojban x doesn't appear in most English dialects at all.
There are two common English sounds that are found in Lojban but are not Lojban consonants: the “ch” of “church” and the “j” of “judge”. In Lojban, these are considered two consonant sounds spoken together without an intervening vowel sound, and so are represented in Lojban by the two separate consonants: tc (IPA [tʃ]) and dj (IPA [dʒ]). In general, whether a complex sound is considered one sound or two depends on the language: Russian views “ts” as a single sound, whereas English, French, and Lojban consider it to be a consonant cluster.
The apostrophe, period, and comma need special attention. They are all used as indicators of a division between syllables, but each has a different pronunciation, and each is used for different reasons:
The apostrophe represents a phoneme similar to a short, breathy English “h” , (IPA [h]). The letter “h” is not used to represent this sound for two reasons: primarily in order to simplify explanations of the morphology, but also because the sound is very common, and the apostrophe is a visually lightweight representation of it. The apostrophe sound is a consonant in nature, but is not treated as either a consonant or a vowel for purposes of Lojban morphology (word-formation), which is explained in Chapter 4. In addition, the apostrophe visually parallels the comma and the period, which are also used (in different ways) to separate syllables.
The apostrophe is included in Lojban only to enable a smooth transition between vowels, while joining the vowels within a single word. In fact, one way to think of the apostrophe is as representing an unvoiced vowel glide.
As a permitted variant, any unvoiced fricative other than those already used in Lojban may be used to render the apostrophe: IPA [θ] is one possibility. The convenience of the listener should be regarded as paramount in deciding to use a substitute for [h].
The period represents a mandatory pause, with no specified length; a glottal stop (IPA [ʔ]) is considered a pause of shortest length. A pause (or glottal stop) may appear between any two words, and in certain cases – explained in detail in Section 4.9 – must occur. In particular, a word beginning with a vowel is always preceded by a pause, and a word ending in a consonant is always surrounded by pauses.
Technically, the period is an optional reminder to the reader of a mandatory pause that is dictated by the rules of the language; because these rules are unambiguous, a missing period can be inferred from otherwise correct text. Periods are included only as an aid to the reader.
A period also may be found apparently embedded in a word. When this occurs, such a written string is not one word but two, written together to indicate that the writer intends a unitary meaning for the compound. It is not really necessary to use a space between words if a period appears.
The comma is used to indicate a syllable break within a word, generally one that is not obvious to the reader. Such a comma is written to separate syllables, but indicates that there must be no pause between them, in contrast to the period. Between two vowels, a comma indicates that some type of glide may be necessary to avoid a pause that would split the two syllables into separate words. It is always legal to use the apostrophe (IPA [h]) sound in pronouncing a comma. However, a comma cannot be pronounced as a pause or glottal stop between the two letters separated by the comma, because that pronunciation would split the word into two words.
Otherwise, a comma is usually only used to clarify the presence of syllabic l , m , n , or r (discussed later). Commas are never required: no two Lojban words differ solely because of the presence or placement of a comma.
Here is a somewhat artificial example of the difference in pronunciation between periods, commas and apostrophes. In the English song about Old MacDonald's Farm, the vowel string which is written as “ee-i-ee-i-o” in English could be Lojbanized with periods as:
However, this would sound clipped, staccato, and unmusical compared to the English. Furthermore, although Example 3.1 is a string of meaningful Lojban words, as a sentence it makes very little sense. (Note the use of periods embedded within the written word.)
If commas were used instead of periods, we could represent the English string as a Lojbanized name, ending in a consonant:
The commas represent new syllable breaks, but prohibit the use of pauses or glottal stop. The pronunciation shown is just one possibility, but closely parallels the intended English pronunciation.
However, the use of commas in this way is risky to unambiguous interpretation, since the glides might be heard by some listeners as diphthongs, producing something like
which is technically a different Lojban name. Since the intent with Lojbanized names is to allow them to be pronounced more like their native counterparts, the comma is allowed to represent vowel glides or some non-Lojbanic sound. Such an exception affects only spelling accuracy and the ability of a reader to replicate the desired pronunciation exactly; it will not affect the recognition of word boundaries.
Still, it is better if Lojbanized names are always distinct. Therefore, the apostrophe is preferred in regular Lojbanized names that are not attempting to simulate a non-Lojban pronunciation perfectly. (Perfection, in any event, is not really achievable, because some sounds simply lack reasonable Lojbanic counterparts.)
If apostrophes were used instead of commas in Example 3.2 , it would appear as:
which preserves the rhythm and length, if not the exact sounds, of the original English.
There exist 16 diphthongs in the Lojban language. A diphthong is a vowel sound that consists of two elements, a short vowel sound and a glide, either a labial (IPA [w]) or palatal (IPA [j]) glide, that either precedes (an on-glide) or follows (an off-glide) the main vowel. Diphthongs always constitute a single syllable.
For Lojban purposes, a vowel sound is a relatively long speech-sound that forms the nucleus of a syllable. Consonant sounds are relatively brief and normally require an accompanying vowel sound in order to be audible. Consonants may occur at the beginning or end of a syllable, around the vowel, and there may be several consonants in a cluster in either position. Each separate vowel sound constitutes a distinct syllable; consonant sounds do not affect the determination of syllables.
The six Lojban vowels are a , e , i , o , u , and y. The first five vowels appear freely in all kinds of Lojban words. The vowel y has a limited distribution: it appears only in Lojbanized names, in the Lojban names of the letters of the alphabet, as a glue vowel in compound words, and standing alone as a space-filler word (like English “uh” or “er”).
The Lojban diphthongs are shown in the table below. (Variant pronunciations have been omitted, but are much as one would expect based on the variant pronunciations of the separate vowel letters: ai may be pronounced [ɑj] , for example.)
| Letters | IPA | Description |
| ai | [aj] | an open vowel with palatal off-glide |
| ei | [ɛj] | a front mid vowel with palatal off-glide |
| oi | [oj] | a back mid vowel with palatal off-glide |
| au | [aw] | an open vowel with labial off-glide |
| ia | [ja] | an open vowel with palatal on-glide |
| ie | [jɛ] | a front mid vowel with palatal on-glide |
| ii | [ji] | a front close vowel with palatal on-glide |
| io | [jo] | a back mid vowel with palatal on-glide |
| iu | [ju] | a back close vowel with palatal on-glide |
| ua | [wa] | an open vowel with labial on-glide |
| ue | [wɛ] | a front mid vowel with labial on-glide |
| ui | [wi] | a front close vowel with labial on-glide |
| uo | [wo] | a back mid vowel with labial on-glide |
| uu | [wu] | a back close vowel with labial on-glide |
| iy | [jə] | a central mid vowel with palatal on-glide |
| uy | [wə] | a central mid vowel with labial on-glide |
(Approximate English equivalents of most of these diphthongs exist: see Section 3.11 for examples.)
The first four diphthongs above ( ai , ei , oi , and au , the ones with off-glides) are freely used in most types of Lojban words; the ten following ones are used only as stand-alone words and in Lojbanized names and borrowings; and the last two ( iy and uy) are used only in Lojbanized names.
The syllabic consonants of Lojban, [l̩] , [m̩] , [n̩] , and [r̩] , are variants of the non-syllabic [l] , [m] , [n] , and [r] respectively. They normally have only a limited distribution, appearing in Lojbanized names and borrowings, although in principle any l , m , n , or r may be pronounced syllabically. If a syllabic consonant appears next to a l , m , n , or r that is not syllabic, it may not be clear which is which:
is a hypothetical Lojbanized name with more than one valid pronunciation; however it is pronounced, it remains the same word.
Syllabic consonants are treated as consonants rather than vowels from the standpoint of Lojban morphology. Thus Lojbanized names, which are generally required to end in a consonant, are allowed to end with a syllabic consonant. An example is .rl. , which is an approximation of the English name “Earl” , and has two syllabic consonants.
Syllables with syllabic consonants and no vowel are never stressed or counted when determining which syllables to stress (see Section 3.9).
Lojban vowels also occur in pairs, where each vowel sound is in a separate syllable. These two vowel sounds are connected (and separated) by an apostrophe. Lojban vowel pairs should be pronounced continuously with the [h] sound between (and not by a glottal stop or pause, which would split the two vowels into separate words).
All vowel combinations are permitted in two-syllable pairs with the apostrophe separating them; this includes those which constitute diphthongs when the apostrophe is not included.
| a'a | a'e | a'i | a'o | a'u | a'y |
| e'a | e'e | e'i | e'o | e'u | e'y |
| i'a | i'e | i'i | i'o | i'u | i'y |
| o'a | o'e | o'i | o'o | o'u | o'y |
| u'a | u'e | u'i | u'o | u'u | u'y |
| y'a | y'e | y'i | y'o | y'u | y'y |
Vowel pairs involving y appear only in Lojbanized names. They could appear in cmavo (structure words), but only .y'y. is so used – it is the Lojban name of the apostrophe letter (see Section 17.2).
When more than two vowels occur together in Lojban, the normal pronunciation pairs vowels from the left into syllables, as in the Lojbanized name:
Example 3.6 contains the diphthong ei followed by the vowel i. In order to indicate a different grouping, the comma must always be used, leading to:
which contains the vowel e followed by the diphthong ii. In rough English representation, Example 3.6 is “May Een” , whereas Example 3.7 is “Meh Yeen”.
A consonant sound is a relatively brief speech-sound that precedes or follows a vowel sound in a syllable; its presence either preceding or following does not add to the count of syllables, nor is a consonant required in either position for any syllable. Lojban has seventeen consonants: for the purposes of this section, the apostrophe is not counted as a consonant.
An important distinction dividing Lojban consonants is that of voicing. The following table shows the unvoiced consonants and the corresponding voiced ones:
| UNVOICED | VOICED |
| p | b |
| t | d |
| k | g |
| f | v |
| c | j |
| s | z |
| x | - |
The consonant x has no voiced counterpart in Lojban. The remaining consonants, l , m , n , and r , are typically pronounced with voice, but can be pronounced unvoiced.
Consonant sounds occur in languages as single consonants, or as doubled, or as clustered combinations. Single consonant sounds are isolated by word boundaries or by intervening vowel sounds from other consonant sounds. Doubled consonant sounds are either lengthened like [s] in English “hiss” , or repeated like [k] in English “backcourt”. Consonant clusters consist of two or more single or doubled consonant sounds in a group, each of which is different from its immediate neighbor. In Lojban, doubled consonants are excluded altogether, and clusters are limited to two or three members, except in Lojbanized names.
Consonants can occur in three positions in words: initial (at the beginning), medial (in the middle), and final (at the end). In many languages, the sound of a consonant varies depending upon its position in the word. In Lojban, as much as possible, the sound of a consonant is unrelated to its position. In particular, the common American English trait of changing a “t” between vowels into a “d” or even an alveolar tap (IPA [ɾ]) is unacceptable in Lojban.
Lojban imposes no restrictions on the appearance of single consonants in any valid consonant position; however, no consonant (including syllabic consonants) occurs final in a word except in Lojbanized names.
Pairs of consonants can also appear freely, with the following restrictions:
-
It is forbidden for both consonants to be the same, as this would violate the rule against double consonants.
-
It is forbidden for one consonant to be voiced and the other unvoiced. The consonants l , m , n , and r are exempt from this restriction. As a result, bf is forbidden, and so is sd , but both fl and vl , and both ls and lz , are permitted.
-
It is forbidden for both consonants to be drawn from the set c , j , s , z.
-
The specific pairs cx , kx , xc , xk , and mz are forbidden.
These rules apply to all kinds of words, even Lojbanized names. If a name would normally contain a forbidden consonant pair, a y can be inserted to break up the pair:
The regular English pronunciation of “James” , which is [dʒɛjmz] , would Lojbanize as .djeimz. , which contains a forbidden consonant pair.
The set of consonant pairs that may appear at the beginning of a word (excluding Lojbanized names) is far more restricted than the fairly large group of permissible consonant pairs described in Section 3.6. Even so, it is more than English allows, although hopefully not more than English-speakers (and others) can learn to pronounce.
There are just 48 such permissible initial consonant pairs, as follows:
| bl | br | ||||||
| cf | ck | cl | cm | cn | cp | cr | ct |
| dj | dr | dz | |||||
| fl | fr | ||||||
| gl | gr | ||||||
| jb | jd | jg | jm | jv | |||
| kl | kr | ||||||
| ml | mr | ||||||
| pl | pr | ||||||
| sf | sk | sl | sm | sn | sp | sr | st |
| tc | tr | ts | |||||
| vl | vr | ||||||
| xl | xr | ||||||
| zb | zd | zg | zm | zv |
Lest this list seem almost random, a pairing of voiced and unvoiced equivalent consonants will show significant patterns which may help in learning:
| pl | pr | fl | fr | ||||||||
| bl | br | vl | vr | ||||||||
| cp | cf | ct | ck | cm | cn | cl | cr | ||||
| jb | jv | jd | jg | jm | |||||||
| sp | sf | st | sk | sm | sn | sl | sr | ||||
| zb | zv | zd | zg | zm | |||||||
| tc | tr | ts | kl | kr | |||||||
| dj | dr | dz | gl | gr | |||||||
| ml | mr | xl | xr |
Note that if both consonants of an initial pair are voiced, the unvoiced equivalent is also permissible, and the voiced pair can be pronounced simply by voicing the unvoiced pair. (The converse is not true: cn is a permissible initial pair, but jn is not.)
Consonant triples can occur medially in Lojban words. They are subject to the following rules:
Lojbanized names can begin or end with any permissible consonant pair, not just the 48 initial consonant pairs listed above, and can have consonant triples in any location, as long as the pairs making up those triples are permissible. In addition, Lojbanized names can contain consonant clusters with more than three consonants, again requiring that each pair within the cluster is valid.
Many languages do not have consonant clusters at all, and even those languages that do have them often allow only a subset of the full Lojban set. As a result, the Lojban design allows the use of a buffer sound between consonant combinations which a speaker finds unpronounceable. This sound may be any non-Lojbanic vowel which is clearly separable by the listener from the Lojban vowels. Some possibilities are IPA [ɪ] , [ɨ] , [ʊ] , or even [ʏ] , but there probably is no universally acceptable buffer sound. When using a consonant buffer, the sound should be made as short as possible. Two examples showing such buffering (we will use [ɪ] in this chapter) are:
When a buffer vowel is used, it splits each buffered consonant into its own syllable. However, the buffering syllables are never stressed, and are not counted in determining stress. They are, in effect, not really syllables to a Lojban listener, and thus their impact is ignored.
Here are more examples of unbuffered and buffered pronunciations:
In Example 3.12 , we see that buffering vowels can be used in just some, rather than all, of the possible places: the second pronunciation buffers the pc consonant pair but not the ck. The third pronunciation buffers both.
Example 3.13 cannot contain any buffering vowel. It is important not to confuse the vowel y , which is pronounced [ə] , with the buffer, which has a variety of possible pronunciations and is never written. Consider the contrast between
an unlikely Lojban compound word meaning “bone bread” (note the use of [ŋ] as a representative of n before g) and
a possible borrowing from another language (Lojban borrowings can only take a limited form). If Example 3.15 were pronounced with buffering, as
it would be very similar to Example 3.14. Only a clear distinction between y and any buffering vowel would keep the two words distinct.
Since buffering is done for the benefit of the speaker in order to aid pronounceability, there is no guarantee that the listener will not mistake a buffer vowel for one of the six regular Lojban vowels. The buffer vowel should be as laxly pronounced as possible, as central as possible, and as short as possible. Furthermore, it is worthwhile for speakers who use buffers to pronounce their regular vowels a bit longer than usual, to avoid confusion with buffer vowels. The speakers of many languages will have trouble correctly hearing any of the suggested buffer vowels otherwise. By this guideline, Example 3.16 would be pronounced
with lengthened vowels.
A Lojban word has one syllable for each of its vowels, diphthongs, and syllabic consonants (referred to simply as “vowels” for the purposes of this section). Syllabication rules determine which of the consonants separating two vowels belong to the preceding vowel and which to the following vowel. These rules are conventional only; the phonetic facts of the matter about how utterances are syllabified in any language are always very complex.
A single consonant always belongs to the following vowel. A consonant pair is normally divided between the two vowels; however, if the pair constitute a valid initial consonant pair, they are normally both assigned to the following vowel. A consonant triple is divided between the first and second consonants. Apostrophes and commas, of course, also represent syllable breaks. Syllabic consonants usually appear alone in their syllables.
It is permissible to vary from these rules in Lojbanized names. For example, there are no definitive rules for the syllabication of Lojbanized names with consonant clusters longer than three consonants. The comma is used to indicate variant syllabication or to explicitly mark normal syllabication.
Here are some examples of Lojban syllabication:
This word has no consonant pairs and is therefore syllabified before each medial consonant.
This word is split at a consonant pair.
This word is split at a consonant triple, between the first two consonants of the triple.
This word contains the consonant pair rg ; the r may be pronounced syllabically or not.
This word contains the permissible initial pair zb , and so may be syllabicated either between z and b or before zb.
Stress is a relatively louder pronunciation of one syllable in a word or group of words. Since every syllable has a vowel sound (or diphthong or syllabic consonant) as its nucleus, and the stress is on the vowel sound itself, the terms “stressed syllable” and “stressed vowel” are largely interchangeable concepts.
Most Lojban words are stressed on the next-to-the-last, or penultimate, syllable. In counting syllables, however, syllables whose vowel is y or which contain a syllabic consonant ( l , m , n , or r) are never counted. (The Lojban term for penultimate stress is da'amoi terbasna.) Similarly, syllables created solely by adding a buffer vowel, such as [ɪ] , are not counted.
There are actually three levels of stress – primary, secondary, and weak. Weak stress is the lowest level, so it really means no stress at all. Weak stress is required for syllables containing y , a syllabic consonant, or a buffer vowel.
Primary stress is required on the penultimate syllable of Lojban content words (called brivla). Lojbanized names (called cmevla) may be stressed on any syllable, but if a syllable other than the penultimate is stressed, the syllable (or at least its vowel) must be capitalized in writing. Lojban structural words (called cmavo) may be stressed on any syllable or none at all. However, primary stress may not be used in a syllable just preceding a brivla, unless a pause divides them; otherwise, the two words may run together.
Secondary stress is the optional and non-distinctive emphasis used for other syllables besides those required to have either weak or primary stress. There are few rules governing secondary stress, which typically will follow a speaker's native language habits or preferences. Secondary stress can be used for contrast, or for emphasis of a point. Secondary stress can be emphasized at any level up to primary stress, although the speaker must not allow a false primary stress in brivla, since errors in word resolution could result.
The following are Lojban words with stress explicitly shown:
(In a fully-buffered dialect, the pronunciation would be: ['di kə ʒɪ vo].) Note that the syllable ky. is not counted in determining stress. The vowel y is never stressed in a normal Lojban context.
This is a Lojbanized version of the name “Armstrong”. The final g must be explicitly pronounced. With full buffering, the name would be pronounced:
However, there is no need to insert a buffer in every possible place just because it is inserted in one place: partial buffering is also acceptable. In every case, however, the stress remains in the same place: on the first syllable.
The English pronunciation of “Armstrong” , as spelled in English, is not correct by Lojban standards; the letters “ng” in English represent a velar nasal (IPA [ŋ]) which is a single consonant. In Lojban, ng represents two separate consonants that must both be pronounced; you may not use [ŋ] to pronounce Lojban ng , although [ŋg] is acceptable. English speakers are likely to have to pronounce the ending with a buffer, as one of the following:
The normal English pronunciation of the name “Armstrong” could be Lojbanized as:
since Lojban n is allowed to be pronounced as the velar nasal [ŋ].
Here is another example showing the use of y :
This word is a compound word, or lujvo, built from the two affixes bis and dja. When they are joined, an impermissible consonant pair results: sd. In accordance with the algorithm for making lujvo, explained in Section 4.11 , a y is inserted to separate the impermissible consonant pair; the y is not counted as a syllable for purposes of stress determination.
These two syllabications sound the same to a Lojban listener – the association of unbuffered consonants in syllables is of no import in recognizing the word.
In Example 3.30 , .e'u is a cmavo and bridi is a brivla. Either of the first two pronunciations is permitted: no primary stress on either syllable of .e'u , or primary stress on the first syllable. The third pronunciation, which places primary stress on the second syllable of the cmavo, requires that – since the following word is a brivla – the two words must be separated by a pause. Consider the following two cases:
If the cmavo no in Example 3.32 were to be stressed, the phrase would sound exactly like the given pronunciation of Example 3.31 , which is unacceptable in Lojban: a single pronunciation cannot represent both.
There are many dialects of English, thus making it difficult to define the standardized symbols of the IPA in terms useful to every reader. All the symbols used in this chapter are repeated here, in more or less alphabetical order, with examples drawn from General American. In addition, some attention is given to the Received Pronunciation of (British) English. These two dialects are referred to as GA and RP respectively. Speakers of other dialects should consult a book on phonetics or their local television sets.
| [ˈ] | An IPA indicator of primary stress; the syllable which follows [ˈ] receives primary stress. |
| [ʔ] | An allowed variant of Lojban .. This sound is not usually considered part of English. It is the catch in your throat that sometimes occurs prior to the beginning of a word (and sometimes a syllable) which starts with a vowel. In some dialects, like Cockney and some kinds of American English, it is used between vowels instead of “t” : “bottle” [boʔl̩]. The English interjection “uh-oh!” almost always has it between the syllables. |
| [ː] | A symbol indicating that the previous vowel is to be spoken for a longer time than usual. Lojban vowels can be pronounced long in order to make a greater contrast with buffer vowels. |
| [a] | The preferred pronunciation of Lojban a. This sound doesn't occur in GA, but sounds somewhat like the “ar” of “park” , as spoken in RP or New England American. It is pronounced further forward in the mouth than [ɑ]. |
| [ɑ] | An allowed variant of Lojban a. The “a” of GA “father”. The sound [a] is preferred because GA speakers often relax an unstressed [ɑ] into a schwa [ə] , as in the usual pronunciations of “about” and “sofa”. Because schwa is a distinct vowel in Lojban, English speakers must either learn to avoid this shift or to use [a] instead: the Lojban word for “sofa” is sfofa , pronounced [sfofa] or [sfofɑ] but never [sfofə] which would be the non-word sfofy. |
| [æ] | Not a Lojban sound. The “a” of English “cat”. |
| [b] | The preferred pronunciation of Lojban b. As in English “boy” , “sober” , or “job”. |
| [β] | An allowed variant of Lojban v. Not an English sound; the Spanish “b” or “v” between vowels. This sound should not be used for Lojban b. |
| [d] | The preferred pronunciation of Lojban d. As in English “dog” , “soda” , or “mad”. |
| [ɛ] | The preferred pronunciation of Lojban e. The “e” of English “met”. |
| [e] | An allowed variant of Lojban e. This sound is not found in English, but is the Spanish “e” , or the tense «e» of Italian. The vowel of English “say” is similar except for the off-glide: you can learn to make this sound by holding your tongue steady while saying the first part of the English vowel. |
| [ə] | The preferred pronunciation of Lojban y. As in the “a” of English “sofa” or “about”. Schwa is generally unstressed in Lojban, as it is in English. It is a totally relaxed sound made with the tongue in the middle of the mouth. |
| [f] | The preferred pronunciation of Lojban f. As in “fee” , “loafer” , or “chef”. |
| [ɸ] | An allowed variant of Lojban f. Not an English sound; the Japanese “f” sound. |
| [g] | The preferred pronunciation of Lojban g. As in English “go” , “eagle” , or “dog”. |
| [h] | The preferred pronunciation of the Lojban apostrophe sound. As in English “aha” or the second "h" in “oh, hello”. |
| [i] | The preferred pronunciation of Lojban i. Essentially like the English vowel of “pizza” or “machine” , although the English vowel is sometimes pronounced with an off-glide, which should not be present in Lojban. |
| [ɪ] | A possible Lojban buffer vowel. The “i” of English “bit”. |
| [ɨ] | A possible Lojban buffer vowel. The “u” of “just” in some varieties of GA, those which make the word sound more or less like “jist”. Also Russian «y» as in «byt'» (to be); like a schwa [ə] , but higher in the mouth. |
| [j] | Used in Lojban diphthongs beginning or ending with i. Like the “y” in English “yard” or “say”. |
| [k] | The preferred pronunciation of Lojban k. As in English “kill” , “token” , or “flak”. |
| [l] | The preferred pronunciation of Lojban l. As in English “low” , “nylon” , or “excel”. |
| [l̩] | The syllabic version of Lojban l , as in English “bottle” or “middle”. |
| [m] | The preferred pronunciation of Lojban m. As in English “me” , “humor” , or “ham”. |
| [m̩] | The syllabic version of Lojban m. As in English “catch 'em” or “bottom”. |
| [n] | The preferred pronunciation of Lojban n. As in English no , “honor” , or “son”. |
| [n̩] | The syllabic version of Lojban n. As in English “button”. |
| [ŋ] | An allowed variant of Lojban n , especially in Lojbanized names and before g or k. As in English “sing” or “singer” (but not “finger” or “danger”). |
| [ŋ̍] | An allowed variant of Lojban syllabic n , especially in Lojbanized names. |
| [o] | The preferred pronunciation of Lojban o. As in the French « haute (cuisine) » or Spanish “como”. There is no exact English equivalent of this sound. The nearest GA equivalent is the “o” of “dough” or “joke” , but it is essential that the off-glide (a [w] -like sound) at the end of the vowel is not pronounced when speaking Lojban. The RP sound in these words is [əw] in IPA terms, and has no [o] in it at all; unless you can speak with a Scots, Irish, or American accent, you may have trouble with this sound. |
| [ɔ] | An allowed variant of Lojban o , especially before r. This sound is a shortened form of the “aw” in GA “dawn” (for those people who don't pronounce “dawn” and “Don” alike; if you do, you may have trouble with this sound). In RP, but not GA, it is the “o” of “hot”. |
| [p] | The preferred pronunciation of Lojban p. As in English “pay” , “super” , or “up”. |
| [r] | One version of Lojban r. Not an English sound. The Spanish “rr” and the Scots “r” , a tongue-tip trill. |
| [ɹ] | One version of Lojban r. As in GA “right” , “baron” , or “car”. Not found in RP. |
| [ɾ] | One version of Lojban r. In GA, appears as a variant of “t” or “d” in the words “metal” and “medal” respectively. A tongue-tip flap. |
| [ʀ] | One version of Lojban r. Not an English sound. The French or German « r » in « reine » or „rot“ respectively. A uvular trill. |
| [r̩] , [ɹ̩] , [ʀ̩] | Syllabic versions of the above. [ɹ̩] appears in the GA (but not RP) pronunciation of “bird”. |
| [s] | The preferred pronunciation of Lojban s. As in English “so” , “basin” , or “yes”. |
| [ʃ] | The preferred pronunciation of Lojban c. The “sh” of English “ship” , “ashen” , or “dish”. |
| [ʂ] | An allowed variant of Lojban c. Not an English sound. The Hindi retroflex “s” with dot below, or Klingon “S”. |
| [t] | The preferred pronunciation of Lojban t. As in English “tea” , “later” , or “not”. It is important to avoid the GA habit of pronouncing the “t” between vowels as [d] or [ɾ]. |
| [θ] | Not normally a Lojban sound, but a possible variant of Lojban '. The “th” of English “thin” (but not “then”). |
| [u] | The preferred pronunciation of Lojban u. As in the French « boule » or German „Stuhl“. There is no exact English equivalent of this sound. The nearest sound appears in “boot” or “cool”, but many dialects pronounce these with an off-glide, which should not be present when speaking Lojban. |
| [v] | The preferred pronunciation of Lojban v. As in English “voice” , “savor” , or “live”. |
| [w] | Used in Lojban diphthongs beginning or ending with u. Like the “w” in English “wet” [wɛt] or “cow” [kɑw]. |
| [x] | The preferred pronunciation of Lojban x. Not normally an English sound, but used in some pronunciations of “loch” and “Bach” ; “gh” in Scots “might” and “night”. The German „Ach-Laut“. To pronounce [x] , force air through your throat without vibrating your vocal chords; there should be lots of scrape. |
| [ʏ] | A possible Lojban buffer vowel. Not an English sound: the „ü“ of German „hübsch“. |
| [z] | The preferred pronunciation of Lojban z. As in English “zoo” , “hazard” , or “fizz”. |
| [ʒ] | The preferred pronunciation of Lojban j. The “si” of English “vision” , or the consonant at the end of GA “garage”. |
| [ʐ] | An allowed variant of Lojban j. Not an English sound. The voiced version of [ʂ]. |
The following guide will help American English speakers approximate Lojban sounds using familiar reference points from their dialect. When speaking Lojban, aim to pronounce each sound clearly and distinctly. Avoid the tendency in American English to reduce unstressed vowels to schwa or to add glides to pure vowels. Practice each sound individually and in combination to improve your Lojban pronunciation.
| [a] | The Lojban a. Similar to the “a” in “father”, but pronounced slightly forward in the mouth. Think of the “a” in “spa” without rounding your lips. |
| [b] | The Lojban b. Identical to the “b” in “boy” or “about”. |
| [d] | The Lojban d. As in “dog” or “add”. Be careful not to soften this to a flap [ɾ] between vowels, as in American “ladder”. |
| [e] | The Lojban e. Similar to the “ay” in “say”, but without the glide at the end. Hold your tongue still while saying the first part of the English vowel. |
| [f] | The Lojban f. As in “four” or “if”. |
| [g] | The Lojban g. As in “go” or “big”. |
| [h] | The Lojban apostrophe. As in “ahead” or the second “h” in “oh hi”. |
| [i] | The Lojban i. Like the “ee” in “see”, but without any glide at the end. |
| [j] | Used in Lojban diphthongs with i. Like the “y” in “yes” or the “i” in “radio”. |
| [k] | The Lojban k. As in “ski” or “take”. |
| [l] | The Lojban l. As in “love” or “fall”. |
| [m] | The Lojban m. As in “more” or “him”. |
| [n] | The Lojban n. As in “no” or “on”. |
| [o] | The Lojban o. Similar to the “o” in “go”, but without the glide at the end. Hold your tongue still while saying the first part of the English vowel. |
| [p] | The Lojban p. As in “spin” or “top”. |
| [r] | The Lojban r. Similar to the American “r” in “red” or “car”, but can also be trilled as in Spanish. |
| [s] | The Lojban s. As in “sit” or “bus”. |
| [ʃ] | The Lojban c. The “sh” sound in “ship” or “cash”. |
| [t] | The Lojban t. As in “stop” or “it”. Avoid softening to a flap [ɾ] between vowels, as in American “water”. |
| [u] | The Lojban u. Similar to the “oo” in “boot”, but without any glide at the end. Hold your tongue still while saying the vowel. |
| [v] | The Lojban v. As in “vote” or “have”. |
| [w] | Used in Lojban diphthongs with u. As in “wet” or “cow”. |
| [x] | The Lojban x. Similar to the “ch” in the German “Bach” or Scottish “loch”. Pronounce like a strong “h” with friction in your throat. |
| [y] | The Lojban y. Like the “a” in “sofa” or the “u” in “supply”. This is the schwa sound. |
| [z] | The Lojban z. As in “zip” or “easy”. |
| [ʒ] | The Lojban j. The “s” in “treasure” or “j” in “Jacques”. |
The following table is tailored for speakers of British English, particularly those familiar with Received Pronunciation (RP). While Lojban has a standardised pronunciation, some sounds may be challenging for RP speakers. This guide aims to clarify these differences and provide familiar reference points.
| [a] | The preferred pronunciation of Lojban a. Similar to the “a” in RP “bath” or “palm”, but shorter and more forward in the mouth. Avoid the tendency to use the “æ” sound as in “cat”. |
| [ɛ] | The preferred pronunciation of Lojban e. As in the “e” of RP “bet” or “set”. |
| [i] | The preferred pronunciation of Lojban i. Similar to the “ee” in RP “see” or “meat”, but without the slight glide often present in English. |
| [o] | The preferred pronunciation of Lojban o. This sound doesn“t quite exist in RP. It”s similar to the first part of the “o” in “go”, but without the glide to [ʊ]. Think of the “o” in Scottish English “go” or try to hold the first part of the RP “o” sound without moving your tongue. |
| [u] | The preferred pronunciation of Lojban u. Similar to the “oo” in RP “boot” or “food”, but without the slight glide often present in English. It's closer to the “u” in Scottish English “good”. |
| [ə] | The preferred pronunciation of Lojban y. As in the “a” of RP “about” or the “er” of “river” when not rhotic. This is the neutral schwa sound. |
| [x] | The preferred pronunciation of Lojban x. This sound is not common in RP but occurs in Scottish “loch” or German “Bach”. Produce it by forcing air through your throat without vibrating your vocal cords. |
| [r] | One version of Lojban r. This is a trilled “r”, not typically used in RP. It's similar to the Scottish rolled “r”. RP speakers may find it easier to use [ɹ], which is also acceptable in Lojban. |
| [ʃ] | The preferred pronunciation of Lojban c. As in the “sh” of RP “ship” or “wash”. |
| [ʒ] | The preferred pronunciation of Lojban j. As in the “s” in RP “vision” or “measure”. |
Note that Lojban consonants not listed here are pronounced similarly to their RP counterparts. RP speakers should be particularly mindful of the following:
-
Lojban r can be pronounced as in RP, but a trilled [r] is also acceptable and sometimes preferred.
-
The letter x represents a sound not native to RP. Practice may be required to produce this sound consistently.
-
Vowels in Lojban are pure, without the glides often found in RP. Concentrate on producing steady vowel sounds without movement.
-
Lojban does not use the RP vowels [ɪ] (as in “bit”), [ʊ] (as in “put”), or [ʌ] (as in “but”). Be careful not to substitute these for Lojban vowels.
Here is a list of English words that contain diphthongs that are similar to the Lojban diphthongs. This list does not constitute an official pronunciation guide; it is intended as a help to English-speakers.
| Lojban | English |
| ai | “pie” |
| ei | “pay” |
| oi | “boy” |
| au | “cow” |
| ia | “yard” |
| ie | “yes” |
| ii | “ye” |
| io | “yodel” (in GA only) |
| iu | “unicorn” or “few” |
| ua | “suave” |
| ue | “wet” |
| ui | “we” |
| uo | “woe” (in GA only) |
| uu | “woo” |
| iy | “million” (the “io” part, that is) |
| uy | “was” (when unstressed) |
The following notes describe ways in which Lojban has been written or could be written that differ from the standard orthography explained in the rest of this chapter. Nobody needs to read this section except people with an interest in the obscure. Technicalities are used without explanation or further apology.
There exists an alternative orthography for Lojban, which is designed to be as compatible as possible (but no more so) with the orthography used in pre-Lojban versions of Loglan. The consonants undergo no change, except that x is replaced by h. The individual vowels likewise remain unchanged. However, the vowel pairs and diphthongs are changed as follows:
-
ai , ei , oi , au become ai , ei , oi , ao.
-
ia through iu and ua through uu remain unchanged.
-
a'i , e'i , o'i and a'o become a,i , e,i , o,i and a,o.
-
i'a through i'u and u'a through u'u are changed to ia through iu and ua through uu in lujvo and cmavo other than attitudinals, but become i,a through i,u and u,a through u,u in cmevla, fu'ivla, and attitudinal cmavo.
-
All other vowel pairs simply drop the apostrophe.
The result of these rules is to eliminate the apostrophe altogether, replacing it with comma where necessary, and otherwise with nothing. In addition, names and the cmavo .i are capitalized, and irregular stress is marked with an apostrophe (now no longer used for a sound) following the stressed syllable.
Three points must be emphasized about this alternative orthography:
-
It does not represent any changes to the standard Lojban phonology; it is simply a representation of the same phonology using a different written form.
-
It was designed to aid in a planned rapprochement between the Logical Language Group and The Loglan Institute, a group headed by James Cooke Brown. The rapprochement never took place.
There also exists a Cyrillic orthography for Lojban which was designed when the introductory Lojban brochure was translated into Russian.
|
|
|
|
||||||||
|
|
|
|
||||||||
|
|
|
|
||||||||
|
|
|
|
||||||||
|
|
|
|
||||||||
|
|
|
The Lojban letter “y” is mapped onto the hard sign “ъ” , as in Bulgarian. The apostrophe, comma, and period are unchanged. Diphthongs are written as vowel pairs, as in the Roman representation. Capital Lojban letters are written using corresponding capital Cyrillic letters.
An orthography using the Tengwar of Féanor, a fictional orthography invented by J. R. R. Tolkien and described in the Appendixes to The Lord Of The Rings , has been devised for Lojban. The following mapping, which closely resembles that used for Westron, will be meaningful only to those who have read those appendixes. In brief, the tincotéma and parmatéma are used in the conventional ways; the calmatéma represents palatal consonants, and the quessetéma represents velar consonants.
|
|
|
|
||||||||
|
|
|
|
||||||||
|
|
|
|
||||||||
|
|
|
|
||||||||
|
|
|
|
||||||||
|
|
|
|
The letters “vala” and “anna” are used for u and i only when those letters are used to represent glides. Of the additional letters, r , l , s , and z are written with “rómen” , “lambe” , “silme” , and “áre” / “esse” respectively; the inverted forms are used as free variants.
Finally, the zbalermorna orthography exists, which is completely unofficial.
In this orthography each symbol is made of a base “radical element”, which represents a consonant, which is then modified, if necessary, by another smaller symbol called a “diacritic element”, which represents a vowel.
If the consonant is not followed by a vowel then no diacritic element is used.
The set of radical elements in zbalermorna:
|
|
|
|
||||||||
|
|
|
|
||||||||
|
|
|
|
||||||||
|
|
|
|
||||||||
|
|||||||||||
|
|
|
|||||||||
|
|
||||||||||
The set of diacritic elements:
|
|
|
|
|
||||||||||
|
|
|
|
|
Diacritic elements are written above radical elements, e.g. “” (“drani”), “” (“roda”), “” (“rode”), “” (“rodi”).
Words in zbalermorna are separated with spaces.
The radical element for the Lojban letter “i” (“”) is only used in front of vowels; it is not interchangeable with “ ”. Similarly, the element for “u” (“”) is only used in front of vowels and is not interchangeable with “ ”).
When a fu'ivla or a cmavo starts with “i” or “u” and a vowel follows it then in zbalermorna the radical for the initial period is not used.
An example would be “ ” (“do .io .ui” with no initial periods).
The symbol for the period after the word can also be optionally omitted for the word of any class in cases when this word is the last word of the text and in cases when the current and the next word are separated with space. Periods in front of and after cmevla are not required, and are discouraged from being used when they are at text borders or separated by space from other words.
In zbalermorna there is an alternate form of the apostrophe called the “combining .y'y.bu” or “attitudinal shorthand”; it exists to make it more natural to write a period and an apostrophe in two consecutive syllables (a sequence, which represents the majority of the set of attitudinals). The “combining .y'y.bu” spans over both syllables and replaces the radical elements in them.
Examples would be “” (“.i'i”), “” (“.a'e”), “” (“.y'y.bu”).
There is an additional set of elements for vowels, called “full vowel elements”:
|
|
|
|
|
||||||||||
|
|
|
|
|
These full vowels elements are to be used in cmevla and fu'ivla instead of diacritic elements. Symbols “” (for i before vowels) and “” (for u before vowels) are used as previously explained. Examples of cmevla would be “” (“.katrinas.” with no periods), “” (“.djein.” with no periods).
There are two reasons for using full vowel elements.
Firstly, to give a distinct visual style and flavour to cmevla and fu'ivla.
Secondly, to implement some functionality of the comma. In standard orthography the comma can be used to separate consecutive vowels into different syllables. In the zbalermorna orthography, full vowel elements can be used to represent a comma and a following vowel. An example would be “” (“.uein.”) as opposed to “” (“.ue,in.”).
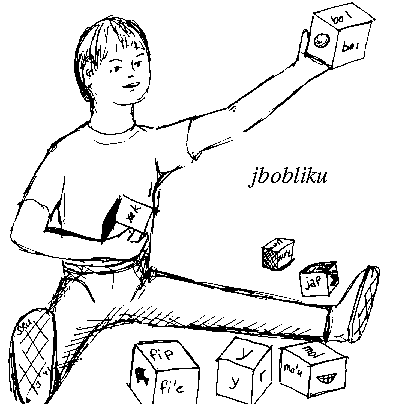
Morphology is the part of grammar that deals with the form of words. Lojban's morphology is fairly simple compared to that of many languages, because Lojban words don't change form depending on how they are used. English has only a small number of such changes compared to languages like Russian, but it does have changes like “boys” as the plural of “boy” , or “walked” as the past-tense form of “walk”. To make plurals or past tenses in Lojban, you add separate words to the sentence that express the number of boys, or the time when the walking was going on.
However, Lojban does have what is called “derivational morphology” : the capability of building new words from old words. In addition, the form of words tells us something about their grammatical uses, and sometimes about the means by which they entered the language. Lojban has very orderly rules for the formation of words of various types, both the words that already exist and new words yet to be created by speakers and writers.
A stream of Lojban sounds can be uniquely broken up into its component words according to specific rules. These so-called “morphology rules” are summarized in this chapter. (However, a detailed algorithm for breaking sounds into words has not yet been fully debugged, and so is not presented in this book.) First, here are some conventions used to talk about groups of Lojban letters, including vowels and consonants.
-
V represents any single Lojban vowel except y ; that is, it represents a , e , i , o , or u.
-
VV represents either a diphthong, one of the following:
ai ei oi au or a two-syllable vowel pair with an apostrophe separating the vowels, one of the following:
a'a a'e a'i a'o a'u e'a e'e e'i e'o e'u i'a i'e i'i i'o i'u o'a o'e o'i o'o o'u u'a u'e u'i u'o u'u -
C represents a single Lojban consonant, not including the apostrophe, one of b , c , d , f , g , j , k , l , m , n , p , r , s , t , v , x , or z . Syllabic l , m , n , and r always count as consonants for the purposes of this chapter.
-
CC represents two adjacent consonants of type C which constitute one of the 48 permissible initial consonant pairs:
pl pr fl fr bl br vl vr cp cf ct ck cm cn cl cr jb jv jd jg jm sp sf st sk sm sn sl sr zb zv zd zg zm tc tr ts kl kr dj dr dz gl gr ml mr xl xr -
C/C represents two adjacent consonants which constitute one of the permissible consonant pairs (not necessarily a permissible initial consonant pair). The permissible consonant pairs are explained in Section 3.6. In brief, any consonant pair is permissible unless it: contains two identical letters, contains both a voiced (excluding r , l , m , n) and an unvoiced consonant, or is one of certain specified forbidden pairs.
-
C/CC represents a consonant triple. The first two consonants must constitute a permissible consonant pair; the last two consonants must constitute a permissible initial consonant pair.
Lojban has three basic word classes – parts of speech – in contrast to the eight that are traditional in English. These three classes are called cmavo, brivla, and cmevla. Each of these classes has uniquely identifying properties – an arrangement of letters that allows the word to be uniquely and unambiguously recognized as a separate word in a string of Lojban, upon either reading or hearing, and as belonging to a specific word-class.
They are also functionally different: cmavo are the structure words, corresponding to English words like “and” , “if” , “the” and “to” ; brivla are the content words, corresponding to English words like “come” , “red” , “doctor” , and “freely” ; cmevla are proper names, corresponding to English “James” , “Afghanistan” , and “Pope John Paul II”.
The first group of Lojban words discussed in this chapter are the cmavo. They are the structure words that hold the Lojban language together. They often have no semantic meaning in themselves, though they may affect the semantics of brivla to which they are attached. The cmavo include the equivalent of English articles, conjunctions, prepositions, numbers, and punctuation marks. There are over a hundred subcategories of cmavo, known as selma'o , each having a specifically defined grammatical usage. The various selma'o are discussed throughout Chapter 5 to Chapter 19 and summarized in Chapter 20.
Standard cmavo occur in four forms defined by their word structure. Here are some examples of the various forms:
| V-form | .a | .e | .i | .o | .u |
| CV-form | ba | ce | di | fo | gu |
| VV-form | .au | .ei | .ia | .o'u | .u'e |
| CVV-form | ki'a | pei | mi'o | coi | cu'u |
In addition, there is the cmavo .y. (remember that y is not a V), which must have pauses before and after it.
A simple cmavo thus has the property of having only one or two vowels, or of having a single consonant followed by one or two vowels. Words consisting of three or more vowels in a row, or a single consonant followed by three or more vowels, are also of cmavo form, but are reserved for experimental use: a few examples are ku'a'e , sau'e , and bai'ai. All CVV cmavo beginning with the letter x are also reserved for experimental use. In general, though, the form of a cmavo tells you little or nothing about its grammatical use.
“Experimental use” means that the language designers will not assign any standard meaning or usage to these words, and words and usages coined by Lojban speakers will not appear in official dictionaries for the indefinite future. Experimental-use words provide an escape hatch for adding grammatical mechanisms (as opposed to semantic concepts) the need for which was not foreseen.
The cmavo of VV-form include not only the diphthongs and vowel pairs listed in Section 4.1 , but also the following ten additional diphthongs:
| .ia | .ie | .ii | .io | .iu |
| .ua | .ue | .ui | .uo | .uu |
In addition, cmavo can have the form Cy , a consonant followed by the letter y. These cmavo represent letters of the Lojban alphabet, and are discussed in detail in Chapter 17.
Compound cmavo are sequences of cmavo attached together to form a single written word. A compound cmavo is always identical in meaning and in grammatical use to the separated sequence of simple cmavo from which it is composed. These words are written in compound form merely to save visual space, and to ease the reader's burden in identifying when the component cmavo are acting together.
Compound cmavo, while not visually short like their components, can be readily identified by two characteristics:
-
They have no consonant pairs or clusters, and
-
They end in a vowel.
For example:
The cmavo .u'e begins with a vowel, and like all words beginning with a vowel, requires a pause (represented by .) before it. This pause cannot be omitted simply because the cmavo is incorporated into a compound cmavo. On the other hand,
is a single cmavo reserved for experimental purposes: it has four vowels.
Again the pauses are required (see Section 4.9); the pause after cy. merges with the pause before .ibu.
There is no particular stress required in cmavo or their compounds. Some conventions do exist that are not mandatory. For two-syllable cmavo, for example, stress is typically placed on the first vowel; an example is
This convention results in a consistent rhythm to the language, since brivla are required to have penultimate stress; some find this esthetically pleasing.
If the final syllable of one word is stressed, and the first syllable of the next word is stressed, you must insert a pause or glottal stop between the two stressed syllables. Thus
can be optionally pronounced
since there are no rules forcing stress on either of the first two words; the stress on re , though, demands that a pause separate re from the following syllable nan to ensure that the stress on nan is properly heard as a stressed syllable. The alternative pronunciation
is also valid; this would apply secondary stress (used for purposes of emphasis, contrast or sentence rhythm) to le , comparable in rhythmical effect to the English phrase “THE two men”. In Example 4.8 , the secondary stress on re would be similar to that in the English phrase “the TWO men”.
Both cmavo may also be left unstressed, thus:
This would probably be the most common usage.
Predicate words, called brivla , are at the core of Lojban. They carry most of the semantic information in the language. They serve as the equivalent of English nouns, verbs, adjectives, and adverbs, all in a single part of speech.
Every brivla belongs to one of three major subtypes. These subtypes are defined by the form, or morphology, of the word – all words of a particular structure can be assigned by sight or sound to a particular type (cmavo, brivla, or cmevla) and subtype. Knowing the type and subtype then gives you, the reader or listener, significant clues to the meaning and the origin of the word, even if you have never heard the word before.
The same principle allows you, when speaking or writing, to invent new brivla for new concepts “on the fly” ; yet it offers people that you are trying to communicate with a good chance to figure out your meaning. In this way, Lojban has a flexible vocabulary which can be expanded indefinitely.
All brivla have the following properties:
-
always end in a vowel;
-
always contain a consonant pair in the first five letters, where y and apostrophe are not counted as letters for this purpose (see Section 4.6);
-
always are stressed on the next-to-the-last (penultimate) syllable; this implies that they have two or more syllables.
The presence of a consonant pair distinguishes brivla from cmavo and their compounds. The final vowel distinguishes brivla from cmevla, which always end in a consonant. Thus da'amei must be a compound cmavo because it lacks a consonant pair; .lojban. must be a cmevla because it lacks a final vowel.
Thus, bisycla has the consonant pair sc in the first five non- y letters even though the sc actually appears in the form of sy.. Similarly, the word ro'inre'o contains nr in the first five letters because the apostrophes are not counted for this purpose.
The gismu, or Lojban root words, are those brivla representing concepts most basic to the language. The gismu were chosen for various reasons: some represent concepts that are very familiar and basic; some represent concepts that are frequently used in other languages; some were added because they would be helpful in constructing more complex words; some because they represent fundamental Lojban concepts (like cmavo and gismu themselves).
The gismu do not represent any sort of systematic partitioning of semantic space. Some gismu may be superfluous, or appear for historical reasons: the gismu list was being collected for almost 35 years and was only weeded out once. Instead, the intention is that the gismu blanket semantic space: they make it possible to talk about the entire range of human concerns.
There are about 1350 gismu. In learning Lojban, you need only to learn most of these gismu and their combining forms (known as rafsi) as well as perhaps 200 major cmavo, and you will be able to communicate effectively in the language. This may sound like a lot, but it is a small number compared to the vocabulary needed for similar communications in other languages.
All gismu have very strong form restrictions. Using the conventions defined in Section 4.1 , all gismu are of the forms CVC/CV or CCVCV. They must meet the rules for all brivla given in Section 4.3 ; furthermore, they:
-
always have five letters;
-
always start with a consonant and end with a single vowel;
-
always contain exactly one consonant pair, which is a permissible initial pair (CC) if it's at the beginning of the gismu, but otherwise only has to be a permissible pair (C/C);
-
are always stressed on the first syllable (since that is penultimate).
The five letter length distinguishes gismu from lujvo and fu'ivla. In addition, no gismu contains '.
With the exception of five special brivla variables, broda , brode , brodi , brodo , and brodu , no two gismu differ only in the final vowel. Furthermore, the set of gismu was specifically designed to reduce the likelihood that two similar sounding gismu could be confused. For example, because gismu is in the set of gismu, kismu , xismu , gicmu , gizmu , and gisnu cannot be.
Almost all Lojban gismu are constructed from pieces of words drawn from other languages, specifically Chinese, English, Hindi, Spanish, Russian, and Arabic, the six most widely spoken natural languages. For a given concept, words in the six languages that represent that concept were written in Lojban phonetics. Then a gismu was selected to maximize the recognizability of the Lojban word for speakers of the six languages by weighting the inclusion of the sounds drawn from each language by the number of speakers of that language. See Section 4.14 for a full explanation of the algorithm.
Here are a few examples of gismu, with rough English equivalents (not definitions):
A small number of gismu were formed differently; see Section 4.15 for a list.
When specifying a concept that is not found among the gismu (or, more specifically, when the relevant gismu seems too general in meaning), a Lojbanist generally attempts to express the concept as a tanru. Lojban tanru are an elaboration of the concept of “metaphor” used in English. In Lojban, any brivla can be used to modify another brivla. The first of the pair modifies the second. This modification is usually restrictive – the modifying brivla reduces the broader sense of the modified brivla to form a more narrow, concrete, or specific concept. Modifying brivla may thus be seen as acting like English adverbs or adjectives. For example,
is the tanru which expresses the concept of “computer user”.
The simplest Lojban tanru are pairings of two concepts or ideas. Such tanru take two simpler ideas that can be represented by gismu and combine them into a single more complex idea. Two-part tanru may then be recombined in pairs with other tanru, or with individual gismu, to form more complex or more specific ideas, and so on.
The meaning of a tanru is usually at least partly ambiguous: skami pilno could refer to a computer that is a user, or to a user of computers. There are a variety of ways that the modifier component can be related to the modified component. It is also possible to use cmavo within tanru to provide variations (or to prevent ambiguities) of meaning.
Making tanru is essentially a poetic or creative act, not a science. While the syntax expressing the grouping relationships within tanru is unambiguous, tanru are still semantically ambiguous, since the rules defining the relationships between the gismu are flexible. The process of devising a new tanru is dealt with in detail in Chapter 5.
To express a simple tanru, simply say the component gismu together. Thus the binary metaphor “big boat” becomes the tanru
representing roughly the same concept as the English word “ship”.
The binary metaphor “father mother” can refer to a paternal grandmother ( “a father-ly type of mother”), while “mother father” can refer to a maternal grandfather ( “a mother-ly type of father”). In Lojban, these become the tanru
and
respectively.
The possibility of semantic ambiguity can easily be seen in the last case. To interpret Example 4.22 , the listener must determine what type of motherliness pertains to the father being referred to. In an appropriate context, mamta patfu could mean not “grandfather” but simply “father with some motherly attributes” , depending on the culture. If absolute clarity is required, there are ways to expand upon and explain the exact interrelationship between the components; but such detail is usually not needed.
When a concept expressed in a tanru proves useful, or is frequently expressed, it is desirable to choose one of the possible meanings of the tanru and assign it to a new brivla. For Example 4.19 , we would probably choose “user of computers” , and form the new word
Such a brivla, built from the rafsi which represent its component words, is called a lujvo. Another example, corresponding to the tanru of Example 4.20 , would be:
The lujvo representing a given tanru is built from units representing the component gismu. These units are called rafsi in Lojban. Each rafsi represents only one gismu. The rafsi are attached together in the order of the words in the tanru, occasionally inserting so-called “hyphen” letters to ensure that the pieces stick together as a single word and cannot accidentally be broken apart into cmavo, gismu, or other word forms. As a result, each lujvo can be readily and accurately recognized, allowing a listener to pick out the word from a string of spoken Lojban, and if necessary, unambiguously decompose the word to a unique source tanru, thus providing a strong clue to its meaning.
The lujvo that can be built from the tanru mamta patfu in Example 4.22 is
which refers specifically to the concept “maternal grandfather”. The two gismu that constitute the tanru are represented in mampa'u by the rafsi mam- and -pa'u , respectively; these two rafsi are then concatenated together to form mampa'u.
Like gismu, lujvo have only one meaning. When a lujvo is formally entered into a dictionary of the language, a specific definition will be assigned based on one particular interrelationship between the terms. (See Chapter 12 for how this has been done.) Unlike gismu, lujvo may have more than one form. This is because there is no difference in meaning between the various rafsi for a gismu when they are used to build a lujvo. A long rafsi may be used, especially in noisy environments, in place of a short rafsi; the result is considered the same lujvo, even though the word is spelled and pronounced differently. Thus the word brivla , built from the tanru bridi valsi , is the same lujvo as brivalsi , bridyvla , and bridyvalsi , each of which uses a different combination of rafsi.
When assembling rafsi together into lujvo, the rules for valid brivla must be followed: a consonant cluster must occur in the first five letters (excluding y and '), and the lujvo must end in a vowel.
A y (which is ignored in determining stress or consonant clusters) is inserted in the middle of the consonant cluster to glue the word together when the resulting cluster is either not permissible or the word is likely to break up. There are specific rules describing these conditions, detailed in Section 4.6.
An r (in some cases, an n) is inserted when a CVV-form rafsi attaches to the beginning of a lujvo in such a way that there is no consonant cluster. For example, in the lujvo
the rafsi soi- and -sai are joined, with the additional r making up the rs consonant pair needed to make the word a brivla. Without the r , the word would break up into soi sai , two cmavo. The pair of cmavo have no relation to their rafsi lookalikes; they will either be ungrammatical (as in this case), or will express a different meaning from what was intended.
Learning rafsi and the rules for assembling them into lujvo is clearly seen to be necessary for fully using the potential Lojban vocabulary.
Most important, it is possible to invent new lujvo while you speak or write in order to represent a new or unfamiliar concept, one for which you do not know any existing Lojban word. As long as you follow the rules for building these compounds, there is a good chance that you will be understood without explanation.
Every gismu has from two to five rafsi, each of a different form, but each such rafsi represents only one gismu. It is valid to use any of the rafsi forms in building lujvo – whichever the reader or listener will most easily understand, or whichever is most pleasing – subject to the rules of lujvo making. There is a scoring algorithm which is intended to determine which of the possible and legal lujvo forms will be the standard dictionary form (see Section 4.12).
Each gismu always has at least two rafsi forms; one is the gismu itself (used only at the end of a lujvo), and one is the gismu without its final vowel (used only at the beginning or middle of a lujvo). These forms are represented as CVC/CV or CCVCV (called “the 5-letter rafsi”), and CVC/C or CCVC (called “the 4-letter rafsi”) respectively. The dashes in these rafsi form representations show where other rafsi may be attached to form a valid lujvo. When lujvo are formed only from 4-letter and 5-letter rafsi, known collectively as “long rafsi” , they are called “unreduced lujvo”.
Some examples of unreduced lujvo forms are:
In addition to these two forms, each gismu may have up to three additional short rafsi, three letters long. All short rafsi have one of the forms CVC, CCV, or CVV. The total number of rafsi forms that are assigned to a gismu depends on how useful the gismu is, or is presumed to be, in making lujvo, when compared to other gismu that could be assigned the rafsi.
For example, zmadu ( “more than”) has the two short rafsi zma and mau (in addition to its unreduced rafsi zmad and zmadu), because a vast number of lujvo have been created based on zmadu , corresponding in general to English comparative adjectives ending in “-er” such as “whiter” (Lojban labmau). On the other hand, bakri ( “chalk”) has no short rafsi and few lujvo.
There are at most one CVC-form, one CCV-form, and one CVV-form rafsi per gismu. In fact, only a tiny handful of gismu have both a CCV-form and a CVV-form rafsi assigned, and still fewer have all three forms of short rafsi. However, gismu with both a CVC-form and another short rafsi are fairly common, partly because more possible CVC-form rafsi exist. Yet CVC-form rafsi, even though they are fairly easy to remember, cannot be used at the end of a lujvo (because lujvo must end in vowels), so justifying the assignment of an additional short rafsi to many gismu.
The intention was to use the available “rafsi space” - the set of all possible short rafsi forms – in the most efficient way possible; the goal is to make the most-used lujvo as short as possible (thus maximizing the use of short rafsi), while keeping the rafsi very recognizable to anyone who knows the source gismu. For this reason, the letters in a rafsi have always been chosen from among the five letters of the corresponding gismu. As a result, there are a limited set of short rafsi available for assignment to each gismu. At most seven possible short rafsi are available for consideration (of which at most three can be used, as explained above).
Here are the only short rafsi forms that can possibly exist for gismu of the form CVC/CV, like sakli. The digits in the second column represent the gismu letters used to form the rafsi.
| CVC | 123 | -sak- |
| CVC | 124 | -sal- |
| CVV | 12'5 | -sa'i- |
| CVV | 125 | -sai- |
| CCV | 345 | -kli- |
| CCV | 132 | -ska- |
(The only actual short rafsi for sakli is -sal-.)
For gismu of the form CCVCV, like blaci , the only short rafsi forms that can exist are:
| CVC | 134 | -bac- |
| CVC | 234 | -lac- |
| CVV | 13'5 | -ba'i- |
| CVV | 135 | -bai- |
| CVV | 23'5 | -la'i- |
| CVV | 235 | -lai- |
| CCV | 123 | -bla- |
(In fact, blaci has none of these short rafsi; they are all assigned to other gismu. Lojban speakers are not free to reassign any of the rafsi; the tables shown here are to help understand how the rafsi were chosen in the first place.)
There are a few restrictions: a CVV-form rafsi without an apostrophe cannot exist unless the vowels make up one of the four diphthongs ai , ei , oi , or au ; and a CCV-form rafsi is possible only if the two consonants form a permissible initial consonant pair (see Section 4.1). Thus mamta , which has the same form as salci , can only have mam , mat , and ma'a as possible rafsi: in fact, only mam is assigned to it.
Some cmavo also have associated rafsi, usually CVC-form. For example, the ten common numerical digits, which are all CV form cmavo, each have a CVC-form rafsi formed by adding a consonant to the cmavo. Most cmavo that have rafsi are ones used in composing tanru.
The term for a lujvo made up solely of short rafsi is “fully reduced lujvo”. Here are some examples of fully reduced lujvo:
In addition, the unreduced forms in Example 4.27 and Example 4.28 may be fully reduced to:
As noted above, CVC-form rafsi cannot appear as the final rafsi in a lujvo, because all lujvo must end with one or two vowels. As a brivla, a lujvo must also contain a consonant cluster within the first five letters – this ensures that they cannot be mistaken for compound cmavo. Of course, all lujvo have at least six letters since they have two or more rafsi, each at least three letters long; hence they cannot be confused with gismu.
When attaching two rafsi together, it may be necessary to insert a hyphen letter. In Lojban, the term “hyphen” always refers to a letter, either the vowel y or one of the consonants r and n. (The letter l can also be a hyphen, but is not used as one in lujvo.)
The y-hyphen is used after a CVC-form rafsi when joining it with the following rafsi could result in an impermissible consonant pair, or when the resulting lujvo could fall apart into two or more words (either cmavo or gismu).
Thus, the tanru pante tavla ( “protest talk”) cannot produce the lujvo patta'a , because tt is not a permissible consonant pair; the lujvo must be patyta'a. Similarly, the tanru mudri siclu ( “wooden whistle”) cannot form the lujvo mudsiclu ; instead, mudysiclu must be used. (Remember that y is not counted in determining whether the first five letters of a brivla contain a consonant cluster: this is why.)
The y-hyphen is also used to attach a 4-letter rafsi, formed by dropping the final vowel of a gismu, to the following rafsi. (This procedure was shown, but not explained, in Example 4.27 to Example 4.31.)
The lujvo forms zunlyjamfu , zunlyjma , zuljamfu , and zuljma are all legitimate and equivalent forms made from the tanru zunle jamfu ( “left foot”). Of these, zuljma is the preferred one since it is the shortest; it thus is likely to be the form listed in a Lojban dictionary.
The r-hyphen and its close relative, the n-hyphen, are used in lujvo only after CVV-form rafsi. A hyphen is always required in a two-part lujvo of the form CVV-CVV, since otherwise there would be no consonant cluster.
An r-hyphen or n-hyphen is also required after the CVV-form rafsi of any lujvo of the form CVV-CVC/CV or CVV-CCVCV since it would otherwise fall apart into a CVV-form cmavo and a gismu. In any lujvo with more than two parts, a CVV-form rafsi in the initial position must always be followed by a hyphen. If the hyphen were to be omitted, the supposed lujvo could be broken into smaller words without the hyphen: because the CVV-form rafsi would be interpreted as a cmavo, and the remainder of the word as a valid lujvo that is one rafsi shorter.
An n-hyphen is only used in place of an r-hyphen when the following rafsi begins with r. For example, the tanru rokci renro ( “rock throw”) cannot be expressed as ro'ire'o (which breaks up into two cmavo), nor can it be ro'irre'o (which has an impermissible double consonant); the n-hyphen is required, and the correct form of the hyphenated lujvo is ro'inre'o. The same lujvo could also be expressed without hyphenation as rokre'o.
There is also a different way of building lujvo, or rather phrases which are grammatically and semantically equivalent to lujvo. You can make a phrase containing any desired words, joining each pair of them with the special cmavo zei. Thus,
is the exact equivalent of brivla (but not necessarily the same as the underlying tanru bridi valsi , which could have other meanings). Using zei is the only way to get a cmavo lacking a rafsi, a cmevla, or a fu'ivla into a lujvo:
Example 4.41 is particularly noteworthy because the phrase that would be produced by removing the zei s from it doesn't end with a brivla, and in fact is not even grammatical. As written, the example is a tanru with two components, but by adding a zei between by. and livgyterbilma to produce
the whole phrase would become a single lujvo. The longer lujvo of Example 4.43 may be preferable, because its place structure can be built from that of bilma , whereas the place structure of a lujvo without a brivla must be constructed ad hoc.
Note that rafsi may not be used in zei phrases, because they are not words. CVV rafsi look like words (specifically cmavo) but there can be no confusion between the two uses of the same letters, because cmavo appear only as separate words or in compound cmavo (which are really just a notation for writing separate but closely related words as if they were one); rafsi appear only as parts of lujvo and fu'ivla.
The use of tanru or lujvo is not always appropriate for very concrete or specific terms (e.g. “brie” or “cobra”), or for jargon words specialized to a narrow field (e.g. “quark” , “integral” , or “iambic pentameter”). These words are in effect names for concepts, and the names were invented by speakers of another language. The vast majority of words referring to plants, animals, foods, and scientific terminology cannot be easily expressed as tanru. They thus must be borrowed (actually “copied”) into Lojban from the original language.
There are four stages of borrowing in Lojban, as words become more and more modified (but shorter and easier to use). Stage 1 is the use of a foreign name quoted with the cmavo la'o (explained in full in Section 19.10):
is a predicate with the place structure “x1 is a quantity of spaghetti”.
Stage 2 involves changing the foreign name to a Lojbanized name, as explained in Section 4.8:
One of these expedients is often quite sufficient when you need a word quickly in conversation. (This can make it easier to get by when you do not yet have full command of the Lojban vocabulary, provided you are talking to someone who will recognize the borrowing.)
Where a little more universality is desired, the word to be borrowed must be Lojbanized into one of several permitted forms. A rafsi is then usually attached to the beginning of the Lojbanized form, using a hyphen to ensure that the resulting word doesn't fall apart.
The rafsi categorizes or limits the meaning of the fu'ivla; otherwise a word having several different jargon meanings in other languages would require the word-inventor to choose which meaning should be assigned to the fu'ivla, since fu'ivla (like other brivla) are not permitted to have more than one definition. Such a Stage 3 borrowing is the most common kind of fu'ivla.
Finally, Stage 4 fu'ivla do not have any rafsi classifier, and are used where a fu'ivla has become so common or so important that it must be made as short as possible. (See Section 4.16 for a proposal concerning Stage 4 fu'ivla.)
The form of a fu'ivla reliably distinguishes it from both the gismu and the cmavo. Like cultural gismu, fu'ivla are generally based on a word from a single non-Lojban language. The word is “borrowed” (actually “copied” , hence the Lojban tanru fukpi valsi) from the other language and Lojbanized – the phonemes are converted to their closest Lojban equivalent and modifications are made as necessary to make the word a legitimate Lojban fu'ivla-form word. All fu'ivla:
-
must contain a consonant cluster in the first five letters of the word; if this consonant cluster is at the beginning, it must either be a permissible initial consonant pair, or a longer cluster such that each pair of adjacent consonants in the cluster is a permissible initial consonant pair: spraile is acceptable, but not ktraile or trkaile ;
-
must end in one or more vowels;
-
must not be gismu or lujvo, or any combination of cmavo, gismu, and lujvo; furthermore, a fu'ivla with a CV cmavo joined to the front of it must not have the form of a lujvo (the so-called “slinku'i test” , not discussed further in this book);
-
cannot contain y , although they may contain syllabic pronunciations of Lojban consonants;
-
like other brivla, are stressed on the penultimate syllable.
Note that consonant triples or larger clusters that are not at the beginning of a fu'ivla can be quite flexible, as long as all consonant pairs are permissible. There is no need to restrict fu'ivla clusters to permissible initial pairs except at the beginning.
This is a fairly liberal definition and allows quite a lot of possibilities within “fu'ivla space”. Stage 3 fu'ivla can be made easily on the fly, as lujvo can, because the procedure for forming them always guarantees a word that cannot violate any of the rules. Stage 4 fu'ivla require running tests that are not simple to characterize or perform, and should be made only after deliberation and by someone knowledgeable about all the considerations that apply.
Here is a simple and reliable procedure for making a non-Lojban word into a valid Stage 3 fu'ivla:
-
Eliminate all double consonants and silent letters.
-
Convert all sounds to their closest Lojban equivalents. Lojban y , however, may not be used in any fu'ivla.
-
If the last letter is not a vowel, modify the ending so that the word ends in a vowel, either by removing a final consonant or by adding a suggestively chosen final vowel.
-
If the first letter is not a consonant, modify the beginning so that the word begins with a consonant, either by removing an initial vowel or adding a suggestively chosen initial consonant.
-
Prefix the result of steps 1-4 with a 4-letter rafsi that categorizes the fu'ivla into a “topic area”. It is only safe to use a 4-letter rafsi; short rafsi sometimes produce invalid fu'ivla. Hyphenate the rafsi to the rest of the fu'ivla with an r-hyphen; if that would produce a double r , use an n-hyphen instead; if the rafsi ends in r and the rest of the fu'ivla begins with n (or vice versa), or if the rafsi ends in "r" and the rest of the fu'ivla begins with "tc", "ts", "dj", or "dz" (using "n" would result in a phonotactically impermissible cluster), use an l-hyphen. (This is the only use of l-hyphen in Lojban.)
Alternatively, if a CVC-form short rafsi is available it can be used instead of the long rafsi.
-
Remember that the stress necessarily appears on the penultimate (next-to-the-last) syllable.
In this section, the hyphen is set off with commas in the examples, but these commas are not required in writing, and the hyphen need not be pronounced as a separate syllable.
Here are a few examples:
|
spaghetti (from English or Italian) |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
spageti (Lojbanize) |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
cidj,r,spageti (prefix long rafsi) |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
dja,r,spageti (prefix short rafsi) |
where cidj- is the 4-letter rafsi for cidja , the Lojban gismu for “food” , thus categorizing cidjrspageti as a kind of food. The form with the short rafsi happens to work, but such good fortune cannot be relied on: in any event, it means the same thing.
|
Acer (the scientific name of maple trees) |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
acer (Lojbanize) |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
xaceru (add initial consonant and final vowel) |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
tric,r,xaceru (prefix rafsi) |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
ric,r,xaceru (prefix short rafsi) |
where tric- and ric- are rafsi for tricu , the gismu for “tree”. Note that by the same principles, “maple sugar” could get the fu'ivla saktrxaceru , or could be represented by the tanru tricrxaceru sakta. Technically, ricrxaceru and tricrxaceru are distinct fu'ivla, but they would surely be given the same meanings if both happened to be in use.
where cirl- represents cirla ( “cheese”).
where sinc- represents since ( “snake”).
where sask- represents saske ( “science”). Note the extra vowel a added to the end of the word, and the diphthong ua , which never appears in gismu or lujvo, but may appear in fu'ivla.
where ler- represents lerfu ( “letter”). Note the l-hyphen in "lerldjamo", since "lerndjamo" contains the forbidden cluster "ndj".
The use of the prefix helps distinguish among the many possible meanings of the borrowed word, depending on the field. As it happens, spageti and kuarka are valid Stage 4 fu'ivla, but xaceru looks like a compound cmavo, and kobra like a gismu.
For another example, “integral” has a specific meaning to a mathematician. But the Lojban fu'ivla .integrale , which is a valid Stage 4 fu'ivla, does not convey that mathematical sense to a non-mathematical listener, even one with an English-speaking background; its source – the English word “integral” – has various other specialized meanings in other fields.
Left uncontrolled, .integrale almost certainly would eventually come to mean the same collection of loosely related concepts that English associates with “integral” , with only the context to indicate (possibly) that the mathematical term is meant.
The prefix method would render the mathematical concept as cmacrntegrale , if the i of .integrale is removed, or something like cmacrnintegrale , if a new consonant is added to the beginning; cmac- is the rafsi for cmaci ( “mathematics”). The architectural sense of “integral” might be conveyed with dinjrnintegrale or tarmrnintegrale , where dinju and tarmi mean “building” and “form” respectively.
Here are some fu'ivla representing cultures and related things, shown with more than one rafsi prefix:
Note the commas in Example 4.55 and Example 4.56 , used because ea is not a valid diphthong in Lojban. Arguably, some form of the native name “Chosen” should have been used instead of the internationally known “Korea” ; this is a recurring problem in all borrowings. In general, it is better to use the native name unless using it will severely impede understanding: “Navajo” is far more widely known than “Dine'e”.
Lojbanized names, called cmevla , are very much like their counterparts in other languages. They are labels applied to things (or people) to stand for them in descriptions or in direct address. They may convey meaning in themselves, but do not necessarily do so.
Because names are often highly personal and individual, Lojban attempts to allow native language names to be used with a minimum of modification. The requirement that the Lojban speech stream be unambiguously analyzable, however, means that most names must be modified somewhat when they are Lojbanized. Here are a few examples of English names and possible Lojban equivalents:
(Note that syllabic r is skipped in determining the stressed syllable, so Example 4.62 is stressed on the ka.)
Cmevla may have almost any form, but always end in a consonant, are preceded by a pause, and are followed by a pause. They are penultimately stressed, unless unusual stress is marked with capitalization. A cmevla may have multiple parts, each ending with a consonant, starting and ending with a pause, or the parts may be combined into a single word with no pause in between. For example,
and
are both valid Lojbanizations of “John Brown”.
The final arbiter of the correct form of a name is the person doing the naming, although most cultures grant people the right to determine how they want their own name to be spelled and pronounced. The English name “Mary” can thus be Lojbanized as .meris. , .maris. , .meiris. , .merix. , or even .marys.. The last alternative is not pronounced much like its English equivalent, but may be desirable to someone who values spelling over pronunciation. The final consonant need not be an s ; there must, however, be some Lojban consonant at the end.
Lojban cmevla are identifiable as word forms by the following characteristics:
-
They must end in one or more consonants. There are no rules about how many consonants may appear in a cluster in cmevla, provided that each consonant pair (whether standing by itself, or as part of a larger cluster) is a permissible pair.
-
They may contain the letter y as a normal, non-hyphenating vowel. They are the only kind of Lojban word that may contain the two diphthongs iy and uy.
-
They are always surrounded in speech by pauses, one right before the first letter, and the other one right after the final consonant, both being written as “.”.
-
They may be stressed on any syllable; if this syllable is not the penultimate one, it must be capitalized when writing. Neither names nor words that begin sentences are capitalized in Lojban, so this is the only use of capital letters.
cmevla meeting these criteria may be invented, Lojbanized from names in other languages, or formed by appending a consonant onto a cmavo, a gismu, a fu'ivla or a lujvo. Some cmevla built from Lojban words are:
To Lojbanize a name from the various natural languages, apply the following rules:
-
Eliminate double consonants and silent letters.
-
Add a final s or n (or some other consonant that sounds good) if the name ends in a vowel.
-
Convert all sounds to their closest Lojban equivalents.
-
If possible and acceptable, shift the stress to the penultimate (next-to-the-last) syllable. Use commas and capitalization in written Lojban when it is necessary to preserve non-standard syllabication or stress. Do not capitalize names otherwise.
-
If the name contains an impermissible consonant pair, insert a vowel between the consonants: y is recommended.
There are some additional rules for Lojbanizing the scientific names (technically known as “Linnaean binomials” after their inventor) which are internationally applied to each species of animal or plant. Where precision is essential, these names need not be Lojbanized, but can be directly inserted into Lojban text using the cmavo la'o , explained in Section 19.10. Using this cmavo makes the already lengthy Latinized names at least four syllables longer, however, and leaves the pronunciation in doubt. The following suggestions, though incomplete, will assist in converting Linnaean binomals to valid Lojban names. They can also help to create fu'ivla based on Linnaean binomials or other words of the international scientific vocabulary. The term “back vowel” in the following list refers to any of the letters a , o , or u ; the term “front vowel” correspondingly refers to any of the letters e , i , or y.
-
Change double consonants other than cc to single consonants.
-
Change cc before a front vowel to kc , but otherwise to k.
-
Change c before a back vowel and final c to k.
-
Change ng before a consonant (other than h) and final ng to n.
-
Change x to z initially, but otherwise to ks.
-
Change pn to n initially.
-
Change final ie and ii to i.
-
Make the following idiosyncratic substitutions:
aa a ae e ch k ee i eigh ei ew u igh ai oo u ou u ow au ph f q k sc sk w u y i However, the diphthong substitutions should not be done if the two vowels are in two different syllables.
-
Change “h” between two vowels to ' , but otherwise remove it completely. If preservation of the “h” seems essential, change it to x instead.
-
Place ' between any remaining vowel pairs that do not form Lojban diphthongs.
Some further examples of Lojbanized names are:
| English | “Mary” | .meris. or .meiris. |
| English | “Smith” | .smit. |
| English | “Jones” | .djonz. |
| English | “John” | .djan. or .jan. (American) or .djon. or .jon. (British) |
| English | “Alice” | .alis. |
| English | “Elise” | .eLIS. |
| English | “Johnson” | .djansn. |
| English | “William” | .uiliam. or .uil,iam. |
| English | “Brown” | .braun. |
| English | “Charles” | .tcarlz. |
| French | “Charles” | .carl. |
| French | “De Gaulle” | .dyGOL. |
| German | “Heinrich” | .xainrix. |
| Spanish | “Joaquin” | .xuaKIN. |
| Russian | “Svetlana” | .sfietlanys. |
| Russian | “Khrushchev” | .xrucTCOF. |
| Hindi | “Krishna” | .kricnas. |
| Polish | “Lech Walesa” | .lex. .va,uensas. |
| Spanish | “Don Quixote” | .don. .kicotes. or modern Spanish: .don. .kixotes. or Mexican dialect: .don. .ki'otes. |
| Chinese | “Mao Zedong” | .maudzydyn. |
| Japanese | “Fujiko” | .fudjikos. or .fujikos. |
Summarized in one place, here are the rules for inserting pauses between Lojban words:
-
Any two words may have a pause between them; it is always illegal to pause in the middle of a word, because that breaks up the word into two words.
-
Every word ending in a consonant must be surrounded by pauses. Necessarily, all such words are cmevla.
-
Every word beginning with a vowel must be preceded by a pause. Such words are either cmavo, fu'ivla, or cmevla; all gismu and lujvo begin with consonants.
-
If the last syllable of a word bears the stress, and a brivla follows, the two must be separated by a pause, to prevent confusion with the primary stress of the brivla. In this case, the first word must be either a cmavo or a cmevla with unusual stress (which already ends with a pause, of course).
-
A cmavo of the form “Cy” must be followed by a pause unless another “Cy” -form cmavo follows.
-
When non-Lojban text is embedded in Lojban, it must be preceded and followed by pauses. (How to embed non-Lojban text is explained in Section 19.10.)
Given a tanru which expresses an idea to be used frequently, it can be turned into a lujvo by following the lujvo-making algorithm which is given in Section 4.11.
In building a lujvo, the first step is to replace each gismu with a rafsi that uniquely represents that gismu. These rafsi are then attached together by fixed rules that allow the resulting compound to be recognized as a single word and to be analyzed in only one way.
There are three other complications; only one is serious.
The first is that there is usually more than one rafsi that can be used for each gismu. The one to be used is simply whichever one sounds or looks best to the speaker or writer. There are usually many valid combinations of possible rafsi. They all are equally valid, and all of them mean exactly the same thing. (The scoring algorithm given in Section 4.12 is used to choose the standard form of the lujvo – the version which would be entered into a dictionary.)
The second complication is the serious one. Remember that a tanru is ambiguous – it has several possible meanings. A lujvo, or at least one that would be put into the dictionary, has just a single meaning. Like a gismu, a lujvo is a predicate which encompasses one area of the semantic universe, with one set of places. Hopefully the meaning chosen is the most useful of the possible semantic spaces. A possible source of linguistic drift in Lojban is that as Lojbanic society evolves, the concept that seems the most useful one may change.
You must also be aware of the possibility of some prior meaning of a new lujvo, especially if you are writing for posterity. If a lujvo is invented which involves the same tanru as one that is in the dictionary, and is assigned a different meaning (or even just a different place structure), linguistic drift results. This isn't necessarily bad. Every natural language does it. But in communication, when you use a meaning different from the dictionary definition, someone else may use the dictionary and therefore misunderstand you. You can use the cmavo za'e (explained in Section 19.11) before a newly coined lujvo to indicate that it may have a non-dictionary meaning.
The essential nature of human communication is that if the listener understands, then all is well. Let this be the ultimate guideline for choosing meanings and place structures for invented lujvo.
The third complication is also simple, but tends to scare new Lojbanists with its implications. It is based on Zipf's Law, which says that the length of words is inversely proportional to their usage. The shortest words are those which are used more; the longest ones are used less. Conversely, commonly used concepts will be tend to be abbreviated. In English, we have abbreviations and acronyms and jargon, all of which represent complex ideas that are used often by small groups of people, so they shortened them to convey more information more rapidly.
Therefore, given a complicated tanru with grouping markers, abstraction markers, and other cmavo in it to make it syntactically unambiguous, the psychological basis of Zipf's Law may compel the lujvo-maker to drop some of the cmavo to make a shorter (technically incorrect) tanru, and then use that tanru to make the lujvo.
This doesn't lead to ambiguity, as it might seem to. A given lujvo still has exactly one meaning and place structure. It is just that more than one tanru is competing for the same lujvo. But more than one meaning for the tanru was already competing for the “right” to define the meaning of the lujvo. Someone has to use judgment in deciding which one meaning is to be chosen over the others.
If the lujvo made by a shorter form of tanru is in use, or is likely to be useful for another meaning, the decider then retains one or more of the cmavo, preferably ones that set this meaning apart from the shorter form meaning that is used or anticipated. As a rule, therefore, the shorter lujvo will be used for a more general concept, possibly even instead of a more frequent word. If both words are needed, the simpler one should be shorter. It is easier to add a cmavo to clarify the meaning of the more complex term than it is to find a good alternate tanru for the simpler term.
And of course, we have to consider the listener. On hearing an unknown word, the listener will decompose it and get a tanru that makes no sense or the wrong sense for the context. If the listener realizes that the grouping operators may have been dropped out, he or she may try alternate groupings, or try inserting an abstraction operator if that seems plausible. (The grouping of tanru is explained in Chapter 5 ; abstraction is explained in Chapter 11.) Plausibility is the key to learning new ideas and to evaluating unfamiliar lujvo.
The following is the current algorithm for generating Lojban lujvo given a known tanru and a complete list of gismu and their assigned rafsi. The algorithm was designed by Bob LeChevalier and Dr. James Cooke Brown for computer program implementation. It was modified in 1989 with the assistance of Nora LeChevalier, who detected a flaw in the original “tosmabru test”.
Given a tanru that is to be made into a lujvo:
-
Choose a 3-letter or 4-letter rafsi for each of the gismu and cmavo in the tanru except the last.
-
Choose a 3-letter (CVV-form or CCV-form) or 5-letter rafsi for the final gismu in the tanru.
-
Join the resulting string of rafsi, initially without hyphens.
-
Add hyphen letters where necessary. It is illegal to add a hyphen at a place that is not required by this algorithm. Right-to-left tests are recommended, for reasons discussed below.
-
If there are more than two words in the tanru, put an r-hyphen (or an n-hyphen) after the first rafsi if it is CVV-form. If there are exactly two words, then put an r-hyphen (or an n-hyphen) between the two rafsi if the first rafsi is CVV-form, unless the second rafsi is CCV-form (for example, saicli requires no hyphen). Use an r-hyphen unless the letter after the hyphen is r , in which case use an n-hyphen. Never use an n-hyphen unless it is required.
-
Put a y-hyphen between the consonants of any impermissible consonant pair. This will always appear between rafsi.
-
-
Test all forms with one or more initial CVC-form rafsi – with the pattern “CVC ... CVC + X” – for “tosmabru failure”. In order to fail, X must either be a CVCCV long rafsi that happens to have a permissible initial pair as the consonant cluster, or is something which has caused a y-hyphen to be inserted between the preceding CVC and X in step 4.b.
The test is as follows:
-
Examine all the C/C consonant pairs up to the first y-hyphen, or up to the end of the word in case there are no y-hyphens.
These consonant pairs are called "joints”.
-
If all of those joints are permissible initials, then the trial word will break up into a cmavo and a shorter brivla, so we need to add a “y”-hyphen at the first joint. If not, the word will not break up, and no further hyphens are needed.
-
Install a y-hyphen at the first such joint.
-
Note that the “tosmabru test”, which affects hyphenation after the first rafsi, cannot be performed until after hyphenation to the right under step 4 has already been determined.
This algorithm was devised by Bob and Nora LeChevalier in 1989. It is not the only possible algorithm, but it usually gives a choice that people find preferable. The algorithm may be changed in the future. The lowest-scoring variant will usually be the dictionary form of the lujvo. (In previous versions, it was the highest-scoring variant.)
-
Count the total number of letters, including hyphens and apostrophes; call it L.
-
Count the number of apostrophes; call it A.
-
Count the number of y- , r- , and n-hyphens; call it H.
-
For each rafsi, find the value in the following table. Sum this value over all rafsi; call it R :
CVC/CV (final) ( -sarji) 1 CVC/C ( -sarj-) 2 CCVCV (final) ( -zbasu) 3 CCVC ( -zbas-) 4 CVC ( -nun-) 5 CVV with an apostrophe ( -ta'u-) 6 CCV ( -zba-) 7 CVV with no apostrophe ( -sai-) 8 -
Count the number of vowels, not including y ; call it V.
In case of ties, there is no preference. This should be rare. Note that the algorithm essentially encodes a hierarchy of priorities: short words are preferred (counting apostrophes as half a letter), then words with fewer hyphens, words with more pleasing rafsi (this judgment is subjective), and finally words with more vowels are chosen. Each decision principle is applied in turn if the ones before it have failed to choose; it is possible that a lower-ranked principle might dominate a higher-ranked one if it is ten times better than the alternative.
Here are some lujvo with their scores (not necessarily the lowest scoring forms for these lujvo, nor even necessarily sensible lujvo):
This section contains examples of making and scoring lujvo. First, we will start with the tanru gerku zdani ( “dog house”) and construct a lujvo meaning “doghouse” , that is, a house where a dog lives. We will use a brute-force application of the algorithm in Section 4.12 , using every possible rafsi.
The rafsi for gerku are:
| -ger- , | -ge'u- , | -gerk- , | -gerku |
The rafsi for zdani are:
| -zda- , | -zdan- , | -zdani. |
Step 1 of the algorithm directs us to use -ger- , -ge'u- and -gerk- as possible rafsi for gerku ; Step 2 directs us to use -zda- and -zdani as possible rafsi for zdani. The six possible forms of the lujvo are then:
| ger -zda |
| ger -zdani |
| ge'u -zda |
| ge'u -zdani |
| gerk -zda |
| gerk -zdani |
We must then insert appropriate hyphens in each case. The first two forms need no hyphenation: ge cannot fall off the front, because the following word would begin with rz , which is not a permissible initial consonant pair. So the lujvo forms are gerzda and gerzdani.
The third form, ge'u -zda , needs no hyphen, because even though the first rafsi is CVV, the second one is CCV, so there is a consonant cluster in the first five letters. So ge'uzda is this form of the lujvo.
The fourth form, ge'u-zdani , however, requires an r-hyphen; otherwise, the ge'u- part would fall off as a cmavo. So this form of the lujvo is ge'urzdani.
The last two forms require y-hyphens, as all 4-letter rafsi do, and so are gerkyzda and gerkyzdani respectively.
The scoring algorithm is heavily weighted in favor of short lujvo, so we might expect that gerzda would win. Its L score is 6, its A score is 0, its H score is 0, its R score is 12, and its V score is 3, for a final score of 5878. The other forms have scores of 7917, 6367, 9506, 8008, and 10047 respectively. Consequently, this lujvo would probably appear in the dictionary in the form gerzda.
For the next example, we will use the tanru bloti klesi ( “boat class”) presumably referring to the category (rowboat, motorboat, cruise liner) into which a boat falls. We will omit the long rafsi from the process, since lujvo containing long rafsi are almost never preferred by the scoring algorithm when there are short rafsi available.
The rafsi for bloti are -lot- , -blo- , and -lo'i- ; for klesi they are -kle- and -lei-. Both these gismu are among the handful which have both CVV-form and CCV-form rafsi, so there is an unusual number of possibilities available for a two-part tanru:
| lotkle | blokle | lo'ikle |
| lotlei | blolei | lo'irlei |
Only lo'irlei requires hyphenation (to avoid confusion with the cmavo sequence lo'i lei). All six forms are valid versions of the lujvo, as are the six further forms using long rafsi; however, the scoring algorithm produces the following results:
| lotkle | 5878 |
| blokle | 5858 |
| lo'ikle | 6367 |
| lotlei | 5867 |
| blolei | 5847 |
| lo'irlei | 7456 |
So the form blolei is preferred, but only by a tiny margin over blokle ; "lotlei" and "lotkle" are only slightly worse; lo'ikle suffers because of its apostrophe, and lo'irlei because of having both apostrophe and hyphen.
Our third example will result in forming both a lujvo and a cmevla from the tanru logji bangu girzu , or “logical-language group” in English. ( “The Logical Language Group” is the name of the publisher of this book and the organization for the promotion of Lojban.)
The available rafsi are -loj- and -logj- ; -ban- , -bau- , and -bang- ; and -gri- and -girzu , and (for cmevla purposes only) -gir- and -girz-. The resulting 12 lujvo possibilities are:
| loj -ban -gri | loj -bau -gri | loj -bang -gri |
| logj -ban -gri | logj -bau -gri | logj -bang -gri |
| loj -ban -girzu | loj -bau -girzu | loj -bang -girzu |
| logj -ban -girzu | logj -bau -girzu | logj -bang -girzu |
and the 12 cmevla possibilities are:
| loj -ban -gir | loj -bau -gir | loj -bang -gir |
| logj -ban -gir | logj -bau -gir | logj -bang -gir |
| loj -ban -girz | loj -bau -girz | loj -bang -girz |
| logj -ban -girz | logj -bau -girz | logj -bang -girz |
After hyphenation, we have:
| lojbangri | lojbaugri | lojbangygri |
| logjybangri | logjybaugri | logjybangygri |
| lojbangirzu | lojbaugirzu | lojbangygirzu |
| logjybangirzu | logjybaugirzu | logjybangygirzu |
| lojbangir | lojbaugir | lojbangygir |
| logjybangir | logjybaugir | logjybangygir |
| lojbangirz | lojbaugirz | lojbangygirz |
| logjybangirz | logjybaugirz | logjybangygirz |
The only fully reduced lujvo forms are lojbangri and lojbaugri , of which the latter has a slightly lower score: 8827 versus 8796, respectively. However, for the name of the organization, we chose to make sure the name of the language was embedded in it, and to use the clearer long-form rafsi for girzu , producing .lojbangirz.
Finally, here is a four-part lujvo with a cmavo in it, based on the tanru nakni ke cinse ctuca or “male (sexual teacher)”. The ke cmavo ensures the interpretation “teacher of sexuality who is male” , rather than “teacher of male sexuality”. Here are the possible forms of the lujvo, both before and after hyphenation:
| nak -kem -cin -ctu | nakykemcinctu |
| nak -kem -cin -ctuca | nakykemcinctuca |
| nak -kem -cins -ctu | nakykemcinsyctu |
| nak -kem -cins -ctuca | nakykemcinsyctuca |
| nakn -kem -cin -ctu | naknykemcinctu |
| nakn -kem -cin -ctuca | naknykemcinctuca |
| nakn -kem -cins -ctu | naknykemcinsyctu |
| nakn -kem -cins -ctuca | naknykemcinsyctuca |
Of these forms, nakykemcinctu is the shortest and is preferred by the scoring algorithm. On the whole, however, it might be better to just make a lujvo for cinse ctuca (which would be cinctu) since the sex of the teacher is rarely important. If there was a reason to specify “male” , then the simpler tanru nakni cinctu ( “male sexual-teacher”) would be appropriate. This tanru is actually shorter than the four-part lujvo, since the ke required for grouping need not be expressed.
The gismu were created through the following process:
-
At least one word was found in each of the six source languages (Chinese, English, Hindi, Spanish, Russian, Arabic) corresponding to the proposed gismu. This word was rendered into Lojban phonetics rather liberally: consonant clusters consisting of a stop and the corresponding fricative were simplified to just the fricative ( tc became c , dj became j) and non-Lojban vowels were mapped onto Lojban ones. Furthermore, morphological endings were dropped. The same mapping rules were applied to all six languages for the sake of consistency.
-
All possible gismu forms were matched against the six source-language forms. The matches were scored as follows:
-
If three or more letters were the same in the proposed gismu and the source-language word, and appeared in the same order, the score was equal to the number of letters that were the same. Intervening letters, if any, did not matter.
-
If exactly two letters were the same in the proposed gismu and the source-language word, and either the two letters were consecutive in both words, or were separated by a single letter in both words, the score was 2. Letters in reversed order got no score.
-
-
The scores were divided by the length of the source-language word in its Lojbanized form, and then multiplied by a weighting value specific to each language, reflecting the proportional number of first-language and second-language speakers of the language. (Second-language speakers were reckoned at half their actual numbers.) The weights were chosen to sum to 1.00. The sum of the weighted scores was the total score for the proposed gismu form.
-
Any gismu forms that conflicted with existing gismu were removed. Obviously, being identical with an existing gismu constitutes a conflict. In addition, a proposed gismu that was identical to an existing gismu except for the final vowel was considered a conflict, since two such gismu would have identical 4-letter rafsi.
More subtly: If the proposed gismu was identical to an existing gismu except for a single consonant, and the consonant was "too similar” based on the following table, then the proposed gismu was rejected.
proposed gismu existing gismu b p , v c j , s d t f p , v g k , x j c , z k g , x l r m n n m p b , f r l s c , z t d v b , f x g , k z j , s See Section 4.4 for an example.
-
The gismu form with the highest score usually became the actual gismu. Sometimes a lower-scoring form was used to provide a better rafsi. A few gismu were changed in error as a result of transcription blunders (for example, the gismu gismu should have been gicmu , but it's too late to fix it now).
The language weights used to make most of the gismu were as follows:
Chinese 0.36 English 0.21 Hindi 0.16 Spanish 0.11 Russian 0.09 Arabic 0.07 reflecting 1985 number-of-speakers data. A few gismu were made much later using updated weights:
Chinese 0.347 Hindi 0.196 English 0.160 Spanish 0.123 Russian 0.089 Arabic 0.085 (English and Hindi switched places due to demographic changes.)
Note that the stressed vowel of the gismu was considered sufficiently distinctive that two or more gismu may differ only in this vowel; as an extreme example, bradi , bredi , bridi , and brodi (but fortunately not brudi) are all existing gismu.
The following gismu were not made by the gismu creation algorithm. They are, in effect, coined words similar to fu'ivla. They are exceptions to the otherwise mandatory gismu creation algorithm where there was sufficient justification for such exceptions. Except for the small metric prefixes and the assignable predicates beginning with brod- , they all end in the letter o , which is otherwise a rare letter in Lojban gismu.
The following gismu represent concepts that are sufficiently unique to Lojban that they were either coined from combining forms of other gismu, or else made up out of whole cloth. These gismu are thus conceptually similar to lujvo even though they are only five letters long; however, unlike lujvo, they have rafsi assigned to them for use in building more complex lujvo. Assigning gismu to these concepts helps to keep the resulting lujvo reasonably short.
| broda |
1st assignable predicate |
| brode |
2nd assignable predicate |
| brodi |
3rd assignable predicate |
| brodo |
4th assignable predicate |
| brodu |
5th assignable predicate |
| cmavo | |
| lojbo | |
| lujvo | |
| mekso |
Mathematical EXpression |
It is important to understand that even though cmavo , lojbo , and lujvo were made up from parts of other gismu, they are now full-fledged gismu used in exactly the same way as all other gismu, both in grammar and in word formation.
The following three groups of gismu represent concepts drawn from the international language of science and mathematics. They are used for concepts that are represented in most languages by a root which is recognized internationally.
Small metric prefixes (values less than 1):
| decti | .1 | deci |
| centi | .01 | centi |
| milti | .001 | milli |
| mikri | 10 -6 | micro |
| nanvi | 10 -9 | nano |
| picti | 10 -12 | pico |
| femti | 10 -15 | femto |
| xatsi | 10 -18 | atto |
| zepti | 10 -21 | zepto |
| gocti | 10 -24 | yocto |
Large metric prefixes (values greater than 1):
| dekto | 10 | deka |
| xecto | 100 | hecto |
| kilto | 1000 | kilo |
| megdo | 10 6 | mega |
| gigdo | 10 9 | giga |
| terto | 10 12 | tera |
| petso | 10 15 | peta |
| xexso | 10 18 | exa |
| zetro | 10 21 | zetta |
| gotro | 10 24 | yotta |
Other scientific or mathematical terms:
| delno |
candela |
| kelvo |
kelvin |
| molro |
mole |
| radno |
radian |
| sinso |
sine |
| stero |
steradian |
| tanjo |
tangent |
| xampo |
ampere |
The gismu sinso and tanjo were only made non-algorithmically because they were identical (having been borrowed from a common source) in all the dictionaries that had translations. The other terms in this group are units in the international metric system; some metric units, however, were made by the ordinary process (usually because they are different in Chinese).
Finally, there are the cultural gismu, which are also borrowed, but by modifying a word from one particular language, instead of using the multi-lingual gismu creation algorithm. Cultural gismu are used for words that have local importance to a particular culture; other cultures or languages may have no word for the concept at all, or may borrow the word from its home culture, just as Lojban does. In such a case, the gismu algorithm, which uses weighted averages, doesn't accurately represent the frequency of usage of the individual concept. Cultural gismu are not even required to be based on the six major languages.
The six Lojban source languages:
Seven other widely spoken languages that were on the list of candidates for gismu-making, but weren't used:
| bengo |
Bengali |
| porto |
Portuguese |
| baxso |
Bahasa Melayu/Bahasa Indonesia |
| ponjo |
Japanese (from “Nippon”) |
| dotco |
German (from „Deutsch“) |
| fraso |
French (from « Français ») |
| xurdo |
Urdu |
(Urdu and Hindi began as the same language with different writing systems, but have now become somewhat different, principally in borrowed vocabulary. Urdu-speakers were counted along with Hindi-speakers when weights were assigned for gismu-making purposes.)
Countries with a large number of speakers of any of the above languages (where the meaning of “large” is dependent on the specific language):
| Arabic: | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| filso | Palestinian | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| jerxo | Algerian | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| jordo | Jordanian | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| libjo | Libyan | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| lubno | Lebanese | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| misro | Egyptian | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| morko | Moroccan | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| rakso | Iraqi | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| sadjo | Saudi | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| sirxo | Syrian | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Portuguese: | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| brazo | Brazilian | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Urdu: | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| kisto | Pakistani | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
The continents (and oceanic regions) of the Earth:
| bemro | |
| dzipo | |
| ketco |
South American (from “Quechua”) |
| friko |
African |
| polno |
Polynesian/Oceanic |
| ropno |
European |
| xazdo |
Asiatic |
A few smaller but historically important cultures:
The list of cultures represented by gismu, given in Section 4.15 , is unavoidably controversial. Much time has been spent debating whether this or that culture “deserves a gismu” or “must languish in fu'ivla space”. To help defuse this argument, a last-minute proposal was made when this book was already substantially complete. I have added it here with experimental status: it is not yet a standard part of Lojban, since all its implications have not been tested in open debate, and it affects a part of the language (lujvo-making) that has long been stable, but is known to be fragile in the face of small changes. (Many attempts were made to add general mechanisms for making lujvo that contained fu'ivla, but all failed on obvious or obscure counterexamples; finally the general zei mechanism was devised instead.)
The first part of the proposal is uncontroversial and involves no change to the language mechanisms. All valid Type 4 fu'ivla of the form CCVVCV would be reserved for cultural brivla analogous to those described in Section 4.15. For example,
is of the appropriate form, and passes all tests required of a Stage 4 fu'ivla. No two fu'ivla of this form would be allowed to coexist if they differed only in the final vowel; this rule was applied to gismu, but does not apply to other fu'ivla or to lujvo.
The second, and fully experimental, part of the proposal is to allow rafsi to be formed from these cultural fu'ivla by removing the final vowel and treating the result as a 4-letter rafsi (although it would contain five letters, not four). These rafsi could then be used on a par with all other rafsi in forming lujvo. The tanru
could be represented by the lujvo
which is an illegal word in standard Lojban, but a valid lujvo under this proposal. There would be no short rafsi or 5-letter rafsi assigned to any fu'ivla, so no fu'ivla could appear as the last element of a lujvo.
The cultural fu'ivla introduced under this proposal are called rafsi fu'ivla , since they are distinguished from other Type 4 fu'ivla by the property of having rafsi. If this proposal is workable and introduces no problems into Lojban morphology, it might become standard for all Type 4 fu'ivla, including those made for plants, animals, foodstuffs, and other things.

At the center, logically and often physically, of every Lojban bridi is one or more words which constitute the selbri. A bridi expresses a relationship between things: the selbri specifies which relationship is referred to. The difference between:
and
lies in the different selbri.
The simplest kind of selbri is a single Lojban content word: a brivla. There are three different varieties of brivla: those which are built into the language (the gismu), those which are derived from combinations of the gismu (the lujvo), and those which are taken (usually in a modified form) from other languages (the fu'ivla). In addition, there are a few cmavo that can act like brivla; these are mentioned in Section 5.9, and discussed in full in Chapter 7.
For the purposes of this chapter, however, all brivla are alike. For example,
illustrate the three types of brivla (gismu, lujvo, and fu'ivla respectively), but in each case the selbri is composed of a single word whose meaning can be learned independent of its origins.
The remainder of this chapter will mostly use gismu as example brivla, because they are short. However, it is important to keep in mind that wherever a gismu appears, it could be replaced by any other kind of brivla.
Beyond the single brivla, a selbri may consist of two brivla placed together. When a selbri is built in this way from more than one brivla, it is called a tanru, a word with no single English equivalent. The nearest analogue to tanru in English are combinations of two nouns such as “lemon tree”. There is no way to tell just by looking at the phrase “lemon tree” exactly what it refers to, even if you know the meanings of “lemon” and “tree” by themselves. As English-speakers, we must simply know that it refers to “a tree which bears lemons as fruits”. A person who didn't know English very well might think of it as analogous to “brown tree” and wonder, “What kind of tree is lemon-colored?”
In Lojban, tanru are also used for the same purposes as English adjective-noun combinations like “big boy” and adverb-verb combinations like “quickly run”. This is a consequence of Lojban not having any such categories as “noun”, “verb”, “adjective”, or “adverb”. English words belonging to any of these categories are translated by simple brivla in Lojban. Here are some examples of tanru:
Note that pelnimre is a lujvo for “lemon”; it is derived from the gismu pelxu, yellow, and nimre, citrus. Note also that sutra can mean “fast/quick” or “quickly” depending on its use:
shows sutra used to translate an adjective, whereas in Example 5.8 it is translating an adverb. (Another correct translation of Example 5.8, however, would be “I am a quick runner”.)
There are special Lojban terms for the two components of a tanru, derived from the place structure of the word tanru. The first component is called the seltau, and the second component is called the tertau.
The most important rule for use in interpreting tanru is that the tertau carries the primary meaning. A pelnimre tricu is primarily a tree, and only secondarily is it connected with lemons in some way. For this reason, an alternative translation of Example 5.6 would be:
This “type of” relationship between the components of a tanru is fundamental to the tanru concept.
We may also say that the seltau modifies the meaning of the tertau:
would be another possible translation of Example 5.6. In the same way, a more explicit translation of Example 5.7 might be:
This “way that boys are big” would be quite different from the way in which elephants are big; big-for-a-boy is small-for-an-elephant.
All tanru are ambiguous semantically. Possible translations of:
include:
-
That is a table which goes (a wheeled table, perhaps).
-
That is a table owned by one who goes.
-
That is a table used by those who go (a sports doctor's table?).
-
That is a table when it goes (otherwise it is a chair?).
In each case the object referred to is a “goer type of table”, but the ambiguous “type of” relationship can mean one of many things. A speaker who uses tanru (and pragmatically all speakers must) takes the risk of being misunderstood. Using tanru is convenient because they are short and expressive; the circumlocution required to squeeze out all ambiguity can require too much effort.
No general theory covering the meaning of all possible tanru exists; probably no such theory can exist. However, some regularities obviously do exist:
are parallel tanru, in the sense that the relationship between barda and prenu is the same as that between cmalu and prenu. Section 5.14 and Section 5.15 contain a partial listing of some types of tanru, with examples.
The following cmavo is discussed in this section:
|
bo |
BO |
closest scope grouping |
Consider the English sentence:
What does it mean? Two possible readings are:
This ambiguity is quite different from the simple tanru ambiguity described in Section 5.2. We understand that “girls' school” means “a school where girls are the students”, and not “a school where girls are the teachers” or “a school which is a girl” (!). Likewise, we understand that “little girl” means “girl who is small”. This is an ambiguity of grouping. Is “girls' school” to be taken as a unit, with “little” specifying the type of girls' school? Or is “little girl” to be taken as a unit, specifying the type of school? In English speech, different tones of voice, or exaggerated speech rhythm showing the grouping, are used to make the distinction; English writing usually leaves it unrepresented.
Lojban makes no use of tones of voice for any purpose; explicit words are used to do the work. The cmavo bo (which belongs to selma'o BO) may be placed between the two brivla which are most closely associated. Therefore, a Lojban translation of Example 5.17 would be:
Example 5.18 might be translated:
The bo is represented in the literal translation by a bracketed hyphen (not to be confused with the bare hyphen used as a placeholder in other glosses) because in written English a hyphen is sometimes used for the same purpose: “a big dog-catcher” would be quite different from a “big-dog catcher” (presumably someone who catches only big dogs).
Analysis of Example 5.19 and Example 5.20 reveals a tanru nested within a tanru. In Example 5.19, the main tanru has a seltau of cmalu and a tertau of nixli bo ckule; the tertau is itself a tanru with nixli as the seltau and ckule as the tertau. In Example 5.20, on the other hand, the seltau is cmalu bo nixli (itself a tanru), whereas the tertau is ckule. This structure of tanru nested within tanru forms the basis for all the more complex types of selbri that will be explained below.
What about Example 5.21 ? What does it mean?
The rules of Lojban do not leave this sentence ambiguous, as the rules of English do with Example 5.16. The choice made by the language designers is to say that Example 5.21 means the same as Example 5.20. This is true no matter what three brivla are used: the leftmost two are always grouped together. This rule is called the “left-grouping rule”. Left-grouping in seemingly ambiguous structures is quite common – though not universal – in other contexts in Lojban.
Another way to express the English meaning of Example 5.19 and Example 5.20, using parentheses to mark grouping, is:
Because “type-of” is implicit in the Lojban tanru form, it has no Lojban equivalent.
Note: It is perfectly legal, though pointless, to insert bo into a simple tanru:
is a legal Lojban bridi that means exactly the same thing as Example 5.13, and is ambiguous in exactly the same ways. The cmavo bo serves only to resolve grouping ambiguity: it says nothing about the more basic ambiguity present in all tanru.
If one element of a tanru can be another tanru, why not both elements?
| do | mutce | bo | barda | gerku | bo | kavbu |
| You | are-a-(very | type-of | large) | (dog | type-of | capturer). |
|
You are a very large dog-catcher. |
In Example 5.25, the selbri is a tanru with seltau mutce bo barda and tertau gerku bo kavbu. It is worth emphasizing once again that this tanru has the same fundamental ambiguity as all other Lojban tanru: the sense in which the “dog type-of capturer” is said to be “very type-of large” is not precisely specified. Presumably it is his body which is large, but theoretically it could be one of his other properties.
We will now justify the title of this chapter by exploring the ramifications of the phrase “pretty little girls' school”, an expansion of the tanru used in Section 5.3 to four brivla. (Although this example has been used in the Loglan Project almost since the beginning – it first appeared in Quine's book Word and Object (1960) – it is actually a mediocre example because of the ambiguity of English “pretty”; it can mean “beautiful”, the sense intended here, or it can mean “very”. Lojban melbi is not subject to this ambiguity: it means only “beautiful”.)
Here are four ways to group this phrase:
| ta | melbi | cmalu | nixli | ckule | |||
| That | is-a-((pretty | type-of | little) | type-of | girl) | type-of | school. |
|
That is a school for girls who are beautifully small. |
| ta | melbi | cmalu | nixli | bo | ckule | |
| That | is-a-(pretty | type-of | little) | (girl | type-of | school). |
|
That is a girls' school which is beautifully small. |
| ta | melbi | cmalu | bo | nixli | ckule | ||
| That | is-a-(pretty | type-of | (little | type-of | girl)) | type-of | school. |
|
That is a school for small girls who are beautiful. |
| ta | melbi | cmalu | bo | nixli | bo | ckule | |
| That | is-a-pretty | type-of | (little | type-of | (girl | type-of | school)). |
|
That is a small school for girls which is beautiful. |
Example 5.29 uses a construction which has not been seen before: cmalu bo nixli bo ckule, with two consecutive uses of bo between brivla. The rule for multiple bo constructions is the opposite of the rule when no bo is present at all: the last two are grouped together. Not surprisingly, this is called the “right-grouping rule”, and it is associated with every use of bo in the language. Therefore,
means the same as Example 5.19, not Example 5.20. This rule may seem peculiar at first, but one of its consequences is that bo is never necessary between the first two elements of any of the complex tanru presented so far: all of Example 5.26 through Example 5.29 could have bo inserted between melbi and cmalu with no change in meaning.
The following cmavo are discussed in this section:
|
ke |
KE |
start grouping |
|
ke'e |
KEhE |
end grouping |
There is, in fact, a fifth grouping of “pretty little girls' school” that cannot be expressed with the resources explained so far. To handle it, we must introduce the grouping parentheses cmavo, ke and ke'e (belonging to selma'o KE and KEhE respectively). Any portion of a selbri sandwiched between these two cmavo is taken to be a single tanru component, independently of what is adjacent to it. Thus, Example 5.26 can be rewritten in any of the following ways:
Even more versions could be created simply by placing any number of ke cmavo at the beginning of the selbri, and a like number of ke'e cmavo at its end. Obviously, all of these are a waste of breath once the left-grouping rule has been grasped. However, the following is equivalent to Example 5.28 and may be easier to understand:
| ta | melbi | ke | cmalu | nixli | ke'e | ckule | |||||
| That | is-a-( | pretty | type-of | ( | little | type-of | girl | ) | ) | type-of | school. |
Likewise, a ke and ke'e version of Example 5.27 would be:
The final ke'e is given in square brackets here to indicate that it can be elided. It is always possible to elide ke'e at the end of the selbri, making Example 5.35 as terse as Example 5.27.
Now how about that fifth grouping? It is
| ta | melbi | ke | cmalu | nixli | ckule | [ke'e] | |||||
| That | is-a-pretty | type-of | ( | ( | little | type-of | girl | ) | type-of | school | ). |
|
That is a beautiful school for small girls. |
Example 5.36 is distinctly different in meaning from any of Example 5.26 through Example 5.29. Note that within the ke … ke'e parentheses, the left-grouping rule is applied to cmalu nixli ckule.
It is perfectly all right to mix bo and ke … ke'e in a single selbri. For instance, Example 5.29, which in pure ke … ke'e form is
| ta | melbi | ke | cmalu | |
| That | is-a-pretty | type-of | ( | little |
| ke | nixli | ckule | [ke'e] | [ke'e] | ||
| type-of | ( | girl | type-of | school | ) | ). |
can equivalently be expressed as:
| ta | melbi | ke | cmalu | nixli | bo | ckule | [ke'e] | ||
| That | is-a-pretty | type-of | ( | little | type-of-( | girl | type-of | school | )). |
and in many other different forms as well.
The following cmavo are discussed in this section:
|
je |
JA |
tanru logical “and” |
|
ja |
JA |
tanru logical “or” |
|
joi |
JOI |
mixed mass “and” |
|
gu'e |
GUhA |
tanru forethought logical “and” |
|
gi |
GI |
forethought connection separator |
Consider the English phrase “big red dog”. How shall this be rendered as a Lojban tanru? The naive attempt:
will not do, as it means a dog whose redness is big, in whatever way redness might be described as “big”. Nor is
much better. After all, the straightforward understanding of the English phrase is that the dog is big as compared with other dogs, not merely as compared with other red dogs. In fact, the bigness and redness are independent properties of the dog, and only obscure rules of English adjective ordering prevent us from saying “red big dog”.
The Lojban approach to this problem is to introduce the cmavo je, which is one of the many equivalents of English “and”. A big red dog is one that is both big and red, and we can say:
Of course,
is equally satisfactory and means the same thing. As these examples indicate, joining two brivla with je makes them a unit for tanru purposes. However, explicit grouping with bo or ke … ke'e associates brivla more closely than je does:
| barda | je | pelxu | bo | xunre | gerku |
| (big | and | (yellow | type-of | red)) | dog |
| barda | je | ke | pelxu | xunre | ke'e | gerku | |
| (big | and | ( | yellow | type-of | red) | ) | dog |
|
big yellowish-red dog |
With no grouping indicators, we get:
| barda | je | pelxu | xunre | gerku | ||
| ((big | and | yellow) | type-of | red) | type-of | dog |
|
biggish- and yellowish-red dog |
which again raises the question of Example 5.39: what does “biggish-red” mean?
Unlike bo and ke … ke'e, je is useful as well as merely legal within simple tanru. It may be used to partly resolve the ambiguity of simple tanru:
definitely refers to something which is both blue and is a house, and not to any of the other possible interpretations of simple blanu zdani. Furthermore, blanu zdani refers to something which is blue in the way that houses are blue; blanu je zdani has no such implication – the blueness of a blanu je zdani is independent of its houseness.
With the addition of je, many more versions of “pretty little girls' school” are made possible: see Section 5.16 for a complete list.
A subtle point in the semantics of tanru like Example 5.41 needs special elucidation. There are at least two possible interpretations of:
It can be understood as:
or as:
The interpretation specified by Example 5.47 treats the tanru as a sort of abbreviation for:
| ta | ke | melbi | ckule | ke'e | je | ke | nixli | ckule | [ke'e] | ||
| That | is-a-( | beautiful | type-of | school | ) | and | ( | girl | type-of | school | ) |
whereas the interpretation specified by Example 5.48 does not. This is a kind of semantic ambiguity for which Lojban does not compel a firm resolution. The way in which the school is said to be of type “beautiful and girl” may entail that it is separately a beautiful school and a girls' school; but the alternative interpretation, that the members of the school are beautiful and girls, is also possible. Still another interpretation is:
so while the logical connectives help to resolve the meaning of tanru, they by no means compel a single meaning in and of themselves.
In general, logical connectives within tanru cannot undergo the formal manipulations that are possible with the related logical connectives that exist outside tanru; see Section 14.12 for further details.
The logical connective je is only one of the fourteen logical connectives that Lojban provides. Here are a few examples of some of the others:
| xamgu | jo | tordu | nuntavla |
| (good | if-and-only-if | short) | speech |
|
speech which is good if (and only if) it is short |
| vajni | ju | pluka | nuntavla |
| (important | whether-or-not | pleasing) | event-of-talking |
|
speech which is important, whether or not it is pleasing |
In Example 5.51, ja is grammatically equivalent to je but means “or” (more precisely, “and/or”). Likewise, naja means “only if” in Example 5.52, jo means “if and only if” in Example 5.53, and ju means “whether or not” in Example 5.54.
Now consider the following example:
which illustrates a new grammatical feature: the use of both ja and bo between tanru components. The two cmavo combine to form a compound whose meaning is that of ja but which groups more closely; ja bo is to ja as plain bo is to no cmavo at all. However, both ja and ja bo group less closely than bo does:
An alternative form of Example 5.55 is:
In addition to the logical connectives, there are also a variety of non-logical connectives, grammatically equivalent to the logical ones. The only one with a well-understood meaning in tanru contexts is joi, which is the kind of “and” that denotes a mixture:
The ball described is neither solely red nor solely blue, but probably striped or in some other way exhibiting a combination of the two colors. Example 5.58 is distinct from:
which would be a ball whose color is some sort of purple tending toward red, since xunre is the more important of the two components. On the other hand,
is probably self-contradictory, seeming to claim that the ball is independently both blue and red at the same time, although some sensible interpretation may exist.
Finally, just as English “and” has the variant form “both ... and”, so je between tanru components has the variant form gu'e … gi, where gu'e is placed before the components and gi between them:
is equivalent in meaning to Example 5.41. For each logical connective related to je, there is a corresponding connective related to gu'e … gi in a systematic way.
The portion of a gu'e … gi construction before the gi is a full selbri, and may use any of the selbri resources including je logical connections. After the gi, logical connections are taken to be wider in scope than the gu'e … gi, which has in effect the same scope as bo:
| gu'e | barda | je | xunre | gi | gerku | ja | mlatu |
| (both | (big | and | red) | and | dog) | or | cat |
|
something which is either big, red, and a dog, or else a cat |
leaves mlatu outside the gu'e … gi construction. The scope of the gi arm extends only to a single brivla or to two or more brivla connected with bo or ke … ke'e.
The following cmavo are discussed in this section:
|
be |
BE |
linked sumti marker |
|
bei |
BEI |
linked sumti separator |
|
be'o |
BEhO |
linked sumti terminator |
The question of the place structures of selbri has been glossed over so far. This chapter does not attempt to treat place structure issues in detail; they are discussed in Chapter 9. One grammatical structure related to places belongs here, however. In simple sentences such as Example 5.1, the place structure of the selbri is simply the defined place structure of the gismu mamta. What about more complex selbri?
For tanru, the place structure rule is simple: the place structure of a tanru is always the place structure of its tertau. Thus, the place structure of blanu zdani is that of zdani: the x1 place is a house or nest, and the x2 place is its occupants.
What about the places of blanu ? Is there any way to get them into the act? In fact, blanu has only one place, and this is merged, as it were, with the x1 place of zdani. It is whatever is in the x1 place that is being characterized as blue-for-a-house. But if we replace blanu with xamgu, we get:
Since xamgu has three places (x1, the good thing; x2, the person for whom it is good; and x3, the standard of goodness), Example 5.63 necessarily omits information about the last two: there is no room for them. Room can be made, however!
| ti | xamgu | be | do | bei | mi | [be'o] | zdani |
| This | is-a-good | (for | you | by-standard | me) | house. |
|
This is a house that is good for you by my standards. |
Here, the gismu xamgu has been followed by the cmavo be (of selma'o BE), which signals that one or more sumti follows. These sumti are not part of the overall bridi place structure, but fill the places of the brivla they are attached to, starting with x2. If there is more than one sumti, they are separated by the cmavo bei (of selma'o BEI), and the list of sumti is terminated by the elidable terminator be'o (of selma'o BEhO).
Grammatically, a brivla with sumti linked to it in this fashion plays the same role in tanru as a simple brivla. To illustrate, here is a fully fleshed-out version of Example 5.19, with all places filled in:
| ti | cmalu | be | le | ka | se | canlu |
| This | is-a-small | (in-dimension | the | property-of | [swap x1 and x2] | volume |
| bei | lo'e | ckule | be'o |
| by-standard | the-typical | school) |
| nixli | be | le | nanca | be | li | mu | be'o |
| (girl | (of | the | years-in-duration | of | the-number | five) |
| bei | lo | merko | be'o | bo | ckule |
| by-standard | some | American-thing) | school-located-at) |
| la | .bryklyn. |
| that-named | Brooklyn |
| loi | pemci |
| with-subject | poems |
| le | mela | .nu,IORK. | prenu |
| for-audience-the | among-that-named | New-York | persons |
| le | jecta |
| with-operator-the | state. |
|
This is a school, small in volume compared to the typical school, pertaining to five-year-old girls (by American standards), in Brooklyn, teaching poetry to the New York community and operated by the state. |
Here the three places of cmalu, the three of nixli, and the four of ckule are fully specified. Since the places of ckule are the places of the bridi as a whole, it was not necessary to link the sumti which follow ckule. It would have been legal to do so, however:
means the same as
No matter how complex a tanru gets, the last brivla always dictates the place structure: the place structure of
| melbi | je | cmalu | nixli | bo | ckule | |
| a | (pretty | and | little) | (girl | school) |
|
a school for girls which is both beautiful and small |
is simply that of ckule. (The sole exception to this rule is discussed in Section 5.8.)
It is possible to precede linked sumti by the place structure ordering tags fe, fi, fo, and fu (of selma'o FA, discussed further in Section 9.3), which serve to explicitly specify the x2, x3, x4, and x5 places respectively. Normally, the place following the be is the x2 place and the other places follow in order. If it seems convenient to change the order, however, it can be accomplished as follows:
which is equivalent in meaning to Example 5.64. Note that the order of be, bei, and be'o does not change; only the inserted fi tells us that mi is the x3 place (and correspondingly, the inserted fe tells us that do is the x2 place). Changing the order of sumti is often done to match the order of another language, or for emphasis or rhythm.
Of course, using FA cmavo makes it easy to specify one place while omitting a previous place:
| ti | xamgu | be | fi | mi | [be'o] | zdani |
| This | is-a-good | ( | by-standard | me | ) | house. |
|
This is a good house by my standards. |
Similarly, sumti labeled by modal or tense tags can be inserted into strings of linked sumti just as they can into bridi:
| ta | blanu | be | ga'a | mi | [be'o] | zdani |
| That | is-a-blue | ( | to-observer | me | ) | house. |
|
That is a blue, as I see it, house. |
The meaning of Example 5.71 is slightly different from:
See discussions in Chapter 9 of modals and in Chapter 10 of tenses for more explanations.
The terminator be'o is almost always elidable: however, if the selbri belongs to a description, then a relative clause following it will attach to the last linked sumti unless be'o is used, in which case it will attach to the outer description:
(Relative clauses are explained in Chapter 8.)
In other cases, however, be'o cannot be elided if ku has also been elided:
requires either ku or be'o, and since there is only one occurrence of be, the be'o must match it, whereas it may be confusing which occurrence of le the ku terminates (in fact the second one is correct).
The following cmavo is discussed in this section:
|
co |
CO |
tanru inversion marker |
The standard order of Lojban tanru, whereby the modifier precedes what it modifies, is very natural to English-speakers: we talk of “blue houses”, not of “houses blue”. In other languages, however, such matters are differently arranged, and Lojban supports this reverse order (tertau before seltau) by inserting the particle co. Example 5.76 and Example 5.77 mean exactly the same thing:
This change is called “tanru inversion”. In tanru inversion, the element before co (zdani in Example 5.77) is the tertau, and the element following co (blanu) in Example 5.77) is the seltau.
The meaning, and more specifically, the place structure, of a tanru is not affected by inversion: the place structure of zdani co blanu is still that of zdani. However, the existence of inversion in a selbri has a very special effect on any sumti which follow that selbri. Instead of being interpreted as filling places of the selbri, they actually fill the places (starting with x2) of the seltau. In Section 5.7, we saw how to fill interior places with be … bei … be'o, and in fact Example 5.78 and Example 5.79 have the same meaning:
| mi | klama | be | le | zarci | bei | le | zdani | be'o | troci |
| I | am-a-(goer | to | the | market | from | the | house | ) | type-of-trier. |
|
I try to go to the market from the house. |
| mi | troci | co | klama | le | zarci | le | zdani |
| I | am-a-trier | of-type | (goer | to-the | market | from-the | house). |
|
I try to go to the market from the house. |
Example 5.79 is a less deeply nested construction, requiring fewer cmavo. As a result it is probably easier to understand.
Note that in Lojban “trying to go” is expressed using troci as the tertau. The reason is that “trying to go” is a “going type of trying”, not a “trying type of going”. The trying is more fundamental than the going – if the trying fails, we may not have a going at all.
Any sumti which precede a selbri with an inverted tanru fill the places of the selbri (i.e., the places of the tertau) in the ordinary way. In Example 5.79, mi fills the x1 place of troci co klama, which is the x1 place of troci. The other places of the selbri remain unfilled. The trailing sumti le zarci and le zdani do not occupy selbri places, despite appearances.
As a result, the regular mechanisms (involving the vo'a and the go'a-series, explained in Section 7.6 and Section 7.8) for referring to individual sumti of a bridi cannot refer to any of the trailing places of Example 5.79, because they are not really “sumti of the bridi” at all.
When inverting a more complex tanru, it is possible to invert it only at the most general modifier-modified pair. The only possible inversion of Example 5.19, for instance, is:
| ta | nixli | [bo] | ckule | co | cmalu |
| That | (is-a-girl | type-of | school) | of-type | little. |
|
That's a girls' school which is small. |
Note that the bo of Example 5.19 is optional in Example 5.80, because co groups more loosely than any other cmavo used in tanru, including none at all. Not even ke … ke'e parentheses can encompass a co:
| ta | cmalu | ke | nixli | ckule | [ke'e] | co | melbi | ||
| That | is-a-(little | type-of | ( | girl | type-of | school | )) | of-type | pretty. |
|
That's a small school for girls which is beautiful. |
In Example 5.81, the ke'e is automatically inserted before the co rather than at its usual place at the end of the selbri. As a result, there is a simple and mechanical rule for removing co from any selbri: change “A co B” to “ke B ke'e A”. (At the same time, any sumti following the selbri must be transformed into be … bei … be'o form and attached following B.) Therefore,
means the same as:
Multiple co cmavo can appear within a selbri, indicating multiple inversions: a right-grouping rule is employed, as for bo. The above rule can be applied to interpret such selbri, but all co cmavo must be removed simultaneously:
becomes formally
which by the left-grouping rule is simply
As stated above, the selbri places, other than the first, of
cannot be filled by placing sumti after the selbri, because any sumti in that position fill the places of sutra, the seltau. However, the tertau places (which means in effect the selbri places) can be filled with be:
| mi | klama | be | le | zarci | be'o | co | sutra |
| I | am-a-goer | ( | to-the | store | ) | of-type | quick. |
|
I go to the store quickly. |
The following cmavo are discussed in this section:
|
go'i |
GOhA |
repeats the previous bridi |
|
du |
GOhA |
equality |
|
nu'a |
NUhA |
math operator to selbri |
|
moi |
MOI |
changes number to ordinal selbri |
|
mei |
MOI |
changes number to cardinal selbri |
|
nu |
NU |
event abstraction |
|
kei |
KEI |
terminator for NU |
So far we have only discussed brivla and tanru built up from brivla as possible selbri. In fact, there are a few other constructions in Lojban which are grammatically equivalent to brivla: they can be used either directly as selbri, or as components in tanru. Some of these types of simple selbri are discussed at length in Chapter 7, Chapter 11, and Chapter 18; but for completeness these types are mentioned here with a brief explanation and an example of their use in selbri.
The cmavo of selma'o GOhA (with one exception) serve as pro-bridi, providing a reference to the content of other bridi; none of them has a fixed meaning. The most commonly used member of GOhA is probably go'i, which amounts to a repetition of the previous bridi, or part of it. If I say:
you may retort:
Example 5.90 is short for:
because the whole bridi of Example 5.89 has been packaged up into the single word go'i and inserted into Example 5.90.
The exceptional member of GOhA is du, which represents the relation of identity. Its place structure is:
x1 is identical with x2, x3, ...
for as many places as are given. More information on selma'o GOhA is available in Chapter 7.
Lojban mathematical expressions (mekso) can be incorporated into selbri in two different ways. Mathematical operators such as su'i, meaning “plus”, can be transformed into selbri by prefixing them with nu'a (of selma'o NUhA). The resulting place structure is:
x1 is the result of applying (the operator) to arguments x2, x3, etc.
for as many arguments as are required. (The result goes in the x1 place because the number of following places may be indefinite.) For example:
A possible tanru example might be:
| mi | jimpe | tu'a | loi | nu'a su'i | nabmi |
| I | understand | something-about | the-mass-of | is-the-sum-of | problems. |
|
I understand addition problems. |
More usefully, it is possible to combine a mathematical expression with a cmavo of selma'o MOI to create one of various numerical selbri. Details are available in Section 18.11. Here are a few tanru:
| la | .prim. | .palvr. | pamoi | cusku |
| That-named | Preem | Palver | is-the-1-th | speaker. |
|
Preem Palver is the first speaker. |
| la | .an,iis. | joi | la | .asun. |
| That-named | Anyi | massed-with | that-named | Asun |
| bruna | remei |
| are-a-brother | type-of-twosome. |
|
Anyi and Asun are two brothers. |
Finally, an important type of simple selbri which is not a brivla is the abstraction. Grammatically, abstractions are simple: a cmavo of selma'o NU, followed by a bridi, followed by the elidable terminator kei of selma'o KEI. Semantically, abstractions are an extremely subtle and powerful feature of Lojban whose full ramifications are documented in Chapter 11. A few examples:
Example 5.96 is quite distinct in meaning from:
which suggests the meaning “a room that amuses someone”.
The following cmavo are discussed in this section:
|
me |
ME |
changes sumti to simple selbri |
|
me'u |
MEhU |
terminator for me |
A sumti can be made into a simple selbri by preceding it with me (of selma'o ME) and following it with the elidable terminator me'u (of selma'o MEhU). This makes a selbri with the place structure
x1 is one of the referents of “[the sumti]”
which is true of the thing, or things, that are the referents of the sumti, and not of anything else. For example, consider the sumti
If these are understood to be the Three Kings of Christian tradition, who arrive every year on January 6, then we may say:
| la | .BALtazar. | cu | me | le ci nolraitru |
| That-named | Balthazar | is-one-of-the-referents-of | “the three kings.” |
|
Balthazar is one of the three kings. |
and likewise
and
If the sumti refers to a single object, then the effect of me is much like that of du:
means the same as
It is common to use me selbri, especially those based on name sumti using la, as seltau. For example:
| ta | me | lai .kraislr. | [me'u] | karce |
| That | (is-a-referent-of | “ the-mass-named ‘Chrysler’ ” | ) | car. |
|
That is a Chrysler car. |
The elidable terminator me'u can usually be omitted. It is absolutely required only if the me selbri is being used in an indefinite description (a type of sumti explained in Section 6.8), and if the indefinite description is followed by a relative clause (explained in Chapter 8) or a sumti logical connective (explained in Section 14.6). Without a me'u, the relative clause or logical connective would appear to belong to the sumti embedded in the me expression. Here is a contrasting pair of sentences:
| re | me | le | ci | nolraitru | .e | la | .djan. | [me'u] | cu | blabi |
|
Two of the group “the three kings and John” are white. |
In Example 5.105 the me selbri covers the three kings plus John, and the indefinite description picks out two of them that are said to be white: we cannot say which two. In Example 5.106, though, the me selbri covers only the three kings: two of them are said to be white, and so is John.
Finally, here is another example requiring me'u:
| ta | me la'e le se cusku be do | me'u | cukta | |
| That | is-a-(what-you-said) | type-of | book. |
|
That is the kind of book you were talking about. |
There are other sentences where either me'u or some other elidable terminator must be expressed:
| le | me le ci nolraitru | [ku] | me'u | nunsalci |
| the | (the three kings) | type-of-event-of-celebrating |
|
the Three Kings celebration |
requires either ku or me'u to be explicit, and (as with be'o in Section 5.7) the me'u leaves no doubt which cmavo it is paired with.
Conversion is the process of changing a selbri so that its places appear in a different order. This is not the same as labeling the sumti with the cmavo of FA, as mentioned in Section 5.7, and then rearranging the order in which the sumti are spoken or written. Conversion transforms the selbri into a distinct, though closely related, selbri with renumbered places.
In Lojban, conversion is accomplished by placing a cmavo of selma'o SE before the selbri:
is equivalent in meaning to:
Conversion is fully explained in Section 9.4. For the purposes of this chapter, the important point about conversion is that it applies only to the following simple selbri. When trying to convert a tanru, therefore, it is necessary to be careful! Consider Example 5.111:
| la | .alis. | cu | cadzu | klama | le | zarci |
| That-named | Alice | is-a-walker | type-of-goer-to | the | market. | |
| That-named | Alice | walkingly | goes-to | the | market. |
|
Alice walks to the market. |
To convert this sentence so that le zarci is in the x1 place, one correct way is:
| le | zarci | cu | se |
| The | market | is-a-[swap x1/x2] | |
| The | market |
| ke | cadzu | klama | [ke'e] | la | .alis. |
| ( | walker | type-of-goer-to | ) | that-named | Alice. |
| is-walkingly | gone-to-by | that-named | Alice. |
The ke … ke'e brackets cause the entire tanru to be converted by the se, which would otherwise convert only cadzu, leading to:
| le | zarci | cu | se | cadzu |
| The | market | (is-a-[swap x1/x2] | walker) | |
| The | market | is-a-walking-surface |
| klama | la | .alis. |
| type-of-goer-to | that-named | Alice. |
| type-of-goer-to | that-named | Alice. |
whatever that might mean. An alternative approach, since the place structure of cadzu klama is that of klama alone, is to convert only the latter:
But the tanru in Example 5.114 may or may not have the same meaning as that in Example 5.111; in particular, because cadzu is not converted, there is a suggestion that although Alice is the goer, the market is the walker. With a different sumti as x1, this seemingly odd interpretation might make considerable sense:
suggests that Alice is going to John, who is a moving target.
There is an alternative type of conversion, using the cmavo jai of selma'o JAI optionally followed by a modal or tense construction. Grammatically, such a combination behaves exactly like conversion using SE. More details can be found in Section 9.12.
Negation is too large and complex a topic to explain fully in this chapter; see Chapter 15. In brief, there are two main types of negation in Lojban. This section is concerned with so-called “scalar negation”, which is used to state that a true relation between the sumti is something other than what the selbri specifies. Scalar negation is expressed by cmavo of selma'o NAhE:
| la | .alis. | cu | na'e | ke | cadzu | klama | [ke'e] | le | zarci |
| That-named | Alice | non- | ( | walkingly | goes-to | ) | the | market. |
|
Alice doesn't walk to the market. |
meaning that Alice's relationship to the market is something other than that of walking there. But if the ke were omitted, the result would be:
| la | .alis. | cu | na'e | cadzu | klama | le | zarci |
| That-named | Alice | non- | walkingly | goes-to | the | market. |
|
Alice doesn't walk to the market. |
meaning that Alice does go there in some way (klama is not negated), but by a means other than that of walking. Example 5.116 negates both cadzu and klama, suggesting that Alice's relation to the market is something different from walkingly-going; it might be walking without going, or going without walking, or neither.
Of course, any of the simple selbri types explained in Section 5.9 may be used in place of brivla in any of these examples:
Since only pamoi is negated, an appropriate inference is that he is some other kind of speaker.
Here is an assortment of more complex examples showing the interaction of scalar negation with bo grouping, ke and ke'e grouping, logical connection, and sumti linked with be and bei. Note that both bo and be bind less tightly than NAhE.
| mi | na'e | sutra | bo | cadzu | be | fi | le | birka | be'o | klama | le | zarci |
| I | ((non- | quickly) | (walking | using | the | arms | )) | go-to | the | market. |
|
I go to the market, walking using my arms other than quickly. |
In Example 5.119, na'e negates only sutra. Contrast Example 5.120:
| mi | na'e | ke | sutra | cadzu | be | fi | le | birka | [be'o] |
| I | non- | ( | quickly | (walking | using | the | arms | ) |
| ke'e | klama | le | zarci |
| ) | go-to | the | market. |
|
I go to the market, other than by walking quickly on my arms. |
Now consider Example 5.121 and Example 5.122, which are equivalent in meaning, but use bo grouping and ke grouping respectively:
| mi | sutra | bo | cadzu | be | fi | le | birka | be'o |
| I | (quickly | (walking | using | the | arms | ) |
| je | masno | klama | le | zarci |
| and | slowly) | go-to | the | market. |
|
I go to the market, both quickly walking using my arms and slowly. |
| mi | ke | sutra | cadzu | be | fi | le | birka | [be'o] | ke'e |
| I | ( | (quickly | (walking | using | the | arms | ) | ) |
| je | masno | klama | le | zarci |
| and | slowly) | go-to | the | market. |
|
I go to the market, both quickly walking using my arms and slowly. |
However, if we place a na'e at the beginning of the selbri in both Example 5.121 and Example 5.122, we get different results:
| mi | na'e | sutra | bo | cadzu | be | fi | le | birka | be'o |
| I | ((non- | quickly) | (walking | using | the | arms | ) |
| je | masno | klama | le | zarci |
| and | slowly) | go-to | the | market. |
|
I go to the market, both walking using my arms other than quickly, and also slowly. |
| mi | na'e | ke | sutra | cadzu | be | fi | le | birka | [be'o] | ke'e |
| I | (non | ( | quickly | (walking | using | the | arms) | ) |
| je | masno | klama | le | zarci |
| and | slowly) | go-to | the | market. |
|
I go to the market, both other than quickly walking using my arms, and also slowly. |
The difference arises because the na'e in Example 5.124 negates the whole construction from ke to ke'e, whereas in Example 5.123 it negates sutra alone.
Beware of omitting terminators in these complex examples! If the explicit ke'e is left out in Example 5.124, it is transformed into:
| mi | na'e | ke | sutra | bo | cadzu | be | fi | le | birka | be'o |
| I | non- | ( | quickly | walking | [ | using | the | arms | ] |
| je | masno | klama | [ke'e] | le | zarci |
| and | slowly | go-to | ) | the | market. |
|
I do something other than quickly both going to the market walking using my arms and slowly going to the market. |
And if both ke'e and be'o are omitted, the results are even sillier:
| mi | na'e | ke | sutra | bo | cadzu | be | fi | le | birka | je | masno |
| I | non | ( | quickly | walk | on-my | (the | arm-type | and | slow) |
| klama | [be'o] | [ke'e] | le | zarci | |
| goers | ) | on-surface | the | market. |
|
I do something other than quickly walking using the goers, both arm-type and slow, relative-to the market. |
In Example 5.126, everything after be is a linked sumti, so the place structure is that of cadzu, whose x2 place is the surface walked upon. It is less than clear what an “arm-type goer” might be. Furthermore, since the x3 place has been occupied by the linked sumti, the le zarci following the selbri falls into the nonexistent x4 place of cadzu. As a result, the whole example, though grammatical, is complete nonsense. (The bracketed Lojban words appear where a fluent Lojbanist would understand them to be implied.)
Finally, it is also possible to place na'e before a gu'e … gi logically connected tanru construction. The meaning of this usage has not yet been firmly established.
A bridi can have cmavo associated with it which specify the time, place, or mode of action. For example, in
the cmavo pu specifies that the action of the speaker going to the market takes place in the past. Tenses are explained in full detail in Chapter 10. Tense is semantically a property of the entire bridi; however, the usual syntax for tenses attaches them at the front of the selbri, as in Example 5.127. There are alternative ways of expressing tense information as well. Modals, which are explained in Chapter 9, behave in the same way as tenses.
Similarly, a bridi may have the particle na (of selma'o NA) attached to the beginning of the selbri to negate the bridi. A negated bridi expresses what is false without saying anything about what is true. Do not confuse this usage with the scalar negation of Section 5.12. For example:
| la | .djonz. | na | pamoi | cusku |
| That-named | Jones | (Not!) | is-the-first | speaker |
|
It is not true that Jones is the first speaker. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Jones isn't the first speaker. |
Jones may be the second speaker, or not a speaker at all; Example 5.128 doesn't say. There are other ways of expressing bridi negation as well; the topic is explained fully in Chapter 15.
Various combinations of tense and bridi negation cmavo are permitted. If both are expressed, either order is permissible with no change in meaning:
It is also possible to have more than one na, in which case pairs of na cmavo cancel out:
It is even possible, though somewhat pointless, to have multiple na cmavo and tense cmavo mixed together, subject to the limitation that two adjacent tense cmavo will be understood as a compound tense, and must fit the grammar of tenses as explained in Chapter 10.
| mi | na | pu | na | ca | klama | le | zarci |
| I | [not] | [past] | [not] | [present] | go-to | the | market |
|
It is not the case that in the past it was not the case that in the present I went to the market. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
I didn't not go to the market. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
I went to the market. |
Tense, modal, and negation cmavo can appear only at the beginning of the selbri. They cannot be embedded within it.
This section and Section 5.15 contain some example tanru classified into groups based on the type of relationship between the modifying seltau and the modified tertau. All the examples are paralleled by compounds actually observed in various natural languages. In the tables which follow, each group is preceded by a brief explanation of the relationship. The tables themselves contain a tanru, a literal gloss, the languages which exhibit a compound analogous to this tanru, and (for those tanru with no English parallel) a translation.
The tanru discussed in this section are asymmetrical tanru; that is, ones in which the order of the terms is fundamental to the meaning of the tanru. For example, junla dadysli, or “clock pendulum”, is the kind of pendulum used in a clock, whereas dadysli junla, or “pendulum clock”, is the kind of clock that employs a pendulum. Most tanru are asymmetrical in this sense. Symmetrical tanru are discussed in Section 5.15.
The tertau represents an action, and the seltau then represents the object of that action:
Table 5.1. Example tanru
The tertau represents a set, and the seltau the type of the elements contained in that set:
Table 5.3. Example tanru
Conversely: the tertau is an element, and the seltau represents a set in which that element is contained. Implicitly, the meaning of the tertau is restricted from its usual general meaning to the specific meaning appropriate for elements in the given set. Note the opposition between zdani lijgri in the previous group, and lijgri zdani in this one, which shows why this kind of tanru is called “asymmetrical”.
The seltau specifies an object and the tertau a component or detail of that object; the tanru as a whole refers to the detail, specifying that it is a detail of that whole and not some other.
Table 5.6. Example tanru
Conversely: the seltau specifies a characteristic or important detail of the object described by the tertau; objects described by the tanru as a whole are differentiated from other similar objects by this detail.
The tertau specifies a general class of object (a genus), and the seltau specifies a sub-class of that class (a species):
The tertau specifies an object of possession, and the seltau may specify the possessor (the possession may be intrinsic or otherwise). In English, these compounds have an explicit possessive element in them: “lion's mane”, “child's foot”, “noble's cow”.
Table 5.11. Example tanru
The tertau specifies a habitat, and the seltau specifies the inhabitant:
The tertau specifies a causative agent, and the seltau specifies the effect of that cause:
Conversely: the tertau specifies an effect, and the seltau specifies its cause.
The tertau specifies an instrument, and the seltau specifies the purpose of that instrument:
More vaguely: the tertau specifies an instrument, and the seltau specifies the object of the purpose for which that instrument is used:
The tertau specifies a product from some source, and the seltau specifies the source of the product:
Table 5.20. Example tanru
Conversely: the tertau specifies the source of a product, and the seltau specifies the product:
The tertau specifies an object, and the seltau specifies the material from which the object is made. This case is especially interesting, because the referent of the tertau may normally be made from just one kind of material, which is then overridden in the tanru.
Table 5.24. Example tanru
Note: the two senses of blaci kanla can be discriminated as:
The tertau specifies a typical object used to measure a quantity and the seltau specifies something measured. The tanru as a whole refers to a given quantity of the thing being measured. English does not have compounds of this form, as a rule.
The tertau specifies an object with certain implicit properties, and the seltau overrides one of those implicit properties:
The seltau specifies a whole, and the tertau specifies a part which normally is associated with a different whole. The tanru then refers to a part of the seltau which stands in the same relationship to the whole seltau as the tertau stands to its typical whole.
The tertau specifies the producer of a certain product, and the seltau specifies the product. In this way, the tanru as a whole distinguishes its referents from other referents of the tertau which do not produce the product.
The tertau specifies an object, and the seltau specifies another object which has a characteristic property. The tanru as a whole refers to those referents of the tertau which possess the property.
As a particular case (when the property is that of resemblance): the seltau specifies an object which the referent of the tanru resembles.
The seltau specifies a place, and the tertau an object characteristically located in or at that place.
Specifically: the tertau is a place where the seltau is sold or made available to the public.
The seltau specifies the locus of application of the tertau.
The tertau specifies an implement used in the activity denoted by the seltau.
The tertau specifies a protective device against the undesirable features of the referent of the seltau.
The tertau specifies a container characteristically used to hold the referent of the seltau.
Table 5.44. Example tanru
The seltau specifies the characteristic time of the event specified by the tertau.
The seltau specifies a source of energy for the referent of the tertau.
Finally, some tanru which don't fall into any of the above categories.
It is clear that “tooth” is being specified, and that “milk” and “eye” act as modifiers. However, the relationship between ladru and denci is something like “tooth which one has when one is drinking milk from one's mother”, a relationship certainly present nowhere except in this particular concept. As for kanla denci, the relationship is not only not present on the surface, it is hardly possible to formulate it at all.
This section deals with symmetrical tanru, where order is not important. Many of these tanru can be expressed with a logical or non-logical connective between the components.
The tanru may refer to things which are correctly specified by both tanru components. Some of these instances may also be seen as asymmetrical tanru where the seltau specifies a material. The connective je is appropriate:
Table 5.50. Example tanru
Table 5.51. Mini-Glossary
| cipnrstrigi |
fu'ivla for “owl” based on Linnean name |
| pacru'i |
evil-spirit |
| tolvri |
opposite-of-brave |
The tanru may refer to all things which are specified by either of the tanru components. The connective ja is appropriate:
Table 5.52. Example tanru
Table 5.53. Mini-Glossary
| nunji'a |
event-of-winning |
| nunterji'a |
event-of-losing |
| nuncti |
event-of-eating |
| nunpinxe |
event-of-drinking |
Alternatively, the tanru may refer to things which are specified by either of the tanru components or by some more inclusive class of things which the components typify:
The tanru components specify crucial or typical parts of the referent of the tanru as a whole:
The following examples show every possible grouping arrangement of melbi cmalu nixli ckule using bo or ke … ke'e for grouping and je or je bo for logical connection. Most of these are definitely not plausible interpretations of the English phrase “pretty little girls' school”, especially those which describe something which is both a girl and a school.
Example 5.26, Example 5.27, Example 5.28, Example 5.29, and Example 5.36 are repeated here as Example 5.132, Example 5.140, Example 5.148, Example 5.156, and Example 5.164 respectively. The seven examples following each of these share the same grouping pattern, but differ in the presence or absence of je at each possible site. Some of the examples have more than one Lojban version. In that case, they differ only in grouping mechanism, and are always equivalent in meaning.
The logical connective je is associative: that is, “A and (B and C)” is the same as “(A and B) and C”. Therefore, some of the examples have the same meaning as others. In particular, Example 5.139, Example 5.147, Example 5.155, Example 5.163, and Example 5.171 all have the same meaning because all four brivla are logically connected and the grouping is simply irrelevant. Other equivalent forms are noted in the examples themselves. However, if je were replaced by naja or jo or most of the other logical connectives, the meanings would become distinct.
It must be emphasized that, because of the ambiguity of all tanru, the English translations are by no means definitive – they represent only one possible interpretation of the corresponding Lojban sentence.
| melbi | cmalu | nixli | ckule | |||
| ((pretty | type-of | little) | type-of | girl) | type-of | school |
|
school for girls who are beautifully small |
| melbi | je | cmalu | nixli | ckule | ||
| ((pretty | and | little) | type-of | girl) | type-of | school |
|
school for girls who are beautiful and small |
| melbi | bo | cmalu | je | nixli | ckule | |
| ((pretty | type-of | little) | and | girl) | type-of | school |
|
school for girls and for beautifully small things |
| ke | melbi | cmalu | nixli | ke'e | je | ckule | ||
| (( | pretty | type-of | little) | type-of | girl | ) | and | school |
|
thing which is a school and a beautifully small girl |
| melbi | je | cmalu | je | nixli | ckule | |
| ((pretty | and | little) | and | girl) | type-of | school |
|
school for things which are beautiful, small, and girls |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Note: same as Example 5.152 |
| melbi | bo | cmalu | je | nixli | je | ckule |
| ((pretty | type-of | little) | and | girl) | and | school |
|
thing which is beautifully small, a school, and a girl |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Note: same as Example 5.145 |
| ke | melbi | je | cmalu | nixli | ke'e | je | ckule | |
| (( | pretty | and | little) | type-of | girl | ) | and | school |
|
thing which is a school and a girl who is both beautiful and small |
| melbi | je | cmalu | je | nixli | je | ckule |
| ((pretty | and | little) | and | girl) | and | school |
|
thing which is beautiful, small, a girl, and a school |
| melbi | cmalu | nixli | bo | ckule | ||
| (pretty | type-of | little) | type-of | (girl | type-of | school) |
|
girls' school which is beautifully small |
| melbi | je | cmalu | nixli | bo | ckule | |
| (pretty | and | little) | type-of | (girl | type-of | school) |
|
girls' school which is beautiful and small |
| melbi | cmalu | nixli | je | ckule | ||
| (pretty | type-of | little) | type-of | (girl | and | school) |
|
something which is a girl and a school which is beautifully small |
| melbi | bo | cmalu | je | nixli | bo | ckule |
| (pretty | type-of | little) | and | (girl | type-of | school) |
|
something which is beautifully small and a girls' school |
| melbi | je | cmalu | nixli | je | ckule | |
| (pretty | and | little) | type-of | (girl | and | school) |
|
a pretty and little type of thing which is both a girl and a school |
| melbi | bo | cmalu | je | nixli | jebo | ckule |
| (pretty | type-of | little) | and | (girl | and | school) |
|
thing which is beautifully small, a school, and a girl |
Note: same as Example 5.137
| melbi | jebo | cmalu | je | nixli | bo | ckule |
| (pretty | and | little) | and | (girl | type-of | school) |
|
thing which is beautiful and small and a girl's school |
Note: same as Example 5.161
| melbi | jebo | cmalu | je | nixli | jebo | ckule |
| (pretty | and | little) | and | (girl | and | school) |
|
thing which is beautiful, small, a girl, and a school |
| melbi | cmalu | bo | nixli | ckule | ||
| (pretty | type-of | (little | type-of | girl)) | type-of | school |
|
school for beautiful girls who are small |
| melbi | cmalu | je | nixli | ckule | ||
| (pretty | type-of | (little | and | girl)) | type-of | school |
|
school for beautiful things which are small and are girls |
| melbi | je | cmalu | bo | nixli | ckule | |
| (pretty | and | (little | type-of | girl)) | type-of | school |
|
school for things which are beautiful and are small girls |
| ke | melbi | cmalu | bo | nixli | ke'e | je | ckule | |
| melbi | bo | cmalu | bo | nixli | je | ckule | ||
| ( | pretty | type-of | (little | type-of | girl | )) | and | school |
|
thing which is a school and a small girl who is beautiful |
| melbi | je | cmalu | jebo | nixli | ckule | |
| (pretty | and | (little | and | girl)) | type-of | school |
|
school for things which are beautiful, small, and girls |
Note: same as Example 5.136
| melbi | je | cmalu | bo | nixli | je | ckule |
| (pretty | and | (little | type-of | girl)) | and | school |
|
thing which is beautiful, a small girl, and a school |
Note: same as Example 5.169
| ke | melbi | cmalu | je | nixli | ke'e | je | ckule | |
| ( | pretty | type-of | (little | and | girl | )) | and | school |
|
thing which is beautifully small, a beautiful girl, and a school |
| melbi | je | cmalu | jebo | nixli | je | ckule |
| (pretty | and | (little | and | girl)) | and | school |
|
thing which is beautiful, small, a girl, and a school |
| melbi | cmalu | bo | nixli | bo | ckule | |||
| melbi | ke | cmalu | ke | nixli | ckule | [ke'e] | [ke'e] | |
| pretty | type-of | (little | type-of | (girl | type-of | school | ) | ) |
|
small school for girls which is beautiful |
| melbi | ke | cmalu | nixli | je | ckule | [ke'e] | |
| pretty | type-of | (little | type-of | (girl | and | school | )) |
|
small thing, both a girl and a school, which is beautiful |
| melbi | cmalu | je | nixli | bo | ckule | |
| pretty | type-of | (little | and | (girl | type-of | school)) |
|
thing which is beautifully small and a girls' school that is beautiful |
| melbi | je | cmalu | bo | nixli | bo | ckule | |||
| melbi | je | ke | cmalu | nixli | bo | ckule | [ke'e] | ||
| melbi | je | ke | cmalu | ke | nixli | ckule | [ke'e] | [ke'e] | |
| pretty | and | ( | little | type-of | (girl | type-of | school | ) | ) |
|
thing which is beautiful and a small type of girls' school |
| melbi | cmalu | je | nixli | jebo | ckule | |||
| melbi | cmalu | je | ke | nixli | je | ckule | [ke'e] | |
| pretty | type-of | (little | and | ( | girl | and | school | )) |
|
thing which is beautifully small, a beautiful girl, and a beautiful school |
Note: same as Example 5.168
| melbi | je | cmalu | jebo | nixli | bo | ckule | ||
| melbi | je | ke | cmalu | je | nixli | bo | ckule | [ke'e] |
| pretty | and | ( | little | and | (girl | type-of | school | )) |
|
thing which is beautiful, small and a girls' school |
Note: same as Example 5.146
| melbi | je | ke | cmalu | nixli | je | ckule | [ke'e] | |
| pretty | and | ( | little | type-of | (girl | and | school | )) |
|
beautiful thing which is a small girl and a small school |
| melbi | jebo | cmalu | jebo | nixli | jebo | ckule |
| pretty | and | (little | and | (girl | and | school)) |
|
thing which is beautiful, small, a girl, and a school |
| melbi | ke | cmalu | nixli | ckule | [ke'e] | ||
| pretty | type-of | ((little | type-of | girl) | type-of | school | ) |
|
beautiful school for small girls |
| melbi | ke | cmalu | je | nixli | ckule | [ke'e] | |
| pretty | type-of | ((little | and | girl) | type-of | school |
|
beautiful school for things which are small and are girls |
| melbi | ke | cmalu | bo | nixli | je | ckule | [ke'e] |
| pretty | type-of | ((little | type-of | girl) | and | school | ) |
|
beautiful thing which is a small girl and a school |
| melbi | je | ke | cmalu | nixli | ckule | [ke'e] | ||
| pretty | and | (( | little | type-of | girl) | type-of | school | ) |
|
thing which is beautiful and a school for small girls |
| melbi | cmalu | je | nixli | je | ckule | |
| pretty | type-of | ((little | and | girl) | and | school) |
|
thing which is beautifully small, a beautiful girl, and a beautiful school |
Note: same as Example 5.160
| melbi | je | ke | cmalu | bo | nixli | je | ckule | [ke'e] |
| pretty | and | (( | little | type-of | girl) | and | school | ) |
|
thing which is beautiful, a small girl and a school |
Note: same as Example 5.153
| melbi | je | ke | cmalu | je | nixli | ckule | [ke'e] | |
| pretty | and | (( | little | and | girl) | type-of | school | ) |
|
thing which is beautiful and is a small school and a girls' school |
| melbi | je | ke | cmalu | je | nixli | je | ckule | [ke'e] |
| pretty | and | (( | little | and | girl) | and | school | ) |
|
thing which is beautiful, small, a girl, and a school |

If you understand anything about Lojban, you know what a sumti is by now, right? An argument, one of those things that fills the places of simple Lojban sentences like:
In Example 6.1 , mi and le zarci are the sumti. It is easy to see that these two sumti are not of the same kind: mi is a pro-sumti (the Lojban analogue of a pronoun) referring to the speaker, whereas le zarci is a description which refers to something described as being a market.
There are five kinds of simple sumti provided by Lojban:
Here are a few examples of each kind of sumti:
| e'osai | ko | sarji | la | .lojban. |
| [request] [!] | You [imperative] | support | that-named | Lojban. |
|
Please support Lojban! |
Example 6.2 exhibits ko , a pro-sumti; and la .lojban. , a name.
| mi | cusku | lu | e'osai | li'u | le | tcidu |
| I | express | [quote] | [request] [!] | [unquote] | to-the | reader. |
|
I express “Please!” to the reader. |
Example 6.3 exhibits mi , a pro-sumti; lu e'osai li'u , a quotation; and le tcidu , a description.
Example 6.4 exhibits ti , a pro-sumti; and li ci , a number.
Most of this chapter is about descriptions, as they have the most complicated syntax and usage. Some attention is also given to names, which are closely interwoven with descriptions. Pro-sumti, numbers, and quotations are described in more detail in Chapter 7 , Chapter 18 , and Chapter 19 respectively, so this chapter only gives summaries of their forms and uses. See Section 6.13 through Section 6.15 for these summaries.
The following cmavo are discussed in this section:
|
le |
LE |
the, the one(s) described as |
|
lo |
LE |
some, some of those which really are |
|
la |
LA |
the one(s) named |
|
ku |
KU |
elidable terminator for LE, LA |
The syntax of descriptions is fairly complex, and not all of it can be explained within the confines of this chapter: relative clauses, in particular, are discussed in Chapter 8. However, most descriptions have just two components: a descriptor belonging to selma'o LE or LA, and a selbri. (The difference between selma'o LE and selma'o LA is not important until Section 6.12.) Furthermore, the selbri is often just a single brivla. Here is an elementary example:
The long gloss for le is of course far too long to use most of the time, and in fact le is quite close in meaning to English “the”. It has particular implications, however, which “the” does not have.
The general purpose of all descriptors is to create a sumti which might occur in the x1 place of the selbri belonging to the description. Thus le zarci conveys something which might be found in the x1 place of zarci , namely a market.
The specific purpose of le is twofold. First, it indicates that the speaker has one or more specific markets in mind (whether or not the listener knows which ones they are). Second, it also indicates that the speaker is merely describing the things he or she has in mind as markets, without being committed to the truth of that description.
| le | zarci | cu | barda |
| One-or-more-specific-things-which-I-describe-as | “markets” | is/are-big. |
|
The market is big. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
The markets are big. |
Note that English-speakers must state whether a reference to markets is to just one ( “the market”) or to more than one ( “the markets”). Lojban requires no such forced choice, so both colloquial translations of Example 6.6 are valid. Only the context can specify which is meant. (This rule does not mean that Lojban has no way of specifying the number of markets in such a case: that mechanism is explained in Section 6.7.)
Now consider the following strange-looking example:
| le | mlatu | cu | gerku |
| One-or-more-specific-things-which-I-describe-as | “cats” | is/are-dogs. |
|
The cat is a dog. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
The cats are dogs. |
Example 6.7 is not self-contradictory in Lojban, because le mlatu merely means something or other which, for my present purposes, I choose to describe as a cat, whether or not it really is a cat. A plausible instance would be: some animal we had assumed to be a cat at a distance turned out to be actually a dog on closer observation. Example 6.7 is what I would say to point out my observation to you.
In all descriptions with le , the listener is presumed to either know what I have in mind or else not to be concerned at present (perhaps I will give more identifying details later). In particular, I might be pointing at the supposed cat or cats: Example 6.7 would then be perfectly intelligible, since le mlatu merely clarifies that I am pointing at the supposed cat, not at a landscape, or a nose, which happens to lie in the same direction.
The second descriptor dealt with in this section is lo. Unlike le , lo is nonspecific:
Again, there are two colloquial English translations. The effect of using lo in Example 6.8 is to refer generally to one or more markets, without being specific about which. Unlike le zarci , lo zarci must refer to something which actually is a market (that is, which can appear in the x1 place of a truthful bridi whose selbri is zarci). Thus
must be false in Lojban, given that there are no objects in the real world which are both cats and dogs. Pointing at some specific cats or dogs would not make Example 6.9 true, because those specific individuals are no more both-cat-and-dog than any others. In general, lo refers to whatever individuals meet its description.
The last descriptor of this section is la , which indicates that the selbri which follows it has been dissociated from its normal meaning and is being used as a name. Like le descriptions, la descriptions are implicitly restricted to those I have in mind. (Do not confuse this use of la with its use before regular Lojbanized names, which is discussed in Section 6.12.) For example:
In Example 6.10 , la cribe refers to someone whose naming predicate is cribe , i.e. “Bear”. In English, most names don't mean anything, or at least not anything obvious. The name “Frank” coincides with the English word “frank” , meaning “honest” , and so one way of translating “Frank ate some cheese” into Lojban would be:
English-speakers typically would not do this, as we tend to be more attached to the sound of our names than their meaning, even if the meaning (etymological or current) is known. Speakers of other languages may feel differently. (In point of fact, “Frank” originally meant “the free one” rather than “the honest one”.)
It is important to note the differences between Example 6.10 and the following:
| le | cribe | pu | finti | le | lisri |
| One-or-more-specific-things-which-I-describe-as | bears | [past] | creates | the | story. |
|
The bear(s) wrote the story. |
| lo | cribe | pu | finti | le | lisri |
| One-or-more-of-the-things-which-really | are-bears | [past] | creates | the | story. |
|
A bear wrote the story. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Some bears wrote the story. |
Example 6.12 is about a specific bear or bearlike thing(s), or thing(s) which the speaker (perhaps whimsically or metaphorically) describes as a bear (or more than one); Example 6.13 is about one or more of the really existing, objectively defined bears. In either case, though, each of them must have contributed to the writing of the story, if more than one bear (or “bear”) is meant.
(The notion of a “really existing, objectively defined bear” raises certain difficulties. Is a panda bear a “real bear” ? How about a teddy bear? In general, the answer is “yes”. Lojban gismu are defined as broadly as possible, allowing tanru and lujvo to narrow down the definition. There probably are no necessary and sufficient conditions for defining what is and what is not a bear that can be pinned down with complete precision: the real world is fuzzy. In borderline cases, le may communicate better than lo.)
So while Example 6.10 could easily be true (there is a real writer named “Greg Bear”), and Example 6.12 could be true if the speaker is sufficiently peculiar in what he or she describes as a bear, Example 6.13 is certainly false.
Similarly, compare the following two examples, which are analogous to Example 6.12 and Example 6.13 respectively:
| le | remna | pu | finti | le | lisri |
| Those-described-as | a-human | [past] | writes | that-described-as | a-story. |
|
The human being(s) wrote the story. |
| lo | remna | pu | finti | le | lisri |
| That-which-really-is | a-human | [past] | writes | that-described-as | a-story. |
|
A human being wrote the story. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Some human beings wrote the story. |
Example 6.14 says who the author of the story is: one or more particular human beings that the speaker has in mind. If the topic of conversation is the story, then Example 6.14 identifies the author as someone who can be pointed out or who has been previously mentioned; whereas if the topic is a person, then le remna is in effect a shorthand reference to that person. Example 6.15 merely says that the author is human.
The elidable terminator for all descriptions is ku. It can almost always be omitted with no danger of ambiguity. The main exceptions are in certain uses of relative clauses, which are discussed in Section 8.6 , and in the case of a description immediately preceding the selbri. In this latter case, using an explicit cu before the selbri makes the ku unnecessary. There are also a few other uses of ku : in the compound negator naku (discussed in Chapter 16) and to terminate place-structure, tense, and modal tags that do not have associated sumti (discussed in Chapter 9 and Chapter 10).
The following cmavo are discussed in this section:
|
lei |
LE |
the mass I describe as |
|
loi |
LE |
part of the mass of those which really are |
|
lai |
LA |
the mass of those named |
All Lojban sumti are classified by whether they refer to one of three types of objects, known as “individuals” , “masses” , and “sets”. The term “individual” is misleading when used to refer to more than one object, but no less-confusing term has as yet been found. All the descriptions in Section 6.1 and Section 6.2 refer to individuals, whether one or more than one. Consider the following example:
| le | prenu | cu | bevri | le | pipno |
| One-or-more-of-those-I-describe-as | persons | carry | the | piano. |
|
The person(s) carry the piano. |
(Of course the second le should really get the same translation as the first, but I am putting the focus of this discussion on the first le , the one preceding prenu. I will assume that there is only one piano under discussion.)
Suppose the context of Example 6.16 is such that you can determine that I am talking about three persons. What am I claiming? I am claiming that each of the three persons carried the piano. This claim can be true if the persons carried the piano one at a time, or in turns, or in a variety of other ways. But in order for Example 6.16 to be true, I must be willing to assert that person 1 carried the piano, and that person 2 carried the piano, and that person 3 carried the piano.
But suppose I am not willing to claim that. For in fact pianos are heavy, and very few persons can carry a piano all by themselves. The most likely factual situation is that person 1 carried one end of the piano, and person 2 the other end, while person 3 either held up the middle or else supervised the whole operation without actually lifting anything. The correct way of expressing such a situation in Lojban is:
| lei | prenu | cu | bevri | le | pipno |
| The-mass-of-one-or-more-of-those-I-describe-as | persons | carry | the | piano. |
|
The person(s) carry the piano. |
Here the same three persons are treated not as individuals, but as a so-called “mass entity” , or just “mass”. A mass has the properties of each individual which composes it, and may have other properties of its own as well. This can lead to apparent contradictions. Thus suppose in the piano-moving example above that person 1 has fair skin, whereas person 2 has dark skin. Then it is correct to say that the person-mass has both fair skin and dark skin. Using the mass descriptor lei signals that ordinary logical reasoning is not applicable: contradictions can be maintained, and all sorts of other peculiarities may exist. However, we can safely say that a mass inherits only the component properties that are relevant to it; it would be ludicrous to say that a mass of two persons is of molecular dimensions, simply because some of the parts (namely, the molecules) of the persons are that small.
The descriptors loi and lai are analogous to lo and la respectively, but refer to masses either by property ( loi) or by name ( lai). A classic example of loi use is:
| loi | cinfo | cu | xabju | le | fi'ortu'a |
| Part-of-the-mass-of-those-which-really | are-lions | dwell-in | the | African-land. |
|
The lion dwells in Africa. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Lions dwell in Africa. |
The difference between lei and loi is that lei cinfo refers to a mass of specific individuals which the speaker calls lions, whereas loi cinfo refers to some part of the mass of all those individuals which actually are lions. The restriction to “some part of the mass” allows statements like Example 6.18 to be true even though some lions do not dwell in Africa – they live in various zoos around the world. On the other hand, Example 6.18 doesn't actually say that most lions live in Africa: equally true is
| loi | glipre |
| Part-of-the-mass-of-those-which-really | are-English-persons |
| cu | xabju | le | fi'ortu'a |
| dwell-in | the | African-land. |
|
The English dwell in Africa. |
since there is at least one English person living there. Section 6.4 explains another method of saying what is usually meant by “The lion lives in Africa” which does imply that living in Africa is normal, not exceptional, for lions.
Note that the Lojban mass articles are sometimes translated by English plurals (the most usual case), sometimes by English singulars (when the singular is used to express typicalness or abstraction), and sometimes by singulars with no article:
| loi | matne | cu | ranti |
| Part-of-the-mass-of-that-which-really-is | a-quantity-of-butter | is-soft. |
|
Butter is soft. |
Of course, some butter is hard (for example, if it is frozen butter), so the “part-of” implication of loi becomes once again useful. The reason this mechanism works is that the English words like “butter” , which are seen as already describing masses, are translated in Lojban by non-mass forms. The place structure of matne is “x1 is a quantity of butter from source x2” , so the single English word “butter” is translated as something like “a part of the mass formed from all the quantities of butter that exist”. (Note that the operation of forming a mass entity does not imply, in Lojban, that the components of the mass are necessarily close to one another or even related in any way other than conceptually. Masses are formed by the speaker's intention to form a mass, and can in principle contain anything.)
The mass name descriptor lai is used in circumstances where we wish to talk about a mass of things identified by a name which is common to all of them. It is not used to identify a mass by a single name peculiar to it. Thus the mass version of Example 6.9 ,
| lai | cribe | pu | finti | le | vi | cukta |
| The-mass-of-those-named | “bear” | [past] | creates | the | nearby | book. |
|
The Bears wrote this book. |
in a context where la cribe would be understood as plural, would mean that either Tom Bear or Fred Bear (to make up some names) might have written the book, or that Tom and Fred might have written it as collaborators. Using la instead of lai in Example 6.21 would give the implication that each of Tom and Fred, considered individually, had written it.
The following cmavo are discussed in this section:
|
le'i |
LE |
the set described as |
|
lo'i |
LE |
the set of those which really are |
|
la'i |
LA |
the set of those named |
Having said so much about masses, let us turn to sets. Sets are easier to understand than masses, but are more rarely used. Like a mass, a set is an abstract object formed from a number of individuals; however, the properties of a set are not derived from any of the properties of the individuals that compose it.
Sets have properties like cardinality (how many elements in the set), membership (the relationship between a set and its elements), and set inclusion (the relationship between two sets, one of which – the superset – contains all the elements of the other – the subset). The set descriptors le'i , lo'i and la'i correspond exactly to the mass descriptors lei , loi , and lai except that normally we talk of the whole of a set, not just part of it. Here are some examples contrasting lo , loi , and lo'i :
The mass of rats is small because at least one rat is small; the mass of rats is also large; the set of rats, though, is unquestionably large – it has billions of members. The mass of rats is also brown, since some of its components are; but it would be incorrect to call the set of rats brown – brown-ness is not the sort of property that sets possess.
Lojban speakers should generally think twice before employing the set descriptors. However, certain predicates have places that require set sumti to fill them. For example, the place structure of fadni is:
x1 is ordinary/common/typical/usual in property x2 among the members of set x3
Why is it necessary for the x3 place of fadni to be a set? Because it makes no sense for an individual to be typical of another individual: an individual is typical of a group. In order to make sure that the bridi containing fadni is about an entire group, its x3 place must be filled with a set:
| mi | fadni | zo'e | lo'i | lobypli |
| I | am-ordinary | in-property [unspecified] | among-the-set-of | Lojban-users. |
|
I am a typical Lojban user. |
Note that the x2 place has been omitted; I am not specifying in exactly which way I am typical – whether in language knowledge, or age, or interests, or something else. If lo'i were changed to lo in Example 6.25 , the meaning would be something like “I am typical of some Lojban user” , which is nonsense.
The following cmavo are discussed in this section:
|
lo'e |
LE |
the typical |
|
le'e |
LE |
the stereotypical |
As promised in Section 6.3 , Lojban has a method for discriminating between “the lion” who lives in Africa and “the Englishman” who, generally speaking, doesn't live in Africa even though some Englishmen do. The descriptor lo'e means “the typical” , as in
| lo'e | cinfo | cu | xabju | le | fi'ortu'a |
| The-typical | lion | dwells-in | the | African-land. |
|
The lion dwells in Africa. |
What is this “typical lion” ? Surely it is not any particular lion, because no lion has all of the “typical” characteristics, and (worse yet) some characteristics that all real lions have can't be viewed as typical. For example, all real lions are either male or female, but it would be bizarre to suppose that the typical lion is either one. So the typical lion has no particular sex, but does have a color (golden brown), a residence (Africa), a diet (game), and so on. Likewise we can say that
| lo'e | glipre | cu | xabju |
| The-typical | English-person | dwells-in |
| le | fi'ortu'a | na.e | le | gligugde |
| the | African-land | (Not!) and | the | English-country. |
|
The typical English person dwells not in Africa but in England. |
The relationship between lo'e cinfo and lo'i cinfo may be explained thus: the typical lion is an imaginary lion-abstraction which best exemplifies the members of the set of lions. There is a similar relationship between le'e and le'i :
| le'e | xelso | merko | cu | gusta | ponse |
| The-stereotypical | Greek-type-of | American | is-a-restaurant-type-of | owner. |
|
Lots of Greek-Americans own restaurants. |
Here we are concerned not with the actual set of Greek-Americans, but with the set of those the speaker has in mind, which is typified by one (real or imaginary) who owns a restaurant. The word “stereotypical” is often derogatory in English, but le'e need not be derogatory in Lojban: it simply suggests that the example is typical in the speaker's imagination rather than in some objectively agreed-upon way. Of course, different speakers may disagree about what the features of “the typical lion” are (some would include having a short intestine, whereas others would know nothing of lions' intestines), so the distinction between lo'e cinfo and le'e cinfo may be very fine.
Furthermore,
| le'e | skina | cu | se finti | ne'i | la | .xali,uyd. |
| The-stereotypical | movie | is-invented | in | that-named | Hollywood. |
is probably true to an American, but might be false (not the stereotype) to someone living in India or Russia.
Note that there is no naming equivalent of lo'e and le'e , because there is no need, as a rule, for a “typical George” or a “typical Smith”. People or things who share a common name do not, in general, have any other common attributes worth mentioning.
The following cmavo are discussed in this section:
|
ro |
PA |
all of/each of |
|
su'o |
PA |
at least (one of) |
Quantifiers tell us how many: in the case of quantifiers with sumti, how many things we are talking about. In Lojban, quantifiers are expressed by numbers and mathematical expressions: a large topic discussed in some detail in Chapter 18. For the purposes of this chapter, a simplified treatment will suffice. Our examples will employ either the simple Lojban numbers pa , re , ci , vo , and mu , meaning “one” , “two” , “three” , “four” , “five” respectively, or else one of four special quantifiers, two of which are discussed in this section and listed above. These four quantifiers are important because every Lojban sumti has either one or two of them implicitly present in it – which one or two depends on the particular kind of sumti. There is more explanation of implicit quantifiers later in this section. (The other two quantifiers, piro and pisu'o , are explained in Section 6.7.)
Every Lojban sumti may optionally be preceded by an explicit quantifier. The purpose of this quantifier is to specify how many of the things referred to by the sumti are being talked about. Here are some simple examples contrasting sumti with and without explicit quantifiers:
The difference between Example 6.30 and Example 6.31 is the presence of the explicit quantifier re in the latter example. Although re by itself means “two” , when used as a quantifier it means “two-of”. Out of the group of listeners (the number of which isn't stated), two (we are not told which ones) are asserted to be “walkers on the ice”. Implicitly, the others (if any) are not walkers on the ice. In Lojban, you cannot say “I own three shoes” if in fact you own four shoes. Numbers need never be specified, but if they are specified they must be correct.
(This rule does not mean that there is no way to specify a number which is vague. The sentence
is true if you own three shoes, or four, or indeed any larger number. More details on vague numbers appear in the discussion of mathematical expressions in Chapter 18.)
Now consider Example 6.30 again. How many of the listeners are claimed to walk on the ice? The answer turns out to be: all of them, however many that is. So Example 6.30 and Example 6.33 :
turn out to mean exactly the same thing. This is a safe strategy, because if one of my listeners doesn't turn out to be walking on the ice, I can safely claim that I didn't intend that person to be a listener! And in fact, all of the personal pro-sumti such as mi and mi'o and ko obey the same rule. We say that personal pro-sumti have a so-called “implicit quantifier” of ro (all). This just means that if no quantifier is given explicitly, the meaning is the same as if the implicit quantifier had been used.
Not all sumti have ro as the implicit quantifier, however. Consider the quotation in:
| mi | cusku | lu | do | cadzu | le | bisli | li'u |
| I | express | [quote] | you | walk-on | the | ice | [unquote]. |
|
I say, “You walk on the ice.” |
What is the implicit quantifier of the quotation lu do cadzu le bisli li'u ? Surely not ro. If ro were supplied explicitly, thus:
the meaning would be something like “I say every occurrence of the sentence 'You walk on the ice'”. Of course I don't say every occurrence of it, only some occurrences. One might suppose that Example 6.34 means that I express exactly one occurrence, but it is more Lojbanic to leave the number unspecified, as with other sumti. We can say definitely, however, that I say it at least once.
The Lojban cmavo meaning “at least” is su'o , and if no ordinary number follows, su'o means “at least once”. (See Example 6.32 for the use of su'o with an ordinary number). Therefore, the explicitly quantified version of Example 6.34 is
| mi | cusku | su'o | lu | do | cadzu | le | bisli | li'u |
| I | express | at-least-one-of | [quote] | you | walk-on | the | ice | [unquote]. |
|
I say one or more instances of “You walk on the ice”. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
I say “You walk on the ice”. |
If an explicit ordinary number such as re were to appear, it would have to convey an exact expression, so
means that I say the sentence exactly twice, neither more nor less.
The following cmavo are discussed in this section:
|
piro |
PA |
the whole of |
|
pisu'o |
PA |
a part of |
Like other sumti, descriptions can be quantified. When a quantifier appears before a description, it has the same meaning as one appearing before a non-description sumti: it specifies how many things, of all those referred to by the description, are being talked about in this particular bridi. Suppose that context tells us that le gerku refers to three dogs. Then we can say that exactly two of them are white as follows:
When discussing descriptions, this ordinary quantifier is called an “outer quantifier” , since it appears outside the description. But there is another possible location for a quantifier: between the descriptor and the selbri. This quantifier is called an “inner quantifier” , and its meaning is quite different: it tells the listener how many objects the description selbri characterizes.
For example, the context of Example 6.38 supposedly told us that le gerku referred to some three specific dogs. This assumption can be made certain with the use of an explicit inner quantifier:
(As explained in the discussion of Example 6.32 , simple numbers like those in Example 6.39 must be exact: it therefore follows that the third dog cannot be white.)
You may also specify an explicit inner quantifier and leave the outer quantifier implicit:
There are rules for each of the 11 descriptors specifying what the implicit values for the inner and outer quantifiers are. They are meant to provide sensible default values when context is absent, not necessarily to prescribe hard and fast rules. The following table lists the implicit values:
| le : | ro le su'o | all of the at-least-one described as |
| lo : | su'o lo ro | at least one of all of those which really are |
| la : | ro la su'o | all of the at least one named |
| lei : | pisu'o lei su'o | some part of the mass of the at-least-one described as |
| loi : | pisu'o loi ro | some part of the mass of all those that really are |
| lai : | pisu'o lai su'o | some part of the mass of the at-least-one named |
| le'i : | piro le'i su'o | the whole of the set of the at-least-one described as |
| lo'i : | piro lo'i ro | the whole of the set of all those that really are |
| la'i : | piro la'i su'o | the whole of the set of the at-least-one named |
| le'e : | ro le'e su'o | all the stereotypes of the at-least-one described as |
| lo'e : | su'o lo'e ro | at least one of the types of all those that really are |
When examined for the first time, this table looks dreadfully arbitrary. In fact, there are quite a few regularities in it. First of all, the la-series (that is, the descriptors la , lai , and la'i) and the le-series (that is, the descriptors le , lei , le'i , and le'e) always have corresponding implicit quantifiers, so we may subsume the la-series under the le-series for the rest of this discussion: “le-series cmavo” will refer to both the le-series proper and to the la-series.
The rule for the inner quantifier is very simple: the lo-series cmavo (namely, lo , loi , lo'i , and lo'e) all have an implicit inner quantifier of ro , whereas the le-series cmavo all have an implicit inner quantifier of su'o.
Why? Because lo-series descriptors always refer to all of the things which really fit into the x1 place of the selbri. They are not restricted by the speaker's intention. Descriptors of the le-series, however, are so restricted, and therefore talk about some number, definite or indefinite, of objects the speaker has in mind – but never less than one.
Understanding the implicit outer quantifier requires rules of greater subtlety. In the case of mass and set descriptors, a single rule suffices for each: reference to a mass is implicitly a reference to some part of the mass; reference to a set is implicitly a reference to the whole set. Masses and sets are inherently singular objects: it makes no sense to talk about two distinct masses with the same components, or two distinct sets with the same members. Therefore, the largest possible outer quantifier for either a set description or a mass description is piro , the whole of it.
(Pedantically, it is possible that the mass of water molecules composing an ice cube might be thought of as different from the same mass of water molecules in liquid form, in which case we might talk about re lei djacu , two masses of the water-bits I have in mind.)
Why “pi - ” ? It is the Lojban cmavo for the decimal point. Just as pimu means “.5” , and when used as a quantifier specifies a portion consisting of five tenths of a thing, piro means a portion consisting of the all-ness – the entirety – of a thing. Similarly, pisu'o specifies a portion consisting of at least one part of a thing, i.e. some of it.
Smaller quantifiers are possible for sets, and refer to subsets. Thus pimu le'i nanmu is a subset of the set of men I have in mind; we don't know precisely which elements make up this subset, but it must have half the size of the full set. This is the best way to say “half of the men” ; saying pimu le nanmu would give us a half-portion of one of them instead! Of course, the result of pimu le'i nanmu is still a set; if you need to refer to the individuals of the subset, you must say so (see lu'a in Section 6.10).
The case of outer quantifiers for individual descriptors (including le , lo , la , and the typical descriptors le'e and lo'e) is special. When we refer to specific individuals with le , we mean to refer to all of those we have in mind, so ro is appropriate as the implicit quantifier, just as it is appropriate for do. Reference to non-specific individuals with lo , however, is typically to only some of the objects which can be correctly described, and so su'o is the appropriate implicit quantifier, just as for quotations.
From the English-speaking point of view, the difference in structure between the following example using le :
| [ro] | le | ci | gerku | cu | blabi |
| [All-of] | those-described-as | three | dogs | are-white. |
|
The three dogs are white. |
and the corresponding form with lo :
looks very peculiar. Why is the number ci found as an inner quantifier in Example 6.41 and as an outer quantifier in Example 6.42 ? The number of dogs is the same in either case. The answer is that the ci in Example 6.41 is part of the specification: it tells us the actual number of dogs in the group that the speaker has in mind. In Example 6.42 , however, the dogs referred to by ... lo gerku are all the dogs that exist: the outer quantifier then restricts the number to three; which three, we cannot tell. The implicit quantifiers are chosen to avoid claiming too much or too little: in the case of le , the implicit outer quantifier ro says that each of the dogs in the restricted group is white; in the case of lo , the implicit inner quantifier simply says that three dogs, chosen from the group of all the dogs there are, are white.
Using exact numbers as inner quantifiers in lo-series descriptions is dangerous, because you are stating that exactly that many things exist which really fit the description. So examples like
are semantically anomalous; Example 6.43 claims that some dog (or dogs) is white, but also that there are just three dogs in the universe!
Nevertheless, inner quantifiers are permitted on lo descriptors for consistency's sake, and may occasionally be useful.
Note that the inner quantifier of le , even when exact, need not be truthful: le ci nanmu means “what I describe as three men” , not “three of what I describe as men”. This follows from the rule that what is described by a le description represents the speaker's viewpoint rather than the objective way things are.
By a quirk of Lojban syntax, it is possible to omit the descriptor lo , but never any other descriptor, from a description like that of Example 6.42 ; namely, one which has an explicit outer quantifier but no explicit inner quantifier. The following example:
is equivalent in meaning to Example 6.42. Even though the descriptor is not present, the elidable terminator ku may still be used. The name “indefinite description” for this syntactic form is historically based: of course, it is no more and no less indefinite than its counterpart with an explicit lo. Indefinite descriptions were introduced into the language in order to imitate the syntax of English and other natural languages.
Indefinite descriptions must fit this mold exactly: there is no way to make one which does not have an explicit outer quantifier (thus *gerku cu blabi is ungrammatical), or which has an explicit inner quantifier (thus *reboi ci gerku cu blabi is also ungrammatical – re ci gerku cu blabi is fine, but means “23 dogs are white”).
Note: Example 6.32 also contains an indefinite description, namely su'o ci cutci ; another version of that example using an explicit lo would be:
| mi | ponse | su'o | ci | lo | cutci |
| I | possess | at-least | three | things-which-really-are | shoes |
|
I own three (or more) shoes. |
As stated in Section 6.2 , most descriptions consist of just a descriptor and a selbri. (In this chapter, the selbri have always been single gismu, but of course any selbri, however complex, can be employed in a description. The syntax and semantics of selbri are explained in Chapter 5.) In the intervening sections, inner and outer quantifiers have been added to the syntax. Now it is time to discuss a description of a radically different kind: the sumti-based description.
A sumti-based description has a sumti where the selbri would normally be, and the inner quantifier is required – it cannot be implicit. An outer quantifier is permitted but not required.
A full theory of sumti-based descriptions has yet to be worked out. One common case, however, is well understood. Compare the following:
Example 6.46 simply specifies that of the group of listeners, size unknown, two are men. Example 6.47 , which has the sumti-based description le re do , says that of the two listeners, all (the implicit outer quantifier ro) are men. So in effect the inner quantifier re gives the number of individuals which the inner sumti do refers to.
Here is another group of examples:
In each case, le ci cribe restricts the bears (or alleged bears) being talked of to some group of three which the speaker has in mind. Example 6.48 says that two of them (which two is not stated) are brown. Example 6.49 says that a specific pair of them are brown. Example 6.50 says that of a specific pair chosen from the original three, one or the other of that pair is brown.
The following cmavo are discussed in this section:
|
la'e |
LAhE |
something referred to by |
|
lu'e |
LAhE |
a reference to |
|
tu'a |
LAhE |
an abstraction involving |
|
lu'a |
LAhE |
an individual/member/component of |
|
lu'i |
LAhE |
a set formed from |
|
lu'o |
LAhE |
a mass formed from |
|
vu'i |
LAhE |
a sequence formed from |
|
na'ebo |
NAhE+BO |
something other than |
|
to'ebo |
NAhE+BO |
the opposite of |
|
no'ebo |
NAhE+BO |
the neutral form of |
|
je'abo |
NAhE+BO |
that which indeed is |
|
lu'u |
LUhU |
elidable terminator for LAhE and NAhE+BO |
Well, that's quite a list of cmavo. What are they all about?
The above cmavo and compound cmavo are called the “sumti qualifiers”. All of them are either single cmavo of selma'o LAhE, or else compound cmavo involving a scalar negation cmavo of selma'o NAhE immediately followed by bo of selma'o BO. Syntactically, you can prefix a sumti qualifier to any sumti and produce another simple sumti. (You may need to add the elidable terminator lu'u to show where the qualified sumti ends.)
Semantically, sumti qualifiers represent short forms of certain common special cases. Suppose you want to say “I see 'The Red Pony'” , where “The Red Pony” is the title of a book. How about:
But Example 6.51 doesn't work: it says that you see a piece of text “The Red Pony”. That might be all right if you were looking at the cover of the book, where the words “The Red Pony” are presumably written. (More precisely, where the words le xunre cmaxirma are written – but we may suppose the book has been translated into Lojban.)
What you really want to say is:
| mi | viska | le | selsinxa |
| I | see | the | thing-represented-by |
| be | lu | le | xunre | cmaxirma | li'u |
| [quote] | the | red | small-horse | [unquote]. |
The x2 place of selsinxa (the x1 place of sinxa) is a sign or symbol, and the x1 place of selsinxa (the x2 place of sinxa) is the thing represented by the sign. Example 6.52 allows us to use a symbol (namely the title of a book) to represent the thing it is a symbol of (namely the book itself).
This operation turns out to be needed often enough that it's useful to be able to say:
| mi | viska | la'e | lu | le | xunre | cmaxirma | li'u | [lu'u] |
| I | see | the-referent-of | [quote] | the | red | small-horse | [unquote] | -. |
So when la'e is prefixed to a sumti referring to a symbol, it produces a sumti referring to the referent of that symbol. (In computer jargon, la'e dereferences a pointer.)
By introducing a sumti qualifier, we correct a false sentence ( Example 6.51), which too closely resembles its literal English equivalent, into a true sentence ( Example 6.53), without having to change it overmuch; in particular, the structure remains the same. Most of the uses of sumti qualifiers are of this general kind.
The sumti qualifier lu'e provides the converse operation: it can be prefixed to a sumti referring to some thing to produce a sumti referring to a sign or symbol for the thing. For example,
| mi | pu | cusku | lu'e | le | vi | cukta |
| I | [past] | express | a-symbol-for | the | nearby | book. |
|
I said the title of this book. |
The equivalent form not using a sumti qualifier would be:
which is equivalent to Example 6.54 , but longer.
The other sumti qualifiers follow the same rules. The cmavo tu'a is used in forming abstractions, and is explained more fully in Section 11.10. The triplet lu'a , lu'i , and lu'o convert between individuals, sets, and masses; vu'i belongs to this group as well, but creates a sequence, which is similar to a set but has a definite order. (The set of John and Charles is the same as the set of Charles and John, but the sequences are different.) Here are some examples:
Example 6.56 might mean that I try to do something else involving the door; the form is deliberately vague.
Most of the following examples make use of the cmavo ri , belonging to selma'o KOhA. This cmavo means “the thing last mentioned” ; it is equivalent to repeating the immediately previous sumti (but in its original context). It is explained in more detail in Section 7.6.
| lo'i | ratcu | cu | barda |
| The-set-of | rats | is-large. |
| .iku'i | lu'a | ri | cmalu |
| But | some-members-of | it-last-mentioned | are-small. |
|
The set of rats is large, but some of its members are small. |
| lo | ratcu | cu | cmalu | .iku'i | lu'i | ri | barda |
| Some | rats | are-small. | But | the-set-of | them-last-mentioned | is-large. |
|
Some rats are small, but the set of rats is large. |
| mi | ce | do | girzu |
| I | in-a-set-with | you | are-a-set. |
| .i | lu'o | ri | gunma |
| The-mass-of | it-last-mentioned | is-a-mass. | |
| .i | vu'i | ri | porsi |
| The-sequence-of | it-last-mentioned | is-a-sequence |
|
The set of you and me is a set. The mass of you and me is a mass. The sequence of you and me is a sequence. |
(Yes, I know these examples are a bit silly. This set was introduced for completeness, and practical examples are as yet hard to come by.)
Finally, the four sumti qualifiers formed from a cmavo of NAhE and bo are all concerned with negation, which is discussed in detail in Chapter 15. Here are a few examples of negation sumti qualifiers:
This compound, na'ebo , is the most common of the four negation sumti qualifiers. The others usually only make sense in the context of repeating, with modifications, something already referred to:
| mi | nelci | loi | glare | cidja |
| I | like | part-of-the-mass-of | hot-type-of | food. |
| .ije | do | nelci | to'ebo | ri |
| And | you | like | the-opposite-of | the-last-mentioned. |
| .ije | la | .djein. | nelci | no'ebo | ra |
| And | that-named | Jane | likes | the-neutral-value-of | something-mentioned. |
|
I like hot food, and you like cold food, and Jane likes lukewarm food. |
(In Example 6.61 , the sumti ra refers to some previously mentioned sumti other than that referred to by ri. We cannot use ri here, because it would signify la .djein. , that being the most recent sumti available to ri. See more detailed explanations in Section 7.6.)
Vocative phrases are not sumti, but are explained in this chapter because their syntax is very similar to that of sumti. Grammatically, a vocative phrase is one of the so-called “free modifiers” of Lojban, along with subscripts, parentheses, and various other constructs explained in Chapter 19. They can be placed after many, but not all, constructions of the grammar: in general, after any elidable terminator (which, however, must not then be elided!), at the beginnings and ends of sentences, and in many other places.
The purpose of a vocative phrase is to indicate who is being addressed, or to indicate to that person that he or she ought to be listening. A vocative phrase begins with a cmavo of selma'o COI or DOI, all of which are explained in more detail in Section 13.14. Sometimes that is all there is to the phrase:
In these cases, the person being addressed is obvious from the context. However, a vocative word (more precisely, one or more cmavo of COI, possibly followed by doi , or else just doi by itself) can be followed by one of several kinds of phrases, all of which are intended to indicate the addressee. The most common case is a cmevla (name-word):
Using doi instead is like just saying someone's name to attract his or her attention:
In place of a cmevla, a description may appear, lacking its descriptor, which is understood to be le :
The listener need not really be a xunre pastu nixli , as long as she understands herself correctly from the description. (Actually, only a bare selbri can appear; explicit quantifiers are forbidden in this form of vocative, so the implicit quantifiers su'o le ro are in effect.)
Finally, a complete sumti may be used, the most general case.
Example 6.66 is thus the same as:
and Example 6.65 is the same as:
Finally, the elidable terminator for vocative phrases is do'u (of selma'o DOhU), which is rarely needed except when a simple vocative word is being placed somewhere within a bridi. It may also be required when a vocative is placed between a sumti and its relative clause, or when there are a sequence of so-called “free modifiers” (vocatives, subscripts, utterance ordinals – see Chapter 18 – metalinguistic comments – see Section 19.12 – or reciprocals – see Chapter 19) which must be properly separated.
The meaning of a vocative phrase that is within a sentence is not affected by its position in the sentence: thus Example 6.70 and Example 6.71 mean the same thing:
As usual for this chapter, the full syntax of vocative phrases has not been explained: relative clauses, discussed in Chapter 8 , make for more possibilities.
Names have been used freely as sumti throughout this chapter without too much explanation. The time for the explanation has now come.
First of all, there are two different kinds of things usually called “names” when talking about Lojban. The naming predicates of Section 6.2 are just ordinary predicates which are being used in a special sense. In addition, though, there is a class of Lojban words which are used only to name things: these can be recognized by the fact that they end in a consonant and are surrounded by pauses. Some examples:
Names of this kind have two basic uses in Lojban: when used in a vocative phrase (see Section 6.11) they indicate who the listener is or should be. When used with a descriptor of selma'o LA, namely la , lai , or la'i , they form sumti which refer to the persons or things known by the name.
| lai | .djonz. | klama | le | zarci |
| The-mass-of-those-named | Jones | goes-to | the | store. |
|
The Joneses go to the store. |
In Example 6.73 , the significance is that all the persons (perhaps only one) I mean to refer to by the name .djonz. are going to the store. In Example 6.74 , the Joneses are massified, and only some part of them needs to be going. Of course, by .djonz. I can mean whomever I want: that person need not use the name .djonz. at all.
The sumti in Example 6.73 and Example 6.74 operate exactly like the similar uses of la and lai in Example 6.10 and Example 6.21 respectively. The only difference is that these descriptors are followed by Lojban name-words (i.e. cmevla). And in fact, the only difference between descriptors of selma'o LA (these three) and of selma'o LE (all the other descriptors) is that the former can be followed by name-words, whereas the latter cannot.
Unless some other rule prevents it (such as the rule that zo is always followed by a single word, which is quoted), multiple name-words may appear wherever one name-word is permitted, each with its terminating pause:
| doi | .djan. .pol. .djonz. | le | bloti | cu | klama | fi la | .niuport. .niuz. |
| O | John Paul Jones | the | boat | goes | from-that-named | Newport News. |
|
John Paul Jones, the boat comes (to somewhere) from Newport News. |
A name-word may not contain any consonant combination that is illegal in Lojban words generally: the “impermissible consonant clusters” of Lojban morphology (explained in Section 3.6). Thus .djeimz. is not a valid version of “James” (because mz is invalid): djeimyz will suffice.
Names may be borrowed from other languages or created arbitrarily. Another common practice is to use one or more rafsi, arranged to end with a consonant, to form a name: thus the rafsi loj- for logji (logical) and ban- for bangu (language) unite to form the name of this language:
When borrowing names from another language which end in a vowel, or when turning a Lojban brivla (all of which end in vowels) into a cmevla, the vowel may be removed or an arbitrary consonant added. It is common (but not required) to use the consonants s or n when borrowing vowel-final names from English; speakers of other languages may wish to use other consonant endings.
The implicit quantifier for name sumti of the form la followed by a cmevla (name-word) is su'o , just as for la followed by a selbri.
The Lojban pro-sumti are the cmavo of selma'o KOhA. They fall into several classes: personal, definable, quantificational, reflexive, back-counting, indefinite, demonstrative, metalinguistic, relative, question. More details are given in Chapter 7 ; this section mostly duplicates information found there, but adds material on the implicit quantifier of each pro-sumti.
The following examples illustrate each of the classes. Unless otherwise noted below, the implicit quantification for pro-sumti is ro (all). In the case of pro-sumti which refer to other sumti, the ro signifies “all of those referred to by the other sumti” : thus it is possible to restrict, but not to extend, the quantification of the other sumti.
Personal pro-sumti ( mi , do , mi'o , mi'a , ma'a , do'o , ko) refer to the speaker or the listener or both, with or without third parties:
The personal pro-sumti may be interpreted in context as either representing individuals or masses, so the implicit quantifier may be pisu'o rather than ro : in particular, mi'o , mi'a , ma'a , and do'o specifically represent mass combinations of the individuals (you and I, I and others, you and I and others, you and others) that make them up.
Definable pro-sumti ( ko'a , ko'e , ko'i , ko'o , ko'u , fo'a , fo'e , fo'i , fo'o , fo'u) refer to whatever the speaker has explicitly made them refer to. This reference is accomplished with goi (of selma'o GOI), which means “defined-as”.
| le | cribe | goi | ko'a | cu | xekri | .i | ko'a | citka | le | smacu |
| The | bear | defined-as | it-1 | is-black. | It-1 | eats | the | mouse. |
Quantificational pro-sumti ( da , de , di) are used as variables in bridi involving predicate logic:
| ro | da | poi | prenu |
| All | somethings-1 | which | are-persons |
| cu | prami | pa | de | poi | finpe |
| love | one | something-2 | which | is-a-fish. |
|
All persons love a fish (each his/her own). |
(This is not the same as “All persons love a certain fish” ; the difference between the two is one of quantifier order.) The implicit quantification rules for quantificational pro-sumti are particular to them, and are discussed in detail in Chapter 16. Roughly speaking, the quantifier is su'o (at least one) when the pro-sumti is first used, and ro (all) thereafter.
Reflexive pro-sumti ( vo'a , vo'e , vo'i , vo'o , vo'u) refer to the same referents as sumti filling other places in the same bridi, with the effect that the same thing is referred to twice:
Back-counting pro-sumti ( ri , ra , ru) refer to the referents of previous sumti counted backwards from the pro-sumti:
| mi | klama | la | .frankfurt. | ri |
| I | go-to | that-named | Frankfurt | from-the-referent-of-the-last-sumti |
|
I go from Frankfurt to Frankfurt (by some unstated route). |
Indefinite pro-sumti ( zo'e , zu'i , zi'o) refer to something which is unspecified:
| mi | klama | la | .frankfurt. |
| I | go-to | that-named | Frankfurt |
| zo'e | zo'e | zo'e |
| from-unspecified | via-unspecified | by-means-unspecified. |
The implicit quantifier for indefinite pro-sumti is, well, indefinite. It might be ro (all) or su'o (at least one) or conceivably even no (none), though no would require a very odd context indeed.
Demonstrative pro-sumti ( ti , ta , tu) refer to things pointed at by the speaker, or when pointing is not possible, to things near or far from the speaker:
| ko | muvgau |
| You [imperative] | move |
| ti | ta | tu |
| this-thing | from-that-nearby-place | to-that-further-away-place. |
|
Move this from there to over there! |
Metalinguistic pro-sumti ( di'u , de'u , da'u , di'e , de'e , da'e , dei , do'i) refer to spoken or written utterances, either preceding, following, or the same as the current utterance.
| li | re | su'i | re | du | li | vo |
| The-number | two | plus | two | equals | the-number | four. |
| .i | la'e | di'u | jetnu |
| The-referent-of | the-previous-utterance | is-true. |
The implicit quantifier for metalinguistic pro-sumti is su'o (at least one), because they are considered analogous to lo descriptions: they refer to things which really are previous, current, or following utterances.
The relative pro-sumti ( ke'a) is used within relative clauses (see Chapter 8 for a discussion of relative clauses) to refer to whatever sumti the relative clause is attached to.
| mi | viska | le | mlatu | ku | poi | zo'e |
| I | see | the | cat(s) | such-that | something-unspecified |
| zbasu | ke'a | loi | slasi |
| makes | it/them-(the-cats) | from-a-mass-of | plastic. |
|
I see the cat(s) made of plastic. |
The question pro-sumti ( ma) is used to ask questions which request the listener to supply a sumti which will make the question into a truth:
The implicit quantifier for the question pro-sumti is su'o (at least one), because the listener is only being asked to supply a single answer, not all correct answers.
In addition, sequences of lerfu words (of selma'o BY and related selma'o) can also be used as definable pro-sumti.
There are four kinds of quotation in Lojban: text quotation, words quotation, single-word quotation, non-Lojban quotation. More information is provided in Chapter 19.
Text quotations are preceded by lu and followed by li'u , and are an essential part of the surrounding text: they must be grammatical Lojban texts.
Words quotations are quotations of one or more Lojban words. The words need not mean anything, but they must be morphologically valid so that the end of the quotation can be discerned.
Note that the translation of Example 6.88 does not translate the Lojban words, because they are not presumed to have any meaning (in fact, they are ungrammatical).
Single-word quotation quotes a single Lojban word. Compound cmavo are not allowed.
Non-Lojban quotation can quote anything, Lojban or not, even non-speech such as drum talk, whistle words, music, or belching. A Lojban word which does not appear within the quotation is used before and after it to set it off from the surrounding Lojban text.
The implicit quantifier for all types of quotation is su'o (at least one), because quotations are analogous to lo descriptions: they refer to things which actually are words or sequences of words.
The sumti which refer to numbers consist of the cmavo li (of selma'o LI) followed by an arbitrary Lojban mekso, or mathematical expression. This can be anything from a simple number up to the most complicated combination of numbers, variables, operators, and so on. Much more information on numbers is given in Chapter 18. Here are a few examples of increasing complexity:
| li | .abu | bi'epi'i | xy. | bi'ete'a | re | su'i | by. | bi'epi'i | xy. | su'i | cy. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| the-number | a | times | x | to-power | 2 | plus | b | times | x | plus | c | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
ax
2
+ bx + c
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
An alternative to li is me'o , also of selma'o LI. Number expressions beginning with me'o refer to the actual expression, rather than its value. Thus Example 6.91 and Example 6.92 above have the same meaning, the number four, whereas
and
refer to different pieces of text.
The implicit quantifier for numbers and mathematical expressions is su'o , because these sumti are analogous to lo descriptions: they refer to things which actually are numbers or pieces of text. In the case of numbers (with li), this is a distinction without a difference, as there is only one number which is 4; but there are many texts “4” , as many as there are documents in which that numeral appears.
Speakers of Lojban, like speakers of other languages, require mechanisms of abbreviation. If every time we referred to something, we had to express a complete description of it, life would be too short to say what we have to say. In English, we have words called “pronouns” which allow us to replace nouns or noun phrases with shorter terms. An English with no pronouns might look something like this:
Speakers of Lojban, like speakers of other languages, require mechanisms of abbreviation. If every time speakers of Lojban referred to a thing to which speakers of Lojban refer, speakers of Lojban had to express a complete description of what speakers of Lojban referred to, life would be too short to say what speakers of Lojban have to say.
Speakers of this kind of English would get mightily sick of talking. Furthermore, there are uses of pronouns in English which are independent of abbreviation. There is all the difference in the world between:
and
Example 7.3 does not imply that the two sticks are necessarily the same, whereas Example 7.2 requires that they are.
In Lojban, we have sumti rather than nouns, so our equivalent of pronouns are called by the hybrid term “pro-sumti”. A purely Lojban term would be sumti cmavo: all of the pro-sumti are cmavo belonging to selma'o KOhA. In exactly the same way, Lojban has a group of cmavo (belonging to selma'o GOhA) which serve as selbri or full bridi. These may be called “pro-bridi” or bridi cmavo. This chapter explains the uses of all the members of selma'o KOhA and GOhA. They fall into a number of groups, known as series: thus, in selma'o KOhA, we have among others the mi-series, the ko'a-series, the da-series, and so on. In each section, a series of pro-sumti is explained, and if there is a corresponding series of pro-bridi, it is explained and contrasted. Many pro-sumti series don't have pro-bridi analogues, however.
A few technical terms: The term “referent” means the thing to which a pro-sumti (by extension, a pro-bridi) refers. If the speaker of a sentence is James, then the referent of the word “I” is James. On the other hand, the term “antecedent” refers to a piece of language which a pro-sumti (or pro-bridi) implicitly repeats. In
the antecedent of “himself” is “John”; not the person, but a piece of text (a name, in this case). John, the person, would be the referent of “himself”. Not all pro-sumti or pro-bridi have antecedents, but all of them have referents.
The following cmavo are discussed in this section:
|
mi |
KOhA |
mi-series |
I, me |
|
do |
KOhA |
mi-series |
you |
|
mi'o |
KOhA |
mi-series |
you and I |
|
mi'a |
KOhA |
mi-series |
I and others, we but not you |
|
ma'a |
KOhA |
mi-series |
you and I and others |
|
do'o |
KOhA |
mi-series |
you and others |
|
ko |
KOhA |
mi-series |
you-imperative |
The mi-series of pro-sumti refer to the speaker, the listener, and others in various combinations. mi refers to the speaker and perhaps others for whom the speaker speaks; it may be a Lojbanic mass. do refers to the listener or listeners. Neither mi nor do is specific about the number of persons referred to; for example, the foreman of a jury may refer to the members of the jury as mi, since in speaking officially he represents all of them.
The referents of mi and do are usually obvious from the context, but may be assigned by the vocative words of selma'o COI, explained in Section 13.14. The vocative mi'e assigns mi, whereas all of the other vocatives assign do.
| mi'e | .djan. | doi | .frank. | mi | cusku | lu | mi | bajra | li'u | do | |
| I-am | John, | O | Frank, | I | express | [quote] | I | run | [unquote] | to | you |
|
I am John, Frank; I tell you “I run”. |
The cmavo mi'o, mi'a, ma'a, and do'o express various combinations of the speaker and/or the listener and/or other people:
All of these pro-sumti represent masses. For example, mi'o is the same as mi joi do, the mass of me and you considered jointly.
In English, “we” can mean mi or mi'o or mi'a or even ma'a, and English-speakers often suffer because they cannot easily distinguish mi'o from mi'a:
Does this include the listener or not? There's no way to be sure.
Finally, the cmavo ko is logically equivalent to do; its referent is the listener. However, its use alters an assertion about the listener into a command to the listener to make the assertion true:
becomes:
| ko | klama | le | zarci |
| You [imperative] | go-to | the | store. |
|
Make “you go to the store” true! |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Go to the store! |
In English, the subject of a command is omitted, but in Lojban, the word ko must be used. However, ko does not have to appear in the x1 place:
In Example 7.9, it is necessary to make the verb passive in English in order to convey the effect of ko in the x2 place. Indeed, ko does not even have to be a sumti of the main bridi:
| mi | viska | le | prenu | poi | prami | ko |
| I | see | the | person | that | loves | you-[imperative] |
|
Make “I see the person that loves you” true! |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Be such that the person who loves you is seen by me! |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Show me the person who loves you! |
As mentioned in Section 7.1, some pro-sumti series have corresponding pro-bridi series. However, there is no equivalent of the mi-series among pro-bridi, since a person isn't a relationship.
The following cmavo are discussed in this section:
|
ti |
KOhA |
ti-series |
this here, a nearby object |
|
ta |
KOhA |
ti-series |
that there, a medium-distant object |
|
tu |
KOhA |
ti-series |
that yonder, a far-distant object |
It is often useful to refer to things by pointing to them or by some related non-linguistic mechanism. In English, the words “this” and “that” serve this function among others: “this” refers to something pointed at that is near the speaker, and “that” refers to something further away. The Lojban pro-sumti of the ti-series serve the same functions, but more narrowly. The cmavo ti, ta, and tu provide only the pointing function of “this” and “that”; they are not used to refer to things that cannot be pointed at.
There are three pro-sumti of the ti-series rather than just two because it is often useful to distinguish between objects that are at more than two different distances. Japanese, among other languages, regularly does this. Until the 16th century, English did too; the pronoun “that” referred to something at a medium distance from the speaker, and the now-archaic pronoun “yon” to something far away.
In conversation, there is a special rule about ta and tu that is often helpful in interpreting them. When used contrastingly, ta refers to something that is near the listener, whereas tu refers to something far from both speaker and listener. This makes for a parallelism between ti and mi, and ta and do, that is convenient when pointing is not possible; for example, when talking by telephone. In written text, on the other hand, the meaning of the ti-series is inherently vague; is the writer to be taken as pointing to something, and if so, to what? In all cases, what counts as “near” and “far away” is relative to the current situation.
It is important to distinguish between the English pronoun “this” and the English adjective “this” as in “this boat”. The latter is not represented in Lojban by ti:
does not mean “this boat” but rather “this one's boat”, “the boat associated with this thing”, as explained in Section 8.7. A correct Lojban translation of Example 7.11 is
using a spatial tense before the selbri bloti to express that the boat is near the speaker. (Tenses are explained in full in Chapter 10.) Another correct translation would be:
There are no demonstrative pro-bridi to correspond to the ti-series: you can't point to a relationship.
The following cmavo are discussed in this section:
|
di'u |
KOhA |
di'u-series |
the previous utterance |
|
de'u |
KOhA |
di'u-series |
an earlier utterance |
|
da'u |
KOhA |
di'u-series |
a much earlier utterance |
|
di'e |
KOhA |
di'u-series |
the next utterance |
|
de'e |
KOhA |
di'u-series |
a later utterance |
|
da'e |
KOhA |
di'u-series |
a much later utterance |
|
dei |
KOhA |
di'u-series |
this very utterance |
|
do'i |
KOhA |
di'u-series |
some utterance |
The cmavo of the di'u-series enable us to talk about things that have been, are being, or will be said. In English, it is normal to use “this” and “that” for this (indeed, the immediately preceding “this” is an example of such a usage):
Here “that” does not refer to something that can be pointed to, but to the preceding sentence “You don't like cats”. In Lojban, therefore, Example 7.14 is rendered:
| do | na | nelci | loi | mlatu |
| You | (Not!) | like | the-mass-of | cats |
| .i | di'u | jitfa | jufra |
| . | The-previous-utterance | is-a-false | sentence. |
Using ta instead of di'u would cause the listener to look around to see what the speaker of the second sentence was physically pointing to.
As with ti, ta, and tu, the cmavo of the di'u-series come in threes: a close utterance, a medium-distance utterance, and a distant utterance, either in the past or in the future. It turned out to be impossible to use the i / a / u vowel convention of the demonstratives in Section 7.3 without causing collisions with other cmavo, and so the di'u-series has a unique i / e / a convention in the first vowel of the cmavo.
Most references in speech are to the past (what has already been said), so di'e, de'e, and da'e are not very useful when speaking. In writing, they are frequently handy:
Example 7.16 would typically be followed by a quotation. Note that although presumably the quotation is of something Simon has said in the past, the quotation utterance itself would appear after Example 7.16, and so di'e is appropriate.
The remaining two cmavo, dei and do'i, refer respectively to the very utterance that the speaker is uttering, and to some vague or unspecified utterance uttered by someone at some time:
| do'i | jetnu | jufra |
| Some-utterance | is-a-true | sentence. |
|
That's true (where “that” is not necessarily what was just said). |
The cmavo of the di'u-series have a meaning that is relative to the context. The referent of dei in the current utterance is the same as the referent of di'u in the next utterance. The term “utterance” is used rather than “sentence” because the amount of speech or written text referred to by any of these words is vague. Often, a single bridi is intended, but longer utterances may be thus referred to.
Note one very common construction with di'u and the cmavo la'e (of selma'o LAhE; see Section 6.10) which precedes a sumti and means “the thing referred to by (the sumti)”:
| mi | prami | la | .djein. | .i | mi | nelci | la'e | di'u |
| I | love | that-named | Jane. | And | I | like | the-referent-of | the-last-utterance. |
|
I love Jane, and I like that. |
The effect of la'e di'u in Example 7.19 is that the speaker likes, not the previous sentence, but rather the state of affairs referred to by the previous sentence, namely his loving Jane. This cmavo compound is often written as a single word: la'edi'u. It is important not to mix up di'u and la'edi'u, or the wrong meaning will generally result:
says that the speaker likes one of his own sentences.
There are no pro-bridi corresponding to the di'u-series.
The following cmavo and gismu are discussed in this section:
|
ko'a |
KOhA |
ko'a-series |
it-1 |
|
ko'e |
KOhA |
ko'a-series |
it-2 |
|
ko'i |
KOhA |
ko'a-series |
it-3 |
|
ko'o |
KOhA |
ko'a-series |
it-4 |
|
ko'u |
KOhA |
ko'a-series |
it-5 |
|
fo'a |
KOhA |
ko'a-series |
it-6 |
|
fo'e |
KOhA |
ko'a-series |
it-7 |
|
fo'i |
KOhA |
ko'a-series |
it-8 |
|
fo'o |
KOhA |
ko'a-series |
it-9 |
|
fo'u |
KOhA |
ko'a-series |
it-10 |
|
broda |
BRIVLA |
broda-series |
is-thing-1 |
|
brode |
BRIVLA |
broda-series |
is-thing-2 |
|
brodi |
BRIVLA |
broda-series |
is-thing-3 |
|
brodo |
BRIVLA |
broda-series |
is-thing-4 |
|
brodu |
BRIVLA |
broda-series |
is-thing-5 |
|
goi |
GOI |
pro-sumti assignment |
|
|
cei |
CEI |
pro-bridi assignment |
The discussion of personal pro-sumti in Section 7.2 may have seemed incomplete. In English, the personal pronouns include not only “I” and “you” but also “he”, “she”, “it”, and “they”. Lojban does have equivalents of this latter group: in fact, it has more of them than English does. However, they are organized and used very differently.
There are ten cmavo in the ko'a-series, and they may be assigned freely to any sumti whatsoever. The English word “he” can refer only to males, “she” only to females (and ships and a few other things), “it” only to inanimate things, and “they” only to plurals; the cmavo of the ko'a-series have no restrictions at all. Therefore, it is almost impossible to guess from the context what ko'a-series cmavo might refer to if they are just used freely:
The English gloss “it-1”, plus knowledge about the real world, would tend to make English-speakers believe that ko'a refers to the store; in other words, that its antecedent is le zarci. To a Lojbanist, however, la .alis. is just as likely an antecedent, in which case Example 7.21 means that Alice, not the store, is blue.
To avoid this pitfall, Lojban employs special syntax, using the cmavo goi:
| la | .alis. | klama | le | zarci |
| That-named | Alice | goes-to | the | store |
| .i | ko'a | goi | la | .alis. | cu | blanu |
| . | It-1, | also-known-as | that-named | Alice | , | is-blue. |
Syntactically, goi la .alis. is a relative phrase (relative phrases are explained in Chapter 8). Semantically, it says that ko'a and la .alis. refer to the same thing, and furthermore that this is true because ko'a is being defined as meaning la .alis.. It is equally correct to say:
| la | .alis. | klama | le | zarci |
| That-named | Alice | goes-to | the | store |
| .i | la | .alis. | goi | ko'a | cu | blanu |
| . | That-named | Alice, | also-known-as | it-1, | is-blue. |
in other words, goi is symmetrical. There is a terminator, ge'u (of selma'o GEhU), which is almost always elidable. The details are in Section 8.3.
The afterthought form of goi shown in Example 7.22 and Example 7.23 is probably most common in speech, where we do not know until part way through our utterance that we will want to refer to Alice again. In writing, though, ko'a may be assigned at the point where Alice is first mentioned. An example of this forethought form of goi is:
| la | .alis. | goi | ko'a | klama | le | zarci | .i | ko'a | cu | blanu |
| That-named | Alice, | also-known-as | it-1, | goes-to | the | store | . | It-1 | is-blue. |
Again, ko'a goi la .alis. would have been entirely acceptable in Example 7.24. This last form is reminiscent of legal jargon: “The party of the first part, hereafter known as Buyer, ...”.
Just as the ko'a-series of pro-sumti allows a substitute for a sumti which is long or complex, or which for some other reason we do not want to repeat, so the broda-series of pro-bridi allows a substitute for a selbri or even a whole bridi:
|
ti slasi je mlatu bo cidja lante gacri cei broda .i le crino broda cu barda .i le xunre broda cu cmalu |
|
These are plastic cat-food can covers or thingies. The green thingy is large. The red thingy is small. |
The pro-bridi broda has as its antecedent the selbri slasi je mlatu bo cidja lante gacri. The cmavo cei performs the role of goi in assigning broda to this long phrase, and broda can then be used just like any other brivla. (In fact, broda and its relatives actually are brivla: they are gismu in morphology, although they behave exactly like the members of selma'o GOhA. The reasons for using gismu rather than cmavo are buried in the Loglan Project's history.)
Note that pro-bridi are so called because, even though they have the grammar of selbri, their antecedents are whole bridi. In the following rather contrived example, the antecedent of brode is the whole bridi mi klama le zarci:
| mi | klama | cei | brode | le | zarci | .i | do | brode |
| I | go-to | (which-is | claim-2) | the | store | . | You | claim-2. |
|
I go to the store. You, too. |
In the second bridi, do brode means do klama le zarci, because brode carries the x2 sumti of mi klama le zarci along with it. It also potentially carries the x1 sumti as well, but the explicit x1 sumti do overrides the mi of the antecedent bridi. Similarly, any tense or negation that is present in the antecedent is also carried, and can be overridden by explicit tense or negation cmavo on the pro-bridi. These rules hold for all pro-bridi that have antecedents.
Another use of broda and its relatives, without assignment, is as “sample gismu”:
represents an abstract pattern, a certain kind of tanru. (Historically, this use was the original one.)
As is explained in Section 17.9, the words for Lojban letters, belonging to selma'o BY and certain related selma'o, are also usable as assignable pro-sumti. The main difference between letter pro-sumti and ko'a-series pro-sumti is that, in the absence of an explicit assignment, letters are taken to refer to the most recent name or description sumti beginning with the same letter (excluding the article):
The Lojban word gerku begins with g, so the antecedent of gy., the cmavo for the letter g, must be le gerku. In the English translation, we use the same principle to refer to the dog as “D”. Of course, in case of ambiguity, goi can be used to make an explicit assignment.
Furthermore, goi can even be used to assign a name:
| le | ninmu | goi | la | .sam. | cu | klama | le | zarci |
| The | woman | also-known-as | that-named | Sam | goes-to | the | store. |
|
The woman, whom I'll call Sam, goes to the store. |
This usage does not imply that the woman's name is Sam, or even that the speaker usually calls the woman “Sam”. “Sam” is simply a name chosen, as if at random, for use in the current context only.
The following cmavo are discussed in this section:
|
ri |
KOhA |
ri-series |
(repeats last sumti) |
|
ra |
KOhA |
ri-series |
(repeats previous sumti) |
|
ru |
KOhA |
ri-series |
(repeats long-ago sumti) |
|
go'i |
GOhA |
go'i-series |
(repeats last bridi) |
|
go'a |
GOhA |
go'i-series |
(repeats previous bridi) |
|
go'u |
GOhA |
go'i-series |
(repeats long-ago bridi) |
|
go'e |
GOhA |
go'i-series |
(repeats last-but-one bridi) |
|
go'o |
GOhA |
go'i-series |
(repeats future bridi) |
|
nei |
GOhA |
go'i-series |
(repeats current bridi) |
|
no'a |
GOhA |
go'i-series |
(repeats outer bridi) |
|
ra'o |
RAhO |
pro-cmavo update |
The term “anaphora” literally means “repetition”, but is used in linguistics to refer to pronouns whose significance is the repetition of earlier words, namely their antecedents. Lojban provides three pro-sumti anaphora, ri, ra, and ru; and three corresponding pro-bridi anaphora, go'i, go'a, and go'u. These cmavo reveal the same vowel pattern as the ti-series, but the “distances” referred to are not physical distances, but distances from the anaphoric cmavo to its antecedent.
The cmavo ri is the simplest of these; it has the same referent as the last complete sumti appearing before the ri:
| la | .alis. | sipna | ne'i | le | ri | kumfa | |
| That-named | Alice | sleeps | in | the | of- | [repeat-last-sumti] | room. |
|
Alice sleeps in her room. |
The ri in Example 7.30 is equivalent to repeating the last sumti, which is la .alis., so Example 7.30 is equivalent to:
| la | .alis. | sipna | ne'i | le | la | .alis. | kumfa | |
| That-named | Alice | sleeps | in | the | of- | that-named | Alice | room. |
|
Alice sleeps in Alice's room. |
Note that ri does not repeat le ri kumfa, because that sumti is not yet complete when ri appears. This prevents ri from getting entangled in paradoxes of self-reference. (There are plenty of other ways to do that!) Note also that sumti within other sumti, as in quotations, abstractions, and the like, are counted in the order of their beginnings; thus a lower level sumti like la .alis. in Example 7.31 is considered to be more recent than a higher level sumti that contains it.
Certain sumti are ignored by ri; specifically, most of the other cmavo of KOhA, and the almost-grammatically-equivalent lerfu words of selma'o BY. It is simpler just to repeat these directly:
However, the cmavo of the ti-series can be picked up by ri, because you might have changed what you are pointing at, so repeating ti may not be effective. Likewise, ri itself (or rather its antecedent) can be repeated by a later ri; in fact, a string of ri cmavo with no other intervening sumti always all repeat the same sumti:
| la | .djan. | viska | le | tricu | .i |
| That-named | John | sees | the | tree. |
| ri | se jadni | le | ri | jimca | |
| [repeat-last] | is-adorned-by | the | of- | [repeat-last] | branch. |
|
John sees the tree. It is adorned by its branches. |
Here the second ri has as antecedent the first ri, which has as antecedent le tricu. All three refer to the same thing: a tree.
To refer to the next-to-last sumti, the third-from-last sumti, and so on, ri may be subscripted (subscripts are explained in Section 19.6):
| lo | smuci | .i | lo | forca | .i | la | .rik. | pilno | rixire |
| A | spoon. | A | fork. | That-named | Rick | uses | [repeat-next-to-last]. |
| .i | la | .alis. | pilno | riximu |
| That-named | Alice | uses | [repeat-fifth-from-last]. |
Here rixire, or “ri-sub-2”, skips la .rik. to reach lo forca. In the same way, riximu, or “ri-sub-5”, skips la .alis., rixire, la .rik., and lo forca to reach lo smuci. As can clearly be seen, this procedure is barely practicable in writing, and would break down totally in speech.
Therefore, the vaguer ra and ru are also provided. The cmavo ra repeats a recently used sumti, and ru one that was further back in the speech or text. The use of ra and ru forces the listener to guess at the referent, but makes life easier for the speaker. Can ra refer to the last sumti, like ri ? The answer is no if ri has also been used. If ri has not been used, then ra might be the last sumti. Likewise, if ra has been used, then any use of ru would repeat a sumti earlier than the one ra is repeating. A more reasonable version of Example 7.34, but one that depends more on context, is:
| lo | smuci | .i | lo | forca | .i | la | .rik. | pilno | ra |
| A | spoon. | A | fork. | That-named | Rick | uses | [some-previous-thing]. |
| .i | la | .alis. | pilno | ru |
| That-named | Alice | uses | [some-more-remote-thing]. |
In Example 7.35, the use of ra tells us that something other than la .rik. is the antecedent; lo forca is the nearest sumti, so it is probably the antecedent. Similarly, the antecedent of ru must be something even further back in the utterance than lo forca, and lo smuci is the obvious candidate.
The meaning of ri must be determined every time it is used. Since ra and ru are more vaguely defined, they may well retain the same meaning for a while, but the listener cannot count on this behavior. To make a permanent reference to something repeated by ri, ra, or ru, use goi and a ko'a-series cmavo:
| la | .alis. | klama | le | zarci |
| That-named | Alice | goes-to | the | store |
| .i | ri | goi | ko'a | blanu |
| . | It-last-mentioned | also-known-as | it-1 | is-blue. |
allows the store to be referred to henceforth as ko'a without ambiguity. Example 7.36 is equivalent to Example 7.21 and eliminates any possibility of ko'a being interpreted by the listener as referring to Alice.
The cmavo go'i, go'a, and go'u follow exactly the same rules as ri, ra, and ru, except that they are pro-bridi, and therefore repeat bridi, not sumti – specifically, main sentence bridi. Any bridi that are embedded within other bridi, such as relative clauses or abstractions, are not counted. Like the cmavo of the broda-series, the cmavo of the go'i-series copy all sumti with them. This makes go'i by itself convenient for answering a question affirmatively, or for repeating the last bridi, possibly with new sumti:
| xu | zo | .djan. | cmene | do | .i | go'i |
| [True-false?] | The-word | “John” | is-the-name-of | you? | [repeat last bridi]. |
|
Is John your name? Yes. |
| mi | klama | le | zarci | .i | do | go'i |
| I | go-to | the | store | . | You | [repeat last bridi]. |
|
I go to the store . You, too. |
Note that Example 7.38 means the same as Example 7.26, but without the bother of assigning an actual broda-series word to the first bridi. For long-term reference, use go'i cei broda or the like, analogously to ri goi ko'a in Example 7.36.
The remaining four cmavo of the go'i-series are provided for convenience or for achieving special effects. The cmavo go'e means the same as go'ixire: it repeats the last bridi but one. This is useful in conversation:
| A: | mi | ba | klama | le | zarci |
| A: | I | [future] | go-to | the | store. |
|
A: I am going to the store. |
| B: | mi | nelci | le | si'o | mi | go'i |
| B: | I | like | the | concept-of | I | [repeat-last-bridi]. |
|
B: I like the idea of my going. |
| A: | do | go'e |
| A: | You | [repeat-last-bridi-but-one]. |
|
A: You'll go, too. |
Here B's sentence repeats A's within an abstraction (explained in Chapter 11): le si'o mi go'i means le si'o mi klama le zarci. Why must B use the word mi explicitly to replace the x1 of mi klama le zarci, even though it looks like mi is replacing mi ? Because B's mi refers to B, whereas A's mi refers to A. If B said:
that would mean:
I like the idea of your going to the store.
The repetition signalled by go'i is not literally of words, but of concepts. Finally, A repeats her own sentence, but with the x1 changed to do, meaning B. Note that in Example 7.39, the tense ba (future time) is carried along by both go'i and go'e.
Descriptions based on go'i-series cmavo can be very useful for repeating specific sumti of previous bridi:
| le | xekri | mlatu | cu | klama | le | zarci | .i | le |
| The | black | cat | goes-to | the | store. | That-described-as-the-x1-place-of |
| go'i | cu | cadzu | le | bisli |
| [repeat-last-bridi] | walks-on | the | ice. |
|
The black cat goes to the store. It walks on the ice. |
Here the go'i repeats le xekri mlatu cu klama le zarci, and since le makes the x1 place into a description, and the x1 place of this bridi is le xekri mlatu, le go'i means le xekri mlatu.
The cmavo go'o, nei, and no'a have been little used so far. They repeat respectively some future bridi, the current bridi, and the bridi that encloses the current bridi (no'a, unlike the other members of the go'i- series, can repeat non-sentence bridi). Here are a few examples:
| mi | nupre | le | nu | mi | go'o |
| I | promise | the | event-of | I | [repeat-future-bridi]. |
| .i | ba | dunda | le | jdini | le | bersa | |
| [Future] | give | the | money | to | the | son |
| .i | ba | dunda | le | zdani | le | tixnu | |
| [Future] | give | the | house | to | the | daughter |
|
I promise to do the following: Give the money to my son. Give the house to my daughter. |
(Note: The Lojban does not contain an equivalent of the “my” in the colloquial English; it leaves the fact that it is the speaker's son and daughter that are referred to implicit. To make the fact explicit, use le bersa / tixnu be mi.)
For good examples of nei and no'a, we need nested bridi contexts:
| mi | se | pluka | le | nu | do | pensi | le | nu |
| I | am-pleased-by | the | event-of | (you | think-about | the | (event-of |
| nei | kei | pu | le | nu | do | zukte |
| [main-bridi] | ) | before | the | (event-of | your | acting). |
|
I am pleased that you thought about whether I would be pleased (about ...) before you acted. |
| mi | ba | klama | ca | le | nu | do | no'a |
| I | [future] | go | [present] | the | event-of | you | [repeats outer bridi] |
|
I will go when you do. |
Finally, ra'o is a cmavo that can be appended to any go'i-series cmavo, or indeed any cmavo of selma'o GOhA, to signal that pro-sumti or pro-bridi cmavo in the antecedent are to be repeated literally and reinterpreted in their new context. Normally, any pro-sumti used within the antecedent of the pro-bridi keep their meanings intact. In the presence of ra'o, however, their meanings must be reinterpreted with reference to the new environment. If someone says to you:
you might reply either:
or:
The ra'o forces the second mi from the original bridi to mean the new speaker rather than the former speaker. This means that mi nelci le si'o go'i ra'o would be an acceptable alternative to mi nelci le si'o mi go'i in B's statement in Example 7.39.
The anaphoric pro-sumti of this section can be used in quotations, but never refer to any of the supporting text outside the quotation, since speakers presumably do not know that they may be quoted by someone else.
However, a ri- series or go'a- series reference within a quotation can refer to something mentioned in an earlier quotation if the two quotations are closely related in time and context. This allows a quotation to be broken up by narrative material without interfering with the pro-sumti within it. Here's an example:
| la | .djan. | cusku | lu | mi | klama | le | zarci | li'u |
| That-named | John | says | [quote] | I | go-to | the | store | [unquote]. |
| .i | la | .alis. | cusku | lu | mi | go'i | li'u |
| That-named | Alice | says | [quote] | I | [repeat] | [unquote]. |
|
John says, “I am going to the store.” Alice says, “Me too.” |
Of course, there is no problem with narrative material referring to something within a quotation: people who quote, unlike people who are quoted, are aware of what they are doing.
The following cmavo are discussed in this section:
|
zo'e |
KOhA |
zo'e-series |
the obvious value |
|
zu'i |
KOhA |
zo'e-series |
the typical value |
|
zi'o |
KOhA |
zo'e-series |
the nonexistent value |
|
co'e |
GOhA |
co'e-series |
has the obvious relationship |
The cmavo of the zo'e-series represent indefinite, unspecified sumti. The cmavo zo'e represents an elliptical value for this sumti place; it is the optional spoken place holder when a sumti is skipped without being specified. Note that the elliptical value is not always the typical value. The properties of ellipsis lead to an elliptical sumti being defined as “whatever I want it to mean but haven't bothered to figure out, or figure out how to express”.
The cmavo zu'i, on the other hand, represents the typical value for this place of this bridi:
| mi | klama | le | bartu | be | le | zdani | |
| I | go-to | the | outside | of | the | house | from |
| le | nenri | be | le | zdani | zu'i | zu'i |
| the | inside | of | the | house | [by-typical-route] | [by-typical-means] |
In Example 7.49, the first zu'i probably means something like “by the door”, and the second zu'i probably means something like “on foot”, those being the typical route and means for leaving a house. On the other hand, if you are at the top of a high rise during a fire, neither zu'i is appropriate. It's also common to use zu'i in “by standard” places.
Finally, the cmavo zi'o represents a value which does not even exist. When a bridi fills one of its places with zi'o, what is really meant is that the selbri has a place which is irrelevant to the true relationship the speaker wishes to express. For example, the place structure of zbasu is:
actor x1 makes x2 from materials x3
Living things are made from cells.
This cannot be correctly expressed as:
| loi | jmive | cu | se zbasu | [zo'e] | fi | loi | selci |
| The-mass-of | living-things | is-made | [by-something] | from | the-mass-of | cells |
because the zo'e, expressed or understood, in Example 7.50 indicates that there is still a “maker” in this relationship. We do not generally suppose, however, that someone “makes” living things from cells. The best answer is probably to find a different selbri, one which does not imply a “maker”: however, an alternative strategy is to use zi'o to eliminate the maker place:
| loi | jmive | cu |
| The-mass-of | living-things |
| se zbasu | zi'o | loi | selci | |
| is-made | [without-maker] | from | the-mass-of | cells. |
Note: The use of zi'o to block up, as it were, one place of a selbri actually creates a new selbri with a different place structure. Consider the following examples:
| mi | zbasu | le | dinju | loi | mudri | |
| I | make | the | building | from | some-of-the-mass-of | wood. |
|
I make the building out of wood. |
| zi'o | zbasu | le | dinju | loi | mudri | |
| [without-maker] | makes | the | building | from | some-of-the-mass-of | wood. |
|
The building is made out of wood. |
| mi | zbasu | zi'o | loi | mudri | |
| I | make | [without-thing-made] | from | some-of-the-mass-of | wood. |
|
I build using wood. |
If Example 7.52 is true, then Example 7.53 through Example 7.55 must be true also. However, Example 7.51 does not correspond to any sentence with three regular (non- zi'o) sumti.
The pro-bridi co'e (which by itself constitutes the co'e-series of selma'o GOhA) represents the elliptical selbri. Lojban grammar does not allow the speaker to merely omit a selbri from a bridi, although any or all sumti may be freely omitted. Being vague about a relationship requires the use of co'e as a selbri place-holder:
| mi | troci | le | nu | mi | co'e | le | vorme |
| I | try | the | event-of | my | [doing-the-obvious-action] | to-the | door. |
|
I try the door. |
The English version means, and the Lojban version probably means, that I try to open the door, but the relationship of opening is not actually specified; the Lojbanic listener must guess it from context. Lojban, unlike English, makes it clear that there is an implicit action that is not being expressed.
The form of co'e was chosen to resemble zo'e; the cmavo do'e of selma'o BAI (see Section 9.6) also belongs to the same group of cmavo.
Note that do'i, of the di'u-series, is also a kind of indefinite pro-sumti: it is indefinite in referent, but is restricted to referring only to an utterance.
The following cmavo are discussed in this section:
|
vo'a |
KOhA |
vo'a-series |
x1 of this bridi |
|
vo'e |
KOhA |
vo'a-series |
x2 of this bridi |
|
vo'i |
KOhA |
vo'a-series |
x3 of this bridi |
|
vo'o |
KOhA |
vo'a-series |
x4 of this bridi |
|
vo'u |
KOhA |
vo'a-series |
x5 of this bridi |
|
soi |
SOI |
reciprocity |
|
|
se'u |
SEhU |
soi terminator |
The cmavo of the vo'a-series are pro-sumti anaphora, like those of the ri-series, but have a specific function. These cmavo refer to the other places of the same bridi; the five of them represent up to five places. The same vo'a-series cmavo mean different things in different bridi. Some examples:
To refer to places of neighboring bridi, constructions like le se go'i ku do the job: this refers to the 2nd place of the previous main bridi, as explained in Section 7.6.
The cmavo of the vo'a-series are also used with soi (of selma'o SOI) to precisely express reciprocity, which in English is imprecisely expressed with a discursive phrase like “vice versa”:
| mi | prami | do | soi | vo'a | vo'e |
| I | love | you | [reciprocity] | [x1 of this bridi] | [x2 of this bridi]. |
|
I love you and vice versa (swapping “I” and “you”). |
The significance of soi vo'a vo'e is that the bridi is still true even if the x1 (specified by vo'a) and the x2 (specified by vo'e) places are interchanged. If only a single sumti follows soi, then the sumti immediately preceding soi is understood to be one of those involved:
again involves the x1 and x2 places.
Of course, other places can be involved, and other sumti may be used in place of vo'a-series cmavo, provided those other sumti can be reasonably understood as referring to the same things mentioned in the bridi proper. Here are several examples that mean the same thing:
|
mi bajykla ti ta soi vo'e - |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
mi bajykla ti ta soi vo'e vo'i |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
soi vo'e vo'i mi bajykla ti ta |
|
I runningly-go to this from that and vice versa (to that from this). |
The elidable terminator for soi is se'u (selma'o SEhU), which is normally needed only if there is just one sumti after the soi, and the soi construction is not at the end of the bridi. Constructions using soi are free modifiers, and as such can go almost anywhere. Here is an example where se'u is required:
| mi | bajykla | ti | soi | vo'i | se'u | ta | |
| I | runningly-go-to | this | [reciprocity] | [x3 of this bridi] | from | that |
|
I runningly-go to this from that and vice versa. |
The following cmavo are discussed in this section:
|
ma |
KOhA |
sumti question |
|
mo |
GOhA |
bridi question |
Lojban questions are more fully explained in Section 19.5, but ma and mo are listed in this chapter for completeness. The cmavo ma asks for a sumti to make the bridi true:
The cmavo mo, on the other hand, asks for a selbri which makes the question bridi true. If the answer is a full bridi, then the arguments of the answer override the arguments in the question, in the same manner as the go'i-series cmavo. A simple example is:
Example 7.64 is a truly pregnant question that will have several meanings depending on context.
(One thing it probably does not mean is “Who are you?” in the sense “What is your name/identity?”, which is better expressed by:
or even
which uses the vocative doi to address someone, and simultaneously asks who the someone is.)
A further example of mo:
| lo | mo | prenu | cu | darxi | do | .i | barda | |
| A | [what selbri?] | type-of | person | hit | you? | A big thing. |
|
Which person hit you? The big one. |
When ma or mo is repeated, multiple questions are being asked simultaneously:
The following cmavo are discussed in this section:
|
ke'a |
KOhA |
relativized sumti |
This pro-sumti is used in relative clauses (explained in Chapter 8) to indicate how the sumti being relativized fits within the clause. For example:
| mi | catlu | lo | mlatu | poi | [zo'e] |
| I | see | a | cat | such-that | something-unspecified |
| zbasu | ke'a | lei | slasi | |
| makes | the-thing-being-relativized-[the-cat] | from | some-mass-of | plastic. |
|
I see a cat made of plastic. |
If ke'a were omitted from Example 7.69, it might be confused with:
| mi | catlu | lo | mlatu | poi |
| I | see | a | cat | such-that |
| [ke'a] | zbasu | lei | slasi |
| the-thing-being-relativized-[the-cat] | makes | a-mass-of | plastic |
|
I see a cat that makes plastic. |
The anaphora cmavo ri cannot be used in place of ke'a in Example 7.69 and Example 7.70, because the relativized sumti is not yet complete when the ke'a appears.
Note that ke'a is used only with relative clauses, and not with other embedded bridi such as abstract descriptions. In the case of relative clauses within relative clauses, ke'a may be subscripted to make the difference clear (see Section 8.10).
The following cmavo are discussed in this section:
|
ce'u |
KOhA |
abstraction focus |
The cmavo ce'u is used within abstraction bridi, particularly property abstractions introduced by the cmavo ka. Abstractions, including the uses of ce'u, are discussed in full in Chapter 11.
In brief: Every property abstraction specifies a property of one of the sumti in it; that sumti place is filled by using ce'u. This convention enables us to distinguish clearly between:
and
| le | ka | gleki | ce'u |
| the | property-of | (being-happy-about | X) |
|
the property of being that which someone is happy about |
The following cmavo are discussed in this section:
|
da |
KOhA |
da-series |
something-1 |
|
de |
KOhA |
da-series |
something-2 |
|
di |
KOhA |
da-series |
something-3 |
|
bu'a |
GOhA |
bu'a-series |
some-predicate-1 |
|
bu'e |
GOhA |
bu'a-series |
some-predicate-2 |
|
bu'i |
GOhA |
bu'a-series |
some-predicate-3 |
Bound variables belong to the predicate-logic part of Lojban, and are listed here for completeness only. Their semantics is explained in Chapter 16. It is worth mentioning that the Lojban translation of Example 7.2 is:
| la | .djan. | cu | lafmuvgau | da | poi |
| That-named | John | raised | something-1 | which |
| grana | ku'o | gi'e | desygau | da |
| is-a-stick | and | shake-did | something-1. |
|
John picked up a stick and shook it. |
The following cmavo are discussed in this section:
|
da'o |
DAhO |
cancel all pro-sumti/pro-bridi |
How long does a pro-sumti or pro-bridi remain stable? In other words, once we know the referent of a pro-sumti or pro-bridi, how long can we be sure that future uses of the same cmavo have the same referent? The answer to this question depends on which series the cmavo belongs to.
Personal pro-sumti are stable until there is a change of speaker or listener, possibly signaled by a vocative. Assignable pro-sumti and pro-bridi last indefinitely or until rebound with goi or cei. Bound variable pro-sumti and pro-bridi also generally last until re-bound; details are available in Section 16.14.
Utterance pro-sumti are stable only within the utterance in which they appear; similarly, reflexive pro-sumti are stable only within the bridi in which they appear; and ke'a is stable only within its relative clause. Anaphoric pro-sumti and pro-bridi are stable only within narrow limits depending on the rules for the particular cmavo.
Demonstrative pro-sumti, indefinite pro-sumti and pro-bridi, and sumti and bridi questions potentially change referents every time they are used.
However, there are ways to cancel all pro-sumti and pro-bridi, so that none of them have known referents. (Some, such as mi, will acquire the same referent as soon as they are used again after the cancellation.) The simplest way to cancel everything is with the cmavo da'o of selma'o DAhO, which is used solely for this purpose; it may appear anywhere, and has no effect on the grammar of texts containing it. One use of da'o is when entering a conversation, to indicate that one's pro-sumti assignments have nothing to do with any assignments already made by other participants in the conversation.
In addition, the cmavo ni'o and no'i of selma'o NIhO, which are used primarily to indicate shifts in topic, may also have the effect of canceling pro-sumti and pro-bridi assignments, or of reinstating ones formerly in effect. More explanations of NIhO can be found in Section 19.3.
The following cmavo is discussed in this section:
|
du |
GOhA |
identity |
The cmavo du has the place structure:
x1 is identical with x2, x3, ...
and appears in selma'o GOhA for reasons of convenience: it is not a pro-bridi. du serves as mathematical “=”, and outside mathematical contexts is used for defining or identifying. Mathematical examples may be found in Chapter 18.
and
is this defining nature. Example 7.74 presumes that the speaker is responding to a request for information about what ko'a refers to, or that the speaker in some way feels the need to define ko'a for later reference. A bridi with du is an identity sentence, somewhat metalinguistically saying that all attached sumti are representations for the same referent. There may be any number of sumti associated with du, and all are said to be identical.
Example 7.75, however, predicates; it is used to make a claim about the identity of ko'a, which presumably has been defined previously.
Note: du historically is derived from dunli, but dunli has a third place which du lacks: the standard of equality.
There exist rafsi allocated to a few cmavo of selma'o KOhA, but they are rarely used. (See Section 7.16 for a complete list.) The obvious way to use them is as internal sumti, filling in an appropriate place of the gismu or lujvo to which they are attached; as such, they usually stand as the first rafsi in their lujvo.
Thus donta'a, meaning “you-talk”, would be interpreted as tavla be do, and would have the place structure
since t2 (the addressee) is already known to be do.
On the other hand, the lujvo donma'o, literally “you-cmavo”, which means “a second person personal pronoun”, would be interpreted as cmavo be zo do, and have the place structure:
since both the c2 place (the grammatical class) and the c3 place (the meaning) are obvious from the context do.
An anticipated use of rafsi for cmavo in the fo'a series is to express lujvo which can't be expressed in a convenient rafsi form, because they are too long to express, or are formally inconvenient (fu'ivla, cmevla, and so forth). An example would be:
Finally, lujvo involving zi'o are also possible. The convention is to use the rafsi for zi'o as a prefix immediately followed by the rafsi for the number of the place to be deleted. Thus, if we consider a beverage (something drunk without considering who, if anyone, drinks it) as a se pinxe be zi'o, the lujvo corresponding to this is zilrelselpinxe (deleting the second place of se pinxe). Deleting the x1 place in this fashion would move all remaining places up by one. This would mean that zilpavypinxe has the same place structure as zilrelselpinxe, and lo zilpavypinxe, like lo zilrelselpinxe, refers to a beverage, and not to a non-existent drinker.
The pro-bridi co'e, du, and bu'a also have rafsi, which can be used just as if they were gismu. The resulting lujvo have (except for du- based lujvo) highly context-dependent meanings.
mi-series
|
mi |
I (rafsi: mib) |
|
do |
you (rafsi: don and doi) |
|
mi'o |
you and I |
|
mi'a |
I and others, we but not you |
|
ma'a |
you and I and others |
|
do'o |
you and others |
|
ko |
you-imperative |
ti-series
|
ti |
this here; something nearby (rafsi: tif) |
|
ta |
that there; something distant (rafsi: taz) |
|
tu |
that yonder; something far distant (rafsi: tuf) |
di'u-series
|
di'u |
the previous utterance |
|
de'u |
an earlier utterance |
|
da'u |
a much earlier utterance |
|
di'e |
the next utterance |
|
de'e |
a later utterance |
|
da'e |
a much later utterance |
|
dei |
this very utterance |
|
do'i |
some utterance |
ko'a-series
|
ko'a |
it-1; 1st assignable pro-sumti |
|
ko'e |
it-2; 2nd assignable pro-sumti |
|
ko'i |
it-3; 3rd assignable pro-sumti |
|
ko'o |
it-4; 4th assignable pro-sumti |
|
ko'u |
it-5; 5th assignable pro-sumti |
|
fo'a |
it-6; 6th assignable pro-sumti (rafsi: fo'a) |
|
fo'e |
it-7; 7th assignable pro-sumti (rafsi: fo'e) |
|
fo'i |
it-8; 8th assignable pro-sumti (rafsi: fo'i) |
|
fo'o |
it-9; 9th assignable pro-sumti |
|
fo'u |
it-10; 10th assignable pro-sumti |
ri-series
|
ri |
(repeats the last sumti) |
|
ra |
(repeats a previous sumti) |
|
ru |
(repeats a long-ago sumti) |
zo'e-series
|
zo'e |
the obvious value |
|
zu'i |
the typical value |
|
zi'o |
the nonexistent value (rafsi: zil) |
vo'a-series
|
vo'a |
x1 of this bridi |
|
vo'e |
x2 of this bridi |
|
vo'i |
x3 of this bridi |
|
vo'o |
x4 of this bridi |
|
vo'u |
x5 of this bridi |
da-series
|
da |
something-1 (rafsi: dav / dza) |
|
de |
something-2 |
|
di |
something-3 |
others:
|
ke'a |
relativized sumti |
|
ma |
sumti question |
|
ce'u |
abstraction focus |
broda-series (not GOhA):
|
broda |
is-1; 1st assignable pro-bridi |
|
brode |
is-2; 2nd assignable pro-bridi |
|
brodi |
is-3; 3rd assignable pro-bridi |
|
brodo |
is-4; 4th assignable pro-bridi |
|
brodu |
is-5; 5th assignable pro-bridi |
go'i-series
|
go'i |
(repeats the last bridi) |
|
go'a |
(repeats a previous bridi) |
|
go'u |
(repeats a long-ago bridi) |
|
go'e |
(repeats the last-but-one bridi) |
|
go'o |
(repeats a future bridi) |
|
nei |
(repeats the current bridi) |
|
no'a |
(repeats the next outer bridi) |
bu'a-series
|
bu'a |
some-predicate-1 (rafsi: bul) |
|
bu'e |
some-predicate-2 |
|
bu'i |
some-predicate-3 |
others:
|
co'e |
has the obvious relationship (rafsi: com / co'e) |
||
|
mo |
bridi question |
||
|
du |
identity: x1 is identical to x2, x3 ... |
dub |
du'o |

The following cmavo are discussed in this section:
|
poi |
NOI |
restrictive relative clause introducer |
|
ke'a |
KOhA |
relative pro-sumti |
|
ku'o |
KUhO |
relative clause terminator |
Let us think about the problem of communicating what it is that we are pointing at when we are pointing at something. In Lojban, we can refer to what we are pointing at by using the pro-sumti ti if it is nearby, or ta if it is somewhat further away, or tu if it is distant. (Pro-sumti are explained in full in Chapter 7.)
However, even with the assistance of a pointing finger, or pointing lips, or whatever may be appropriate in the local culture, it is often hard for a listener to tell just what is being pointed at. Suppose one is pointing at a person (in particular, in the direction of his or her face), and says:
What is the referent of ti ? Is it the person? Or perhaps it is the person's nose? Or even (for ti can be plural as well as singular, and mean “these ones” as well as “this one”) the pores on the person's nose?
To help solve this problem, Lojban uses a construction called a “relative clause”. Relative clauses are usually attached to the end of sumti, but there are other places where they can go as well, as explained later in this chapter. A relative clause begins with a word of selma'o NOI, and ends with the elidable terminator ku'o (of selma'o KUhO). As you might suppose, noi is a cmavo of selma'o NOI; however, first we will discuss the cmavo poi , which also belongs to selma'o NOI.
In between the poi and the ku'o appears a full bridi, with the same syntax as any other bridi. Anywhere within the bridi of a relative clause, the pro-sumti ke'a (of selma'o KOhA) may be used, and it stands for the sumti to which the relative clause is attached (called the “relativized sumti”). Here are some examples before we go any further:
| ti | poi | ke'a | prenu | ku'o | cu | barda |
| This-thing | such-that-( | IT | is-a-person | ) | is-large. |
|
This thing which is a person is big. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
This person is big. |
| ti | poi | ke'a | nazbi | ku'o | cu | barda |
| This-thing | such-that-( | IT | is-a-nose | ) | is-large. |
|
This thing which is a nose is big. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
This nose is big. |
| ti | poi | ke'a | nazbi | kapkevna | ku'o | cu | barda | |
| This-thing | such-that-( | IT | is-a-nose | type-of | skin-hole | ) | is-big. |
|
These things which are nose-pores are big. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
These nose-pores are big. |
In the literal translations throughout this chapter, the word “IT” , capitalized, is used to represent the cmavo ke'a. In each case, it serves to represent the sumti (in Example 8.2 through Example 8.4 , the cmavo ti) to which the relative clause is attached.
Of course, there is no reason why ke'a needs to appear in the x1 place of a relative clause bridi; it can appear in any place, or indeed even in a sub-bridi within the relative clause bridi. Here are two more examples:
| tu | poi | le | mlatu | pu | lacpu | ke'a | ku'o | cu | ratcu |
| That-distant-thing | such-that-( | the | cat | [past] | drags | IT | ) | is-a-rat. |
|
That thing which the cat dragged is a rat. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
What the cat dragged is a rat. |
| ta | poi | mi | djica | le | nu |
| That-thing | such-that-( | I | desire | the | event-of( |
| mi | ponse | ke'a | [kei] | ku'o | cu | bloti |
| I | own | IT | ) | ) | is-a-boat. |
|
That thing that I want to own is a boat. |
In Example 8.6 , ke'a appears in an abstraction clause (abstractions are explained in Chapter 11) within a relative clause.
Like any sumti, ke'a can be omitted. The usual presumption in that case is that it then falls into the x1 place:
almost certainly means the same thing as Example 8.3. However, ke'a can be omitted if it is clear to the listener that it belongs in some place other than x1:
is equivalent to Example 8.4.
As stated before, ku'o is an elidable terminator, and in fact it is almost always elidable. Throughout the rest of this chapter, ku'o will not be written in any of the examples unless it is absolutely required: thus, Example 8.2 can be written:
without any change in meaning. Note that poi is translated “which” rather than “such-that” when ke'a has been omitted from the x1 place of the relative clause bridi. The word “which” is used in English to introduce English relative clauses: other words that can be used are “who” and “that” , as in:
and
In Example 8.10 the relative clause is “who was going to the store” , and in Example 8.11 it is “that the school was located in”. Sometimes “who” , “which” , and “that” are used in literal translations in this chapter in order to make them read more smoothly.
The following cmavo is discussed in this section:
|
noi |
NOI |
incidental relative clause introducer |
There are two basic kinds of relative clauses: restrictive relative clauses introduced by poi , and incidental (sometimes called simply “non-restrictive”) relative clauses introduced by noi. The difference between restrictive and incidental relative clauses is that restrictive clauses provide information that is essential to identifying the referent of the sumti to which they are attached, whereas incidental relative clauses provide additional information which is helpful to the listener but is not essential for identifying the referent of the sumti. All of the examples in Section 8.1 are restrictive relative clauses: the information in the relative clause is essential to identification. (The title of this chapter, though, uses an incidental relative clause.)
Consider the following examples:
| le | gerku | noi | blanu | cu | barda |
| The | dog | incidentally-which | is-blue | is-large. |
|
The dog, which is blue, is large. |
In Example 8.12 , the information conveyed by poi blanu is essential to identifying the dog in question: it restricts the possible referents from dogs in general to dogs that are blue. This is why poi relative clauses are called restrictive. In Example 8.13 , on the other hand, the dog which is referred to has presumably already been identified clearly, and the relative clause noi blanu just provides additional information about it. (If in fact the dog hasn't been identified clearly, then the relative clause does not help identify it further.)
In English, the distinction between restrictive and incidental relative clauses is expressed in writing by surrounding incidental, but not restrictive, clauses with commas. These commas are functioning as parentheses, because incidental relative clauses are essentially parenthetical. This distinction in punctuation is represented in speech by a difference in tone of voice. In addition, English restrictive relative clauses can be introduced by “that” as well as “which” and “who” , whereas incidental relative clauses cannot begin with “that”. Lojban, however, always uses the cmavo poi and noi rather than punctuation or intonation to make the distinction.
Here are more examples of incidental relative clauses:
In this example, mi is already sufficiently restricted, and the additional information that I am a judge is being provided solely for the listener's edification.
| xu | do | viska | le | mi | karce | noi | blabi |
| [True?] | You | see | my | car | incidentally-which | is-white. |
|
Do you see my car, which is white? |
In Example 8.15 , the speaker is presumed to have only one car, and is providing incidental information that it is white. (Alternatively, he or she might have more than one car, since le karce can be plural, in which case the incidental information is that each of them is white.) Contrast Example 8.16 with a restrictive relative clause:
| xu | do | viska | le | mi | karce | poi | blabi |
| [True?] | You | see | my | car | which | is-white. |
|
Do you see my car that is white? |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Do you see my white car? |
Here the speaker probably has several cars, and is restricting the referent of the sumti le mi karce (and thereby the listener's attention) to the white one only. Example 8.16 means much the same as Example 8.17 , which does not use a relative clause:
So a restrictive relative clause attached to a description can often mean the same as a description involving a tanru. However, blabi karce , like all tanru, is somewhat vague: in principle, it might refer to a car which carries white things, or even express some more complicated concept involving whiteness and car-ness; the restrictive relative clause of Example 8.16 can only refer to a car which is white, not to any more complex or extended concept.
The following cmavo are discussed in this section:
|
pe |
GOI |
restrictive association |
|
po |
GOI |
restrictive possession |
|
po'e |
GOI |
restrictive intrinsic possession |
|
po'u |
GOI |
restrictive identification |
|
ne |
GOI |
incidental association |
|
no'u |
GOI |
incidental identification |
|
ge'u |
GEhU |
relative phrase terminator |
There are types of relative clauses (those which have a certain selbri) which are frequently wanted in Lojban, and can be expressed using a shortcut called a relative phrase. Relative phrases are introduced by cmavo of selma'o GOI, and consist of a GOI cmavo followed by a single sumti.
Here is an example of pe , plus an equivalent sentence using a relative clause:
In Example 8.18 and Example 8.19 , the link between the chair and the speaker is of the loosest kind.
Here is an example of po :
| le | stizu | poi | ke'a | se steci | srana | mi | cu | xunre |
| The | chair | such-that-( | IT | is-specifically | associated-with | me | ) | is-red. |
Example 8.20 and Example 8.21 contrast with Example 8.18 and Example 8.19 : the chair is more permanently connected with the speaker. A plausible (though not the only possible) contrast between Example 8.18 and Example 8.20 is that pe mi would be appropriate for a chair the speaker is currently sitting on (whether or not the speaker owned that chair), and po mi for a chair owned by the speaker (whether or not he or she was currently occupying it).
As a result, the relationship expressed between two sumti by po is usually called “possession” , although it does not necessarily imply ownership, legal or otherwise. The central concept is that of specificity ( steci in Lojban).
Here is an example of po'e , as well as another example of po :
| le | birka | poi | jinzi | ke | se steci |
| The | arm | which | is-intrinsically | ( | specifically |
| srana | mi | cu | spofu |
| associated-with) | me | is-broken. |
Example 8.22 and Example 8.23 on the one hand, and Example 8.24 on the other, illustrate the contrast between two types of possession called “intrinsic” and “extrinsic” , or sometimes “inalienable” and “alienable” , respectively. Something is intrinsically (or inalienably) possessed by someone if the possession is part of the possessor, and cannot be changed without changing the possessor. In the case of Example 8.22 , people are usually taken to intrinsically possess their arms: even if an arm is cut off, it remains the arm of that person. (If the arm is transplanted to another person, however, it becomes intrinsically possessed by the new user, though, so intrinsic possession is a matter of degree.)
By contrast, the bottle of Example 8.24 can be given away, or thrown away, or lost, or stolen, so it is possessed extrinsically (alienably). The exact line between intrinsic and extrinsic possession is culturally dependent. The U.S. Declaration of Independence speaks of the “inalienable rights” of men, but just what those rights are, and even whether the concept makes sense at all, varies from culture to culture.
Note that Example 8.22 can also be expressed without a relative clause:
reflecting the fact that the gismu birka has an x2 place representing the body to which the arm belongs. Many, but not all, cases of intrinsic possession can be thus covered without using po'e by placing the possessor into the appropriate place of the description selbri.
Here is an example of po'u :
The cmavo po'u does not represent possession at all, but rather identity. (Note that it means poi du and its form was chosen to suggest the relationship.)
In Example 8.26 , the use of po'u tells us that le gerku and le mi pendo represent the same thing. Consider the contrast between Example 8.26 and:
The facts of the case are the same, but the listener's knowledge about the situation may not be. In Example 8.26 , the listener is presumed not to understand which dog is meant by le gerku , so the speaker adds a relative phrase clarifying that it is the particular dog which is the speaker's friend.
Example 8.28 , however, assumes that the listener does not know which of the speaker's friends is referred to, and specifies that it is the friend that is the dog (which dog is taken to be obvious). Here is another example of the same contrast:
The principle that the possessor and the possessed may change places applies to all the GOI cmavo, and allows for the possibility of odd effects:
| le | kabri | pe | le | mi | pendo | cu | cmalu |
| The | cup | associated-with | my | friend | is-small. |
|
My friend's cup is small |
| le | mi | pendo | pe | le | kabri | cu | cmalu |
| My | friend | associated-with | the | cup | is-small. |
|
My friend, the one with the cup, is small. |
Example 8.31 is useful in a context which is about my friend, and states that his or her cup is small, whereas Example 8.32 is useful in a context that is primarily about a certain cup, and makes a claim about “my friend of the cup” , as opposed to some other friend of mine. Here the cup appears to “possess” the person! English can't even express this relationship with a possessive – “the cup's friend of mine” looks like nonsense – but Lojban has no trouble doing so.
Finally, the cmavo ne and no'u stand to pe and po'u , respectively, as noi does to poi- they provide incidental information:
| le | blabi | gerku | ne | mi | cu | batci | do |
| The | white | dog, | incidentally-associated-with | me | , | bites | you. |
|
The white dog, which is mine, bites you. |
In Example 8.33 , the white dog is already fully identified (after all, presumably the listener knows which dog bit him or her!). The fact that it is yours is merely incidental to the main bridi claim.
Distinguishing between po'u and no'u can be a little tricky. Consider a room with several men in it, one of whom is named Jim. If you don't know their names, I might say:
| le | nanmu | no'u | la | .djim. | cu | terpemci |
| The | man, | incidentally-who-is | that-named | Jim | , | is-a-poet. |
|
The man, Jim, is a poet. |
Here I am saying that one of the men is a poet, and incidentally telling you that he is Jim. But if you do know the names, then
is appropriate. Now I am using the fact that the man I am speaking of is Jim in order to pick out which man I mean.
It is worth mentioning that English sometimes over-specifies possession from the Lojban point of view (and the point of view of many other languages, including ones closely related to English). The idiomatic English sentence
seems strange to a French- or German-speaking person: whose pockets would he put his hands into? and even odder, whose hands would he put into his pockets? In Lojban, the sentence
is very natural. Of course, if the man is in fact putting his hands into another's pockets, or another's hands into his pockets, the fact can be specified.
Finally, the elidable terminator for GOI cmavo is ge'u of selma'o GEhU; it is almost never required. However, if a logical connective immediately follows a sumti modified by a relative phrase, then an explicit ge'u is needed to allow the connective to affect the relativized sumti rather than the sumti of the relative phrase. (What about the cmavo after which selma'o GOI is named? It is discussed in Section 7.5 , as it is not semantically akin to the other kinds of relative phrases, although the syntax is the same.)
|
zi'e |
ZIhE |
relative clause joiner |
Sometimes it is necessary or useful to attach more than one relative clause to a sumti. This is made possible in Lojban by the cmavo zi'e (of selma'o ZIhE), which is used to join one or more relative clauses together into a single unit, thus making them apply to the same sumti. For example:
| le | gerku | poi | blabi | zi'e | poi | batci | le | nanmu | cu | klama |
|
The dog which is white and which bites the man goes. |
The most usual translation of zi'e in English is “and” , but zi'e is not really a logical connective: unlike most of the true logical connectives (which are explained in Chapter 14), it cannot be converted into a logical connection between sentences.
It is perfectly correct to use zi'e to connect relative clauses of different kinds:
| le | gerku | poi | blabi | zi'e | noi |
| The | dog | that-is | (white) | and | incidentally-such-that |
| le | mi | pendo | cu | ponse | ke'a | cu | klama |
| (- | my | friend | owns | IT | ) | goes. |
|
The dog that is white, which my friend owns, is going. |
In Example 8.39 , the restrictive clause poi blabi specifies which dog is referred to, but the incidental clause noi le mi pendo cu ponse is mere incidental information: the listener is supposed to already have identified the dog from the poi blabi. Of course, the meaning (though not necessarily the emphasis) is the same if the incidental clause appears first.
It is also possible to connect relative phrases with zi'e , or a relative phrase with a relative clause:
| le | botpi | po | mi | zi'e | poi | blanu | cu | spofu |
| The | bottle | specific-to | me | and | which-is | blue | is-broken. |
|
My blue bottle is broken. |
Note that if the colloquial translation of Example 8.40 were “My bottle, which is blue, is broken” , then noi rather than poi would have been correct in the Lojban version, since that version of the English implies that you do not need to know the bottle is blue. As written, Example 8.40 suggests that I probably have more than one bottle, and the one in question needs to be picked out as the blue one.
| mi | ba | zutse | le | stizu | pe |
| I | [future] | sit-in | the | chair | associated-with |
| mi | zi'e | po | do | zi'e | poi | xunre |
| me | and | specific-to | you | and | which | is-red. |
|
I will sit in my chair (really yours), the red one. |
Example 8.41 illustrates that more than two relative phrases or clauses can be connected with zi'e. It almost defies colloquial translation because of the very un-English contrast between pe mi , implying that the chair is temporarily connected with me, and po do , implying that the chair has a more permanent association with you. (Perhaps I am a guest in your house, in which case the chair would naturally be your property.)
Here is another example, mixing a relative phrase and two relative clauses, a restrictive one and a non-restrictive one:
| mi | ba | citka | le | dembi | pe | mi | zi'e | poi | cpana |
| I | [future] | eat | the | beans | associated-with | me | and | which | are-upon |
| le | mi | palta | zi'e | noi | do | dunda | ke'a | mi | |
| my | plate | and | which-incidentally | you | gave | IT | to | me. |
|
I'll eat my beans that are on my plate, the ones you gave me. |
|
voi |
NOI |
non-veridical relative clause introducer |
There is another member of selma'o NOI which serves to introduce a third kind of relative clause: voi. Relative clauses introduced by voi are restrictive, like those introduced by poi. However, there is a fundamental difference between poi and voi relative clauses. A poi relative clause is said to be veridical, in the same sense that a description using lo or loi is: it is essential to the interpretation that the bridi actually be true. For example:
it must actually be true that the dog is white, or the sentence constitutes a miscommunication. If there is a white dog and a brown dog, and the speaker uses le gerku poi blabi to refer to the brown dog, then the listener will not understand correctly. However,
puts the listener on notice that the dog in question may not actually meet objective standards (whatever they are) for being white: only the speaker can say exactly what is meant by the term. In this way, voi is like le ; the speaker's intention determines the meaning.
As a result, the following two sentences
mean essentially the same thing (except that Example 8.46 involves pointing thanks to the use of ti , whereas Example 8.45 doesn't), and neither one is self-contradictory: it is perfectly all right to describe something as a man (although perhaps confusing to the listener) even if it actually is a woman.
So far, this chapter has described the various kinds of relative clauses (including relative phrases). The list is now complete, and the rest of the chapter will be concerned with the syntax of sumti that include relative clauses. So far, all relative clauses have appeared directly after the sumti to which they are attached. This is the most common position (and originally the only one), but a variety of other placements are also possible which produce a variety of semantic effects.
There are actually three places where a relative clause can be attached to a description sumti: after the descriptor ( le , lo , or whatever), after the embedded selbri but before the elidable terminator (which is ku), and after the ku. The relative clauses attached to descriptors that we have seen have occupied the second position. Thus Example 8.43 , if written out with all elidable terminators, would appear as:
| le | gerku | poi | blabi | ku'o | ku | cu | klama | vau |
| The | (dog | which | (is-white | ) | ) | goes | . |
|
The dog which is white is going. |
Here ku'o is the terminator paired with poi and ku with le , and vau is the terminator of the whole bridi.
When a simple descriptor using le , like le gerku , has a relative clause attached, it is purely a matter of style and emphasis where the relative clause should go. Therefore, the following examples are all equivalent in meaning to Example 8.47 :
Example 8.47 will seem most natural to speakers of languages like English, which always puts relative clauses after the noun phrases they are attached to; Example 8.48 , on the other hand, may seem more natural to Finnish or Chinese speakers, who put the relative clause first. Note that in Example 8.48 , the elidable terminator ku'o must appear, or the selbri of the relative clause ( blabi) will merge with the selbri of the description ( gerku), resulting in an ungrammatical sentence. The purpose of the form appearing in Example 8.49 will be apparent shortly.
As is explained in detail in Section 6.7 , two different numbers (known as the “inner quantifier” and the “outer quantifier”) can be attached to a description. The inner quantifier specifies how many things the descriptor refers to: it appears between the descriptor and the description selbri. The outer quantifier appears before the descriptor, and specifies how many of the things referred to by the descriptor are involved in this particular bridi. In the following example,
| re | le | mu | prenu | cu | klama | le | zarci | |
| Two | of | the | five | persons | go-to | the | market. |
|
Two of the five people [that I have in mind] are going to the market. |
mu is the inner quantifier and re is the outer quantifier. Now what is meant by attaching a relative clause to the sumti re le mu prenu ? Suppose the relative clause is poi ninmu (meaning “who are women”). Now the three possible attachment points discussed previously take on significance.
| re | le | poi | ninmu | ku'o | |
| Two | of | the | such-that([they] | are-women | ) |
| mu | prenu | cu | klama | le | zarci |
| five | persons | go-to | the | market. |
|
Two women out of the five persons go to the market. |
| re | le | mu | prenu | poi | ninmu | [ku] | cu | klama | le | zarci | |
| Two | of | the | (five | persons | which-( | are-women) | ) | go-to | the | market. |
|
Two of the five women go to the market. |
| re | le | mu | prenu | ku | poi | ninmu | cu | klama | le | zarci | |
| (Two | of | the | five | persons | ) | which-( | are-women | ) | go-to | the | market. |
|
Two women out of the five persons go to the market. |
As the parentheses show, Example 8.52 means that all five of the persons are women, whereas Example 8.53 means that the two who are going to the market are women. How do we remember which is which? If the relative clause comes after the explicit ku , as in Example 8.53 , then the sumti as a whole is qualified by the relative clause. If there is no ku , or if the relative clause comes before an explicit ku , then the relative clause is understood to apply to everything which the underlying selbri applies to.
What about Example 8.51 ? By convention, it means the same as Example 8.53 , and it requires no ku , but it does typically require a ku'o instead. Note that the relative clause comes before the inner quantifier.
When le is the descriptor being used, and the sumti has no explicit outer quantifier, then the outer quantifier is understood to be ro (meaning “all”), as is explained in Section 6.7. Thus le gerku is taken to mean “all of the things I refer to as dogs” , possibly all one of them. In that case, there is no difference between a relative clause after the ku or before it. However, if the descriptor is lo , the difference is quite important:
| lo | prenu | ku | noi | blabi | cu | klama | le | zarci |
| (Some | persons | ) | incidentally-which-( | are-white | ) | go-to | the | market. |
|
Some people, who are white, go to the market. |
| lo | prenu | noi | blabi | [ku] | cu | klama | le | zarci |
| Some | (persons | incidentally-which | are-white | ) | go | to-the | market. |
|
Some of the people, who by the way are white, go to the market. |
Both Example 8.54 and Example 8.55 tell us that one or more persons are going to the market. However, they make very different incidental claims. Now, what does lo prenu noi blabi mean? Well, the default inner quantifier is ro (meaning “all”), and the default outer quantifier is su'o (meaning “at least one”). Therefore, we must first take all persons, then choose at least one of them. That one or more people will be going.
In Example 8.54 , the relative clause described the sumti once the outer quantifier was applied: one or more people, who are white, are going. But in Example 8.55 , the relative clause actually describes the sumti before the outer quantification is applied, so that it ends up meaning “First take all persons – by the way, they're all white”. But not all people are white, so the incidental claim being made here is false.
The safe strategy, therefore, is to always use ku when attaching a noi relative clause to a lo descriptor. Otherwise we may end up claiming far too much.
When the descriptor is la , indicating that what follows is a selbri used for naming, then the positioning of relative clauses has a different significance. A relative clause inside the ku , whether before or after the selbri, is reckoned part of the name; a relative clause outside the ku is not. Therefore,
| mi | viska | la | nanmu | poi | terpa | le | ke'a | xirma | [ku] |
| I | see | that-named-( | man | which | fears | the | of-IT | horse | ). |
|
I see Man Afraid Of His Horse. |
says that the speaker sees a person with a particular name, who does not necessarily fear any horses, whereas
| mi | viska | la | nanmu | ku | poi | terpa | le | ke'a | xirma. |
| I | see | that-named-( | Man | ) | which | fears | the | of-IT | horse. |
|
I see the person named “Man” who is afraid of his horse. |
refers to one (or more) of those named “Man” , namely the one(s) who are afraid of their horses.
Finally, so-called indefinite sumti like re karce , which means almost the same as re lo karce (which in turn means the same as re lo ro karce), can have relative clauses attached; these are taken to be of the outside-the- ku variety. Here is an example:
The restrictive relative clause only affects the two cars being affected by the main bridi, not all cars that exist. It is ungrammatical to try to place a relative clause within an indefinite sumti (that is, before an explicitly expressed terminating ku.) Use an explicit lo instead.
In Example 8.15 through Example 8.17 , the sumti le mi karce appears, glossed as “my car”. Although it might not seem so, this sumti actually contains a relative phrase. When a sumti appears between a descriptor and its description selbri, it is actually a pe relative phrase. So
and
mean exactly the same thing. Furthermore, since there are no special considerations of quantifiers here,
means the same thing as well. A sumti like the one in Example 8.59 is called a “possessive sumti”. Of course, it does not really indicate possession in the sense of ownership, but like pe relative phrases, indicates only weak association; you can say le mi karce even if you've only borrowed it for the night. (In English, “my car” usually means le karce po mi , but we do not have the same sense of possession in “my seat on the bus” ; Lojban simply makes the weaker sense the standard one.) The inner sumti, mi in Example 8.59 , is correspondingly called the “possessor sumti”.
Historically, possessive sumti existed before any other kind of relative phrase or clause, and were retained when the machinery of relative phrases and clauses as detailed in this chapter so far was slowly built up. When preposed relative clauses of the Example 8.60 type were devised, possessive sumti were most easily viewed as a special case of them.
Although any sumti, however complex, can appear in a full-fledged relative phrase, only simple sumti can appear as possessor sumti, without a pe. Roughly speaking, the legal possessor sumti are: pro-sumti, quotations, names and descriptions, and numbers. In addition, the possessor sumti may not be preceded by a quantifier, as such a form would be interpreted as the unusual “descriptor + quantifier + sumti” type of description. All these sumti forms are explained in full in Chapter 6.
Here is an example of a description used in a possessive sumti:
Note the explicit ku at the end of the possessor sumti, which prevents the selbri of the possessor sumti from merging with the selbri of the main description sumti. Because of the need for this ku , the most common kind of possessor sumti are pro-sumti, especially personal pro-sumti, which require no elidable terminator. Descriptions are more likely to be attached with relative phrases.
And here is a number used as a possessor sumti:
which is not quite the same as “the fifth juror” ; it simply indicates a weak association between the particular juror and the number 5.
A possessive sumti may also have regular relative clauses attached to it. This would need no comment if it were not for the following special rule: a relative clause immediately following the possessor sumti is understood to affect the possessor sumti, not the possessive. For example:
means that my car isn't going; the incidental claim of noi sipna applies to me, not my car, however. If I wanted to say that the car is sleeping (whatever that might mean) I would need:
Note that Example 8.64 uses vau rather than ku'o at the end of the relative clause: this terminator ends every simple bridi and is almost always elidable; in this case, though, it is a syllable shorter than the equally valid alternative, ku'o.
The following cmavo is discussed in this section:
|
vu'o |
VUhO |
relative clause attacher |
Normally, relative clauses attach only to simple sumti or parts of sumti: pro-sumti, names and descriptions, pure numbers, and quotations. An example of a relative clause attached to a pure number is:
| li | pai | noi | na'e | frinu | namcu |
| The-number | pi, | incidentally-which | is-a-non- | fraction | number |
|
The irrational number pi |
And here is an incidental relative clause attached to a quotation:
| lu | mi | klama | le | zarci | li'u |
| [quote] | I | go-to | the | market | [unquote] |
| noi | mi | cusku | ke'a | cu | jufra |
| incidentally-which-( | I | express | IT | ) | is-a-sentence. |
|
“I'm going to the market” , which I'd said, is a sentence. |
which may serve to identify the author of the quotation or some other relevant, but subsidiary, fact about it. All such relative clauses appear only after the simple sumti, never before it.
In addition, sumti with attached sumti qualifiers of selma'o LAhE or NAhE+BO (which are explained in detail in Section 6.10) can have a relative clause appearing after the qualifier and before the qualified sumti, as in:
| la'e | poi | tolcitno | vau | lu | le | xunre |
| A-referent-of | (which | is-old | ) | [quote] | The | Red |
| cmaxirma | li'u | cu | zvati | le | vu | kumfa |
| Small-horse | [unquote] | is-at | the | [far-distance] | room. |
|
An old “The Red Pony” is in the far room. |
Example 8.68 is a bit complex, and may need some picking apart. The quotation lu le xunre cmaxirma li'u means the string of words “The Red Pony”. If the la'e at the beginning of the sentence were omitted, Example 8.68 would claim that a certain string of words is in a room distant from the speaker. But obviously a string of words can't be in a room! The effect of the la'e is to modify the sumti so that it refers not to the words themselves, but to the referent of those words, a novel by John Steinbeck (presumably in Lojban translation). The particular copy of “The Red Pony” is identified by the restrictive relative clause. Example 8.68 means exactly the same as:
| la'e | lu | le | xunre | cmaxirma | li'u | lu'u |
| A-referent-of | ([quote] | The | Red | Small-horse | [unquote] | ) |
| poi | to'ercitno | cu | zvati | le | vu | kumfa |
| which | is-old | is-at | the | [far-distance] | room. |
and the two sentences can be considered stylistic variants. Note the required lu'u terminator, which prevents the relative clause from attaching to the quotation itself: we do not wish to refer to an old quotation!
Sometimes, however, it is important to make a relative clause apply to the whole of a more complex sumti, one which involves logical or non-logical connection (explained in Chapter 14). For example,
| la | .frank. | .e | la | .djordj. | noi |
| That-named | Frank | and | that-named | George | incidentally-who |
| nanmu | cu | klama | le | zdani |
| is-a-man | go-to | the | house. |
|
Frank and George, who is a man, go to the house. |
The incidental claim in Example 8.70 is not that Frank and George are men, but only that George is a man, because the incidental relative clause attaches only to la djordj , the immediately preceding simple sumti.
To make a relative clause attach to both parts of the logically connected sumti in Example 8.70 , a new cmavo is needed, vu'o (of selma'o VUhO). It is placed between the sumti and the relative clause, and extends the sphere of influence of that relative clause to the entire preceding sumti, including however many logical or non-logical connectives there may be.
| la | .frank. | .e | la | .djordj. | vu'o |
| (That-named | Frank | and | that-named | George | ) |
| noi | nanmu | cu | klama | le | zdani |
| incidentally-who | are-men | go | to-the | house. |
|
Frank and George, who are men, go to the house. |
The presence of vu'o here means that the relative clause noi nanmu extends to the entire logically connected sumti la .frank. .e la .djordj. ; in other words, both Frank and George are claimed to be men, as the colloquial translation shows.
English is able to resolve the distinction correctly in the case of Example 8.70 and Example 8.71 by making use of number: “who is” rather than “who are”. Lojban doesn't distinguish between singular and plural verbs: nanmu can mean “is a man” or “are men” , so another means is required. Furthermore, Lojban's mechanism works correctly in general: if nanmu (meaning “is-a-man”) were replaced with pu bajra ( “ran”), English would have to make the distinction some other way:
| la | .frank. | .e | la | .djordj. | noi |
| That-named | Frank | and | (that-named | George | who |
| pu | bajra | cu | klama | le | zdani |
| [past] | runs) | go-to | the | house. |
|
Frank and George, who ran, go to the house. |
| la | .frank. | .e | la | .djordj. | vu'o |
| (That-named | Frank | and | that-named | George | ) |
| noi | pu | bajra | cu | klama | le | zdani |
| who | [past] | run | go-to | the | house. |
|
Frank and George, who ran, go to the house. |
In spoken English, tone of voice would serve; in written English, one or both sentences would need rewriting.
Vocative phrases are explained in more detail in Section 6.11. Briefly, they are a method of indicating who a sentence or discourse is addressed to: of identifying the intended listener. They take three general forms, all beginning with cmavo from selma'o COI or DOI (called “vocative words” ; there can be one or many), followed by either a cmevla, a selbri, or a sumti. Here are three examples:
Note that Example 8.75 says farewell to something which doesn't really have to be a horse, something that the speaker simply thinks of as being a horse, or even might be something (a person, for example) who is named “Horse”. In a sense, Example 8.75 is ambiguous between co'o le xirma and co'o la xirma , a relatively safe semantic ambiguity, since names are ambiguous in general: saying “George” doesn't distinguish between the possible Georges.
Similarly, Example 8.74 can be thought of as an abbreviation of:
Syntactically, vocative phrases are a kind of free modifier, and can appear in many places in Lojban text, generally at the beginning or end of some complete construct; or, as in Example 8.74 to Example 8.76 , as sentences by themselves.
As can be seen, the form of vocative phrases is similar to that of sumti, and as you might expect, vocative phrases allow relative clauses in various places. In vocative phrases which are simple names (after the vocative words), any relative clauses must come just after the names:
| coi | .frank. | poi | xunre | se bende |
| Hello, | Frank | who | is-a-red | team-member |
|
Hello, Frank from the Red Team! |
The restrictive relative clause in Example 8.78 suggests that there is some other Frank (perhaps on the Green Team) from whom this Frank, the one the speaker is greeting, must be distinguished.
A vocative phrase containing a selbri can have relative clauses either before or after the selbri; both forms have the same meaning. Here are some examples:
| co'o | poi | mi | zvati | ke'a | ku'o | xirma |
| Goodbye, | such-that-( | I | am-at | IT | ) | horse |
|
Goodbye, horse where I am! |
Example 8.79 and Example 8.80 mean the same thing. In fact, relative clauses can appear in both places.
For the most part, these are straightforward and uncomplicated: a sumti that is part of a relative clause bridi may itself be modified by a relative clause:
However, an ambiguity can exist if ke'a is used in a relative clause within a relative clause: does it refer to the outermost sumti, or to the sumti within the outer relative clause to which the inner relative clause is attached? The latter. To refer to the former, use a subscript on ke'a :
| le | prenu | poi | zvati | le | kumfa | poi | ke'axire | zbasu | ke'a | cu | masno |
| The | person | who | is-in | the | room | which | IT-sub-2 | built | IT | is-slow. |
|
The person who is in the room which he built is slow. |
Here, the meaning of “IT-sub-2” is that sumti attached to the second relative clause, counting from the innermost, is used. Therefore, ke'axipa (IT-sub-1) means the same as plain ke'a.
Alternatively, you can use a prenex (explained in full in Chapter 16), which is syntactically a series of sumti followed by the special cmavo zo'u , prefixed to the relative clause bridi:
| le | prenu | poi | ke'a | goi | ko'a | zo'u |
| The | man | who | (IT | = | it1 | : |
| ko'a | zvati | le | kumfa | poi | ke'a | goi | ko'e | zo'u |
| it1 | is-in | the | room | which | (IT | = | it2 | : |
| ko'a | zbasu | ko'e | cu | masno |
| it1 | built | it2) | is-slow. |
Example 8.83 is more verbose than Example 8.82 , but may be clearer, since it explicitly spells out the two ke'a cmavo, each on its own level, and assigns them to the assignable cmavo ko'a and ko'e (explained in Section 7.5).
Relative clause introducers (selma'o NOI):
|
noi |
incidental clauses |
|
poi |
restrictive clauses |
|
voi |
restrictive clauses (non-veridical) |
Relative phrase introducers (selma'o GOI):
|
goi |
pro-sumti assignment |
|
pe |
restrictive association |
|
ne |
incidental association |
|
po |
extrinsic (alienable) possession |
|
po'e |
intrinsic (inalienable) possession |
|
po'u |
restrictive identification |
|
no'u |
incidental identification |
Relativizing pro-sumti (selma'o KOhA):
|
ke'a |
pro-sumti for relativized sumti |
Relative clause joiner (selma'o ZIhE):
|
zi'e |
joins relative clauses applying to a single sumti |
Relative clause associator (selma'o VUhO):
|
vu'o |
causes relative clauses to apply to all of a complex sumti |
Elidable terminators (each its own selma'o):
|
ku'o |
relative clause elidable terminator |
|
ge'u |
relative phrase elidable terminator |

The basic type of Lojban sentence is the bridi: a claim by the speaker that certain objects are related in a certain way. The objects are expressed by Lojban grammatical forms called sumti ; the relationship is expressed by the Lojban grammatical form called a selbri.
The sumti are not randomly associated with the selbri, but according to a systematic pattern known as the “place structure” of the selbri. This chapter describes the various ways in which the place structure of Lojban bridi is expressed and by which it can be manipulated. The place structure of a selbri is a sequence of empty slots into which the sumti associated with that selbri are placed. The sumti are said to occupy the places of the selbri.
For our present purposes, every selbri is assumed to have a well-known place structure. If the selbri is a brivla, the place structure can be looked up in a dictionary (or, if the brivla is a lujvo not in any dictionary, inferred from the principles of lujvo construction as explained in Chapter 12); if the selbri is a tanru, the place structure is the same as that of the final component in the tanru.
The stock example of a place structure is that of the gismu klama :
klama x1 comes/goes to destination x2 from origin x3 via route x4 employing means of transport x5.
The “x1 ... x5” indicates that klama is a five-place predicate, and show the natural order (as assigned by the language engineers) of those places: agent, destination, origin, route, means.
The place structures of brivla are not absolutely stable aspects of the language. The work done so far has attempted to establish a basic place structure on which all users can, at first, agree. In the light of actual experience with the individual selbri of the language, there will inevitably be some degree of change to the brivla place structures.
The following cmavo is discussed in this section:
|
cu |
CU |
prefixed selbri separator |
The most usual way of constructing a bridi from a selbri such as klama and an appropriate number of sumti is to place the sumti intended for the x1 place before the selbri, and all the other sumti in order after the selbri, thus:
| mi | cu | klama | la | .bastn. | la | .atlantas. |
| I | go | to-that-named | Boston | from-that-named | Atlanta |
| le | dargu | le | karce |
| via-the | road | using-the | car. |
Here the sumti are assigned to the places as follows:
| x1 | agent | mi |
| x2 | destination | la .bastn. |
| x3 | origin | la .atlantas. |
| x4 | route | le dargu |
| x5 | means | le karce |
(Note: Many of the examples in the rest of this chapter will turn out to have the same meaning as Example 9.1 ; this fact will not be reiterated.)
This ordering, with the x1 place before the selbri and all other places in natural order after the selbri, is called “standard bridi form” , and is found in the bulk of Lojban bridi, whether used in main sentences or in subordinate clauses. However, many other forms are possible, such as:
| mi | la | .bastn. | la | .atlantas. |
| I, | to-that-named | Boston | from-that-named | Atlanta |
| le | dargu | le | karce | cu | klama |
| via-the | road | using-the | car, | go. |
Here the selbri is at the end; all the sumti are placed before it. However, the same order is maintained.
Similarly, we may split up the sumti, putting some before the selbri and others after it:
| mi | la | .bastn. | cu | klama | la | .atlantas. |
| I | to-that-named | Boston | go | from-that-named | Atlanta |
| le | dargu | le | karce |
| via-the | road | using-the | car. |
All of the variant forms in this section and following sections can be used to place emphasis on the part or parts which have been moved out of their standard places. Thus, Example 9.2 places emphasis on the selbri (because it is at the end); Example 9.3 emphasizes la .bastn. , because it has been moved before the selbri. Moving more than one component may dilute this emphasis. It is permitted, but no stylistic significance has yet been established for drastic reordering.
In all these examples, the cmavo cu (belonging to selma'o CU) is used to separate the selbri from any preceding sumti. It is never absolutely necessary to use cu. However, providing it helps the reader or listener to locate the selbri quickly, and may make it possible to place a complex sumti just before the selbri, allowing the speaker to omit elidable terminators, possibly a whole stream of them, that would otherwise be necessary.
The general rule, then, is that the selbri may occur anywhere in the bridi as long as the sumti maintain their order. The only exception (and it is an important one) is that if the selbri appears first, the x1 sumti is taken to have been omitted:
| klama | la | .bastn. |
| A-goer | to-that-named | Boston |
| Goes | to-Boston |
| la | .atlantas. |
| from-that-named | Atlanta |
| from-Atlanta |
| le | dargu |
| via-the | road |
| via-the | road |
| le | karce |
| using-the | car. |
| using-the | car. |
|
Look: a goer to Boston from Atlanta via the road using the car! |
Here the x1 place is empty: the listener must guess from context who is going to Boston. In Example 9.4 , klama is glossed “a goer” rather than “go” because “Go” at the beginning of an English sentence would suggest a command: “Go to Boston!”. Example 9.4 is not a command, simply a normal statement with the x1 place unspecified, causing the emphasis to fall on the selbri klama. Such a bridi, with empty x1, is called an “observative” , because it usually calls on the listener to observe something in the environment which would belong in the x1 place. The third translation above shows this observative nature. Sometimes it is the relationship itself which the listener is asked to observe.
(There is a way to both provide a sumti for the x1 place and put the selbri first in the bridi: see Example 9.14.)
Suppose the speaker desires to omit a place other than the x1 place? (Presumably it is obvious or, for one reason or another, not worth saying.) Places at the end may simply be dropped:
| mi | klama | la | .bastn. | la | .atlantas. |
|
I go to-Boston from-Atlanta (via an unspecified route, using an unspecified means). |
Example 9.5 has empty x4 and x5 places: the speaker does not specify the route or the means of transport. However, simple omission will not work for a place when the places around it are to be specified: in
| mi | klama | la | .bastn. | la | .atlantas. | le | karce |
| I | go | to-that-named | Boston | from-that-named | Atlanta | via-the | car. |
le karce occupies the x4 place, and therefore Example 9.6 means:
I go to Boston from Atlanta, using the car as a route.
This is nonsense, since a car cannot be a route. What the speaker presumably meant is expressed by:
| mi | klama | la | .bastn. | la | .atlantas. |
| I | go | to-that-named | Boston | from-that-named | Atlanta |
| zo'e | le | karce |
| via-something-unspecified | using-the | car. |
Here the sumti cmavo zo'e is used to explicitly fill the x4 place; zo'e means “the unspecified thing” and has the same meaning as leaving the place empty: the listener must infer the correct meaning from context.
The following cmavo are discussed in this section:
|
fa |
FA |
tags x1 place |
|
fe |
FA |
tags x2 place |
|
fi |
FA |
tags x3 place |
|
fo |
FA |
tags x4 place |
|
fu |
FA |
tags x5 place |
|
fi'a |
FA |
place structure question |
In sentences like Example 9.1 , it is easy to get lost and forget which sumti falls in which place, especially if the sumti are more complicated than simple names or descriptions. The place structure tags of selma'o FA may be used to help clarify place structures. The five cmavo fa , fe , fi , fo , and fu may be inserted just before the sumti in the x1 to x5 places respectively:
| fa | mi | cu | klama | fe | la | .bastn. | fi | la | .atlantas. |
| x1= | I | go | x2= | that-named | Boston | x3= | that-named | Atlanta |
| fo | le | dargu | fu | le | karce |
| x4= | the | road | x5= | the | car. |
|
I go to Boston from Atlanta via the road using the car. |
In Example 9.8 , the tag fu before le karce clarifies that le karce occupies the x5 place of klama. The use of fu tells us nothing about the purpose or meaning of the x5 place; it simply says that le karce occupies it.
In Example 9.8 , the tags are overkill; they serve only to make Example 9.1 even longer than it is. Here is a better illustration of the use of FA tags for clarification:
| fa | mi | klama | fe | le | zdani | be | mi | be'o | poi |
| x1= | I | go | x2= | (the | house | of | me) | which |
| nurma | vau | fi | la | .nu,IORK. |
| is-rural | x3= | that-named | New-York. |
In Example 9.9 , the place structure of klama is as follows:
| x1 | agent | mi |
| x2 | destination | le zdani be mi be'o poi nurma vau |
| x3 | origin | la .nu,IORK. |
| x4 | route | (empty) |
| x5 | means | (empty) |
The fi tag serves to remind the hearer that what follows is in the x3 place of klama ; after listening to the complex sumti occupying the x2 place, it's easy to get lost.
Of course, once the sumti have been tagged, the order in which they are specified no longer carries the burden of distinguishing the places. Therefore, it is perfectly all right to scramble them into any order desired, and to move the selbri to anywhere in the bridi, even the beginning:
| klama | fa | mi | fi | la | .atlantas. | fu | le | karce |
| go | x1= | I | x3= | that-named | Atlanta | x5= | the | car |
| fe | la | .bastn. | fo | le | dargu |
| x2= | that-named | Boston | x4= | the | road. |
|
Go I from Atlanta using the car to Boston via the road. |
Note that no cu is permitted before the selbri in Example 9.10 , because cu separates the selbri from any preceding sumti, and Example 9.10 has no such sumti.
| fu | le | karce | fo | le | dargu | fi | la | .atlantas. |
| x5= | the | car | x4= | the | road | x3= | that-named | Atlanta |
| fe | la | .bastn. | cu | klama | fa | mi |
| x2= | that-named | Boston | go | x1= | I |
|
Using the car, via the road, from Atlanta to Boston go I. |
Example 9.11 exhibits the reverse of the standard bridi form seen in Example 9.1 and Example 9.8 , but still means exactly the same thing. If the FA tags were left out, however, producing:
| le | karce | le | dargu | la | .atlantas. |
| The | car | to-the | road | from-that-named | Atlanta |
| la | .bastn. | cu | klama | mi |
| via-that-named | Boston | goes | using-me. |
|
The car goes to the road from Atlanta, with Boston as the route, using me as a means of transport. |
the meaning would be wholly changed, and in fact nonsensical.
Tagging places with FA cmavo makes it easy not only to reorder the places but also to omit undesirable ones, without any need for zo'e or special rules about the x1 place:
| klama | fi | la | .atlantas. | fe | la | .bastn. |
| A-goer | x3= | that-named | Atlanta | x2= | that-named | Boston |
| fu | le | karce |
| x5= | the | car. |
|
A goer from Atlanta to Boston using the car. |
Here the x1 and x4 places are empty, and so no sumti are tagged with fa or fo ; in addition, the x2 and x3 places appear in reverse order.
What if some sumti have FA tags and others do not? The rule is that after a FA-tagged sumti, any sumti following it occupy the places numerically succeeding it, subject to the proviso that an already-filled place is skipped:
| klama | fa | mi | la | .bastn. | la | .atlantas. |
| Go | x1= | I | x2=that-named | Boston | x3=that-named | Atlanta |
| le | dargu | le | karce |
| x4=the | road | x5=the | car. |
|
Go I to Boston from Atlanta via the road using the car. |
In Example 9.14 , the fa causes mi to occupy the x1 place, and then the following untagged sumti occupy in order the x2 through x5 places. This is the mechanism by which Lojban allows placing the selbri first while specifying a sumti for the x1 place.
Here is a more complex (and more confusing) example:
| mi | klama | fi | la | .atlantas. | le | dargu |
| I | go | x3= | that-named | Atlanta, | the | road |
| fe | la | .bastn. | le | karce |
| x2= | that-named | Boston, | the | car. |
|
I go from Atlanta via the road to Boston using the car. |
In Example 9.15 , mi occupies the x1 place because it is the first sumti in the sentence (and is before the selbri). The second sumti, la .atlantas. , occupies the x3 place by virtue of the tag fi , and le dargu occupies the x4 place as a result of following la .atlantas.. Finally, la .bastn. occupies the x2 place because of its tag fe , and le karce skips over the already-occupied x3 and x4 places to land in the x5 place.
Such a convoluted use of tags should probably be avoided except when trying for a literal translation of some English (or other natural-language) sentence; the rules stated here are merely given so that some standard interpretation is possible.
It is grammatically permitted to tag more than one sumti with the same FA cmavo. The effect is that of making more than one claim:
| [fa] | la | .rik. | fa | la | .djein. | klama |
| [x1=] | that-named | Rick | x1= | that-named | Jane | goes-to |
| [fe] | le | kindi'u | fe | le | zdani | fe | le | zarci |
| [x2=] | the | movie-theater | x2= | the | house | x2= | the | store |
may be taken to say that both Rick and Jane go to the movie, the house, and the office, merging six claims into one. More likely, however, it will simply confuse the listener. There are better ways, involving logical connectives (explained in Chapter 14), to say such things in Lojban. In fact, putting more than one sumti into a place is odd enough that it can only be done by explicit FA usage: this is the motivation for the proviso above, that already-occupied places are skipped. In this way, no sumti can be forced into a place already occupied unless it has an explicit FA cmavo tagging it.
The cmavo fi'a also belongs to selma'o FA, and allows Lojban users to ask questions about place structures. A bridi containing fi'a is a question, asking the listener to supply the appropriate other member of FA which will make the bridi a true statement:
| fi'a | do | dunda | [fe] | le | vi | rozgu |
| [what-place]? | you | give | x2= | the | nearby | rose |
|
In what way are you involved in the giving of this rose? |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Are you the giver or the receiver of this rose? |
In Example 9.17 , the speaker uses the selbri dunda , whose place structure is:
dunda x1 gives x2 to x3
The tagged sumti fi'a do indicates that the speaker wishes to know whether the sumti do falls in the x1 or the x3 place (the x2 place is already occupied by le rozgu). The listener can reply with a sentence consisting solely of a FA cmavo: fa if the listener is the giver, fi if he/she is the receiver.
I have inserted the tag fe in brackets into Example 9.17 , but it is actually not necessary, because fi'a does not count as a numeric tag; therefore, le vi rozgu would necessarily be in the x2 place even if no tag were present, because it immediately follows the selbri.
There is also another member of FA, namely fai , which is discussed in Section 9.12.
The following cmavo are discussed in this section:
|
se |
SE |
2nd place conversion |
|
te |
SE |
3rd place conversion |
|
ve |
SE |
4th place conversion |
|
xe |
SE |
5th place conversion |
So far we have seen ways to move sumti around within a bridi, but the actual place structure of the selbri has always remained untouched. The conversion cmavo of selma'o SE are incorporated within the selbri itself, and produce a new selbri (called a converted selbri) with a different place structure. In particular, after the application of any SE cmavo, the number and purposes of the places remain the same, but two of them have been exchanged, the x1 place and another. Which place has been exchanged with x1 depends on the cmavo chosen. Thus, for example, when se is used, the x1 place is swapped with the x2 place.
Note that the cmavo of SE begin with consecutive consonants in alphabetical order. There is no “1st place conversion” cmavo, because exchanging the x1 place with itself is a pointless maneuver.
Here are the place structures of se klama :
x1 is the destination of x2's going from x3 via x4 using x5
x1 is the origin and x2 the destination of x3 going via x4 using x5
x1 is the route to x2 from x3 used by x4 going via x5
x1 is the means in going to x2 from x3 via x4 employed by x5
Note that the place structure numbers in each case continue to be listed in the usual order, x1 to x5.
Consider the following pair of examples:
| la | .bastn. | cu | se klama | mi |
| That-named | Boston | is-the-destination | of-me. |
|
Boston is my destination. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Boston is gone to by me. |
Example 9.18 and Example 9.19 mean the same thing, in the sense that there is a relationship of going with the speaker as the agent and Boston as the destination (and with unspecified origin, route, and means). Structurally, however, they are quite different. Example 9.18 has la .bastn. in the x1 place and mi in the x2 place of the selbri se klama , and uses standard bridi order; Example 9.19 has mi in the x1 place and la .bastn. in the x2 place of the selbri klama , and uses a non-standard order.
The most important use of conversion is in the construction of descriptions. A description is a sumti which begins with a cmavo of selma'o LA or LE, called the descriptor, and contains (in the simplest case) a selbri. We have already seen the descriptions le dargu and le karce. To this we could add:
In every case, the description is about something which fits into the x1 place of the selbri. In order to get a description of a destination (that is, something fitting the x2 place of klama), we must convert the selbri to se klama , whose x1 place is a destination. The result is
Likewise, we can create three more converted descriptions:
Example 9.23 does not mean “the route” plain and simple: that is le pluta , using a different selbri. It means a route that is used by someone for an act of klama ; that is, a journey with origin and destination. A “road” on Mars, on which no one has traveled or is ever likely to, may be called le pluta , but it cannot be le ve klama , since there exists no one for whom it is le ve klama be fo da (the route taken in an actual journey by someone [da]).
When converting selbri that are more complex than a single brivla, it is important to realize that the scope of a SE cmavo is only the following brivla (or equivalent unit). In order to convert an entire tanru, it is necessary to enclose the tanru in ke … ke'e brackets:
The place structure of blanu zdani (blue house) is the same as that of zdani , by the rule given in Section 9.1. The place structure of zdani is:
zdani x1 is a house/nest/lair/den for inhabitant x2
The place structure of se ke blanu zdani [ke'e] is therefore:
x1 is the inhabitant of the blue house (etc.) x2
Consequently, Example 9.25 means:
I am the inhabitant of the blue house which is this thing.
Conversion applied to only part of a tanru has subtler effects which are explained in Section 5.11.
It is grammatical to convert a selbri more than once with SE; later (inner) conversions are applied before earlier (outer) ones. For example, the place structure of se te klama is achieved by exchanging the x1 and x2 place of te klama , producing:
x1 is the destination and x2 is the origin of x3 going via x4 using x5
On the other hand, te se klama has a place structure derived from swapping the x1 and x3 places of se klama :
x1 is the origin of x2's going to x3 via x4 using x5
which is quite different. However, multiple conversions like this are never necessary. Arbitrary scrambling of places can be achieved more easily and far more intelligibly with FA tags, and only a single conversion is ever needed in a description.
(Although no one has made any real use of it, it is perhaps worth noting that compound conversions of the form setese , where the first and third cmavo are the same, effectively swap the two given places while leaving the others, including x1, alone: setese (or equivalently tesete) swap the x2 and x3 places, whereas texete (or xetexe) swap the x3 and x5 places.)
The following cmavo are discussed in this section:
|
fi'o |
FIhO |
modal place prefix |
|
fe'u |
FEhU |
modal terminator |
Sometimes the place structures engineered into Lojban are inadequate to meet the needs of actual speech. Consider the gismu viska , whose place structure is:
viska x1 sees x2 under conditions x3
Seeing is a threefold relationship, involving an agent (le viska), an object of sight (le se viska), and an environment that makes seeing possible (le te viska). Seeing is done with one or more eyes, of course; in general, the eyes belong to the entity in the x1 place.
Suppose, however, that you are blind in one eye and are talking to someone who doesn't know that. You might want to say, “I see you with the left eye.” There is no place in the place structure of viska such as “with eye x4” or the like. Lojban allows you to solve the problem by adding a new place, changing the relationship:
| mi | viska | do | fi'o | kanla | [fe'u] | le | zunle |
| I | see | you | [modal] | eye: | the | left-thing |
|
I see you with the left eye. |
The three-place relation viska has now acquired a fourth place specifying the eye used for seeing. The combination of the cmavo fi'o (of selma'o FIhO) followed by a selbri, in this case the gismu kanla , forms a tag which is prefixed to the sumti filling the new place, namely le zunle. The semantics of fi'o kanla le zunle is that le zunle fills the x1 place of kanla , whose place structure is
kanla x1 is an/the eye of body x2
Thus le zunle is an eye. The x2 place of kanla is unspecified and must be inferred from the context. It is important to remember that even though le zunle is placed following fi'o kanla , semantically it belongs in the x1 place of kanla. The selbri may be terminated with fe'u (of selma'o FEhU), an elidable terminator which is rarely required unless a non-logical connective follows the tag (omitting fe'u in that case would make the connective affect the selbri).
The term for such an added place is a “modal place” , as distinguished from the regular numbered places. (This use of the word “modal” is specific to the Loglan Project, and does not agree with the standard uses in either logic or linguistics, but is now too entrenched to change easily.) The fi'o construction marking a modal place is called a “modal tag” , and the sumti which follows it a “modal sumti” ; the purely Lojban terms sumtcita and seltcita sumti , respectively, are also commonly used. Modal sumti may be placed anywhere within the bridi, in any order; they have no effect whatever on the rules for assigning unmarked sumti to numbered places, and they may not be marked with FA cmavo.
Consider Example 9.26 again. Another way to view the situation is to consider the speaker's left eye as a tool, a tool for seeing. The relevant selbri then becomes pilno , whose place structure is
pilno x1 uses x2 as a tool for purpose x3
and we can rewrite Example 9.26 as
| mi | viska | do | fi'o | se | pilno | le | zunle | kanla |
| I | see | you | [modal] | [conversion] | use: | the | left | eye. |
|
I see you using my left eye. |
Here the selbri belonging to the modal is se pilno. The conversion of pilno is necessary in order to get the “tool” place into x1, since only x1 can be the modal sumti. The “tool user” place is the x2 of se pilno (because it is the x1 of pilno) and remains unspecified. The tag fi'o pilno would mean “with tool user” , leaving the tool unspecified.
There are certain selbri which seem particularly useful in constructing modal tags. In particular, pilno is one of them. The place structure of pilno is:
pilno x1 uses x2 as a tool for purpose x3
and almost any selbri which represents an action may need to specify a tool. Having to say fi'o se pilno frequently would make many Lojban sentences unnecessarily verbose and clunky, so an abbreviation is provided in the language design: the compound cmavo sepi'o.
Here se is used before a cmavo, namely pi'o , rather than before a brivla. The meaning of this cmavo, which belongs to selma'o BAI, is exactly the same as that of fi'o pilno fe'u. Since what we want is a tag based on se pilno rather than pilno- the tool, not the tool user – the grammar allows a BAI cmavo to be converted using a SE cmavo. Example 9.27 may therefore be rewritten as:
The compound cmavo sepi'o is much shorter than fi'o se pilno [fe'u] and can be thought of as a single word meaning “with-tool”. The modal tag pi'o , with no se , similarly means “with-tool-user” , probably a less useful concept. Nevertheless, the parallelism with the place structure of pilno makes the additional syllable worthwhile.
Some BAI cmavo make sense with as well as without a SE cmavo; for example, ka'a , the BAI corresponding to the gismu klama , has five usable forms corresponding to the five places of klama respectively:
| ka'a |
with-goer |
| seka'a |
with-destination |
| teka'a |
with-origin |
| veka'a |
with-route |
| xeka'a |
with-means-of-transport |
Any of these tags may be used to provide modal places for bridi, as in the following examples:
| la | .eivn. | cu | vecnu | loi | flira | cinta | ka'a | mi |
| That-named | Avon | sells | a-mass-of | face | paint | with-goer | me. |
|
I am a traveling cosmetics salesperson for Avon. |
( Example 9.29 may seem a bit strained, but it illustrates the way in which an existing selbri, vecnu in this case, may have a place added to it which might otherwise seem utterly unrelated.)
| bloti | teka'a | la | .nu,IORK. |
| [Observative:]-is-a-boat | with-origin | that-named | New-York |
|
A boat from New York! |
There are sixty-odd cmavo of selma'o BAI, based on selected gismu that seemed useful in a variety of settings. The list is somewhat biased toward English, because many of the cmavo were selected on the basis of corresponding English prepositions and preposition compounds such as “with” , “without” , and “by means of”. The BAI cmavo, however, are far more precise than English prepositions, because their meanings are fixed by the place structures of the corresponding gismu.
All BAI cmavo have the form CV'V or CVV. Most of them are CV'V, where the C is the first consonant of the corresponding gismu and the two Vs are the two vowels of the gismu. The table in Section 9.16 shows the exceptions.
There is one additional BAI cmavo that is not derived from a gismu: do'e. This cmavo is used when an extra place is needed, but it seems useful to be vague about the semantic implications of the extra place:
| lo | nanmu | be do'e | le | berti | cu | klama | le | tcadu |
| Some | man | [related-to] | the | north | came | to-the | city. |
|
A man of the north came to the city. |
Here le berti is provided as a modal place of the selbri nanmu , but its exact significance is vague, and is paralleled in the colloquial translation by the vague English preposition “of”. Example 9.34 also illustrates a modal place bound into a selbri with be. This construction is useful when the selbri of a description requires a modal place; this and other uses of be are more fully explained in Section 5.7.
The following cmavo are discussed in this section:
|
ri'a |
BAI |
rinka modal: physical cause |
|
ki'u |
BAI |
krinu modal: justification |
|
mu'i |
BAI |
mukti modal: motivation |
|
ni'i |
BAI |
nibli modal: logical entailment |
This section has two purposes. On the one hand, it explains the grammatical construct called “modal sentence connection”. On the other, it exemplifies some of the more useful BAI cmavo: the causals. (There are other BAI cmavo which have causal implications: ja'e means “with result” , and so seja'e means “with cause of unspecified nature” ; likewise, gau means “with agent” and tezu'e means “with purpose”. These other modal cmavo will not be further discussed here, as my purpose is to explain modal sentence connection rather than Lojbanic views of causation.)
There are four causal gismu in Lojban, distinguishing different versions of the relationships lumped in English as “causal” :
| rinka | event x1 physically causes event x2 |
| krinu | event x1 is the justification for event x2 |
| mukti | event x1 is the (human) motive for event x2 |
| nibli | event x1 logically entails event x2 |
Each of these gismu has a related modal: ri'a , ki'u , mu'i , and ni'i respectively. Using these gismu and these modals, we can create various causal sentences with different implications:
| le | spati | cu | banro | ri'a | le | nu |
| The | plant | grows | with-physical-cause | the | event-of |
| do | djacu | dunda | fi | le | spati |
| you | water | give | to | the | plant. |
|
The plant grows because you water it. |
| la | .djan. | cpacu | le | pamoi | se jinga |
| John | gets | the | first | prize |
| ki'u | le | nu | la | .djan. | jinga |
| with-justification | the | event-of | that-named | John | wins. |
|
John got the first prize because he won. |
| mi | lebna | le | cukta | mu'i |
| I | took | the | book | with-motivation |
| le | nu | mi | viska | le | cukta |
| the | event-of | I | saw | the | book. |
|
I took the book because I saw it. |
| la | .sokrates. | morsi | binxo | ni'i |
| Socrates | dead | became | with-logical-justification |
| le | nu | la | .sokrates. | remna |
| the | event-of | that-named | Socrates | is-human. |
|
Socrates died because Socrates is human. |
In Example 9.35 through Example 9.38 , the same English word “because” is used to translate all four modals, but the types of cause being expressed are quite different. Let us now focus on Example 9.35 , and explore some variations on it.
As written, Example 9.35 claims that the plant grows, but only refers to the event of watering it in an abstraction bridi (abstractions are explained in Chapter 11) without actually making a claim. If I express Example 9.35 , I have said that the plant in fact grows, but I have not said that you actually water it, merely that there is a causal relationship between watering and growing. This is semantically asymmetrical. Suppose I wanted to claim that the plant was being watered, and only mention its growth as ancillary information? Then we could reverse the main bridi and the abstraction bridi, saying:
| do | djacu | dunda | fi | le | spati |
| You | water | give | to | the | plant |
| seri'a | le | nu | ri | banro |
| with-physical-effect | the | event-of | it | grows. |
|
You water the plant; therefore, it grows. |
with the ri'a changed to seri'a. In addition, there are also symmetrical forms:
| le | nu | do | djacu | dunda | fi | le | spati | cu |
| The | event-of | (you | water | give | to | the | plant) |
| rinka | le | nu | le | spati | cu | banro |
| causes | the | event-of | (the | plant | grows). |
|
Your watering the plant causes its growth. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
If you water the plant, then it grows. |
does not claim either event, but asserts only the causal relationship between them. So in Example 9.40 , I am not saying that the plant grows nor that you have in fact watered it. The second colloquial translation shows a form of “if-then” in English quite distinct from the logical connective “if-then” explained in Chapter 14.
Suppose we wish to claim both events as well as their causal relationship? We can use one of two methods:
| le | spati | cu | banro | .iri'abo | do |
| The | plant | grows. | Because | you |
| djacu | dunda | fi | le | spati |
| water | give | to | the | plant. |
|
The plant grows because you water it. |
| do | djacu | dunda | fi | le | spati |
| You | water | give | to | the | plant. |
| .iseri'abo | le | spati | cu | banro |
| Therefore | the | plant | grows. |
|
You water the plant; therefore, it grows. |
The compound cmavo .iri'abo and .iseri'abo serve to connect two bridi, as the initial .i indicates. The final bo is necessary to prevent the modal from “taking over” the following sumti. If the bo were omitted from Example 9.41 we would have:
| le | spati | cu | banro | .i | ri'a | do |
| The | plant | grows. | Because-of | you, |
| djacu | dunda | fi | le | spati | |
| [something] | water | gives | to | the | plant. |
|
The plant grows. Because of you, water is given to the plant. |
Because ri'a do is a modal sumti in Example 9.43 , there is no longer an explicit sumti in the x1 place of djacu dunda , and the translation must be changed.
The effect of sentences like Example 9.41 and Example 9.42 is that the modal, ri'a in this example, no longer modifies an explicit sumti. Instead, the sumti is implicit, the event given by a full bridi. Furthermore, there is a second implication: that the first bridi fills the x2 place of the gismu rinka ; it specifies an event which is the effect. I am therefore claiming three things: that the plant grows, that you have watered it, and that there is a cause-and-effect relationship between the two.
In principle, any modal tag can appear in a sentence connective of the type exemplified by Example 9.41 and Example 9.42. However, it makes little sense to use any modals which do not expect events or other abstractions to fill the places of the corresponding gismu. The sentence connective .ibaubo is perfectly grammatical, but it is hard to imagine any two sentences which could be connected by an “in-language” modal. This is because a sentence describes an event, and an event can be a cause or an effect, but not a language.
Like many Lojban grammatical constructions, sentence modal connection has both forethought and afterthought forms. (See Chapter 14 for a more detailed discussion of Lojban connectives.) Section 9.7 exemplifies only afterthought modal connection, illustrated here by:
| mi | jgari | lei | djacu |
| I | grasp | the-mass-of | water |
| .iri'abo | mi | jgari | le | kabri |
| with-physical-cause | I | grasp | the | cup. |
|
Causing the mass of water to be grasped by me, I grasped the cup. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
I grasp the water because I grasp the cup. |
An afterthought connection is one that is signaled only by a cmavo (or a compound cmavo, in this case) between the two constructs being connected. Forethought connection uses a signal both before the first construct and between the two: the use of “both” and “and” in the first half of this sentence represents a forethought connection (though not a modal one).
To make forethought modal sentence connections in Lojban, place the modal plus gi before the first bridi, and gi between the two. No .i is used within the construct. The forethought equivalent of Example 9.44 is:
| ri'agi | mi | jgari | le | kabri | gi |
| With-physical-cause | I | grasp | the | cup | , |
| mi | jgari | lei | djacu |
| I | grasp | the-mass-of | water. |
|
Because I grasp the cup, I grasp the water. |
Note that the cause, the x1 of rinka is now placed first. To keep the two bridi in the original order of Example 9.44 , we could say:
| seri'agi | mi | jgari | lei | djacu | gi |
| With-physical-effect | I | grasp | the-mass-of | water | , |
| mi | jgari | le | kabri |
| I | grasp | the | cup. |
In English, the sentence “Therefore I grasp the water, I grasp the cup” is ungrammatical, because “therefore” is not grammatically equivalent to “because”. In Lojban, seri'agi can be used just like ri'agi.
When the two bridi joined by a modal connection have one or more elements (selbri or sumti or both) in common, there are various condensed forms that can be used in place of full modal sentence connection with both bridi completely stated.
When the bridi are the same except for a single sumti, as in Example 9.44 through Example 9.46 , then a sumti modal connection may be employed:
Example 9.47 means exactly the same as Example 9.44 through Example 9.46 , but there is no idiomatic English translation that will distinguish it from them.
If the two connected bridi are different in more than one sumti, then a termset may be employed. Termsets are explained more fully in Section 14.11 , but are essentially a mechanism for creating connections between multiple sumti simultaneously.
| mi | dunda | le | cukta | la | .djan. |
| I | gave | the | book | to-that-named | John. |
| .imu'ibo | la | .djan. | dunda | lei | jdini | mi |
| Motivated-by | that-named | John | gave | the-mass-of | money | to-me. |
|
I gave the book to John, because John gave money to me. |
means the same as:
| nu'i | mu'igi | la | .djan. | lei | jdini | mi | gi |
| [start] | because | that-named | John, | the-mass-of | money, | me | ; |
| mi | le | cukta | la | .djan. | nu'u | dunda |
| I, | the | book, | that-named | John | [end] | gives. |
Here there are three sumti in each half of the termset, because the two bridi share only their selbri.
There is no modal connection between selbri as such: bridi which differ only in the selbri can be modally connected using bridi-tail modal connection. The bridi-tail construct is more fully explained in Section 14.9 , but essentially it consists of a selbri with optional sumti following it. Example 9.37 is suitable for bridi-tail connection, and could be shortened to:
Again, no straightforward English translation exists. It is even possible to shorten Example 9.50 further to:
where le cukta is set off by the non-elidable vau and is made to belong to both bridi-tails – see Section 14.9 for more explanations.
Since this is a chapter on rearranging sumti, it is worth pointing out that Example 9.51 can be further rearranged to:
which doesn't require the extra vau ; all sumti before a conjunction of bridi-tails are shared.
Finally, mathematical operands can be modally connected.
| li | ny. | du | li | vo |
| the-number | n | = | the-number | 4. |
| .ini'ibo | li | ny. | du | li | re | su'i | re |
| Entailed-by | the-number | n | = | the-number | 2 | + | 2. |
|
n = 4 because n = 2 + 2. |
can be reduced to:
| li | ny. | du | li |
| the-number | n | = | the-number |
| ni'igi | vei | re | su'i | re | [ve'o] | gi | vo |
| because | ( | 2 | + | 2 | ) | therefore | 4. |
|
n is 2 + 2, and is thus 4. |
The cmavo vei and ve'o represent mathematical parentheses, and are required so that ni'igi affects more than just the immediately following operand, namely the first re. (The right parenthesis, ve'o , is an elidable terminator.) As usual, no English translation does Example 9.54 justice.
Note: Due to restrictions on the Lojban parsing algorithm, it is not possible to form modal connectives using the fi'o- plus-selbri form of modal. Only the predefined modals of selma'o BAI can be compounded as shown in Section 9.7 and Section 9.8.
| mi | tavla | bau | la | .lojban. |
| I | speak | in-language | that-named | Lojban |
| bai | tu'a | la | .frank. |
| with-compeller | some-act-by | that-named | Frank. |
|
I speak in Lojban, under compulsion by Frank. |
Example 9.55 has two modal sumti, using the modals bau and bai. Suppose we wanted to specify the language explicitly but be vague about who's doing the compelling. We can simplify Example 9.55 to:
In Example 9.56 , the elidable terminator ku has taken the place of the sumti which would normally follow bai. Alternatively, we could specify the one who compels but keep the language vague:
| mi | tavla | bau | [ku] |
| I | speak | in-some-language |
| bai | tu'a | la | .frank. |
| under-compulsion-by | some-act-by | that-named | Frank. |
We are also free to move the modal-plus- ku around the bridi:
An alternative to using ku is to place the modal cmavo right before the selbri, following the cu which often appears there. When a modal is present, the cu is almost never necessary.
In this use, the modal is like a tanru modifier semantically, although grammatically it is quite distinct. Example 9.59 is very similar in meaning to:
The se conversion is needed because bapli tavla would be a “compeller type of speaker” rather than a “compelled (by someone) type of speaker” , which is what a bai tavla is.
If the modal preceding a selbri is constructed using fi'o , then fe'u is required to prevent the main selbri and the modal selbri from colliding:
There are two other uses of modals. A modal can be attached to a pair of bridi-tails that have already been connected by a logical, non-logical, or modal connection (see Chapter 14 for more on logical and non-logical connections):
| mi | bai | ke | ge | klama | le | zarci |
| I | under-compulsion | ( | both | go | to-the | market |
| gi | cadzu | le | bisli | [ke'e] |
| and | walk | on-the | ice | ). |
|
Under compulsion, I both go to the market and walk on the ice. |
Here the bai is spread over both klama le zarci and cadzu le bisli , and the ge ... gi represents the logical connection “both-and” between the two.
Similarly, a modal can be attached to multiple sentences that have been combined with tu'e and tu'u , which are explained in more detail in Section 19.2 :
| bai | tu'e | mi | klama | le | zarci |
| Under-compulsion | [start] | I | go | to-the | market. |
| .i | mi | cadzu | le | bisli | [tu'u] |
| I | walk | on-the | ice | [end]. |
means the same thing as Example 9.62.
Note: Either BAI modals or fi'o- plus-selbri modals may correctly be used in any of the constructions discussed in this section.
The following cmavo are discussed in this section:
|
pe |
GOI |
restrictive relative phrase |
|
ne |
GOI |
incidental relative phrase |
|
mau |
BAI |
zmadu modal |
|
me'a |
BAI |
mleca modal |
Relative phrases and clauses are explained in much more detail in Chapter 8. However, there is a construction which combines a modal with a relative phrase which is relevant to this chapter. Consider the following examples of relative clauses:
| la | .apasionatas. | poi | se cusku |
| The | Appassionata | which | is-expressed-by |
| la | .artr. | .rubnstain. | cu | se nelci | mi |
| that-named | Arthur | Rubinstein | is-liked-by | me. |
| la | .apasionatas. | noi | se finti |
| The | Appassionata, | which | is-created-by |
| la | .betovn. | cu | se nelci | mi |
| that-named | Beethoven, | is-liked-by | me. |
In Example 9.64 , la .apasionatas. refers to a particular performance of the sonata, namely the one performed by Rubinstein. Therefore, the relative clause poi se cusku uses the cmavo poi (of selma'o NOI) to restrict the meaning of la .apasionatas to the performance in question.
In Example 9.65 , however, la .apasionatas. refers to the sonata as a whole, and the information that it was composed by Beethoven is merely incidental. The cmavo noi (also of selma'o NOI) expresses the incidental nature of this relationship.
The cmavo pe and ne (of selma'o GOI) are roughly equivalent to poi and noi respectively, but are followed by sumti rather than full bridi. We can abbreviate Example 9.64 and Example 9.65 to:
| la | .apasionatas. | pe | la | .artr. | .rubnstain. | se nelci | mi |
| The | Appassionata | of | that-named | Arthur | Rubinstein | is-liked-by | me. |
| la | .apasionatas. | ne | la | .betovn. | se nelci | mi |
| The | Appassionata, | which-is-of | that-named | Beethoven, | is-liked-by | me. |
Here the precise selbri of the relative clauses is lost: all we can tell is that the Appassionata is connected in some way with Rubinstein (in Example 9.66) and Beethoven (in Example 9.67), and that the relationships are respectively restrictive and incidental.
It happens that both cusku and finti have BAI cmavo, namely cu'u and fi'e. We can recast Example 9.66 and Example 9.67 as:
| la | .apasionatas | pe cu'u |
| The | Appassionata | expressed-by |
| la | .artr. | .rubnstain. | cu | se nelci | mi |
| that-named | Arthur | Rubinstein | is-liked-by | me. |
| la | .apasionatas | ne fi'e |
| The | Appassionata, | invented-by |
| la | .betovn. | cu | se nelci | mi |
| that-named | Beethoven, | is-liked-by | me. |
Example 9.68 and Example 9.69 have the full semantic content of Example 9.64 and Example 9.65 respectively.
Modal relative phrases are often used with the BAI cmavo mau and me'a , which are based on the comparative gismu zmadu (more than) and mleca (less than) respectively. The place structures are:
| zmadu | x1 is more than x2 in property/quantity x3 by amount x4 |
| mleca | x1 is less than x2 in property/quantity x3 by amount x4 |
Here are some examples:
| la | .frank. | nelci | la | .betis. |
| That-named | Frank | likes | that-named | Betty, |
| ne | semau | la | .meiris. |
| which-is | more-than | that-named | Mary. |
|
Frank likes Betty more than (he likes) Mary. |
Example 9.70 requires that Frank likes Betty, but adds the information that his liking for Betty exceeds his liking for Mary. The modal appears in the form semau because the x2 place of zmadu is the basis for comparison: in this case, Frank's liking for Mary.
| la | .frank. | nelci | la | .meiris. |
| That-named | Frank | likes | that-named | Mary, |
| ne | seme'a | la | .betis. |
| which-is | less-than | that-named | Betty. |
|
Frank likes Mary less than (he likes) Betty. |
Here we are told that Frank likes Mary less than he likes Betty; the information about the comparison is the same. It would be possible to rephrase Example 9.70 using me'a rather than semau , and Example 9.71 using mau rather than seme'a , but such usage would be unnecessarily confusing. Like many BAI cmavo, mau and me'a are more useful when converted with se.
If the ne were omitted in Example 9.70 and Example 9.71 , the modal sumti ( la .meiris. and la .betis. respectively) would become attached to the bridi as a whole, producing a very different translation. Example 9.71 would become:
| la | .frank. | nelci | la | .meiris. | seme'a | la | .betis. |
| That-named | Frank | likes | that-named | Mary | is-less-than | that-named | Betty. |
|
Frank's liking Mary is less than Betty. |
which compares a liking with a person, and is therefore nonsense.
Pure comparison, which states only the comparative information but says nothing about whether Frank actually likes either Mary or Betty (he may like neither, but dislike Betty less), would be expressed differently, as:
| le | ni | la | .frank. |
| The | quantity-of | that-named | Frank's |
| nelci | la | .betis. | cu |
| liking | that-named | Betty |
| zmadu | le | ni | la | .frank. |
| is-more-than | the | quantity-of | that-named | Frank's |
| nelci | la | .meiris. |
| liking | that-named | Mary. |
The mechanisms explained in this section are appropriate to many modals other than semau and seme'a. Some other modals that are often associated with relative phrases are: seba'i ( “instead of”), ci'u ( “on scale”), de'i ( “dated”), du'i ( “as much as”). Some BAI tags can be used equally well in relative phrases or attached to bridi; others seem useful only attached to bridi. But it is also possible that the usefulness of particular BAI modals is an English-speaker bias, and that speakers of other languages may find other BAIs useful in divergent ways.
Note: The uses of modals discussed in this section are applicable both to BAI modals and to fi'o- plus-selbri modals.
It is possible to mix logical connection (explained in Chapter 14) with modal connection, in a way that simultaneously asserts the logical connection and the modal relationship. Consider the sentences:
which is a logical connection, and
The meanings of Example 9.74 and Example 9.75 can be simultaneously expressed by combining the two compound cmavo, thus:
Here the two sentences mi nelci do and mi nelci la .djein. are simultaneously asserted, their logical connection is asserted, and their causal relationship is asserted. The logical connective je comes before the modal ki'u in all such mixed connections.
Since mi nelci do and mi nelci la .djein. differ only in the final sumti, we can transform Example 9.76 into a mixed sumti connection:
Note that this connection is an afterthought one. Mixed connectives are always afterthought; forethought connectives must be either logical or modal.
There are numerous other afterthought logical and non-logical connectives that can have modal information planted within them. For example, a bridi-tail connected version of Example 9.77 would be:
The following three complex examples all mean the same thing.
| mi | bevri | le | dakli |
| I | carry | the | sack. |
| .ijeseri'abo | tu'e | mi | bevri | le | gerku |
| And-[effect] | ( | I | carry | the | dog. |
| .ijadu'ibo | mi | bevri | le | mlatu | [tu'u] |
| And/or-[equal] | I | carry | the | cat. | ) |
|
I carry the sack. As a result I carry the dog or I carry the cat, equally. |
| mi | bevri | le | dakli |
| I | carry | the | sack |
| gi'eseri'ake | bevri | le | gerku |
| and-[effect] | (carry | the | dog |
| gi'adu'ibo | bevri | le | mlatu | [ke'e] |
| and/or-[equal] | carry | the | cat) |
|
I carry the sack and as a result carry the dog or carry the cat equally. |
| mi | bevri | le | dakli |
| I | carry | the | sack |
| .eseri'ake | le | gerku |
| and-[effect] | (the | dog |
| .adu'ibo | le | mlatu | [ke'e] |
| and/or-[equal] | the | cat) |
|
I carry the sack, and as a result the cat or the dog equally. |
In Example 9.79 , the tu'e … tu'u brackets are the equivalent of the ke … ke'e brackets in Example 9.80 and Example 9.81 , because ke … ke'e cannot extend across more than one sentence. It would also be possible to change the .ijeseri'abo to .ije seri'a , which would show that the tu'e … tu'u portion was an effect, but would not pin down the mi bevri le dakli portion as the cause. It is legal for a modal (or a tense; see Chapter 10) to modify the whole of a tu'e … tu'u construct.
Note: The uses of modals discussed in this section are applicable both to BAI modals and to fi'o- plus-selbri modals.
The following cmavo are discussed in this section:
|
jai |
JAI |
modal conversion |
|
fai |
FA |
modal place structure tag |
So far, conversion of numbered bridi places with SE and the addition of modal places with BAI have been two entirely separate operations. However, it is possible to convert a selbri in such a way that, rather than exchanging two numbered places, a modal place is made into a numbered place. For example,
has an explicit x1 place occupied by mi and an explicit bau place occupied by la .lojban. To exchange these two, we use a modal conversion operator consisting of jai (of selma'o JAI) followed by the modal cmavo. Thus, the modal conversion of Example 9.82 is:
In Example 9.83 , the modal place la .lojban. has become the x1 place of the new selbri jai bau cusku. What has happened to the old x1 place? There is no numbered place for it to move to, so it moves to a special “unnumbered place” marked by the tag fai of selma'o FA.
Note: For the purposes of place numbering, fai behaves like fi'a ; it does not affect the numbering of the other places around it.
Like SE conversions, JAI conversions are especially convenient in descriptions. We may refer to “the language of an expression” as le jai bau cusku , for example.
In addition, it is grammatical to use jai without a following modal. This usage is not related to modals, but is explained here for completeness. The effect of jai by itself is to send the x1 place, which should be an abstraction, into the fai position, and to raise one of the sumti from the abstract sub-bridi into the x1 place of the main bridi. This feature is discussed in more detail in Section 11.10. The following two examples mean the same thing:
| le | nu | mi | lebna | le | cukta | cu | se krinu |
| The | event-of | (I | take | the | book) | is-justified-by |
| le | nu | mi | viska | le | cukta |
| the | event-of | (I | see | the | book). |
|
My taking the book is justified by my seeing it. |
| mi | jai se krinu | le | nu | mi | viska | le | cukta | kei |
| I | am-justified-by | the | event-of | (I | see | the | book) |
| [fai | le | nu | mi | lebna | le | cukta] |
| [namely, | the | event-of | (I | take | the | book)] |
|
I am justified in taking the book by seeing the book. |
Example 9.85 , with the bracketed part omitted, allows us to say that “I am justified” whereas in fact it is my action that is justified. This construction is vague, but useful in representing natural-language methods of expression.
Note: The uses of modals discussed in this section are applicable both to BAI modals and to fi'o- plus-selbri modals.
Negation is explained in detail in Chapter 15. There are two forms of negation in Lojban: contradictory and scalar negation. Contradictory negation expresses what is false, whereas scalar negation says that some alternative to what has been stated is true. A simple example is the difference between “John didn't go to Paris” (contradictory negation) and “John went to (somewhere) other than Paris” (scalar negation).
Contradictory negation involving BAI cmavo is performed by appending -nai (of selma'o NAI) to the BAI. A common use of modals with -nai is to deny a causal relationship:
Example 9.86 denies that the relationship between my liking you (which is asserted) and your liking me (which is not asserted) is one of motivation. Nothing is said about whether you like me or not, merely that that hypothetical liking is not the motivation for my liking you.
Scalar negation is achieved by prefixing na'e (of selma'o NAhE), or any of the other cmavo of NAhE, to the BAI cmavo.
| le | spati | cu | banro | na'emu'i | le | nu |
| The | plant | grows | other-than-motivated-by | the | event-of |
| do | djacu | dunda | fi | le | spati |
| you | water | give | to | the | plant. |
Example 9.87 says that the relationship between the plant's growth and your watering it is not one of motivation: the plant is not motivated to grow, as plants are not something which can have motivation as a rule. Implicitly, some other relationship between watering and growth exists, but Example 9.87 doesn't say what it is (presumably ri'a).
Note: Modals made with fi'o plus a selbri cannot be negated directly. The selbri can itself be negated either with contradictory or with scalar negation, however.
The following cmavo is discussed in this section:
|
ki |
KI |
stickiness flag |
Like tenses, modals can be made persistent from the bridi in which they appear to all following bridi. The effect of this “stickiness” is to make the modal, along with its following sumti, act as if it appeared in every successive bridi. Stickiness is put into effect by following the modal (but not any following sumti) with the cmavo ki of selma'o KI. For example,
| mi | tavla | bau | la | .lojban. | bai |
| I | speak | in-language | that-named | Lojban | compelled-by |
| ki | tu'a | la | .frank. |
| some-property-of | that-named | Frank. |
| .ibabo | mi | tavla | bau | la | .gliban. |
| Afterward, | I | speak | in-language | that-named | English. |
means the same as:
| mi | tavla | bau | la | .lojban. | bai |
| I | speak | in-language | that-named | Lojban | compelled-by |
| tu'a | la | .frank. |
| some-property-of | that-named | Frank. |
| .ibabo | mi | tavla | bau | la | .gliban. | bai |
| Afterward, | I | speak | in-language | that-named | English | compelled-by |
| tu'a | la | .frank. |
| some-property-of | that-named | Frank. |
In Example 9.88 , bai is made sticky, and so Frank's compelling is made applicable to every following bridi. bau is not sticky, and so the language may vary from bridi to bridi, and if not specified in a particular bridi, no assumption can safely be made about its value.
To cancel stickiness, use the form BAI ki ku , which stops any modal value for the specified BAI from being passed to the next bridi. To cancel stickiness for all modals simultaneously, and also for any sticky tenses that exist ( ki is used for both modals and tenses), use ki by itself, either before the selbri or (in the form ki ku) anywhere in the bridi:
Note: Modals made with fi'o -plus-selbri cannot be made sticky. This is an unfortunate, but unavoidable, restriction.
Logical and non-logical connectives are explained in detail in Chapter 14. For the purposes of this chapter, it suffices to point out that a logical (or non-logical) connection between two bridi which differ only in a modal can be reduced to a single bridi with a connective between the modals. As a result, Example 9.91 and Example 9.92 mean the same thing:
| la | .frank. | bajra | seka'a | le | zdani |
| That-named | Frank | runs | with-destination | the | house. |
| .ije | la | .frank. | bajra | teka'a | le | zdani |
| And | that-named | Frank | runs | with-origin | the | house. |
|
Frank runs to the house, and Frank runs from the house. |
| la | .frank. | bajra | seka'a |
| That-named | Frank | runs | with-destination |
| je | teka'a | le | zdani |
| and | with-origin | the | house. |
|
Frank runs to and from the house. |
Neither example implies whether a single act, or two acts, of running is referred to. To compel the sentence to refer to a single act of running, you can use the form:
| la | .frank. | bajra | seka'a | le | zdani |
| That-named | Frank | runs | with-destination | the | house |
| ce'e | teka'a | le | zdani |
| [joined-to] | with-origin | the | house. |
The cmavo ce'e creates a termset containing two terms (termsets are explained in Chapter 14 and Chapter 16). When a termset contains more than one modal tag derived from a single BAI, the convention is that the two tags are derived from a common event.
There are 65 cmavo of selma'o BAI, of which all but one ( do'e , discussed in Section 9.6), are derived directly from selected gismu. Of these 64 cmavo, 36 are entirely regular and have the form CV'V, where C is the first consonant of the corresponding gismu, and the Vs are the two vowels of the gismu. The remaining BAI cmavo, which are irregular in one way or another, are listed in the table below. The table is divided into sub-tables according to the nature of the exception; some cmavo appear in more than one sub-table, and are so noted.
Table 9.1. Monosyllables of the form CVV
| cmavo | gismu | comments |
|
bai |
bapli |
|
|
bau |
bangu |
|
|
cau |
claxu |
|
|
fau |
fasnu |
|
|
gau |
gasnu |
|
|
kai |
ckaji |
uses 2nd consonant of gismu |
|
mau |
zmadu |
uses 2nd consonant of gismu |
|
koi |
korbi |
|
|
rai |
traji |
uses 2nd consonant of gismu |
|
sau |
sarcu |
|
|
tai |
tamsmi |
based on lujvo, not gismu |
|
zau |
zanru |
Table 9.2. Second consonant of the gismu as the C: (the gismu is always of the form CCVCV)
|
ga'a |
zgana |
|
|
kai |
ckaji |
has CVV form (monosyllable) |
|
ki'i |
ckini |
|
|
la'u |
klani |
has irregular 2nd V |
|
le'a |
klesi |
has irregular 2nd V |
|
mau |
zmadu |
has CVV form (monosyllable) |
|
me'e |
cmene |
|
|
ra'a |
srana |
|
|
ra'i |
krasi |
|
|
rai |
traji |
has CVV form (monosyllable) |
|
ti'i |
stidi |
|
|
tu'i |
stuzi |
Table 9.3. Irregular 2nd V
|
fi'e |
finti |
|
|
la'u |
klani |
uses 2nd consonant of gismu |
|
le'a |
klesi |
uses 2nd consonant of gismu |
|
ma'e |
marji |
|
|
mu'u |
mupli |
|
|
ti'u |
tcika |
|
|
va'o |
vanbi |
Table 9.4. Special cases
|
ri'i |
lifri |
uses 3rd consonant of gismu |
|
tai |
tamsmi |
based on lujvo, not gismu |
|
va'u |
xamgu |
CV'V cmavo can't begin with x |
The following table shows all the cmavo belonging to selma'o BAI, and has seven columns. The first column is the cmavo itself; the second column is the gismu linked to it. The third column gives an English phrase which indicates the meaning of the cmavo; the fourth column indicates its meaning when preceded by se.
For those cmavo with meaningful te , ve , and even xe conversions (depending on the number of places of the underlying gismu), the meanings of these are shown in the next columns.
It should be emphasized that the place structures of the gismu control the meanings of the BAI cmavo. The English phrases shown here are only suggestive, and are often too broad or too narrow to correctly specify what the acceptable range of uses for the modal tag are.
|
ba'i |
basti |
replaced by |
instead of |
|||
|
bai |
bapli |
compelled by |
compelling |
|||
|
bau |
bangu |
in language |
in language of |
|||
|
be'i |
benji |
sent by |
transmitting |
sent to |
with transmit origin |
transmitted via |
|
ca'i |
catni |
by authority of |
with authority over |
|||
|
cau |
claxu |
lacked by |
without |
|||
|
ci'e |
ciste |
in system |
with system function |
of system components |
||
|
ci'o |
cinmo |
felt by |
feeling emotion |
|||
|
ci'u |
ckilu |
on the scale |
on scale measuring |
|||
|
cu'u |
cusku |
as said by |
expressing |
as told to |
expressed in medium |
|
|
de'i |
detri |
dated |
on the same date as |
|||
|
di'o |
diklo |
at the locus of |
at specific locus |
|||
|
----- |
vaguely related to |
|||||
|
du'i |
dunli |
as much as |
equal to |
|||
|
du'o |
djuno |
according to |
knowing facts |
knowing about |
under epistemology |
|
|
fa'e |
fatne |
reverse of |
in reversal of |
|||
|
in the event of |
||||||
|
fi'e |
finti |
created by |
creating work |
created for purpose |
||
|
ga'a |
zgana |
to observer |
observing |
observed by means |
observed under conditions |
|
|
gau |
gasnu |
with agent |
as agent in doing |
|||
|
ja'e |
jalge |
resulting in |
results because of |
|||
|
ja'i |
javni |
by rule |
by rule prescribing |
|||
|
ji'e |
jimte |
up to limit |
as a limit of |
|||
|
ji'o |
jitro |
under direction |
controlling |
|||
|
ji'u |
jicmu |
based on |
supporting |
|||
|
ka'a |
klama |
gone to by |
with destination |
with origin |
via route |
by transport mode |
|
ka'i |
krati |
represented by |
on behalf of |
|||
|
kai |
ckaji |
characterizing |
with property |
|||
|
ki'i |
ckini |
as relation of |
related to |
with relation |
||
|
ki'u |
krinu |
justified by |
with justified result |
|||
|
koi |
korbi |
bounded by |
as boundary of |
bordering |
||
|
ku'u |
kulnu |
in culture |
in culture of |
|||
|
la'u |
klani |
as quantity of |
in quantity |
|||
|
le'a |
klesi |
in category |
as category of |
defined by quality |
||
|
li'e |
lidne |
led by |
leading |
|||
|
ma'e |
marji |
of material |
made from material |
in material form of |
||
|
ma'i |
manri |
in reference frame |
as a standard of |
|||
|
mau |
zmadu |
exceeded by |
more than |
|||
|
me'a |
mleca |
undercut by |
less than |
|||
|
me'e |
cmene |
with name |
as a name for |
|||
|
mu'i |
mukti |
motivated by |
motive therefore |
|||
|
mu'u |
mupli |
exemplified by |
as an example of |
|||
|
ni'i |
nibli |
entailed by |
entails |
|||
|
pa'a |
panra |
in addition to |
similar to |
similar in pattern |
similar by standard |
|
|
pa'u |
pagbu |
with component |
as a part of |
|||
|
pi'o |
pilno |
used by |
using tool |
|||
|
po'i |
porsi |
in the sequence |
sequenced by rule |
|||
|
pu'a |
pluka |
pleased by |
in order to please |
|||
|
pu'e |
pruce |
by process |
processing from |
processing into |
passing through stages |
|
|
pertained to by |
concerning |
|||||
|
from source |
as an origin of |
|||||
|
rai |
traji |
with superlative |
superlative in |
at extreme |
superlative among |
|
|
ri'a |
rinka |
caused by |
causing |
|||
|
ri'i |
lifri |
experienced by |
experiencing |
|||
|
sau |
sarcu |
requiring |
necessarily for |
necessarily under conditions |
||
|
si'u |
sidju |
aided by |
assisting in |
|||
|
ta'i |
tadji |
by method |
as a method for |
|||
|
tai |
tamsmi |
as a form of |
in form |
in form similar to |
||
|
ti'i |
stidi |
suggested by |
suggesting |
suggested to |
||
|
ti'u |
tcika |
with time |
at the time of |
|||
|
tu'i |
stuzi |
with site |
as location of |
|||
|
va'o |
vanbi |
under conditions |
as conditions for |
|||
|
va'u |
xamgu |
benefiting from |
with beneficiary |
|||
|
zau |
zanru |
approved by |
approving |
|||
|
zu'e |
zukte |
with actor |
with means to goal |
with goal |
The lujvo tamsmi on which tai is based is derived from the tanru tarmi simsa and has the place structure:
tamsmi x1 has form x2, similar in form to x3 in property/quality x4
This lujvo is employed because tarmi does not have a place structure useful for the modal's purpose.
This chapter attempts to document and explain the space/time tense system of Lojban. It does not attempt to answer all questions of the form “How do I say such-and-such (an English tense) in Lojban?” Instead, it explores the Lojban tense system from the inside, attempting to educate the reader into a Lojbanic viewpoint. Once the overall system is understood and the resources that it makes available are familiar, the reader should have some hope of using appropriate tense constructs and being correctly understood.
The system of Lojban tenses presented here may seem really complex because of all the pieces and all the options; indeed, this chapter is the longest one in this book. But tense is in fact complex in every language. In your native language, the subtleties of tense are intuitive. In foreign languages, you are seldom taught the entire system until you have reached an advanced level. Lojban tenses are extremely systematic and productive, allowing you to express subtleties based on what they mean rather than on how they act similarly to English tenses. This chapter concentrates on presenting an intuitive approach to the meaning of Lojban tense words and how they may be creatively and productively combined.
What is “tense” ? Historically, “tense” is the attribute of verbs in English and related languages that expresses the time of the action. In English, three tenses are traditionally recognized, conventionally called the past, the present, and the future. There are also a variety of compound tenses used in English. However, there is no simple relationship between the form of an English tense and the time actually expressed:
-
I go to London tomorrow.
-
I will go to London tomorrow.
-
I am going to London tomorrow.
all mean the same thing, even though the first sentence uses the present tense; the second, the future tense; and the third, a compound tense usually called “present progressive”. Likewise, a newspaper headline says “JONES DIES” , although it is obvious that the time referred to must be in the past. Tense is a mandatory category of English: every sentence must be marked for tense, even if in a way contrary to logic, because every main verb has a tense marker built into to it. By contrast, Lojban brivla have no implicit tense marker attached to them.
In Lojban, the concept of tense extends to every selbri, not merely the verb-like ones. In addition, tense structures provide information about location in space as well as in time. All tense information is optional in Lojban: a sentence like:
can be understood as:
-
I went to the market.
-
I am going to the market.
-
I have gone to the market.
-
I will go to the market.
-
I continually go to the market.
as well as many other possibilities: context resolves which is correct.
The placement of a tense construct within a Lojban bridi is easy: right before the selbri. It goes immediately after the cu , and can in fact always replace the cu (although in very complex sentences the rules for eliding terminators may be changed as a result). In the following examples, pu is the tense marker for “past time” :
It is also possible to put the tense somewhere else in the bridi by adding ku after it. This ku is an elidable terminator, but it's almost never possible to actually elide it except at the end of the bridi:
Example 10.2 through Example 10.5 are different only in emphasis. Abnormal order, such as Example 10.3 through Example 10.5 exhibit, adds emphasis to the words that have been moved; in this case, the tense cmavo pu. Words at either end of the sentence tend to be more noticeable.
The following cmavo are discussed in this section:
|
vi |
VA |
short distance |
|
va |
VA |
medium distance |
|
vu |
VA |
long distance |
|
zu'a |
FAhA |
left |
|
ri'u |
FAhA |
right |
|
ga'u |
FAhA |
up |
|
ni'a |
FAhA |
down |
|
ca'u |
FAhA |
front |
|
ne'i |
FAhA |
within |
|
be'a |
FAhA |
north of |
(The complete list of FAhA cmavo can be found in Section 10.28.)
Why is this section about spatial tenses rather than the more familiar time tenses of Section 10.1 , asks the reader? Because the model to be used in explaining both will be easier to grasp for space than for time. The explanation of time tenses will resume in Section 10.4.
English doesn't have mandatory spatial tenses. Although there are plenty of ways in English of showing where an event happens, there is absolutely no need to do so. Considering this fact may give the reader a feel for what the optional Lojban time tenses are like. From the Lojban point of view, space and time are interchangeable, although they are not treated identically.
Lojban specifies the spatial tense of a bridi (the place at which it occurs) by using words from selma'o FAhA and VA to describe an imaginary journey from the speaker to the place referred to. FAhA cmavo specify the direction taken in the journey, whereas VA cmavo specify the distance gone. For example:
| le | nanmu | va | batci | le | gerku |
| The | man | [medium-distance] | bites | the | dog. |
|
Over there the man is biting the dog. |
What is at a medium distance? The event referred to by the bridi: the man biting the dog. What is this event at a medium distance from? The speaker's location. We can understand the va as saying: “If you want to get from the speaker's location to the location of the bridi, journey for a medium distance (in some direction unspecified).” This “imaginary journey” can be used to understand not only Example 10.6 , but also every other spatial tense construct.
Suppose you specify a direction with a FAhA cmavo, rather than a distance with a VA cmavo:
Here the imaginary journey is again from the speaker's location to the location of the bridi, but it is now performed by going to the left (in the speaker's reference frame) for an unspecified distance. So a reasonable translation is:
To my left, the man bites the dog.
The “my” does not have an explicit equivalent in the Lojban, because the speaker's location is understood as the starting point.
(Etymologically, by the way, zu'a is derived from zunle , the gismu for “left” , whereas vi , va , and vu are intended to be reminiscent of ti , ta , and tu , the demonstrative pronouns “this-here” , “that-there” , and “that-yonder”.)
What about specifying both a direction and a distance? The rule here is that the direction must come before the distance:
| le | nanmu | zu'avi | batci | le | gerku |
| The | man | [left-short-distance] | bites | the | dog. |
|
Slightly to my left, the man bites the dog. |
As explained in Section 10.1 , it would be perfectly correct to use ku to move this tense to the beginning or the end of the sentence to emphasize it:
| zu'aviku | le | nanmu | cu | batci | le | gerku |
| [Left-short-distance] | the | man | bites | the | dog. |
|
Slightly to my left, the man bites the dog. |
Humph, says the reader: this talk of “imaginary journeys” is all very well, but what's the point of it? – zu'a means “on the left” and vi means “nearby” , and there's no more to be said. The imaginary-journey model becomes more useful when so-called compound tenses are involved. A compound tense is exactly like a simple tense, but has several FAhAs run together:
The proper interpretation of Example 10.10 is that the imaginary journey has two stages: first move from the speaker's location upward, and then to the left. A translation might read:
Left of a place above me, the man bites the dog.
(Perhaps the speaker is at the bottom of a manhole, and the dog-biting is going on at the edge of the street.)
In the English translation, the keywords “left” and “above” occur in reverse order to the Lojban order. This effect is typical of what happens when we “unfold” Lojban compound tenses into their English equivalents, and shows why it is not very useful to try to memorize a list of Lojban tense constructs and their colloquial English equivalents.
The opposite order also makes sense:
| le | nanmu | zu'a | ga'u | batci | le | gerku |
| The | man | [left] | [up] | bites | the | dog. |
|
Above a place to the left of me, the man bites the dog. |
In ordinary space, the result of going up and then to the left is the same as that of going left and then up, but such a simple relationship does not apply in all environments or to all directions: going south, then east, then north may return one to the starting point, if that point is the North Pole.
Each direction can have a distance following:
| le | nanmu | zu'avi | ga'u | vu | batci | le | gerku |
| The | man | [left-short-distance] | [up] | [long-distance] | bites | the | dog. |
|
Far above a place slightly to the left of me, the man bites the dog. |
A distance can also come at the beginning of the tense construct, without any specified direction. ( Example 10.6 , with VA alone, is really a special case of this rule when no directions at all follow.)
| le | nanmu | vi | zu'a | batci | le | gerku |
| The | man | [short-distance] | [left] | bites | the | dog. |
|
Left of a place near me, the man bites the dog. |
Any number of directions may be used in a compound tense, with or without specified distances for each:
| le | nanmu | ca'u | vi | ni'a | va | ri'u | vu |
| The | man | [front] | [short] | [down] | [medium] | [right] | [long] |
| ne'i | batci | le | gerku | ||||
| [within] | bites | the | dog. |
|
Within a place a long distance to the right of a place which is a medium distance downward from a place a short distance in front of me, the man bites the dog. |
Whew! It's a good thing tense constructs are optional: having to say all that could certainly be painful. Note, however, how much shorter the Lojban version of Example 10.14 is than the English version.
The following cmavo are discussed in this section:
|
pu |
PU |
past |
|
ca |
PU |
present |
|
ba |
PU |
future |
|
zi |
ZI |
short time distance |
|
za |
ZI |
medium time distance |
|
zu |
ZI |
long time distance |
Now that the reader understands spatial tenses, there are only two main facts to understand about temporal tenses: they work exactly like the spatial tenses, with selma'o PU and ZI standing in for FAhA and VA; and when both spatial and temporal tense cmavo are given in a single tense construct, the temporal tense is expressed first. (If space could be expressed before or after time at will, then certain constructions would be ambiguous.)
means that to reach the dog-biting, you must take an imaginary journey through time, moving towards the past an unspecified distance. (Of course, this journey is even more imaginary than the ones talked about in the previous sections, since time-travel is not an available option.)
Lojban recognizes three temporal directions: pu for the past, ca for the present, and ba for the future. (Etymologically, these derive from the corresponding gismu purci , cabna , and balvi. See Section 10.23 for an explanation of the exact relationship between the cmavo and the gismu.) There are many more spatial directions, since there are FAhA cmavo for both absolute and relative directions as well as “direction-like relationships” like “surrounding” , “within” , “touching” , etc. (See Section 10.27 for a complete list.) But there are really only two directions in time: forward and backward, toward the future and toward the past. Why, then, are there three cmavo of selma'o PU?
The reason is that tense is subjective: human beings perceive space and time in a way that does not necessarily agree with objective measurements. We have a sense of “now” which includes part of the objective past and part of the objective future, and so we naturally segment the time line into three parts. The Lojban design recognizes this human reality by providing a separate time-direction cmavo for the “zero direction”. Similarly, there is a FAhA cmavo for the zero space direction: bu'u , which means something like “coinciding”.
(Technical note for readers conversant with relativity theory: The Lojban time tenses reflect time as seen by the speaker, who is assumed to be a “point-like observer” in the relativistic sense: they do not say anything about physical relationships of relativistic interval, still less about implicit causality. The nature of tense is not only subjective but also observer-based.)
Here are some examples of temporal tenses:
| le | nanmu | puzi | batci | le | gerku |
| The | man | [past-short-distance] | bites | the | dog. |
|
A short time ago, the man bit the dog. |
| le | nanmu | pu | pu | batci | le | gerku |
| The | man | [past] | [past] | bites | the | dog. |
|
Earlier than an earlier time than now, the man bit the dog. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
The man had bitten the dog. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
The man had been biting the dog. |
| le | nanmu | ba | puzi | batci | le | gerku |
| The | man | [future] | [past-short] | bites | the | dog. |
|
Shortly earlier than some time later than now, the man will bite the dog. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Soon before then, the man will have bitten the dog. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
The man will have just bitten the dog. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
The man will just have been biting the dog. |
What about the analogue of an initial VA without a direction? Lojban does allow an initial ZI with or without following PUs:
| le | nanmu | zi | pu | batci | le | gerku |
| The | man | [short] | [past] | bites | the | dog. |
|
Before a short time from or before now, the man bit or will bite the dog. |
| le | nanmu | zu | batci | le | gerku |
| The | man | [long] | bites | the | dog. |
|
A long time from or before now, the man will bite or bit the dog. |
Example 10.19 and Example 10.20 are perfectly legitimate, but may not be very much used: zi by itself signals an event that happens at a time close to the present, but without saying whether it is in the past or the future. A rough translation might be “about now, but not exactly now”.
Because we can move in any direction in space, we are comfortable with the idea of events happening in an unspecified space direction ( “nearby” or “far away”), but we live only from past to future, and the idea of an event which happens “nearby in time” is a peculiar one. Lojban provides lots of such possibilities that don't seem all that useful to English-speakers, even though you can put them together productively; this fact may be a limitation of English.
Finally, here are examples which combine temporal and spatial tense:
| le | nanmu | puzu | vu | batci | le | gerku |
| The | man | [past-long-time] | [long-space] | bites | the | dog. |
|
Long ago and far away, the man bit the dog. |
Alternatively,
| le | nanmu | cu | batci | le | gerku | puzuvuku |
| The | man | bites | the | dog | [past-long-time-long-space]. |
|
The man bit the dog long ago and far away. |
The following cmavo are discussed in this section:
|
ve'i |
VEhA |
short space interval |
|
ve'a |
VEhA |
medium space interval |
|
ve'u |
VEhA |
long space interval |
|
ze'i |
ZEhA |
short time interval |
|
ze'a |
ZEhA |
medium time interval |
|
ze'u |
ZEhA |
long time interval |
So far, we have considered only events that are usually thought of as happening at a particular point in space and time: a man biting a dog at a specified place and time. But Lojbanic events may be much more “spread out” than that: mi vasxu (I breathe) is something which is true during the whole of my life from birth to death, and over the entire part of the earth where I spend my life. The cmavo of VEhA (for space) and ZEhA (for time) can be added to any of the tense constructs we have already studied to specify the size of the space or length of the time over which the bridi is claimed to be true.
| le | verba | ve'i | cadzu | le | bisli |
| The | child | [small-space-interval] | walks-on | the | ice. |
|
In a small space, the child walks on the ice. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
The child walks about a small area of the ice. |
means that her walking was done in a small area. Like the distances, the interval sizes are classified only roughly as “small, medium, large” , and are relative to the context: a small part of a room might be a large part of a table in that room.
Here is an example using a time interval:
| le | verba | ze'a | cadzu | le | bisli |
| The | child | [medium-time-interval] | walks-on | the | ice. |
|
For a medium time, the child walks/walked/will walk on the ice. |
Note that with no time direction word, Example 10.24 does not say when the walking happened: that would be determined by context. It is possible to specify both directions or distances and an interval, in which case the interval always comes afterward:
| le | verba | pu | ze'a | cadzu | le | bisli |
| The | child | [past] | [medium-time-interval] | walks-on | the | ice. |
|
For a medium time, the child walked on the ice. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
The child walked on the ice for a while. |
In Example 10.25 , the relationship of the interval to the specified point in time or space is indeterminate. Does the interval start at the point, end at the point, or is it centered on the point? By adding an additional direction cmavo after the interval, this question can be conclusively answered:
| mi | ca | ze'ica | cusku | dei |
| I | [present] | [short-time-interval-present] | express | this-utterance. |
|
I am now saying this sentence. |
means that for an interval starting a short time in the past and extending to a short time in the future, I am expressing the utterance which is Example 10.26. Of course, “short” is relative, as always in tenses. Even a long sentence takes up only a short part of a whole day; in a geological context, the era of Homo sapiens would only be a ze'i interval.
By contrast,
| mi | ca | ze'ipu | cusku | dei |
| I | [present] | [short-time-interval-past] | express | this-utterance. |
|
I have just been saying this sentence. |
means that for a short time interval extending from the past to the present I have been expressing Example 10.27. Here the imaginary journey starts at the present, lays down one end point of the interval, moves into the past, and lays down the other endpoint. Another example:
| mi | pu | ze'aba | citka | le | mi | sanmi |
| I | [past] | [medium-time-interval-future] | eat | the | of-me | meal. |
|
For a medium time afterward, I ate my meal. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
I ate my meal for a while. |
With ca instead of ba , Example 10.28 becomes Example 10.29 ,
| mi | pu | ze'aca | citka | le | mi | sanmi |
| I | [past] | [medium-time-interval-present] | eat | the | of-me | meal. |
|
For a medium time before and afterward, I ate my meal. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
I ate my meal for a while. |
because the interval would then be centered on the past moment rather than oriented toward the future of that moment. The colloquial English translations are the same – English is not well-suited to representing this distinction.
Here are some examples of the use of space intervals with and without specified directions:
| ta | ri'u | ve'i | finpe |
| That-there | [right] | [short-space-interval] | is-a-fish. |
|
That thing on my right is a fish. |
In Example 10.30 , there is no equivalent in the colloquial English translation of the “small interval” which the fish occupies. Neither the Lojban nor the English expresses the orientation of the fish. Compare Example 10.31 :
| ta | ri'u | ve'ica'u | finpe |
| That-there | [right] | [short-space-interval-front] | is-a-fish. |
|
That thing on my right extending forwards is a fish. |
Here the space interval occupied by the fish extends from a point on my right to another point in front of the first point.
What is the significance of failing to specify an interval size of the type discussed in Section 10.5 ? The Lojban rule is that if no interval size is given, the size of the space or time interval is left vague by the speaker. For example:
really means:
At a moment in the past, and possibly other moments as well, the event “I went to the market” was in progress.
The vague or unspecified interval contains an instant in the speaker's past. However, there is no indication whether or not the whole interval is in the speaker's past! It is entirely possible that the interval during which the going-to-the-market is happening stretches into the speaker's present or even future.
Example 10.32 points up a fundamental difference between Lojban tenses and English tenses. An English past-tense sentence like “I went to the market” generally signifies that the going-to-the-market is entirely in the past; that is, that the event is complete at the time of speaking. Lojban pu has no such implication.
This property of a past tense is sometimes called “aorist” , in reference to a similar concept in the tense system of Classical Greek. All of the Lojban tenses have the same property, however:
does not imply (as the colloquial English translation does) that the tree is not green now. The vague interval throughout which the tree is, in fact, green may have already started.
This general principle does not mean that Lojban has no way of indicating that a tree will be green but is not yet green. Indeed, there are several ways of expressing that concept: see Section 10.10 (event contours) and Section 10.20 (logical connection between tenses).
The following cmavo are discussed in this section:
|
vi'i |
VIhA |
on a line |
|
vi'a |
VIhA |
in an area |
|
vi'u |
VIhA |
through a volume |
|
vi'e |
VIhA |
throughout a space/time interval |
The cmavo of ZEhA are sufficient to express time intervals. One fundamental difference between space and time, however, is that space is multi-dimensional. Sometimes we want to say not only that something moves over a small interval, but also perhaps that it moves in a line. Lojban allows for this. I can specify that a motion “in a small space” is more specifically “in a short line” , “in a small area” , or “through a small volume”.
What about the child walking on the ice in Example 10.23 through Example 10.25 ? Given the nature of ice, probably the area interpretation is most sensible. I can make this assumption explicit with the appropriate member of selma'o VIhA:
| le | verba | ve'a | vi'a | cadzu | le | bisli |
| The | child | [medium-space-interval] | [2-dimensional] | walks-on | the | ice. |
|
In a medium-sized area, the child walks on the ice. |
Space intervals can contain either VEhA or VIhA or both, but if both, VEhA must come first, as Example 10.34 shows.
The reader may wish to raise a philosophical point here. (Readers who don't wish to, should skip this paragraph.) The ice may be two-dimensional, or more accurately its surface may be, but since the child is three-dimensional, her walking must also be. The subjective nature of Lojban tense comes to the rescue here: the action is essentially planar, and the third dimension of height is simply irrelevant to walking. Even walking on a mountain could be called vi'a , because relatively speaking the mountain is associated with an essentially two-dimensional surface. Motion which is not confined to such a surface (e.g., flying, or walking through a three-dimensional network of tunnels, or climbing among mountains rather than on a single mountain) would be properly described with vi'u. So the cognitive, rather than the physical, dimensionality controls the choice of VIhA cmavo.
VIhA has a member vi'e which indicates a 4-dimensional interval, one that involves both space and time. This allows the spatial tenses to invade, to some degree, the temporal tenses; it is possible to make statements about space-time considered as an Einsteinian whole. (There are presently no cmavo of FAhA assigned to “pastward” and “futureward” considered as space rather than time directions – they could be added, though, if Lojbanists find space-time expression useful.) If a temporal tense cmavo is used in the same tense construct with a vi'e interval, the resulting tense may be self-contradictory.
The following cmavo is discussed in this section:
|
mo'i |
MOhI |
movement flag |
All the information carried by the tense constructs so far presented has been presumed to be static: the bridi is occurring somewhere or other in space and time, more or less remote from the speaker. Suppose the truth of the bridi itself depends on the result of a movement, or represents an action being done while the speaker is moving? This too can be represented by the tense system, using the cmavo mo'i (of selma'o MOhI) plus a spatial direction and optional distance; the direction now refers to a direction of motion rather than a static direction from the speaker.
| le | verba | mo'i | ri'u | cadzu | le | bisli |
| The | child | [movement] | [right] | walks-on | the | ice. |
|
The child walks toward my right on the ice. |
This is quite different from:
| le | verba | ri'u | cadzu | le | bisli |
| The | child | [right] | walks-on | the | ice. |
|
To the right of me, the child walks on the ice. |
In either case, however, the reference frame for defining “right” and “left” is the speaker's, not the child's. This can be changed thus:
| le | verba | mo'i | ri'u | cadzu | le | bisli |
| The | child | [movement] | [right] | walks-on | the | ice |
| ma'i | vo'a |
| in-reference-frame | the-x1-place. |
|
The child walks toward her right on the ice. |
Example 10.37 is analogous to Example 10.35. The cmavo ma'i belongs to selma'o BAI (explained in Section 9.6), and allows specifying a reference frame.
Both a regular and a mo'i -flagged spatial tense can be combined, with the mo'i construct coming last:
| le | verba | zu'avu | mo'i | ri'uvi | cadzu | le | bisli |
| The | child | [left-long] | [movement] | [right-short] | walks-on | the | ice. |
|
Far to the left of me, the child walks a short distance toward my right on the ice. |
It is not grammatical to use multiple directions like zu'a ca'u after mo'i , but complex movements can be expressed in a separate bridi.
Here is an example of a movement tense on a bridi not inherently involving movement:
| mi | mo'i | ca'uvu | citka | le | mi | sanmi |
| I | [movement] | [front-long] | eat | the | associated-with-me | meal. |
|
While moving a long way forward, I eat my meal. |
(Perhaps I am eating in an airplane.)
There is no parallel facility in Lojban at present for expressing movement in time – time travel – but one could be added easily if it ever becomes useful.
The following cmavo are discussed in this section:
|
di'i |
TAhE |
regularly |
|
na'o |
TAhE |
typically |
|
ru'i |
TAhE |
continuously |
|
ta'e |
TAhE |
habitually |
|
di'inai |
TAhE |
irregularly |
|
na'onai |
TAhE |
atypically |
|
ru'inai |
TAhE |
intermittently |
|
ta'enai |
TAhE |
contrary to habit |
|
roi |
ROI |
“n” times |
|
roinai |
ROI |
other than “n” times |
|
ze'e |
ZEhA |
whole time interval |
|
ve'e |
VEhA |
whole space interval |
Consider Lojban bridi which express events taking place in time. Whether a very short interval (a point) or a long interval of time is involved, the event may not be spread consistently throughout that interval. Lojban can use the cmavo of selma'o TAhE to express the idea of continuous or non-continuous actions.
| mi | puzu | ze'u | velckule |
| I | [past-long-distance] | [long-interval] | am-a-school-attendee (pupil). |
|
Long ago I attended school for a long time. |
probably does not mean that I attended school continuously throughout the whole of that long-ago interval. Actually, I attended school every day, except for school holidays. More explicitly,
| mi | puzu | ze'u | di'i | velckule |
| I | [past-long-distance] | [long-interval] | [regularly] | am-a-pupil. |
|
Long ago I regularly attended school for a long time. |
The four TAhE cmavo are differentiated as follows: ru'i covers the entirety of the interval, di'i covers the parts of the interval which are systematically spaced subintervals; na'o covers part of the interval, but exactly which part is determined by context; ta'e covers part of the interval, selected with reference to the behavior of the actor (who often, but not always, appears in the x1 place of the bridi).
Using TAhE does not require being so specific. Either the time direction or the time interval or both may be omitted (in which case they are vague). For example:
| mi | ba | ta'e | klama | le | zarci |
| I | [future] | [habitually] | go-to | the | market. |
| I | will | habitually | go to | the | market. |
|
I will make a habit of going to the market. |
specifies the future, but the duration of the interval is indefinite. Similarly,
illustrates an interval property in isolation. There are no distance or direction cmavo, so the point of time is vague; likewise, there is no interval cmavo, so the length of the interval during which these goings-to-the-market take place is also vague. As always, context will determine these vague values.
“Intermittently” is the polar opposite notion to “continuously” , and is expressed not with its own cmavo, but by adding the negation suffix -nai (which belongs to selma'o NAI) to ru'i. For example:
| le | verba | ru'inai | cadzu | le | bisli |
| The | child | [continuously-not] | walks-on | the | ice. |
|
The child intermittently walks on the ice. |
As shown in the cmavo table above, all the cmavo of TAhE may be negated with -nai ; ru'inai and di'inai are probably the most useful.
An intermittent event can also be specified by counting the number of times during the interval that it takes place. The cmavo roi (which belongs to selma'o ROI) can be appended to a number to make a quantified tense. Quantified tenses are common in English, but not so commonly named: they are exemplified by the adverbs “never” , “once” , “twice” , “thrice” , ... “always” , and by the related phrases “many times” , “a few times” , “too many times” , and so on. All of these are handled in Lojban by a number plus -roi :
With the quantified tense alone, we don't know whether the past, the present, or the future is intended, but of course the quantified tense need not stand alone:
The English is slightly over-specific here: it entails that both goings-to-the-market were in the past, which may or may not be true in the Lojban sentence, since the implied interval is vague. Therefore, the interval may start in the past but extend into the present or even the future.
Adding -nai to roi is also permitted, and has the meaning “other than (the number specified)” :
| le | ratcu | reroinai | citka | le | cirla |
| The | rat | [twice-not] | eats | the | cheese. |
|
The rat eats the cheese other than twice. |
This may mean that the rat eats the cheese fewer times, or more times, or not at all.
It is necessary to be careful with sentences like Example 10.45 and Example 10.47 , where a quantified tense appears without an interval. What Example 10.47 really says is that during an interval of unspecified size, at least part of which was set in the past, the event of my going to the market happened twice. The example says nothing about what happened outside that vague time interval. This is often less than we mean. If we want to nail down that I went to the market once and only once, we can use the cmavo ze'e which represents the “whole time interval” : conceptually, an interval which stretches from time's beginning to its end:
Since specifying no ZEhA leaves the interval vague, Example 10.47 might in appropriate context mean the same as Example 10.49 after all – but Example 10.49 allows us to be specific when specificity is necessary.
A PU cmavo following ze'e has a slightly different meaning from one that follows another ZEhA cmavo. The compound cmavo ze'epu signifies the interval stretching from the infinite past to the reference point (wherever the imaginary journey has taken you); ze'eba is the interval stretching from the reference point to the infinite future. The remaining form, ze'eca , makes specific the “whole of time” interpretation just given. These compound forms make it possible to assert that something has never happened without asserting that it never will.
| mi | ze'epu | noroi | klama | le | zarci |
| I | [whole-interval-past] | [never] | go-to | the | market. |
|
I have never gone to the market. |
says nothing about whether I might go in future.
The space equivalent of ze'e is ve'e , and it can be used in the same way with a quantified space tense: see Section 10.11 for an explanation of space interval modifiers.
The following cmavo are discussed in this section:
|
pu'o |
ZAhO |
prospective |
|
ca'o |
ZAhO |
continuitive |
|
ba'o |
ZAhO |
retrospective |
|
co'a |
ZAhO |
initiative |
|
co'u |
ZAhO |
cessitive |
|
mo'u |
ZAhO |
completitive |
|
za'o |
ZAhO |
superfective |
|
co'i |
ZAhO |
achievative |
|
de'a |
ZAhO |
pausative |
|
di'a |
ZAhO |
resumptive |
|
re'u |
ROI |
ordinal tense |
The cmavo of selma'o ZAhO express the Lojban version of what is traditionally called “aspect”. This is not a notion well expressed by English tenses, but many languages (including Chinese and Russian among Lojban's six source languages) consider it more important than the specification of mere position in time.
The “event contours” of selma'o ZAhO, with their bizarre keywords, represent the natural portions of an event considered as a process, an occurrence with an internal structure including a beginning, a middle, and an end. Since the keywords are scarcely self-explanatory, each ZAhO will be explained in detail here. Note that from the viewpoint of Lojban syntax, ZAhOs are interval modifiers like TAhEs or ROI compounds; if both are found in a single tense, the TAhE/ROI comes first and the ZAhO afterward. The imaginary journey described by other tense cmavo moves us to the portion of the event-as-process which the ZAhO specifies.
It is important to understand that ZAhO cmavo, unlike the other tense cmavo, specify characteristic portions of the event, and are seen from an essentially timeless perspective. The “beginning” of an event is the same whether the event is in the speaker's present, past, or future. It is especially important not to confuse the speaker-relative viewpoint of the PU tenses with the event-relative viewpoint of the ZAhO tenses.
The cmavo pu'o , ca'o , and ba'o (etymologically derived from the PU cmavo) refer to an event that has not yet begun, that is in progress, or that has ended, respectively:
| le | verba | ba'o | cadzu | le | bisli |
| The | child | [retrospective] | walks-on | the | ice. |
|
The child is no longer walking on the ice. |
As discussed in Section 10.6 , the simple PU cmavo make no assumptions about whether the scope of a past, present, or future event extends into one of the other tenses as well. Example 10.51 through Example 10.53 illustrate that these ZAhO cmavo do make such assumptions possible: the event in Example 10.51 has not yet begun, definitively; likewise, the event in Example 10.53 is definitely over.
Note that in Example 10.51 and Example 10.53 , pu'o and ba'o may appear to be reversed: pu'o , although etymologically connected with pu , is referring to a future event; whereas ba'o , connected with ba , is referring to a past event. This is the natural result of the event-centered view of ZAhO cmavo. The prospective, or pu'o , part of an event, is in the “pastward” portion of that event, when seen from the perspective of the event itself. It is only by inference that we suppose that Example 10.51 refers to the speaker's future: in fact, no PU tense is given, so the prospective part of the event need not be coincident with the speaker's present: pu'o is not necessarily, though in fact often is, the same as ca pu'o.
The cmavo in Example 10.51 through Example 10.53 refer to spans of time. There are also two points of time that can be usefully associated with an event: the beginning, marked by co'a , and the end, marked by co'u. Specifically, co'a marks the boundary between the pu'o and ca'o parts of an event, and co'u marks the boundary between the ca'o and ba'o parts:
| mi | ba | co'a | citka | le | mi | sanmi |
| I | [future] | [initiative] | eat | the | associated-with-me | meal. |
|
I will begin to eat my meal. |
| mi | pu | co'u | citka | le | mi | sanmi |
| I | [past] | [cessitive] | eat | the | associated-with-me | meal. |
|
I ceased eating my meal. |
Compare Example 10.54 with:
which illustrates the combination of a TAhE with a ZAhO.
A process can have two end points, one reflecting the “natural end” (when the process is complete) and the other reflecting the “actual stopping point” (whether complete or not). Example 10.55 may be contrasted with:
| mi | pu | mo'u | citka | le | mi | sanmi |
| I | [past] | [completitive] | eat | the | associated-with-me | meal. |
|
I finished eating my meal. |
In Example 10.57 , the meal has reached its natural end; in Example 10.55 , the meal has merely ceased, without necessarily reaching its natural end.
A process such as eating a meal does not necessarily proceed uninterrupted. If it is interrupted, there are two more relevant point events: the point just before the interruption, marked by de'a , and the point just after the interruption, marked by di'a. Some examples:
| mi | pu | de'a | citka | le | mi | sanmi |
| I | [past] | [pausative] | eat | the | associated-with-me | meal. |
|
I stopped eating my meal (with the intention of resuming). |
| mi | ba | di'a | citka | le | mi | sanmi |
| I | [future] | [resumptive] | eat | the | associated-with-me | meal. |
|
I will resume eating my meal. |
In addition, it is possible for a process to continue beyond its natural end. The span of time between the natural and the actual end points is represented by za'o :
| le | ctuca | pu | za'o | ciksi |
| The | teacher | [past] | [superfective] | explained |
| le | cmaci | seldanfu | le | tadgri |
| the | mathematics | problem | to-the | student-group. |
|
The teacher kept on explaining the mathematics problem to the class too long. |
That is, the teacher went on explaining after the class already understood the problem.
An entire event can be treated as a single moment using the cmavo co'i :
| la | .djan. | pu | co'i | catra | la | djim |
| That-named | John | [past] | [achievative] | kills | that-named | Jim. |
|
John was at the point in time where he killed Jim. |
Finally, since an activity is cyclical, an individual cycle can be referred to using a number followed by re'u , which is the other cmavo of selma'o ROI:
| mi | pare'u | klama | le | zarci |
| I | [first-time] | go-to | the | store. |
|
I go to the store for the first time (within a vague interval). |
Note the difference between:
| mi | pare'u | paroi | klama | le | zarci |
| I | [first-time] | [one-time] | go-to | the | store. |
|
For the first time, I go to the store once. |
and
| mi | paroi | pare'u | klama | le | zarci |
| I | [one-time] | [first-time] | go-to | the | store. |
|
There is one occasion on which I go to the store for the first time. |
The following cmavo is discussed in this section:
|
fe'e |
FEhE |
space interval modifier flag |
Like time intervals, space intervals can also be continuous, discontinuous, or repetitive. Rather than having a whole separate set of selma'o for space interval properties, we instead prefix the flag fe'e to the cmavo used for time interval properties. A space interval property would be placed just after the space interval size and/or dimensionality cmavo:
| ko | vi'i | fe'e | di'i | sombo | le | gurni |
| You-imperative | [1-dimensional] | [space:] | [regularly] | sow | the | grain. |
|
Sow the grain in a line and evenly! |
| mi | fe'e | ciroi | tervecnu | lo | selsalta |
| I | [space:] | [three-places] | buy | those-which-are | salad-ingredients. |
|
I buy salad ingredients in three locations. |
| ze'e | roroi | ve'e | fe'e | roroi | ku |
| [whole-time] | [all-times] | [whole-space] | [space:] | [all-places] |
| li | re | su'i | re | du | li | vo |
| The-number | 2 | + | 2 | = | the-number | 4. |
|
Always and everywhere, two plus two is four. |
As shown in Example 10.67 , when a tense comes first in a bridi, rather than in its normal position before the selbri (in this case du), it is emphasized.
The fe'e marker can also be used for the same purpose before members of ZAhO. (The cmavo be'a belongs to selma'o FAhA; it is the space direction meaning “north of”.)
| tu | ve'abe'a | fe'e | co'a | rokci |
| That-yonder | [medium-space-interval-north] | [space] | [initiative] | is-a-rock. |
|
That is the beginning of a rock extending to my north. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
That is the south face of a rock. |
Here the notion of a “beginning point” represented by the cmavo co'a is transferred from “beginning in time” to “beginning in space” under the influence of the fe'e flag. Space is not inherently oriented, unlike time, which flows from past to future: therefore, some indication of orientation is necessary, and the ve'abe'a provides an orientation in which the south face is the “beginning” and the north face is the “end” , since the rock extends from south (near me) to north (away from me).
Many natural languages represent time by a space-based metaphor: in English, what is past is said to be “behind us”. In other languages, the metaphor is reversed. Here, Lojban is representing space (or space interval modifiers) by a time-based metaphor: the choice of a FAhA cmavo following a VEhA cmavo indicates which direction is mapped onto the future. (The choice of future rather than past is arbitrary, but convenient for English-speakers.)
If both a TAhE (or ROI) and a ZAhO are present as space interval modifiers, the fe'e flag must be prefixed to each.
So far, we have seen tenses only just before the selbri, or (equivalently in meaning) floating about the bridi with ku. There is another major use for tenses in Lojban: as sumtcita, or argument tags. A tense may be used to add spatial or temporal information to a bridi as, in effect, an additional place:
| mi | klama | le | zarci | ca | le | nu | do | klama |
| I | go-to | the | market | [present] | the | event-of | you | go-to |
| le | zdani |
| the | house. |
|
I go to the market when you go to the house. |
Here ca does not appear before the selbri, nor with ku ; instead, it governs the following sumti, the le nu construct. What Example 10.69 asserts is that the action of the main bridi is happening at the same time as the event mentioned by that sumti. So ca , which means “now” when used with a selbri, means “simultaneously-with” when used with a sumti. Consider another example:
| mi | klama | le | zarci | pu | le | nu | do | pu | klama |
| I | go-to | the | market | [past] | the | event-of | you | [past] | go-to |
| le | zdani |
| the | house. |
The second pu is simply the past tense marker for the event of your going to the house, and says that this event is in the speaker's past. How are we to understand the first pu , the sumtcita?
All of our imaginary journeys so far have started at the speaker's location in space and time. Now we are specifying an imaginary journey that starts at a different location, namely at the event of your going to the house. Example 10.70 then says that my going to the market is in the past, relative not to the speaker's present moment, but instead relative to the moment when you went to the house. Example 10.70 can therefore be translated:
I had gone to the market before you went to the house.
(Other translations are possible, depending on the ever-present context.) Spatial direction and distance sumtcita are exactly analogous:
| le | ratcu | cu | citka | le | cirla | vi | le | panka |
| The | rat | eats | the | cheese | [short-distance] | the | park. |
|
The rat eats the cheese near the park. |
| le | ratcu | cu | citka | le | cirla | vi | le | vu | panka |
| The | rat | eats | the | cheese | [short-distance] | the | [long-distance] | park |
|
The rat eats the cheese near the faraway park. |
| le | ratcu | cu | citka | le | cirla | vu | le | vi | panka |
| The | rat | eats | the | cheese | [long-distance] | the | [short-distance] | park |
|
The rat eats the cheese far away from the nearby park. |
The event contours of selma'o ZAhO (and their space equivalents, prefixed with fe'e) are also useful as sumtcita. The interpretation of ZAhO tcita differs from that of FAhA, VA, PU, and ZI tcita, however. The event described in the sumti is viewed as a process, and the action of the main bridi occurs at the phase of the process which the ZAhO specifies, or at least some part of that phase. The action of the main bridi itself is seen as a point event, so that there is no issue about which phase of the main bridi is intended. For example:
| mi | morsi | ba'o | le | nu | mi | jmive |
| I | am-dead | [retrospective] | the | event-of | I | live. |
|
I am dead in the aftermath of my living. |
Here the (point-)event of my being dead is the portion of my living-process which occurs after the process is complete. Contrast Example 10.74 with:
As explained in Section 10.6 , Example 10.75 does not exclude the possibility that I died before I ceased to live!
Likewise, we might say:
which indicates that before my eating begins, I go to the store, whereas
would indicate that I go to the store after I am finished eating.
Here is an example which mixes temporal ZAhO (as a tense) and spatial ZAhO (as a sumtcita):
| le | bloti | pu | za'o | xelklama |
| The | boat | [past] | [superfective] | is-a-transport-mechanism |
| fe'e | ba'o | le | lalxu |
| [space] | [retrospective] | the | lake. |
|
The boat sailed for too long and beyond the lake. |
Probably it sailed up onto the dock. One point of clarification: although xelklama appears to mean simply “is-a-mode-of-transport” , it does not – the bridi of Example 10.78 has four omitted arguments, and thus has the (physical) journey which goes on too long as part of its meaning.
The remaining tense cmavo, which have to do with interval size, dimension, and continuousness (or lack thereof) are interpreted to let the sumti specify the particular interval over which the main bridi operates:
| mi | klama | le | zarci | reroi | le | ca | djedi |
| I | go-to | the | market | [twice] | the | [present] | day. |
|
I go/went/will go to the market twice today. |
Be careful not to confuse a tense used as a sumtcita with a tense used within a seltcita sumti:
| loi | snime | cu | carvi |
| Some-of-the-mass-of | snow | rains |
| ze'u | le | ca | dunra |
| [long-time-interval] | the | [present] | winter. |
|
Snow falls during this winter. |
claims that the interval specified by “this winter” is long, as events of snowfall go, whereas
| loi | snime | cu | carvi | ca | le | ze'u | dunra |
| Some-of-the-mass-of | snow | rains | [present] | the | [long-time] | winter. |
|
Snow falls in the long winter. |
claims that during some part of the winter, which is long as winters go, snow falls.
The following cmavo is discussed in this section:
|
ki |
KI |
sticky tense set/reset |
So far we have only considered tenses in isolated bridi. Lojban provides several ways for a tense to continue in effect over more than a single bridi. This property is known as “stickiness” : the tense gets “stuck” and remains in effect until explicitly “unstuck”. In the metaphor of the imaginary journey, the place and time set by a sticky tense may be thought of as a campsite or way-station: it provides a permanent origin with respect to which other tenses are understood. Later imaginary journeys start from that point rather than from the speaker.
To make a tense sticky, suffix ki to it:
| mi | puki | klama | le | zarci |
| I | [past-sticky] | go-to | the | market. |
| .i | le | nanmu | cu | batci | le | gerku |
| The | man | bites | the | dog. |
|
I went to the market. The man bit the dog. |
Here the use of puki rather than just pu ensures that the tense will affect the next sentence as well. Otherwise, since the second sentence is tenseless, there would be no way of determining its tense; the event of the second sentence might happen before, after, or simultaneously with that of the first sentence.
(The last statement does not apply when the two sentences form part of a narrative. See Section 10.14 for an explanation of “story time” , which employs a different set of conventions.)
What if the second sentence has a tense anyway?
| mi | puki | klama | le | zarci |
| I | [past-sticky] | go-to | the | market. |
| .i | le | nanmu | pu | batci | le | gerku |
| The | man | [past] | bites | the | dog. |
Here the second pu does not replace the sticky tense, but adds to it, in the sense that the starting point of its imaginary journey is taken to be the previously set sticky time. So the translation of Example 10.83 is:
and it is equivalent in meaning (when considered in isolation from any other sentences) to:
| mi | pu | klama | le | zarci |
| I | [past] | go-to | the | market. |
| .i | le | nanmu | pupu | batci | le | gerku |
| The | man | [past-past] | bites | the | dog. |
The point has not been discussed so far, but it is perfectly grammatical to have more than one tense construct in a sentence:
| puku | mi | ba | klama | le | zarci |
| [past] | I | [future] | go-to | the | market. |
|
Earlier, I was going to go to the market. |
Here there are two tenses in the same bridi, the first floating free and specified by puku , the second in the usual place and specified by ba. They are considered cumulative in the same way as the two tenses in separate sentences of Example 10.85. Example 10.86 is therefore equivalent in meaning, except for emphasis, to:
Compare Example 10.88 and Example 10.89 , which have a different meaning from Example 10.86 and Example 10.87 :
| mi | ba | klama | le | zarci | puku |
| I | [future] | go-to | the | market | [past]. |
|
I will have gone to the market earlier. |
So when multiple tense constructs in a single bridi are involved, order counts – the tenses cannot be shifted around as freely as if there were only one tense to worry about.
But why bother to allow multiple tense constructs at all? They specify separate portions of the imaginary journey, and can be useful in order to make part of a tense sticky. Consider Example 10.90 , which adds a second bridi and a ki to Example 10.86 :
| pu | ki | ku | mi | ba | klama | le | zarci |
| [past] | [sticky] | I | [future] | go-to | the | market. |
| .i | le | nanmu | cu | batci | le | gerku |
| The | man | bites | the | dog. |
What is the implied tense of the second sentence? Not puba , but only pu , since only pu was made sticky with ki. So the translation is:
I was going to go to the market. The man bit the dog.
Lojban has several ways of embedding a bridi within another bridi: descriptions, abstractors, relative clauses. (Technically, descriptions contain selbri rather than bridi.) Any of the selbri of these subordinate bridi may have tenses attached. These tenses are interpreted relative to the tense of the main bridi:
The significance of the ba'o in Example 10.91 is that the speaker's destination is described as being “in the aftermath of being a market” ; that is, it is a market no longer. In particular, the time at which it was no longer a market is in the speaker's past, because the ba'o is interpreted relative to the pu tense of the main bridi.
Here is an example involving an abstraction bridi:
| mi | ca | jinvi | le | du'u | mi | ba | morsi |
| I | now | opine | the | fact-that | I | will-be | dead. |
|
I now believe that I will be dead. |
Here the event of being dead is said to be in the future with respect to the opinion, which is in the present.
ki may also be used as a tense by itself. This cancels all stickiness and returns the bridi and all following bridi to the speaker's location in both space and time.
In complex descriptions, multiple tenses may be saved and then used by adding a subscript to ki. A time made sticky with kixipa (ki-sub-1) can be returned to by specifying kixipa as a tense by itself. In the case of written expression, the writer's here-and-now is often different from the reader's, and a pair of subscripted ki tenses could be used to distinguish the two.
Making strict use of the conventions explained in Section 10.13 would be intolerably awkward when a story is being told. The time at which a story is told by the narrator is usually unimportant to the story. What matters is the flow of time within the story itself. The term “story” in this section refers to any series of statements related in more-or-less time-sequential order, not just a fictional one.
Lojban speakers use a different set of conventions, commonly called “story time” , for inferring tense within a story. It is presumed that the event described by each sentence takes place some time more or less after the previous ones. Therefore, tenseless sentences are implicitly tensed as “what happens next”. In particular, any sticky time setting is advanced by each sentence.
The following mini-story illustrates the important features of story time. A sentence-by-sentence explication follows:
| pu | zu | ki | ku | ne'i | ki | le | kevna |
| [past] | [long] | [sticky] | [,] | [inside] | [sticky] | the | cave, |
| le | ninmu | goi | ko'a | zutse | le | rokci |
| the | woman | defined-as | she-1 | sat-on | the | rock |
|
Long ago, in a cave, a woman sat on a rock. |
| .i | ko'a | citka | loi | kanba | rectu |
| She-1 | eat-(tenseless) | some-of-the-mass-of | goat | flesh. |
|
She was eating goat's meat. |
| .i | ko'a | pu | jukpa | ri | le | mudyfagri |
| She | [past] | cook | the-last-mentioned | by-method-the | wood-fire. |
|
She had cooked the meat over a wood fire. |
| .i | le | labno | goi | ko'e |
| The | wolf | defined-as | it-2 |
| ba | za | ki | nenri | klama | le | kevna |
| [future] | [medium] | [sticky] | within | came | to-the | cave. |
|
A while later, a wolf came into the cave. |
| .i | ko'e | lebna | lei | rectu | ko'a |
| It-2 | takes-(tenseless) | the-mass-of | flesh | from-her-1. |
|
It took the meat from her. |
Example 10.93 sets both the time (long ago) and the place (in a cave) using ki , just like the sentence sequences in Section 10.13. No further space cmavo are used in the rest of the story, so the place is assumed to remain unchanged. The English translation of Example 10.93 is marked for past tense also, as the conventions of English storytelling require: consequently, all other English translation sentences are also in the past tense. (We don't notice how strange this is; even stories about the future are written in past tense!) This conventional use of past tense is not used in Lojban narratives.
Example 10.94 is tenseless. Outside story time, it would be assumed that its event happens simultaneously with that of Example 10.93 , since a sticky tense is in effect; the rules of story time, however, imply that the event occurs afterwards, and that the story time has advanced (changing the sticky time set in Example 10.93).
Example 10.95 has an explicit tense. This is taken relative to the latest setting of the sticky time; therefore, the event of Example 10.95 happens before that of Example 10.94. It cannot be determined if Example 10.95 happens before or after Example 10.93.
Example 10.96 is again tenseless. Story time was not changed by the flashback in Example 10.95 , so Example 10.96 happens after Example 10.94.
Example 10.97 specifies the future (relative to Example 10.96) and makes it sticky. So all further events happen after Example 10.97.
Example 10.98 and Example 10.99 are again tenseless, and so happen after Example 10.97. (Story time is changed.)
So the overall order is Example 10.93 - Example 10.95 - Example 10.94 - Example 10.96 - (medium interval) - Example 10.97 - Example 10.98 - Example 10.99. It is also possible that Example 10.95 happens before Example 10.93.
If no sticky time (or space) is set initially, the story is set at an unspecified time (or space): the effect is like that of choosing an arbitrary reference point and making it sticky. This style is common in stories that are jokes. The same convention may be used if the context specifies the sticky time sufficiently.
English has a set of rules, formally known as “sequence of tense rules” , for determining what tense should be used in a subordinate clause, depending on the tense used in the main sentence. Here are some examples:
In Example 10.100 and Example 10.101 , the tense of the main sentence is the present: “says”. If George goes when John speaks, we get the present tense “is going” ( “goes” would be unidiomatic); if George goes before John speaks, we get the past tense “went”. But if the tense of the main sentence is the past, with “said” , then the tense required in the subordinate clause is different. If George goes when John speaks, we get the past tense “went” ; if George goes before John speaks, we get the past-perfect tense “had gone”.
The rule of English, therefore, is that both the tense of the main sentence and the tense of the subordinate clause are understood relative to the speaker of the main sentence (not John, but the person who speaks Example 10.100 through Example 10.103).
Lojban, like Russian and Esperanto, uses a different convention. A tense in a subordinate bridi is understood to be relative to the tense already set in the main bridi. Thus Example 10.100 through Example 10.103 can be expressed in Lojban respectively thus:
| la | .djan. | ca | cusku | le | se | du'u |
| That-named | John | [present] | says | the | statement-that |
| la | .djordj. | ca | klama | le | zarci |
| That-named | George | [present] | goes-to | the | market. |
| la | .djan. | ca | cusku | le | se | du'u |
| That-named | John | [present] | says | the | statement-that |
| la | .djordj. | pu | klama | le | zarci |
| That-named | George | [past] | goes-to | the | market. |
| la | .djan. | pu | cusku | le | se | du'u |
| That-named | John | [past] | says | the | statement-that | |
| la | .djordj. | ca | klama | le | zarci | |
| That-named | George | [present] | goes-to | the | market. |
| la | .djan. | pu | cusku | le | se | du'u |
| That-named | John | [past] | says | the | statement-that |
| la | .djordj. | pu | klama | le | zarci |
| That-named | George | [past] | goes-to | the | market. |
Probably the most counterintuitive of the Lojban examples is Example 10.106. The ca looks quite odd, as if George were going to the market right now, rather than back when John spoke. But this ca is really a ca with respect to a reference point specified by the outer pu. This behavior is the same as the additive behavior of multiple tenses in the same bridi, as explained in Section 10.13.
There is a special cmavo nau (of selma'o CUhE) which can be used to override these rules and get to the speaker's current reference point. (Yes, it sounds like English “now”.) It is not grammatical to combine nau with any other cmavo in a tense, except by way of a logical or non-logical connection (see Section 10.20). Here is a convoluted sentence with several nested bridi which uses nau at the lowest level:
| la | .djan. | pu | cusku | le | se | du'u |
| That-named | John | [past] | says | the | statement-that |
| la | .alis | pu | cusku | le | se | du'u |
| That-named | Alice | [past] | says | the | statement-that |
| la | .djordj. | pu | cusku | le | se | du'u |
| That-named | George | [past] | says | the | statement-that |
| la | .maris. | nau | klama | le | zarci |
| That-named | Mary | [now] | goes-to | the | market. |
|
John said that Alice had said that George had earlier said that Mary is now going to the market. |
The use of nau does not affect sticky tenses.
The sumtcita method, explained in Section 10.12 , of asserting a tense relationship between two events suffers from asymmetry. Specifically,
| le | verba | cu | cadzu | le | bisli |
| The | child | walks-on | the | ice |
| zu'a | le | nu | le | nanmu | cu | batci | le | gerku |
| [left] | the | event-of | the | man | bites | the | dog. |
|
The child walks on the ice to the left of where the man bites the dog. |
which specifies an imaginary journey leftward from the man biting the dog to the child walking on the ice, claims only that the child walks on the ice. By the nature of le nu , the man's biting the dog is merely referred to without being claimed. If it seems desirable to claim both, each event can be expressed as a main sentence bridi, with a special form of .i connecting them:
| le | nanmu | cu | batci | le | gerku |
| The | man | bites | the | dog. |
| .izu'abo | le | verba | cu | cadzu | le | bisli |
| [Left] | the | child | walks-on | the | ice. |
|
The man bites the dog. To the left, the child walks on the ice. |
.izu'abo is a compound cmavo: the .i separates the sentences and the zu'a is the tense. The bo is required to prevent the zu'a from gobbling up the following sumti, namely le verba.
Note that the bridi in Example 10.110 appear in the reverse order from their appearance in Example 10.109. With .izu'abo (and all other afterthought tense connectives) the sentence specifying the origin of the journey comes first. This is a natural order for sentences, but requires some care when converting between this form and the sumtcita form.
Example 10.110 means the same thing as:
| le | nanmu | cu | batci | le | gerku | .i | zu'a | la'edi'u |
| The | man | bites | the | dog. | [Left] | the-referent-of-the-last-sentence |
| le | verba | cu | cadzu | le | bisli |
| the | child | walks-on | the | ice. |
|
The man bites the dog. Left of what I just mentioned, the child walks on the ice. |
If the bo is omitted in Example 10.110 , the meaning changes:
| le | nanmu | cu | batci | le | gerku |
| The | man | bites | the | dog. |
| .i | zu'a | le | verba | cu | cadzu | le | bisli | |
| [Left] | the | child | [something] | walks-on | the | ice. |
|
The man bites the dog. To the left of the child, something walks on the ice. |
Here the first place of the second sentence is unspecified, because zu'a has absorbed the sumti le verba.
Do not confuse either Example 10.110 or Example 10.112 with the following:
| le | nanmu | cu | batci | le | gerku |
| The | man | bites | the | dog. |
| .i | zu'aku | le | verba | cu | cadzu | le | bisli |
| [Left] | the | child | walks-on | the | ice. |
|
The man bites the dog. Left of me, the child walks on the ice. |
In Example 10.113 , the origin point is the speaker, as is usual with zu'aku. Example 10.110 makes the origin point of the tense the event described by the first sentence.
Two sentences may also be connected in forethought by a tense relationship. Just like afterthought tense connection, forethought tense connection claims both sentences, and in addition claims that the time or space relationship specified by the tense holds between the events the two sentences describe.
The origin sentence is placed first, preceded by a tense plus gi. Another gi is used to separate the sentences:
| pugi | mi | klama | le | zarci | gi | mi | klama | le | zdani |
| [past] | I | go-to | the | market | [,] | I | go-to | the | house. |
|
Before I go to the market, I go to the house. |
A parallel construction can be used to express a tense relationship between sumti:
Because English does not have any direct way of expressing a tense-like relationship between nouns, Example 10.115 cannot be expressed in English without paraphrasing it either into Example 10.114 or else into “I go to the house before the market” , which is ambiguous – is the market going?
Finally, a third forethought construction expresses a tense relationship between bridi-tails rather than whole bridi. (The construct known as a “bridi-tail” is explained fully in Section 14.9 ; roughly speaking, it is a selbri, possibly with following sumti.) Example 10.116 is equivalent in meaning to Example 10.114 and Example 10.115 :
| mi | pugi | klama | le | zarci | gi | klama | le | zdani |
| I | [past] | go-to | the | market | [,] | go-to | the | house. |
|
I, before going to the market, go to the house. |
In both Example 10.115 and Example 10.116 , the underlying sentences mi klama le zarci and mi klama le zdani are not claimed; only the relationship in time between them is claimed.
Both the forethought and the afterthought forms are appropriate with PU, ZI, FAhA, VA, and ZAhO tenses. In all cases, the equivalent forms are (where X and Y stand for sentences, and TENSE for a tense cmavo):
| subordinate | X TENSE le nu Y |
| afterthought coordinate | Y .i+TENSE+bo X |
| forethought coordinate | TENSE+gi Y gi X |
The Lojban tense system interacts with the Lojban logical connective system. That system is a separate topic, explained in Chapter 14 and touched on only in summary here. By the rules of the logical connective system, Example 10.117 through Example 10.119 are equivalent in meaning:
| la | .teris. | satre | le | mlatu | .ije | la | .teris. | satre | le | ractu |
|
Terry strokes the cat. And Terry strokes the rabbit. |
Suppose we wish to add a tense relationship to the logical connective “and” ? To say that Terry strokes the cat and later strokes the rabbit, we can combine a logical connective with a tense connective by placing the logical connective first, then the tense, and then the cmavo bo , thus:
| la | .teris. | satre | le | mlatu | .ijebabo | la | .teris. | satre | le | ractu |
|
Terry strokes the cat. And then Terry strokes the rabbit. |
| la | .teris. | satre | le | mlatu | gi'ebabo | satre | le | ractu |
|
Terry strokes the cat, and then strokes the rabbit. |
Example 10.120 through Example 10.122 are equivalent in meaning. They are also analogous to Example 10.117 through Example 10.119 respectively. The bo is required for the same reason as in Example 10.110 : to prevent the ba from functioning as a sumtcita for the following sumti (or, in Example 10.121 , from being attached to the following selbri).
In addition to the bo construction of Example 10.120 through Example 10.122 , there is also a form of tensed logical connective with ke … ke'e ( tu'e … tu'u for sentences). The logical connective system makes Example 10.123 through Example 10.125 equivalent in meaning:
| mi | bevri | le | dakli | .ije | tu'e | mi | bevri | le | gerku |
| I | carry | the | sack. | And | ( | I | carry | the | dog. |
| .ija | mi | bevri | le | mlatu | tu'u |
| And/or | I | carry | the | cat | ). |
|
I carry the sack. And I carry the dog, or I carry the cat, or I carry both. |
| mi | bevri | le | dakli | gi'eke | bevri | le | gerku | gi'a | bevri |
| I | carry | the | sack | and | (carry | the | dog | and/or | carry |
| le | mlatu |
| the | cat). |
|
I carry the sack, and also carry the dog or carry the cat or carry both. |
| mi | bevri | le | dakli | .eke | le | gerku | .a | le | mlatu |
| I | carry | the | sack | and | (the | dog | or | the | cat). |
|
I carry the sack and also the dog or the cat or both. |
Note the uniformity of the Lojban, as contrasted with the variety of ways in which the English provides for the correct grouping. In all cases, the meaning is that I carry the sack in any case, and either the cat or the dog or both.
To express that I carry the sack first (earlier in time), and then the dog or the cat or both simultaneously, I can insert tenses to form Example 10.126 through Example 10.128 :
| mi | bevri | le | dakli | .ije | ba | tu'e | mi | bevri | le | gerku |
| I | carry | the | sack. | And | [future] | ( | I | carry | the | dog. |
| .ija | cabo | mi | bevri | le | mlatu | tu'u |
| And/or | [present] | I | carry | the | cat. | ) |
|
I carry the sack. And then I will carry the dog or I will carry the cat or I will carry both at once. |
| mi | bevri | le | dakli | gi'e | bake | bevri | le | gerku |
| I | carry | the | sack | and | [future] | (carry | the | dog |
| gi'a | cabo | bevri | le | mlatu |
| and/or | [present] | carry | the | cat). |
|
I carry the sack and then will carry the dog or carry the cat or carry both at once. |
| mi | bevri | le | dakli | .e | bake | le | gerku |
| I | carry | the | sack | and | [future] | (the | dog |
| .a | cabo | le | mlatu |
| and/or | [present] | the | cat). |
|
I carry the sack, and then the dog or the cat or both at once. |
Example 10.126 through Example 10.128 are equivalent in meaning to each other, and correspond to the tenseless Example 10.123 through Example 10.125 respectively.
Any bridi which involves tenses of selma'o PU, FAhA, or ZAhO can be contradicted by a -nai suffixed to the tense cmavo. Some examples:
As a contradictory negation, Example 10.129 implies that the bridi as a whole is false without saying anything about what is true. When the negated tense is a sumtcita, -nai negation indicates that the stated relationship does not hold:
| mi | klama | le | zarci | ca | nai |
| I | go-to | the | market | [present] | [not] |
| le | nu | do | klama | le | zdani |
| the | event-of | you | go-to | the | house. |
|
It is not true that I went to the market at the same time that you went to the house. |
| le | nanmu | cu | batci | le | gerku | ne'inai | le | kumfa |
| The | man | bites | the | dog | [within-not] | the | room. |
|
The man didn't bite the dog inside the room. |
| mi | morsi | ca'onai | le | nu | mi | jmive |
| I | am-dead | [continuitive-negated] | the | event-of | I | live. |
|
It is false that I am dead during my life. |
It is also possible to perform scalar negation of whole tense constructs by placing a member of NAhE before them. Unlike contradictory negation, scalar negation asserts a truth: that the bridi is true with some tense other than that specified. The following examples are scalar negation analogues of Example 10.129 to Example 10.131 :
| mi | na'e | pu | klama | le | zarci |
| I | [non-] | [past] | go-to | the | market. |
|
I go to the market other than in the past. |
| le | nanmu | cu | batci | le | gerku | to'e | ne'i | le | kumfa |
| The | man | bites | the | dog | [opposite-of] | [within] | the | room. |
|
The man bites the dog outside the room. |
| mi | klama | le | zarci | na'e | ca | le | nu |
| I | go-to | the | market | [non-] | [present] | the | event-of |
| do | klama | le | zdani |
| you | go-to | the | house. |
|
I went to the market at a time other than the time at which you went to the house. |
| mi | morsi | na'e | ca'o | le | nu | mi | jmive |
| I | am-dead | [non-] | [continuitive] | the | event-of | I | live. |
|
I am dead other than during my life. |
An example of scalar negation of FAhA:
| le | verba | na'e | ri'u | cadzu | le | bisli |
| The | child | [non-] | [right] | walks-on | the | ice |
|
The child walks on the ice other than to my right. |
The use of -nai on cmavo of TAhE and ROI has already been discussed in Section 10.9 ; this use is also a scalar negation.
The following cmavo are discussed in this section:
|
ca'a |
CAhA |
actually is |
|
ka'e |
CAhA |
is innately capable of |
|
nu'o |
CAhA |
can but has not |
|
pu'i |
CAhA |
can and has |
Lojban bridi without tense markers may not necessarily refer to actual events: they may also refer to capabilities or potential events. For example:
is a Lojban truth, even though the colloquial English translation is false or at best ambiguous. This is because the tenseless Lojban bridi doesn't necessarily claim that every duck is swimming or floating now or even at a specific time or place. Even if we add a tense marker to Example 10.138 ,
| ro | datka | ca | flulimna |
| All | ducks | [present] | are-float-swimmers. |
|
All ducks are now swimming by floating. |
the resulting Example 10.139 might still be considered a truth, even though the colloquial English seems even more likely to be false. All ducks have the potential of swimming even if they are not exercising that potential at present. To get the full flavor of “All ducks are now swimming” , we must append a marker from selma'o CAhA to the tense, and say:
| ro | datka | ca | ca'a | flulimna |
| All | ducks | [present] | [actual] | are-float-swimmers. |
|
All ducks are now actually swimming by floating. |
A CAhA cmavo is always placed after any other tense cmavo, whether for time or for space. However, a CAhA cmavo comes before ki , so that a CAhA condition can be made sticky.
Example 10.140 is false in both Lojban and English, since it claims that the swimming is an actual, present fact, true of every duck that exists, whereas in fact there is at least one duck that is not swimming now.
Furthermore, some ducks are dead (and therefore sink); some ducks have just hatched (and do not know how to swim yet), and some ducks have been eaten by predators (and have ceased to exist as separate objects at all). Nevertheless, all these ducks have the innate capability of swimming – it is part of the nature of duckhood. The cmavo ka'e expresses this notion of innate capability:
| ro | datka | ka'e | flulimna |
| All | ducks | [capable] | are-float-swimmers. |
|
All ducks are innately capable of swimming. |
Under some epistemologies, innate capability can be extended in order to apply the innate properties of a mass to which certain individuals belong to the individuals themselves, even if those individuals are themselves not capable of fulfilling the claim of the bridi. For example:
| la | .djan. | ka'e | viska |
| That-named | John | [capable] | sees. |
|
John is innately capable of seeing. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
John can see. |
might be true about a human being named John, even though he has been blind since birth, because the ability to see is innately built into his nature as a human being. It is theoretically possible that conditions might occur that would enable John to see (a great medical discovery, for example). On the other hand,
is not true in most epistemologies, since the ability to see is not part of the innate nature of a book.
Consider once again the newly hatched ducks mentioned earlier. They have the potential of swimming, but have not yet demonstrated that potential. This may be expressed using nu'o , the cmavo of CAhA for undemonstrated potential:
| ro | cifydatka | nu'o | flulimna |
| All | infant-ducks | [can-but-has-not] | are-float-swimmers. |
|
All infant ducks have an undemonstrated potential for swimming by floating. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Baby ducks can swim but haven't yet. |
Contrariwise, if Frank is not blind from birth, then pu'i is appropriate:
| la | .frank. | pu'i | viska |
| That-named | Frank | [can-and-has] | sees. |
|
Frank has demonstrated a potential for seeing. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Frank can see and has seen. |
Note that the glosses given at the beginning of this section for ca'a , nu'o , and pu'i incorporate ca into their meaning, and are really correct for ca ca'a , ca nu'o , and ca pu'i. However, the CAhA cmavo are perfectly meaningful with other tenses than the present:
| la | .frank. | ba | nu'o | klama | le | zarci |
| That-named | Frank | [future] | [can-but-has-not] | goes-to | the | store. |
|
Frank could have, but will not have, gone to the store (at some understood moment in the future). |
As always in Lojban tenses, a missing CAhA can have an indeterminate meaning, or the context can be enough to disambiguate it. Saying
with no CAhA specified can translate the two very different English sentences “That is on fire” and “That is inflammable.” The first demands immediate action (usually), whereas the second merely demands caution. The two cases can be disambiguated with:
and
When no indication is given, as in the simple observative
the prudent Lojbanist will assume the meaning “Fire!”
Like many things in Lojban, tenses may be logically connected; logical connection is explained in more detail in Chapter 14. Some of the terminology in this section will be clear only if you already understand logical connectives.
The appropriate logical connectives belong to selma'o JA. A logical connective between tenses can always be expanded to one between sentences:
| mi | pu | je | ba | klama | le | zarci |
| I | [past] | and | [future] | go-to | the | market. |
|
I went and will go to the market. |
means the same as:
| mi | pu | klama | le | zarci |
| I | [past] | go-to | the | market. |
| .ije | mi | ba | klama | le | zarci |
| And | I | [future] | go-to | the | market. |
|
I went to the market, and I will go to the market. |
Tense connection and tense negation are combined in:
| mi | punai | je | canai | je | ba | klama | le | zarci |
| I | [past-not] | and | [present-not] | and | [future] | go-to | the | market. |
|
I haven't yet gone to the market, but I will in future. |
Example 10.154 is far more specific than
which only says that I will go, without claiming anything about my past or present. ba does not imply punai or canai ; to compel that interpretation, either a logical connection or a ZAhO is needed.
Tense negation can often be removed in favor of negation in the logical connective itself. The following examples are equivalent in meaning:
| mi | mo'izu'anai | je | mo'iri'u | cadzu |
| I | [motion-left-not] | and | [motion-right] | walk. |
|
I walk not leftward but rightward. |
| mi | mo'izu'a | naje | mo'iri'u | cadzu |
| I | [motion-left] | not-and | [motion-right] | walk. |
|
I walk not leftward but rightward. |
There are no forethought logical connections between tenses allowed by the grammar, to keep tenses simpler. Nor is there any way to override simple left-grouping of the connectives, the Lojban default.
The non-logical connectives of selma'o JOI, BIhI, and GAhO are also permitted between tenses. One application is to specify intervals not by size, but by their end-points ( bi'o belongs to selma'o BIhI, and connects the end-points of an ordered interval, like English “from ... to”):
| mi | puza | bi'o | bazu | vasxu |
| I | [past-medium] | from…to | [future-long] | breathe. |
|
I breathe from a medium time ago till a long time to come. |
(It is to be hoped that I have a long life ahead of me.)
One additional use of non-logical connectives within tenses is discussed in Section 10.21. Other uses will probably be identified in future.
Another application of non-logical tense connection is to talk about sub-events of events. Consider a six-shooter: a gun which can fire six bullets in succession before reloading. If I fire off the entire magazine twice, I can express the fact in Lojban thus:
| mi | reroi | pi'u | xaroi | celgau |
| I | [twice] | [cross-product] | [six-times] | shoot |
| le | seldanti |
| the | projectile-launcher. |
|
On two occasions, I fire the gun six times. |
It would be confusing, though grammatical, to run the reroi and the xaroi directly together. However, the non-logical connective pi'u expresses a Cartesian product (also known as a cross product) of two sets. In this case, there is a set of two firings each of which is represented by a set of six shots, for twelve shots in all (hence the name “product” : the product of 2 and 6 is 12). Its use specifies very precisely what occurs.
In fact, you can specify strings of interval properties and event contours within a single tense without the use of a logical or non-logical connective cmavo. This allows tenses of the type:
| la | .djordj. | ca'o | co'a | ciska |
| That-named | George | [continuitive] | [initiative] | writes. |
|
George continues to start to write. |
| mi | reroi | ca'o | xaroi | darxi | le | damri |
| I | [twice] | [continuitive] | [six-times] | hit | the | drum. |
|
On two occasions, I continue to beat the drum six times. |
The following cmavo are discussed in this section:
|
jai |
JAI |
tense conversion |
|
fai |
FA |
indefinite place |
Conversion is the regular Lojban process of moving around the places of a place structure. The cmavo of selma'o SE serve this purpose, exchanging the first place with one of the others:
It is also possible to bring a place that is specified by a sumtcita (for the purposes of this chapter, a tense sumtcita) to the front, by using jai plus the tense as the grammatical equivalent of SE:
| le | ratcu | cu | citka | le | cirla | vi | le | panka |
| The | rat | eats | the | cheese | [short-distance] | the | park. |
|
The rat eats the cheese in the park. |
| le | panka | cu | jai vi | citka | le | cirla | fai | le | ratcu |
| The | park | is-the-place-of | eating | the | cheese | by | the | rat. |
|
The park is where the rat eats the cheese. |
In Example 10.165 , the construction JAI+tense converts the location sumti into the first place. The previous first place has nowhere to go, since the location sumti is not a numbered place; however, it can be inserted back into the bridi with fai , the indefinite member of selma'o FA.
(The other members of FA are used to mark the first, second, etc. places of a bridi explicitly:
means the same as
as well as the simple
in which the place structure is determined by position.)
Like SE conversion, JAI+tense conversion is especially useful in descriptions with LE selma'o:
Here the eater of the cheese is elided, so no fai appears.
Of course, temporal tenses are also usable with JAI:
| mi | djuno | fi | le | jai | ca | morsi | be | fai | la | .djan. | |
| I | know | about | the | [present] | is-dead | of | that-named | “John” | . |
|
I know the time of John's death. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
I know when John died. |
Grammatically, every use of tenses seen so far is exactly paralleled by some use of modals as explained in Chapter 9. Modals and tenses alike can be followed by sumti, can appear before the selbri, can be used in pure and mixed connections, can participate in JAI conversions. The parallelism is perfect. However, there is a deep difference in the semantics of tense constructs and modal constructs, grounded in historical differences between the two forms. Originally, modals and tenses were utterly different things in earlier versions of Loglan; only in Lojban have they become grammatically interchangeable. And even now, differences in semantics continue to be maintained.
The core distinction is that whereas the modal bridi
| mi | nelci | do | mu'i | le | nu | do | nelci | mi |
| I | like | you | with-motivation | the | event-of | you | like | me. |
|
I like you because you like me. |
places the le nu sumti in the x1 place of the gismu mukti (which underlies the modal mu'i), namely the motivating event, the tensed bridi
| mi | nelci | do | ba | le | nu | do | nelci | mi |
| I | like | you | after | the | event-of | you | like | me. |
|
I like you after you like me. |
places the le nu sumti in the x2 place of the gismu balvi (which underlies the tense ba), namely the point of reference for the future tense. Paraphrases of Example 10.171 and Example 10.172 , employing the brivla mukti and balvi explicitly, would be:
| le | nu | do | nelci | mi | cu | mukti | le | nu |
| The | event-of | you | like | me | motivates | the | event-of |
| mi | nelci | do |
| I | like | you. |
|
Your liking me is the motive for my liking you. |
and
| le | nu | mi | nelci | do | cu | balvi | le | nu |
| The | event-of | I | like | you | is-after | the | event-of |
| do | nelci | mi |
| you | like | me. |
|
My liking you follows (in time) your liking me. |
(Note that the paraphrase is not perfect due to the difference in what is claimed; Example 10.173 and Example 10.174 claim only the causal and temporal relationships between the events, not the existence of the events themselves.)
As a result, the afterthought sentence-connective forms of Example 10.171 and Example 10.172 are, respectively:
In Example 10.175 , the order of the two bridi mi nelci do and do nelci mi is the same as in Example 10.171. In Example 10.176 , however, the order is reversed: the origin point do nelci mi physically appears before the future-time event mi nelci do. In both cases, the bridi characterizing the event in the x2 place appears before the bridi characterizing the event in the x1 place of mukti or balvi.
In forethought connections, however, the asymmetry between modals and tenses is not found. The forethought equivalents of Example 10.175 and Example 10.176 are
and
respectively.
The following modal sentence schemata (where X and Y represent sentences) all have the same meaning:
| X .i BAI bo Y |
| BAI gi Y gi X |
| X BAI le nu Y |
whereas the following tensed sentence schemata also have the same meaning:
| X .i TENSE bo Y |
| TENSE gi X gi Y |
| Y TENSE le nu X |
neglecting the question of what is claimed. In the modal sentence schemata, the modal tag is always followed by Y, the sentence representing the event in the x1 place of the gismu that underlies the BAI. In the tensed sentences, no such simple rule exists.
The following cmavo is discussed in this section:
|
cu'e |
CUhE |
tense question |
There are two main ways to ask questions about tense. The main English tense question words are “When?” and “Where?”. These may be paraphrased respectively as “At what time?” and “At what place?” In these forms, their Lojban equivalents simply involve a tense plus ma , the Lojban sumti question:
| do | klama | le | zdani | ca | ma |
| You | go-to | the | house | [present] | [what-sumti?]. |
| You | go-to | the | house | at | what-time? |
|
When do you go to the house? |
| le | verba | vi | ma | pu | cadzu | le | bisli |
| The | child | [short-space] | [what-sumti?] | [past] | walks-on | the | ice. |
| The | child | at/near | what-place | walked-on | the | ice? |
|
Where did the child walk on the ice? |
There is also a non-specific tense and modal question, cu'e , belonging to selma'o CUhE. This can be used wherever a tense or modal construct can be used.
| le | nanmu | cu'e | batci | le | gerku |
| The | man | [what-tense?] | bites | the | dog. |
|
When/Where/How does the man bite the dog? |
Possible answers to Example 10.181 might be:
or even the modal reply (from selma'o BAI; see Section 9.6):
The only way to combine cu'e with other tense cmavo is through logical connection, which makes a question that pre-specifies some information:
| do | puzi | je | cu'e | sombo | le | gurni |
| You | [past-short] | and | [when?] | sow | the | grain? |
|
You sowed the grain a little while ago; when else do you sow it? |
Additionally, the logical connective itself can be replaced by a question word:
| la | .artr. | pu | je'i | ba | nolraitru |
| That-named | Arthur | [past] | [which?] | [future] | is-a-king |
|
Was Arthur a king or will he be? |
Answers to Example 10.188 would be logical connectives such as je , meaning “both” , naje meaning “the latter” , or jenai meaning “the former”.
It is a limitation of the VA and ZI system of specifying magnitudes that they can only prescribe vague magnitudes: small, medium, or large. In order to express both an origin point and an exact distance, the Lojban construction called a “termset” is employed. (Termsets are explained further in Section 14.11 and Section 16.7.) It is grammatical for a termset to be placed after a tense or modal tag rather than a sumti, which allows both the origin of the imaginary journey and its distance to be specified. Here is an example:
| la | .frank. | sanli | zu'a | nu'i | la | .djordj. |
| That-named | Frank | stands | [left] | [start-termset] | George |
| la'u | lo | mitre | be | li | mu | [nu'u] |
| [quantity] | a | thing-measuring-in-meters | the-number | 5 | [end-termset]. |
|
Frank is standing five meters to the left of George. |
Here the termset extends from the nu'i to the implicit nu'u at the end of the sentence, and includes the terms la .djordj. , which is the unmarked origin point, and the tagged sumti lo mitre be li mu , which the cmavo la'u (of selma'o BAI, and meaning “with quantity” ; see Section 9.6) marks as a quantity. Both terms are governed by the tag zu'a
It is not necessary to have both an origin point and an explicit magnitude: a termset may have only a single term in it. A less precise version of Example 10.189 is:
| la | .frank. | sanli | zu'a | nu'i | la'u |
| That-named | Frank | stands | [left] | [termset] | [quantity] |
| lo | mitre | be | li | mu |
| a | thing-measuring-in-meters | the-number | 5. |
|
Frank stands five meters to the left. |
- PU
-
temporal direction
pu
past
ca
present
ba
future
- ZI
-
temporal distance
zi
short
za
medium
zu
long
- ZEhA
-
temporal interval
ze'i
short
ze'a
medium
ze'u
long
ze'e
infinite
- ROI
-
objective quantified tense flag
noroi
never
paroi
once
[N]roi
[N] times
roroi
always
pare'u
the first time
rere'u
the second time
[N]re'u
the [N]th time
- TAhE
-
subjective quantified tense
di'i
regularly
na'o
typically
ru'i
continuously
ta'e
habitually
- ZAhO
-
event contours
see Section 10.10
- FAhA
-
spatial direction
see Section 10.28
- VA
-
spatial distance
vi
short
va
medium
vu
long
- VEhA
-
spatial interval
ve'i
short
ve'a
medium
ve'u
long
ve'e
infinite
- VIhA
-
spatial dimensionality
vi'i
line
vi'a
plane
vi'u
space
vi'e
space-time
- FEhE
-
spatial interval modifier flag
fe'enoroi
nowhere
fe'eroroi
everywhere
fe'eba'o
beyond
etc.
- MOhI
-
spatial movement flag
mo'i
motion
see Section 10.28
- KI
-
set or reset sticky tense
- CUhE
-
tense question, reference point
cu'e
asks for a tense or aspect
nau
use speaker's reference point
- JAI
-
tense conversion
jaica
the time of
jaivi
the place of
etc.
The following list of FAhA cmavo gives rough English glosses for the cmavo, first when used without mo'i to express a direction, and then when used with mo'i to express movement in the direction. When possible, the gismu from which the cmavo is derived is also listed.
|
bu'u |
coincident with ; at the same place as |
||
|
ca'u |
crane |
in front (of) |
forward |
|
ti'a |
trixe |
behind |
backward |
|
zu'a |
zunle |
on the left (of) |
leftward |
|
ri'u |
pritu |
on the right (of) |
rightward |
|
ga'u |
gapru |
above |
upward(ly) |
|
ni'a |
cnita |
below |
downward(ly) |
|
ne'i |
nenri |
within |
into |
|
ru'u |
sruri |
surrounding |
orbiting |
|
pa'o |
pagre |
transfixing |
passing through |
|
ne'a |
next to |
moving while next to |
|
|
te'e |
bordering |
moving along the border (of) |
|
|
re'o |
adjacent (to) |
along |
|
|
fa'a |
farna |
towards |
arriving at |
|
to'o |
away from |
departing from |
|
|
zo'i |
inward (from) |
approaching |
|
|
ze'o |
outward (from) |
receding from |
|
|
zo'a |
tangential (to) |
passing (by) |
|
|
be'a |
berti |
north (of) |
northward(ly) |
|
ne'u |
snanu |
south (of) |
southward(ly) |
|
du'a |
stuna |
east (of) |
eastward(ly) |
|
vu'a |
west (of) |
westward(ly) |
Special note on fa'a , to'o , zo'i , and ze'o :
zo'i and ze'o refer to direction towards or away from the speaker's location, or whatever the origin is.
fa'a and to'o refer to direction towards or away from some other point.

The purpose of the feature of Lojban known as “abstraction” is to provide a means for taking whole bridi and packaging them up, as it were, into simple selbri. Syntactically, abstractions are very simple and uniform; semantically, they are rich and complex, with few features in common between one variety of abstraction and another. We will begin by discussing syntax without regard to semantics; as a result, the notion of abstraction may seem unmotivated at first. Bear with this difficulty until Section 11.2.
An abstraction selbri is formed by taking a full bridi and preceding it by any cmavo of selma'o NU. There are twelve such cmavo; they are known as “abstractors”. The bridi is closed by the elidable terminator kei , of selma'o KEI. Thus, to change the bridi
into an abstraction using nu , one of the members of selma'o NU, we change it into
The bridi may be a simple selbri, or it may have associated sumti, as here. It is important to beware of eliding kei improperly, as many of the common uses of abstraction selbri involve following them with words that would appear to be part of the abstraction if kei had been elided.
(Technically, kei is never necessary, because the elidable terminator vau that closes every bridi can substitute for it; however, kei is specific to abstractions, and using it is almost always clearer.)
The grammatical uses of an abstraction selbri are exactly the same as those of a simple brivla. In particular, abstraction selbri may be used as observatives, as in Example 11.2 , or used in tanru:
| la | .djan. | cu | nu | sonci | kei | djica | ||
| That-named | John | is-an | (event-of | being-a-soldier | ) | type-of | desirer. |
|
John wants to be a soldier. |
Abstraction selbri may also be used in descriptions, preceded by le (or any other member of selma'o LE):
We will most often use descriptions containing abstraction either at the end of a bridi, or just before the main selbri with its cu ; in either of these circumstances, kei can normally be elided.
The place structure of an abstraction selbri depends on the particular abstractor, and will be explained individually in the following sections.
Note: In glosses of bridi within abstractions, the grammatical form used in the English changes. Thus, in the gloss of Example 11.2 we see “my going-to the store” rather than “I go-to the store” ; likewise, in the glosses of Example 11.3 and Example 11.4 we see “being-a-soldier” rather than “is-a-soldier”. This procedure reflects the desire for more understandable glosses, and does not indicate any change in the Lojban form. A bridi is a bridi, and undergoes no change when it is used as part of an abstraction selbri.
The following cmavo is discussed in this section:
|
nu |
NU |
event abstractor |
The examples in Section 11.1 made use of nu as the abstractor, and it is certainly the most common abstractor in Lojban text. Its purpose is to capture the event or state of the bridi considered as a whole. Do not confuse the le description built on a nu abstraction with ordinary descriptions based on le alone. The following sumti are quite distinct:
Example 11.5 through Example 11.9 are descriptions that isolate the five individual sumti places of the selbri klama. Example 11.10 describes something associated with the bridi as a whole: the event of it.
In Lojban, the term “event” is divorced from its ordinary English sense of something that happens over a short period of time. The description:
is an event which lasts for the whole of my life (under normal circumstances). On the other hand,
is relatively brief by comparison (again, under normal circumstances).
We can see from Example 11.10 through Example 11.12 that ellipsis of sumti is valid in the bridi of abstraction selbri, just as in the main bridi of a sentence. Any sumti may be ellipsized if the listener will be able to figure out from context what the proper value of it is, or else to recognize that the proper value is unimportant. It is extremely common for nu abstractions in descriptions to have the x1 place ellipsized:
is elliptical, and most probably means:
In the proper context, of course, Example 11.13 could refer to the event of somebody else swimming. Its English equivalent, “I like swimming” , can't be interpreted as “I like Frank's swimming” ; this is a fundamental distinction between English and Lojban. In Lojban, an omitted sumti can mean whatever the context indicates that it should mean.
Note that the lack of an explicit NU cmavo in a sumti can sometimes hide an implicit abstraction. In the context of Example 11.14 , the appearance of le se nelci ( “that which is liked”) is in effect an abstraction:
which in this context means
My swimming happens often.
Event descriptions with le nu are commonly used to fill the “under conditions...” places, among others, of gismu and lujvo place structures:
| la | .lojban. | cu | frili | mi | |
| That-named | Lojban | is-easy-for | me |
| le | nu | mi | tadni | [kei] | |
| under-conditions | the | event-of | I | study |
|
Lojban is easy for me when I study. |
(The “when” of the English would also be appropriate for a construction involving a Lojban tense, but the Lojban sentence says more than that the studying is concurrent with the ease.)
The place structure of a nu abstraction selbri is simply:
x1 is an event of (the bridi)
The following cmavo are discussed in this section:
|
mu'e |
NU |
point-event abstractor |
|
pu'u |
NU |
process abstractor |
|
zu'o |
NU |
activity abstractor |
|
za'i |
NU |
state abstractor |
Event abstractions with nu suffice to express all kinds of events, whether long, short, unique, repetitive, or whatever. Lojban also has more finely discriminating machinery for talking about events, however. There are four other abstractors of selma'o NU for talking about four specific types of events, or four ways of looking at the same event.
An event considered as a point in time is called a “point-event” , or sometimes an “achievement”. (This latter word should be divorced, in this context, from all connotations of success or triumph.) A point-event can be extended in duration, but it is still a point-event if it is thought of as unitary, having no internal structure. The abstractor mu'e means “point-event-of” :
| le | mu'e | la | .djan. | catra | la | .djim. | cu | zekri |
| The | point-event-of | (that-named | John | kills | that-named | Jim) | is-a-crime. |
|
John's killing Jim (considered as a point in time) is a crime. |
An event considered as extended in time, and structured with a beginning, a middle containing one or more stages, and an end, is called a “process”. The abstractor pu'u means “process-of” :
| ca'o | le | pu'u | le | latmo | balje'a | cu | porpi | kei |
| [continuitive] | the | process-of( | the | Latin | great-state | breaking-up | ) |
| so'i | je'atru | cu | selcatra |
| many | state-rulers | were-killed |
|
During the fall of the Roman Empire, many Emperors were killed. |
An event considered as extended in time and cyclic or repetitive is called an “activity”. The abstractor zu'o means “activity-of” :
| mi | tatpi | ri'a | le | zu'o | mi | plipe |
| I | am-tired | because-of | the | activity-of | (I | jump). |
|
I am tired because I jump. |
An event considered as something that is either happening or not happening, with sharp boundaries, is called a “state”. The abstractor za'i means “state-of” :
| le | za'i | mi | jmive | cu | ckape | do |
| The | state-of | (I | am-alive) | is-dangerous-to | you. |
|
My being alive is dangerous to you. |
The abstractors in Example 11.17 through Example 11.20 could all have been replaced by nu , with some loss of precision. Note that Lojban allows every sort of event to be viewed in any of these four ways:
-
the “state of running” begins when the runner starts and ends when the runner stops;
-
the “activity of running” consists of the cycle “lift leg, step forward, drop leg, lift other leg...” (each such cycle is a process, but the activity consists in the repetition of the cycle);
-
the “process of running” puts emphasis on the initial sprint, the steady speed, and the final slowdown;
-
the “achievement of running” is most alien to English, but sees the event of running as a single indivisible thing, like “Pheidippides' run from Marathon to Athens” (the original marathon).
Further information on types of events can be found in Section 11.12.
The four event type abstractors have the following place structures:
mu'e : x1 is a point event of (the bridi)
pu'u : x1 is a process of (the bridi) with stages x2
za'i : x1 is a continuous state of (the bridi) being true
zu'o : x1 is an activity of (the bridi) consisting of repeated actions x2
The following cmavo are discussed in this section:
|
ka |
NU |
property abstractor |
|
ce'u |
KOhA |
abstraction focus |
The things described by le nu descriptions (or, to put it another way, the things of which nu selbri may correctly be predicated) are only moderately “abstract”. They are still closely tied to happenings in space and time. Properties, however, are much more ethereal. What is “the property of being blue” , or “the property of being a go-er” ? They are what logicians call “intensions”. If John has a heart, then “the property of having a heart” is an abstract object which, when applied to John, is true. In fact,
has the same truth conditions as
| la | .djan. | cu | ckaji |
| That-named | John | has-the-property |
| le | ka | se risna | [zo'e] | [kei] |
| the | property-of | having-as-heart | something. |
|
John has the property of having a heart. |
(The English word “have” frequently appears in any discussion of Lojban properties: things are said to “have” properties, but this is not the same sense of “have” as in “I have money” , which is possession.)
Property descriptions, like event descriptions, are often wanted to fill places in brivla place structures:
| do | cnino | mi | le | ka | xunre | [kei] |
| You | are-new | to-me | in-the-quality-of-the | property-of | being-red. |
|
You are new to me in redness. |
(The English suffix “-ness” often signals a property abstraction, as does the suffix “-ity”.)
It would be suitable to use Example 11.23 to someone who has returned from the beach with a sunburn.
There are several different properties that can be extracted from a bridi, depending on which place of the bridi is “understood” as being specified externally. Thus:
is quite different from
In particular, sentences like Example 11.26 and Example 11.27 are quite different in meaning:
| la | .djan. | cu | zmadu | la | .djordj. |
| That-named | John | exceeds | that-named | George |
| le | ka | mi | prami | |
| in-the | property-of | (I | love | X) |
|
I love John more than I love George. |
| la | .djan. | cu | zmadu | la | .djordj. |
| That-named | John | exceeds | that-named | George |
| le | ka | prami | mi | |
| in-the | property of | (X | loves | me). |
|
John loves me more than George loves me. |
The “X” used in the glosses of Example 11.26 through Example 11.27 as a place-holder cannot be represented only by ellipsis in Lojban, because ellipsis means that there must be a specific value that can fill the ellipsis, as mentioned in Section 11.2. Instead, the cmavo ce'u of selma'o KOhA is employed when an explicit sumti is wanted. (The form “X” will be used in literal translations.)
Therefore, an explicit equivalent of Example 11.26 , with no ellipsis, is:
| la | .djan. | cu | zmadu | la | .djordj. |
| That-named | John | exceeds | that-named | George |
| le | ka | mi | prami | ce'u |
| in-the | property-of | (I | love | X). |
and of Example 11.27 is:
| la | .djan. | cu | zmadu | la | .djordj. |
| That-named | John | exceeds | that-named | George |
| le | ka | ce'u | prami | mi |
| in-the | property-of | (X | loves | me). |
This convention allows disambiguation of cases like:
into
| le | ka | ce'u | dunda | le | xirma | [zo'e] | [kei] | |
| the | property-of | (X | is-a-giver-of | the | horse | to | someone-unspecified | ) |
|
the property of being a giver of the horse |
which is the most natural interpretation of Example 11.30 , versus
| le | ka | [zo'e] | dunda | le | xirma | ce'u | [kei] | |
| the | property-of | (someone-unspecified | is-a-giver-of | the | horse | to | X | ) |
|
the property of being one to whom the horse is given |
which is also a possible interpretation.
It is also possible to have more than one ce'u in a ka abstraction, which transforms it from a property abstraction into a relationship abstraction. Relationship abstractions “package up” a complex relationship for future use; such an abstraction can be translated back into a selbri by placing it in the x2 place of the selbri bridi , whose place structure is:
bridi x1 is a predicate relationship with relation x2 (abstraction) among arguments (sequence/set) x3
The place structure of ka abstraction selbri is simply:
ka x1 is a property of (the bridi)
The following cmavo is discussed in this section:
|
ni |
NU |
amount abstraction |
Amount abstractions are far more limited than event or property abstractions. They really make sense only if the selbri of the abstracted bridi is subject to measurement of some sort. Thus we can speak of:
| le | ni | le | pixra | cu | blanu | [kei] |
| the | amount-of | (the | picture | being-blue | ) |
|
the amount of blueness in the picture |
because “blueness” could be measured with a colorimeter or a similar device. However,
| le | ni | la | .djein. | cu | mamta | [kei] |
| the | amount-of | (that-named | Jane | being-a-mother | ) |
|
the amount of Jane's mother-ness (?) |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
the amount of mother-ness in Jane (?) |
makes very little sense in either Lojban or English. We simply do not have any sort of measurement scale for being a mother.
Semantically, a sumti with le ni is a number; however, it cannot be treated grammatically as a quantifier in Lojban unless prefixed by the mathematical cmavo mo'e :
| li | pa | vu'u | mo'e | le | ni | |
| the-number | 1 | minus | the-operand | the | amount-of | ( |
| le | pixra | cu | blanu | [kei] |
| the | picture | being-blue | ) |
|
1 - B , where B = blueness of the picture |
Mathematical Lojban is beyond the scope of this chapter, and is explained more fully in Chapter 18.
Whenever we talk of measurement of an amount, there is some sort of scale, and so the place structure of ni abstraction selbri is:
ni x1 is the amount of (the bridi) on scale x2
Note: the best way to express the x2 places of abstract sumti is to use something like le ni ... kei be. See Example 11.59 for the use of this construction.
The “blueness of the picture” discussed in Section 11.5 refers to the measurable amount of blue pigment (or other source of blueness), not to the degree of truth of the claim that blueness is present. That abstraction is expressed in Lojban using jei , which is closely related semantically to ni. In the simplest cases, le jei produces not a number but a truth value:
| le | jei | li | re | su'i | re | du | li | vo | [kei] |
| the | truth-value-of | the-number | 2 | + | 2 | = | the-number | 4 |
|
the truth of 2 + 2 being 4 |
is equivalent to “truth” , and
| le | jei | li | re | su'i | re | du | li | mu | [kei] |
| the | truth-value-of | the-number | 2 | + | 2 | = | the-number | 5 |
|
the truth of 2 + 2 being 5 |
is equivalent to “falsehood”.
However, not everything in life (or even in Lojban) is simply true or false. There are shades of gray even in truth value, and jei is Lojban's mechanism for indicating the shade of grey intended:
| mi | ba | jdice | tu'a | le | jei | la | .djordj. |
| I | [future] | decide | on | the | (truth-value of | that-named | George |
| cu | zekri | gasnu | [kei] |
| being-a-(crime | doer) | ). |
|
I will decide on the topic of whether George is a criminal. |
Example 11.38 does not imply that George is, or is not, definitely a criminal. Depending on the legal system I am using, I may make some intermediate decision. As a result, jei requires an x2 place analogous to that of ni :
jei x1 is the truth value of (the bridi) under epistemology x2
Abstractions using jei are the mechanism for fuzzy logic in Lojban; the jei abstraction refers to a number between 0 and 1 inclusive (as distinct from ni abstractions, which are often on open-ended scales). The detailed conventions for using jei in fuzzy-logic contexts have not yet been established.
The following cmavo is discussed in this section:
|
du'u |
NU |
predication abstraction |
There are some selbri which demand an entire predication as a sumti; they make claims about some predication considered as a whole. Logicians call these the “propositional attitudes” , and they include (in English) things like knowing, believing, learning, seeing, hearing, and the like. Consider the English sentence:
How's that in Lojban? Let us try:
Not quite right. Events are actually or potentially physical, and can't be contained inside one's mind, except for events of thinking, feeling, and the like; Example 11.40 comes close to claiming that Frank's being-a-fool is purely a mental activity on the part of the speaker. (In fact, Example 11.40 is an instance of improperly marked “sumti raising” , a concept discussed further in Section 11.10 , a properly marked sumti-raising would be mi djuno tu'a le nu la .frank. cu bebna [kei]).
Try again:
Closer. Example 11.41 says that I know whether or not Frank is a fool, but doesn't say that he is one, as Example 11.39 does. To catch that nuance, we must say:
Now we have it. Note that the implied assertion “Frank is a fool” is not a property of le du'u abstraction, but of djuno ; we can only know what is in fact true. (As a result, djuno like jei has a place for epistemology, which specifies how we know.) Example 11.43 has no such implied assertion:
and here du'u could probably be replaced by tu'a le jei without much change in meaning:
| mi | kucli | tu'a | le | jei | la | .frank. | cu | bebna | [kei] |
|
I am curious about how true it is that Frank is a fool. |
As a matter of convenience rather than logical necessity, du'u has been given an x2 place, which is a sentence (piece of language) expressing the bridi:
du'u x1 is the predication (the bridi), expressed in sentence x2
and le se du'u ... is very useful in filling places of selbri which refer to speaking, writing, or other linguistic behavior regarding bridi:
| la | .djan. | cusku | le | se du'u |
| That-named | John | expresses | the | (sentence-expressing-that |
| la | .djordj. | klama | le | zarci | [kei] |
| that-named | George | goes-to | the | store | ) |
|
John says that George goes to the store. |
Example 11.45 differs from
| la | djan | cusku | lu |
| That-named | John | expresses, | quote, |
| la | .djordj. | klama | le | zarci | li'u |
| that-named | George | goes | to-the | store, | unquote. |
|
John says “George goes to the store”. |
because Example 11.46 claims that John actually said the quoted words, whereas Example 11.45 claims only that he said some words or other which were to the same purpose.
le se du'u is much the same as lu'e le du'u , a symbol for the predication, but se du'u can be used as a selbri, whereas lu'e is ungrammatical in a selbri. (See Section 6.10 for a discussion of lu'e.)
The following cmavo is discussed in this section:
|
kau |
UI |
indirect question marker |
There is an alternative type of sentence involving du'u and a selbri expressing a propositional attitude. In addition to sentences like
we can also say things like
This form is called an “indirect question” in English because the embedded English sentence is a question: “Who went to the store?” A person who says Example 11.48 is claiming to know the answer to this question. Indirect questions can occur with many other English verbs as well: I can wonder, or doubt, or see, or hear, as well as know who went to the store.
To express indirect questions in Lojban, we use a le du'u abstraction, but rather than using a question word like “who” ( ma in Lojban), we use any word that will fit grammatically and mark it with the suffix particle kau. This cmavo belongs to selma'o UI, so grammatically it can appear anywhere. The simplest Lojban translation of Example 11.48 is therefore:
| mi | djuno | le | du'u |
| I | know | the | predication-of |
| ma | kau | pu | klama | le | zarci |
| X | [indirect-question] | [past] | going-to | the | store. |
In Example 11.49 , we have chosen to use ma as the word marked by kau. In fact, any other sumti would have done as well: zo'e or da or even la .djan.. Using la .djan. would suggest that it was John who I knew had gone to the store, however:
| mi | djuno | le | du'u |
| I | know | the | predication-of/fact-that |
| la | .djan. | kau | pu | klama | le | zarci |
| that-named | John | [indirect-question] | [past] | going-to | the | store. |
|
I know who went to the store, namely John. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
I know that it was John who went to the store. |
Using one of the indefinite pro-sumti such as ma , zo'e , or da does not suggest any particular value.
Why does Lojban require the kau marker, rather than using ma as English and Chinese and many other languages do? Because ma always signals a direct question, and so
| mi | djuno | le | du'u | ma | pu | klama | le | zarci |
| I | know | the | predication-of | [what sumti?] | [past] | goes-to | the | store |
means
It is actually not necessary to use le du'u and kau at all if the indirect question involves a sumti; there is generally a paraphrase of the type:
| mi | djuno | fi | le | pu | klama | be | le | zarci |
| I | know | about | the | [past] | goer | to | the | store. |
|
I know something about the one who went to the store (namely, his identity). |
because the x3 place of djuno is the subject of knowledge, as opposed to the fact that is known. But when the questioned point is not a sumti, but (say) a logical connection, then there is no good alternative to kau :
| mi | ba | zgana | le | du'u | la | .djan. |
| I | [future] | observe | the | predication-of/fact-that | that-named | John |
| jikau | la | .djordj. | cu | zvati | le | panka |
| [connective-indirect-question] | that-named | George | is-at | the | park. |
|
I will see whether John or George (or both) is at the park. |
In addition, Example 11.53 is only a loose paraphrase of Example 11.49 , because it is left to the listener's insight to realize that what is known about the goer-to-the-store is his identity rather than some other of his attributes.
The following cmavo are discussed in this section:
|
li'i |
NU |
experience abstractor |
|
si'o |
NU |
concept abstractor |
|
su'u |
NU |
general abstractor |
There are three more abstractors in Lojban, all of them little used so far. The abstractor li'i expresses experience:
The abstractor si'o expresses a mental image, a concept, an idea:
Finally, the abstractor su'u is a vague abstractor, whose meaning must be grasped from context:
| ko | zgana | le | su'u | le | ci | smacu | cu | bajra |
| you [imperative] | observe | the | abstract-nature-of | the | three | mice | running |
|
See how the three mice run! |
All three of these abstractors have an x2 place. An experience requires an experiencer, so the place structure of li'i is:
li'i x1 is the experience of (the bridi) as experienced by x2
Similarly, an idea requires a mind to hold it, so the place structure of si'o is:
si'o x1 is the idea/concept of (the bridi) in the mind of x2
Finally, there needs to be some way of specifying just what sort of abstraction su'u is representing, so its place structure is:
su'u x1 is an abstract nature of (the bridi) of type x2
The x2 place of su'u allows it to serve as a substitute for any of the other abstractors, or as a template for creating new ones. For example,
can be paraphrased as
and there is a book whose title might be rendered in Lojban as:
| le | su'u | la | .iecuas. |
| the | abstract-nature-of | (that-named | Jesus |
| kuctai | selcatra | kei |
| is-an-intersect-shape | type-of-killed-one | ) |
| be | lo | sa'ordzifa'a |
| of-type | a | slope-low-direction |
| ke | nalmatma'e | sutyterjvi |
| type-of | non-motor-vehicle | speed-competition |
|
The Crucifixion of Jesus Considered As A Downhill Bicycle Race |
Note the importance of using kei after su'u when the x2 of su'u (or any other abstractor) is being specified; otherwise, the be lo ends up inside the abstraction bridi.
The following cmavo are discussed in this section:
|
tu'a |
LAhE |
an abstraction involving |
|
jai |
JAI |
abstraction conversion |
It is sometimes inconvenient, in a situation where an abstract description is logically required, to express the abstraction. In English we can say:
which in Lojban is:
| mi | troci | le | nu | [mi] | gasnu |
| I | try | the | event-of | (I | am-agent-in |
| le | nu | le | vorme | cu | karbi'o |
| the | event-of | (the | door | open-becomes)). |
which has an abstract description within an abstract description, quite a complex structure. In English (but not in all other languages), we may also say:
where it is understood that what I try is actually not the door itself, but the act of opening it. The same simplification can be done in Lojban, but it must be marked explicitly using a cmavo. The relevant cmavo is tu'a , which belongs to selma'o LAhE. The Lojban equivalent of Example 11.63 is:
The term “sumti-raising” , as in the title of this section, signifies that a sumti which logically belongs within an abstraction (or even within an abstraction which is itself inside an intermediate abstraction) is “raised” to the main bridi level. This transformation from Example 11.62 to Example 11.64 loses information: nothing except convention tells us what the abstraction was.
Using tu'a is a kind of laziness: it makes speaking easier at the possible expense of clarity for the listener. The speaker must be prepared for the listener to respond something like:
which indicates that tu'a le vorme cannot be understood. (The terminator for tu'a is lu'u , and is used in Example 11.65 to make clear just what is being questioned: the sumti-raising, rather than the word vorme as such.) An example of a confusing raised sumti might be:
This must mean that something which John does, or which happens to John, occurs frequently: but without more context there is no way to figure out what. Note that without the tu'a , Example 11.66 would mean that John considered as an event frequently occurs – in other words, that John has some sort of on-and-off existence! Normally we do not think of people as events in English, but the x1 place of cafne is an event, and if something that does not seem to be an event is put there, the Lojbanic listener will attempt to construe it as one. (Of course, this analysis assumes that .djan. is the name of a person, and not the name of some event.)
Logically, a counterpart of some sort is needed to tu'a which transposes an abstract sumti into a concrete one. This is achieved at the selbri level by the cmavo jai (of selma'o JAI). This cmavo has more than one function, discussed in Section 9.12 and Section 10.22 ; for the purposes of this chapter, it operates as a conversion of selbri, similarly to the cmavo of selma'o SE. This conversion changes
| tu'a | mi | rinka | le | nu | do | morsi |
| something-to-do-with | me | causes | the | event-of | you | are-dead |
|
My action causes your death. |
into
| mi | jai | rinka | le | nu | do | morsi |
| I | am-associated-with | causing | the | event-of | your | death. |
|
I cause your death. |
In English, the subject of “cause” can either be the actual cause (an event), or else the agent of the cause (a person, typically); not so in Lojban, where the x1 of rinka is always an event. Example 11.67 and Example 11.68 look equally convenient (or inconvenient), but in making descriptions, Example 11.68 can be altered to:
| le | jai | rinka | be | le | nu | do | morsi | |
| that-which-is | associated-with | causing | ( | the | event-of | your | death | ) |
|
the one who caused your death |
because jai modifies the selbri and can be incorporated into the description – not so for tu'a.
The weakness of jai used in descriptions in this way is that it does not specify which argument of the implicit abstraction is being raised into the x1 place of the description selbri. One can be more specific by using the modal form of jai explained in Section 9.12 :
This section is a logical continuation of Section 11.3.
There exists a relationship between the four types of events explained in Section 11.3 and the event contour tense cmavo of selma'o ZAhO. The specific cmavo of NU and of ZAhO are mutually interdefining; the ZAhO contours were chosen to fit the needs of the NU event types and vice versa. Event contours are explained in full in Section 10.10 , and only summarized here.
The purpose of ZAhO cmavo is to represent the natural portions of an event, such as the beginning, the middle, and the end. They fall into several groups:
-
The cmavo pu'o , ca'o , and ba'o represent spans of time: before an event begins, while it is going on, and after it is over, respectively.
-
The cmavo co'a , de'a , di'a , and co'u represent points of time: the start of an event, the temporary stopping of an event, the resumption of an event after a stop, and the end of an event, respectively. Not all events can have breaks in them, in which case de'a and di'a do not apply.
-
The cmavo mo'u and za'o correspond to co'u and ba'o respectively, in the case of those events which have a natural ending point that may not be the same as the actual ending point: mo'u refers to the natural ending point, and za'o to the time between the natural ending point and the actual ending point (the “excessive” or “superfective” part of the event).
-
The cmavo co'i represents an entire event considered as a point-event or achievement.
All these cmavo are applicable to events seen as processes and abstracted with pu'u. Only processes have enough internal structure to make all these points and spans of time meaningful.
For events seen as states and abstracted with za'i , the meaningful event contours are the spans pu'o , ca'o , and ba'o ; the starting and ending points co'a and co'u , and the achievement contour co'i. States do not have natural endings distinct from their actual endings. (It is an open question whether states can be stopped and resumed.)
For events seen as activities and abstracted with zu'o , the meaningful event contours are the spans pu'o , ca'o , and ba'o , and the achievement contour co'i. Because activities are inherently cyclic and repetitive, the beginning and ending points are not well-defined: you do not know whether an activity has truly begun until it begins to repeat.
For events seen as point-events and abstracted with mu'e , the meaningful event contours are the spans pu'o and ba'o but not ca'o (a point-event has no duration), and the achievement contour co'i.
Note that the parts of events are themselves events, and may be treated as such. The points in time may be seen as mu'e point-events; the spans of time may constitute processes or activities. Therefore, Lojban allows us to refer to processes within processes, activities within states, and many other complicated abstract things.
An abstractor may be replaced by two or more abstractors joined by logical or non-logical connectives. Connectives are explained in detail in Chapter 14.
| le | mikce | cu | se | cinri | le | pu'u | jenai | za'i | mi | sipna |
|
The doctor is interested in the process of me sleeping but not in the state of me sleeping. |
This feature of Lojban has hardly ever been used, and nobody knows what uses it may eventually have.
The following table gives each abstractor, an English gloss for it, a Lojban gismu which is connected with it (more or less remotely: the associations between abstractors and gismu are meant more as memory hooks than for any kind of inference), the rafsi associated with it, and (on the following line) its place structure.
|
nu |
event of |
fasnu |
nun |
x1 is an event of (the bridi) |
|
ka |
property of |
ckaji |
kam |
x1 is a property of (the bridi) |
|
ni |
amount of |
klani |
nil |
x1 is an amount of (the bridi) measured on scale x2 |
|
jei |
truth-value of |
jetnu |
jez |
x1 is a truth-value of (the bridi) under epistemology x2 |
|
li'i |
experience of |
lifri |
liz |
x1 is an experience of (the bridi) to experiencer x2 |
|
si'o |
idea of |
sidbo |
siz |
x1 is an idea/concept of (the bridi) in the mind of x2 |
|
du'u |
predication of |
----- |
dum |
x1 is the bridi (the bridi) expressed by sentence x2 |
|
su'u |
abstraction of |
sucta |
suv |
x1 is an abstract nature of (the bridi) |
|
za'i |
state of |
zasti |
zaz |
x1 is a state of (the bridi) |
|
zu'o |
activity of |
zukte |
zum |
x1 is an activity of (the bridi) |
|
pu'u |
process of |
pruce |
puv |
x1 is a process of (the bridi) |
|
mu'e |
point-event of |
mulno |
muf |
x1 is a point-event/achievement of (the bridi) |
The Lojban vocabulary is founded on its list of 1350-plus gismu, made up by combining word lists from various sources. These gismu are not intended to be either a complete vocabulary for the language nor a minimal list of semantic primitives. Instead, the gismu list serves as a basis for the creation of compound words, or lujvo. The intention is that (except in certain semantically broad but shallow fields such as cultures, nations, foods, plants, and animals) suitable lujvo can be devised to cover the ten million or so concepts expressible in all the world's languages taken together. Grammatically, lujvo behave just like gismu: they have place structures and function as selbri.
There is a close relationship between lujvo and tanru. In fact, lujvo are condensed forms of tanru:
contains a tanru which can be reduced to the lujvo in:
Although the lujvo fagyfesti is derived from the tanru fagri festi , it is not equivalent in meaning to it. In particular, fagyfesti has a distinct place structure of its own, not the same as that of festi. (In contrast, the tanru does have the same place structure as festi.) The lujvo needs to take account of the places of fagri as well. When a tanru is made into a lujvo, there is no equivalent of be … bei … be'o (described in Section 5.7) to incorporate sumti into the middle of the lujvo.
So why have lujvo? Primarily to reduce semantic ambiguity. On hearing a tanru, there is a burden on the listener to figure out what the tanru might mean. Adding further terms to the tanru reduces ambiguity in one sense, by providing more information; but it increases ambiguity in another sense, because there are more and more tanru joints, each with an ambiguous significance. Since lujvo, like other brivla, have a fixed place structure and a single meaning, encapsulating a commonly-used tanru into a lujvo relieves the listener of the burden of creative understanding. In addition, lujvo are typically shorter than the corresponding tanru.
There are no absolute laws fixing the place structure of a newly created lujvo. The maker must consider the place structures of all the components of the tanru and then decide which are still relevant and which can be removed. What is said in this chapter represents guidelines, presented as one possible standard, not necessarily complete, and not the only possible standard. There may well be lujvo that are built without regard for these guidelines, or in accordance with entirely different guidelines, should such alternative guidelines someday be developed. The reason for presenting any guidelines at all is so that Lojbanists have a starting point for deciding on a likely place structure – one that others seeing the same word can also arrive at by similar consideration.
If the tanru includes connective cmavo such as bo , ke , ke'e , or je , or conversion or abstraction cmavo such as se or nu , there are ways of incorporating them into the lujvo as well. Sometimes this makes the lujvo excessively long; if so, the cmavo may be dropped. This leads to the possibility that more than one tanru could produce the same lujvo. Typically, however, only one of the possible tanru is useful enough to justify making a lujvo for it.
The exact workings of the lujvo-making algorithm, which takes a tanru built from gismu (and possibly cmavo) and produces a lujvo from it, are described in Section 4.11.
The meaning of a lujvo is controlled by – but is not the same as – the meaning of the tanru from which the lujvo was constructed. The tanru corresponding to a lujvo is called its veljvo in Lojban, and since there is no concise English equivalent, that term will be used in this chapter. Furthermore, the left (modifier) part of a tanru will be called the seltau , and the right (modified) part the tertau , following the usage of Chapter 5. For brevity, we will speak of the seltau or tertau of a lujvo, meaning of course the seltau or tertau of the veljvo of that lujvo. (If this terminology is confusing, substituting “modifier” for seltau and “modified” for tertau may help.)
The place structure of a tanru is always the same as the place structure of its tertau. As a result, the meaning of the tanru is a modified version of the meaning of the tertau; the tanru will typically, but not always, refer to a subset of the things referred to by the tertau.
The purpose of a tanru is to join concepts together without necessarily focusing on the exact meaning of the seltau. For example, in the Iliad , the poet talks about “the wine-dark sea” , in which “wine” is a seltau relative to “dark” , and the pair of words is a seltau relative to “sea”. We're talking about the sea, not about wine or color. The other words are there to paint a scene in the listener's mind, in which the real action will occur, and to evoke relations to other sagas of the time similarly describing the sea. Logical inferences about wine or color will be rejected as irrelevant.
As a simple example, consider the rather non-obvious tanru klama zdani , or “goer-house”. The gismu zdani has two places:
(but in this chapter we will use simply “house” , for brevity), and the gismu klama has five:
The tanru klama zdani will also have two places, namely those of zdani. Since a klama zdani is a type of zdani , we can assume that all goer-houses – whatever they may be – are also houses.
But is knowing the places of the tertau everything that is needed to understand the meaning of a tanru? No. To see why, let us switch to a less unlikely tanru: gerku zdani , literally “dog house”. A tanru expresses a very loose relation: a gerku zdani is a house that has something to do with some dog or dogs. What the precise relation might be is left unstated. Thus, the meaning of lo gerku zdani can include all of the following: houses occupied by dogs, houses shaped by dogs, dogs which are also houses (e.g. houses for fleas), houses named after dogs, and so on. All that is essential is that the place structure of zdani continues to apply.
For something (call it z1) to qualify as a gerku zdani in Lojban, it's got to be a house, first of all. For it to be a house, it's got to house someone (call that z2). Furthermore, there's got to be a dog somewhere (called g1). For g1 to count as a dog in Lojban, it's got to belong to some breed as well (called g2). And finally, for z1 to be in the first place of gerku zdani , as opposed to just zdani , there's got to be some relationship (called r) between some place of zdani and some place of gerku. It doesn't matter which places, because if there's a relationship between some place of zdani and any place of gerku , then that relationship can be compounded with the relationship between the places of gerku - namely, gerku itself – to reach any of the other gerku places. Thus, if the relationship turns out to be between z2 and g2, we can still state r in terms of z1 and g1: “the relationship involves the dog g1, whose breed has to do with the occupant of the house z1”.
Doubtless to the relief of the reader, here's an illustration. We want to find out whether the White House (the one in which the U. S. President lives, that is) counts as a gerku zdani. We go through the five variables. The White House is the z1. It houses Bill Clinton as z2, as of this writing, so it counts as a zdani. Let's take a dog – say, Spot (g1). Spot has to have a breed; let's say it's a Saint Bernard (g2). Now, the White House counts as a gerku zdani if there is any relationship (r) at all between the White House and Spot. (We'll choose the g1 and z1 places to relate by r; we could have chosen any other pair of places, and simply gotten a different relationship.)
The sky is the limit for r; it can be as complicated as “The other day, g1 (Spot) chased Socks, who is owned by Chelsea Clinton, who is the daughter of Bill Clinton, who lives in z1 (the White House)” or even worse. If no such r can be found, well, you take another dog, and keep going until no more dogs can be found. Only then can we say that the White House cannot fit into the first place of gerku zdani.
As we have seen, no less than five elements are involved in the definition of gerku zdani : the house, the house dweller, the dog, the dog breed (everywhere a dog goes in Lojban, a dog breed follows), and the relationship between the house and the dog. Since tanru are explicitly ambiguous in Lojban, the relationship r cannot be expressed within a tanru (if it could, it wouldn't be a tanru any more!) All the other places, however, can be expressed – thus:
| la | blabi | zdani | cu | gerku | be | fa | la | .spot. |
| That-named | White | House | is-a-dog | ( | namely | that-named | Spot |
| bei | la | .sankt. | .berNARD. | be'o |
| of-breed | that-named | Saint | Bernard | ) |
| zdani | la | .bil. | .klinton. |
| type-of-house-for | that-named | Bill | Clinton. |
Not the most elegant sentence ever written in either Lojban or English. Yet if there is any relation at all between Spot and the White House, Example 12.5 is arguably true. If we concentrate on just one type of relation in interpreting the tanru gerku zdani , then the meaning of gerku zdani changes. So if we understand gerku zdani as having the same meaning as the English word “doghouse” , the White House would no longer be a gerku zdani with respect to Spot, because as far as we know Spot does not actually live in the White House, and the White House is not a doghouse (derogatory terms for incumbents notwithstanding).
This is a fairly long way to go to try and work out how to say “doghouse” ! The reader can take heart; we're nearly there. Recall that one of the components involved in fixing the meaning of a tanru – the one left deliberately vague – is the precise relation between the tertau and the seltau. Indeed, fixing this relation is tantamount to giving an interpretation to the ambiguous tanru.
A lujvo is defined by a single disambiguated instance of a tanru. That is to say, when we try to design the place structure of a lujvo, we don't need to try to discover the relation between the tertau and the seltau. We already know what kind of relation we're looking for; it's given by the specific need we wish to express, and it determines the place structure of the lujvo itself.
Therefore, it is generally not appropriate to simply devise lujvo and decide on place structures for them without considering one or more specific usages for the coinage. If one does not consider specifics, one will be likely to make erroneous generalizations on the relationship r.
The insight driving the rest of this chapter is this: while the relation expressed by a tanru can be very distant (e.g. Spot chasing Socks, above), the relationship singled out for disambiguation in a lujvo should be quite close. This is because lujvo-making, paralleling natural language compounding, picks out the most salient relationship r between a tertau place and a seltau place to be expressed in a single word. The relationship “dog chases cat owned by daughter of person living in house” is too distant, and too incidental, to be likely to need expression as a single short word; the relationship “dog lives in house” is not. From all the various interpretations of gerku zdani , the person creating gerzda should pick the most useful value of r. The most useful one is usually going to be the most obvious one, and the most obvious one is usually the closest one.
In fact, the relationship will almost always be so close that the predicate expressing r will be either the seltau or the tertau predicate itself. This should come as no surprise, given that a word like zdani in Lojban is a predicate. Predicates express relations; so when you're looking for a relation to tie together le zdani and le gerku , the most obvious relation to pick is the very relation named by the tertau, zdani : the relation between a home and its dweller. As a result, the object which fills the first place of gerku (the dog) also fills the second place of zdani (the house-dweller).
The seltau-tertau relationship in the veljvo is expressed by the seltau or tertau predicate itself. Therefore, at least one of the seltau places is going to be equivalent to a tertau place. This place is thus redundant, and can be dropped from the place structure of the lujvo. As a corollary, the precise relationship between the veljvo components can be implicitly determined by finding one or more places to overlap in this way.
So what is the place structure of gerzda ? We're left with three places, since the dweller, the se zdani , turned out to be identical to the dog, the gerku. We can proceed as follows:
(The notation introduced casually in Section 12.2 will be useful in the rest of this chapter. Rather than using the regular x1, x2, etc. to represent places, we'll use the first letter of the relevant gismu in place of the “x” , or more than one letter where necessary to resolve ambiguities. Thus, z1 is the first place of zdani , and g2 is the second place of gerku.)
The place structure of zdani is given as Example 12.3 , but is repeated here using the new notation:
The place structure of gerku is:
But z2 is the same as g1; therefore, the tentative place structure for gerzda now becomes:
which can also be written
or more comprehensively
Despite the apparently conclusive nature of Example 12.10 , our task is not yet done: we still need to decide whether any of the remaining places should also be eliminated, and what order the lujvo places should appear in. These concerns will be addressed in the remainder of the chapter; but we are now equipped with the terminology needed for those discussions.
The set of places of an ordinary lujvo are selected from the places of its component gismu. More precisely, the places of such a lujvo are derived from the set of places of the component gismu by eliminating unnecessary places, until just enough places remain to give an appropriate meaning to the lujvo. In general, including a place makes the concept expressed by a lujvo more general; excluding a place makes the concept more specific, because omitting the place requires assuming a standard value or range of values for it.
It would be possible to design the place structure of a lujvo from scratch, treating it as if it were a gismu, and working out what arguments contribute to the notion to be expressed by the lujvo. There are two reasons arguing against doing so and in favor of the procedure detailed in this chapter.
The first is that it might be very difficult for a hearer or reader, who has no preconceived idea of what concept the lujvo is intended to convey, to work out what the place structure actually is. Instead, he or she would have to make use of a lujvo dictionary every time a lujvo is encountered in order to work out what a se jbopli or a te klagau is. But this would mean that, rather than having to learn just the 1300-odd gismu place structures, a Lojbanist would also have to learn myriads of lujvo place structures with little or no apparent pattern or regularity to them. The purpose of the guidelines documented in this chapter is to apply regularity and to make it conventional wherever possible.
The second reason is related to the first: if the veljvo of the lujvo has not been properly selected, and the places for the lujvo are formulated from scratch, then there is a risk that some of the places formulated may not correspond to any of the places of the gismu used in the veljvo of the lujvo. If that is the case – that is to say, if the lujvo places are not a subset of the veljvo gismu places – then it will be very difficult for the hearer or reader to understand what a particular place means, and what it is doing in that particular lujvo. This is a topic that will be further discussed in Section 12.14.
However, second-guessing the place structure of the lujvo is useful in guiding the process of subsequently eliminating places from the veljvo. If the Lojbanist has an idea of what the final place structure should look like, he or she should be able to pick an appropriate veljvo to begin with, in order to express the idea, and then to decide which places are relevant or not relevant to expressing that idea.
A common pattern, perhaps the most common pattern, of lujvo-making creates what is called a “symmetrical lujvo”. A symmetrical lujvo is one based on a tanru interpretation such that the first place of the seltau is equivalent to the first place of the tertau: each component of the tanru characterizes the same object. As an illustration of this, consider the lujvo balsoi : it is intended to mean “both great and a soldier” - that is, “great soldier” , which is the interpretation we would tend to give its veljvo, banli sonci. The underlying gismu place structures are:
In this case the s1 place of sonci is redundant, since it is equivalent to the b1 place of banli. Therefore the place structure of balsoi need not include places for both s1 and b1, as they refer to the same thing. So the place structure of balsoi is at most
Some symmetrical veljvo have further equivalent places in addition to the respective first places. Consider the lujvo tinju'i , “to listen” ( “to hear attentively, to hear and pay attention”). The place structures of the gismu tirna and jundi are:
and the place structure of the lujvo is:
Why so? Because not only is the j1 place (the one who pays attention) equivalent to the t1 place (the hearer), but the j2 place (the thing paid attention to) is equivalent to the t2 place (the thing heard).
A substantial minority of lujvo have the property that the first place of the seltau ( gerku in this case) is equivalent to a place other than the first place of the tertau; such lujvo are said to be “asymmetrical”. (There is a deliberate parallel here with the terms “asymmetrical tanru” and “symmetrical tanru” used in Chapter 5.)
In principle any asymmetrical lujvo could be expressed as a symmetrical lujvo. Consider gerzda , discussed in Section 12.3 , where we learned that the g1 place was equivalent to the z2 place. In order to get the places aligned, we could convert zdani to se zdani (or selzda when expressed as a lujvo). The place structure of selzda is
and so the three-part lujvo gerselzda would have the place structure
However, although gerselzda is a valid lujvo, it doesn't translate “doghouse” ; its first place is the dog, not the doghouse. Furthermore, it is more complicated than necessary; gerzda is simpler than gerselzda.
From the reader's or listener's point of view, it may not always be obvious whether a newly met lujvo is symmetrical or asymmetrical, and if the latter, what kind of asymmetrical lujvo. If the place structure of the lujvo isn't given in a dictionary or elsewhere, then plausibility must be applied, just as in interpreting tanru.
The lujvo karcykla , for example, is based on karce klama , or “car goer”. The place structure of karce is:
An asymmetrical interpretation of karcykla that is strictly analogous to the place structure of gerzda , equating the kl2 (destination) and ka1 (car) places, would lead to the place structure
kl1 goes to car kl2=ka1 which carries ka2 propelled by ka3 from origin kl3 via route kl4 by means of kl5
But in general we go about in cars, rather than going to cars, so a far more likely place structure treats the ka1 place as equivalent to the kl5 place, leading to
kl1 goes to destination kl2 from origin kl3 via route kl4 by means of car kl5=ka1 carrying ka2 propelled by ka3.
instead.
In order to understand which places, if any, should be completely removed from a lujvo place structure, we need to understand the concept of dependent places. One place of a brivla is said to be dependent on another if its value can be predicted from the values of one or more of the other places. For example, the g2 place of gerku is dependent on the g1 place. Why? Because when we know what fits in the g1 place (Spot, let us say, a well-known dog), then we know what fits in the g2 place ( “St. Bernard” , let us say). In other words, when the value of the g1 place has been specified, the value of the g2 place is determined by it. Conversely, since each dog has only one breed, but each breed contains many dogs, the g1 place is not dependent on the g2 place; if we know only that some dog is a St. Bernard, we cannot tell by that fact alone which dog is meant.
For zdani , on the other hand, there is no dependency between the places. When we know the identity of a house-dweller, we have not determined the house, because a dweller may dwell in more than one house. By the same token, when we know the identity of a house, we do not know the identity of its dweller, for a house may contain more than one dweller.
The rule for eliminating places from a lujvo is that dependent places provided by the seltau are eliminated. Therefore, in gerzda the dependent g2 place is removed from the tentative place structure given in Example 12.10 , leaving the place structure:
Informally put, the reason this has happened – and it happens a lot with seltau places – is that the third place was describing not the doghouse, but the dog who lives in it. The sentence
really means
| la | .mon. | .rePOS. | zdani | la | .spat. | noi | gerku |
| That-named | Mon | Repos | is-a-house-of | that-named | Spot, | who | is-a-dog. |
since that is the interpretation we have given gerzda. But that in turn means
| la | .mon. | .rePOS. | zdani | la | spat |
| That-named | Mon | Repos | is-a-house-of | that-named | Spot, |
| noi ke'a | gerku | zo'e |
| who | is-a-dog | of-unspecified-breed. |
Specifically,
| la | .mon. | .rePOS. | zdani | la | .spat. |
| That-named | Mon | Repos | is-a-house-of | that-named | Spot, |
| noi ke'a | gerku | la | .sankt. | .berNARD. |
| who | is-a-dog-of-breed | that-named | St. | Bernard. |
and in that case, it makes little sense to say
| la | .mon. | .rePOS. | gerzda | la | .spat. | noi ke'a | gerku |
| That-named | Mon | Repos | is-a-doghouse-of | that-named | Spot, | who | is-a-dog |
| la | .sankt. | .berNARD. | ku'o | |
| of-breed | that-named | St. | Bernard, |
| la | .sankt. | .berNARD. | |
| of-breed | that-named | St. | Bernard. |
employing the over-ample place structure of Example 12.10. The dog breed is redundantly given both in the main selbri and in the relative clause, and (intuitively speaking) is repeated in the wrong place, since the dog breed is supplementary information about the dog, and not about the doghouse.
As a further example, take cakcinki , the lujvo for “beetle” , based on the tanru calku cinki , or “shell-insect”. The gismu place structures are:
This example illustrates a cross-dependency between a place of one gismu and a place of the other. The ca3 place is dependent on ci1, because all insects (which fit into ci1) have shells made of chitin (which fits into ca3). Furthermore, ca1 is dependent on ci1 as well, because each insect has only a single shell. And since ca2 (the thing with the shell) is equivalent to ci1 (the insect), the place structure is
with not a single place of calku surviving independently!
(Note that there is nothing in this explanation that tells us just why cakcinki means “beetle” (member of Coleoptera), since all insects in their adult forms have chitin shells of some sort. The answer, which is in no way predictable, is that the shell is a prominent, highly noticeable feature of beetles in particular.)
What about the dependency of ci2 on ci1? After all, no beetle belongs to more than one species, so it would seem that the ci2 place of cakcinki could be eliminated on the same reasoning that allowed us to eliminate the g2 place of gerzda above. However, it is a rule that dependent places are not eliminated from a lujvo when they are derived from the tertau of its veljvo. This rule is imposed to keep the place structures of lujvo from drifting too far from the tertau place structure; if a place is necessary in the tertau, it's treated as necessary in the lujvo as well.
In general, the desire to remove places coming from the tertau is a sign that the veljvo selected is simply wrong. Different place structures imply different concepts, and the lujvo maker may be trying to shoehorn the wrong concept into the place structure of his or her choosing. This is obvious when someone tries to shoehorn a klama tertau into a litru or cliva concept, for example: these gismu differ in their number of arguments, and suppressing places of klama in a lujvo doesn't make any sense if the resulting modified place structure is that of litru or cliva.
Sometimes the dependency is between a single place of the tertau and the whole event described by the seltau. Such cases are discussed further in Section 12.13.
Unfortunately, not all dependent places in the seltau can be safely removed: some of them are necessary to interpreting the lujvo's meaning in context. It doesn't matter much to a doghouse what breed of dog inhabits it, but it can make quite a lot of difference to the construction of a school building what kind of school is in it! Music schools need auditoriums and recital rooms, elementary schools need playgrounds, and so on: therefore, the place structure of kuldi'u (from ckule dinju , and meaning “school building”) needs to be
even though c3 and c4 are plainly dependent on c1. The other places of ckule , the location (c2) and operators (c5), don't seem to be necessary to the concept “school building” , and are dependent on c1 to boot, so they are omitted. Again, the need for case-by-case consideration of place structures is demonstrated.
So far, we have concentrated on selecting the places to go into the place structure of a lujvo. However, this is only half the story. In using selbri in Lojban, it is important to remember the right order of the sumti. With lujvo, the need to attend to the order of sumti becomes critical: the set of places selected should be ordered in such a way that a reader unfamiliar with the lujvo should be able to tell which place is which.
If we aim to make understandable lujvo, then, we should make the order of places in the place structure follow some conventions. If this does not occur, very real ambiguities can turn up. Take for example the lujvo jdaselsku , meaning “prayer”. In the sentence
we must be able to know if Dong is the person making the prayer, giving the meaning
or is the entity being prayed to, resulting in
We could resolve such problems on a case-by-case basis for each lujvo ( Section 12.14 discusses when this is actually necessary), but case-by-case resolution for run-of-the-mill lujvo makes the task of learning lujvo place structures unmanageable. People need consistent patterns to make sense of what they learn. Such patterns can be found across gismu place structures (see Section 12.16), and are even more necessary in lujvo place structures. Case-by-case consideration is still necessary; lujvo creation is a subtle art, after all. But it is helpful to take advantage of any available regularities.
We use two different ordering rules: one for symmetrical lujvo and one for asymmetrical ones. A symmetrical lujvo like balsoi (from Section 12.5) has the places of its tertau followed by whatever places of the seltau survive the elimination process. For balsoi , the surviving places of banli are b2 and b3, leading to the place structure:
just what appears in Example 12.11. In fact, all place structures shown until now have been in the correct order by the conventions of this section, though the fact has been left tacit until now.
The motivation for this rule is the parallelism between the lujvo bridi-schema
and the more or less equivalent bridi-schema
where gi'e is the Lojban word for “and” when placed between two partial bridi, as explained in Section 14.9.
Asymmetrical lujvo like gerzda , on the other hand, employ a different rule. The seltau places are inserted not at the end of the place structure, but rather immediately after the tertau place which is equivalent to the first place of the seltau. Consider dalmikce , meaning “veterinarian” : its veljvo is danlu mikce , or “animal doctor”. The place structures for those gismu are:
and the lujvo place structure is:
Since the shared place is m2=d1, the animal patient, the remaining seltau place d2 is inserted immediately after the shared place; then the remaining tertau places form the last two places of the lujvo.
The theory we have outlined so far is an account of lujvo with two parts. But often lujvo are made containing more than two parts. An example is bavlamdei , “tomorrow” : it is composed of the rafsi for “future” , “adjacent” , and “day”. How does the account we have given apply to lujvo like this?
The best way to approach such lujvo is to continue to classify them as based on binary tanru, the only difference being that the seltau or the tertau or both is itself a lujvo. So it is easiest to make sense of bavlamdei as having two components: bavla'i , “next” , and djedi. If we know or invent the lujvo place structure for the components, we can compose the new lujvo place structure in the usual way.
In this case, bavla'i is given the place structure
making it a symmetrical lujvo. We combine this with djedi , which has the place structure:
While symmetrical lujvo normally put any trailing tertau places before any seltau places, the day standard is a much less important concept than the day the tomorrow follows, in the definition of bavlamdei. This is an example of how the guidelines presented for selecting and ordering lujvo places are just that, not laws that must be rigidly adhered to. In this case, we choose to rank places in order of relative importance. The resulting place structure is:
Here is another example of a multi-part lujvo: cladakyxa'i , meaning “long-sword” , a specific type of medieval weapon. The gismu place structures are:
Since cladakyxa'i is a symmetrical lujvo based on cladakfu xarci , and cladakfu is itself a symmetrical lujvo, we can do the necessary analyses all at once. Plainly c1 (the long thing), d1 (the knife), and xa1 (the weapon) are all the same. Likewise, the d2 place (the thing cut) is the same as the xa2 place (the target of the weapon), given that swords are used to cut victims. Finally, the c2 place (direction of length) is always along the sword blade in a longsword, by definition, and so is dependent on c1=d1=xa1. Adding on the places of the remaining gismu in right-to-left order we get:
xa1=d1=c1 is a long-sword for use against xa2=d2 by wielder xa3, with a blade made of d3, length measured by standard c3.
If the last place sounds unimportant to you, notice that what counts legally as a “sword” , rather than just a “knife” , depends on the length of the blade (the legal limit varies in different jurisdictions). This fifth place of cladakyxa'i may not often be explicitly filled, but it is still useful on occasion. Because it is so seldom important, it is best that it be last.
It is common to form lujvo that omit the rafsi based on cmavo of selma'o SE, as well as other cmavo rafsi. Doing so makes lujvo construction for common or useful constructions shorter. Since it puts more strain on the listener who has not heard the lujvo before, the shortness of the word should not necessarily outweigh ease in understanding, especially if the lujvo refers to a rare or unusual concept.
Consider as an example the lujvo ti'ifla , from the veljvo stidi flalu , and meaning “bill, proposed law”. The gismu place structures are:
This lujvo does not fit any of our existing molds: it is the second seltau place, st2, that is equivalent to one of the tertau places, namely f1. However, if we understand ti'ifla as an abbreviation for the lujvo selti'ifla , then we get the first places of seltau and tertau lined up. The place structure of selti'i is:
Here we can see that se1 (what is suggested) is equivalent to f1 (the law), and we get a normal symmetrical lujvo. The final place structure is:
f1=se1 is a bill specifying f2 for community f3 under conditions f4 by suggester se2 to audience/lawgivers f5=se3
or, relabeling the places,
f1=st2 is a bill specifying f2 for community f3 under conditions f4 by suggester st1 to audience/lawgivers f5=st3
where the last place (st3) is probably some sort of legislature.
Abbreviated lujvo like ti'ifla are more intuitive (for the lujvo-maker) than their more explicit counterparts like selti'ifla (as well as shorter). They don't require the coiner to sit down and work out the precise relation between the seltau and the tertau: he or she can just rattle off a rafsi pair. But should the lujvo get to the stage where a place structure needs to be worked out, then the precise relation does need to be specified. And in that case, such abbreviated lujvo form a trap in lujvo place ordering, since they obscure the most straightforward relation between the seltau and tertau. To give our lujvo-making guidelines as wide an application as possible, and to encourage analyzing the seltau-tertau relation in lujvo, lujvo like ti'ifla are given the place structure they would have with the appropriate SE added to the seltau.
Note that, with these lujvo, an interpretation requiring SE insertion is safe only if the alternatives are either implausible or unlikely to be needed as a lujvo. This may not always be the case, and Lojbanists should be aware of the risk of ambiguity.
Eliding SE rafsi from tertau gets us into much more trouble. To understand why, recall that lujvo, following their veljvo, describe some type of whatever their tertau describe. Thus, posydji describes a type of djica , gerzda describes a type of zdani , and so on. What is certain is that gerzda does not describe a se zdani - it is not a word that could be used to describe an inhabitant such as a dog.
Now consider how we would translate the word “blue-eyed”. Let's tentatively translate this word as blakanla (from blanu kanla , meaning “blue eye”). But immediately we are in trouble: we cannot say
because Jack is not an eye, kanla , but someone with an eye, se kanla. At best we can say
But look now at the place structure of blakanla : it is a symmetrical lujvo, so the place structure is:
We end up being most interested in talking about the second place, not the first (we talk much more of people than of their eyes), so se would almost always be required.
What is happening here is that we are translating the tertau wrongly, under the influence of English. The English suffix “-eyed” does not mean “eye” , but someone with an eye, which is selkanla.
Because we've got the wrong tertau (eliding a se that really should be there), any attempt to accommodate the resulting lujvo into our guidelines for place structure is fitting a square peg in a round hole. Since they can be so misleading, lujvo with SE rafsi elided from the tertau should be avoided in favor of their more explicit counterparts: in this case, blaselkanla.
People constructing lujvo usually want them to be as short as possible. To that end, they will discard any cmavo they regard as niceties. The first such cmavo to get thrown out are usually ke and ke'e , the cmavo used to structure and group tanru. We can usually get away with this, because the interpretation of the tertau with ke and ke'e missing is less plausible than that with the cmavo inserted, or because the distinction isn't really important.
For example, in bakrecpa'o , meaning “beefsteak” , the veljvo is
because of the usual Lojban left-grouping rule. But there doesn't seem to be much difference between that veljvo and
On the other hand, the lujvo zernerkla , meaning “to sneak in” , almost certainly was formed from the veljvo
because the alternative,
doesn't make much sense. (To go to the inside of a crime? To go into a place where it is criminal to be inside – an interpretation almost identical with Example 12.51 anyway?)
There are cases, however, where omitting a KE or KEhE rafsi can produce another lujvo, equally useful. For example, xaskemcakcurnu means “oceanic shellfish” , and has the veljvo
( “worm” in Lojban refers to any invertebrate), but xasycakcurnu has the veljvo
and might refer to the parasitic worms that infest clamshells.
Such misinterpretation is more likely than not in a lujvo starting with sel- (from se), nal- (from na'e) or tol- (from to'e): the scope of the rafsi will likeliest be presumed to be as narrow as possible, since all of these cmavo normally bind only to the following brivla or ke … ke'e group. For that reason, if we want to modify an entire lujvo by putting se , na'e or to'e before it, it's better to leave the result as two words, or else to insert ke , than to just stick the SE or NAhE rafsi on.
It is all right to replace the phrase se klama with selkla , and the places of selkla are exactly those of se klama. But consider the related lujvo dzukla , meaning “to walk to somewhere”. It is a symmmetrical lujvo, derived from the veljvo cadzu klama as follows:
We can swap the k1 and k2 places using se dzukla , but we cannot directly make se dzukla into seldzukla , which would represent the veljvo selcadzu klama and plausibly mean something like “to go to a walking surface”. Instead, we would need selkemdzukla , with an explicit rafsi for ke. Similarly, nalbrablo (from na'e barda bloti) means “non-big boat” , whereas na'e brablo means “other than a big boat”.
If the lujvo we want to modify with SE has a seltau already starting with a SE rafsi, we can take a shortcut. For instance, gekmau means “happier than” , while selgekmau means “making people happier than, more enjoyable than, more of a 'se gleki' than”. If something is less enjoyable than something else, we can say it is se selgekmau.
But we can also say it is selselgekmau. Two se cmavo in a row cancel each other ( se se gleki means the same as just gleki), so there would be no good reason to have selsel in a lujvo with that meaning. Instead, we can feel free to interpret selsel- as selkemsel-. The rafsi combinations terter- , velvel- and xelxel- work in the same way.
Other SE combinations like selter- , although they might conceivably mean se te , more than likely should be interpreted in the same way, namely as se ke te , since there is no need to re-order places in the way that se te provides. (See Section 9.4.)
The cmavo of NU can participate in the construction of lujvo of a particularly simple and well-patterned kind. Consider that old standard example, klama :
The selbri nu klama [kei] has only one place, the event-of-going, but the full five places exist implicitly between nu and kei , since a full bridi with all sumti may be placed there. In a lujvo, there is no room for such inside places, and consequently the lujvo nunkla ( nun- is the rafsi for nu), needs to have six places:
Here the first place of nunklama is the first and only place of nu , and the other five places have been pushed down by one to occupy the second through the sixth places. Full information on nu , as well as the other abstractors mentioned in this section, is given in Chapter 11.
For those abstractors which have a second place as well, the standard convention is to place this place after, rather than before, the places of the brivla being abstracted. The place structure of nilkla , the lujvo derived from ni klama , is the imposing:
ni1 is the amount of k1's coming/going to k2 from k3 via route k4 by means k5, measured on scale ni2.
It is not uncommon for abstractors to participate in the making of more complex lujvo as well. For example, nunsoidji , from the veljvo
has the place structure
where the d2 place has disappeared altogether, being replaced by the places of the seltau. As shown in Example 12.60 , the ordering follows this idea of replacement: the seltau places are inserted at the point where the omitted abstraction place exists in the tertau.
The lujvo nunsoidji is quite different from the ordinary asymmetric lujvo soidji , a “soldier desirer” , whose place structure is just
A nunsoidji might be someone who is about to enlist, whereas a soidji might be a camp-follower.
One use of abstract lujvo is to eliminate the need for explicit kei in tanru: nunkalri gasnu means much the same as nu kalri kei gasnu , but is shorter. In addition, many English words ending in -hood are represented with nun- lujvo, and other words ending in “-ness” or “-dom” are often representable with kam- lujvo ( kam- is the rafsi for ka); kambla is “blueness”.
Even though the cmavo of NU are long-scope in nature, governing the whole following bridi, the NU rafsi should generally be used as short-scope modifiers, like the SE and NAhE rafsi discussed in Section 12.9.
There is also a rafsi for the cmavo jai , namely jax , which allows sentences like
| mi | jai | rinka | le | nu | do | morsi |
| I | am-associated-with | causing | the | event-of | your | death. |
|
I cause your death. |
explained in Section 11.10 , to be rendered with lujvo:
In making a lujvo that contains jax- for a selbri that contains jai , the rule is to leave the fai place as a fai place of the lujvo; it does not participate in the regular lujvo place structure. (The use of fai is explained in Section 9.12 and Section 10.22.)
Eliding NU rafsi involves the same restrictions as eliding SE rafsi, plus additional ones. In general, NU rafsi should not be elided from the tertau, since that changes the kind of thing the lujvo is talking about from an abstraction to a concrete sumti. However, they may be elided from the seltau if no reasonable ambiguity would result.
A major difference, however, between SE elision and NU elision is that the former is a rather sparse process, providing a few convenient shortenings. Eliding nu , however, is extremely important in producing a class of lujvo called “implicit-abstraction lujvo”.
Let us make a detailed analysis of the lujvo nunctikezgau , meaning “to feed”. (If you think this lujvo is excessively longwinded, be patient.) The veljvo of nunctikezgau is nu citka kei gasnu. The relevant place structures are:
In accordance with the procedure for analyzing three-part lujvo given in Section 12.8 , we will first create an intermediate lujvo, nuncti , whose veljvo is nu citka [kei]. By the rules given in Section 12.12 , nuncti has the place structure
Now we can transform the veljvo of nunctikezgau into nuncti gasnu. The g2 place (what is brought about by the actor g1) obviously denotes the same thing as n1 (the event of eating). So we can eliminate g2 as redundant, leaving us with a tentative place structure of
But it is also possible to omit the n1 place itself! The n1 place describes the event brought about; an event in Lojban is described as a bridi, by a selbri and its sumti; the selbri is already known (it's the seltau), and the sumti are also already known (they're in the lujvo place structure). So n1 would not give us any information we didn't already know. In fact, the n1=g2 place is dependent on c1 and c2 jointly – it does not depend on either c1 or c2 by itself. Being dependent and derived from the seltau, it is omissible. So the final place structure of nunctikezgau is:
There is one further step that can be taken. As we have already seen with balsoi in Section 12.5 , the interpretation of lujvo is constrained by the semantics of gismu and of their sumti places. Now, any asymmetrical lujvo with gasnu as its tertau will involve an event abstraction either implicitly or explicitly, since that is how the g2 place of gasnu is defined.
Therefore, if we assume that nu is the type of abstraction one would expect to be a se gasnu , then the rafsi nun and kez in nunctikezgau are only telling us what we would already have guessed – that the seltau of a gasnu lujvo is an event. If we drop these rafsi out, and use instead the shorter lujvo ctigau , rejecting its symmetrical interpretation ( “someone who both does and eats” ; “an eating doer”), we can still deduce that the seltau refers to an event.
(You can't “do an eater” / gasnu lo citka , with the meaning of do as “bring about an event” ; so the seltau must refer to an event, nu citka. The English slang meanings of “do someone” , namely “socialize with someone” and “have sex with someone” , are not relevant to gasnu.)
So we can simply use ctigau with the same place structure as nunctikezgau :
This particular kind of asymmetrical lujvo, in which the seltau serves as the selbri of an abstraction which is a place of the tertau, is called an implicit-abstraction lujvo, because one deduces the presence of an abstraction which is unexpressed (implicit).
To give another example: the gismu basti , whose place structure is
can form the lujvo basygau , with the place structure:
where both basti and basygau are translated “replace” in English, but represent different relations: basti may be used with no mention of any agent doing the replacing.
In addition, gasnu -based lujvo can be built from what we would consider nouns or adjectives in English. In Lojban, everything is a predicate, so adjectives, nouns and verbs are all treated in the same way. This is consistent with the use of similar causative affixes in other languages. For example, the gismu litki , meaning “liquid” , with the place structure
can give likygau , meaning “to liquefy” :
While likygau correctly represents “causes to be a liquid” , a different lujvo based on galfi (meaning “modify”) may be more appropriate for “causes to become a liquid”. On the other hand, fetsygau is potentially confusing, because it could mean “agent in the event of something becoming female” (the implicit-abstraction interpretation) or simply “female agent” (the parallel interpretation), so using implicit-abstraction lujvo is always accompanied with some risk of being misunderstood.
Many other Lojban gismu have places for event abstractions, and therefore are good candidates for the tertau of an implicit-abstraction lujvo. For example, lujvo based on rinka , with its place structure
are closely related to those based on gasnu. However, rinka is less generally useful than gasnu , because its r1 place is another event rather than a person: lo rinka is a cause, not a causer. Thus the place structure of likyri'a , a lujvo analogous to likygau , is
and would be useful in translating sentences like “The heat of the sun liquefied the block of ice.”
Implicit-abstraction lujvo are a powerful means in the language of rendering quite verbose bridi into succinct and manageable concepts, and increasing the expressive power of the language.
Some lujvo that have been coined and actually employed in Lojban writing do not follow the guidelines expressed above, either because the places that are equivalent in the seltau and the tertau are in an unusual position, or because the seltau and tertau are related in a complex way, or both. An example of the first kind is jdaselsku , meaning “prayer” , which was mentioned in Section 12.7. The gismu places are:
and selsku , the tertau of jdaselsku , has the place structure
Now it is easy to see that the l2 and s2 places are equivalent: the believer in the religion (l2) is the one who expresses the prayer (s2). This is not one of the cases for which a place ordering rule has been given in Section 12.7 or Section 12.13 ; therefore, for lack of a better rule, we put the tertau places first and the remaining seltau places after them, leading to the place structure:
The l3 place (the beliefs of the religion) is dependent on the l1 place (the religion) and so is omitted.
We could make this lujvo less messy by replacing it with se seljdasku , where seljdasku is a normal symmetrical lujvo with place structure:
which, according to the rule expressed in Section 12.9 , can be further expressed as selseljdasku. However, there is no need for the ugly selsel- prefix just to get the rules right: jdaselsku is a reasonable, if anomalous, lujvo.
However, there is a further problem with jdaselsku , not resolvable by using seljdasku. No veljvo involving just the two gismu lijda and cusku can fully express the relationship implicit in prayer. A prayer is not just anything said by the adherents of a religion; nor is it even anything said by them acting as adherents of that religion. Rather, it is what they say under the authority of that religion, or using the religion as a medium, or following the rules associated with the religion, or something of the kind. So the veljvo is somewhat elliptical.
As a result, both seljdasku and jdaselsku belong to the second class of anomalous lujvo: the veljvo doesn't really supply all that the lujvo requires.
Another example of this kind of anomalous lujvo, drawn from the tanru lists in Section 5.14 , is lange'u , meaning “sheepdog”. Clearly a sheepdog is not a dog which is a sheep (the symmetrical interpretation is wrong), nor a dog of the sheep breed (the asymmetrical interpretation is wrong). Indeed, there is simply no overlap in the places of lanme and gerku at all. Rather, the lujvo refers to a dog which controls sheep flocks, a terlanme jitro gerku , the lujvo from which is terlantroge'u with place structure:
based on the gismu place structures
Note that this lujvo is symmetrical between lantro (sheep-controller) and gerku , but lantro is itself an asymmetrical lujvo. The l2 place, the breed of sheep, is removed as dependent on l1. However, the lujvo lange'u is both shorter than terlantroge'u and sufficiently clear to warrant its use: its place structure, however, should be the same as that of the longer lujvo, for which lange'u can be understood as an abbreviation.
Another example is xanmi'e , “to command by hand, to beckon”. The component place structures are:
The relation between the seltau and tertau is close enough for there to be an overlap: xa2 (the person with the hand) is the same as m1 (the one who commands). But interpreting xanmi'e as a symmetrical lujvo with an elided sel- in the seltau, as if from se xance minde , misses the point: the real relation expressed by the lujvo is not just “one who commands and has a hand” , but “to command using the hand”. The concept of “using” suggests the gismu pilno , with place structure
Some possible three-part veljvo are (depending on how strictly you want to constrain the veljvo)
or even
which lead to the three different lujvo xanplimi'e , mi'erxanpli , and minkemxanpli respectively.
Does this make xanmi'e wrong? By no means. But it does mean that there is a latent component to the meaning of xanmi'e , the gismu pilno , which is not explicit in the veljvo. And it also means that, for a place structure derivation that actually makes sense, rather than being ad-hoc, the Lojbanist should probably go through a derivation for xancypliminde or one of the other possibilities that is analogous to the analysis of terlantroge'u above, even if he or she decides to stick with a shorter, more convenient form like xanmi'e. In addition, of course, the possibilities of elliptical lujvo increase their potential ambiguity enormously – an unavoidable fact which should be borne in mind.
English has the concepts of “comparative adjectives” and “superlative adjectives” which can be formed from other adjectives, either by adding the suffixes “-er” and “-est” or by using the words “more” and “most” , respectively. The Lojbanic equivalents, which can be made from any brivla, are lujvo with the tertau zmadu , mleca , zenba , jdika , and traji. In order to make these lujvo regular and easy to make, certain special guidelines are imposed.
We will begin with lujvo based on zmadu and mleca , whose place structures are:
For example, the concept “young” is expressed by the gismu citno , with place structure
The comparative concept “younger” can be expressed by the lujvo citmau (based on the veljvo citno zmadu , meaning “young more-than”).
| mi | citmau | do | lo | nanca | be | li | xa |
| I | am-younger-than | you | by | one-year | multiplied-by | the-number | six. |
|
I am six years younger than you. |
The place structure for citmau is
Similarly, in Lojban you can say:
| do | citme'a | mi | lo | nanca | be | li | xa |
| You | are-less-young-than | me | by | one-year | multiplied-by | the-number | six. |
|
You are six years less young than me. |
In English, “more” comparatives are easier to make and use than “less” comparatives, but in Lojban the two forms are equally easy.
Because of their much simpler place structure, lujvo ending in -mau and -me'a are in fact used much more frequently than zmadu and mleca themselves as selbri. It is highly unlikely for such lujvo to be construed as anything other than implicit-abstraction lujvo. But there is another type of ambiguity relevant to these lujvo, and which has to do with what is being compared.
For example, does nelcymau mean “X likes Y more than X likes Z” , or “X likes Y more than Z likes Y” ? Does klamau mean: “X goes to Y more than to Z” , “X goes to Y more than Z does” , “X goes to Y from Z more than from W” , or what?
We answer this concern by putting regularity above any considerations of concept usefulness: by convention, the two things being compared always fit into the first place of the seltau. In that way, each of the different possible interpretations can be expressed by SE-converting the seltau, and making the required place the new first place. As a result, we get the following comparative lujvo place structures:
nelcymau : z1, more than z2, likes n2 by amount z4
selnelcymau : z1, more than z2, is liked by n1 in amount z4
klamau : z1, more than z2, goes to k2 from k3 via k4 by means of k5 by amount z4
selklamau : z1, more than z2, is gone to by k1 from k3 via k4 by means of k5 by amount z4
terklamau : z1, more than z2, is an origin point for destination k2 for k1's going via k4 by means of k5 by amount z4
(See Chapter 11 for the way in which this problem is resolved when lujvo aren't used.)
The ordering rule places the things being compared first, and the other seltau places following. Unfortunately the z4 place, which expresses by how much one entity exceeds the other, is displaced into a lujvo place whose number is different for each lujvo. For example, while nelcymau has z4 as its fourth place, klamau has it as its seventh place. In any sentence where a difficulty arises, this amount-place can be redundantly tagged with vemau (for zmadu) or veme'a (for mleca) to help make the speaker's intention clear.
It is important to realize that such comparative lujvo do not presuppose their seltau. Just as in English, saying someone is younger than someone else doesn't imply that they're young in the first place: an octogenarian, after all, is still younger than a nonagenarian. Rather, the 80-year-old has a greater ni citno than the 90-year-old. Similarly, a 5-year-old is older than a 1-year-old, but is not considered “old” by most standards.
There are some comparative concepts in which the se zmadu is difficult to specify. Typically, these involve comparisons implicitly made with a former state of affairs, where stating a z2 place explicitly would be problematic.
In such cases, it is best not to use zmadu and leave the comparison hanging, but to use instead the gismu zenba , meaning “increase” (and jdika , meaning “decrease” , in place of mleca). The gismu zenba was included in the language precisely in order to capture those notions of increase which zmadu can't quite cope with; in addition, we don't have to waste a place in lujvo or tanru on something that we'd never fill in with a value anyway. So we can translate “I'm stronger now” not as
which implies that I'm currently stronger than somebody else (the elided occupant of the second or z2 place), but as
Finally, lujvo with a tertau of traji are used to build superlatives. The place structure of traji is
Consider the gismu xamgu , whose place structure is:
The comparative form is xagmau , corresponding to English “better” , with a place structure (by the rules given above) of
We would expect the place structure of xagrai , the superlative form, to somehow mirror that, given that comparatives and superlatives are comparable concepts, resulting in:
The t2 place in traji , normally filled by a property abstraction, is replaced by the seltau places, and the t3 place specifying the extremum of traji (whether the most or the least, that is) is presumed by default to be “the most”.
But the set against which the t1 place of traji is compared is not the t2 place (which would make the place structure of traji fully parallel to that of zmadu), but rather the t4 place. Nevertheless, by a special exception to the rules of place ordering, the t4 place of traji -based lujvo becomes the second place of the lujvo. Some examples:
Unlike the place structures of lujvo, the place structures of gismu were assigned in a far less systematic way through a detailed case-by-case analysis and repeated reviews with associated changes. (The gismu list is now baselined, so no further changes are contemplated.) Nevertheless, certain regularities were imposed both in the choice of places and in the ordering of places which may be helpful to the learner and the lujvo-maker, and which are therefore discussed here.
The choice of gismu places results from the varying outcome of four different pressures: brevity, convenience, metaphysical necessity, and regularity. (These are also to some extent the underlying factors in the lujvo place structures generated by the methods of this chapter.) The implications of each are roughly as follows:
-
Brevity tends to remove places: the fewer places a gismu has, the easier it is to learn, and the less specific it is. As mentioned in Section 12.4 , a brivla with fewer place structures is less specific, and generality is a virtue in gismu, because they must thoroughly blanket all of semantic space.
-
Convenience tends to increase the number of places: if a concept can be expressed as a place of some existing gismu, there is no need to make another gismu, a lujvo or a fu'ivla for it.
-
Metaphysical necessity can either increase or decrease places: it is a pressure tending to provide the “right number” of places. If something is part of the essential nature of a concept, then a place must be made for it; on the other hand, if instances of the concept need not have some property, then this pressure will tend to remove the place.
-
Regularity is a pressure which can also either increase or decrease places. If a gismu has a given place, then gismu which are semantically related to it are likely to have the place also.
Here are some examples of gismu place structures, with a discussion of the pressures operating on them:
Brevity was the most important goal here, reinforced by one interpretation of metaphysical necessity. There is no mention of color standards here, as many people have pointed out; like all color gismu, xekri is explicitly subjective. Objective color standards can be brought in by an appropriate BAI tag such as ci'u ( “on scale” ; see Section 9.6) or by making a lujvo.
The gismu jbena contains places for time and location, which few other gismu have: normally, the time and place at which something is done is supplied by a tense tag (see Chapter 10). However, providing these places makes le te jbena a simple term for “birthday” and le ve jbena for “birthplace” , so these places were provided despite their lack of metaphysical necessity.
The place structure of rinka does not have a place for the agent, the one who causes, as a result of the pressure toward metaphysical necessity. A cause-effect relationship does not have to include an agent: an event (such as snow melting in the mountains) may cause another event (such as the flooding of the Nile) without any human intervention or even knowledge.
Indeed, there is a general tendency to omit agent places from most gismu except for a few such as gasnu and zukte which are then used as tertau in order to restore the agent place when needed: see Section 12.13.
The c2 place of cinfo is provided as a result of the pressure toward regularity. All animal and plant gismu have such an x2 place; although there is in fact only one species of lion, and breeds of lion, though they exist, aren't all that important in talking about lions. The species/breed place must exist for such diversified species as dogs, and for general terms like cinki (insect), and are provided for all other animals and plants as a matter of regularity.
Less can be said about gismu place structure ordering, but some regularities are apparent. The places tend to appear in decreasing order of psychological saliency or importance. There is an implication within the place structure of klama , for example, that lo klama (the one going) will be talked about more often, and is thus more important, than lo se klama (the destination), which is in turn more important than lo xe klama (the means of transport).
Some specific tendencies (not really rules) can also be observed. For example, when there is an agent place, it tends to be the first place. Similarly, when a destination and an origin point are mentioned, the destination is always placed just before the origin point. Places such as “under conditions” and “by standard” , which often go unfilled, are moved to near the end of the place structure.
This chapter explains the various words that Lojban provides for expressing attitude and related notions. In natural languages, attitudes are usually expressed by the tone of voice when speaking, and (very imperfectly) by punctuation when writing. For example, the bare words
can be made, through tone of voice, to express the speaker's feeling of happiness, pity, hope, surprise, or disbelief. These fine points of tone cannot be expressed in writing. Attitudes are also expressed with various sounds which show up in print as oddly spelled words, such as the “Oooh!” , “Arrgh!” , “Ugh!” , and “Yecch!” in the title. These are part of the English language; people born to other languages use a different set; yet you won't find any of these words in a dictionary.
In Lojban, everything that can be spoken can also be written. Therefore, these tones of voice must be represented by explicit words known as “attitudinal indicators” , or just “attitudinals”. This rule seems awkward and clunky to English-speakers at first, but is an essential part of the Lojbanic way of doing things.
The simplest way to use attitudinal indicators is to place them at the beginning of a text. In that case, they express the speaker's prevailing attitude. Here are some examples, correlated with the attitudes mentioned following Example 13.1 :
The primary Lojban attitudinals are all the cmavo of the form VV or V'V: one of the few cases where cmavo have been classified solely by their form. There are 39 of these cmavo: all 25 possible vowel pairs of the form V'V, the four standard diphthongs ( .ai , .au , .ei , and .oi), and the ten more diphthongs that are permitted only in these attitudinal indicators and in Lojbanized names and borrowings ( .ia , .ie , .ii , .io , .iu , .ua , .ue , .ui , .uo , and .uu). Note that each of these cmavo has a period before it, marking the pause that is mandatory before every word beginning with a vowel. Attitudinals, like most of the other kinds of indicators described in this chapter, belong to selma'o UI.
Attitudinals can also be compound cmavo, of the types explained in Sections 4-8; Example 13.6 illustrates one such possibility, the compound attitudinal .ianai. In attitudinals, -nai indicates polar negation: the opposite of the simple attitudinal without the -nai. Thus, as you might suppose, .ia expresses belief, since .ianai expresses disbelief.
In addition to the attitudinals, there are other classes of indicators: intensity markers, emotion categories, attitudinal modifiers, observationals, and discursives. All of them are grammatically equivalent, which is why they are treated together in this chapter.
Every indicator behaves in more or less the same way with respect to the grammar of the rest of the language. In general, one or more indicators can be inserted at the beginning of an utterance or after any word. Indicators at the beginning apply to the whole utterance; otherwise, they apply to the word that they follow. More details can be found in Section 13.9.
Throughout this chapter, tables of indicators will be written in four columns. The first column is the cmavo itself. The second column is a corresponding English word, not necessarily a literal translation. The fourth column represents the opposite of the second column, and shows the approximate meaning of the attitudinal when suffixed with -nai. The third column, which is sometimes omitted, indicates a neutral point between the second and fourth columns, and shows the approximate meaning of the attitudinal when it is suffixed with -cu'i. The cmavo cu'i belongs to selma'o CAI, and is explained more fully in Section 13.4.
One flaw that the English glosses are particularly subject to is that in English it is often difficult to distinguish between expressing your feelings and talking about them, particularly with the limited resource of the written word. So the gloss for .ui should not really be “happiness” but some sound or tone that expresses happiness. However, there aren't nearly enough of those that have unambiguous or obvious meanings in English to go around for all the many, many different emotions Lojban speakers can readily express.
Many indicators of CV'V form are loosely derived from specific gismu. The gismu should be thought of as a memory hook, not an equivalent of the cmavo. Such gismu are shown in this chapter between square brackets, thus: [gismu].
Attitudinals make no claim: they are expressions of attitude, not of facts or alleged facts. As a result, attitudinals themselves have no truth value, nor do they directly affect the truth value of a bridi that they modify. However, since emotional attitudes are carried in your mind, they reflect reactions to that version of the world that the mind is thinking about; this is seldom identical with the real world. At times, we are thinking about our idealized version of the real world; at other times we are thinking about a potential world that might or might not ever exist.
Therefore, there are two groups of attitudinals in Lojban. The “pure emotion indicators” express the way the speaker is feeling, without direct reference to what else is said. These indicators comprise the attitudinals which begin with u or o and many of those beginning with i.
The cmavo beginning with u are simple emotions, which represent the speaker's reaction to the world as it is, or as it is perceived to be.
|
.ua |
discovery |
confusion |
|
|
.u'a |
gain |
loss |
|
|
.ue |
surprise |
no surprise |
expectation |
|
.u'e |
wonder |
commonplace |
|
|
.ui |
happiness |
unhappiness |
|
|
.u'i |
amusement |
weariness |
|
|
.uo |
completion |
incompleteness |
|
|
.u'o |
courage |
timidity |
cowardice |
|
.uu |
pity |
cruelty |
|
|
.u'u |
repentance |
lack of regret |
innocence |
Here are some typical uses of the u attitudinals:
| .ua | mi | facki | fi | le | mi | mapku |
| [Eureka!] | I | found-out | about | the | of-me | hat. |
|
[Eureka!] I found my hat! [emphasizes the discovery of the hat] |
| .u'a | mi | facki | fi | le | mi | mapku |
| [Gain!] | I | found-out | about | the | of-me | hat. |
|
[Gain!] I found my hat! [emphasizes the obtaining of the hat] |
| .ui | mi | facki | fi | le | mi | mapku |
| [Yay!] | I | found-out | about | the | of-me | hat. |
|
[Yay!] I found my hat! [emphasizes the feeling of happiness] |
| .uo | mi | facki | fi | le | mi | mapku |
| [At-last!] | I | found-out | about | the | of-me | hat. |
|
[At last!] I found my hat! [emphasizes that the finding is complete] |
| .u'u | do | cortu |
| [Repentance!] | you | feel-pain. |
|
[Repentance!] you feel pain. [expresses that speaker feels guilty] |
In Example 13.10 , note that the attitudinal .uo is translated by an English non-attitudinal phrase: “At last!” It is common for the English equivalents of Lojban attitudinals to be short phrases of this sort, with more or less normal grammar, but actually expressions of emotion.
In particular, both .uu and .u'u can be translated into English as “I'm sorry” ; the difference between these two attitudes frequently causes confusion among English-speakers who use this phrase, leading to responses like “Why are you sorry? It's not your fault!”
It is important to realize that .uu , and indeed all attitudinals, are meant to be used sincerely, not ironically. In English, the exclamation “Pity!” is just as likely to be ironically intended, but this usage does not extend to Lojban. Lying with attitudinals is (normally) as inappropriate to Lojban discourse as any other kind of lying: perhaps worse, because misunderstood emotions can cause even greater problems than misunderstood statements.
The following examples display the effects of nai and cu'i when suffixed to an attitudinal:
In Example 13.15 , John's coming has been anticipated by the speaker. In Example 13.13 and Example 13.14 , no such anticipation has been made, but in Example 13.14 the lack-of-anticipation goes no further – in Example 13.13 , it amounts to actual surprise.
It is not possible to firmly distinguish the pure emotion words beginning with o or i from those beginning with u , but in general they represent more complex, more ambivalent, or more difficult emotions.
|
.o'a |
pride |
modesty |
shame |
|
.o'e |
closeness |
detachment |
distance |
|
.oi |
complaint/pain |
doing OK |
pleasure |
|
.o'i |
caution |
boldness |
rashness |
|
.o'o |
patience |
mere tolerance |
anger |
|
.o'u |
relaxation |
composure |
stress |
Here are some examples:
Here the speaker is distressed or discomfited over John's coming. The word .oi is derived from the Yiddish word “oy” of similar meaning. It is the only cmavo with a Yiddish origin.
Here the speaker feels anger over John's coming.
Here there is a sense of danger in John's arrival.
In Example 13.19 and Example 13.20 , John's arrival is no problem: in the former example, the speaker feels emotional distance from the situation; in the latter example, John's coming is actually a relief of some kind.
The pure emotion indicators beginning with i are those which could not be fitted into the u or o groups because there was a lack of room, so they are a mixed lot. .ia , .i'a , .ie , and .i'e do not appear here, as they belong in Section 13.3 instead.
|
.ii |
fear |
nervousness |
security |
|
.i'i |
togetherness |
privacy |
|
|
.io |
respect |
disrespect |
|
|
.i'o |
appreciation |
envy |
|
|
.iu |
love |
no love lost |
hatred |
|
.i'u |
familiarity |
mystery |
Here are some examples:
Example 13.21 shows an attitude-colored observative; the attitudinal modifies the situation described by the observative, namely the mouse that is causing the emotion. Lojban-speaking toddlers, if there ever are any, will probably use sentences like Example 13.21 a lot.
Example 13.22 and Example 13.23 use attitudinals that follow la .djan. rather than being at the beginning of the sentence. This form means that the attitude is attached to John rather than the event of his coming; the speaker loves or disrespects John specifically. Compare:
where it is specifically the coming of John that inspires the feeling.
Example 13.23 is a compact way of swearing at John: you could translate it as “That good-for-nothing John is coming.”
As mentioned at the beginning of Section 13.2 , attitudinals may be divided into two groups, the pure emotion indicators explained in that section, and a contrasting group which may be called the “propositional attitude indicators”. These indicators establish an internal, hypothetical world which the speaker is reacting to, distinct from the world as it really is. Thus we may be expressing our attitude towards “what the world would be like if ...” , or more directly stating our attitude towards making the potential world a reality.
In general, the bridi paraphrases of pure emotions look (in English) something like “I'm going to the market, and I'm happy about it”. The emotion is present with the subject of the primary claim, but is logically independent of it. Propositional attitudes, though, look more like “I intend to go to the market” , where the main claim is logically subordinate to the intention: I am not claiming that I am actually going to the market, but merely that I intend to.
There is no sharp distinction between attitudinals beginning with a and those beginning with e ; however, the original intent (not entirely realized due to the need to cram too many attitudes into too little space) was to make the members of the a -series the purer, more attitudinal realizers of a potential world, while the members of the e -series were more ambivalent or complex about the speaker's intention with regard to the predication. The relationship between the a -series and the e -series is similar to that between the u -series and the o -series, respectively. A few propositional attitude indicators overflowed into the i -series as well.
In fact, the entire distinction between pure emotions and propositional attitudes is itself a bit shaky: .u'u can be seen as a propositional attitude indicator meaning “I regret that ...” , and .a'e (discussed below) can be seen as a pure emotion meaning “I'm awake/aware”. The division of the attitudinals into pure-emotion and propositional-attitude classes in this chapter is mostly by way of explanation; it is not intended to permit firm rulings on specific points. Attitudinals are the part of Lojban most distant from the “logical language” aspect.
Here is the list of propositional attitude indicators grouped by initial letter, starting with those beginning with a :
|
.a'a |
attentive |
inattentive |
avoiding |
|
.a'e |
alertness |
exhaustion |
|
|
.ai |
intent |
indecision |
refusal |
|
.a'i |
effort |
no real effort |
repose |
|
.a'o |
hope |
despair |
|
|
.au |
desire |
indifference |
reluctance |
|
.a'u |
interest |
no interest |
repulsion |
Some examples (of a parental kind):
| .a'a | do | zgana | le | veltivni |
| [attentive] | you | observe | the | television-receiver. |
|
I'm noticing that you are watching the TV. |
| .a'enai | do | ranji | bacru |
| [exhaustion] | you | continuously | utter. |
|
I'm worn out by your continuous talking. |
| .a'i | mi | ba | gasnu | le | nu | do | cikna | binxo |
| [effort] | I | [future] | am-the-actor-in | the | event-of | you | awake-ly | become. |
|
It'll be hard for me to wake you up. |
| .a'o | mi | kanryze'a | ca | le | bavlamdei |
| [hope] | I | am-health-increased | at-time | the | future-adjacent-day. |
|
I hope I feel better tomorrow! |
(In a real-life situation, Example 13.25 through Example 13.31 would also be decorated by various pure emotion indicators, certainly including .oicai , but probably also .iucai.)
Splitting off the attitude into an indicator allows the regular bridi grammar to do what it does best: express the relationships between concepts that are intended, desired, hoped for, or whatever. Rephrasing these examples to express the attitude as the main selbri would make for unacceptably heavyweight grammar.
Here are the propositional attitude indicators beginning with e , which stand roughly in the relation to those beginning with a as the pure-emotion indicators beginning with o do to those beginning with u - they are more complex or difficult:
|
.e'a |
permission |
prohibition |
|
|
.e'e |
competence |
incompetence |
|
|
.ei |
obligation |
freedom |
|
|
.e'i |
constraint |
independence |
resistance to constraint |
|
.e'o |
request |
negative request |
|
|
.e'u |
suggestion |
no suggestion |
warning |
More examples (after a good night's sleep):
| .e'e | mi | lifri | tu'a | do |
| [competence] | I | experience | something-related-to | you. |
|
I feel up to dealing with you. |
| .ei | mi | tisygau | le | karce | ctilyvau |
| [obligation] | I | fill | the | car-type-of | petroleum-container. |
|
I should fill the car's gas tank. |
| .e'o | ko | ko | kurji |
| [request] | you-imperative | of-you-imperative | take-care. |
|
Please take care of yourself! |
Finally, the propositional attitude indicators beginning with i , which are the overflow from the other sets:
|
.ia |
belief |
skepticism |
disbelief |
|
.i'a |
acceptance |
blame |
|
|
.ie |
agreement |
disagreement |
|
|
.i'e |
approval |
non-approval |
disapproval |
Still more examples (much, much later):
| .ianai | do | pu | pensi | le | nu | tcica | mi |
| [disbelief] | you | [past] | think | the | event-of | deceiving | me. |
|
I can't believe you thought you could fool me. |
| do | .i'anai | na | xruti | do | le | zdani |
| You | [blame] | did-not | return | you | to-the | house. |
|
I blame you for not coming home. |
| .ie | mi | na | cusku | lu'e |
| [agreement] | I | did-not | express | a-symbol-for |
| le | tcika | be | le | nu | xruti |
| the | time-of-day | of | the | event-of | return. |
|
It's true I didn't tell you when to come back. |
| .i'enai | do | .i'e | zukte |
| [disapproval] | you | [approval] | act. |
|
I don't approve of what you did, but I approve of you. |
Example 13.40 illustrates the use of a propositional attitude indicator, .i'e , in both the usual sense (at the beginning of the bridi) and as a pure emotion (attached to do). The event expressed by the main bridi is disapproved of by the speaker, but the referent of the sumti in the x1 place (namely the listener) is approved of.
To indicate that an attitudinal discussed in this section is not meant to indicate a propositional attitude, the simplest expedient is to split the attitudinal off into a separate sentence. Thus, a version of Example 13.32 which actually claimed that the listener was or would be driving the car might be:
| do | sazri | le | karce | .i | .e'a |
| You | drive | the | car. | [Permission]. |
|
You're driving (or will drive) the car, and that's fine. |
In Lojban, all emotions and attitudes are scales. These scales run from some extreme value (which we'll call “positive”) to an opposite extreme (which we'll call “negative”). In the tables above, we have seen three points on the scale: “positive” , neutral, and “negative”. The terms “positive” and “negative” are put into quotation marks because they are loaded words when applied to emotions, and the attitudinal system reflects this loading, which is a known cultural bias. Only two of the “positive” words, namely .ii (fear) and .oi (pain/complaint), represent emotions commonly thought of as less “virtuous” in most cases than their negative counterparts. But these two were felt to be instinctive, distinct, and very powerful emotions that needed to be expressible in a monosyllable when necessary, while their counterparts are less commonly expressed.
(Why the overt bias? Because there are a lot of attitudinals and they will be difficult to learn as an entire set. By aligning our scales arbitrarily, we give the monosyllable nai a useful meaning and make it easier for a novice to recognize at least the positive or negative alignment of an indicator, if not the specific word. Other choices considered were “random” orientation, which would have unknown biases and be difficult to learn, and orientation based on our guesses as to which scale orientations made the most frequent usages shorter, which would be biased in favor of American perceptions of “usefulness”. If bias must exist in our indicator set, it might as well be a known bias that eases learning, and in addition might as well favor a harmonious and positive world-view.)
In fact, though, each emotional scale has seven positions defined, three “positive” ones (shown below on the left), three “negative” ones (shown below on the right), and a neutral one indicating that no particular attitude on this scale is felt. The following chart indicates the seven positions of the scale and the associated cmavo. All of these cmavo, except nai , are in selma'o CAI.
A scalar attitude is expressed by using the attitudinal word, and then following it by the desired scalar intensity. The bias creeps in because the “negative” emotions take the extra syllable nai to indicate their negative position on the axis, and thus require a bit more effort to express.
Much of this system is optional. You can express an attitude without a scale indicator, if you don't want to stop and think about how strongly you feel. Indeed, for most attitudinals, we've found that either no scalar value is used, or cai is used to indicate especially high intensity. Less often, ru'e is used for a recognizably weak intensity, and cu'i is used in response to the attitudinal question pei (see Section 13.10) to indicate that the emotion is not felt.
The following shows the variations resulting from intensity variation:
| .eicai |
| [obligation-maximal] |
|
I shall/must |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
(an intense obligation or requirement, possibly a formal one) |
| .eisai |
| [obligation-strong] |
|
I should |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
(a strong obligation or necessity, possibly an implied but not formal requirement) |
| .eiru'e |
| [obligation-weak] |
|
I might |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
(a weak obligation – in English often mixed with permission and desire) |
You can also utter a scale indicator without a specific emotion. This is often used in the language: in order to emphasize a point about which you feel strongly, you mark what you are saying with the scale indicator cai. You could also indicate that you don't care using cu'i by itself.
Each of the attitude scales constitutes an axis in a multi-dimensional space. In effect, given our total so far of 39 scales, we have a 39-dimensional space. At any given time, our emotions and attitudes are represented by a point in this 39-dimensional space, with the intensity indicators serving as coordinates along each dimension. A complete attitudinal inventory, should one decide to express it, would consist of reading off each of the scale values for each of the emotions, with the vector sum serving as a distinct single point, which is our attitude.
Now no one is going to ever utter a string of 100-odd attitudinals to express their emotions. If asked, we normally do not recognize more than one or two emotions at a time – usually the ones that are strongest or which most recently changed in some significant way. But the scale system provides some useful insights into a possible theory of emotion (which might be testable using Lojban), and incidentally explains how Lojbanists express compound emotions when they do recognize them.
The existence of 39 scales highlights the complexity of emotion. We also aren't bound to the 39. There are modifiers described in Section 13.6 that multiply the set of scales by an order of magnitude. You can also have mixed feelings on a scale, which might be expressed by cu'i , but could also be expressed by using both the “positive” and “negative” scale emotions at once. One expression of “fortitude” might be .ii.iinai - fear coupled with security.
Uttering one or more attitudinals to express an emotion reflects several things. We will tend to utter emotions in their immediate order of importance to us. We feel several emotions at once, and our expression reflects these emotions simultaneously, although their order of importance to us is also revealing – of our attitude towards our attitude, so to speak. There is little analysis necessary; for those emotions you feel, you express them; the “vector sum” naturally expresses the result. This is vital to their nature as attitudinals – if you had to stop and think about them, or to worry about grammar, they wouldn't be emotions but rationalizations.
People have proposed that attitudinals be expressed as bridi just like everything else; but emotions aren't logical or analytical – saying “I'm awed” is not the same as saying “Wow!!!”. The Lojban system is intended to give the effects of an analytical system without the thought involved. Thus, you can simply feel in Lojban.
A nice feature of this design is that you can be simple or complex, and the system works the same way. The most immediate benefit is in learning. You only need to learn a couple of the scale words and a couple of attitude words, and you're ready to express your emotions Lojbanically. As you learn more, you can express your emotions more thoroughly and more precisely, but even a limited vocabulary offers a broad range of expression.
The Lojban attitudinal system was designed by starting with a long list of English emotion words, far too many to fit into the 39 available VV-form cmavo. To keep the number of cmavo limited, the emotion words in the list were grouped together by common features: each group was then assigned a separate cmavo. This was like making tanru in reverse, and the result is a collection of indicators that can be combined, like tanru, to express very complex emotions. Some examples in a moment.
The most significant “common feature” we identified was that the emotional words on the list could easily be broken down into six major groups, each of which was assigned its own cmavo:
|
ro'a |
social |
asocial |
antisocial |
|
ro'e |
mental |
mindless |
|
|
ro'i |
emotional |
denying emotion |
|
|
ro'o |
physical |
denying physical |
|
|
ro'u |
sexual |
sexual abstinence |
|
|
re'e |
spiritual |
secular |
sacrilegious |
Using these, we were able to assign .o'u to mark a scale of what we might call “generalized comfort”. When you are comfortable, relaxed, satisfied, you express comfort with .o'u , possibly followed by a scale indicator to indicate how comfortable you are. The six cmavo given above allow you to turn this scale into six separate ones, should you wish.
For example, embarrassment is a social discomfort, expressible as .o'unairo'a. Some emotions that we label “stress” in English are expressed in Lojban with .o'unairo'i. Physical distress can be expressed with .o'unairo'o , which makes a nice groan if you say it with feeling. Mental discomfort might be what you feel when you don't know the answer to the test question, but feel that you should. Most adults can recall some instance where we felt sexual discomfort, .o'unairo'u. Spiritual discomfort, .o'unaire'e , might be felt by a church-goer who has wandered into the wrong kind of religious building.
Most of the time when expressing an emotion, you won't categorize it with these words. Emotional expressions should be quickly expressible without having to think about them. However, we sometimes have mixed emotions within this set, as for example emotional discomfort coupled with physical comfort or vice versa.
Coupling these six words with our 39 attitude scales, each of which has a positive and negative side, already gives you far more emotional expression words than we have emotional labels in English. Thus, you'll never see a Lojban-English emotional dictionary that covers all the Lojban possibilities. Some may be useless, but others convey emotions that probably never had a word for them before, though many have felt them ( .eiro'u , for example – look it up).
You can use scale markers and nai on these six category words, and you can also use category words without specifying the emotion. Thus, “I'm trying to concentrate” could be expressed simply as ro'e , and if you are feeling anti-social in some non-specific way, ro'anai will express it.
There is a mnemonic device for the six emotion categories, based on moving your arms about. In the following table, your hands begin above your head and move down your body in sequence.
|
ro'a |
hands above head |
social |
|
ro'e |
hands on head |
intellectual |
|
ro'i |
hands on heart |
emotional |
|
ro'o |
hands on belly |
physical |
|
ro'u |
hands on groin |
sexual |
|
re'e |
hands moving around |
spiritual |
The implicit metaphors “heart” for emotional and “belly” for physical are not really Lojbanic, but they work fine for English-speakers.
The following cmavo are discussed in this section:
|
ga'i |
[galtu] |
hauteur; rank |
equal rank |
meekness; lack of rank |
|
le'o |
aggressive |
passive |
defensive |
|
|
vu'e |
[vrude] |
virtue ( zabna) |
sin ( mabla) |
|
|
se'i |
[sevzi] |
self-orientation |
other-orientation |
|
|
ri'e |
[zifre] |
release |
restraint |
control |
|
fu'i |
[frili] |
with help; easily |
without help |
with opposition; with difficulty |
|
be'u |
lack/need |
presence/satisfaction |
satiation |
|
|
se'a |
[sevzi] |
self-sufficiency |
dependency |
It turned out that, once we had devised the six emotion categories, we also recognized some other commonalities among emotions. These tended to fit nicely on scales of their own, but generally tend not to be thought of as separate emotions. Some of these are self-explanatory, some need to be placed in context. Some of these tend to go well with only a few of the attitudinals, others go with nearly all of them. To really understand these modifiers, try to use them in combination with one or two of the attitudinals found in Section 13.2 and Section 13.3 , and see what emotional pictures you can build:
The cmavo ga'i expresses the scale used to indicate condescension or polite deference; it is not respect in general, which is .io. Whatever it is attached to is marked as being below (for ga'i) or above (for ga'inai) the speaker's rank or social position. Note that it is always the referent, not the speaker or listener, who is so marked: in order to mark the listener, the listener must appear in the sentence, as with doi ga'inai , which can be appended to a statement addressed to a social superior.
| ko | ga'inai | nenri | klama | le | mi | zdani |
| You-imperative | [low-rank!] | enter-type-of | come-to | the | of-me | house. |
|
I would be honored if you would enter my residence. |
Note that imperatives in Lojban need not be imperious! Corresponding examples with ga'icu'i and ga'i :
| ko | ga'icu'i | nenri | klama | le | mi | zdani |
| You-imperative | [equal-rank!] | enter-type-of | come-to | the | of-me | house. |
|
Come on in to my place. |
| ko | ga'i | nenri | klama | le | mi | zdani |
| You-imperative | [high-rank!] | enter-type-of | come-to | the | of-me | house. |
|
You! Get inside! |
Since ga'i expresses the relative rank of the speaker and the referent, it does not make much sense to attach it to mi , unless the speaker is using mi to refer to a group (as in English “we”), or a past or future version of himself with a different rank.
It is also possible to attach ga'i to a whole bridi, in which case it expresses the speaker's superiority to the event the bridi refers to:
| ga'i | le | xarju | pu | citka |
| [High-rank!] | the | pig | [past] | eats. |
|
The pig ate (which is an event beneath my notice). |
When used without being attached to any bridi, ga'i expresses the speaker's superiority to things in general, which may represent an absolute social rank: ga'icai is an appropriate opening word for an emperor's address from the throne.
The cmavo le'o represents the scale of aggressiveness. We seldom overtly recognize that we are feeling aggressive or defensive, but perhaps in counseling sessions, a psychologist might encourage someone to express these feelings on this scale. And football teams could be urged on by their coach using ro'ole'o. le'o is also useful in threats as an alternative to .o'onai , which expresses anger.
The cmavo vu'e represents ethical virtue or its absence. An excess of almost any emotion is usually somewhat “sinful” in the eyes of most ethical systems. On the other hand, we often feel virtuous about our feelings – what we call righteous indignation might be .o'onaivu'e. Note that this is distinct from lack of guilt: .u'unai.
The cmavo se'i expresses the difference between selfishness and generosity, for example (in combination with .au):
In both cases, the English “it” is vague, reflecting the absence of a bridi. Example 13.52 and Example 13.53 are pure expressions of attitude. Analogously, .uuse'i is self-pity, whereas .uuse'inai is pity for someone else.
The modifier ri'e indicates emotional release versus emotional control. “I will not let him know how angry I am” , you say to yourself before entering the room. The Lojban is much shorter:
On the other hand, ri'e can be used by itself to signal an emotional outburst.
The cmavo fu'i may express a reason for feeling the way we do, as opposed to a feeling in itself; but it is a reason that is more emotionally determined than most. For example, it could show the difference between the mental discomfort mentioned in Section 13.6 when it is felt on an easy test, as opposed to on a hard test. When someone gives you a back massage, you could use .o'ufu'i to show appreciation for the assistance in your comfort.
The cmavo be'u expresses, roughly speaking, whether the emotion it modifies is in response to something you don't have enough of, something you have enough of, or something you have too much of. It is more or less the attitudinal equivalent of the subjective quantifier cmavo mo'a , rau , and du'e (these belong to selma'o PA, and are discussed in Section 18.8). For example,
might be something you say after a large meal which you enjoyed.
Like all modifiers, be'u can be used alone:
| le | cukta | be'u | cu | zvati | ma |
| The | book | [Needed!] | is-at-location | [what-sumti?] |
|
Where's the book? – I need it! |
Lastly, the modifier se'a shows whether the feeling is associated with self-sufficiency or with dependence on others.
is something a Lojban-speaking child might say. On the other hand,
from the same child would indicate a (hopefully temporary) loss of self-confidence. It is also possible to negate the .e'e in Example 13.54 and Example 13.55 , leading to:
and
Some of the emotional expressions may seem too complicated to use. They might be for most circumstances. It is likely that most combinations will never get used. But if one person uses one of these expressions, another person can understand (as unambiguously as the expresser intends) what emotion is being expressed. Most probably as the system becomes well-known and internalized by Lojban-speakers, particular attitudinal combinations will come to be standard expressions (if not cliches) of emotion.
The grammar of indicators is quite simple; almost all facets are optional. You can combine indicators in any order, and they are still grammatical. The presumed denotation is additive; thus the whole is the sum of the parts regardless of the order expressed, although the first expressed is presumed most important to the speaker. Every possible string of UI cmavo has some meaning.
Within a string of indicators, there will be conventions of interpretation which amount to a kind of second-order grammar. Each of the modifier words is presumed to modify an indicator to the left, if there is one. (There is an “unspecified emotion” word, ge'e , reserved to ensure that if you want to express a modifier without a root emotion, it doesn't attach to and modify a previous but distinct emotional expression.)
For example, .ieru'e expresses a weak positive value on the scale of agreement: the speaker agrees (presumably with the listener or with something else just stated), but with the least possible degree of intensity. But .ie ge'eru'e expresses agreement (at an unspecified level), followed by some other unstated emotion which is felt at a weak level. A rough English equivalent of .ie ge'eru'e might be “I agree, but ...” where the “but” is left hanging. (Again, attitudes aren't always expressed in English by English attitudinals.)
A scale variable similarly modifies the previous emotion word. You put the scale word for a root emotion word before a modifier, since the latter can have its own scale word. This merely maximizes the amount of information expressible. For example, .oinaicu'i ro'ucai expresses a feeling midway between pain ( .oi) and pleasure ( .oinai) which is intensely sexual ( ro'u) in nature.
The cmavo nai is the most tightly bound modifier in the language: it always negates exactly one word – the preceding one. Of all the words used in indicator constructs, nai is the only one with any meaning outside the indicator system. If you try to put an indicator between a non-indicator cmavo and its nai negator, the nai will end up negating the last word of the indicator. The result, though unambiguous, is not what you want. For example,
means “I and (unfortunately) you” , whereas
means “I but (fortunately) not you”. Attitudinal nai expresses a “scalar negation” , a concept explained in Section 15.3 ; since every attitudinal word implies exactly one scale, the effect of nai on each should be obvious.
Thus, the complete internal grammar of UI is as follows, with each listed part optionally present or absent without affecting grammaticality, though it obviously would affect meaning.
| attitudinal | nai | intensity-word | nai | modifier | nai | intensity-word | nai | (possiblyrepeated) |
ge'e , the non-specific emotion word, functions as an attitudinal. If multiple attitudes are being expressed at once, then in the 2nd or greater position, either ge'e or a VV word must be used to prevent any modifiers from modifying the previous attitudinal.
The behavior of indicators in the “outside grammar” is nearly as simple as their internal structure. Indicator groupings are identified immediately after the metalinguistic erasers si , sa , and su and some, though not all, kinds of quotations. The details of such interactions are discussed in Section 19.16.
A group of indicators may appear anywhere that a single indicator may, except in those few situations (as in zo quotation, explained in Section 19.10) where compound cmavo may not be used.
At the beginning of a text, indicators modify everything following them indefinitely: such a usage is taken as a raw emotional expression, and we normally don't turn off our emotions when we start and stop sentences. In every other place in an utterance, the indicator (or group) attaches to the word immediately to its left, and indicates that the attitude is being expressed concerning the object or concept to which the word refers.
If the word that an indicator (or group) attaches to is itself a cmavo which governs a grammatical structure, then the indicator construct pertains to the referent of the entire structure. There is also a mechanism, discussed in Section 19.8 , for explicitly marking the range of words to which an indicator applies.
More details about the uses of indicators, and the way they interact with other specialized cmavo, are given in Chapter 19. It is worth mentioning that real-world interpretation is not necessarily consistent with the formal scope rules. People generally express emotions when they feel them, with only a minimum of grammatical constraint on that expression; complexities of emotional expression are seldom logically analyzable. Lojban attempts to provide a systematic reference that could possibly be ingrained to an instinctive level. However, it should always be assumed that the referent of an indicator has some uncertainty.
For example, in cases of multiple indicators expressed together, the combined form has some ambiguity of interpretation. It is possible to interpret the second indicator as expressing an attitude about the first, or to interpret both as expressing attitudes about the common referent. For example, in
can be interpreted as expressing complaint about the anger, in which case it means “Damn, I snapped at you” ; or as expressing both anger and complaint about the listener, in which case it means “I told you, you pest!”
Similarly, an indicator after the final brivla of a tanru may be taken to express an attitude about the particular brivla placed there – as the rules have it – or about the entire bridi which hinges on that brivla. Remembering that indicators are supposedly direct expressions of emotion, this ambiguity is acceptable.
Even if the scope rules given for indicators turn out to be impractical or unintuitive for use in conversation, they are still useful in written expression. There, where you can go back and put in markers or move words around, the scope rules can be used in lieu of elaborate nuances of body language and intonation to convey the writer's intent.
The following cmavo are discussed in this section:
|
pei |
attitude question |
||
|
dai |
empathy |
||
|
bu'o |
start emotion |
continue emotion |
end emotion |
You can ask someone how they are feeling with a normal bridi sentence, but you will get a normal bridi answer in response, one which may be true or false. Since the response to a question about emotions is no more logical than the emotion itself, this isn't appropriate.
The word pei is therefore reserved for attitude questions. Asked by itself, it captures all of the denotation of English “How are you?” coupled with “How do you feel?” (which has a slightly different range of usage).
When asked in the context of discourse, pei acts like other Lojban question words – it requests the respondent to “fill in the blank” , in this case with an appropriate attitudinal describing the respondent's feeling about the referent expression. As with other questions, plausibility is polite; if you answer with an irrelevant UI cmavo, such as a discursive, you are probably making fun of the questioner. (A ge'e , however, is always in order – you are not required to answer emotionally. This is not the same as .i'inai , which is privacy as the reverse of conviviality.)
Most often, however, the asker will use pei as a place holder for an intensity marker. (As a result, pei is placed in selma'o CAI, although selma'o UI would have been almost as appropriate. Grammatically, there is no difference between UI and CAI.) Such usage corresponds to a whole range of idiomatic usages in natural languages:
Example 13.66 might appear at the end of a command, to which the response
corresponds to “Aye! Aye!” (hence the choice of cmavo).
Additionally, when pei is used at the beginning of an indicator construct, it asks specifically if that construct reflects the attitude of the respondent, as in (asked of someone who has been ill or in pain):
Empathy, which is not really an emotion, is expressed by the indicator dai. (Don't confuse empathy with sympathy, which is .uuse'inai.) Sometimes, as when telling a story, you want to attribute emotion to someone else. You can of course make a bridi claim that so-and-so felt such-and-such an emotion, but you can also make use of the attitudinal system by adding the indicator dai , which attributes the preceding attitudinal to someone else – exactly whom, must be determined from context. You can also use dai conversationally when you empathize, or feel someone else's emotion as if it were your own:
It is even possible to “empathize” with a non-living object:
| le | bloti | .iidai | .uu | pu | klama | le | xasloi |
| The | ship | [fear-empathy] | [pity!] | [past] | goes-to | the | ocean-floor. |
|
Fearfully the ship, poor thing, sank. |
suggesting that the ship felt fear at its impending destruction, and simultaneously reporting the speaker's pity for it.
Both pei and dai represent exceptions to the normal rule that attitudinals reflect the speaker's attitude.
Finally, we often want to report how our attitudes are changing. If our attitude has not changed, we can just repeat the attitudinal. (Therefore, .ui .ui .ui is not the same as .uicai , but simply means that we are continuing to be happy.) If we want to report that we are beginning to feel, continuing to feel, or ceasing to feel an emotion, we can use the attitudinal contour cmavo bu'o.
When attached to an attitudinal, bu'o means that you are starting to have that attitude, bu'ocu'i that you are continuing to have it, and bu'onai that you are ceasing to have it. Some examples:
Note the difference in effect between Example 13.75 and:
| mi | ca | ba'o | prami | do | ja'e | le | nu | mi | badri |
| I | [present] | [cessitive] | love | you | with-result | the | event-of | (I | am-sad). |
|
I no longer love you; therefore, I am sad. |
which is a straightforward bridi claim. Example 13.76 states that you have (or have had) certain emotions; Example 13.75 expresses those emotions directly.
The following cmavo are discussed in this section:
|
ja'o |
[jalge] |
I conclude |
||
|
ca'e |
I define |
|||
|
ba'a |
[balvi] |
I expect |
I experience |
I remember |
|
su'a |
[sucta] |
I generalize |
I particularize |
|
|
ti'e |
[tirna] |
I hear (hearsay) |
||
|
ka'u |
[kulnu] |
I know by cultural means |
||
|
se'o |
[senva] |
I know by internal experience |
||
|
za'a |
[zgana] |
I observe |
||
|
pe'i |
[pensi] |
I opine |
||
|
ru'a |
[sruma] |
I postulate |
||
|
ju'a |
[jufra] |
I state |
Now we proceed from the attitudinal indicators and their relatives to the other, semantically unrelated, categories of indicators. The indicators known as “evidentials” show how the speaker came to say the utterance; i.e. the source of the information or the idea. Lojban's list of evidentials was derived from lists describing several American Indian languages. Evidentials are also essential to the constructed language Láadan, designed by the linguist and novelist Suzette Haden Elgin. Láadan's set of indicators was drawn on extensively in developing the Lojban indicator system.
It is important to realize, however, that evidentials are not some odd system used by some strange people who live at the other end of nowhere: although their English equivalents aren't single words, English-speakers have vivid notions of what constitutes evidence, and of the different kinds of evidence.
Like the attitudinal indicators, the evidentials belong to selma'o UI, and may be treated identically for grammatical purposes. Most of them are not usually considered scalar in nature, but a few have associated scales.
A bridi with an evidential in it becomes “indisputable” , in the sense that the speaker is saying “how it is with him or her” , which is beyond argument. Claims about one's own mental states may be true or false, but are hardly subject to other people's examination. If you say that you think, or perceive, or postulate such-and-such a predication, who can contradict you? Discourse that uses evidentials has therefore a different rhetorical flavor than discourse that does not; arguments tend to become what can be called dialogues or alternating monologues, depending on your prejudices.
Evidentials are most often placed at the beginning of sentences, and are often attached to the .i that separates sentences in connected discourse. It is in the nature of an evidential to affect the entire bridi in which it is placed: like the propositional attitude indicators, they strongly affect the claim made by the main bridi.
A bridi marked by ja'o is a conclusion by the speaker based on other (stated or unstated) information or ideas. Rough English equivalents of ja'o are “thus” and “therefore”.
A bridi marked by ca'e is true because the speaker says so. In addition to definitions of words, ca'e is also appropriate in what are called performatives, where the very act of speaking the words makes them true. An English example is “I now pronounce you husband and wife” , where the very act of uttering the words makes the listeners into husband and wife. A Lojban translation might be:
The three scale positions of ba'a , when attached to a bridi, indicate that it is based on the speaker's view of the real world. Thus ba'a means that the statement represents a future event as anticipated by the speaker; ba'acu'i , a present event as experienced by the speaker; ba'anai , a past event as remembered by the speaker. It is accidental that this scale runs from future to past instead of past to future.
| ba'acu'i | le | tuple | be | mi | cu | se cortu |
| [I-experience!] | the | leg | of | me | is-the-locus-of-pain. |
|
My leg hurts. |
A bridi marked by su'a is a generalization by the speaker based on other (stated or unstated) information or ideas. The difference between su'a and ja'o is that ja'o suggests some sort of reasoning or deduction (not necessarily rigorous), whereas su'a suggests some sort of induction or pattern recognition from existing examples (not necessarily rigorous).
The opposite point of the scale, su'anai , indicates abduction, or drawing specific conclusions from general premises or patterns.
This cmavo can also function as a discursive (see Section 13.12), in which case su'a means “abstractly” or “in general” , and su'anai means “concretely” or “in particular”.
A bridi marked by ti'e is relayed information from some source other than the speaker. There is no necessary implication that the information was relayed via the speaker's ears; what we read in a newspaper is an equally good example of ti'e , unless we have personal knowledge of the content.
A bridi marked by ka'u is one held to be true in the speaker's cultural context, as a matter of myth or custom, for example. Such statements should be agreed on by a community of people – you cannot just make up your own cultural context – although “objectivity” in the sense of actual correspondence with the facts is certainly not required.
On the other hand, se'o marks a bridi whose truth is asserted by the speaker as a result of an internal experience not directly available to others, such as a dream, vision, or personal revelation. In some cultures, the line between ka'u and se'o is fuzzy or even nonexistent.
A bridi marked by za'a is based on perception or direct observation by the speaker. This use of “observe” is not connected with the Lojban “observative” , or bridi with the first sumti omitted. The latter has no explicit aspect, and could be a direct observation, a conclusion, an opinion, or other aspectual point of view.
A bridi marked by pe'i is the opinion of the speaker. The form pe'ipei is common, meaning “Is this your opinion?”. (Strictly, this should be peipe'i , in accordance with the distinction explained in Example 13.69 through Example 13.71 , but since pe'i is not really a scale, there is no real difference between the two orders.)
| pe'i | la | .kartagos. | .ei | se daspo |
| [I-opine!] | that-named | Carthage | [obligation] | is-destroyed. |
|
In my opinion, Carthage should be destroyed. |
A bridi marked by ru'a is an assumption made by the speaker. This is similar to one possible use of .e'u.
| ru'a | doi | .livinston. |
| [I-presume] | o | Livingstone. |
|
Dr. Livingstone, I presume? (A rhetorical question: Stanley knew who he was.) |
Finally, the evidential ju'a is used to avoid stating a specific basis for a statement. It can also be used when the basis for the speaker's statement is not covered by any other evidential. For the most part, using ju'a is equivalent to using no evidential at all, but in question form it can be useful: ju'apei means “What is the basis for your statement?” and serves as an evidential, as distinct from emotional, question.
The term “discursive” is used for those members of selma'o UI that provide structure to the discourse, and which show how a given word or utterance relates to the whole discourse. To express these concepts in regular bridi would involve extra layers of nesting: rather than asserting that “I also came” , we would have to say “I came; furthermore, the event of my coming is an additional instance of the relationship expressed by the previous sentence” , which is intolerably clumsy. Typical English equivalents of discursives are words or phrases like “however” , “summarizing” , “in conclusion” , and “for example”.
Discursives are not attitudinals: they express no particular emotion. Rather, they are abbreviations for metalinguistic claims that reference the sentence or text they are found in.
Discursives are most often used at the beginning of sentences, often attached to the .i that separates sentences in running discourse, but can (like all other indicators) be attached to single words when it seems necessary or useful.
The discursives discussed in this section are given in groups, roughly organized by function. First, the “consecutive discourse” group:
|
ku'i |
[karbi] |
however/but/in contrast |
|
ji'a |
[jmina] |
additionally |
|
si'a |
[simsa] |
similarly |
|
mi'u |
[mintu] |
ditto |
|
po'o |
the only relevant case |
These five discursives are mutually exclusive, and therefore they are not usually considered as scales. The first four are used in consecutive discourse. The first, ku'i , makes an exception to the previous argument. The second, ji'a , adds weight to the previous argument. The third, si'a , adds quantity to the previous argument, enumerating an additional example. The fourth, mi'u , adds a parallel case to the previous argument, and can also be used in tables or the like to show that something is being repeated from the previous column. It is distinct from go'i (of selma'o GOhA, discussed in Section 7.6), which is a non-discursive version of “ditto” that explicitly repeats the claim of the previous bridi.
Lastly, po'o is used when there is no other comparable case, and thus corresponds to some of the uses of “only” , a word difficult to express in pure bridi form:
| mi | po'o | darxi | le | mi | tamne | fo | le | nazbi |
| I | [only] | hit | the | of-me | cousin | at-locus | the | nose. |
|
Only I (nobody else) hit my cousin on his nose. |
| mi | darxi | po'o | le | mi | tamne | fo | le | nazbi |
| I | hit | [only] | the | of-me | cousin | at-locus | the | nose. |
|
I only hit my cousin on his nose (I did nothing else to him). |
| mi | darxi | le | mi | tamne | ku | po'o | fo | le | nazbi |
| I | hit | the | of-me | cousin | [only] | at-locus | the | nose. |
|
I hit only my cousin on his nose (no one else). |
| mi | darxi | le | mi | tamne | fo | le | nazbi | ku | po'o |
| I | hit | the | of-me | cousin | at-locus | the | nose | [only]. |
|
I hit my cousin only on his nose (nowhere else). |
Note that “only” can go before or after what it modifies in English, but po'o , as an indicator, always comes afterward.
Next, the “commentary on words” group:
|
va'i |
[valsi] |
in other words |
in the same words |
|
ta'u |
[tanru] |
expanding a tanru |
making a tanru |
The discursives va'i and ta'u operate at the level of words, rather than discourse proper, or if you like, they deal with how things are said. An alternative English expression for va'i is “rephrasing” ; for va'inai , “repeating”. Also compare va'i with ke'u , discussed below.
The cmavo ta'u is a discursive unique to Lojban; it expresses the particularly Lojbanic device of tanru. Since tanru are semantically ambiguous, they are subject to misunderstanding. This ambiguity can be removed by expanding the tanru into some semantically unambiguous structure, often involving relative clauses or the introduction of additional brivla. The discursive ta'u marks the transition from the use of a brief but possibly confusing tanru to its fuller, clearer expansion; the discursive ta'unai marks a transition in the reverse direction.
Next, the “commentary on discourse” group:
|
li'a |
[klina] |
clearly; obviously |
obscurely |
|
|
ba'u |
[banli] |
exaggeration |
accuracy |
understatement |
|
zo'o |
humorously |
dully |
seriously |
|
|
sa'e |
[satci] |
precisely speaking |
loosely speaking |
|
|
to'u |
[tordu] |
in brief |
in detail |
|
|
do'a |
[dunda] |
generously |
parsimoniously |
|
|
sa'u |
[sampu] |
simply |
elaborating |
|
|
pa'e |
[pajni] |
justice |
prejudice |
|
|
je'u |
[jetnu] |
truly |
falsely |
This group is used by the speaker to characterize the nature of the discourse, so as to prevent misunderstanding. It is well-known that listeners often fail to recognize a humorous statement and take it seriously, or miss an exaggeration, or try to read more into a statement than the speaker intends to put there. In speech, the tone of voice often provides the necessary cue, but the reader of ironic or understated or imprecise discourse is often simply clueless. As with the attitudinals, the use of these cmavo may seem fussy to new Lojbanists, but it is important to remember that zo'o , for example, is the equivalent of smiling while you speak, not the equivalent of a flat declaration like “What I'm about to say is supposed to be funny.”
A few additional English equivalents: for sa'enai , “roughly speaking” or “approximately speaking” ; for sa'unai , “furthermore” ; for to'u , “in short” or “skipping details” ; for do'a , “broadly construed” ; for do'anai (as you might expect), “narrowly construed”.
The cmavo pa'e is used to claim (truly or falsely) that one is being fair or just to all parties mentioned, whereas pa'enai admits (or proclaims) a bias in favor of one party.
The scale of je'u and je'unai is a little different from the others in the group. By default, we assume that people speak the truth – or at least, that if they are lying, they will do their best to conceal it from us. So under what circumstances would je'unai be used, or je'u be useful? For one thing, je'u can be used to mark a tautology: a sentence that is a truth of logic, like “All cats are cats.” Its counterpart je'unai then serves to mark a logical contradiction. In addition, je'unai can be used to express one kind of sarcasm or irony, where the speaker pretends to believe what he/she says, but actually wishes the listener to infer a contrary opinion. Other forms of irony can be marked with zo'o (humor) or .ianai (disbelief).
When used as a discursive, su'a (see Section 13.11) belongs to this group.
Next, the “knowledge” group:
|
ju'o |
[djuno] |
certainly |
uncertain |
certainly not |
|
la'a |
[lakne] |
probably |
improbably |
These two discursives describe the speaker's state of knowledge about the claim of the associated bridi. They are similar to the propositional attitudes of Section 13.3 , as they create a hypothetical world. We may be quite certain that something is true, and label our bridi with ju'o ; but it may be false all the same.
Next, the “discourse management” group:
|
ta'o |
[tanjo] |
by the way |
returning to point |
|
|
ra'u |
[ralju] |
chiefly |
equally |
incidentally |
|
mu'a |
[mupli] |
for example |
omitting examples |
end examples |
|
zu'u |
on the one hand |
on the other hand |
||
|
ke'u |
[krefu] |
repeating |
continuing |
|
|
da'i |
supposing |
in fact |
This final group is used to perform what may be called “managing the discourse” : providing reference points to help the listener understand the flow from one sentence to the next.
Other English equivalents of ta'onai are “anyway” , “anyhow” , “in any case” , “in any event” , “as I was saying” , and “continuing”.
The scale of ra'u has to do with the importance of the point being, or about to be, expressed: ra'u is the most important point, ra'ucu'i is a point of equal importance, and ra'unai is a lesser point. Other English equivalents of ra'u are “above all” and “primarily”.
The cmavo ke'u is very similar to va'i , although ke'unai and va'inai are quite different. Both ke'u and va'i indicate that the same idea is going to be expressed using different words, but the two cmavo differ in emphasis. Using ke'u emphasizes that the content is the same; using va'i emphasizes that the words are different. Therefore, ke'unai shows that the content is new (and therefore the words are also); va'inai shows that the words are the same (and therefore so is the content). One English equivalent of ke'unai is “furthermore”.
The discursive da'i marks the discourse as possibly taking a non-real-world viewpoint ( “Supposing that” , “By hypothesis”), whereas da'inai insists on the real-world point of view ( “In fact” , “In truth” , “According to the facts”). A common use of da'i is to distinguish between:
| ganai | da'i | do | viska | le | mi | citno | mensi |
| If | [hypothetical] | you | see | the | of-me | young | sister, |
| gi | ju'o | do | djuno | le | du'u | ri | pazvau |
| then | [certain] | you | know | the | predication-of | she | is-pregnant. |
|
If you were to see my younger sister, you would certainly know she is pregnant. |
| ganai | da'inai | do | viska | le | mi | citno | mensi |
| If | [factual] | you | see | the | of-me | young | sister, |
| gi | ju'o | do | djuno | le | du'u | ri | pazvau |
| then | [certainty] | you | know | the | predication-of | she | is-pregnant. |
|
If you saw my younger sister, you would certainly know she is pregnant. |
It is also perfectly correct to omit the discursive altogether, and leave the context to indicate which significance is meant. (Chinese always leaves this distinction to the context: the Chinese sentence
-
如果你看到我的妹妹,你一定会知道,她怀孕了。
-
Rúguǒ nǐ kàn dào wǒ de mèimei, nǐ yīdìng huì zhīdào, tā huáiyùnle.
-
if you see-arrive my younger-sister, you certainly know she pregnant
is the equivalent of either Example 13.87 or Example 13.88.)
Some indicators do not fall neatly into the categories of attitudinal, evidential, or discursive. This section discusses the following miscellaneous indicators:
|
ki'a |
metalinguistic confusion |
||
|
na'i |
metalinguistic negator |
||
|
jo'a |
metalinguistic affirmer |
||
|
li'o |
omitted text (quoted material) |
||
|
sa'a |
material inserted by editor/narrator |
||
|
xu |
true-false question |
||
|
pau |
question premarker |
rhetorical question |
|
|
pe'a |
figurative language |
literal language |
|
|
bi'u |
new information |
old information |
|
|
ge'e |
non-specific indicator |
The cmavo ki'a is one of the most common of the miscellaneous indicators. It expresses metalinguistic confusion; i.e. confusion about what has been said, as opposed to confusion not tied to the discourse (which is .uanai). The confusion may be about the meaning of a word or of a grammatical construct, or about the referent of a sumti. One of the uses of English “which” corresponds to ki'a :
Here, the second speaker does not understand the referent of the sumti le ctuca , and so echoes back the sumti with the confusion marker.
The metalinguistic negation cmavo na'i and its opposite jo'a are explained in full in Chapter 15. In general, na'i indicates that there is something wrong with a piece of discourse: either an error, or a false underlying assumption, or something else of the sort. The discourse is invalid or inappropriate due to the marked word or construct.
Similarly, jo'a marks something which looks wrong but is in fact correct. These two cmavo constitute a scale, but are kept apart for two reasons: na'inai means the same as jo'a , but would be too confusing as an affirmation; jo'anai means the same as na'i , but is too long to serve as a convenient metalinguistic negator.
The next two cmavo are used to assist in quoting texts written or spoken by others. It is often the case that we wish to quote only part of a text, or to supply additional material either by way of commentary or to make a fragmentary text grammatical. The cmavo li'o serves the former function. It indicates that words were omitted from the quotation. What remains of the quotation must be grammatical, however, as li'o does not serve any grammatical function. It cannot, for example, take the place of a missing selbri in a bridi, or supply the missing tail of a description sumti: le li'o in isolation is not grammatical.
The cmavo sa'a indicates in a quotation that the marked word or construct was not actually expressed, but is inserted for editorial, narrative, or grammatical purposes. Strictly, even a li'o should appear in the form li'osa'a , since the li'o was not part of the original quotation. In practice, this and other forms which are already associated with metalinguistic expressions, such as sei (of selma'o SEI) or to'i (of selma'o TO) need not be marked except where confusion might result.
In the rare case that the quoted material already contains one or more instances of sa'a , they can be changed to sa'asa'a.
The cmavo xu marks truth questions, which are discussed in detail in Section 15.8. In general, xu may be translated “Is it true that ... ?” and questions whether the attached bridi is true. When xu is attached to a specific word or construct, it directs the focus of the question to that word or construct.
Lojban question words, unlike those of English, frequently do not stand at the beginning of the question. Placing the cmavo pau at the beginning of a bridi helps the listener realize that the bridi is a question, like the symbol at the beginning of written Spanish questions that looks like an upside-down question mark. The listener is then warned to watch for the actual question word.
Although pau is grammatical in any location (like all indicators), it is not really useful except at or near the beginning of a bridi. Its scalar opposite, paunai , signals that a bridi is not really a question despite its form. This is what we call in English a rhetorical question: an example appears in the English text near the beginning of Section 13.11.
The cmavo pe'a is the indicator of figurative speech, indicating that the previous word should be taken figuratively rather than literally:
Here the house is not blue in the sense of color, but in some other sense, whose meaning is entirely culturally dependent. The use of pe'a unambiguously marks a cultural reference: blanu in Example 13.91 could mean “sad” (as in English) or something completely different.
The negated form, pe'anai , indicates that what has been said is to be interpreted literally, in the usual way for Lojban; natural-language intuition is to be ignored.
Alone among the cmavo of selma'o UI, pe'a has a rafsi, namely pev. This rafsi is used in forming figurative (culturally dependent) lujvo, whose place structure need have nothing to do with the place structure of the components. Thus risnyjelca (heart burn) might have a place structure like:
x1 is the heart of x2, burning in atmosphere x3 at temperature x4
whereas pevrisnyjelca , explicitly marked as figurative, might have the place structure:
x1 is indigestion/heartburn suffered by x2
which obviously has nothing to do with the places of either risna or jelca.
The uses of bi'u and bi'unai correspond to one of the uses of the English articles “the” and “a/an”. An English-speaker telling a story may begin with “I saw a man who ...”. Later in the story, the same man will be referred to with the phrase “the man”. Lojban does not use its articles in the same way: both “a man” and “the man” would be translated le nanmu , since the speaker has in mind a specific man. However, the first use might be marked le bi'u nanmu , to indicate that this is a new man, not mentioned before. Later uses could correspondingly be tagged le bi'unai nanmu.
Most of the time, the distinction between bi'u and bi'unai need not be made, as the listener can infer the right referent. However, if a different man were referred to still later in the story, le bi'u nanmu would clearly show that this man was different from the previous one.
Finally, the indicator ge'e has been discussed in Section 13.8 and Section 13.10. It is used to express an attitude which is not covered by the existing set, or to avoid expressing any attitude.
Another use for ge'e is to explicitly avoid expressing one's feeling on a given scale; in this use, it functions like a member of selma'o CAI: .iige'e means roughly “I'm not telling whether I'm afraid or not.”
|
kau |
indirect question |
This cmavo is explained in detail in Section 11.8. It marks the word it is attached to as the focus of an indirect question:
| mi | djuno | le | du'u | dakau | klama | le | zarci |
| I | know | the | predication-of | somebody-[indirect?] | goes | to-the | store. |
|
I know who goes to the store. |
“Vocatives” are words used to address someone directly; they precede and mark a name used in direct address, just as la (and the other members of selma'o LA) mark a name used to refer to someone. The vocatives actually are indicators – in fact, discursives – but the need to tie them to names and other descriptions of listeners requires them to be separated from selma'o UI. But like the cmavo of UI, the members of selma'o COI can be “negated” with nai to get the opposite part of the scale.
Because of the need for redundancy in noisy environments, the Lojban design does not compress the vocatives into a minimum number of scales. Doing so would make a non-redundant nai too often vital to interpretation of a protocol signal, as explained later in this section.
The grammar of vocatives is explained in Section 6.11 ; but in brief, a vocative may be followed by a cmevla (without la), a description (without le or its relatives), a complete sumti, or nothing at all (if the addressee is obvious from the context). There is an elidable terminator, do'u (of selma'o DOhU) which is almost never required unless no cmevla (or other indication of the addressee) follows the vocative.
Using any vocative except mi'e (explained below) implicitly defines the meaning of the pro-sumti do , as the whole point of vocatives is to specify the listener, or at any rate the desired listener – even if the desired listener isn't listening! We will use the terms “speaker” and “listener” for clarity, although in written Lojban the appropriate terms would be “writer” and “reader”.
In the following list of vocatives, the translations include the symbol X. This represents the name (or identifying description, or whatever) of the listener.
The cmavo doi is the general-purpose vocative. It is not considered a scale, and doinai is not grammatical. In general, doi needs no translation in English (we just use names by themselves without any preceding word, although in poetic styles we sometimes say “Oh X” , which is equivalent to doi). One may attach an attitudinal to doi to express various English vocatives. For example, doi .io means “Sir/Madam!” , whereas doi .ionai means “You there!”.
|
coi |
greetings |
|
“Hello, X” ; “Greetings, X” ; indicates a greeting to the listener. |
|
co'o |
partings |
|
“Good-bye, X” ; indicates parting from immediate company by either the speaker or the listener. coico'o means “greeting in passing”. |
|
ju'i |
[jundi] |
attention |
at ease |
ignore me/us |
|
“Attention/Lo/Hark/Behold/Hey!/Listen, X” ; indicates an important communication that the listener should listen to. |
|
nu'e |
[nupre] |
promise |
release promise |
non-promise |
|
“I promise, X” ; indicates a promise to the listener. In some contexts, nu'e may be prefixed to an oath or other formal declaration. |
|
ta'a |
[tavla] |
interruption |
|
“I interrupt, X” , “I desire the floor, X” ; a vocative expression to (possibly) interrupt and claim the floor to make a statement or expression. This can be used for both rude and polite interruptions, although rude interruptions will probably tend not to use a vocative at all. An appropriate response to an interruption might be re'i (or re'inai to ignore the interruption). |
|
pe'u |
[cpedu] |
request |
|
“Please, X” ; indicates a request to the listener. It is a formal, non-attitudinal, equivalent of .e'o with a specific recipient being addressed. On the other hand, .e'o may be used when there is no specific listener, but merely a “sense of petition floating in the air” , as it were. |
|
ki'e |
[ckire] |
appreciation; gratitude |
disappreciation; ingratitude |
|
“Thank you, X” ; indicates appreciation or gratitude toward the listener. The usual response is je'e , but fi'i is appropriate on rare occasions: see the explanation of fi'i. |
|
fi'i |
[friti] |
welcome; offering |
unwelcome; inhospitality |
|
“At your service, X” ; “Make yourself at home, X” ; offers hospitality (possibly in response to thanks, but not necessarily) to the listener. Note that fi'i is not the equivalent of American English “You're welcome” as a mechanical response to “Thank you” ; that is je'e , as noted below. |
|
be'e |
[benji] |
request to send |
|
re'i |
[bredi] |
ready to receive |
not ready |
|
“Ready to receive, X” ; indicates that the speaker is attentive and awaiting communication from the listener. It can be used instead of mi'e to respond when called to the telephone. The negative form can be used to prevent the listener from continuing to talk when the speaker is unable to pay attention: it can be translated “Hold on!” or “Just a minute”. |
|
mu'o |
[mulno] |
completion of utterance |
more to follow |
|
“Over, X” ; indicates that the speaker has completed the current utterance and is ready to hear a response from the listener. The negative form signals that the pause or non-linguistic sound which follows does not represent the end of the current utterance: more colloquially, “I'm not done talking!” |
|
je'e |
[jimpe] |
successful receipt |
unsuccessful receipt |
|
“Roger, X!” , “I understand” ; acknowledges the successful receipt of a communication from the listener. The negative form indicates failure to receive correctly, and is usually followed by ke'o. The colloquial English equivalents of je'e and je'enai are the grunt typically written “uh-huh” and “What?/Excuse me?”. je'e is also used to mean “You're welcome” when that is a response to “Thank you”. |
|
vi'o |
will comply |
will not comply |
|
“Wilco, X” , “I understand and will comply”. Similar to je'e but signals an intention (similar to .ai) to comply with the other speaker's request. This cmavo is the main way of saying “OK” in Lojban, in the usual sense of “Agreed!” , although .ie carries some of the same meaning. The negative form indicates that the message was received but that you will not comply: a very colloquial version is “No way!”. |
|
ke'o |
[krefu] |
please repeat |
no repeat needed |
|
“What did you say, X?” ; a request for repetition or clarification due to unsuccessful receipt or understanding. This is the vocative equivalent of ki'a , and is related to je'enai. The negative form may be rendered “Okay, already; I get the point!” |
|
fe'o |
[fanmo] |
end of communication |
not done |
|
“Over and out, X” ; indicates completion of statement(s) and communication directed at the identified person(s). Used to terminate a letter if a signature is not required because the sender has already been identified (as in memos). The negative form means “Wait, hold it, we're not done!” and differs from mu'onai in that it means more exchanges are to follow, rather than that the current exchange is incomplete. Do not confuse fe'o with fa'o (selma'o FAhO) which is a mechanical, extra-grammatical signal that a text is complete. One may say fe'o to one participant of a multi-way conversation and then go on speaking to the others. |
|
mi'e |
[cmavo: mi] |
self-identification |
non-identification |
|
“And I am X” ; a generalized self-vocative. Although grammatically just like the other members of selma'o COI, mi'e is quite different semantically. In particular, rather than specifying the listener, the person whose name (or description) follows mi'e is taken to be the speaker. Therefore, using mi'e specifies the meaning of the pro-sumti mi. It can be used to introduce oneself, to close letters, or to identify oneself on the telephone. |
This cmavo is often combined with other members of COI: fe'omi'e would be an appropriate closing at the end of a letter; re'imi'e would be a self-vocative used in delayed responses, as when called to the phone, or possibly in a roll-call. As long as the mi'e comes last, the following name is that of the speaker; if another COI cmavo is last, the following name is that of the listener. It is not possible to name both speaker and listener in a single vocative expression, but this fact is of no importance, because wherever one vocative expression is grammatical, any number of consecutive ones may appear.
The negative form denies an identity which someone else has attributed to you; mi'enai .djan. means that you are saying you are not John.
Many of the vocatives have been listed with translations which are drawn from radio use: “roger” , “wilco” , “over and out”. This form of translation does not mean that Lojban is a language of CB enthusiasts, but rather that in most natural languages these forms are so well handled by the context that only in specific domains (like speaking on the radio) do they need special words. In Lojban, dependence on the context can be dangerous, as speaker and listener may not share the right context, and so the vocatives provide a formal protocol for use when it is appropriate. Other appropriate contexts include computer communications and parliamentary procedure: in the latter context, the protocol question ta'apei would mean “Will the speaker yield?”
The following dialogue in Lojban illustrates the uses of attitudinals and protocol vocatives in conversation. The phrases enclosed in sei ... se'u indicate the speaker of each sentence.
| la | .rik. | .e | la | .alis. | nerkla | le | kafybarja |
| That-name | Rick | and | that-named | Alice | in-go | to-the | coffee-bar. |
|
Rick and Alice go into the coffee bar. |
| .i | sei | la | .rik. | cusku | se'u |
| [Comment] | that-named | Rick | says, | [end-comment] |
| ta'a | ro | zvati | be | ti |
| [Interrupt] | all | at | this-place, |
| mi | ba | za | speni | ti | .iu |
| I | [future] | [medium] | am-spouse-to | this-one | [love]. |
|
Rick said, “Sorry to break in, everybody. Pretty soon I'm getting married to my love here.” |
| .i | sei | la | .djordj. | cusku | se'u |
| [Comment] | that-named | George | says, | [end-comment] |
| .a'o | ko | gleki | doi | ma |
| [Hope] | [You-imperative] | are-happy, | O | [who?] |
|
George said, “I hope you'll be happy, um, ...?” |
| .i | sei | la | .pam. | cusku | se'u | pe'u | .alis. |
| [Comment] | that-named | Pam | says, | [end-comment] | [Please] | Alice, |
| xu | mi | ba | terfriti | le | nunspenybi'o |
| [Is-it-true?] | I | [future] | receive-offer-of | the | event-of-spouse-becoming? |
|
Pam said, “Please, Alice, am I going to be invited to the wedding?” |
| .i | sei | la | .mark. | cusku | se'u |
| [Comment] | that-named | Mark | says, | [end-comment] |
| coi | ba | za | speni |
| [Greetings] | [future] | [medium] | spouse(s), |
| a'o | le | re | do | lifri | le | ka | gleki |
| [Hope] | the | two | of-you | experience | the | property-of | being-happy. |
|
Mark said, “Hello, spouses-to-be. I hope both of you will be very happy.” |
| .i | sei | la | .rik. | cusku | se'u |
| [Comment] | that-named | Rick | says, | [end-comment] |
| mi'e | .rik. | doi | terpreti |
| [I-am] | Rick, | O | questioners. |
|
Rick said, “My name is Rick, for those of you who want to know.” |
| .i | sei | la | .alis. | cusku | se'u |
| [Comment] | that-named | Alice | says, | [end-comment] |
| nu'e | .pam. | .o'e | ro'i | do | ba | zvati |
| [Promise-to] | Pam, | [closeness] | [emotional] | you | [future] | are-at. |
|
Alice said, “I promise you'll be there, Pam honey.” |
| .i | sei | la | .fred. | cusku | se'u |
| [Comment] | that-named | Fred | says, | [end-comment] |
| .ui | nai | cai | ro'i | mi | ji'a |
| [Happy] | [not] | [maximal] | [emotional] | I | [additionally] |
| prami | la | .alis. | fe'o | .rik. |
| love | that-named | Alice. | [Over-and-out-to] | Rick. |
|
“I love Alice too,” said Fred miserably. “Have a nice life, Rick.” |
| .i | la | .fred. | cliva |
| that-named | Fred | leaves. |
|
And he left. |
| .i | sei | la | .rik. | cusku | se'u |
| [Comment] | that-named | Rick | says, | [end-comment] |
| fi'i | ro | zvati |
| [Welcome-to] | all | at-place, |
| ko | pinxe | pa | ckafi | fi'o | pleji | mi |
| [You-imperative] | drink | one | coffee | with | payer | me. |
|
Rick said, raising his voice, “A cup of coffee for the house, on me.” |
| .i | sei | la | .pam. | cusku | se'u |
| [Comment] | that-named | Pam | says, | [end-comment] |
| be'e | selfu |
| [Request-to-speak-to] | server. |
|
Pam said, “Waiter!” |
| .i | sei | le | selfu | cu | cusku | se'u | re'i |
| [Comment] | the | server | says, | [end-comment] | [Ready-to-receive]. |
|
The waiter replied, “May I help you?” |
| .i | sei | la | .pam. | cusku | se'u |
| [Comment] | that-named | Pam | says, | [end-comment] |
| .e'o | ko | selfu | le | traji | xamgu | ckafi |
| [Petition] | [You-imperative] | serve | the | (superlatively | good) | coffee |
| le | ba | za | speni | fi'o | pleji | mi |
| to-the | [future] | [medium] | spouse | with | payer | me. |
|
Pam said, “One Jamaica Blue for the lovebirds here, on my tab.” |
| .i | sei | le | selfu | cu | cusku | se'u | vi'o |
| [Comment] | the | server | says, | [end-comment] | [Will-comply] |
|
“Gotcha” , said the waiter. |
| .i | sei | la | .rik. | cusku | se'u | ki'e | .pam. |
| [Comment] | that-named | Rick | says, | [end-comment] | [Thanks] | Pam. |
|
“Thanks, Pam” , said Rick. |
| .i | sei | la | .pam. | cusku | se'u | je'e |
| [Comment] | that-named | Pam | says, | [end-comment] | [Acknowledge]. |
|
“Sure” , said Pam. |
| .i | sei | la | .djan. | cusku | se'u |
| [Comment] | that-named | John | says, | [end-comment] |
| .y. | mi | .y. | mutce | spopa | .y. | le | nu | le | speni |
| [Uh] | I | [uh] | very | [nonexistent-gismu] | [uh] | the | event-of | the | spouse |
| si | .y. | ba | speni | .y. | .y. | su | .yyyyyy. | mu'o |
| [erase] | [uh] | [future] | spouse | [uh] | [uh] | [erase-all] | [uh] | [over] |
|
John said, “I, er, a lotta, uh, marriage, upcoming marriage, .... Oh, forget it. Er, later.” |
| .i | sei | la | .djordj. | cusku | se'u |
| [Comment] | that-named | George | says, | [end-comment] |
| ke'o | .djan. | zo'o |
| [Repeat-O] | John | [humor]. |
|
“How's that again, John?” said George. |
| .i | sei | la | .pam. | cusku | se'u |
| [Comment] | that-named | Pam | says, | [end-comment] |
| ju'i | .djordj. | .e'unai | le | kabri | ba | zi | farlu |
| [Attention] | George, | [Warning] | the | cup | [future] | [short] | falls. |
|
“George, watch out!” said Pam. “The cup's falling!” |
| .i | le | kabri | cu | je'a | farlu |
| The | cup | indeed | falls. |
|
The cup fell. |
| .i | sei | la | .djan. | cusku | se'u |
| [Comment] | that-named | John | says, | [end-comment] |
| e'o | doi | .djordj. | zo'o | rapygau |
| [Petition] | o | George | [humor] | repeat-cause. |
|
John said, “Try that again, George!” |
| .i | sei | la | .djordj. | cusku | se'u |
| [Comment] | that-named | George | says, | [end-comment] |
| co'o | ro | zvati | pe | secau | la | .djan. | ga'i |
| [Partings] | all | at-place | which-are | without | that-named | John | [superiority] |
|
“Goodbye to all of you,” said George sneeringly, “except John.” |
| .i | la | .djordj. | cliva |
| that-named | George | leaves. |
|
George left. |
The exact ramifications of the indicator system in actual usage are unknown. There has never been anything like it in natural language before. The system provides great potential for emotional expression and transcription, from which significant Sapir-Whorf effects can be anticipated. When communicating across cultural boundaries, where different indicators are often used for the same emotion, accidental offense can be avoided. If we ever ran into an alien race, a culturally neutral language of emotion could be vital. (A classic example, taken from the science fiction of Larry Niven, is to imagine speaking Lojban to the carnivorous warriors called Kzinti, noting that a human smile bares the teeth, and could be seen as an intent to attack.) And for communicating emotions to computers, when we cannot identify all of the signals involved in subliminal human communication (things like body language are also cultural), a system like this is needed.
We have tried to err on the side of overkill. There are distinctions possible in this system that no one may care to make in any culture. But it was deemed more neutral to overspecify and let usage decide, than to choose a limited set and constrain emotional expression. For circumstances in which even the current indicator set is not enough, it is possible using the cmavo sei , explained in Section 19.12 , to create metalinguistic comments that act like indicators.
We envision an evolutionary development. At this point, the system is little more than a mental toy. Many of you who read this will try playing around with various combinations of indicators, trying to figure out what emotions they express and when the expressions might be useful. You may even find an expression for which there currently is no good English word and start using it. Why not, if it helps you express your feelings?
There will be a couple dozen of these used pretty much universally – mostly just simple attitudinals with, at most, intensity markers. These are the ones that will quickly be expressed at the subconscious level. But every Lojbanist who plays with the list will bring in a couple of new words. Poets will paint emotional pictures, and people who identify with those pictures will use the words so created for their own experiences.
Just as a library of tanru is built up, so will a library of attitudes be built. Unlike the tanru, though, the emotional expressions are built on some fairly nebulous root emotions – words that cannot be defined with the precision of the gismu. The emotion words of Lojban will very quickly take on a life of their own, and the outline given here will evolve into a true system of emotions.
There are several theories as to the nature of emotion, and they change from year to year as we learn more about ourselves. Whether or not Lojban's additive/scalar emotional model is an accurate model for human emotions, it does support the linguistic needs for expressing those emotions. Researchers may learn more about the nature of human emotions by exploring the use of the system by Lojban speakers. They also may be able to use the Lojban system as a means for more clearly recording emotions.
The full list of scales and attitudes will probably not be used until someone speaks the language from birth. Until then, people will use the attitudes that are important to them. In this way, we counter cultural bias – if a culture is prone to recognizing and/or expressing certain emotions more than others, its members will use only those out of the enormous set available. If a culture hides certain emotions, its members simply won't express them.
Perhaps native Lojban speakers will be more expressively clear about their emotions than others. Perhaps they will feel some emotions more strongly than others in ways that can be correlated with the word choices; any difference from the norms of other cultures could be significant. Psychologists have devised elaborate tests for measuring attitudes and personality; this may be the easiest area in which to detect any systematic cultural effect of the type sought to confirm Sapir-Whorf, simply because we already have tools in existence to test it. Because Lojban is unique among languages in having such extensive and expressive indicators, it is likely that a Sapir-Whorf effect will occur and will be recognized.
It is unlikely that we will know the true potential of a system like this one until and unless we have children raised entirely in a multi-cultural Lojban-speaking environment. We learn too many cultural habits in the realm of emotional communication “at our mother's knee”. Such children will have a Lojban system that has stronger reinforcement than any typical culture system. The second generation of such children, then, could be said to be the start of a true Lojbanic culture.
We shouldn't need to wait that long to detect significant effects. Emotion is so basic to our lives that even a small change or improvement in emotional communication would have immediately noticeable effects. Perhaps it will be the case that the most important contribution of our “logical language” will be in the non-logical realm of emotion!
Lojban is a logical language: the name of the language itself means “logical language”. The fundamentals of ordinary logic (there are variant logics, which aren't addressed in this book) include the notions of a “sentence” (sometimes called a “statement” or “proposition”), which asserts a truth or falsehood, and a small set of “truth functions” , which combine two sentences to create a new sentence. The truth functions have the special characteristic that the truth value (that is, the truth or falsehood) of the results depends only on the truth value of the component sentences. For example,
is true if “John is a man” is true, or if “James is a woman” is true. If we know whether John is a man, and we know whether James is a woman, we know whether “John is a man or James is a woman” is true, provided we know the meaning of “or”. Here “John is a man” and “James is a woman” are the component sentences.
We will use the phrase “negating a sentence” to mean changing its truth value. An English sentence may always be negated by prefixing “It is false that ...” , or more idiomatically by inserting “not” at the right point, generally before the verb. “James is not a woman” is the negation of “James is a woman” , and vice versa. Recent slang can also negate a sentence by following it with the exclamation “Not!”
Words like “or” are called “logical connectives” , and Lojban has many of them, as befits a logical language. This chapter is mostly concerned with explaining the forms and uses of the Lojban logical connectives. There are a number of other logical connectives in English such as “and” , “and/or” , “if” , “only if” , “whether or not” , and others; however, not every use of these English words corresponds to a logical connective. This point will be made clear in particular cases as needed. The other English meanings are supported by different Lojban connective constructs.
The Lojban connectives form a system (as the title of this chapter suggests), regular and predictable, whereas natural-language connectives are rather less systematic and therefore less predictable.
There exist 16 possible different truth functions. A truth table is a graphical device for specifying a truth function, making it clear what the value of the truth function is for every possible value of the component sentences. Here is a truth table for “or” :
| first | second | result |
| True | True | True |
| True | False | True |
| False | True | True |
| False | False | False |
This table means that if the first sentence stated is true, and the second sentence stated is true, then the result of the truth function is also true. The same is true for every other possible combination of truth values except the one where both the first and the second sentences are false, in which case the truth value of the result is also false.
Suppose that “John is a man” is true (and “John is not a man” is false), and that “James is a woman” is false (and “James is not a woman” is true). Then the truth table tells us that
| “John is a man, or James is not a woman” (true true ) is true |
| “John is a man, or James is a woman” (true , false) is true |
| “John is not a man, or James is not a woman” (false, true ) is true |
| “John is not a man, or James is a woman” (false, false) is false |
Note that the kind of “or” used in this example can also be expressed (in formal English) with “and/or”. There is a different truth table for the kind of “or” that means “either ... or ... but not both”.
To save space, we will write truth tables in a shorter format henceforth. Let the letters T and F stand for True and False. The rows will always be given in the order shown above: TT, TF, FT, FF for the two sentences. Then it is only necessary to give the four letters from the result column, which can be written TTTF, as can be seen by reading down the third column of the table above. So TTTF is the abbreviated truth table for the “or” truth function. Here are the 16 possible truth functions, with an English version of what it means to assert that each function is, in fact, true ( “first” refers to the first sentence, and “second” to the second sentence):
| TTTT | (always true) |
| TTTF | first is true and/or second is true. |
| TTFT | first is true if second is true. |
| TTFF | first is true whether or not second is true. |
| TFTT | first is true only if second is true. |
| TFTF | whether or not first is true, second is true. |
| TFFT | first is true if and only if second is true. |
| TFFF | first is true and second is true |
| FTTT | first and second are not both true. |
| FTTF | first or second is true, but not both. |
| FTFT | whether or not first is true, second is false. |
| FTFF | first is true, but second is false. |
| FFTT | first is false whether or not second is true. |
| FFTF | first is false, but second is true. |
| FFFT | neither first nor second is true. |
| FFFF | (always false) |
Skeptics may work out the detailed truth tables for themselves.
Lojban regards four of these 16 truth functions as fundamental, and assigns them the four vowels A , E , O , and U. These letters do not represent actual cmavo or selma'o, but rather a component vowel from which actual logical-connective cmavo are built up, as explained in the next section. Here are the four vowels, their truth tables, and rough English equivalents:
| A | TTTF | or, and/or |
| E | TFFF | and |
| O | TFFT | if and only if |
| U | TTFF | whether or not |
More precisely:
| A is true if either or both sentences are true |
| E is true if both sentences are true, but not otherwise |
| O is true if the sentences are both true or both false |
| U is true if the first sentence is true, regardless of the truth value of the second sentence |
With the four vowels, the ability to negate either sentence, and the ability to exchange the sentences, as if their order had been reversed, we can create all of the 16 possible truth functions except TTTT and FFFF, which are fairly useless anyway. The following table illustrates how to create each of the 14 remaining truth functions:
| TTTF | A |
| TTFT | A with second sentence negated |
| TTFF | U |
| TFTT | A with first sentence negated |
| TFTF | U with sentences exchanged |
| TFFT | O |
| TFFF | E |
| FTTT | A with both sentences negated |
| FTTF | O with either first or second negated (not both) |
| FTFT | U with sentences exchanged and then second negated |
| FTFF | E with second sentence negated |
| FFTT | U with first sentence negated |
| FFTF | E with first sentence negated |
| FFFT | E with both sentences negated |
Note that exchanging the sentences is only necessary with U. The three other basic truth functions are commutative; that is, they mean the same thing regardless of the order of the component sentences. There are other ways of getting some of these truth tables; these just happen to be the methods usually employed.
In order to remain unambiguous, Lojban cannot have only a single logical connective for each truth function. There are many places in the grammar of the language where logical connection is permitted, and each must have its appropriate set of connectives. If the connective suitable for sumti were used to connect selbri, ambiguity would result.
Consider the English sentence:
where the last word could be followed by “the door” , a noun phrase, or by “saw the horses” , a sentence with subject omitted, or by “John went to the door” , a full sentence, or by one of a variety of other English grammatical constructions. Lojban cannot tolerate such grammatical looseness.
Instead, there are a total of five different selma'o used for logical connection: A, GA, GIhA, GUhA, and JA. Each of these includes four cmavo, one based on each of the four vowels, which is always the last vowel in the cmavo. In selma'o A, the vowel is the entire cmavo.
Thus, in selma'o A, the cmavo for the function A is .a. (Do not confuse A, which is a selma'o, with A , which is a truth function, or .a, which is a cmavo.) Likewise, the cmavo for E in selma'o GIhA is gi'e , and the cmavo for U in selma'o GA is gu. This systematic regularity makes the cmavo easier to learn.
Obviously, four cmavo are not enough to express the 14 truth functions explained in Section 14.1. Therefore, compound cmavo must be used. These compound cmavo follow a systematic pattern: each has one cmavo from the five logical connection selma'o at its heart, and may also contain one or more of the auxiliary cmavo se , na , or nai. Which auxiliaries are used with which logical connection cmavo, and with what grammar and meaning, will be explained in the following sections. The uses of each of these auxiliary cmavo relates to its other uses in other parts of Lojban grammar.
For convenience, each of the types of compound cmavo used for logical connection is designated by a Lojban name. The name is derived by changing the final “-A” of the selma'o name to “-ek” ; the reasons for using “-ek” are buried deep in the history of the Loglan Project. Thus, compound cmavo based on selma'o A are known as eks, and those based on selma'o JA are known as jeks. (When writing in English, it is conventional to use “eks” as the plural of “ek”.) When the term “logical connective” is used in this chapter, it refers to one or more of these kinds of compound cmavo.
Why does the title of this section refer to “six types” when there are only five selma'o? A jek may be preceded by .i , the usual Lojban cmavo for connecting two sentences. The compound produced by .i followed by a jek is known as an ijek. It is useful to think of ijeks as a sixth kind of logical connective, parallel to eks, jeks, geks, giheks, and guheks.
There also exist giks, joiks, ijoiks, and joigiks, which are not logical connectives, but are other kinds of compound cmavo which will be introduced later.
Now we are ready to express Example 14.1 in Lojban! The kind of logical connective which is placed between two Lojban bridi to connect them logically is an ijek:
Here we have two separate Lojban bridi, la .djan. nanmu and la .djeimyz. ninmu. These bridi are connected by .i ja , the ijek for the truth function A. The .i portion of the ijek tells us that we are dealing with separate sentences here. Similarly, we can now say:
| la | .djan. | nanmu | .ijo | la | .djeimyz. | ninmu |
| That-named | John | is-a-man | if-and-only-if | that-named | James | is-a-woman. |
| la | .djan. | nanmu | .iju | la | .djeimyz. | ninmu |
| That-named | John | is-a-man | whether-or-not | that-named | James | is-a-woman. |
To obtain the other truth tables listed in Section 14.2 , we need to know how to negate the two bridi which represent the component sentences. We could negate them directly by inserting na before the selbri, but Lojban also allows us to place the negation within the connective itself.
To negate the first or left-hand bridi, prefix na to the JA cmavo but after the .i. To negate the second or right-hand bridi, suffix -nai to the JA cmavo. In either case, the negating word is placed on the side of the connective that is closest to the bridi being negated.
So to express the truth table FTTF, which requires O with either of the two bridi negated (not both), we can say either:
| la | .djan. | nanmu | .inajo | la | .djeimyz. | ninmu |
| That-named | John | is-not-a-man | if-and-only-if | that-named | James | is-a-woman. |
| la | .djan. | nanmu | .ijonai | la | .djeimyz. | ninmu |
| That-named | John | is-a-man | if-and-only-if | that-named | James | is-not-a-woman. |
The meaning of both Example 14.7 and Example 14.8 is the same as that of:
Here is another example:
| la | .djan. | nanmu | .ijanai | la | .djeimyz. | ninmu |
| That-named | John | is-a-man | or | that-named | James | is-not-a-woman. |
|
John is a man if James is a woman. |
How's that again? Are those two English sentences in Example 14.10 really equivalent? In English, no. The Lojban TTFT truth function can be glossed “A if B” , but the “if” does not quite have its English sense. Example 14.10 is true so long as John is a man, even if James is not a woman; likewise, it is true just because James is not a woman, regardless of John's gender. This kind of “if-then” is technically known as a “material conditional”.
Since James is not a woman (by our assertions in Section 14.1), the English sentence “John is a man if James is a woman” seems to be neither true nor false, since it assumes something which is not true. It turns out to be most convenient to treat this “if” as TTFT, which on investigation means that Example 14.10 is true. Example 14.11 , however, is equally true:
| la | .djan. | ninmu | .ijanai | la | .djeimyz. | ninmu |
| That-named | John | is-a-woman | if | that-named | James | is-a-woman. |
This can be thought of as a principle of consistency, and may be paraphrased as follows: “If a false statement is true, any statement follows from it.” All uses of English “if” must be considered very carefully when translating into Lojban to see if they really fit this Lojban mold.
Example 14.12 , which uses the TFTT truth function, is subject to the same rules: the stated gloss of TFTT as “only if” works naturally only when the right-hand bridi is false; if it is true, the left-hand bridi may be either true or false. The last gloss of Example 14.12 illustrates the use of “if ... then” as a more natural substitute for “only if”.
| la | .djan. | nanmu | .inaja | la | .djeimyz. | ninmu |
| That-named | John | is-not-a-man | or | that-named | James | is-a-woman. |
|
John is a man only if James is a woman. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
If John is a man, then James is a woman. |
The following example illustrates the use of se to, in effect, exchange the two sentences. The normal use of se is to (in effect) transpose places of a bridi, as explained in Section 5.11.
If both na and se are present, which is legal but never necessary, na would come before se.
The full syntax of ijeks, therefore, is:
.i [na] [se] JA [nai]
where the cmavo in brackets are optional.
Many concepts in Lojban are expressible in two different ways, generally referred to as “afterthought” and “forethought”. Section 14.4 discussed what is called “afterthought bridi logical connection”. The word “afterthought” is used because the connective cmavo and the second bridi were added, as it were, afterwards and without changing the form of the first bridi. This form might be used by someone who makes a statement and then wishes to add or qualify that statement after it has been completed. Thus,
is a complete bridi, and adding an afterthought connection to make
provides additional information without requiring any change in the form of what has come before; changes which may not be possible or practical, especially in speaking. (The meaning, however, may be changed by the use of a negating connective.) Afterthought connectives make it possible to construct all the important truth-functional relationships in a variety of ways.
In forethought style the speaker decides in advance, before expressing the first bridi, that a logical connection will be expressed. Forethought and afterthought connectives are expressed with separate selma'o. The forethought logical connectives corresponding to afterthought ijeks are geks:
ga is the cmavo which represents the A truth function in selma'o GA. The word gi does not belong to GA at all, but constitutes its own selma'o: it serves only to separate the two bridi without having any content of its own. The English translation of ga … gi is “either ... or” , but in the English form the truth function is specified both by the word “either” and by the word “or” : not so in Lojban.
Even though two bridi are being connected, geks and giks do not have any .i in them. The forethought construct binds up the two bridi into a single sentence as far as the grammar is concerned.
Some more examples of forethought bridi connection are:
| gu | la | .djan. | nanmu | gi | la | .djeimyz. | ninmu |
|
It is true that John is a man, whether or not James is a woman. |
It is worth emphasizing that Example 14.18 does not assert that James is (or is not) a woman. The gu which indicates that la .djeimyz. ninmu may be true or false is unfortunately rather remote from the bridi thus affected.
Perhaps the most important of the truth functions commonly expressed in forethought is TFTT, which can be paraphrased as “if ... then ...” :
| ganai | la | .djan. | nanmu | gi | la | .djeimyz. | ninmu |
| Either | that-named | John | is-not-a-man, | or | that-named | James | is-a-woman. |
|
If John is a man, then James is a woman. |
Note the placement of the nai in Example 14.19. When added to afterthought selma'o such as JA, a following nai negates the second bridi, to which it is adjacent. Since GA cmavo precede the first bridi, a following nai negates the first bridi instead.
Why does English insist on forethought in the translation of Example 14.19 ? Possibly because it would be confusing to seemingly assert a sentence and then make it conditional (which, as the Lojban form shows, involves a negation). Truth functions which involve negating the first sentence may be confusing, even to the Lojbanic understanding, when expressed using afterthought.
It must be reiterated here that not every use of English “if ... then” is properly translated by .i na ja or ganai … gi ; anything with implications of time needs a somewhat different Lojban translation, which will be discussed in Section 14.18. Causal sentences like “If you feed the pig, then it will grow” are not logical connectives of any type, but rather need a translation using rinka as the selbri joining two event abstractions, thus:
| le | nu | do | cidja | dunda | fi | le | xarju |
| The | event-of | (you | food | give | to | the | pig) |
| cu | rinka | le | nu | ri | ba | banro |
| causes | the | event-of | (it | will | grow). |
Causality is discussed in far more detail in Section 9.7.
Example 14.21 and Example 14.22 illustrates a truth function, FTTF, which needs to negate either the first or the second bridi. We already understand how to negate the first bridi:
| gonai | la | .djan. | nanmu | gi | la | .djeimyz. | ninmu |
|
John is not a man if and only if James is a woman. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Either John is a man or James is a woman but not both. |
How can the second bridi be negated? By adding -nai to the gi.
| go | la | .djan. | nanmu | ginai | la | .djeimyz. | ninmu |
|
John is a man if and only if James is not a woman. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Either John is a man or James is a woman but not both. |
A compound cmavo based on gi is called a gik; the only giks are gi itself and gi nai.
Further examples:
[se] GA [nai]
and of giks (which are not themselves connectives, but part of the machinery of forethought connection) is:
gi [nai]
Geks and ijeks are sufficient to state every possible logical connection between two bridi. However, it is often the case that two bridi to be logically connected have one or more portions in common:
| la | .djan. | klama | le | zarci | .ije | la | .alis. | klama | le | zarci |
|
John goes to the market, and Alice goes to the market. |
Here only a single sumti differs between the two bridi. Lojban does not require that both bridi be expressed in full. Instead, a single bridi can be given which contains both of the different sumti and uses a logical connective from a different selma'o to combine the two sumti:
Example 14.26 means exactly the same thing as Example 14.25 : one may be rigorously transformed into the other without any change of logical meaning. This rule is true in general for every different kind of logical connection in Lojban; all of them, with one exception (see Section 14.12), can always be transformed into a logical connection between sentences that expresses the same truth function.
The afterthought logical connectives between sumti are eks, which contain a connective cmavo of selma'o A. If ijeks were used in Example 14.26 , the meaning would be changed:
| la | .djan. | .ije | |
| That-named | John | [is/does-something]. | And |
| la | .alis. | klama | le | zarci |
| that-named | Alice | goes-to | the | market. |
leaving the reader uncertain why John is mentioned at all.
Any ek may be used between sumti, even if there is no direct English equivalent:
| la | .djan. | .o | la | .alis. | klama | le | zarci |
| That-named | John | if-and-only-if | that-named | Alice | goes-to | the | market. |
|
John goes to the market if, and only if, Alice does. |
The second line of Example 14.27 is highly stilted English, but the first line (of which it is a literal translation) is excellent Lojban.
What about forethought sumti connection? As is the case for bridi connection, geks are appropriate. They are not the only selma'o of forethought logical-connectives, but are the most commonly used ones.
Of course, eks include all the same patterns of compound cmavo that ijeks do. When na or se is part of an ek, a special writing convention is invoked, as in the following example:
| la | .djan. | na.a | la | .alis. | klama | le | zarci |
| That-named | John | only-if | that-named | Alice | goes-to | the | market. |
|
John goes to the market only if Alice does. |
Note the period in na .a. The cmavo of A begin with vowels, and therefore must always be preceded by a pause. It is conventional to write all connective compounds as single words (with no spaces), but this pause must still be marked in writing as in speech; otherwise, the na and .a would tend to run together.
So far we have seen logical connectives used to connect exactly two sentences. How about connecting three or more? Is this possible in Lojban? The answer is yes, subject to some warnings and some restrictions.
Of the four primitive truth functions A , E , O , and U , all but O have the same truth values no matter how their component sentences are associated in pairs. Therefore,
means that all three component sentences are true. Likewise,
means that one or more of the component sentences is true.
O , however, is different. Working out the truth table for
| mi | dotco | .ijo | mi | ricfu | .ijo | mi | nanmu |
| I | am-German. | If-and-only-if | I | am-rich. | If-and-only-if | I | am-a-man. |
shows that Example 14.33 does not mean that either I am all three of these things or none of them; instead, an accurate translation would be:
Of the three properties – German-ness, wealth, and manhood – I possess either exactly one or else all three.
Because of the counterintuitiveness of this outcome, it is safest to avoid O with more than two sentences. Likewise, the connectives which involve negation also have unexpected truth values when used with more than two sentences.
In fact, no combination of logical connectives can produce the “all or none” interpretation intended (but not achieved) by Example 14.33 without repeating one of the bridi. See Example 14.48.
There is an additional difficulty with the use of more than two sentences. What is the meaning of:
| mi | nelci | la | .djan. | .ije | mi | nelci | la | .martas. |
| I | like | that-named | John. | And | I | like | that-named | Martha. |
| .ija | mi | nelci | la | .meris. |
| Or | I | like | that-named | Mary. |
Does this mean:
Or is the correct translation:
Example 14.36 is the correct translation of Example 14.34. The reason is that Lojban logical connectives pair off from the left, like many constructs in the language. This rule, called the left-grouping rule, is easy to forget, especially when intuition pulls the other way. Forethought connectives are not subject to this problem:
| ga | ge | mi | nelci | la | .djan. |
| Either | (Both | I | like | that-named | John |
| gi | mi | nelci | la | .martas. |
| and | I | like | that-named | Martha) |
| gi | mi | nelci | la | .meris. |
| or | I | like | that-named | Mary. |
is equivalent in meaning to Example 14.34 , whereas
| ge | mi | nelci | la | .djan. |
| Both | I | like | that-named | John |
| gi | ga | mi | nelci | la | .martas. |
| and | (Either | I | like | that-named | Martha |
| gi | mi | nelci | la | .meris. |
| or | I | like | that-named | Mary). |
is not equivalent to Example 14.34 , but is instead a valid translation into Lojban, using forethought, of Example 14.35.
There are several ways in Lojban to render Example 14.35 using afterthought only. The simplest method is to make use of the cmavo bo (of selma'o BO). This cmavo has several functions in Lojban, but is always associated with high precedence and short scope. In particular, if bo is placed after an ijek, the result is a grammatically distinct kind of ijek which overrides the regular left-grouping rule. Connections marked with bo are interpreted before connections not so marked. Example 14.39 is equivalent in meaning to Example 14.38 :
| mi | nelci | la | .djan. | .ije | mi | nelci | la | .martas. |
| I | like | that-named | John, | and | I | like | that-named | Martha |
| .ijabo | mi | nelci | la | .meris. |
| or | I | like | that-named | Mary. |
The English translation feebly indicates with a comma what the Lojban marks far more clearly: the “I like Martha” and “I like Mary” sentences are joined by .i ja first, before the result is joined to “I like John” by .i je.
Eks can have bo attached in exactly the same way, so that Example 14.40 is equivalent in meaning to Example 14.39 :
Forethought connectives, however, never can be suffixed with bo , for every use of forethought connectives clearly indicates the intended pattern of grouping.
What happens if bo is used on both connectives, giving them the same high precedence, as in Example 14.41 ?
Does this wind up meaning the same as Example 14.34 and Example 14.36 ? Not at all. A second rule relating to bo is that where two or more bo -marked connectives are used in succession, the normal Lojban left-grouping rule is replaced by a right-grouping rule. As a result, Example 14.41 in fact means the same as Example 14.39 and Example 14.40. This rule may be occasionally exploited for special effects, but is tricky to keep straight; in writing intended to be easy to understand, multiple consecutive connectives marked with bo should be avoided.
The use of bo , therefore, gets tricky in complex connections of more than three sentences. Looking back at the English translations of Example 14.37 and Example 14.38 , parentheses were used to clarify the grouping. These parentheses have their Lojban equivalents, two sets of them actually. tu'e and tu'u are used with ijeks, and ke and ke'e with eks and other connectives to be discussed later. ( ke and ke'e are also used in other roles in the language, but always as grouping markers). Consider the English sentence:
where the semantics tells us that the instances of “and” are meant to have higher precedence than that of “if”. If we wish to express Example 14.42 in afterthought, we can say:
| mi | cinba | do | .ije[bo] | do | cinba | mi |
| I | kiss | you | and | you | kiss | me, |
| .ijanai | mi | prami | do | .ijebo | do | prami | mi |
| if | I | love | you | and | you | love | me. |
marking two of the ijeks with bo for high precedence. (The first bo is not strictly necessary, because of the left-grouping rule, and is shown here in brackets.)
But it may be clearer to use explicit parenthesis words and say:
| tu'e | mi | cinba | do | .ije | do | cinba | mi | tu'u |
| ( | I | kiss | you | and | you | kiss | me | ) |
| .ijanai | tu'e | mi | prami | do | .ije | do | prami | mi | [tu'u] |
| if | ( | I | love | you | and | you | love | me | ). |
where the tu'e … tu'u pairs set off the structure. The cmavo tu'u is an elidable terminator, and its second occurrence in Example 14.44 is bracketed, because all terminators may be elided at the end of a text.
In addition, parentheses are a general solution: multiple parentheses may be nested inside one another, and additional afterthought material may be added without upsetting the existing structure. Neither of these two advantages apply to bo grouping. In general, afterthought constructions trade generality for simplicity.
Because of the left-grouping rule, the first set of tu'e … tu'u parentheses may actually be left off altogether, producing:
| mi | cinba | do | .ije | do | cinba | mi |
| I | kiss | you | and | you | kiss | me |
| .ijanai | tu'e | mi | prami | do | .ije | do | prami | mi | [tu'u] |
| if | ( | I | love | you | and | you | love | me | ). |
What about parenthesized sumti connection? Consider
Two pairs of parentheses, analogous to Example 14.44 , would seem to be the right approach. However, it is a rule of Lojban grammar that a sumti may not begin with ke , so the first set of parentheses must be omitted, producing Example 14.47 , which is instead parallel to Example 14.45 :
| mi | dzukla | le | zarci | .e | le | zdani |
| I | walk-to | the | market | and | the | house |
| .a | ke | le | ckule | .e | le | briju | [ke'e] |
| or | ( | the | school | and | the | office | ). |
If sumti were allowed to begin with ke , unavoidable ambiguities would result, so ke grouping of sumti is allowed only just after a logical connective. This rule does not apply to tu'e grouping of bridi, as Example 14.44 shows.
Now we have enough facilities to handle the problem of Example 14.33 : “I am German, rich, and a man – or else none of these.” The following paraphrase has the correct meaning:
| [tu'e] | mi | dotco | .ijo | mi | ricfu | [tu'u] |
| ( | I | am-German | if-and-only-if | I | am-rich | ) |
| .ije | tu'e | mi | dotco | .ijo | mi | nanmu | [tu'u] |
| and | ( | I | am-German | if-and-only-if | I | am-a-man | ). |
The truth table, when worked out, produces T if and only if all three component sentences are true or all three are false.
So far we have seen how to handle two sentences that need have no similarity at all (bridi connection) and sentences that are identical except for a difference in one sumti (sumti connection). It would seem natural to ask how to logically connect sentences that are identical except for having different selbri.
Surprise! Lojban provides no logical connective that is designed to handle selbri and nothing else. Instead, selbri connection is provided as part of a more general-purpose mechanism called “compound bridi”. Compound bridi result from logically connecting sentences that differ in their selbri and possibly some of their sumti.
The simplest cases result when the x1 sumti is the only common point:
is equivalent in meaning to the compound bridi:
As Example 14.50 indicates, giheks are used in afterthought to create compound bridi; gi'e is the gihek corresponding to “and”. The actual phrases klama le zarci and nelci la .djan. that the gihek connects are known as “bridi-tails” , because they represent (in this use) the “tail end” of a bridi, including the selbri and any following sumti, but excluding any sumti that precede the selbri:
In Example 14.51 , the first bridi-tail is ricfu , a simple selbri, and the second bridi-tail is klama le zarci , a selbri with one following sumti.
Suppose that more than a single sumti is identical between the two sentences:
| mi | dunda | le | cukta | do | .ije | mi | lebna | lo | jdini | do |
| I | give | the | book | to-you, | and | I | take | some | money | from-you. |
In Example 14.52 , the first and last sumti of each bridi are identical; the selbri and the second sumti are different. By moving the final sumti to the beginning, a form analogous to Example 14.50 can be achieved:
where the fi does not have an exact English translation because it merely places do in the third place of both lebna and dunda. However, a form that preserves natural sumti order also exists in Lojban. Giheks connect two bridi-tails, but also allow sumti to be added following the bridi-tail. These sumti are known as tail-terms, and apply to both bridi. The straightforward gihek version of Example 14.52 therefore is:
The vau (of selma'o VAU) serves to separate the bridi-tail from the tail-terms. Every bridi-tail is terminated by an elidable vau , but only in connection with compound bridi is it ever necessary to express this vau. Thus:
has a single elided vau , and Example 14.50 is equivalent to:
where the double vau at the end of Example 14.56 terminates both the right-hand bridi-tail and the unexpressed tail-terms.
A final use of giheks is to combine bridi-tails used as complete sentences, the Lojban observative:
Since x1 is omitted in both of the bridi underlying Example 14.57 , this compound bridi does not necessarily imply that the goer and the walker are the same. Only the presence of an explicit x1 (other than zo'e , which is equivalent to omission) can force the goer and the walker to be identical.
A strong argument for this convention is provided by analysis of the following example:
| klama | la | .nu,IORK. |
| A-goer | to-that-named | New-York |
| la | .finyks. |
| from-that-named | Phoenix |
| gi'e | klama | la | .nu,IORK. |
| and | a-goer | to-that-named | New-York |
| la | .rom. |
| from-that-named | Rome. |
If the rule were that the x1 places of the two underlying bridi were considered identical, then (since there is nothing special about x1), the unspecified x4 (route) and x5 (means) places would also have to be the same, leading to the absurd result that the route from Phoenix to New York is the same as the route from Rome to New York. Inserting da , meaning roughly “something” , into the x1 place cures the problem:
| da | klama | la | .nu,IORK. | la | .finyks. |
| Something | is-a-goer | to-that-named | New-York | from-that-named | Phoenix |
| gi'e | klama | la | .nu,IORK. | la | .rom. |
| and | is-a-goer | to-that-named | New-York | from-that-named | Rome. |
[na] [se] GIhA [nai]
which is exactly parallel to the syntax of eks.
Giheks can be combined with bo in the same way as eks:
| mi | nelci | la | .djan. | gi'e | nelci | la | .martas. | gi'abo | nelci | la | .meris. |
|
I like John and ( like Martha or like Mary ). |
is equivalent in meaning to Example 14.39 and Example 14.40. Likewise, ke … ke'e grouping can be used after giheks:
| mi | dzukla | le | zarci |
| I | walk-to | the | market |
| gi'e | dzukla | le | zdani |
| and | walk-to | the | house, |
| gi'a | ke | dzukla | le | ckule |
| or | ( | walk-to | the | school |
| gi'e | dzukla | le | briju | [ke'e] |
| and | walk-to | the | office. | ) |
is the gihek version of Example 14.47. The same rule about using ke … ke'e bracketing only just after a connective applies to bridi-tails as to sumti, so the first two bridi-tails in Example 14.61 cannot be explicitly grouped; implicit left-grouping suffices to associate them.
Each of the pairs of bridi-tails joined by multiple giheks can have its own set of tail-terms:
| mi | dejni | lo | rupnu | la | .djan. | |
| [If] | I | owe | some | currency-units | to-that-named | John, |
| .inaja | mi | dunda | le | cukta | la | .djan. |
| then | I | give | the | book | to-that-named | John |
| .ijabo | mi | lebna | le | cukta | la | .djan. |
| or | I | take | the | book | from-that-named | John. |
is equivalent in meaning to:
| mi | dejni | lo | rupnu | nagi'a | dunda | |
| [If] | I | owe | some | currency-units | then | (give |
| gi'abo | lebna | vau | le | cukta | vau | la | .djan. |
| or | take) | a | book | to/from-that-named | John. |
The literal English translation in Example 14.63 is almost unintelligible, but the Lojban is perfectly grammatical. mi fills the x1 place of all three selbri; lo rupnu is the x2 of dejni , whereas le cukta is a tail-term shared between dunda and lebna ; la .djan. is a tail-term shared by dejni and by dunda gi'abo lebna. In this case, greater clarity is probably achieved by moving la .djan. to the beginning of the sentence, as in Example 14.53 :
| fi | la | .djan. | fa | mi | dejni | lo | rupnu | |
| To/from | that-named | John, | [if] | I | owe | some | currency-units |
| nagi'a | dunda | gi'abo | lebna | vau | le | cukta | |
| then | [I] | give | or | take | the | book. |
Finally, what about forethought logical connection of bridi-tails? There is no direct mechanism for the purpose. Instead, Lojban grammar allows a pair of forethought-connected sentences to function as a single bridi-tail, and of course the sentences need not have terms before their selbri. For example:
is equivalent in meaning to Example 14.50.
Of course, either of the connected sentences may contain giheks:
| mi | ge | klama | le | zarci | gi'e | dzukla | le | zdani |
| I | both | (go | to-the | market | and | walk | to-the | house) |
| gi | nelci | la | .djan. |
| and | like | that-named | John. |
The entire gek-connected sentence pair may be negated as a whole by prefixing na :
Since a pair of sentences joined by geks is the equivalent of a bridi-tail, it may be followed by tail terms. The forethought equivalent of Example 14.54 is:
| mi | ge | dunda | le | cukta |
| I | both | (give | the | book) |
| gi | lebna | lo | jdini | vau | do |
| and | (take | some | money | ) | to/from-you. |
Here is a pair of gek-connected observatives, a forethought equivalent of Example 14.57 :
Finally, here is an example of gek-connected sentences with both shared and unshared terms before their selbri:
| mi | gonai | le | zarci | cu | klama | gi | le | bisli | cu | dansu |
| I | either-but-not-both | to-the | office | go | or | on-the | ice | dance. |
|
I either go to the office or dance on the ice (but not both). |
So far we have seen sentences that differ in all components, and require bridi connection; sentences that differ in one sumti only, and permit sumti connection; and sentences that differ in the selbri and possibly one or more sumti, and permit bridi-tail connection. Termset logical connectives are employed for sentences that differ in more than one sumti but not in the selbri, such as:
The Lojban version of Example 14.71 requires two termsets joined by a logical connective. A “term” is either a sumti or a sumti preceded by a tense or modal tag such as pu or bai. Afterthought termsets are formed by linking terms together by inserting the cmavo ce'e (of selma'o CEhE) between each of them. Furthermore, the logical connective (which is a jek) must be prefixed by the cmavo pe'e (of selma'o PEhE). (We could refer to the combination of pe'e and a jek as a “pehejek” , I suppose.)
| mi | klama | le | zarci | ce'e | le | briju |
| I | go | to-the | market | [plus] | from-the | office |
| pe'e | je | le | zdani | ce'e | le | ckule |
| [joint] | and | to-the | house | [plus] | from-the | school. |
The literal translation uses “[plus]” to indicate the termset connective, and “[joint]” to indicate the position of the logical connective joint. As usual, there is an equivalent bridi-connection form:
| mi | klama | le | zarci | le | briju |
| I | go | to-the | market | from-the | office, |
| .ije | mi | klama | le | zdani | le | ckule |
| and | I | go | to-the | house | from-the | school. |
which illustrates that the two bridi differ in the x2 and x3 places only.
What happens if the two joined sets of terms are of unequal length? Expanding to bridi connection will always make clear which term goes in which place of which bridi. It can happen that a sumti may fall in the x2 place of one bridi and the x3 place of another:
| mi | pe'e | ja | do | ce'e | le | zarci | cu | klama | le | briju |
| I | [joint] | or | you | [plus] | to-the | market | go | to/from-the | office. |
can be clearly understood by expansion to:
| mi | klama | le | briju | .ija | do | le | zarci | cu | klama |
| I | go | to-the | office, | or | you | to-the | market | go |
| le | briju |
| from-the | office. |
So le briju is your origin but my destination, and thus falls in the x2 and x3 places of klama simultaneously! This is legal because even though there is only one selbri, klama , there are two distinct bridi expressed here. In addition, mi in Example 14.74 is serving as a termset containing only one term. An analogous paradox applies to compound bridi with tail-terms and unequal numbers of sumti within the connected bridi-tails:
means that I go to the market from the office, and I walk to the office; le briju is the x3 place of klama and the x2 place of dzukla.
Forethought termsets also exist, and use nu'i of selma'o NUhI to signal the beginning and nu'u of selma'o NUhU (an elidable terminator) to signal the end. Nothing is inserted between the individual terms: they simply sit side-by-side. To make a logical connection in a forethought termset, use a gek, with the gek just after the nu'i , and an extra nu'u just before the gik:
| mi | klama | nu'i | ge | le | zarci | le | briju |
| I | go | [start-termset] | both | to-the | market | from-the | office |
| nu'u | gi | le | zdani | le | ckule | [nu'u] |
| [joint] | and | to-the | house | from-the | school | [end-termset]. |
Note that even though two termsets are being connected, only one nu'i is used.
The grammatical uses of termsets that do not contain logical connectives are explained in Section 9.8 , Section 10.25 , and Section 16.7.
As noted at the beginning of Section 14.9 , there is no logical connective in Lojban that joins selbri and nothing but selbri. However, it is possible to have logical connectives within a selbri, forming a kind of tanru that involves a logical connection. Consider the simple tanru blanu zdani , blue house. Now anything that is a blue ball, in the most ordinary understanding of the phrase at least, is both blue and a ball. And indeed, instead of blanu bolci , Lojbanists can say blanu je bolci , using a jek connective within the tanru. (We saw jeks used in Section 14.11 also, but there they were always prefixed by pe'e ; in this section they are used alone.) Here is a pair of examples:
But of course Example 14.78 and Example 14.79 are not necessarily equivalent in meaning! It is the most elementary point about Lojban tanru that Example 14.78 might just as well mean
and Example 14.79 certainly is not equivalent in meaning to Example 14.80.
A full explanation of logical connection within tanru belongs rather to a discussion of selbri structure than to logical connectives in general. Why? Because although Example 14.79 happens to mean the same as
and therefore as
the rule of expansion into separate bridi simply does not always work for tanru connection. Supposing Alice to be a person who lives in blue houses, then
would be true, because tanru grouping with a jek has higher precedence than unmarked tanru grouping, but:
| la | .alis. | cu | blanu | prenu | |
| That-named | Alice | is-a | blue | person, |
| .ije | la | .alis. | cu | zdani | prenu | |
| and | that-named | Alice | is-a | house | person. |
is probably false, because the blueness is associated with the house, not with Alice, even leaving aside the question of what it means to say “Alice is a blue person”. (Perhaps she belongs to the Blue team, or is wearing blue clothes.) The semantic ambiguity of tanru make such logical manipulations impossible.
It suffices to note here, then, a few purely grammatical points about tanru logical connection. bo may be appended to jeks as to eks, with the same rules:
The components of tanru may be grouped with ke both before and after a logical connective:
| la | .teris. | cu | [ke] | ricfu | ja | pindi | [ke'e] |
| That-named | Terry | ( | is-rich | or | is-poor | ) |
| je | ke | nakni | ja | fetsi | [ke'e] |
| and | ( | male | or | female | ). |
where the first ke … ke'e pair may be omitted altogether by the rule of left-grouping, but is optionally permitted. In any case, the last instance of ke'e may be elided.
[na] [se] JA [nai]
parallel to eks and giheks.
Forethought tanru connection does not use geks, but uses guheks instead. Guheks have exactly the same form as geks:
[se] GUhA [nai]
Using guheks in tanru connection (rather than geks) resolves what would otherwise be an unacceptable ambiguity between bridi-tail and tanru connection:
Note that giks are used with guheks in exactly the same way they are used with geks. Like jeks, guheks bind more closely than unmarked tanru grouping does:
is the forethought version of Example 14.83.
A word of caution about the use of logically connected tanru within descriptions. English-based intuition can lead the speaker astray. In correctly reducing
to
there is a great temptation to reduce further to:
But Example 14.91 means that you see one thing which is both a cat and a dog simultaneously! A mlatu je gerku is a catdog, a presumably non-existent creature who is both a mlatu and a gerku.
So far we have addressed only sentences which are statements. Lojban, like all human languages, needs also to deal with sentences which are questions. There are many ways of asking questions in Lojban, but some of these (like questions about quantity, tense, and emotion) are discussed in other chapters.
The simplest kind of question is of the type “Is it true that ...” where some statement follows. This type is called a “truth question” , and can be represented in English by Example 14.92 :
Note the two formulations. English truth questions can always be formed by prefixing “Is it true that” to the beginning of a statement; there is also usually a more idiomatic way involving putting the verb before its subject. “Is Fido a dog?” is the truth question corresponding to “Fido is a dog”. In Lojban, the equivalent mechanism is to prefix the cmavo xu (of selma'o UI) to the statement:
Example 14.92 and Example 14.93 are equivalent in meaning.
A truth question can be answered “yes” or “no” , depending on the truth or falsity, respectively, of the underlying statement. The standard way of saying “yes” in Lojban is go'i and of saying “no” is na go'i. (The reasons for this rule are explained in Section 7.6.) In answer to Example 14.93 , the possible answers are:
and
Some English questions seemingly have the same form as the truth questions so far discussed. Consider
Superficially, Example 14.96 seems like a truth question with the underlying statement:
By translating Example 14.97 into Lojban and prefixing xu to signal a truth question, we get:
| xu | la | .faidon. | gerku | gi'onai | mlatu | |
| Is-it-true-that | that-named | Fido | is-a-dog | or | is-a-cat | (but not both)? |
Given that Fido really is either a dog or a cat, the appropriate answer would be go'i ; if Fido were a fish, the appropriate answer would be na go'i.
But that is not what an English-speaker who utters Example 14.96 is asking! The true significance of Example 14.96 is that the speaker desires to know the truth value of either of the two underlying bridi (it is presupposed that only one is true).
Lojban has an elegant mechanism for rendering this kind of question which is very unlike that used in English. Instead of asking about the truth value of the connected bridi, Lojban users ask about the truth function which connects them. This is done by using a special question cmavo: there is one of these for each of the logical connective selma'o, as shown by the following table:
|
ge'i |
GA |
forethought connective question |
|
gi'i |
GIhA |
bridi-tail connective question |
|
gu'i |
GUhA |
tanru forethought connective question |
|
je'i |
JA |
tanru connective question |
|
ji |
A |
sumti connective question |
(This list unfortunately departs from the pretty regularity of the other cmavo for logical connection. The two-syllable selma'o, GIhA and GUhA, make use of the cmavo ending in “-i” which is not used for a truth function, but gi and .i were not available, and different cmavo had to be chosen. This table must simply be memorized, like most other non-connective cmavo assignments.)
One correct translation of Example 14.96 employs a question gihek:
Here are some plausible answers:
Example 14.103 is correct but uncooperative.
As usual, Lojban questions are answered by filling in the blank left by the question. Here the blank is a logical connective, and therefore it is grammatical in Lojban to utter a bare logical connective without anything for it to connect.
The answer gi'e , meaning that Fido is a dog and is a cat, is impossible in the real world, but for:
| do | djica | tu'a | loi | ckafi |
| You | desire | something-about | a-mass-of | coffee |
| ji | loi | tcati |
| [truth-function?] | a-mass-of | tea? |
|
Do you want coffee or tea? |
the answer .e , meaning that I want both, is perfectly plausible, if not necessarily polite.
The forethought questions ge'i and gu'i are used like the others, but ambiguity forbids the use of isolated forethought connectives as answers – they sound like the start of forethought-connected bridi. So although Example 14.105 is the forethought version of Example 14.104 :
| do | djica | tu'a | ge'i | loi | ckafi |
| You | desire | something-about | [truth-function?] | a-mass-of | coffee |
| gi | loi | tcati |
| [or] | a-mass-of | tea? |
the answer must be in afterthought form.
There are natural languages, notably Chinese, which employ the Lojbanic form of connective question. The Chinese sentence
means “Do you walk or run?” , and is exactly parallel to the Lojban:
However, Chinese does not use logical connectives in the reply to such a question, so the resemblance, though striking, is superficial.
Truth questions may be used in bridi connection. This form of sentence is perfectly legitimate, and can be interpreted by using the convention that a truth question is true if the answer is “yes” and false if the answer is no. Analogously, an imperative sentence (involving the special pro-sumti ko , which means “you” but marks the sentence as a command) is true if the command is obeyed, and false otherwise. A request of Abraham Lincoln's may be translated thus:
| ganai | ti | ckafi | gi | ko | bevri | loi | tcati | mi |
| If | this | is-coffee | then | [you!] | bring | a-mass-of | tea | to-me, |
| .ije | ganai | ti | tcati | gi | ko | bevri | loi | ckafi | mi |
| and | if | this | is-tea | then | [you!] | bring | a-mass-of | coffee | to-me. |
|
If this is coffee, bring me tea; but if this is tea, bring me coffee. |
In logical terms, however, “but” is the same as “and” ; the difference is that the sentence after a “but” is felt to be in tension or opposition to the sentence before it. Lojban represents this distinction by adding the discursive cmavo ku'i (of selma'o UI), which is explained in Section 13.12 , to the logical .i je.)
Way back in Section 14.1 , the point was made that not every use of English “and” , “if ... then” , and so on represents a Lojban logical connective. In particular, consider the “and” of:
Given the nature of pianos, this probably means that John carried one end and Alice the other. So it is not true that:
which would mean that each of them carried the piano by himself/herself. Lojban deals with this particular linguistic phenomenon as a “mass”. John and Alice are joined together into a mass, John-and-Alice, and it is this mass which carried the piano, not either of them separately. The cmavo joi (of selma'o JOI) is used to join two or more components into a mass:
| la | .djan. | joi | la | .alis. | cu | bevri | le | pipno |
| That-named | John | massed-with | that-named | Alice | carry | the | piano. |
Example 14.111 covers the case mentioned, where John and Alice divide the labor; it also could mean that John did all the hauling and Alice did the supervising. This possibility arises because the properties of a mass are the properties of its components, which can lead to apparent contradictions: if John is small and Alice is large, then John-and-Alice is both small and large. Masses are also discussed in Section 6.3.
Grammatically, joi can appear between two sumti (like an ek) or between two tanru components (like a jek). This flexibility must be paid for in the form of occasional terminators that cannot be elided:
The cmavo ku is the elidable terminator for le , which can almost always be elided, but not in this case. If the first ku were elided here, Lojban's parsing rules would see le nanmu joi and assume that another tanru component is to follow; since the second le cannot be part of a tanru, a parsing error results. No such problem can occur with logical connectives, because an ek signals a following sumti and a jek a following tanru component unambiguously.
Single or compound cmavo involving members of selma'o JOI are called joiks, by analogy with the names for logical connectives. It is not grammatical to use joiks to connect bridi-tails.
In tanru, joi has the connotation “mixed with” , as in the following example:
Here the ball is neither wholly blue nor wholly red, but partly blue and partly red. Its blue/redness is a mass property. (Just how blue something has to be to count as “wholly blue” is an unsettled question, though. A blanu zdani may be so even though not every part of it is blue.)
There are several other cmavo in selma'o JOI which can be used in the same grammatical constructions. Not all of them are well-defined as yet in all contexts. All have clear definitions as sumti connectives; those definitions are shown in the following table:
| A joi B | the mass with components A and B |
| A ce B | the set with elements A and B |
| A ce'o B | the sequence with elements A and B in order |
| A se ce'o B | the sequence with elements B and A in order |
| A jo'u B | A and B considered jointly |
| A fa'u B | A and B respectively |
| A se fa'u B | B and A respectively |
| A jo'e B | the union of sets A and B |
| A ku'a B | the intersection of sets A and B |
| A pi'u B | the cross product of sets A and B |
| A se pi'u B | the cross product of sets B and A |
The cmavo se is grammatical before any JOI cmavo, but only useful with those that have inherent order. Here are some examples of joiks:
| mi | cuxna | la | .alis. | la | .frank. |
| I | choose | that-named | Alice | from-that-named | Frank |
| ce | la | .alis. | ce | la | .djeimyz. |
| and-member | that-named | Alice | and-member | that-named | James. |
|
I choose Alice from among Frank, Alice, and James. |
The x3 place of cuxna is a set from which the choice is being made. A set is an abstract object which is determined by specifying its members. Unlike those of a mass, the properties of a set are unrelated to its members' properties: the set of all rats is large (since many rats exist), but the rats themselves are small. This chapter does not attempt to explain set theory (the mathematical study of sets) in detail: explaining propositional logic is quite enough for one chapter!
In Example 14.114 we specify that set by listing the members with ce joining them.
| ti | liste | do | ce'o | mi | ce'o | la | .djan. |
| This | is-a-list-of | you | and-sequence | me | and-sequence | that-named | John. |
|
This is a list of you, me, and John. |
The x2 place of liste is a sequence of the things which are mentioned in the list. (It is worth pointing out that lo liste means a physical object such as a grocery list: a purely abstract list is lo porsi , a sequence.) Here the three sumti connected by ce'o are in a definite order, not just lumped together in a set or a mass.
So joi , ce , and ce'o are parallel, in that the sumti connected are taken to be individuals, and the result is something else: a mass, a set, or a sequence respectively. The cmavo jo'u serves as a fourth element in this pattern: the sumti connected are individuals, and the result is still individuals – but inseparably so. The normal Lojban way of saying that James and George are brothers is:
possibly adding a discursive element meaning “and vice versa”. However, “James and George are brothers” cannot be correctly translated as:
since that expands to two bridi and means that James is a brother and so is George, but not necessarily of each other. If the .e is changed to jo'u , however, the meaning of Example 14.116 is preserved:
| la | .djeimyz. | jo'u |
| That-named | James | in-common-with |
| la | .djordj. | cu | remei | bruna |
| that-named | George | are-a-twosome | type-of-brothers. |
The tanru remei bruna is not strictly necessary in this sentence, but is used to make clear that we are not saying that James and George are both brothers of some third person not specified. Alternatively, we could turn the tanru around: the x1 place of re mei is a mass with two components, leading to:
| la | .djeimyz. | joi |
| That-named | James | massed-with |
| la | .djordj. | cu | bruna | remei |
| that-named | George | are-a-brother | type-of-twosome. |
where joi is used to create the necessary mass.
Likewise, fa'u can be used to put two individuals together where order matters. Typically, there will be another fa'u somewhere else in the same bridi:
| la | .djeimyz. | fa'u | la | .djordj. |
| That-named | James | jointly-in-order-with | that-named | George |
| prami | la | .meris. | fa'u | la | .martas. |
| loves | that-named | Mary | jointly-in-order-with | that-named | Martha. |
|
James and George love Mary and Martha, respectively. |
Here the information carried by the English adverb “respectively” , namely that James loves Mary and George loves Martha, is divided between the two occurrences of fa'u. If both uses of fa'u were to be changed to .e , we would get:
| la | .djeimyz. | .e | la | .djordj. | prami |
| That-named | James | and | that-named | George | love |
| la | .meris. | .e | la | .martas. |
| that-named | Mary | and | that-named | Martha. |
which can be transformed to four bridi:
| la | .djeimyz. | prami | la | .meris. | .ije | la | .djordj. | prami |
| That-named | James | loves | that-named | Mary, | and | that-named | George | loves |
| la | .meris. | .ije | la | .djeimyz. | prami | la | .martas. |
| that-named | Mary, | and | that-named | James | loves | that-named | Martha, |
| .ije | la | .djordj. | prami | la | .martas. |
| and | that-named | George | loves | that-named | Martha. |
which represents quite a different state of affairs from Example 14.120. The meaning of Example 14.120 can also be conveyed by a termset:
| la | .djeimyz. | ce'e | la | .meris. | pe'e |
| That-named | James | [plus] | that-named | Mary | [joint] |
| je | la | .djordj. | ce'e | la | .martas. | prami |
| and | that-named | George | [plus] | that-named | Martha | loves. |
at the expense of re-ordering the list of names so as to make the pairs explicit. This option is not available when one of the lists is only described rather than enumerated:
| la | .djeimyz. | fa'u | la | .djordj. | prami | re | mensi |
| That-named | James | and-respectively | that-named | George | love | two | sisters. |
which conveys that James loves one sister and George the other, though we are not able to tell which of the sisters is which.
The final three JOI cmavo, jo'e , ku'a , and pi'u , are probably only useful when talking explicitly about sets. They represent three standard set operators usually called “union” , “intersection” , and “cross product” (also known as “Cartesian product”). The union of two sets is a set containing all the members that are in either set; the intersection of two sets is a set containing all the members that are in both sets. The cross product of two sets is the set of all possible ordered pairs, where each ordered pair contains a single element from the first set followed by a single element from the second. This may seem very abstract; hopefully, the following examples will help:
| lo'i | ricfu | ku | jo'e | lo'i | dotco | cu | barda |
| The-set-of | rich-things | union | the-set-of | German-things | is-large. |
| lo'i | ricfu | ku | ku'a | lo'i | dotco | cu | cmalu |
| The-set-of | rich-things | intersection | the-set-of | German-things | is-small. |
There is a parallelism between logic and set theory that makes Example 14.125 and Example 14.126 equivalent respectively to:
and
The following example uses se remei , which is a set (not a mass) of two elements:
| la | .djeimyz. | ce[bo] | la | .djordj. | pi'u |
| That-named | James | and-set | that-named | George | cross-product |
| la | .meris. | cebo | la | .martas. | cu | prami | se | remei |
| that-named | Mary | and-set | that-named | Martha | are-lover | type-of-pairs. |
means that each of the pairs James/Mary, George/Mary, James/Martha, and George/Martha love each other. Therefore it is similar in meaning to Example 14.121 ; however, that example speaks only of the men loving the women, not vice versa.
Joiks may be combined with bo or with ke in the same way as eks and jeks; this allows grouping of non-logical connections between sumti and tanru units, in complete parallelism with logical connections:
| mi | joibo | do | ce | la | .djan. | joibo | la | .djein. |
| (I | massed-with | you) | and | (that-named | John | massed-with | that-named | Jane) |
| cu | gunma | se | remei |
| are-a-mass | type-of-two-set |
asserts that there is a set of two items each of which is a mass.
Non-logical connection is permitted at the joint of a termset; this is useful for associating more than one sumti or tagged sumti with each side of the non-logical connection. The place structure of casnu is:
casnu the mass x1 discusses/talks about x2
so the x1 place must be occupied by a mass (for reasons not explained here); however, different components of the mass may discuss in different languages. To associate each participant with his or her language, we can say:
| mi | ce'e | bau | la | .lojban. | pe'e | joi |
| (I | [plus] | in-language | that-named | Lojban | [joint] | massed-with |
| do | ce'e | bau | la | .gliban. | casnu |
| you | [plus] | in-language | that-named | English | discuss. |
Like all non-logical connectives, the usage shown in Example 14.131 cannot be mechanically converted into a non-logical connective placed at another location in the bridi. The forethought equivalent of Example 14.131 is:
Non-logical forethought termsets are also useful when the things to be non-logically connected are sumti preceded with tense or modal (BAI) tags:
| la | .djan. | fa'u | la | .frank. | cusku |
| That-named | John | respectively-with | that-named | Frank | express |
| nu'i | fa'ugi | bau | la | .lojban. |
| [start-termset] | [respectively-with] | in-language | that-named | Lojban |
| nu'u | gi | bai |
| [joint] | and | under-compulsion-by |
| tu'a | la | .djordj. | [nu'u] |
| something-about | that-named | George. |
|
John and Frank speak in Lojban and under George's compulsion, respectively. |
Example 14.133 associates speaking in Lojban with John, and speaking under George's compulsion with Frank. We do not know what language Frank uses, or whether John speaks under anyone's compulsion.
Joiks may be prefixed with .i to produce ijoiks, which serve to non-logically connect sentences. The ijoik .i ce'o indicates that the event of the second bridi follows that of the first bridi in some way other than a time relationship (which is handled with a tense):
| mi | ba | gasnu | la'e | di'e | .i |
| I | [future] | do | the-referent-of | the-following: |
| tu'e | kanji | lo | ni | cteki | .ice'o | lumci | le | karce |
| ( | Compute | the | quantity-of | taxes. | And-then | wash | the | car. |
| .ice'o | dzukansa | le | gerku | tu'u |
| And-then | walkingly-accompany | the | dog. | ) |
|
List of things to do: Figure taxes. Wash car. Walk dog. |
Example 14.134 represents a list of things to be done in priority order. The order is important, hence the need for a sequence connective, but does not necessarily represent a time order (the dog may end up getting walked first). Note the use of tu'e and tu'u as general brackets around the whole list. This is related to, but distinct from, their use in Section 14.8 , because there is no logical connective between the introductory phrase mi ba gasnu la'edi'e and the rest. The brackets effectively show how large an utterance the word di'e , which means “the following utterance” , refers to.
Similarly, .i joi is used to connect sentences that represent the components of a joint event such as a joint cause: the Lojban equivalent of “Fran hit her head and fell out of the boat, so that she drowned” would join the events “Fran hit her head” and “Fran fell out of the boat” with .i joi.
The following nai , if present, does not negate either of the things to be connected, but instead specifies that some other connection (logical or non-logical) is applicable: it is a scalar negation:
The result of mi jo'u do would be two individuals, not a mass, therefore jo'u is not applicable; joi would be the correct connective.
There is no joik question cmavo as such; however, joiks and ijoiks may be uttered in isolation in response to a logical connective question, as in the following exchange:
| do | djica | tu'a | loi | ckafi |
| You | desire | something-about | a-mass-of | coffee |
| ji | loi | tcati |
| [what-connective?] | a-mass-of | tea? |
|
Do you want coffee or tea? |
In addition to the non-logical connectives of selma'o JOI explained in Section 14.14 and Section 14.15 , there are three other connectives which can appear in joiks: bi'i , bi'o , and mi'i , all of selma'o BIhI. The first two cmavo are used to specify intervals: abstract objects defined by two endpoints. The cmavo bi'i is correct if the endpoints are independent of order, whereas bi'o or se bi'o are used when order matters.
An example of bi'i in sumti connection:
| mi | ca | sanli |
| I | [present] | stand-on-surface |
| la | .drezdn. | bi'i | la | .frankfurt. |
| that-named | Dresden | [interval] | that-named | Frankfurt. |
|
I am standing between Dresden and Frankfurt. |
In Example 14.138 , it is all the same whether I am standing between Dresden and Frankfurt or between Frankfurt and Dresden, so bi'i is the appropriate interval connective. The sumti la .drezdn. bi'i la .frankfurt. falls into the x2 place of sanli , which is the surface I stand on; the interval specifies that surface by its limits. (Obviously, I am not standing on the whole of the interval; the x2 place of sanli specifies a surface which is typically larger in extent than just the size of the stander's feet.)
| mi | cadzu | ca | la | .pacac. |
| I | walk | simultaneous-with | First-hour |
| bi'o | la | .recac. |
| [ordered-interval] | Second-hour. |
|
I walk from one o'clock to two o'clock. |
In Example 14.139 , on the other hand, it is essential that la .pacac. comes before la .recac. ; otherwise we have an 11-hour (or 23-hour) interval rather than a one-hour interval. In this use of an interval, the whole interval is probably intended, or at least most of it.
Example 14.139 is equivalent to:
| mi | cadzu | ca | la | .recac. |
| I | walk | simultaneous-with | Second-hour |
| se | bi'o | la | .pacac. |
| [reverse] | [ordered] | First-hour. |
English cannot readily express se bi'o , but its meaning can be understood by reversing the two sumti.
The third cmavo of selma'o BIhI, namely mi'i , expresses an interval seen from a different viewpoint: not a pair of endpoints, but a center point and a distance. For example:
| le | jbama | pu | daspo | la | .uacintyn. |
| The | bomb | [past] | destroys | Washington |
| mi'i | lo | minli | be | li | muno |
| [center] | what-is | measured-in-miles | by | 50. |
|
The bomb destroyed Washington and fifty miles around. |
Here we have an interval whose center is Washington and whose distance, or radius, is fifty miles.
In Example 14.138 , is it possible that I am standing in Dresden (or Frankfurt) itself? Yes. The connectives of selma'o BIhI are ambiguous about whether the endpoints themselves are included in or excluded from the interval. Two auxiliary cmavo ga'o and ke'i (of cmavo GAhO) are used to indicate the status of the endpoints: ga'o means that the endpoint is included, ke'i that it is excluded:
| mi | ca | sanli | la | .drezdn. | ga'o |
| I | [present] | stand | that-named | Dresden | [inclusive] |
| bi'i | ga'o | la | .frankfurt. |
| [interval] | [inclusive] | that-named | Frankfurt. |
|
I am standing between Dresden and Frankfurt, inclusive of both. |
| mi | ca | sanli | la | .drezdn. | ga'o |
| I | [present] | stand | that-named | Dresden | [inclusive] |
| bi'i | ke'i | la | .frankfurt. |
| [interval] | [exclusive] | that-named | Frankfurt. |
|
I am standing between Dresden (inclusive) and Frankfurt (exclusive). |
| mi | ca | sanli | la | .drezdn. | ke'i |
| I | [present] | stand | that-named | Dresden | [exclusive] |
| bi'i | ga'o | la | .frankfurt. |
| [interval] | [inclusive] | that-named | Frankfurt. |
|
I am standing between Dresden (exclusive) and Frankfurt (inclusive). |
| mi | ca | sanli | la | .drezdn. | ke'i |
| I | [present] | stand | that-named | Dresden | [exclusive] |
| bi'i | ke'i | la | .frankfurt. |
| [interval] | [exclusive] | that-named | Frankfurt. |
|
I am standing between Dresden and Frankfurt, exclusive of both. |
As these examples should make clear, the GAhO cmavo that applies to a given endpoint is the one that stands physically adjacent to it: the left-hand endpoint is referred to by the first GAhO, and the right-hand endpoint by the second GAhO. It is ungrammatical to have just one GAhO.
(Etymologically, ga'o is derived from ganlo , which means “closed” , and ke'i from kalri , which means “open”. In mathematics, inclusive intervals are referred to as closed intervals, and exclusive intervals as open ones.)
BIhI joiks are grammatical anywhere that other joiks are, including in tanru connection and (as ijoiks) between sentences. No meanings have been found for these uses.
Negated intervals, marked with a -nai following the BIhI cmavo, indicate an interval that includes everything but what is between the endpoints (with respect to some understood scale):
| do | dicra | .e'a | mi | ca | la | .daucac. |
| You | disturb | (allowed) | me | at | that-named | 10 |
| bi'onai | la | .gaicac. |
| not-from-...-to | that-named | 12 |
|
You can contact me except from 10 to 12. |
The complete syntax of joiks is:
[se] JOI [nai]
[se] BIhI [nai]
GAhO [se] BIhI [nai] GAhO
Notice that the colloquial English translations of bi'i and bi'o have forethought form: “between ... and” for bi'i , and “from ... to” for bi'o. In Lojban too, non-logical connectives can be expressed in forethought. Rather than using a separate selma'o, the forethought logical connectives are constructed from the afterthought ones by suffixing gi. Such a compound cmavo is not unnaturally called a “joigik” ; the syntax of joigiks is any of:
[se] JOI [nai] GI
[se] BIhI [nai] GI
GAhO [se] BIhI [nai] GAhO GI
Joigiks may be used to non-logically connect bridi, sumti, and bridi-tails; and also in termsets.
Example 14.111 in forethought becomes:
| joigi | la | .djan. | gi | la | .alis. | bevri | le | pipno |
| [Together] | that-named | John | and | that-named | Alice | carry | the | piano. |
The first gi is part of the joigik; the second gi is the regular gik that separates the two things being connected in all forethought forms.
Example 14.143 can be expressed in forethought as:
| mi | ca | sanli | ke'i | bi'i |
| I | [present] | stand | [exclusive] | between |
| ga'o | gi | la | .drezdn. | gi | la | .frankfurt. |
| [inclusive] | and | that-named | Dresden | and | that-named | Frankfurt. |
|
I am standing between Dresden (exclusive) and Frankfurt (inclusive). |
In forethought, unfortunately, the GAhOs become physically separated from the endpoints, but the same rule applies: the first GAhO refers to the first endpoint.
Lojban has a separate grammar embedded within the main grammar for representing mathematical expressions (or mekso in Lojban) such as “2 + 2”. Mathematical expressions are explained fully in Chapter 18. The basic components of mekso are operands, like “2” , and operators, like “+”. Both of these may be either logically or non-logically connected.
Operands are connected in afterthought with eks and in forethought with geks, just like sumti. Operators, on the other hand, are connected in afterthought with jeks and in forethought with guheks, just like tanru components. (However, jeks and joiks with bo are not allowed for operators.) This parallelism is no accident.
In addition, eks with bo and with ke … ke'e are allowed for grouping logically connected operands, and ke … ke'e is allowed for grouping logically connected operators, although there is no analogue of tanru among the operators.
Only a few examples of each kind of mekso connection will be given. Despite the large number of rules required to support this feature, it is of relatively minor importance in either the mekso or the logical-connective scheme of things. These examples are drawn from Section 18.17 , and contain many mekso features not explained in this chapter.
Example 14.149 exhibits afterthought logical connection between operands:
Example 14.150 is equivalent in meaning, but uses forethought connection:
Note that the mekso in Example 14.149 and Example 14.150 are being used as quantifiers. Lojban requires that any mekso other than a simple number be enclosed in vei and ve'o parentheses when used as a quantifier. The right parenthesis mark, ve'o , is an elidable terminator.
Simple examples of logical connection between operators are hard to come by. A contrived example is:
| li | re | su'i | je | pi'i | re | du | li | vo |
| The-number | 2 | plus | and | times | 2 | equals | the-number | 4. |
|
2 + 2 = 4 and 2 x 2 = 4. |
The forethought form of Example 14.151 is:
| li | re | gu'e | su'i | gi | pi'i | re | du | li | vo |
| The-number | two | both | plus | and | times | two | equals | the-number | four. |
|
Both 2 + 2 = 4 and 2 x 2 = 4. |
Non-logical connection with joiks or joigiks is also permitted between operands and between operators. One use for this construct is to connect operands with bi'i to create mathematical intervals:
| li | no | ga'o | bi'i | ke'i | pa | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| the-number | zero | (inclusive) | from-to | (exclusive) | one | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
[0,1)
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
the numbers from zero to one, including zero but not including one |
You can also combine two operands with ce'o , the sequence connective of selma'o JOI, to make a compound subscript:
Note that the boi in Example 14.154 is not elidable, because the xi subscript needs something to attach to.
The tense and modal systems of Lojban interact with the logical connective system. No one chapter can explain all of these simultaneously, so each chapter must present its own view of the area of interaction with emphasis on its own concepts and terminology. In the examples of this chapter, the many tenses of various selma'o as well as the modals of selma'o BAI are represented by the simple time cmavo pu , ca , and ba (of selma'o PU) representing the past, the present, and the future respectively. Preceding a selbri, these cmavo state the time when the bridi was, is, or will be true (analogous to English verb tenses); preceding a sumti, they state that the event of the main bridi is before, simultaneous with, or after the event given by the sumti (which is generally a le nu abstraction; see Section 11.2).
The two types of interaction between tenses and logical connectives are logically connected tenses and tensed logical connections. The former are fairly simple. Jeks may be used between tense cmavo to specify two connected bridi that differ only in tense:
| la | .artr. | pu | nolraitru |
| That-named | Arthur | [past] | is-a-noblest-governor. |
| .ije | la | .artr. | ba | nolraitru |
| And | that-named | Arthur | [future] | is-a-noblest-governor. |
|
Arthur was a king, and Arthur will be a king. |
can be reduced to:
| la | .artr. | pu | je | ba | nolraitru |
| That-named | Arthur | [past] | and | [future] | is-a-noblest-governor. |
|
Arthur was and will be king. |
Example 14.155 and Example 14.156 are equivalent in meaning; neither says anything about whether Arthur is king now.
Non-logical connection with joiks is also possible between tenses:
| mi | pu | bi'o | ba | vasxu |
| I | [past] | from-...-to | [future] | breathe. |
|
I breathe from a past time until a future time. |
The full tense system makes more interesting tense intervals expressible, such as “from a medium time ago until a long time from now”.
No forethought connections between tenses are permitted by the grammar, nor is there any way to override the default left-grouping rule; these limitations are imposed to keep the tense grammar simpler. Whatever can be said with tenses or modals can be said with subordinate bridi stating the time, place, or mode explicitly, so it is reasonable to try to remove at least some complications.
Tensed logical connections are both more complex and more important than logical connections between tenses. Consider the English sentence:
The verbatim translation of Example 14.158 , namely:
| mi | pu | klama | le | zarci | .ije | mi | pu | tervecnu | lo | cidja |
| I | [past] | go-to | the | market. | And | I | [past] | buy | items-of | food. |
fails to fully represent a feature of the English, namely that the buying came after the going. (It also fails to represent that the buying was a consequence of the going, which can be expressed by a modal that is discussed in Chapter 9.) However, the tense information – that the event of my going to the market preceded the event of my buying food – can be added to the logical connective as follows. The .i je is replaced by .i je bo , and the tense cmavo ba is inserted between .i je and bo :
| mi | pu | klama | le | zarci |
| I | [past] | go-to | the | market. |
| .ije | babo | mi | pu | tervecnu | lo | cidja |
| And | [later] | I | [past] | buy | items-of | food. |
Here the pu cmavo in the two bridi-tails express the time of both actions with respect to the speaker: in the past. The ba relates the two items to one another: the second item is later than the first item. The grammar does not permit omitting the bo ; if it were omitted, the ba and the second pu would run together to form a compound tense bapu applying to the second bridi-tail only.
Adding tense or modal information to a logical connective is permitted only in the following situations:
Between an ek (or joik) and bo , as in:
| la | .djan | .e | cabo | la | .alis. | klama | le | zarci |
| That-named | John | and | [simultaneous] | that-named | Alice | go-to | the | market. |
|
John and Alice go to the market simultaneously. |
Between an ek (or joik) and ke , as in:
| mi | dzukla | le | zarci | .e | pu |
| I | walk-to | the | market | and | [earlier] |
| ke | le | zdani | .a | le | ckule | [ke'e] |
| ( | the | house | or | the | school | ). |
|
I walk to the market and, before that, to the house or the school. |
Between a gihek and bo , as in:
| mi | dunda | le | cukta | gi'e | babo |
| I | give | the | book | and | [later] |
| lebna | lo | jdini | vau | do |
| take | some | money | from/to-you. |
|
I give you the book and then take some dollars (pounds, yen) from you. |
Between a gihek and ke , as in:
| mi | dzukla | le | zarci | gi'e | ca |
| I | walk-to | the | market | and | [simultaneous] |
| ke | cusku | zo'e | la | .djan. | [ke'e] |
| ( | express | something | to-that-named | John. | ) |
|
I walk to the market and at the same time talk to John. |
Between an ijek (or ijoik) and bo , as in:
| mi | viska | pa | nanmu | .ije | babo | mi | viska | pa | ninmu |
| I | see | a | man. | And | [later] | I | see | a | woman. |
|
I see a man, and then I see a woman. |
Between an ijek (or ijoik) and tu'e , as in:
| mi | viska | pa | nanmu | .ije | batu'e | mi | viska | pa | ninmu | [tu'u] |
| I | see | a | man. | And | [later] | I | see | a | woman. |
|
I see a man, and then I see a woman. |
And finally, between a jek (or joik) and bo , as in:
As can be seen from Example 14.165 and Example 14.166 , the choice between bo and ke (or tu'e) is arbitrary when there are only two things to be connected. If there were no tense information to include, of course neither would be required; it is only the rule that tense information must always be sandwiched between the logical connective and a following bo , ke , or tu'e that requires the use of one of these grouping cmavo in Example 14.161 and Example 14.163 through Example 14.167.
Non-logical connectives with bo and ke can include tense information in exactly the same way as logical connectives. Forethought connectives, however (except as noted below) are unable to do so, as are termsets or tense connectives. Mathematical operands and operators can also include tense information in their logical connectives as a result of their close parallelism with sumti and tanru components respectively:
| vei | ci | .ebabo | vo | [ve'o] | tadni | cu | zvati | le | kumfa |
| ( | 3 | and-[future] | 4 | ) | students | are-at | the | room. |
|
Three and, later, four students were in the room. |
is a simple example. There is a special grammatical rule for use when a tense applies to both of the selbri in a forethought bridi-tail connection: the entire forethought construction can just be preceded by a tense. For example:
| mi | pu | ge | klama | le | zarci | gi | tervecnu | lo | cidja |
| I | [past] | both | go-to | the | market | and | buy | some | food |
|
I went to the market and bought some food. |
Example 14.169 is similar to Example 14.159. There is no time relationship specified between the going and the buying; both are simply set in the past.
Last and (as a matter of fact) least: a logical connective is allowed between abstraction markers of selma'o NU. Jeks are the appropriate connective.
| le | mikce | cu | se | cinri | le | pu'u | jenai | za'i | mi | sipna |
| The | doctor | is-interested-in | the | process-of | and-not | state-of | me | sleeping. |
|
The doctor is interested in the process of me sleeping but not in the state of me sleeping. |
As with tenses and modals, there is no forethought and no way to override the left-grouping rule.
Logical connectives and abstraction are related in another way as well, though. Since an abstraction contains a bridi, the bridi may have a logical connection inside it. Is it legitimate to split the outer bridi into two, joined by the logical connection? Absolutely not. For example:
| mi | jinvi | le | du'u | loi | jmive |
| I | opine | the | fact-that | a-mass-of | living-things |
| cu | zvati | gi'onai | na | zvati | vau | la | .iupiter. |
| (is-at | or-else | is-not | at) | that-named | Jupiter. |
|
I believe there either is or isn't life on Jupiter. |
is true, since the embedded sentence is a tautology, but:
| mi | jinvi | le | du'u | loi | jmive | cu | zvati | la | .iupiter. |
| I | opine | the | fact-that | a-mass-of | living-things | is-at | that-named | Jupiter |
| .ijonai | mi | jinvi | le | du'u | loi | jmive |
| or-else | I | opine | the | fact-that | a-mass-of | living-things |
| na | zvati | la | .iupiter. |
| isn't-at | that-named | Jupiter |
is false, since I have no evidence one way or the other ( jinvi requires some sort of evidence, real or fancied, unlike krici).
The following table specifies, for each kind of construct that can be logically or non-logically connected in Lojban, what kind of connective is required for both afterthought and (when possible) forethought modes. An asterisk (*) indicates that tensed connection is permitted.
A dash indicates that connection of the specified type is not possible.
| construct | afterthought logical | forethought logical | afterthought non-logical | forethought non-logical |
| bridi | ijek* | gek | ijoik* | joigik |
| sumti | ek* | gek | joik* | joigik |
| bridi-tails | gihek* | gek | - | joigik |
| termsets | ek* | gek | joik* | joigik |
| tanru parts | jek | guhek | joik* | - |
| operands | ek* | gek | joik* | joigik |
| operators | jek | guhek | joik | - |
| tenses/modals | jek | - | joik | - |
| abstractors | jek | - | joik | - |
The following table specifies, for each truth function, the most-often used cmavo or compound cmavo which expresses it for each of the six types of logical connective. (Other compound cmavo are often possible: for example, se .a means the same as .a , and could be used instead.)
| truth | ek | jek | gihek | gek-gik | guhek-gik |
| TTTF | .a | ja | gi'a | ga - gi | gu'a - gi |
| TTFT | .a nai | ja nai | gi'a nai | ga - gi nai | gu'a - gi nai |
| TTFF | .u | ju | gi'u | gu - gi | gu'u - gi |
| TFTT | na .a | na ja | na gi'a | ganai - gi | gu'anai - gi |
| TFTF | se .u | se ju | se gi'u | segu - gi | segu'u - gi |
| TFFT | .o | jo | gi'o | go - gi | gu'o - gi |
| TFFF | .e | je | gi'e | ge - gi | gu'e - gi |
| FTTT | na .a nai | na ja nai | na gi'a nai | ganai - gi nai | gu'anai - gi nai |
| FTTF | .o nai | jo nai | gi'o nai | go - gi nai | gu'o - gi nai |
| FTFT | se .u nai | se ju nai | se gi'u nai | segu - gi nai | segu'u - gi nai |
| FTFF | .e nai | je nai | gi'e nai | ge - gi nai | gu'e - gi nai |
| FFTT | na .u | na ju | na gi'u | gunai - gi | gu'unai - gi |
| FFTF | na .e | na je | na gi'e | genai - gi | gu'enai - gi |
| FFFT | na .e nai | na je nai | na gi'e nai | genai - gi nai | gu'enai - gi nai |
Note: ijeks are exactly the same as the corresponding jeks, except for the prefixed .i.
The full set of rules for inserting na , se , and nai into any connective is:
Afterthought logical connectives (eks, jeks, giheks, ijeks):
Forethought logical connectives (geks, guheks):
Non-logical connectives (joiks, joigiks):
Section 14.1 : a table explaining the meaning of each truth function in English.
Section 14.2 : a table relating the truth functions to the four basic vowels.
Section 14.13 : a table of the connective question cmavo.
Section 14.14 : a table of the meanings of JOI cmavo when used to connect sumti.
The grammatical expression of negation is a critical part of Lojban's claim to being logical. The problem of negation, simply put, is to come up with a complete definition of the word “not”. For Lojban's unambiguous grammar, this means further that meanings of “not” with different grammatical effect must be different words, and even different grammatical structures.
Logical assertions are implicitly required in a logical language; thus, an apparatus for expressing them is built into Lojban's logical connectives and other structures.
In natural languages, especially those of Indo-European grammar, we have sentences composed of two parts which are typically called “subject” and “predicate”. In the statement
“John” is the subject, and “goes to the store” is the predicate. Negating Example 15.1 to produce
has the effect of declaring that the predicate does not hold for the subject. Example 15.2 says nothing about whether John goes somewhere else, or whether someone else besides John goes to the store.
We will call this kind of negation “natural language negation”. This kind of negation is difficult to manipulate by the tools of logic, because it doesn't always follow the rules of logic. Logical negation is bi-polar: either a statement is true, or it is false. If a statement is false, then its negation must be true. Such negation is termed contradictory negation.
Let's look at some examples of how natural language negation can violate the rules of contradictory negation.
Both of these statements are true; yet one is apparently the negation of the other. Another example:
At first thought, Example 15.5 negates Example 15.6. Thinking further, we realize that there is an intermediate state wherein I am permitted to go to the dance, but not obligated to do so. Thus, it is possible that both statements are false.
Sometimes order is significant:
Our minds play tricks on us with this one. Because Example 15.7 is written in what is called the “active voice” , we immediately get confused about whether “the falling rock” is a suitable subject for the predicate “did kill Sam”. “Kill” implies volition to us, and rocks do not have volition. This confusion is employed by opponents of gun control who use the argument “Guns don't kill people; people kill people.”
Somehow, we don't have the same problem with Example 15.8. The subject is Sam, and we determine the truth or falsity of the statement by whether he was or wasn't killed by the falling rock.
Example 15.8 also helps us focus on the fact that there are at least two questionable facts implicit in this sentence: whether Sam was killed, and if so, whether the falling rock killed him. If Sam wasn't killed, the question of what killed him is moot.
This type of problem becomes more evident when the subject of the sentence turns out not to exist:
In the natural languages, we would be inclined to say that both of these statements are false, since there is no King of Mexico.
The rest of this chapter is designed to explain the Lojban model of negation.
In discussing Lojban negation, we will call the form of logical negation that simply denies the truth of a statement “bridi negation”. Using bridi negation, we can say the equivalent of “I haven't stopped beating my wife” without implying that I ever started, nor even that I have a wife, meaning simply “It isn't true that I have stopped beating my wife.” Since Lojban uses bridi as smaller components of complex sentences, bridi negation is permitted in these components as well at the sentence level.
For the bridi negation of a sentence to be true, the sentence being negated must be false. A major use of bridi negation is in making a negative response to a yes/no question; such responses are usually contradictory, denying the truth of the entire sentence. A negative answer to
is taken as a negation of the entire sentence, equivalent to
The most important rule about bridi negation is that if a bridi is true, its negation is false, and vice versa.
The simplest way to express a bridi negation is to use the cmavo na of selma'o NA before the selbri of the affirmative form of the bridi (but after the cu , if there is one):
when negated becomes:
Note that we have used a special convention to show in the English that a bridi negation is present. We would like to use the word “not” , because this highlights the naturalness of putting the negation marker just before the selbri, and makes the form easier to learn. But there is a major difference between Lojban's bridi negation with na and natural language negation with “not”. In English, the word “not” can apply to a single word, to a phrase, to an English predicate, or to the entire sentence. In addition, “not” may indicate either contradictory negation or another form of negation, depending on the sentence. Lojban's internal bridi negation, on the other hand, always applies to an entire bridi, and is always a contradictory negation; that is, it contradicts the claim of the whole bridi.
Because of the ambiguity of English “not” , we will use “[false]” in the translation of Lojban examples to remind the reader that we are expressing a contradictory negation. Here are more examples of bridi negation:
| mi | [cu] | na | ca | klama | le | zarci |
| I | [false] | now | am-a-go-er-to | the | market. |
|
I am not going to the market now. |
| lo | ca | nolraitru | be |
| The-actual | present | noblest-governor | of |
| le | fasygu'e | cu | na | krecau |
| the | French-country | [false] | is-hair-without. |
|
The current king of France isn't bald. |
| ti | na | barda | prenu | co | melbi | mi |
| This | [false] | is-a-big | person | of-type | (beautiful-to | me). |
|
This isn't a big person who is beautiful to me. |
Although there is this fundamental difference between Lojban's internal bridi negation and English negation, we note that in many cases, especially when there are no existential or quantified variables (the cmavo da , de , and di of selma'o KOhA, explained in Chapter 16) in the bridi, you can indeed translate Lojban na as “not” (or “isn't” or “doesn't” , as appropriate).
The most important rule about bridi negation is that if a bridi is true, its negation is false, and vice versa.
In Lojban, there are several structures that implicitly contain bridi, so that Lojban sentences may contain more than one occurrence of na. For example:
| mi | na | gleki | le | nu |
| I | [false] | am-happy-about | the | event-of |
| na | klama | le | nu | dansu |
| ([false] | going-to | the | event-of | dancing). |
|
It is not the case that I am happy about it not being the case that I am going to the dance. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
I am not happy about not going to the dance. |
In the previous example, we used internal negations in abstraction bridi; bridi negation may also be found in descriptions within sumti. For example:
| mi | nelci | le | na | melbi |
| I | am-fond-of | the-one-described-as | ([false] | beautiful). |
|
I am fond of the one who isn't beautiful. |
A more extreme (and more indefinite) example is:
| mi | nelci | lo | na |
| I | am-fond-of | one-who-is | ([false] |
| ca | nolraitru | be | le | fasygu'e |
| the-current | king | of | the | French-country). |
|
I am fond of one who isn't the current king of France. |
The claim of Example 15.20 could apply to anyone except a person who is fond of no one at all, since the relation within the description is false for everyone. You cannot readily express these situations in colloquial English.
Negation with na applies to an entire bridi, and not to just part of a selbri. Therefore, you won't likely have reason to put na inside a tanru. In fact, the grammar currently does not allow you to do so (except in a lujvo and in elaborate constructs involving GUhA, the forethought connector for selbri). Any situation where you might want to do so can be expressed in a less-compressed non-tanru form. This grammatical restriction helps ensure that bridi negation is kept separate from other forms of negation.
The grammar of na allows multiple adjacent negations, which cancel out, as in normal logic:
which is the same as:
When a selbri is tagged with a tense or a modal, negation with na is permitted in two positions: before or after the tag. No semantic difference between these forms has yet been defined, but this is not finally determined, since the interactions between tenses/modals and bridi negation have not been fully explored. In particular, it remains to be seen whether sentences using less familiar tenses, such as:
mean the same thing with na before the ta'e , as when the negation occurs afterwards; we'll let future, Lojban-speaking, logicians decide on how they relate to each other.
A final caution on translating English negations into Lojban: if you translate the English literally, you'll get the wrong one. With English causal statements, and other statements with auxiliary clauses, this problem is more likely.
Thus, if you translate the English:
as:
| mi | na | klama | le | zarci | ki'u |
| I | [false] | go-to | the | market | because-of |
| lenu | le | karce | cu | spofu |
| the-event-of | the | car | is-broken. |
|
It is false that: I go to the market because the car is broken. |
you end up negating too much.
Such mistranslations result from the ambiguity of English compounded by the messiness of natural language negation. A correct translation of the normal interpretation of Example 15.24 is:
| le | nu | mi | na | klama | le | zarci | cu | se | krinu |
| The | event-of | (my | [false] | going-to | the | market) | is-justified-by |
| le | nu | le | karce | cu | spofu |
| the | event-of | (the | car | being-broken). |
|
My not going to the market is because the car is broken. |
In Example 15.26 , the negation is clearly confined to the event abstraction in the x1 sumti, and does not extend to the whole sentence. The English could also have been expressed by two separate sentences joined by a causal connective (which we'll not go into here).
The problem is not confined to obvious causals. In the English:
we do not intend the uncle's help to be part of the negation. We must thus move the negation into an event clause or use two separate sentences. The event-clause version would look like:
It is possible that someone will want to incorporate bridi negations into lujvo. For this reason, the rafsi -nar- has been reserved for na. However, before using this rafsi, make sure that you intend the contradictory bridi negation, and not the scalar negation described in Section 15.3 , which will be much more common in tanru and lujvo.
Let us now consider some other types of negation. For example, when we say:
we make a positive inference – that the chair is some other color. Thus, it is legitimate to respond:
Whether we agree that the chair is brown or not, the fact that the statement refers to color has significant effect on how we interpret some responses. If we hear the following exchange:
we immediately start to wonder about the unusual wood that isn't brown. If we hear the exchange:
we are unsettled because the response seems to be a non-sequitur. But since it might be true and it is a statement about the chair, one can't say it is entirely irrelevant!
What is going on in these statements is something called “scalar negation”. As the name suggests, scalar negation presumes an implied scale. A negation of this type not only states that one scalar value is false, but implies that another value on the scale must be true. This can easily lead to complications. The following exchange seems reasonably natural (a little suspension of disbelief in such inane conversation will help):
We have acknowledged a scalar negation by providing a correct value which is another color in the set of colors permissible for houses. While a little less likely, the following exchange is also natural:
Again, we have acknowledged a scalar negation, and substituted a different object in the universe of discourse of things that can be blue.
Now, if the following exchange occurs:
we find the result unsettling. This is because it seems that two corrections have been applied when there is only one negation. Yet out of context, “blue house” and “green car” seem to be reasonably equivalent units that should be mutually replaceable in a sentence. It's just that we don't have a clear way in English to say:
aloud so as to clearly imply that the scalar negation is affecting the pair of words as a single unit.
Another even more confusing example of scalar negation is to the sentence:
Might Example 15.37 imply that John went to Paris from somewhere else? Or did he go somewhere else from Rome? Or perhaps he didn't go anywhere at all: maybe someone else did, or maybe there was no event of going whatsoever. One can devise circumstances where any one, two or all three of these statements might be inferred by a listener.
In English, we have a clear way of distinguishing scalar negation from predicate negation that can be used in many situations. We can use the partial word “non-” as a prefix. But this is not always considered good usage, even though it would render many statements much clearer. For example, we can clearly distinguish
from the related sentence
Example 15.38 and Example 15.39 have the advantage that, while they contain a negative indication, they are in fact positive assertions. They say what is true by excluding the false; they do not say what is false.
We can't always use “non-” though, because of the peculiarities of English's grammar. It would sound strange to say:
or
although these would clarify the vague negation. Another circumlocution for English scalar negation is “other than” , which works where “non-” does not, but is wordier.
Finally, we have natural language negations that are called polar negations, or opposites:
To be immoral is much more than to just be not moral: it implies the opposite condition. Statements like Example 15.43 are strong negations which not only deny the truth of a statement, but assert its opposite. Since, “opposite” implies a scale, polar negations are a special variety of scalar negations.
To examine this concept more closely, let us draw a linear scale, showing two examples of how the scale is used:
Affirmations (positive) Negations (negative)
|-----------|-----------|-----------|-----------|
All Most Some Few None
Excellent Good Fair Poor Awful
Some scales are more binary than the examples we diagrammed. Thus we have “not necessary” or “unnecessary” being the polar opposite of necessary. Another scale, especially relevant to Lojban, is interpreted based on situations modified by one's philosophy: “not true” may be equated with “false” in a bi-valued truth-functional logic, while in tri-valued logic an intermediate between “true” and “false” is permitted, and in fuzzy logic a continuous scale exists from true to false. The meaning of “not true” requires a knowledge of which variety of truth scale is being considered.
We will define the most general form of scalar negation as indicating only that the particular point or value in the scale or range is not valid and that some other (unspecified) point on the scale is correct. This is the intent expressed in most contexts by “not mild” , for example.
Using this paradigm, contradictory negation is less restrictive than scalar negation – it says that the point or value stated is incorrect (false), and makes no statement about the truth of any other point or value, whether or not on the scale.
In English, scalar negation semantically includes phrases such as “other than” , “reverse of” , or “opposite from” expressions and their equivalents. More commonly, scalar negation is expressed in English by the prefixes “non-” , “un-” , “il-” , and “im-”. Just which form and permissible values are implied by a scalar negation is dependent on the semantics of the word or concept which is being negated, and on the context. Much confusion in English results from the uncontrolled variations in meaning of these phrases and prefixes.
In the examples of Section 15.4 , we will translate the general case of scalar negation using the general formula “other than” when a phrase is scalar-negated, and “non-” when a single word is scalar-negated.
All the scalar negations illustrated in Section 15.3 are expressed in Lojban using the cmavo na'e (of selma'o NAhE). The most common use of na'e is as a prefix to the selbri:
Comparing these two, we see that the negation operator being used in Example 15.45 is na'e. But what exactly does na'e negate? Does the negation include only the gismu klama , which is the entire selbri in this case, or does it include the le zarci as well? In Lojban, the answer is unambiguously “only the gismu”. The cmavo na'e always applies only to what follows it.
Example 15.45 looks as if it were parallel to:
but in fact there is no real parallelism at all. A negation using na denies the truth of a relationship, but a selbri negation with na'e asserts that a relationship exists other than that stated, one which specifically involves the sumti identified in the statement. The grammar allotted to na'e allows us to unambiguously express scalar negations in terms of scope, scale, and range within the scale. Before we explain the scalar aspects, let us show how the scope of na'e is determined.
In tanru, we may wish to negate an individual element before combining it with another to form the tanru. We in effect need a shorter-than-selbri-scope negation, for which we can use na'e as well. The positive sentence
can be subjected to selbri negation in several ways. Two are:
These negations show the default scope of na'e is close-binding on an individual brivla in a tanru. Example 15.48 says that I am going to the market, but in some kind of a non-walking manner. (As with most tanru, there are a few other possible interpretations, but we'll assume this one – see Chapter 5 for a discussion of tanru meaning).
In neither Example 15.48 nor Example 15.49 does the na'e negate the entire selbri. While both sentences contain negations that deny a particular relationship between the sumti, they also have a component which makes a positive claim about such a relationship. This is clearer in Example 15.48 , which says that I am going, but in a non-walking manner. In Example 15.49 , we have claimed that the relationship between me and the market in some way involves walking, but is not one of “going to” (perhaps we are walking around the market, or walking-in-place while at the market).
The “scale” , or actually the “set” , implied in Lojban tanru negations is anything which plausibly can be substituted into the tanru. (Plausibility here is interpreted in the same way that answers to a mo question must be plausible – the result must not only have the right number of places and have sumti values appropriate to the place structure, it must also be appropriate or relevant to the context.) This minimal condition allows a speaker to be intentionally vague, while still communicating meaningful information. The speaker who uses selbri negation is denying one relationship, while minimally asserting a different relationship.
We also need a scalar negation form that has a scope longer than a single brivla. There exists such a longer-scope selbri negation form, as exemplified by (each Lojban sentence in the next several examples is given twice, with parentheses in the second copy showing the scope of the na'e):
| mi | na'e | ke | cadzu | klama | [ke'e] | le | zarci |
| mi | na'e | (ke | cadzu | klama | [ke'e]) | le | zarci |
| I | other-than | ( | walkingly | go-to | ) | the | market. |
This negation uses the same ke and ke'e delimiters (the ke'e is always elidable at the end of a selbri) that are used in tanru. The sentence clearly negates the entire selbri. The ke'e , whether elided or not, reminds us that the negation does not include the trailing sumti. While the trailing-sumti place-structure is defined as that of the final brivla, the trailing sumti themselves are not part of the selbri and are thus not negated by na'e.
Negations of just part of the selbri are also permitted:
| mi | na'e | ke | sutra | cadzu | ke'e | klama | le | zarci |
| mi | na'e | (ke | sutra | cadzu | ke'e) | klama | le | zarci |
| I | other-than | ( | quickly | walkingly | ) | go-to | the | market. |
In Example 15.51 , only the sutra cadzu tanru is negated, so the speaker is indeed going to the market, but not by walking quickly.
Negations made with na'e or na'eke also include within their scope any sumti attached to the brivla or tanru with be or bei. Such attached sumti are considered part of the brivla or tanru:
| mi | na'e | ke | sutra | cadzu | be | le | mi | birka |
| I | other-than | ( | quickly | walking | on | the | of-me | arms-ly |
| ke'e | klama | le | zarci |
| ) | go-to | the | market. |
Note that Example 15.53 and Example 15.54 do not express the same thing:
| mi | na'e | ke | sutra | cadzu | [ke'e] | lemi | birka |
| mi | na'e | (ke | sutra | cadzu | [ke'e]) | lemi | birka |
| I | other-than | ( | quickly | walk-on | ) | my | arms. |
| mi | na'e | ke | sutra | cadzu | be | lemi | birka | [ke'e] |
| mi | na'e | (ke | sutra | cadzu | be | lemi | birka | [ke'e]) |
| I | other-than | ( | quickly | walk | on | my | arms | ). |
The translations show that the negation in Example 15.53 is more restricted in scope; i.e. less of the sentence is negated with respect to x1 ( mi).
Logical scope being an important factor in Lojban's claims to be unambiguous, let us indicate the relative precedence of na'e as an operator. Grouping with ke and ke'e , of course, has an overt scope, which is its advantage. na'e is very close binding to its brivla. Internal binding of tanru, with bo , is not as tightly bound as na'e. co , the tanru inversion operator has a scope that is longer than all other tanru constructs.
In short, na'e and na'eke define a type of negation, which is shorter in scope than bridi negation, and which affects all or part of a selbri. The result of na'e negation remains an assertion of some specific truth and not merely a denial of another claim.
The similarity becomes striking when it is noticed that the rafsi -nal- , representing na'e when a tanru is condensed into a lujvo, forms an exact parallel to the English usage of non-. Turning a series of related negations into lujvo gives:
-
na'e klama becomes nalkla
-
na'e cadzu klama becomes naldzukla
-
na'e sutra cadzu klama becomes nalsu'adzukla
-
na'e ke sutra cadzu ke'e klama becomes nalsu'adzuke'ekla
Note: -kem- is the rafsi for ke , but it is omitted in the final lujvo as superfluous – ke'e is its own rafsi, and its inclusion in the lujvo implies a ke after the -nal- , since it needs to close something; only a ke immediately after the negation would make the ke'e meaningful in the tanru expressed in this lujvo.
In a lujvo, it is probably clearest to translate -nal- as “non-” , to match the English combining forms, except when the na'e has single word scope and English uses “un-” or “im-” to negate that single word. Translation style should determine the use of “other than” , “non-” , or another negator for na'e in tanru; the translator must render the Lojban into English so it is clear in context. Let's go back to our simplest example:
Note that to compare with the English translation form using “non-” , we've translated the Lojban as if the selbri were a noun. Since Lojban klama is indifferently a noun, verb, or adjective, the difference is purely a translation change, not a true change in meaning. The English difference seems significant, though, due to the strongly different English grammatical forms and the ambiguity of English negation.
Consider the following highly problematic sentence:
| lo | ca | nolraitru |
| An-actual | currently | noblest-governor |
| be | le | fasygu'e | cu | krecau |
| of | the | French-country | is-hair-without. |
|
The current King of France is bald. |
The selbri krecau negates with na'e as:
| lo | ca | nolraitru |
| An-actual | currently | noblest-governor |
| be | le | fasygu'e | cu | na'e | krecau |
| of | the | French-country | is-other-than | hair-without. |
|
The current King of France is other-than-bald. |
or, as a lujvo:
| lo | ca | nolraitru |
| An-actual | currently | noblest-governor |
| be | le | fasygu'e | cu | nalkrecau |
| of | the | French-country | is-non-hair-without. |
|
The current King of France is a non-bald-one. |
Example 15.59 and Example 15.60 express the predicate negation forms using a negation word ( na'e) or rafsi ( -nal-); yet they make positive assertions about the current King of France; ie., that he is other-than-bald or non-bald. This follows from the close binding of na'e to the brivla. The lujvo form makes this overt by absorbing the negative marker into the word.
Since there is no current King of France, it is false to say that he is bald, or non-bald, or to make any other affirmative claim about him. Any sentence about the current King of France containing only a selbri negation is as false as the sentence without the negation. No amount of selbri negations have any effect on the truth value of the sentence, which is invariably “false” , since no affirmative statement about the current King of France can be true. On the other hand, bridi negation does produce a truth:
| lo | ca | nolraitru |
| An-actual | current | noblest-governor |
| be | le | fasygu'e | cu | na | krecau |
| of | the | French-country | [false] | is-hair-without. |
|
It is false that the current King of France is bald. |
Note: lo is used in these sentences because negation relates to truth conditions. To meaningfully talk about truth conditions in sentences carrying a description, it must be clear that the description actually applies to the referent. A sentence using le instead of lo can be true even if there is no current king of France, as long as the speaker and the listener agree to describe something as the current king of France. (See the explanations of le in Section 6.2.)
In expressing a scalar negation, we can provide some indication of the scale, range, frame-of-reference, or universe of discourse that is being dealt with in an assertion. As stated in Section 15.4 , the default is the set of plausible alternatives. Thus if we say:
the pragmatic interpretation is that we mean a different color and not
However, if we have reason to be more explicit (an obtuse or contrary listener, or simply an overt logical analysis), we can clarify that we are referring to a color by saying:
We might also have reduced the pragmatic ambiguity by making the two trailing sumti values explicit (the “as perceived by” and “under conditions” places have been added to the place structure of xunre). But assume we have a really stubborn listener (an artificially semi-intelligent computer?) who will find a way to misinterpret Example 15.64 even with three specific sumti provided.
In this case, we use a sumti tagged with the sumtcita ci'u , which translates roughly as “on a scale of X” , where X is the sumti. For maximal clarity, the tagged sumti can be bound into the negated selbri with be. To clarify Example 15.64 , we might say:
| le | stizu | cu | na'e | xunre | be | ci'u | loka | skari |
| The | chair | is-non | (red | on | a-scale-of | a-property | color-ness). |
We can alternately use the sumtcita teci'e , based on ciste , which translates roughly as “of a system of components X” , for universes of discourse; in this case, we would express Example 15.64 as:
| le | stizu | cu | na'e | xunre |
| The | chair | is-a-non | (red |
| be | teci'e | le | skari |
| of | a-system | with-components-the | colors)-thing. |
Other places of ciste can be brought out using the grammar of selma'o BAI modals, allowing slightly different forms of expression, thus:
| le | stizu | cu | na'e | xunre |
| The | chair | is-a-non | (red |
| be | ci'e | lo'i | skari |
| of | a-system | which-is-the-set-of | colors)-thing. |
The cmavo le'a , also in selma'o BAI, can be used to specify a category:
| le | stizu | cu | na'e | xunre |
| The | chair | is-a-non | (red |
| be | le'a | lo'i | skari |
| of | a-category | which-is-the-set-of | colors)-thing. |
which is minimally different in meaning from Example 15.67.
The cmavo na'e is not the only member of selma'o NAhE. If we want to express a scalar negation which is a polar opposite, we use the cmavo to'e , which is grammatically equivalent to na'e :
| le | stizu | cu | to'e | xunre | be | ci'u | loka | skari |
| The | chair | is-a-(opposite-of | red) | on | scale | a-property-of | color-ness. |
Likewise, the midpoint of a scale can be expressed with the cmavo no'e , also grammatically equivalent to na'e. Here are some parallel examples of na'e , no'e , and to'e :
| ta | no'e | melbi |
| That | is-neutrally | beautiful. |
|
That is plain/ordinary-looking (neither ugly nor beautiful). |
The cmavo to'e has the assigned rafsi -tol- and -to'e- ; the cmavo no'e has the assigned rafsi -nor- and -no'e-. The selbri in Example 15.71 through Example 15.73 could be replaced by the lujvo nalmle , normle , and tolmle respectively.
This large variety of scalar negations is provided because different scales have different properties. Some scales are open-ended in both directions: there is no “ultimately ugly” or “ultimately beautiful”. Other scales, like temperature, are open at one end and closed at the other: there is a minimum temperature (so-called “absolute zero”) but no maximum temperature. Still other scales are closed at both ends.
Correspondingly, some selbri have no obvious to'e - what is the opposite of a dog? – while others have more than one, and need ci'u to specify which opposite is meant.
There are two ways of negating sumti in Lojban. We have the choice of quantifying the sumti with zero, or of applying the sumti-negator na'ebo before the sumti. It turns out that a zero quantification serves for contradictory negation. As the cmavo we use implies, na'ebo forms a scalar negation.
Let us show examples of each.
| no | lo | ca | nolraitru | be |
| Zero | of-those-who-are | currently | noblest-governors | of |
| le | fasygu'e | cu | krecau |
| the | French-country | are-hair-without. |
|
No current king of France is bald. |
Is Example 15.74 true? Yes, because it merely claims that of the current Kings of France, however many there may be, none are bald, which is plainly true, since there are no such current Kings of France.
Now let us look at the same sentence using na'ebo negation:
| na'ebo | lo | ca | nolraitru |
| Something-other-than | (the | current | noblest-governor |
| be | le | fasygu'e | cu | krecau |
| of | the | French-country) | is-hair-without. |
|
Something other than the current King of France is bald. |
Example 15.75 is true provided that something reasonably describable as “other than a current King of France” , such as the King of Saudi Arabia, or a former King of France, is in fact bald.
In place of na'ebo , you may also use no'ebo and to'ebo , to be more specific about the sumti which would be appropriate in place of the stated sumti. Good examples are hard to come by, but here's a valiant try:
(Boston and Perth are nearly, but not quite, antipodal cities. In a purely United States context, San Francisco might be a better “opposite”.) Coming up with good examples is difficult, because attaching to'ebo to a description sumti is usually the same as attaching to'e to the selbri of the description.
It is not possible to transform sumti negations of either type into bridi negations or scalar selbri negations. Negations of sumti will be used in Lojban conversation. The inability to manipulate these negations logically will, it is hoped, prevent the logical errors that result when natural languages attempt corresponding manipulations.
We have a few other constructs that can be negated, all of them based on negating individual words. For such negation, we use the suffix-combining negator, which is nai. nai , by the way, is almost always written as a compound into the previous word that it is negating, although it is a regular separate-word cmavo and the sole member of selma'o NAI.
Most of these negation forms are straightforward, and should be discussed and interpreted in connection with an analysis of the particular construct being negated. Thus, we will not go into much detail here.
The following are places where nai is used:
When attached to tenses and modals (see Section 9.13 , Section 10.9 , Section 10.18 and Section 10.20), the nai suffix usually indicates a contradictory negation of the tagged bridi. Thus punai as a tense inflection means “not-in-the-past” , or “not-previously” , without making any implication about any other time period unless explicitly stated. As a result,
and
mean exactly the same thing, although there may be a difference of emphasis.
Tenses and modals can be logically connected, with the logical connectives containing contradictory negations; this allows negated tenses and modals to be expressed positively using logical connectives. Thus punai je ca means the same thing as pu naje ca.
As a special case, a -nai attached to the interval modifiers of selma'o TAhE, ROI, or ZAhO (explained in Chapter 10) signals a scalar negation:
means that I dance on the ice either zero or else two or more times within the relevant time interval described by the bridi. Example 15.79 is very different from the English use of “not once” , which is an emphatic way of saying “never” – that is, exactly zero times.
In indicators and attitudinals of selma'o UI or CAI, nai denotes a polar negation. As discussed in Section 13.4 , most indicators have an implicit scale, and nai changes the indicator to refer to the opposite end of the scale. Thus .uinai expresses unhappiness, and .ienai expresses disagreement (not ambivalence, which is expressed with the neutral or undecided intensity as .iecu'i).
Vocative cmavo of selma'o COI are considered a kind of indicator, but one which identifies the listener. Semantically, we could dispense with about half of the COI selma'o words based on the scalar paradigm. For example, co'o could be expressed as coinai. However, this is not generally done.
Most of the COI cmavo are used in what are commonly called protocol situations. These protocols are used, for example, in radio conversations, which often take place in a noisy environment. The negatives of protocol words tend to convey diametrically opposite communications situations (as might be expected). Therefore, only one protocol vocative is dependent on nai : negative acknowledgement, which is je'enai ( “I didn't get that”).
Unlike the attitudinal indicators, which tend to be unimportant in noisy situations, the protocol vocatives become more important. So if, in a noisy environment, a protocol listener makes out only nai , he or she can presume it is a negative acknowledgement and repeat transmission or otherwise respond accordingly. Section 13.14 provides more detail on this topic.
The abstractors of selma'o NU follow the pattern of the tenses and modals. NU allows negative abstractions, especially in compound abstractions connected by logical connectives: pu'ujeza'inai , which corresponds to pu'u jenai za'i just as punai je ca corresponds to pu naje ca. It is not clear how much use logically connected abstractors will be: see Section 11.12.
A nai attached to a non-logical connective (of selma'o JOI or BIhI) is a scalar negation, and says that the bridi is false under the specified mixture, but that another connective is applicable. Non-logical connectives are discussed in Section 14.14.
One application of negation is in answer to truth questions (those which expect the answers “Yes” or “No”). The truth question cmavo xu is in selma'o UI; placed at the beginning of a sentence, it asks whether the sentence as a whole is true or false.
| xu | la | .djan. | pu | klama |
| Is-it-true-that: | (that-named | John | previously | went-to |
| la | .paris. | .e | la | .rom. |
| that-named | Paris | and | that-named | Rome.) |
You can now use each of the several kinds of negation we've discussed in answer to this (presuming the same question and context for each answer).
The straightforward negative answer is grammatically equivalent to the expanded sentence with the na immediately after the cu (and before any tense/modal):
which means
| la | .djan. | [cu] | na | pu | klama |
| That-named | John | [false] | previously | went-to |
| la | .paris. | .e | la | .rom. |
| that-named | Paris | and | that-named | Rome. |
|
It's not true that John went to Paris and Rome. |
The respondent can change the tense, putting the na in either before or after the new tense:
meaning
| la | .djan. | [cu] | na | ba | klama |
| That-named | John | [false] | later | will-go-to |
| la | .paris. | .e | la | .rom. |
| that-named | Paris | and | that-named | Rome. |
|
It is false that John will go to Paris and Rome. |
or alternatively
meaning
| la | .djan. | [cu] | ba | na |
| that-named | John | later-will | [false] |
| klama | la | .paris. | .e | la | .rom. |
| go-to | that-named | Paris | and | that-named | Rome. |
We stated in Section 15.2 that sentences like Example 15.84 and Example 15.86 appear to be semantically identical, but that subtle semantic distinctions may eventually be found.
You can also use a scalar negation with na'e , in which case, it is equivalent to putting a na'eke immediately after any tense:
which means
| la | .djan. | [cu] | pu | na'eke | klama | [ke'e] |
| that-named | John | previously | other-than( | went-to | ) |
| la | .paris. | .e | la | .rom. |
| that-named | Paris | and | that-named | Rome. |
He might have telephoned the two cities instead of going there. The unnecessary ke and ke'e would have been essential if the selbri had been a tanru.
There is an explicit positive form for both selma'o NA ( ja'a) and selma'o NAhE ( je'a), each of which would supplant the corresponding negator in the grammatical position used, allowing one to assert the positive in response to a negative question or statement without confusion. Assuming the same context as in Section 15.8 :
or equivalently
| xu | la | .djan. | [cu] | na | pu |
| Is-it-true-that: | that-named | John | [false] | previously |
| klama | la | .paris. | .e | la | .rom. |
| went-to | that-name | Paris | and | that-named | Rome. |
The obvious, but incorrect, positive response to this negative question is:
A plain go'i does not mean “Yes it is” ; it merely abbreviates repeating the previous statement unmodified, including any negators present; and Example 15.91 actually states that it is false that John went to both Paris and Rome.
When considering:
as a response to a negative question like Example 15.90 , Lojban designers had to choose between two equally plausible interpretations with opposite effects. Does Example 15.92 create a double negative in the sentence by adding a new na to the one already there (forming a double negative and hence a positive statement), or does the na replace the previous one, leaving the sentence unchanged?
It was decided that substitution, the latter alternative, is the preferable choice, since it is then clear whether we intend a positive or a negative sentence without performing any manipulations. This is the way English usually works, but not all languages work this way – Russian, Japanese, and Navajo all interpret a negative reply to a negative question as positive.
The positive assertion cmavo of selma'o NA, which is "ja'a", can also replace the na in the context, giving:
ja'a can replace na in a similar manner wherever the latter is used:
je'a can replace na'e in exactly the same way, stating that scalar negation does not apply, and that the relation indeed holds as stated. In the absence of a negation context, it emphasizes the positive:
The question of truth or falsity is not entirely synonymous with negation. Consider the English sentence
If I never started such a heinous activity, then this sentence is neither true nor false. Such a negation simply says that something is wrong with the non-negated statement. Generally, we then use either tone of voice or else a correction to express a preferred true claim: “I never have beaten my wife.”
Negations which follow such a pattern are called “metalinguistic negations”. In natural languages, the mark of metalinguistic negation is that an indication of a correct statement always, or almost always, follows the negation. Tone of voice or emphasis may be further used to clarify the error.
Negations of every sort must be expressible in Lojban; errors are inherent to human thought, and are not excluded from the language. When such negations are metalinguistic, we must separate them from logical claims about the truth or falsity of the statement, as well as from scalar negations which may not easily express (or imply) the preferred claim. Because Lojban allows concepts to be so freely combined in tanru, limits on what is plausible or not plausible tend to be harder to determine.
Mimicking the muddled nature of natural language negation would destroy this separation. Since Lojban does not use tone of voice, we need other means to metalinguistically indicate what is wrong with a statement. When the statement is entirely inappropriate, we need to be able to express metalinguistic negation in a more non-specific fashion.
Here is a list of some different kinds of metalinguistic negation with English-language examples:
I have not held THREE jobs previously, but four.
(inaccurate quantity; the difference from the previous example is that someone who has held four jobs has also held three jobs)
It is not good, but bad.
(undue quantity negation indicating that the value on a scale for measuring the predicate is incorrect)
The house is not blue, but green.
(the scale/category being used is incorrect, but a related category applies)
The house is not blue, but is colored.
(the scale/category being used is incorrect, but a broader category applies)
The cat is not blue, but long-haired.
(the scale/category being used is incorrect, but an unrelated category applies)
The set of possible metalinguistic errors is open-ended.
Many of these forms have a counterpart in the various examples that we've discussed under logical negation. Metalinguistic negation doesn't claim that the sentence is false or true, though. Rather, it claims that, due to some error in the statement, “true” and “false” don't really apply.
Because one can metalinguistically negate a true statement intending a non-contradictory correction (say, a spelling error), we need a way (or ways) to metalinguistically negate a statement which is independent of our logical negation schemes using na , na'e and kin. The cmavo na'i is assigned this function. If it is present in a statement, it indicates metalinguistically that something in the statement is incorrect. This metalinguistic negation must override any evaluation of the logic of the statement. It is equally allowed in both positive and negative statements.
Since na'i is not a logical operator, multiple occurrences of na'i need not be assumed to cancel each other. Indeed, we can use the position of na'i to indicate metalinguistically what is incorrect, preparatory to correcting it in a later sentence; for this reason, we give na'i the grammar of UI. The inclusion of na'i anywhere in a sentence makes it a non-assertion, and suggests one or more pitfalls in assigning a truth value.
Let us briefly indicate how the above-mentioned metalinguistic errors can be identified. Other metalinguistic problems can then be marked by devising analogies to these examples:
Existential failure can be marked by attaching na'i to the descriptor lo or the poi in a da poi -form sumti. (See Section 6.2 and Section 16.4 for details on these constructions.) Remember that if a le sumti seems to refer to a non-existent referent, you may not understand what the speaker has in mind – the appropriate response is then ki'a , asking for clarification.
Presupposition failure can be marked directly if the presupposition is overt; if not, one can insert a “mock presupposition” to question with the sumtcita (selma'o BAI) word ji'u ; ji'uku thus explicitly refers to an unexpressed assumption, and ji'una'iku metalinguistically says that something is wrong with that assumption. (See Chapter 9.)
Scale errors and category errors can be similarly expressed with selma'o BAI. le'a has meaning “of category/class/type X” , ci'u has meaning “on scale X” , and ci'e , based on ciste , can be used to talk about universes of discourse defined either as systems or sets of components, as shown in Section 15.8. kai and la'u also exist in BAI for discussing other quality and quantity errors.
We have to make particular note of potential problems in the areas of undue quantity and incorrect scale/category. Assertions about the relationships between gismu are among the basic substance of the language. It is thus invalid to logically require that if something is blue, that it is colored, or if it is not-blue, then it is some other color. In Lojban, blanu ( “blue”) is not explicitly defined as a skari ( “color”). Similarly, it is not implicit that the opposite of “good” is “bad”.
This mutual independence of gismu is only an ideal. Pragmatically, people will categorize things based on their world-views. We will write dictionary definitions that will relate gismu, unfortunately including some of these world-view assumptions. Lojbanists should try to minimize these assumptions, but this seems a likely area where logical rules will break down (or where Sapir-Whorf effects will be made evident). In terms of negation, however, it is vital that we clearly preserve the capability of denying a presumably obvious scale or category assumption.
Solecisms, grammatical and spelling errors will be marked by marking the offending word or phrase with na'i (in the manner of any selma'o UI cmavo). In this sense, na'i becomes equivalent to the English metalinguistic marker “[sic]”. Purists may choose to use ZOI or LOhU/LEhU quotes or sa'a -marked corrections to avoid repeating a truly unparsable passage, especially if a computer is to analyze the speech/text. See Section 19.12 for explanations of these usages.
In summary, metalinguistic negation will typically take the form of referring to a previous statement and marking it with one or more na'i to indicate what metalinguistic errors have been made, and then repeating the statement with corrections. References to previous statements may be full repetitions, or may use members of selma'o GOhA. na'i at the beginning of a statement merely says that something is inappropriate about the statement, without specificity.
In normal use, metalinguistic negation requires that a corrected statement follow the negated statement. In Lojban, however, it is possible to completely and unambiguously specify metalinguistic errors without correcting them. It will eventually be seen whether an uncorrected metalinguistic negation remains an acceptable form in Lojban. In such a statement, metalinguistic expression would involve an ellipsis not unlike that of tenseless expression.
Note that metalinguistic negation gives us another kind of legitimate negative answer to a xu question (see Section 15.8). na'i will be used when something about the questioned statement is inappropriate, such as in questions like “Have you stopped beating your wife?” :
| xu | do | sisti | lezu'o |
| is-it-true-that: | you | cease | the-activity-of |
| do | rapydarxi | ledo | fetspe |
| you | repeat-hitting | your | female-spouse? |
|
Have you stopped beating your wife? |
Responses could include:
| na'i | go'i |
| [metalinguistic-negation] | [repeat-previous] |
|
The bridi as a whole is inappropriate in some way. |
| go'i | na'i |
| [repeat-previous] | [metalinguistic-negation] |
|
The selbri ( sisti) is inappropriate in some way. |
One can also specifically qualify the metalinguistic negation, by explicitly repeating the erroneous portion of the bridi to be metalinguistically negated, or adding on of the selma'o BAI qualifiers mentioned above:
| go'i | ji'una'iku |
| [repeat-previous] | [presupposition-wrong] |
|
Some presupposition is wrong with the previous bridi. |
Finally, one may metalinguistically affirm a bridi with jo'a , another cmavo of selma'o UI. A common use for jo'a might be to affirm that a particular construction, though unusual or counterintuitive, is in fact correct; another usage would be to disagree with – by overriding – a respondent's metalinguistic negation.
The following brief dialogue is from Chapter 7 of Through The Looking Glass by Lewis Carroll.
“Who did you pass on the road?” the King went on, holding out his hand to the Messenger for some more hay.
“Quite right,” said the King: “this young lady saw him too. So of course Nobody walks slower than you.”
This nonsensical conversation results because the King insists on treating the word “nobody” as a name, a name of somebody. However, the essential nature of the English word “nobody” is that it doesn't refer to somebody; or to put the matter another way, there isn't anybody to which it refers.
The central point of contradiction in the dialogue arises in Example 16.3 , when the King says “... Nobody walks slower than you”. This claim would be plausible if “Nobody” were really a name, since the Messenger could only pass someone who does walk more slowly than he. But the Messenger interprets the word “nobody” in the ordinary English way, and says (in Example 16.4) “... nobody walks much faster than I do” (i.e., I walk faster, or as fast as, almost everyone), which the King then again misunderstands. Both the King and the Messenger are correct according to their respective understandings of the ambiguous word “nobody/Nobody”.
There are Lojban words or phrases corresponding to the problematic English words “somebody” , “nobody” , “anybody” , “everybody” (and their counterparts “some/no/any/everyone” and “some/no/any/everything”), but they obey rules which can often be surprising to English-speakers. The dialogue above simply cannot be translated into Lojban without distortion: the name “Nobody” would have to be represented by a Lojban name, which would spoil the perfection of the wordplay. As a matter of fact, this is the desired result: a logical language should not allow two conversationalists to affirm “Nobody walks slower than the Messenger” and “Nobody walks faster than the Messenger” and both be telling the truth. (Unless, of course, nobody but the Messenger walks at all, or everyone walks at exactly the same speed.)
This chapter will explore the Lojban mechanisms that allow the correct and consistent construction of sentences like those in the dialogue. There are no new grammatical constructs explained in this chapter; instead, it discusses the way in which existing facilities that allow Lojban-speakers to resolve problems like the above, using the concepts of modern logic. However, we will not approach the matter from the viewpoint of logicians, although readers who know something of logic will discover familiar notions in Lojban guise.
Although Lojban is called a logical language, not every feature of it is “logical”. In particular, the use of le is incompatible with logical reasoning based on the description selbri, because that selbri may not truthfully apply: you cannot conclude from my statement that
that there really is a man; the only thing you can conclude is that there is one thing (or more) that I choose to refer to as a man. You cannot even tell which man is meant for sure without asking me (although communication is served if you already know from the context).
In addition, the use of attitudinals (see Chapter 13) often reduces or removes the ability to make deductions about the bridi to which those attitudinals are applied. From the fact that I hope George will win the election, you can conclude nothing about George's actual victory or defeat.
Let us consider, to begin with, a sentence that is not in the dialogue:
There are two plausible Lojban translations of Example 16.7. The simpler one is:
The cmavo zo'e indicates that a sumti has been omitted (indeed, even zo'e itself can be omitted in this case, as explained in Section 7.7) and the listener must fill in the correct value from context. In other words, Example 16.8 means “‘You-know-what’ sees me. ”
However, Example 16.7 is just as likely to assert simply that there is someone who sees me, in which case a correct translation is:
Example 16.9 does not presuppose that the listener knows who sees the speaker, but simply tells the listener that there is someone who sees the speaker. Statements of this kind are called “existential claims”. (Formally, the one doing the seeing is not restricted to being a person; it could be an animal or – in principle – an inanimate object. We will see in Section 16.4 how to represent such restrictions.)
Example 16.9 has a two-part structure: there is the part da zo'u , called the prenex, and the part da viska mi , the main bridi. Almost any Lojban bridi can be preceded by a prenex, which syntactically is any number of sumti followed by the cmavo zo'u (of selma'o ZOhU). For the moment, the sumti will consist of one or more of the cmavo da , de , and di (of selma'o KOhA), glossed in the literal translations as “X” , “Y” , and “Z” respectively. By analogy to the terminology of symbolic logic, these cmavo are called “variables”.
Here is an example of a prenex with two variables:
In Example 16.10 , the literal interpretation of the two variables da and de as “there-is-an-X” and “there-is-a-Y” tells us that there are two things which stand in the relationship that one loves the other. It might be the case that the supposed two things are really just a single thing that loves itself; nothing in the Lojban version of Example 16.10 rules out that interpretation, which is why the colloquial translation does not say “Somebody loves somebody else.” The things referred to by different variables may be different or the same. (We use “somebody” here rather than “something” for naturalness; lovers and beloveds are usually persons, though the Lojban does not say so.)
It is perfectly all right for the variables to appear more than once in the main bridi:
What Example 16.11 claims is fundamentally different from what Example 16.10 claims, because da prami da is not structurally the same as da prami de. However,
means exactly the same thing as Example 16.11 ; it does not matter which variable is used as long as they are used consistently.
It is not necessary for a variable to be a sumti of the main bridi directly:
is perfectly correct even though the da is used only in a possessive construction. (Possessives are explained in Section 8.7.)
It is very peculiar, however, even if technically grammatical, for the variable not to appear in the main bridi at all:
| da | zo'u | la | .ralf. | gerku |
| There-is-an-X | such-that | that-named | Ralph | is-a-dog |
|
There is something such that Ralph is a dog. |
has a variable bound in a prenex whose relevance to the claim of the following bridi is completely unspecified.
What happens if we substitute “everything” for “something” in Example 16.7 ? We get:
Of course, this example is false, because there are many things which do not see the speaker. It is not easy to find simple truthful examples of so-called universal claims (those which are about everything), so bear with us for a while. (Indeed, some Lojbanists tend to avoid universal claims even in other languages, since they are so rarely true in Lojban.)
The Lojban translation of Example 16.15 is
When the variable cmavo da is preceded by ro , the combination means “For every X” rather than “There is an X”. Superficially, these English formulations look totally unrelated: Section 16.6 will bring them within a common viewpoint. For the moment, accept the use of ro da for “everything” on faith.
Here is a universal claim with two variables:
Again, X and Y can represent the same thing, so Example 16.17 does not mean “Everything loves everything else.” Furthermore, because the claim is universal, it is about every thing, not merely every person, so we cannot use “everyone” or “everybody” in the translation.
Note that ro appears before both da and de. If ro is omitted before either variable, we get a mixed claim, partly existential like those of Section 16.2 , partly universal.
| da | ro | de | zo'u | da | viska | de |
| There-is-an-X | such-that-for-every | Y | : | X | sees | Y. |
|
Something sees everything. |
Example 16.18 and Example 16.19 mean completely different things. Example 16.18 says that for everything, there is something which it sees, not necessarily the same thing seen for every seer. Example 16.19 , on the other hand, says that there is a particular thing which can see everything that there is (including itself). Both of these are fairly silly, but they are different kinds of silliness.
There are various possible translations of universal claims in English: sometimes we use “anybody/anything” rather than “everybody/everything”. Often it makes no difference which of these is used: when it does make a difference, it is a rather subtle one which is explained in Section 16.8.
The universal claims of Section 16.3 are not only false but absurd: there is really very little to be said that is both true and non-trivial about every object whatsoever. Furthermore, we have been glossing over the distinction between “everything” and “everybody” and the other pairs ending in “-thing” and “-body”. It is time to bring up the most useful feature of Lojban variables: the ability to restrict their ranges.
In Lojban, a variable da , de , or di may be followed by a poi relative clause in order to restrict the range of things that the variable describes. Relative clauses are described in detail in Chapter 8 , but the kind we will need at present consist of poi followed by a bridi (often just a selbri) terminated with ku'o or vau (which can usually be elided). Consider the difference between
and
| da | poi | prenu | zo'u | da | viska | la | .djim. |
| There-is-an-X | which | is-a-person | : | X | sees | that-named | Jim. |
|
Someone sees Jim. |
In Example 16.20 , the variable da can refer to any object whatever; there are no restrictions on it. In Example 16.21 , da is restricted by the poi prenu relative clause to persons only, and so da poi prenu translates as “someone.” (The difference between “someone” and “somebody” is a matter of English style, with no real counterpart in Lojban.) If Example 16.21 is true, then Example 16.20 must be true, but not necessarily vice versa.
Universal claims benefit even more from the existence of relative clauses. Consider
and
| ro | da | poi | gerku | zo'u | da | vasxu |
| For-every | X | which | is-a-dog | : | X | breathes. |
|
Every dog breathes. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Each dog breathes. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
All dogs breathe. |
Example 16.22 is a silly falsehood, but Example 16.23 is an important truth (at least if applied in a timeless or potential sense: see Section 10.19). Note the various colloquial translations “every dog” , “each dog” , and “all dogs”. They all come to the same thing in Lojban, since what is true of every dog is true of all dogs. “All dogs” is treated as an English plural and the others as singular, but Lojban makes no distinction.
If we make an existential claim about dogs rather than a universal one, we get:
It isn't really necessary for every Lojban bridi involving variables to have a prenex on the front. In fact, none of the examples we've seen so far required prenexes at all! The rule for dropping the prenex is simple: if the variables appear in the same order within the bridi as they did in the prenex, then the prenex is superfluous. However, any ro or poi appearing in the prenex must be transferred to the first occurrence of the variable in the main part of the bridi. Thus, Example 16.9 becomes just:
and Example 16.23 becomes:
You might well suppose, then, that the purpose of the prenex is to allow the variables in it to appear in a different order than the bridi order, and that would be correct. Consider
| ro | da | poi | prenu | ku'o | de |
| For-every | X | which | is-a-person, | there-is-a-Y |
| poi | gerku | ku'o | zo'u | de | batci | da |
| which | is-a-dog | : | Y | bites | X. |
The prenex of Example 16.27 is like that of Example 16.18 (but with relative clauses): it notes that the following bridi is true of every person with respect to some dog, not necessarily the same dog for each. But in the main bridi part, the de appears before the da. Therefore, the true translation is
If we tried to omit the prenex and move the ro and the relative clauses into the main bridi, we would get:
| de | poi | gerku | cu | batci | ro | da | poi | prenu |
| There-is-a-Y | which | is-a-dog | which-bites | every | X | which | is-a-person |
|
Some dog bites everyone. |
which has the structure of Example 16.19 : it says that there is a dog (call him Fido) who bites, has bitten, or will bite every person that has ever existed! We can safely rule out Fido's existence, and say that Example 16.29 is false, while agreeing to Example 16.27.
Even so, Example 16.27 is most probably false, since some people never experience dogbite. Examples like Example 16.27 and Example 16.23 (might there be some dogs which never have breathed, because they died as embryos?) indicate the danger in Lojban of universal claims even when restricted. In English we are prone to say that “Everyone says” or that “Everybody does” or that “Everything is” when in fact there are obvious counterexamples which we are ignoring for the sake of making a rhetorical point. Such statements are plain falsehoods in Lojban, unless saved by a context (such as tense) which implicitly restricts them.
How can we express Example 16.27 in Lojban without a prenex? Since it is the order in which variables appear that matters, we can say:
| ro | da | poi | prenu | cu | se | batci | de | poi | gerku |
| Every | X | which | is-a-person | is-bitten-by | some-Y | which | is-a-dog. |
using the conversion operator se (explained in Section 5.11) to change the selbri batci ( “bites”) into se batci ( “is bitten by”). The translation given in Example 16.28 uses the corresponding strategy in English, since English does not have prenexes (except in strained “logician's English”). This implies that a sentence with both a universal and an existential variable can't be freely converted with se ; one must be careful to preserve the order of the variables.
If a variable occurs more than once, then any ro or poi decorations are moved only to the first occurrence of the variable when the prenex is dropped. For example,
| di | poi | prenu | zo'u |
| There-is-a-Z | which | is-a-person | : |
| ti | xarci | di | di |
| this-thing | is-a-weapon | for-use-against-Z | by-Z |
|
This is a weapon for someone to use against himself/herself. |
(in which di is used rather than da just for variety) loses its prenex as follows:
As the examples in this section show, dropping the prenex makes for terseness of expression often even greater than that of English (Lojban is meant to be an unambiguous language, not necessarily a terse or verbose one), provided the rules are observed.
So far, we have seen variables with either nothing in front, or with the cmavo ro in front. Now ro is a Lojban number, and means “all” ; thus ro prenu means “all persons” , just as re prenu means “two persons”. In fact, unadorned da is also taken to have an implicit number in front of it, namely su'o , which means “at least one”. Why is this? Consider Example 16.9 again, this time with an explicit su'o :
From this version of Example 16.9 , we understand the speaker's claim to be that of all the things that there are, at least one of them sees him or her. The corresponding universal claim, Example 16.16 , says that of all the things that exist, every one of them can see the speaker.
Any other number can be used instead of ro or su'o to precede a variable. Then we get claims like:
This means that exactly two things, no more or less, saw the speaker on the relevant occasion. In English, we might take “Two things see me” to mean that at least two things see the speaker, but there might be more; in Lojban, though, that claim would have to be made as:
which would be false if nothing, or only one thing, saw the speaker, but not otherwise. We note the su'o here meaning “at least” ; su'o by itself is short for su'opa where pa means “one” , as is explained in Section 18.9.
The prenex may be removed from Example 16.34 and Example 16.35 as from the others, leading to:
and
respectively, subject to the rules prescribed in Section 16.5.
Now we can explain the constructions ro prenu for “all persons” and re prenu for “two persons” which were casually mentioned at the beginning of this Section. In fact, ro prenu , a so-called “indefinite description” , is shorthand for ro DA poi prenu , where “DA” represents a fictitious variable that hasn't been used yet and will not be used in future. (Even if all three of da , de , and di have been used up, it does not matter, for there are ways of getting more variables, discussed in Section 16.14.) So in fact
is short for
which in turn is short for:
Note that when we move more than one variable to the prenex (along with its attached relative clause), we must make sure that the variables are in the same order in the prenex as in the bridi proper.
Let us consider a sentence containing two quantifier expressions neither of which is ro or su'o (remembering that su'o is implicit where no explicit quantifier is given):
The question raised by Example 16.41 is, does each of the dogs bite the same two men, or is it possible that there are two different men per dog, for six men altogether? If the former interpretation is taken, the number of men involved is fixed at two; but if the latter, then the speaker has to be taken as saying that there might be any number of men between two and six inclusive. Let us transform Example 16.41 step by step as we did with Example 16.38 :
(Note that we need separate variables da and de , because of the rule that says each indefinite description gets a variable never used before or since.)
| ci | da | poi | gerku | ku'o | re | de | poi | nanmu | zo'u |
| For-three | Xes | which | are-dogs | -, | for-two | Ys | which | are-men | : |
| da | batci | de |
| X | bites | Y. |
Here we see that indeed each of the dogs is said to bite two men, and it might be different men each time; a total of six biting events altogether.
How then are we to express the other interpretation, in which just two men are involved? We cannot just reverse the order of variables in the prenex to
| re | de | poi | nanmu | ku'o | ci | da | poi | gerku | zo'u |
| For-two | Ys | which | are-men | -, | for-three | Xes | which | are-dogs, | : |
| da | batci | de |
| X | bites | Y. |
for although we have now limited the number of men to exactly two, we end up with an indeterminate number of dogs, from three to six. The distinction is called a “scope distinction” : in Example 16.42 , ci gerku is said to have wider scope than re nanmu , and therefore precedes it in the prenex. In Example 16.44 the reverse is true.
The solution is to use a termset, which is a group of terms either joined by ce'e (of selma'o CEhE) between each term, or else surrounded by nu'i (of selma'o NUhI) on the front and nu'u (of selma'o NUhU) on the rear. Terms (which are either sumti or sumti prefixed by tense or modal tags) that are grouped into a termset are understood to have equal scope:
| ci | gerku | ce'e | re | nanmu | cu | batci | ||
| nu'i | ci | gerku | re | nanmu | [nu'u] | cu | batci | |
| Three | dogs | [plus] | two | men, | bite. |
which picks out two groups, one of three dogs and the other of two men, and says that every one of the dogs bites each of the men. The second Lojban version uses forethought; note that nu'u is an elidable terminator, and in this case can be freely elided.
What about descriptors, like ci lo gerku , le nanmu or re le ci mlatu ? They too can be grouped in termsets, but usually need not be, except for the lo case which functions like the case without a descriptor. Unless an actual quantifier precedes it, le nanmu means ro le nanmu , as is explained in Section 6.7. Two sumti with ro quantifiers are independent of order, so:
means that each of the dogs specified bites each of the men specified, for six acts of biting altogether. However, if there is an explicit quantifier before le other than ro , the problems of this section reappear.
Using the facilities already discussed, a plausible translation might be
| ro | da | poi | klama | le | zarci | cu | cadzu | le | foldi |
| All | X | such-that-it | goes-to | the | store | walks-on | the | field. |
|
Everyone who goes to the store walks across the field. |
But there is a subtle difference between Example 16.47 and Example 16.48. Example 16.48 tells us that, in fact, there are people who go to the store, and that they walk across the field. A sumti of the type ro da poi klama requires that there are things which klama : Lojban universal claims always imply the corresponding existential claims as well. Example 16.47 , on the other hand, does not require that there are any people who go to the store: it simply states, conditionally, that if there is anyone who goes to the store, he or she walks across the field as well. This conditional form mirrors the true Lojban translation of Example 16.47 :
| ro | da | zo'u | da | go | klama | le | zarci |
| For-every | X | : | X | if-and-only-if | it-is-a-goer-to | the | store |
| gi | cadzu | le | foldi |
| is-a-walker-on | the | field. |
Although Example 16.49 is a universal claim as well, its universality only implies that there are objects of some sort or another in the universe of discourse. Because the claim is conditional, nothing is implied about the existence of goers-to-the-store or of walkers-on-the-field, merely that any entity which is one is also the other.
There is another use of “any” in English that is not universal but existential. Consider
Example 16.50 does not at all mean that I need every box bigger than this one, for indeed I do not; I require only one box. But the naive translation
does not work either, because it asserts that there really is such a box, as the prenex paraphrase demonstrates:
| da | poi | tanxe | gi'e | bramau | ti | zo'u | mi | nitcu | da |
| There-is-an-X | which | is-a-box | and | is-bigger-than | this | : | I | need | X. |
What to do? Well, the x2 place of nitcu can be filled with an event as well as an object, and in fact Example 16.51 can also be paraphrased as:
| mi | nitcu | lo | nu | mi | ponse | lo | tanxe |
| I | need | an | event-of | I | possess | some | box(es) |
| poi | bramau | ti |
| which-are | bigger-than | this-one. |
Rewritten using variables, Example 16.53 becomes
| mi | nitcu | lo | nu | da | zo'u |
| I | need | an | event-of | there-being-an-X | such-that: |
| da | se | ponse | mi |
| X | is-possessed-by | me |
| gi'e | tanxe | gi'e | bramau | ti |
| and | is-a-box | and | is-bigger-than | this-thing. |
So we see that a prenex can be attached to a bridi that is within a sentence. By default, a variable always behaves as if it is bound in the prenex which (notionally) is attached to the smallest enclosing bridi, and its scope does not extend beyond that bridi. However, the variable may be placed in an outer prenex explicitly:
| da | poi | tanxe | gi'e | bramau | ti | zo'u |
| There-is-an-X | which | is-a-box | and | is-bigger-than | this-one | such-that: |
| mi | nitcu | le | nu | mi | ponse | da |
| I | need | the | event-of | my | possessing | X. |
But what are the implications of Example 16.53 and Example 16.55 ? The main difference is that in Example 16.55 , the da is said to exist in the real world of the outer bridi; but in Example 16.53 , the existence is only within the inner bridi, which is a mere event that need not necessarily come to pass. So Example 16.55 means
which is what Example 16.52 says, whereas Example 16.53 turns out to be an effective translation of our original Example 16.47. So uses of “any” that aren't universal end up being reflected by variables bound in the prenex of a subordinate bridi.
This section, as well as Section 16.10 through Section 16.12 , are in effect a continuation of Chapter 15 , introducing features of Lojban negation that require an understanding of prenexes and variables. In the examples below, “there is a Y” and the like must be understood as “there is at least one Y, possibly more”.
As explained in Section 15.2 , the negation of a bridi is usually accomplished by inserting na at the beginning of the selbri:
| mi | na | klama | le | zarci |
| I | [false] | go-to | the | store. |
|
It is false that I go to the store. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
I don't go to the store. |
The other form of bridi negation is expressed by using the compound cmavo naku in the prenex, which is identified and compounded by the lexer before looking at the sentence grammar. In Lojban grammar, naku is then treated like a sumti. In a prenex, naku means precisely the same thing as the logician's “it is not the case that” in a similar English context. (Outside of a prenex, naku is also grammatically treated as a single entity – the equivalent of a sumti – but does not have this exact meaning; we'll discuss these other situations in Section 16.11.)
To represent a bridi negation using a prenex, remove the na from before the selbri and place naku at the left end of the prenex. This form is called “external bridi negation” , as opposed to “internal bridi negation” using na. The prenex version of Example 16.57 is
| naku | zo'u | mi | klama | le | zarci |
| It-is-not-the-case-that | : | I | go-to | the | store. |
|
It is false that: I go to the store. |
However, naku can appear at other points in the prenex as well. Compare
| naku | de | zo'u | de | zutse |
| It-is-not-the-case-that: | for-some-Y | : | Y | sits. |
| It-is-false-that: | for-at-least-one-Y | : | Y | sits. |
|
It is false that something sits. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Nothing sits. |
with
| su'ode | naku | zo'u | de | zutse |
| For-at-least-one-Y, | it-is-false-that | : | Y | sits. |
|
There is something that doesn't sit. |
The relative position of negation and quantification terms within a prenex has a drastic effect on meaning. Starting without a negation, we can have:
| roda | su'ode | zo'u | da | prami | de |
| For-every-X, | there-is-a-Y, | such-that | X | loves | Y. |
|
Everybody loves at least one thing (each, not necessarily the same thing). |
or:
| su'ode | roda | zo'u | da | prami | de |
| There-is-a-Y, | such-that-for-each-X | : | X | loves | Y. |
|
There is at least one particular thing that is loved by everybody. |
The simplest form of bridi negation to interpret is one where the negation term is at the beginning of the prenex:
| naku | roda | su'ode | zo'u | da | prami | de |
| It-is-false-that: | for-every-X, | there-is-a-Y, | such-that: | X | loves | Y. |
|
It is false that: everybody loves at least one thing. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
(At least) someone doesn't love anything. |
the negation of Example 16.61 , and
| naku | su'ode | roda | zo'u | da | prami | de | |
| It-is-false-that: | there-is-a-Y | such-that | for-each-X | : | X | loves | Y. |
|
It is false that: there is at least one thing that is loved by everybody. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
There isn't any one thing that everybody loves. |
the negation of Example 16.62.
The rules of formal logic require that, to move a negation boundary within a prenex, you must “invert any quantifier” that the negation boundary passes across. Inverting a quantifier means that any ro (all) is changed to su'o (at least one) and vice versa. Thus, Example 16.63 and Example 16.64 can be restated as, respectively:
| su'oda | naku | su'ode | zo'u | da | prami | de |
| For-some-X, | it-is-false-that: | there-is-a-Y | such-that: | X | loves | Y. |
|
There is somebody who doesn't love anything. |
and:
| rode | naku | roda | zo'u | da | prami | de |
| For-every-Y, | it-is-false-that: | for-every-X | : | X | loves | Y. |
|
For each thing, it is not true that everybody loves it. |
Another movement of the negation boundary produces:
| su'oda | rode | naku | zo'u | da | prami | de |
| There-is-an-X | such-that-for-every-Y, | it-is-false-that | : | X | loves | Y. |
|
There is someone who, for each thing, doesn't love that thing. |
and
| rode | su'oda | naku | zo'u | da | prami | de |
| For-every-Y, | there-is-an-X, | such-that-it-is-false-that | : | X | loves | Y. |
|
For each thing there is someone who doesn't love it. |
Investigation will show that, indeed, each transformation preserves the meanings of Example 16.63 and Example 16.64.
The quantifier no (meaning “zero of”) also involves a negation boundary. To transform a bridi containing a variable quantified with no , we must first expand it. Consider
| noda | rode | zo'u | da | prami | de |
| There-is-no-X, | for-every-Y, | such-that | X | loves | Y. |
|
Nobody loves everything. |
which is negated by:
| naku | noda | rode | zo'u | da | prami | de |
| It-is-false-that: | there-is-no-X-that, | for-every-Y | : | X | loves | Y. |
|
It is false that there is nobody who loves everything. |
We can simplify Example 16.70 by transforming the prenex. To move the negation phrase within the prenex, we must first expand the no quantifier. Thus “for no x” means the same thing as “it is false that for some x” , and the corresponding Lojban noda can be replaced by naku su'oda. Making this substitution, we get:
| naku | naku | su'oda |
| It-is-false-that | it-is-false-that | there-is-some-X-such-that |
| …rode | zo'u | da | prami | de |
| for-every-X | : | X | loves | Y |
|
It is false that it is false that: for an X, for every Y: X loves Y. |
Adjacent pairs of negation boundaries in the prenex can be dropped, so this means the same as:
| su'oda | rode | zo'u | da | prami | de |
| There-is-an-X-such-that, | for-every-Y | : | X | loves | Y. |
|
At least one person loves everything. |
which is clearly the desired contradiction of Example 16.69.
The interactions between quantifiers and negation mean that you cannot eliminate double negatives that are not adjacent. You must first move the negation phrases so that they are adjacent, inverting any quantifiers they cross, and then the double negative can be eliminated.
A complete discussion of logical connectives appears in Chapter 14. What is said here is intentionally quite incomplete and makes several oversimplifications.
A logical connective is a cmavo or compound cmavo. In this chapter, we will make use of the logical connectives “and” and “or” (where “or” really means “and/or” , “either or both”). The following simplified recipes explain how to make some logical connectives:
-
To logically connect two Lojban sumti with “and” , put them both in the bridi and separate them with the cmavo .e.
-
To logically connect two Lojban bridi with “and” , replace the regular separator cmavo .i with the compound cmavo .ije.
-
To logically connect two Lojban sumti with “or” , put them both in the bridi and separate them with the cmavo .a.
-
To logically connect two Lojban bridi with “or” , replace the regular separator cmavo .i with the compound cmavo .ija.
More complex logical connectives also exist; in particular, one may place na before .e or .a , or between .i and je or ja ; likewise, one may place nai at the end of a connective. Both na and nai have negative effects on the sumti or bridi being connected. Specifically, na negates the first or left-hand sumti or bridi, and nai negates the second or right-hand one.
Whenever a logical connective occurs in a sentence, that sentence can be expanded into two sentences by repeating the common terms and joining the sentences by a logical connective beginning with .i. Thus the following sentence:
can be expanded to:
| mi | klama | ti | .ije | do | klama | ti |
| I | come-to | this-here | and | you | come-to | this-here |
|
I come here, and, you come here. |
The same type of expansion can be performed for any logical connective, with any valid combination of na or nai attached. No change in meaning occurs under such a transformation.
Clearly, if we know what negation means in the expanded sentence forms, then we know what it means in all of the other forms. But what does negation mean between sentences?
The mystery is easily solved. A negation in a logical expression is identical to the corresponding bridi negation, with the negator placed at the beginning of the prenex. Thus:
expands to:
and then into prenex form as:
| roda | zo'u | mi | prami | da | .ije |
| For-each-thing | : | I | love | it, | and |
| naku | do | prami | da |
| it-is-false-that | you | love | (the-same)-it. |
|
For each thing: I love it, and it is false that you love (the same) it. |
By the rules of predicate logic, the ro quantifier on da has scope over both sentences. That is, once you've picked a value for da for the first sentence, it stays the same for both sentences. (The da continues with the same fixed value until a new paragraph or a new prenex resets the meaning.)
Thus the following example has the indicated translation:
| su'oda | zo'u | mi | prami | da |
| For-at-least-one-thing | : | I | love | that-thing. |
| .ije | naku | zo'u | do | prami | da |
| And | it-is-false-that | : | you | love | that-(same)-thing. |
|
There is something that I love that you don't. |
If you remember only two rules for prenex manipulation of negations, you won't go wrong:
Let us consider the English sentence
We cannot express this directly with na ; the apparently obvious translation
| su'oda | poi | verba |
| At-least-one-X | which-are | child(ren) |
| na | klama | su'ode | poi | ckule |
| [false] | go-to | at-least-one-Y | which-are | school(s). |
when converted to the external negation form produces:
| naku | zo'u | su'oda | poi | verba | cu |
| It-is-false | that | some-which | are | children |
| klama | su'ode | poi | ckule |
| go-to | some-which | are | schools. |
|
All children don't go to some school (not just some children). |
Lojban provides a negation form which more closely emulates natural language negation. This involves putting naku before the selbri, instead of a na. naku is clearly a contradictory negation, given its parallel with prenex bridi negation. Using naku , Example 16.79 can be expressed as:
| su'oda | poi | verba | ku'o | naku | klama | su'ode | poi | ckule |
| Some | that | are-children | don't | go-to | some | that-are | schools. |
|
Some children don't go to a school. |
Although it is not technically a sumti, naku can be used in most of the places where a sumti may appear. We'll see what this means in a moment.
When you use naku within a bridi, you are explicitly creating a negation boundary. As explained in Section 16.9 , when a prenex negation boundary expressed by naku moves past a quantifier, the quantifier has to be inverted. The same is true for naku in the bridi proper. We can move naku to any place in the sentence where a sumti can go, inverting any quantifiers that the negation boundary crosses. Thus, the following are equivalent to Example 16.82 (no good English translations exist):
| su'oda | poi | verba | cu | klama | rode | poi | ckule | ku'o | naku |
|
For some children, for every school, they don't go to it. |
In Example 16.83 , we moved the negation boundary rightward across the quantifier of de , forcing us to invert it. In Example 16.85 we moved the negation boundary across the quantifier of da , forcing us to invert it instead. Example 16.84 merely switched the selbri and the negation boundary, with no effect on the quantifiers.
The same rules apply if you rearrange the sentence so that the quantifier crosses an otherwise fixed negation. You can't just convert the selbri of Example 16.82 and rearrange the sumti to produce
or rather, Example 16.86 means something completely different from Example 16.82. Conversion with se under naku negation is not symmetric; not all sumti are treated identically, and some sumti are not invariant under conversion. Thus, internal negation with naku is considered an advanced technique, used to achieve stylistic compatibility with natural languages.
It isn't always easy to see which quantifiers have to be inverted in a sentence. Example 16.82 is identical in meaning to:
but in Example 16.87 , the bound variables da and de have been hidden.
It is trivial to export an internal bridi negation expressed with na to the prenex, as we saw in Section 16.9 ; you just move it to the left end of the prenex. In comparison, it is non-trivial to export a naku to the prenex because of the quantifiers. The rules for exporting naku require that you export all of the quantified variables (implicit or explicit) along with naku , and you must export them from left to right, in the same order that they appear in the sentence. Thus Example 16.82 goes into prenex form as:
| su'oda | poi | verba | ku'o | naku |
| For-some-X | which | is-a-child, | it-is-not-the-case-that |
| su'ode | poi | ckule | zo'u | da | klama | de | |
| there-is-a-Y | which | is-a-school | such-that: | X | goes | to | Y. |
We can now move the naku to the left end of the prenex, getting a contradictory negation that can be expressed with na :
| naku | roda | poi | verba | ku'o |
| It-is-not-the-case-that | for-all-X's | which-are | children, |
| su'ode | poi | ckule | zo'u | da | klama | de |
| there-is-a-Y | which-is | a-school | such-that: | X | goes-to | Y. |
from which we can restore the quantified variables to the sentence, giving:
| naku | zo'u | roda | poi | verba | cu | klama | su'ode | poi | ckule |
|
It is not the case that all children go to some school. |
or more briefly
As noted in Section 16.5 , a sentence with two different quantified variables, such as Example 16.91 , cannot always be converted with se without first exporting the quantified variables. When the variables have been exported, the sentence proper can be converted, but the quantifier order in the prenex must remain unchanged:
| roda | poi | verba | ku'o | su'ode |
| for-all-X's | that-are | children | , | there-is-a-Y |
| poi | ckule | zo'u | de | na | se | klama | da |
| that | is-a-school | such-that: | Y | it-is-not-the-case-that: | is-gone-to-by | X. |
While you can't freely convert with se when you have two quantified variables in a sentence, you can still freely move sumti to either side of the selbri, as long as the order isn't changed. If you use na negation in such a sentence, nothing special need be done. If you use naku negation, then quantified variables that cross the negation boundary must be inverted.
Clearly, if all of Lojban negation was built on naku negation instead of na negation, logical manipulation in Lojban would be as difficult as in natural languages. In Section 16.12 , for example, we'll discuss DeMorgan's Law, which must be used whenever a sumti with a logical connection is moved across a negation boundary.
Since naku has the grammar of a sumti, it can be placed almost anywhere a sumti can go, including be and bei clauses; it isn't clear what these mean, and we recommend avoiding such constructs.
You can put multiple naku compounds in a sentence, each forming a separate negation boundary. Two adjacent naku compounds in a bridi are a double negative and cancel out:
Other expressions using two naku compounds may or may not cancel out. If there is no quantified variable between them, then the naku compounds cancel.
Negation with internal naku is clumsy and non-intuitive for logical manipulations, but then, so are the natural language features it is emulating.
DeMorgan's Law states that when a logical connective between terms falls within a negation, then expanding the negation requires a change in the connective. Thus (where “p” and “q” stand for terms or sentences) “not (p or q)” is identical to “not p and not q” , and “not (p and q)” is identical to “not p or not q”. The corresponding changes for the other two basic Lojban connectives are: “not (p equivalent to q)” is identical to “not p exclusive-or not q” , and “not (p whether-or-not q)” is identical to both “not p whether-or-not q” and “not p whether-or-not not q”. In any Lojban sentence having one of the basic connectives, you can substitute in either direction from these identities. (These basic connectives are explained in Chapter 14.)
The effects of DeMorgan's Law on the logical connectives made by modifying the basic connectives with nai , na and se can be derived directly from these rules; modify the basic connective for DeMorgan's Law by substituting from the above identities, and then, apply each nai , na and se modifier of the original connectives. Cancel any double negatives that result.
When do we apply DeMorgan's Law? Whenever we wish to “distribute” a negation over a logical connective; and, for internal naku negation, whenever a logical connective moves in to, or out of, the scope of a negation – when it crosses a negation boundary.
Let us apply DeMorgan's Law to some sample sentences. These sentences make use of forethought logical connectives, which are explained in Section 14.5. It suffices to know that ga and gi , used before each of a pair of sumti or bridi, mean “either” and “or” respectively, and that ge and gi used similarly mean “both” and “and”. Furthermore, ga , ge , and gi can all be suffixed with nai to negate the bridi or sumti that follows.
We have defined na and naku zo'u as, respectively, internal and external bridi negation. These forms being identical, the negation boundary always remains at the left end of the prenex. Thus, exporting or importing negation between external and internal bridi negation forms never requires DeMorgan's Law to be applied. Example 16.94 and Example 16.95 are exactly equivalent:
| la | .djan. | na | klama | ga |
| that-named | John | [false] | goes-to | either |
| la | .paris. | gi | la | .rom. |
| that-named | Paris | or | that-named | Rome. |
| naku | zo'u | la | .djan. | klama |
| It-is-false | that: | that-named | John | goes-to |
| ga | la | .paris. | gi | la | .rom. |
| either | that-named | Paris | or | that-named | Rome. |
It is not an acceptable logical manipulation to move a negator from the bridi level to one or more sumti. However, Example 16.94 and related examples are not sumti negations, but rather expand to form two logically connected sentences. In such a situation, DeMorgan's Law must be applied. For instance, Example 16.95 expands to:
| ge | la | .djan. | la | .paris. | na | klama | |
| [It-is-true-that] | both | that-named | John, | to-that-named | Paris, | [false] | goes, |
| gi | la | .djan. | la | .rom. | na | klama |
| and | that-named | John, | to-that-named | Rome, | [false] | goes. |
The ga and gi , meaning “either-or” , have become ge and gi , meaning “both-and” , as a consequence of moving the negators into the individual bridi.
Here is another example of DeMorgan's Law in action, involving bridi-tail logical connection (explained in Section 14.9):
| la | .djein. | le | zarci | na | ge | dzukla | gi | bajrykla |
| that-named | Jane | to-the | market | [false] | both | walks | and | runs. |
| la | .djein. | le | zarci | ganai | dzukla | ginai | bajrykla |
| that-named | Jane | to-the | market | either-([false] | walks) | or-([false] | runs. |
| that-named | Jane | to-the | market | if | walks | then-([false] | runs). |
(Placing le zarci before the selbri makes sure that it is properly associated with both parts of the logical connection. Otherwise, it is easy to erroneously leave it off one of the two sentences.)
It is wise, before freely doing transformations such as the one from Example 16.97 to Example 16.98 , that you become familiar with expanding logical connectives to separate sentences, transforming the sentences, and then recondensing. Thus, you would prove the transformation correct by the following steps. By moving its na to the beginning of the prenex as a naku , Example 16.97 becomes:
| naku | zo'u | la | .djein. | le | zarci |
| It-is-false-that | : | that-named | Jane | to-the | market |
| ge | dzukla | gi | bajrykla |
| (both | walks | and | runs). |
And by dividing the bridi with logically connected selbri into two bridi,
| naku | zo'u | ge | la | .djein. | le | zarci | cu | dzukla |
| It-is-false | that: | both | (that-named | Jane | to-the | market | walks) |
| gi | la | .djein. | le | zarci | cu | bajrykla |
| and | (that-named | Jane | to-the | market | runs). |
is the result.
At this expanded level, we apply DeMorgan's Law to distribute the negation in the prenex across both sentences, to get
| ga | la | .djein. | le | zarci | na | dzukla |
| Either | that-named | Jane | to-the | market | [false] | walks, |
| gi | la | .djein. | le | zarci | na | bajrykla |
| or | that-named | Jane | to-the | market | [false] | runs. |
which is the same as
| ganai | la | .djein. | le | zarci | cu | dzukla |
| If | that-named | Jane | to-the | market | walks, |
| ginai | la | .djein. | le | zarci | cu | bajrykla |
| then-([false] | that-named | Jane | to-the | market | runs). |
|
If Jane walks to the market, then she doesn't run. |
which then condenses down to Example 16.98.
DeMorgan's Law must also be applied to internal naku negations:
| ga | la | .paris. | gi | la | .rom. |
| (Either | that-named | Paris | or | that-named | Rome) |
| naku | se | klama | la | .djan. |
| is-not | gone-to-by | that-named | John. |
| la | .djan. | naku | klama | ge |
| that-named | John | doesn't | go-to | both |
| la | .paris. | gi | la | .rom. |
| that-named | Paris | and | that-named | Rome. |
That Example 16.103 and Example 16.104 mean the same should become evident by studying the English. It is a good exercise to work through the Lojban and prove that they are the same.
In addition to the variables da , de , and di that we have seen so far, which function as sumti and belong to selma'o KOhA, there are three corresponding variables bu'a , bu'e , and bu'i which function as selbri and belong to selma'o GOhA. These new variables allow existential or universal claims which are about the relationships between objects rather than the objects themselves. We will start with the usual silly examples; the literal translation will represent bu'a , bu'e and bu'i with F, G, and H respectively.
| su'o | bu'a | zo'u | la | .djim. |
| For-at-least-one | relationship-F | : | that-named | Jim |
| bu'a | la | .djan. |
| stands-in-relationship-F | to-that-named | John. |
|
There's some relationship between Jim and John. |
The translations of Example 16.105 show how unidiomatic selbri variables are in English; Lojban sentences like Example 16.105 need to be totally reworded in English. Furthermore, when a selbri variable appears in the prenex, it is necessary to precede it with a quantifier such as su'o ; it is ungrammatical to just say bu'a zo'u. This rule is necessary because only sumti can appear in the prenex, and su'o bu'a is technically a sumti – in fact, it is an indefinite description like re nanmu , since bu'a is grammatically equivalent to a brivla like nanmu. However, indefinite descriptions involving the bu'a-series cannot be imported from the prenex.
When the prenex is omitted, the preceding number has to be omitted too:
As a result, if the number before the variable is anything but su'o , the prenex is required:
| ro | bu'a | zo'u | la | .djim. |
| For-every | relationship-F | : | that-named | Jim |
| bu'a | la | .djan. |
| stands-in-relationship-F | to-that-named | John. |
|
Every relationship exists between Jim and John. |
Example 16.105 and Example 16.106 are almost certainly true: Jim and John might be brothers, or might live in the same city, or at least have the property of being jointly human. Example 16.107 is palpably false, however; if Jim and John were related by every possible relationship, then they would have to be both brothers and father-and-son, which is impossible.
A variable may have a quantifier placed in front of it even though it has already been quantified explicitly or implicitly by a previous appearance, as in:
What does Example 16.108 mean? The appearance of ci da quantifies da as referring to three things, which are restricted by the relative clause to be cats. When re da appears later, it refers to two of those three things – there is no saying which ones. Further uses of da alone, if there were any, would refer once more to the three cats, so the requantification of da is purely local.
In general, the scope of a prenex that precedes a sentence extends to following sentences that are joined by ijeks (explained in Section 14.4) such as the .ije in Example 16.108. Theoretically, a bare .i terminates the scope of the prenex. Informally, however, variables may persist for a while even after an .i , as if it were an .ije. Prenexes that precede embedded bridi such as relative clauses and abstractions extend only to the end of the clause, as explained in Section 16.8. A prenex preceding tu'e … tu'u long-scope brackets persists until the tu'u , which may be many sentences or even paragraphs later.
If the variables da , de , and di (or the selbri variables bu'a , bu'e , and bu'i) are insufficient in number for handling a particular problem, the Lojban approach is to add a subscript to any of them. Each possible different combination of a subscript and a variable cmavo counts as a distinct variable in Lojban. Subscripts are explained in full in Section 19.6 , but in general consist of the cmavo xi (of selma'o XI) followed by a number, one or more lerfu words forming a single string, or a general mathematical expression enclosed in parentheses.
A quantifier can be prefixed to a variable that has already been bound either in a prenex or earlier in the bridi, thus:
| ci | da | poi | prenu | cu | se ralju | pa | da |
| Three | Xs | which | are-persons | are-led-by | one-of | X |
|
Three people are led by one of them. |
The pa da in Example 16.109 does not specify the number of things to which da refers, as the preceding ci da does. Instead, it selects one of them for use in this sumti only. The number of referents of da remains three, but a single one (there is no way of knowing which one) is selected to be the leader.
This chapter is incomplete. There are many more aspects of logic that I neither fully understand nor feel competent to explain, neither in abstract nor in their Lojban realization. Lojban was designed to be a language that makes predicate logic speakable, and achieving that goal completely will need to wait for someone who understands both logic and Lojban better than I do. I can only hope to have pointed out the areas that are well-understood (and by implication, those that are not).

James Cooke Brown, the founder of the Loglan Project, coined the word “letteral” (by analogy with “numeral”) to mean a letter of the alphabet, such as “f” or “z”. A typical example of its use might be
(Don't forget the one within quotation marks.) Using the word “letteral” avoids confusion with “letter” , the kind you write to someone. Not surprisingly, there is a Lojban gismu for “letteral” , namely lerfu , and this word will be used in the rest of this chapter.
Lojban uses the Latin alphabet, just as English does, right? Then why is there a need for a chapter like this? After all, everyone who can read it already knows the alphabet. The answer is twofold:
First, in English there are a set of words that correspond to and represent the English lerfu. These words are rarely written down in English and have no standard spellings, but if you pronounce the English alphabet to yourself you will hear them: ay, bee, cee, dee ... . They are used in spelling out words and in pronouncing most acronyms. The Lojban equivalents of these words are standardized and must be documented somehow.
Second, English has names only for the lerfu used in writing English. (There are also English names for Greek and Hebrew lerfu: English-speakers usually refer to the Greek lerfu conventionally spelled “phi” as “fye” , whereas “fee” would more nearly represent the name used by Greek-speakers. Still, not all English-speakers know these English names.) Lojban, in order to be culturally neutral, needs a more comprehensive system that can handle, at least potentially, all of the world's alphabets and other writing systems.
Letterals have several uses in Lojban: in forming acronyms and abbreviations, as mathematical symbols, and as pro-sumti – the equivalent of English pronouns.
In earlier writings about Lojban, there has been a tendency to use the word lerfu for both the letterals themselves and for the Lojban words which represent them. In this chapter, that tendency will be ruthlessly suppressed, and the term “lerfu word” will invariably be used for the latter. The Lojban equivalent would be lerfu valsi or lervla.
The first requirement of a system of lerfu words for any language is that they must represent the lerfu used to write the language. The lerfu words for English are a motley crew: the relationship between “doubleyou” and “w” is strictly historical in nature; “aitch” represents “h” but has no clear relationship to it at all; and “z” has two distinct lerfu words, “zee” and “zed” , depending on the dialect of English in question.
All of Lojban's basic lerfu words are made by one of three rules:
Therefore, the following table represents the basic Lojban alphabet:
|
|
|
|
|
|
||||||||||||
|
|
|
|
|
|
||||||||||||
|
|
|
|
|
|
||||||||||||
|
|
|
|
|
|
There are several things to note about this table. The consonant lerfu words are a single syllable, whereas the vowel and ' lerfu words are two syllables and must be preceded by pause (since they all begin with a vowel). Another fact, not evident from the table but important nonetheless, is that by. and its like are single cmavo of selma'o BY, as is .y'y.. The vowel lerfu words, on the other hand, are compound cmavo, made from a single vowel cmavo plus the cmavo bu (which belongs to its own selma'o, BU). All of the vowel cmavo have other meanings in Lojban (logical connectives, sentence separator, hesitation noise), but those meanings are irrelevant when bu follows.
Here are some illustrations of common Lojban words spelled out using the alphabet above:
Spelling out words is less useful in Lojban than in English, for two reasons: Lojban spelling is phonemic, so there can be no real dispute about how a word is spelled; and the Lojban lerfu words sound more alike than the English ones do, since they are made up systematically. The English words “fail” and “vale” sound similar, but just hearing the first lerfu word of either, namely “eff” or “vee” , is enough to discriminate easily between them – and even if the first lerfu word were somehow confused, neither “vail” nor “fale” is a word of ordinary English, so the rest of the spelling determines which word is meant. Still, the capability of spelling out words does exist in Lojban.
Note that the lerfu words ending in y were written (in Example 17.2 and Example 17.3) with pauses after them. It is not strictly necessary to pause after such lerfu words, but failure to do so can in some cases lead to ambiguities:
without a pause after cy. would be interpreted as:
A safe guideline is to pause after any cmavo ending in y unless the next word is also a cmavo ending in y. The safest and easiest guideline is to pause after all of them.
Lojban doesn't use lower-case (small) letters and upper-case (capital) letters in the same way that English does; sentences do not begin with an upper-case letter, nor do names. However, upper-case letters are used in Lojban to mark irregular stress within cmevla, thus:
It would require far too many cmavo to assign one for each upper-case and one for each lower-case lerfu, so instead we have two special cmavo ga'e and to'a representing upper case and lower case respectively. They belong to the same selma'o as the basic lerfu words, namely BY, and they may be freely interspersed with them.
The effect of ga'e is to change the interpretation of all lerfu words following it to be the upper-case version of the lerfu. An occurrence of to'a causes the interpretation to revert to lower case. Thus, ga'e .abu means not “a” but “A” , and Ivan's name may be spelled out thus:
The cmavo and compound cmavo of this type will be called “shift words”.
How long does a shift word last? Theoretically, until the next shift word that contradicts it or until the end of text. In practice, it is common to presume that a shift word is only in effect until the next word other than a lerfu word is found.
It is often convenient to shift just a single letter to upper case. The cmavo tau , of selma'o LAU, is useful for the purpose. A LAU cmavo must always be immediately followed by a BY cmavo or its equivalent: the combination is grammatically equivalent to a single BY. (See Section 17.14 for details.)
A likely use of tau is in the internationally standardized symbols for the chemical elements. Each element is represented using either a single upper-case lerfu or one upper-case lerfu followed by one lower-case lerfu:
If a shift to upper-case is in effect when tau appears, it shifts the next lerfu word only to lower case, reversing its usual effect.
So far we have seen bu only as a suffix to vowel cmavo to produce vowel lerfu words. Originally, this was the only use of bu. In developing the lerfu word system, however, it proved to be useful to allow bu to be attached to any word whatsoever, in order to allow arbitrary extensions of the basic lerfu word set.
Formally, bu may be attached to any single Lojban word. Compound cmavo do not count as words for this purpose. The special cmavo ba'e , za'e , zei , zo , zoi , la'o , lo'u , si , sa , su , and fa'o may not have bu attached, because they are interpreted before bu detection is done; in particular,
is needed when discussing bu in Lojban. It is also illegal to attach bu to itself, but more than one bu may be attached to a word; thus .abubu is legal, if ugly. (Its meaning is not defined, but it is presumably different from .abu.) It does not matter if the word is a cmavo, a cmevla, or a brivla. All such words suffixed by bu are treated grammatically as if they were cmavo belonging to selma'o BY.
The ability to attach bu to words has been used primarily to make names for various logograms and other unusual characters. For example, the Lojban name for the “happy face” is me'o .uibu , based on the attitudinal .ui that means “happiness” (the cmavo me'o is used here to represent the very character as opposed to a lerfu word; this is explained in Section 17.9). Likewise, the “smiley face” , written “:-)” and used on computer networks to indicate humor, is called me'o .u'ibu. The existence of these names does not mean that you should insert me'o .uibu into running Lojban text to indicate that you are happy, or me'o .u'ibu when something is funny; instead, use the appropriate attitudinal directly.
Likewise, me'o joibu represents the ampersand character, “&” , based on the cmavo joi meaning “mixed “and””. Many more such lerfu words will probably be invented in future.
The . and , characters used in Lojbanic writing to represent pause and syllable break respectively have been assigned the lerfu words me'o denpa bu (literally, “pause bu”) and me'o slaka bu (literally, “syllable bu”). The written space is mandatory here, because denpa and slaka are normal gismu with normal stress: denpabu would be a fu'ivla (word borrowed from another language into Lojban) stressed denPAbu. No pause is required between denpa (or slaka) and bu , though.
As stated in Section 17.1 , Lojban's goal of cultural neutrality demands a standard set of lerfu words for the lerfu of as many other writing systems as possible. When we meet these lerfu in written text (particularly, though not exclusively, mathematical text), we need a standard Lojbanic way to pronounce them.
There are certainly hundreds of alphabets and other writing systems in use around the world, and it is probably an unachievable goal to create a single system which can express all of them, but if perfection is not demanded, a usable system can be created from the raw material which Lojban provides.
One possibility would be to use the lerfu word associated with the language itself, Lojbanized and with bu added. Indeed, an isolated Greek “alpha” in running Lojban text is probably most easily handled by calling it .alfas. bu. Here the Greek lerfu word has been made into a Lojbanized name by adding s and then into a Lojban lerfu word by adding bu. Note that the pause after .alfas. is still needed.
Likewise, the easiest way to handle the Latin letters “h” , “q” , and “w” that are not used in Lojban is by a consonant lerfu word with bu attached. The following assignments have been made:
As an example, the English word “quack” would be spelled in Lojban thus:
Note that the fact that the letter “c” in this word has nothing to do with the sound of the Lojban letter c is irrelevant; we are spelling an English word and English rules control the choice of letters, but we are speaking Lojban and Lojban rules control the pronunciations of those letters.
A few more possibilities for Latin-alphabet letters used in languages other than English:
However, this system is not ideal for all purposes. For one thing, it is verbose. The native lerfu words are often quite long, and with bu added they become even longer: the worst-case Greek lerfu word would be .Omikron. bu , with four syllables and two mandatory pauses. In addition, alphabets that are used by many languages have separate sets of lerfu words for each language, and which set is Lojban to choose?
The alternative plan, therefore, is to use a shift word similar to those introduced in Section 17.3. After the appearance of such a shift word, the regular lerfu words are re-interpreted to represent the lerfu of the alphabet now in use. After a shift to the Greek alphabet, for example, the lerfu word ty. would represent not Latin “t” but Greek “tau”. Why “tau” ? Because it is, in some sense, the closest counterpart of “t” within the Greek lerfu system. In principle it would be all right to map ty. to “phi” or even “omega” , but such an arbitrary relationship would be extremely hard to remember.
Where no obvious closest counterpart exists, some more or less arbitrary choice must be made. Some alien lerfu may simply not have any shifted equivalent, forcing the speaker to fall back on a bu form. Since a bu form may mean different things in different alphabets, it is safest to employ a shift word even when bu forms are in use.
Shifts for several alphabets have been assigned cmavo of selma'o BY:
| lo'a |
Latin/Roman/Lojban alphabet |
| ge'o |
Greek alphabet |
| je'o |
Hebrew alphabet |
| jo'o |
Arabic alphabet |
| ru'o |
Cyrillic alphabet |
The cmavo zai (of selma'o LAU) is used to create shift words to still other alphabets. The BY word which must follow any LAU cmavo would typically be a name representing the alphabet with bu suffixed:
Unlike the cmavo above, these shift words have not been standardized and probably will not be until someone actually has a need for them. (Note the . characters marking leading and following pauses.)
In addition, there may be multiple visible representations within a single alphabet for a given letter: roman vs. italics, handwriting vs. print, Baskerville vs. Comic. These traditional “font and face” distinctions are also represented by shift words, indicated with the cmavo ce'a (of selma'o LAU) and a following BY word:
The cmavo na'a (of selma'o BY) is a universal shift-word cancel: it returns the interpretation of lerfu words to the default of lower-case Lojban with no specific font. It is more general than lo'a , which changes the alphabet only, potentially leaving font and case shifts in place.
Several sections at the end of this chapter contain tables of proposed lerfu word assignments for various languages.
Many languages that make use of the Latin alphabet add special marks to some of the lerfu they use. The diacritics used in French orthography are the acute accent (“é”; accent aigu), the grave accent (“è”; accent grave), the circumflex (“ê”; accent circonflexe), the diaeresis (“ë”; tréma), and the cedilla (“ç”; cédille). Diacritics have no effect on the primary alphabetical order. Likewise, German uses a mark called “umlaut” (e.g. “ä”); a mark which looks the same is also used in French, but with a different name and meaning.
These marks may be considered lerfu, and each has a corresponding lerfu word in Lojban. So far, no problem. But the marks appear over lerfu, whereas the words must be spoken (or written) either before or after the lerfu word representing the basic lerfu. Typewriters (for mechanical reasons) and the computer programs that emulate them usually require their users to type the accent mark before the basic lerfu, whereas in speech the accent mark is often pronounced afterwards (for example, in German “a umlaut” is preferred to “umlaut a”).
Lojban cannot settle this question by fiat. Either it must be left up to default interpretation depending on the language in question, or the lerfu-word compounding cmavo tei (of selma'o TEI) and foi (of selma'o FOI) must be used. These cmavo are always used in pairs; any number of lerfu words may appear between them, and the whole is treated as a single compound lerfu word. The French word “été” , with acute accent marks on both “e” lerfu, could be spelled as:
and it does not matter whether .akut. bu appears before or after .ebu ; the tei … foi grouping guarantees that the acute accent is associated with the correct lerfu. Of course, the level of precision represented by Example 17.18 would rarely be required: it might be needed by a Lojban-speaker when spelling out a French word for exact transcription by another Lojban-speaker who did not know French.
This system breaks down in languages which use more than one accent mark on a single lerfu; some other convention must be used for showing which accent marks are written where in that case. The obvious convention is to represent the mark nearest the basic lerfu by the lerfu word closest to the word representing the basic lerfu. Any remaining ambiguities must be resolved by further conventions not yet established.
Some languages, like Swedish and Finnish, consider certain accented lerfu to be completely distinct from their unaccented equivalents, but Lojban does not make a formal distinction, since the printed characters look the same whether they are reckoned as separate letters or not. In addition, some languages consider certain 2-letter combinations (like “ll” and “ch” in Spanish) to be letters; this may be represented by enclosing the combination in tei … foi.
In addition, when discussing a specific language, it is permissible to make up new lerfu words, as long as they are either explained locally or well understood from context: thus Spanish “ll” or Croatian “lj” could be called .ibu , but that usage would not necessarily be universally understood.
Section 17.19 contains a table of proposed lerfu words for some common accent marks.
Lojban does not have punctuation marks as such: the denpa bu and the slaka bu are really a part of the alphabet. Other languages, however, use punctuation marks extensively. As yet, Lojban does not have any words for these punctuation marks, but a mechanism exists for devising them: the cmavo lau of selma'o LAU. lau must always be followed by a BY word; the interpretation of the BY word is changed from a lerfu to a punctuation mark. Typically, this BY word would be a cmevla or brivla with a bu suffix.
Why is lau necessary at all? Why not just use a bu -marked word and announce that it is always to be interpreted as a punctuation mark? Primarily to avoid ambiguity. The bu mechanism is extremely open-ended, and it is easy for Lojban users to make up bu words without bothering to explain what they mean. Using the lau cmavo flags at least the most important of such nonce lerfu words as having a special function: punctuation. (Exactly the same argument applies to the use of zai to signal an alphabet shift or ce'a to signal a font shift.)
Since different alphabets require different punctuation marks, the interpretation of a lau -marked lerfu word is affected by the current alphabet shift and the current font shift.
Chinese characters ( “hànzì” in Chinese, kanji in Japanese) represent an entirely different approach to writing from alphabets or syllabaries. (A syllabary, such as Japanese hiragana or Amharic writing, has one lerfu for each syllable of the spoken language.) Very roughly, Chinese characters represent single elements of meaning; also very roughly, they represent single syllables of spoken Chinese. There is in principle no limit to the number of Chinese characters that can exist, and many thousands are in regular use.
It is hopeless for Lojban, with its limited lerfu and shift words, to create an alphabet which will match this diversity. However, there are various possible ways around the problem.
First, both Chinese and Japanese have standard Latin-alphabet representations, known as “pinyin” for Chinese and “romaji” for Japanese, and these can be used. Thus, the word “ han 4 zi 4 ” ( “hànzì”) is conventionally written with two characters, but it may be spelled out as:
The cmavo vo is the Lojban digit “4”. It is grammatical to intersperse digits (of selma'o PA) into a string of lerfu words; as long as the first cmavo is a lerfu word, the whole will be interpreted as a string of lerfu words. In Chinese, the digits can be used to represent tones. Pinyin is more usually written using accent marks, the mechanism for which was explained in Section 17.6.
The Japanese company named “Mitsubishi” in English is spelled the same way in romaji, and could be spelled out in Lojban thus:
Alternatively, a really ambitious Lojbanist could assign lerfu words to the individual strokes used to write Chinese characters (there are about seven or eight of them if you are a flexible human being, or about 40 if you are a rigid computer program), and then represent each character with a tei , the stroke lerfu words in the order of writing (which is standardized for each character), and a foi. No one has as yet attempted this project.
So far, lerfu words have only appeared in Lojban text when spelling out words. There are several other grammatical uses of lerfu words within Lojban. In each case, a single lerfu word or more than one may be used. Therefore, the term “lerfu string” is introduced: it is short for “sequence of one or more lerfu words”.
A lerfu string may be used as a pro-sumti (a sumti which refers to some previous sumti), just like the pro-sumti ko'a , ko'e , and so on:
In Example 17.21 , .abu and by. represent specific sumti, but which sumti they represent must be inferred from context.
Alternatively, lerfu strings may be assigned by goi , the regular pro-sumti assignment cmavo:
There is a special rule that sometimes makes lerfu strings more advantageous than the regular pro-sumti cmavo. If no assignment can be found for a lerfu string (especially a single lerfu word), it can be assumed to refer to the most recent sumti whose name or description begins in Lojban with that lerfu. So Example 17.22 can be rephrased:
(A less literal English translation would use “D” for “dog” instead.)
Here is an example using two names and longer lerfu strings:
| la | .stivn. | .mark. | .djonz. | cu | merko |
| that-named | Steven | Mark | Jones | is-American. |
| .i | la | .aleksandr. | .pavlovitc. | .kuznietsof. | cu | rusko |
| that-named | Alexander | Pavlovich | Kuznetsov | is-Russian. |
| .i | symydy. | tavla | .abupyky. | bau | la | .lojban. |
| SMD | talks-to | APK | in | that-named | Lojban. |
Perhaps Alexander's name should be given as ru'o.abupyky instead.
Does this mean that A gives B to C? No. by. cy. is a single lerfu string, although written as two words, and represents a single pro-sumti. The true interpretation is that A gives BC to someone unspecified. To solve this problem, we need to introduce the elidable terminator boi (of selma'o BOI). This cmavo is used to terminate lerfu strings and also strings of numerals; it is required when two of these appear in a row, as here. (The other reason to use boi is to attach a free modifier – subscript, parenthesis, or what have you – to a lerfu string.) The correct version is:
where the two occurrences of boi in brackets are elidable, but the remaining occurrence is not. Likewise:
requires the first boi to separate the lerfu string xy. from the digit string ro.
The rules of Section 17.9 make it impossible to use unmarked lerfu words to refer to lerfu themselves. In the sentence:
the hearer would try to find what previous sumti .abu refers to. The solution to this problem makes use of the cmavo me'o of selma'o LI, which makes a lerfu string into a sumti representing that very string of lerfu. This use of me'o is a special case of its mathematical use, which is to introduce a mathematical expression used literally rather than for its value.
Now we can translate Example 17.1 into Lojban:
| dei | vasru | vo | lerfu | po'u | me'o | .ebu |
| this-sentence | contains | four | letterals | which-are | the-expression | “e” |
|
This sentence contains four “e” s. |
Since the Lojban sentence has only four e lerfu rather than fourteen, the translation is not a literal one – but Example 17.30 is a Lojban truth just as Example 17.1 is an English truth. Coincidentally, the colloquial English translation of Example 17.30 is also true!
The reader might be tempted to use quotation with lu … li'u instead of me'o , producing:
(The single-word quote zo cannot be used, because .abu is a compound cmavo.) But Example 17.31 is false, because it says:
which is not the case; rather, the thing symbolized by the word .abu is a letteral. In Lojban, that would be:
which is correct.
This chapter is not about Lojban mathematics, which is explained in Chapter 18 , so the mathematical uses of lerfu strings will be listed and exemplified but not explained.
-
A lerfu string as function name (preceded by ma'o of selma'o MAhO):
Note the boi here to separate the lerfu strings fy. and xy..
| le | vi | ratcu | cu | ny.moi | le'i | mi | ratcu |
| the | here | rat | is-nth-of | the-set-of | my | rats |
|
This rat is my Nth rat. |
-
A lerfu string as subscript (preceded by xi of selma'o XI):
The parentheses are required because ny. lo prenu would be two separate sumti, ny. and lo prenu. In general, any mathematical expression other than a simple number must be in parentheses when used as a quantifier; the right parenthesis mark, the cmavo ve'o , can usually be elided.
All the examples above have exhibited single lerfu words rather than lerfu strings, in accordance with the conventions of ordinary mathematics. A longer lerfu string would still be treated as a single variable or function name: in Lojban, .abu by. cy. is not the multiplication “a × b × c” but is the variable abc. (Of course, a local convention could be employed that made the value of a variable like abc , with a multi-lerfu-word name, equal to the values of the variables a , b , and c multiplied together.)
There is a special rule about shift words in mathematical text: shifts within mathematical expressions do not affect lerfu words appearing outside mathematical expressions, and vice versa.
An acronym is a name constructed of lerfu. English examples are “DNA” , “NATO” , “CIA”. In English, some of these are spelled out (like “DNA” and “CIA”) and others are pronounced more or less as if they were ordinary English words (like “NATO”). Some acronyms fluctuate between the two pronunciations: “SQL” may be “ess cue ell” or “sequel”.
In Lojban, a name is often represented by one cmevla (a word that ends in a consonant and is surrounded by pauses). The easiest way to Lojbanize acronym names is to glue the lerfu words together, using ' wherever two vowels would come together (pauses are illegal in cmevla) and adding a final consonant:
|
la .dyny'abub. .i la .ny'abuty'obub. .i la .cy'ibu'abub. |
|
DNA. NATO. CIA. |
|
… .i la .sykybulyl. .i la .ibubymym. .i la .ny'ybucyc. |
|
… SQL. IBM. NYC. |
There is no fixed convention for assigning the final consonant. In Example 17.40 , the last consonant of the lerfu string has been replicated into final position.
Some compression can be done by leaving out bu after vowel lerfu words (except for .ybu , wherein the bu cannot be omitted without ambiguity). Compression is moderately important because it's hard to say long cmevla without introducing an involuntary (and illegal) pause:
|
la .dyny'am. .i la .ny'aty'om. .i la .cy'i'am. |
|
DNA. NATO. CIA. |
|
… .i la .sykybulym. .i la .ibymym. .i la .ny'ybucym. |
|
… SQL. IBM. NYC. |
In Example 17.41 , the final consonant m stands for merko , indicating the source culture of these acronyms.
Another approach, which some may find easier to say and which is compatible with older versions of the language that did not have a ' character, is to use the consonant z instead of ' :
|
la .dynyzaz. .i la .nyzatyzoz. .i la .cyzizaz. |
|
DNA. NATO. CIA. |
|
… .i la .sykybulyz. .i la .ibymyz. .i la .nyzybucyz. |
|
… SQL. IBM. NYC. |
One more alternative to these lengthy cmevla is to use the lerfu string itself prefixed with me , the cmavo that makes sumti into selbri:
This works because la , the cmavo that normally introduces cmevla used as sumti, may also be used before a predicate to indicate that the predicate is a (meaningful) name:
Example 17.44 does not of course refer to a bear ( le cribe or lo cribe) but to something else, probably a person, named “Bear”. Similarly, me dy ny. .abu is a predicate which can be used as a name, producing a kind of acronym which can have pauses between the individual lerfu words.
Since the first application of computers to non-numerical information, character sets have existed, mapping numbers (called “character codes”) into selected lerfu, digits, and punctuation marks (collectively called “characters”). Historically, each of these character sets has only covered a particular writing system. International efforts have now created Unicode, a unified character set that can represent essentially all the characters in essentially all the world's writing systems. Lojban can take advantage of these encoding schemes by using the cmavo se'e (of selma'o BY). This cmavo is conventionally followed by digit cmavo of selma'o PA representing the character code, and the whole string indicates a single character in some computerized character set:
| me'o | se'e | cixa | cu | lerfu | la | .asycy'i'is. |
| The-expression | [code] | 36 | is-a-letteral-in-set | ASCII |
| loi | rupnu | be | fi | le | merko |
| for-the-mass-of | currency-units | in | the | American-system. |
|
The character code 36 in ASCII represents American dollars. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
“$” represents American dollars. |
Understanding Example 17.45 depends on knowing the value in the ASCII character set (one of the simplest and oldest) of the “$” character. Therefore, the se'e convention is only intelligible to those who know the underlying character set. For precisely specifying a particular character, however, it has the advantages of unambiguity and (relative) cultural neutrality, and therefore Lojban provides a means for those with access to descriptions of such character sets to take advantage of them.
As another example, the Unicode character set (also known as ISO 10646) represents the international symbol of peace, an inverted trident in a circle, using the base-16 value 262E. In a suitable context, a Lojbanist may say:
| me'o | se'e | rexarerei | sinxa | le | ka | panpi |
| the-expression | [code] | 262E | is-a-sign-of | the | quality-of | being-at-peace |
When a se'e string appears in running discourse, some metalinguistic convention must specify whether the number is base 10 or some other base, and which character set is in use.
|
bu |
BU |
makes previous word into a lerfu word |
|
ga'e |
BY |
upper case shift |
|
to'a |
BY |
lower case shift |
|
tau |
LAU |
case-shift next lerfu word only |
|
lo'a |
BY |
Latin/Lojban alphabet shift |
|
ge'o |
BY |
Greek alphabet shift |
|
je'o |
BY |
Hebrew alphabet shift |
|
jo'o |
BY |
Arabic alphabet shift |
|
ru'o |
BY |
Cyrillic alphabet shift |
|
se'e |
BY |
following digits are a character code |
|
na'a |
BY |
cancel all shifts |
|
zai |
LAU |
following lerfu word specifies alphabet |
|
ce'a |
LAU |
following lerfu word specifies font |
|
lau |
LAU |
following lerfu word is punctuation |
|
tei |
TEI |
start compound lerfu word |
|
foi |
FOI |
end compound lerfu word |
Note that LAU cmavo must be followed by a BY cmavo or the equivalent, where “equivalent” means: either any Lojban word followed by bu , another LAU cmavo (and its required sequel), or a tei … foi compound cmavo.
The following sections contain tables of proposed lerfu words for some of the standard alphabets supported by the Lojban lerfu system. The first column of each list is the lerfu (actually, a Latin-alphabet name sufficient to identify it). The second column is the proposed name-based lerfu word, and the third column is the proposed lerfu word in the system based on using the cmavo of selma'o BY with a shift word.
These tables are not meant to be authoritative (several authorities within the Lojban community have niggled over them extensively, disagreeing with each other and sometimes with themselves). They provide a working basis until actual usage is available, rather than a final resolution of lerfu word problems. Probably the system presented here will evolve somewhat before settling down into a final, conventional form.
For Latin-alphabet lerfu words, see Section 17.2 (for Lojban) and Section 17.5 (for non-Lojban Latin-alphabet lerfu).
| α | .alfas. bu | .abu |
| β | .betas. bu | by. |
| γ | .gamas. bu | gy. |
| δ | .deltas. bu | dy. |
| ε | .Epsilon. bu | .ebu |
| ζ | .zetas. bu | zy. |
| η | .etas. bu | .e'ebu |
| θ | .tetas. bu | ty. bu |
| ι | .iotas. bu | .ibu |
| κ | .kapas. bu | ky. |
| λ | .lymdas. bu | ly. |
| μ | .mus. bu | my. |
| ν | .nus. bu | ny. |
| ξ | .ksis. bu | .ksis. bu |
| ο | .Omikron. bu | .obu |
| π | .pis. bu | py. |
| ρ | .ros. bu | ry. |
| σ | .sigmas. bu | sy. |
| τ | .taus. bu | ty. |
| υ | .Upsilon. bu | .ubu |
| φ | .fis. bu | py. bu |
| χ | .xis. bu | ky. bu |
| ψ | .psis. bu | .psis. bu |
| ω | .omegas. bu | .o'obu |
| rough breathing | .dasei,as. bu | .y'y. |
| smooth breathing | .psiles. bu | xutla bu |
The second column in this listing is based on the historical names of the letters in Old Church Slavonic. Only those letters used in Russian are shown; other languages require more letters which can be devised as needed.
| а | .azys. bu | .abu |
| б | .bukys. bu | by. |
| в | .vedis. bu | vy. |
| г | .glagolis. bu | gy. |
| д | .dobros. bu | dy. |
| е | .iestys. bu | .ebu |
| ж | .jivet. bu | jy. |
| з | .zemlias. bu | zy. |
| и | .ije,is. bu | .ibu |
| й | .itord. bu | .itord. bu |
| к | .kakos. bu | ky. |
| л | .liudi,ies. bu | ly. |
| м | .myslites. bu | my. |
| н | .naciys. bu | ny. |
| о | .onys. bu | .obu |
| п | .pokois. bu | py. |
| р | .riytsis. bu | ry. |
| с | .slovos. bu | sy. |
| т | .tyvriydos. bu | ty. |
| у | .ukys. bu | .ubu |
| ф | .friytys. bu | fy. |
| х | .xerys. bu | xy. |
| ц | .tsis. bu | .tsys. bu |
| ч | .tcriyviys. bu | .tcys. bu |
| ш | .cas. bu | cy. |
| щ | .ctas. bu | .ctcys. bu |
| ъ | .ier. bu | jdari bu |
| ы | .ierys. bu | .ybu |
| ь | .ieriys. bu | ranti bu |
| э | .ecarn. bu | .ecarn. bu |
| ю | .ius. bu | .iubu |
| я | .ias. bu | .iabu |
| א | .alef. bu | .alef. bu |
| ב | .bet. bu | by. |
| ג | .gimel. bu | gy. |
| ד | .daled. bu | dy. |
| ה | .xex. bu | .y'y. |
| ו | .vav. bu | vy. |
| ז | .zai,in. bu | zy. |
| ח | .xet. bu | xy. bu |
| ט | .tet. bu | ty. bu |
| י | .iud. bu | .iud. bu |
| כ | .kaf. bu | ky. |
| ל | .LYmed. bu | ly. |
| מ | .mem. bu | my. |
| נ | .nun. bu | ny. |
| ס | .samex. bu | .samex. bu |
| ע | .ai,in. bu | .ai,in bu |
| פ | .pex. bu | py. |
| צ | .tsadik. bu | .tsadik. bu |
| ק | .kuf. bu | ky. bu |
| ר | .rec. bu | ry. |
| ש | .cin. bu | cy. |
| ת | .taf. bu | ty. |
| dagesh | .daGEC. bu | .daGEC. bu |
| hiriq | .xirik. bu | .ibu |
| tsere | .tseirex. bu | .eibu |
| segol | .seGOL. bu | .ebu |
| kubutz | .kubuts. bu | .ubu |
| kamatz | .kamats. bu | .abu |
| patach | .patax. bu | .a'abu |
| shva | .cyVAS. bu | .ybu |
| holam | .xolem. bu | .obu |
| shuruk | .curuk. bu | .u'ubu |
This list is intended to be suggestive, not complete: there are lerfu such as Polish “ł” and Maltese “ħ” that do not yet have symbols.
| acute (as in “á”) | .akut. bu or .pritygal. bu [ pritu galtu ] |
| grave (as in “à”) | .grav. bu or .zulgal. bu [ zunle galtu ] |
| circumflex (as in “â”) | .cirkumfleks. bu or .midgal. bu [ midju galtu ] |
| tilde ( “~”) | .tildes. bu |
| macron (as in “ā”) | .makron. bu |
| breve (as in “ă”) | .brevis. bu |
| over-dot (as in “ȧ”) | .gapmoc. bu [ gapru mokca ] |
| diaeresis/umlaut/tréma (as in “ä”) | .relmoc. bu [ re mokca ] |
| overring (as in “å”) | .gapyjin. bu [ gapru djine ] |
| cedilla (as in “ç”) | .seDIlys. bu |
| double acute (as in “a̋”) | .re'akut. bu [re .akut.] |
| ogonek (as in “ą”) | .ogonek. bu |
| caron, háček (as in “ǎ”) | .xatcek. bu |
| ligatured fi | tei fy. ibu foi |
| Danish/Latin æ | tei .abu .ebu foi |
| Dutch ij | tei .ibu jy. foi |
| German ß, Eszett | tei sy. zy. foi |
There is a set of English words which are used, by international agreement, as lerfu words (for the English alphabet) over the radio, or in noisy situations where the utmost clarity is required. Formally they are known as the “ICAO Phonetic Alphabet” , and are used even in non-English-speaking countries.
This table presents the standard English spellings and proposed Lojban versions. The Lojbanizations are not straightforward renderings of the English sounds, but make some concessions both to the English spellings of the words and to the Lojban pronunciations of the lerfu (thus .carlis. bu , not .tcarlis. bu).
| Alfa | |
| Bravo | |
| Charlie | |
| Delta | |
| Echo | |
| Foxtrot | |
| Golf | |
| Hotel | |
| India | |
| Juliet | |
| Kilo | |
| Lima | |
| Mike | |
| November | |
| Oscar | |
| Papa | |
| Quebec | |
| Romeo | |
| Sierra | |
| Tango | |
| Uniform | |
| Victor | |
| Whiskey | |
| X-ray | |
| Yankee | |
| Zulu |
lojbau mekso ( “Lojbanic mathematical-expression”) is the part of the Lojban language that is tailored for expressing statements of a mathematical character, or for adding numerical information to non-mathematical statements. Its formal design goals include:
-
representing all the different forms of expression used by mathematicians in their normal modes of writing, so that a reader can unambiguously read off mathematical text as written with minimal effort and expect a listener to understand it;
-
providing a vocabulary of commonly used mathematical terms which can readily be expanded to include newly coined words using the full resources of Lojban;
-
permitting the formulation, both in writing and in speech, of unambiguous mathematical text;
-
encompassing all forms of quantified expression found in natural languages, as well as encouraging greater precision in ordinary language situations than natural languages allow.
Goal 1 requires that mekso not be constrained to a single notation such as Polish notation or reverse Polish notation, but make provision for all forms, with the most commonly used forms the most easily used.
Goal 2 requires the provision of several conversion mechanisms, so that the boundary between mekso and full Lojban can be crossed from either side at many points.
Goal 3 is the most subtle. Written mathematical expression is culturally unambiguous, in the sense that mathematicians in all parts of the world understand the same written texts to have the same meanings. However, international mathematical notation does not prescribe unique forms. For example, the expression
contains omitted multiplication operators, but there are other possible interpretations for the strings and than as mathematical multiplication. Therefore, the Lojban verbal (spoken and written) form of Example 18.1 must not omit the multiplication operators.
The remainder of this chapter explains (in as much detail as is currently possible) the mekso system. This chapter is by intention complete as regards mekso components, but only suggestive about uses of those components – as of now, there has been no really comprehensive use made of mekso facilities, and many matters must await the test of usage to be fully clarified.
The following cmavo are discussed in this section:
|
|
The simplest kind of mekso are numbers, which are cmavo or compound cmavo. There are cmavo for each of the 10 decimal digits, and numbers greater than 9 are made by stringing together the cmavo. Some examples:
| pa | re | ci | vo | mu | xa | ze | bi | so | no | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| one | two | three | four | five | six | seven | eight | nine | zero | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
1234567890
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
one billion, two hundred and thirty-four million, five hundred and sixty-seven thousand, eight hundred and ninety. |
Therefore, there are no separate cmavo for “ten” , “hundred” , etc.
There is a pattern to the digit cmavo (except for no , 0) which is worth explaining. The cmavo from 1 to 5 end in the vowels a , e , i , o , u respectively; and the cmavo from 6 to 9 likewise end in the vowels a , e , i , and o respectively. None of the digit cmavo begin with the same consonant, to make them easy to tell apart in noisy environments.
The following cmavo are discussed in this section:
|
ma'u |
PA |
positive sign |
|
ni'u |
PA |
negative sign |
|
pi |
PA |
decimal point |
|
fi'u |
PA |
fraction slash |
|
ra'e |
PA |
repeating decimal |
|
ce'i |
PA |
percent sign |
|
ki'o |
PA |
comma between digits |
A number can be given an explicit sign by the use of ma'u and ni'u , which are the positive and negative signs as distinct from the addition, subtraction, and negation operators. For example:
Grammatically, the signs are part of the number to which they are attached. It is also possible to use ma'u and ni'u by themselves as numbers; the meaning of these numbers is explained in Section 18.8.
Various numerical punctuation marks are likewise expressed by cmavo, as illustrated in the following examples:
(In some cultures, a comma is used instead of a period in the symbolic version of Example 18.6 ; pi is still the Lojban representation for the decimal point.)
Example 18.7 is the name of the number two-sevenths; it is not the same as “the result of 2 divided by 7” in Lojban, although numerically these two are equal. If the denominator of the fraction is present but the numerator is not, the numerator is taken to be 1, thus expressing the reciprocal of the following number:
| pi | ci | mu | ra'e | pa | vo | re | bi | mu | ze | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| point | three | five | repeating | one | four | two | eight | five | seven | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
.35142857142857...
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Note that the ra'e marks unambiguously where the repeating portion “142857” begins.
(In some cultures, spaces are used in the symbolic representation of Example 18.11 ; ki'o is still the Lojban representation.)
It is also possible to have less than three digits between successive ki'o s, in which case zeros are assumed to have been elided:
In the same way, ki'o can be used after pi to divide fractions into groups of three:
The following cmavo are discussed in this section:
|
ci'i |
PA |
infinity, ∞ |
|
ka'o |
PA |
imaginary i , √-1 |
|
pai |
PA |
π, pi (approx 3.14159...) |
|
te'o |
PA |
exponential e (approx 2.71828...) |
|
fi'u |
PA |
golden ratio, φ , phi, (1 + √5) / 2 (approx. 1.61803...) |
The last cmavo is the same as the fraction sign cmavo: a fraction sign with neither numerator nor denominator represents the golden ratio.
Numbers can have any of these digit, punctuation, and special-number cmavo of Sections 2, 3, and 4 in any combination:
Note that ka'o is both a special number (meaning “i”) and a number punctuation mark (separating the real and the imaginary parts of a complex number).
The special numbers pai and te'o are mathematically important, which is why they are given their own cmavo:
However, many combinations are as yet undefined:
Example 18.21 is not “1 minus 2” , which is represented by a different cmavo sequence altogether. It is a single number which has not been assigned a meaning. There are many such numbers which have no well-defined meaning; they may be used for experimental purposes or for future expansion of the Lojban number system.
It is possible, of course, that some of these “oddities” do have a meaningful use in some restricted area of mathematics. A mathematician appropriating these structures for specialized use needs to consider whether some other branch of mathematics would use the structure differently.
More information on numbers may be found in Section 18.8 to Section 18.12.
The following cmavo are discussed in this section:
|
du |
GOhA |
equals |
|
su'i |
VUhU |
plus |
|
vu'u |
VUhU |
minus |
|
pi'i |
VUhU |
times |
|
te'a |
VUhU |
raised to the power |
|
ny. |
BY |
letter “n” |
|
vei |
VEI |
left parenthesis |
|
ve'o |
VEhO |
right parenthesis |
Let us begin at the beginning: one plus one equals two. In Lojban, that sentence translates to:
Example 18.22 , a mekso sentence, is a regular Lojban bridi that exploits mekso features. du is the predicate meaning “x1 is mathematically equal to x2”. It is a cmavo for conciseness, but it has the same grammatical uses as any brivla. Outside mathematical contexts, du means “x1 is identical with x2” or “x1 is the same object as x2”.
The cmavo li is the number article. It is required whenever a sentence talks about numbers as numbers, as opposed to using numbers to quantify things. For example:
requires no li article, because the ci is being used to specify the number of prenu. However, the sentence
| levi | sfani | cu | grake | li | ci |
| This | fly | masses-in-grams | the-number | three. |
|
This fly has a mass of 3 grams. |
requires li because ci is being used as a sumti. Note that this is the way in which measurements are stated in Lojban: all the predicates for units of length, mass, temperature, and so on have the measured object as the first place and a number as the second place. Using li for le in Example 18.23 would produce
which is grammatical but nonsensical: numbers are not persons.
The cmavo su'i belongs to selma'o VUhU, which is composed of mathematical operators, and means “addition”. As mentioned before, it is distinct from ma'u which means the positive sign as an indication of a positive number:
| li | ma'u | pa | su'i |
| The-number | positive-sign | one | plus |
| ni'u | pa | du | li | no | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| negative-sign | one | equals | the-number | zero. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
+1 + -1 = 0
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Of course, it is legal to have complex mekso on both sides of du :
| li | mu | su'i | pa | du | li | ci | su'i | ci | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| The-number | five | plus | one | equals | the-number | three | plus | three. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
5 + 1 = 3 + 3
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Why don't we say li mu su'i li pa rather than just li mu su'i pa ? The answer is that VUhU operators connect mekso operands (numbers, in Example 18.27), not general sumti. li is used to make the entire mekso into a sumti, which then plays the roles applicable to other sumti: in Example 18.27 , filling the places of a bridi
By default, Lojban mathematics is like simple calculator mathematics: there is no notion of “operator precedence”. Consider the following example, where pi'i means “times” , the multiplication operator:
| li | ci | su'i | vo | pi'i | mu | du | li | reci | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| The-number | three | plus | four | times | five | equals | the-number | two-three. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
3 + 4 × 5 = 23
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Is the Lojban version of Example 18.28 true? No! “3 + 4 × 5” is indeed 23, because the usual conventions of mathematics state that multiplication takes precedence over addition; that is, the multiplication “4 × 5” is done first, giving 20, and only then the addition “3 + 20”. But VUhU operators by default are done left to right, like other Lojban grouping, and so a truthful bridi would be:
| li | ci | su'i | vo | pi'i | mu | du | li | cimu | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| The-number | three | plus | four | times | five | equals | the-number | three-five. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
3 + 4 × 5 = 35
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Here we calculate 3 + 4 first, giving 7, and then calculate 7 × 5 second, leading to the result 35. While possessing the advantage of simplicity, this result violates the design goal of matching the standards of mathematics. What can be done?
There are three solutions, all of which will probably be used to some degree. The first solution is to ignore the problem. People will say li ci su'i vo pi'i mu and mean 23 by it, because the notion that multiplication takes precedence over addition is too deeply ingrained to be eradicated by Lojban parsing, which totally ignores semantics. This convention essentially allows semantics to dominate syntax in this one area.
(Why not hard-wire the precedences into the grammar, as is done in computer programming languages? Essentially because there are too many operators, known and unknown, with levels of precedence that vary according to usage. The programming language 'C' has 13 levels of precedence, and its list of operators is not even extensible. For Lojban this approach is just not practical. In addition, hard-wired precedence could not be overridden in mathematical systems such as spreadsheets where the conventions are different.)
The second solution is to use explicit means to specify the precedence of operators. This approach is fully general, but clumsy, and will be explained in Section 18.20.
The third solution is simple but not very general. When an operator is prefixed with the cmavo bi'e (of selma'o BIhE), it becomes automatically of higher precedence than other operators not so prefixed. Thus,
| li | ci | su'i | vo | bi'e | pi'i | mu | du | li | reci | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| The-number | three | plus | four | times | five | equals | the-number | two-three. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
3 + 4 × 5 = 23
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
is a truthful Lojban bridi. If more than one operator has a bi'e prefix, grouping is from the right; multiple bi'e prefixes on a single operator are not allowed.
In addition, of course, Lojban has the mathematical parentheses vei and ve'o , which can be used just like their written equivalents “(” and “)” to group expressions in any way desired:
| li | vei | ny. | su'i | pa | ve'o | pi'i | vei | ny. | su'i | pa | [ve'o] |
| The-number | ( | n | plus | one | ) | times | ( | n | plus | one | ) |
| du | li | ny. | [bi'e] | te'a | re |
| equals | the-number | n | to-the-power | two |
| su'i | re | bi'e | pi'i | ny. | su'i | pa | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| plus | two | times | n | plus | 1. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
(n+1)(n+1) = n
2
+ 2n + 1
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
There are several new usages in Example 18.31 : te'a means “raised to the power” , and we also see the use of the lerfu word ny. , representing the letter “n”. In mekso, letters stand for just what they do in ordinary mathematics: variables. The parser will accept a string of lerfu words (called a “lerfu string”) as the equivalent of a single lerfu word, in agreement with computer-science conventions; “abc” is a single variable, not the equivalent of “a × b × c”. (Of course, a local convention could state that the value of a variable like “abc” , with a multi-lerfu name, was equal to the values of the variables “a” , “b” , and “c” multiplied together.)
The explicit operator pi'i is required in the Lojban verbal form whereas multiplication is implicit in the symbolic form. Note that ve'o (the right parenthesis) is an elidable terminator: the first use of it in Example 18.31 is required, but the second use (marked by square brackets) could be elided. Additionally, the first bi'e (also marked by square brackets) is not necessary to get the proper grouping, but it is included here for symmetry with the other one.
The following cmavo are discussed in this section:
|
boi |
BOI |
numeral/lerfu string terminator |
|
va'a |
VUhU |
negation/additive inverse |
|
pe'o |
PEhO |
forethought flag |
|
ku'e |
KUhE |
forethought terminator |
|
ma'o |
MAhO |
convert operand to operator |
|
py. |
BY |
letter “p” |
|
xy. |
BY |
letter “x” |
|
zy. |
BY |
letter “z” |
|
fy. |
BY |
letter “f” |
The infix form explained so far is reasonable for many purposes, but it is limited and rigid. It works smoothly only where all operators have exactly two operands, and where precedences can either be assumed from context or are limited to just two levels, with some help from parentheses.
But there are many operators which do not have two operands, or which have a variable number of operands. The preferred form of expression in such cases is the use of “forethought operators” , also known as Polish notation. In this style of writing mathematics, the operator comes first and the operands afterwards:
| li | su'i | paboi | reboi | ci[boi] | du | li | xa | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| The-number | the-sum-of | one | two | three | equals | the-number | six. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
sum(1,2,3) = 6
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Note that the normally elidable number terminator boi is required after pa and re because otherwise the reading would be pareci = 123. It is not required after ci but is inserted here in brackets for the sake of symmetry. The only time boi is required is, as in Example 18.32 , when there are two consecutive numbers or lerfu strings.
Forethought mekso can use any number of operands, in Example 18.32 , three. How do we know how many operands there are in ambiguous circumstances? The usual Lojban solution is employed: an elidable terminator, namely ku'e. Here is an example:
| li | py. | su'i | va'a | ny. | ku'e | su'i | zy | du |
| The-number | “p” | plus | negative-of( | “n” | ) | plus | “z” | equals |
| li | xy. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| the-number | “x” | . | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
p + -n + z = x
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
where we know that va'a is a forethought operator because there is no operand preceding it.
va'a is the numerical negation operator, of selma'o VUhU. In contrast, vu'u is not used for numerical negation, but only for subtraction, as it always has two or more operands. Do not confuse va'a and vu'u , which are operators, with ni'u , which is part of a number.
In Example 18.33 , the operator va'a and the terminator ku'e serve in effect as parentheses. (The regular parentheses vei and ve'o are NOT used for this purpose.) If the ku'e were omitted, the su'i zy would be swallowed up by the va'a forethought operator, which would then appear to have two operands, ny. and su'i zy. , where the latter is also a forethought expression.
Forethought mekso is also useful for matching standard functional notation. How do we represent “z = f(x)” ? The answer is:
Again, no parentheses are used. The construct ma'o fy.boi is the equivalent of an operator, and appears in forethought here (although it could also be used as a regular infix operator). In mathematics, letters sometimes mean functions and sometimes mean variables, with only the context to tell which. Lojban chooses to accept the variable interpretation as the default, and uses the special flag ma'o to mark a lerfu string as an operator. The cmavo xy. and zy. are variables, but fy. is an operator (a function) because ma'o marks it as such. The boi is required because otherwise the xy. would look like part of the operator name. (The use of ma'o can be generalized from lerfu strings to any mekso operand: see Section 18.21.)
When using forethought mekso, the optional marker pe'o may be placed in front of the operator. This usage can help avoid confusion by providing clearly marked pe'o and ku'e pairs to delimit the operand list. Example 18.32 to Example 18.34 , respectively, with explicit pe'o and ku'e :
Note: When using forethought mekso, be sure that the operands really are operands: they cannot contain regular infix expressions unless parenthesized with vei and ve'o. An earlier version of the complex Example 18.119 came to grief because I forgot this rule.
So far our examples have been isolated mekso (it is legal to have a bare mekso as a sentence in Lojban) and equation bridi involving du. What about inequalities such as “x < 5” ? The answer is to use a bridi with an appropriate selbri, thus:
Here is a partial list of selbri useful in mathematical bridi:
| du | x1 is identical to x2, x3, x4, ... |
| dunli | x1 is equal/congruent to x2 in/on property/quality/dimension/quantity x3 |
| mleca | x1 is less than x2 |
| zmadu | x1 is greater than x2 |
| dubjavme'a | x1 is less than or equal to x2 [ du ja mleca , equal or less] |
| dubjavmau | x1 is greater than or equal to x2 [ du ja zmadu , equal or greater] |
| tamdu'i | x1 is similar to x2 [ tarmi dunli , shape-equal] |
| turdu'i | x1 is isomorphic to x2 [ stura dunli , structure-equal] |
| cmima | x1 is a member of set x2 |
| gripau | x1 is a subset of set x2 [ girzu pagbu , set-part] |
| na'ujbi | x1 is approximately equal to x2 [ namcu jibni , number-near] |
| terci'e | x1 is a component with function x2 of system x3 |
Note the difference between dunli and du ; dunli has a third place that specifies the kind of equality that is meant. du refers to actual identity, and can have any number of places:
Lojban bridi can have only one predicate, so the du is not repeated.
Any of these selbri may usefully be prefixed with na , the contradictory negation cmavo, to indicate that the relation is false:
As usual in Lojban, negated bridi say what is false, and do not say anything about what might be true.
The following cmavo are discussed in this section:
|
ro |
PA |
all |
|
so'a |
PA |
almost all |
|
so'e |
PA |
most |
|
so'i |
PA |
many |
|
so'o |
PA |
several |
|
so'u |
PA |
a few |
|
no'o |
PA |
the typical number of |
|
da'a |
PA |
all but (one) of |
|
piro |
PA+PA |
the whole of/all of |
|
piso'a |
PA+PA |
almost the whole of |
|
piso'e |
PA+PA |
most of |
|
piso'i |
PA+PA |
much of |
|
piso'o |
PA+PA |
a small part of |
|
piso'u |
PA+PA |
a tiny part of |
|
pino'o |
PA+PA |
the typical portion of |
|
rau |
PA |
enough |
|
du'e |
PA |
too many |
|
mo'a |
PA |
too few |
|
pirau |
PA+PA |
enough of |
|
pidu'e |
PA+PA |
too much of |
|
pimo'a |
PA+PA |
too little of |
Not all the cmavo of PA represent numbers in the usual mathematical sense. For example, the cmavo ro means “all” or “each”. This number does not have a definite value in the abstract: li ro is undefined. But when used to count or quantify something, the parallel between ro and pa is clearer:
Example 18.41 might be true, whereas Example 18.42 is almost certainly false.
The cmavo so'a , so'e , so'i , so'o , and so'u represent a set of indefinite numbers less than ro. As you go down an alphabetical list, the magnitude decreases:
The English equivalents are only rough: the cmavo provide space for up to five indefinite numbers between ro and no , with a built-in ordering. In particular, so'e does not mean “most” in the sense of “a majority” or “more than half”.
Each of these numbers, plus ro , may be prefixed with pi (the decimal point) in order to make a fractional form which represents part of a whole rather than some elements of a totality. piro therefore means “the whole of” :
Similarly, piso'a means “almost the whole of” ; and so on down to piso'u , “a tiny part of”. These numbers are particularly appropriate with masses, which are usually measured rather than counted, as Example 18.48 shows.
In addition to these cmavo, there is no'o , meaning “the typical value” , and pino'o , meaning “the typical portion” : Sometimes no'o can be translated “the average value” , but the average in question is not, in general, a mathematical mean, median, or mode; these would be more appropriately represented by operators.
da'a is a related cmavo meaning “all but” :
Example 18.52 is similar in meaning to Example 18.43.
If no number follows da'a , then pa is assumed; da'a by itself means “all but one” , or in ordinal contexts “all but the last” :
(The use of da'a means that Example 18.53 does not require that all rats can eat themselves, but does allow it. Each rat has one rat it cannot eat, but that one might be some rat other than itself. Context often dictates that “itself” is, indeed, the “other” rat.)
As mentioned in Section 18.3 , ma'u and ni'u are also legal numbers, and they mean “some positive number” and “some negative number” respectively.
All of the numbers discussed so far are objective, even if indefinite. If there are exactly six superpowers ( rairgugde , “superlative-states”) in the world, then ro rairgugde means the same as xa rairgugde. It is often useful, however, to express subjective indefinite values. The cmavo rau (enough), du'e (too many), and mo'a (too few) are then appropriate:
Like the so'a -series, rau , du'e , and mo'a can be preceded by pi ; for example, pirau means “a sufficient part of.”
Another possibility is that of combining definite and indefinite numbers into a single number. This usage implies that the two kinds of numbers have the same value in the given context:
| mi | speni | so'ici | prenu |
| I | am-married-to | many/three | persons. |
|
I am married to three persons (which is “many” in the circumstances). |
Example 18.59 assumes a mostly monogamous culture by stating that three is “many”.
The following cmavo are discussed in this section:
|
ji'i |
PA |
approximately |
|
su'e |
PA |
at most |
|
su'o |
PA |
at least |
|
me'i |
PA |
less than |
|
za'u |
PA |
more than |
The cmavo ji'i (of selma'o PA) is used in several ways to indicate approximate or rounded numbers. If it appears at the beginning of a number, the whole number is approximate:
If ji'i appears in the middle of a number, all the digits following it are approximate:
| vo | no | ji'i | mu | no |
| four | zero | approximation | five | zero |
|
roughly 4050 (where the “four thousand” is exact, but the “fifty” is approximate) |
If ji'i appears at the end of a number, it indicates that the number has been rounded. In addition, it can then be followed by a sign cmavo ( ma'u or ni'u), which indicate truncation towards positive or negative infinity respectively.
Example 18.62 through Example 18.64 are all approximations to te'o (exponential e). ji'i can also appear by itself, in which case it means “approximately the typical value in this context”.
The four cmavo su'e , su'o , me'i , and za'u , also of selma'o PA, express inexact numbers with upper or lower bounds:
Each of these is a subtly different claim: Example 18.66 is true of two or any greater number, whereas Example 18.68 requires three persons or more. Likewise, Example 18.65 refers to zero, one, or two; Example 18.67 to zero or one. (Of course, when the context allows numbers other than non-negative integers, me'i re can be any number less than 2, and likewise with the other cases.) The exact quantifier, “exactly 2, neither more nor less” is just re. Note that su'ore is the exact Lojban equivalent of English plurals.
If no number follows one of these cmavo, pa is understood: therefore,
is a meaningful claim.
Like the numbers in Section 18.8 , all of these cmavo may be preceded by pi to make the corresponding quantifiers for part of a whole. For example, pisu'o means “at least some part of”. The quantifiers ro , su'o , piro , and pisu'o are particularly important in Lojban, as they are implicitly used in the descriptions introduced by the cmavo of selma'o LA and LE, as explained in Section 6.7. Descriptions in general are outside the scope of this chapter.
The following cmavo are discussed in this section:
|
ju'u |
VUhU |
to the base |
|
dau |
PA |
hex digit A = 10 |
|
fei |
PA |
hex digit B = 11 |
|
gai |
PA |
hex digit C = 12 |
|
jau |
PA |
hex digit D = 13 |
|
rei |
PA |
hex digit E = 14 |
|
vai |
PA |
hex digit F = 15 |
|
pi'e |
PA |
compound base point |
In normal contexts, Lojban assumes that all numbers are expressed in the decimal (base 10) system. However, other bases are possible, and may be appropriate in particular circumstances.
To specify a number in a particular base, the VUhU operator ju'u is suitable:
Here, the final pa no is assumed to be base 10, as usual; so is the base specification. (The base may also be changed permanently by a metalinguistic specification; no standard way of doing so has as yet been worked out.)
Lojban has digits for representing bases up to 16, because 16 is a base often used in computer applications. In English, it is customary to use the letters A-F as the base 16 digits equivalent to the numbers ten through fifteen. In Lojban, this ambiguity is avoided:
Note the pattern in the cmavo: the diphthongs .au , .ei , .ai are used twice in the same order. The digits for A to D use consonants different from those used in the decimal digit cmavo; E and F unfortunately overlap 2 and 4 – there was simply not enough available cmavo space to make a full differentiation possible. The cmavo are also in alphabetical order.
The base point pi is used in non-decimal bases just as in base 10:
Since ju'u is an operator of selma'o VUhU, it is grammatical to use any operand as the left argument. Semantically, however, it is undefined to use anything but a numeral string on the left. The reason for making ju'u an operator is to allow reference to a base which is not a constant.
There are some numerical values that require a “base” that varies from digit to digit. For example, times represented in hours, minutes, and seconds have, in effect, three “digits” : the first is base 24, the second and third are base 60. To express such numbers, the compound base separator pi'e is used:
Each digit sequence separated by instances of pi'e is expressed in decimal notation, but the number as a whole is not decimal and can only be added and subtracted by special rules:
| li | ci | pi'e | rere | pi'e | vono | su'i | pi'e | ci | pi'e | cici |
| The-number | 3 | : | 22 | : | 40 | plus | : | 3 | : | 33 |
| du | li | ci | pi'e | rexa | pi'e | paci | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| equals | the-number | 3 | : | 26 | : | 13. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
3:22:40 + 0:3:33 = 3:26:13
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Of course, only context tells you that the first part of the numbers in Example 18.74 and Example 18.75 is hours, the second minutes, and the third seconds.
The same mechanism using pi'e can be used to express numbers which have a base larger than 16. For example, base-20 Mayan mathematics might use digits from no to paso , each separated by pi'e :
Carefully note the difference between:
which is equal to ten, and:
which is equal to twenty.
Both pi and pi'e can be used to express large-base fractions:
| li | pa | pi'e | vo | pi | ze | ju'u | reno |
| The-number | 1 | ; | 4 | . | 7 | base | 20 |
| du | li | revo | pi | cimu |
| equals | the-number | 24 | . | 35 |
pi'e is also used where the base of each digit is vague, as in the numbering of the examples in this chapter:
| dei | jufra | pabipi'ebinomoi |
| This-utterance | is-a-sentence-type-of | 18;80th-thing. |
|
This is Sentence 18.80. |
The following cmavo are discussed in this section:
|
mei |
MOI |
cardinal selbri |
|
moi |
MOI |
ordinal selbri |
|
si'e |
MOI |
portion selbri |
|
cu'o |
MOI |
probability selbri |
|
va'e |
MOI |
scale selbri |
|
me |
ME |
make sumti into selbri |
|
me'u |
MEhU |
terminator for ME |
Lojban possesses a special category of selbri which are based on mekso. The simplest kind of such selbri are made by suffixing a member of selma'o MOI to a number. There are five members of MOI, each of which serves to create number-based selbri with specific place structures.
The cmavo mei creates cardinal selbri. The basic place structure is:
x1 is a mass formed from the set x2 of n members, one or more of which is/are x3
A cardinal selbri interrelates a set with a given number of members, the mass formed from that set, and the individuals which make the set up. The mass argument is placed first as a matter of convenience, not logical necessity.
Some examples:
| lei | mi | ratcu | cu | cimei |
| Those-I-describe-as-the-mass-of | my | rats | are-a-threesome. |
|
My rats are three. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
I have three rats. |
Here, the mass of my rats is said to have three components; that is, I have three rats.
Another example, with one element this time:
In Example 18.82 , mi refers to a mass, “the mass consisting of me”. Personal pronouns are vague between masses, sets, and individuals.
However, when the number expressed before -mei is an objective indefinite number of the kind explained in Section 18.8 , a slightly different place structure is required:
x1 is a mass formed from a set x2 of n members, one or more of which is/are x3, measured relative to the set x4.
An example:
| lei | ratcu | poi | zvati | le | panka |
| The-mass-of | rats | that | are-in | the | park |
| cu | so'umei | fo | lo'i | ratcu |
| are-a-fewsome | with-respect-to | the-set-of | rats. |
|
The rats in the park are a small number of all the rats there are. |
In Example 18.83 , the x2 and x3 places are vacant, and the x4 place is filled by lo'i ratcu , which (because no quantifiers are explicitly given) means “the whole of the set of all those things which are rats” , or simply “the set of all rats.”
| le'i | ratcu | poi | zvati | le | panka | cu | se | so'imei |
| The-set-of | rats | which-are | in | the | park | is-a | manysome. |
|
There are many rats in the park. |
In Example 18.84 , the conversion cmavo se swaps the x1 and the x2 places, so that the new x1 is the set. The x4 set is unspecified, so the implication is that the rats are “many” with respect to some unspecified comparison set.
More explanations about the interrelationship of sets, masses, and individuals can be found in Section 6.3.
The cmavo moi creates ordinal selbri. The place structure is:
x1 is the (n)th member of set x2 when ordered by rule x3
Some examples:
| mi | raumoi | le | velskina | porsi |
| I | am-enough-th-in | the | movie-audience | sequence |
|
I am enough-th in the movie line. |
Example 18.87 means, in the appropriate context, that my position in line is sufficiently far to the front that I will get a seat for the movie.
The cmavo si'e creates portion selbri. The place structure is:
x1 is an (n)th portion of mass x2
Some examples:
| levi | sanmi | cu | fi'ucisi'e | lei | mi | djedi | cidja |
| This-here | meal | is-a-slash-three-portion-of | my | day | food. |
|
This meal is one-third of my daily food. |
The cmavo cu'o creates probability selbri. The place structure is:
event x1 has probability (n) of occurring under conditions x2
The number must be between 0 and 1 inclusive. For example:
| le | nu | lo | sicni | cu | sedja'o | cu | pimucu'o |
| The | event-of | a | coin | being-a-head-displayer | has-probability-.5. |
The cmavo va'e creates a scale selbri. The place structure is:
x1 is at scale position (n) on the scale x2
If the scale is granular rather than continuous, a form like cifi'uxa (3/6) may be used; in this case, 3/6 is not the same as 1/2, because the third position on a scale of six positions is not the same as the first position on a scale of two positions. Here is an example:
| levi | rozgu | cu | sofi'upanova'e | xunre |
| This-here | rose | is-9/10-scale | red. |
|
This rose is 9 out of 10 on the scale of redness. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
This rose is very red. |
When the quantifier preceding any MOI cmavo includes the subjective numbers rau , du'e , or mo'a (enough, too many, too few) then an additional place is added for “by standard”. For example:
| lei | ratcu | poi | zvati | le |
| The-mass-of | rats | which-are | in | the |
| panka | cu | du'emei | fo | mi |
| park | are-too-many | by-standard | me. |
|
There are too many rats in the park for me. |
The extra place (which for -mei is the x4 place labeled by fo) is provided rather than using a BAI tag such as ma'i because a specification of the standard for judgment is essential to the meaning of subjective words like “enough”.
This place is not normally explicit when using one of the subjective numbers directly as a number. Therefore, du'e ratcu means “too many rats” without specifying any standard.
It is also grammatical to substitute a lerfu string for a number:
More complex mekso cannot be placed directly in front of MOI, due to the resulting grammatical ambiguities. Instead, a somewhat artificial form of expression is required.
The cmavo me (of selma'o ME) has the function of making a sumti into a selbri. A whole me construction can have a member of MOI added to the end to create a complex mekso selbri:
| ta | me | li | ny. | su'i | pa | me'u | moi |
| That | is | the-number | n | plus | one | -th-of |
| le'i | mi | ratcu |
| the-set-of | associated-with-me | rats. |
|
That is my (n+1)-th rat. |
Here the mekso ny. su'i pa is made into a sumti (with li) and then changed into a mekso selbri with me and me'u moi. The elidable terminator me'u is required here in order to keep the pa and the moi separate; otherwise, the parser will combine them into the compound pamoi and reject the sentence as ungrammatical.
It is perfectly possible to use non-numerical sumti after me and before a member of MOI, producing strange results indeed:
| le | nu | mi | nolraitru | cu | me |
| The | event-of | me | being-a-nobly-superlative-ruler |
| le'e | snime | bolci | be | vi | la | .xel. | cu'o |
| has-the-stereotypical | snow | type-of-ball | at | Hell | probability. |
|
I have a snowball's chance in Hell of being king. |
Note: the elidable terminator boi is not used between a number and a member of MOI. As a result, the me'u in Example 18.93 could also be replaced by a boi , which would serve the same function of preventing the pa and moi from joining into a compound.
The following cmavo is discussed in this section:
|
xo |
PA |
number question |
The cmavo xo , a member of selma'o PA, is used to ask questions whose answers are numbers. Like most Lojban question words, it fills the blank where the answer should go. (See Section 19.5 for more on Lojban questions.)
| le | xomoi | prenu | cu | darxi | do |
| The | what-number-th | person | hit | you? |
|
Which person [as in a police lineup] hit you? |
xo can also be combined with other digits to ask questions whose answers are already partly specified. This ability could be very useful in writing tests of elementary arithmetical knowledge:
to which the correct reply would be mu , or 5. The ability to utter bare numbers as grammatical Lojban sentences is primarily intended for giving answers to xo questions. (Another use, obviously, is for counting off physical objects one by one.)
The following cmavo is discussed in this section:
|
xi |
XI |
subscript |
Subscripting is a general Lojban feature, not used only in mekso; there are many things that can logically be subscripted, and grammatically a subscript is a free modifier, usable almost anywhere. In particular, of course, mekso variables (lerfu strings) can be subscripted:
| li | xy.boixici | du | li | xy.boixipa | su'i | xy.boixire | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| The-number | x-sub-3 | equals | the-number | x-sub-1 | plus | x-sub-2. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
x
3
= x
1
+ x
2
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Subscripts always begin with the flag xi (of selma'o XI). xi may be followed by a number, a lerfu string, or a general mekso expression in parentheses:
Note that subscripts attached directly to lerfu words (variables) generally need a boi terminating the variable. Free modifiers, of which subscripts are one variety, generally require the explicit presence of an otherwise elidable terminator.
There is no standard way of handling superscripts (other than those used as exponents) or for subscripts or superscripts that come before the main expression. If necessary, further cmavo could be assigned to selma'o XI for these purposes.
The elidable terminator for a subscript is that for a general number or lerfu string, namely boi. By convention, a subscript following another subscript is taken to be a sub-subscript:
See Example 18.123 for the standard method of specifying multiple subscripts on a single object.
More information on the uses of subscripts may be found in Section 19.6.
The following cmavo are discussed in this section:
|
tu'o |
PA |
null operand |
|
ge'a |
VUhU |
null operator |
|
gei |
VUhU |
exponential notation |
The infix operators presented so far have always had exactly two operands, and for more or fewer operands forethought notation has been required. However, it is possible to use an operator in infix style even though it has more or fewer than two operands, through the use of a pair of tricks: the null operand tu'o and the null operator ge'a. The first is suitable when there are too few operands, the second when there are too many. For example, suppose we wanted to express the numerical negation operator va'a in infix form. We would use:
| li | tu'o | va'a | ny. | du | li | no | vu'u | ny. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| The-number | (null) | additive-inverse | n | equals | the-number | zero | minus | n. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
-n = 0 − n
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
The tu'o fulfills the grammatical requirement for a left operand for the infix use of va'a , even though semantically none is needed or wanted.
Finding a suitable example of ge'a requires exhibiting a ternary operator, and ternary operators are not common. The operator gei , however, has both a binary and a ternary use. As a binary operator, it provides a terse representation of scientific (also called “exponential”) notation. The first operand of gei is the exponent, and the second operand is the mantissa or fraction:
| li | cinonoki'oki'o | du |
| The-number | three-zero-zero-comma-comma | equals |
| li | bi | gei | ci | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| the-number | eight | scientific | three. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
300,000,000 = 3 × 10
8
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Why are the arguments to gei in reverse order from the conventional symbolic notation? So that gei can be used in forethought to allow easy specification of a large (or small) imprecise number:
Note, however, that although 10 is far and away the most common exponent base, it is not the only possible one. The third operand of gei , therefore, is the base, with 10 as the default value. Most computers internally store so-called “floating-point” numbers using 2 as the exponent base. (This has nothing to do with the fact that computers also represent all integers in base 2; the IBM 360 series used an exponent base of 16 for floating point, although each component of the number was expressed in base 2.) Here is a computer floating-point number with a value of 40:
| papano | bi'eju'u | re | gei |
| (one-one-zero | base | 2) | scientific |
| pipanopano | bi'eju'u | re | ge'a | re | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| (point-one-zero-one-zero | base | 2) | with-base | 2 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
.1010
2
x 2
110
2
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
The following cmavo are discussed in this section:
|
jo'i |
JOhI |
start vector |
|
te'u |
TEhU |
end vector |
|
pi'a |
VUhU |
matrix row combiner |
|
sa'i |
VUhU |
matrix column combiner |
A mathematical vector is a list of numbers, and a mathematical matrix is a table of numbers. Lojban considers matrices to be built up out of vectors, which are in turn built up out of operands.
jo'i , the only cmavo of selma'o JOhI, is the vector indicator: it has a syntax reminiscent of a forethought operator, but has very high precedence. The components must be simple operands rather than full expressions (unless parenthesized). A vector can have any number of components; te'u is the elidable terminator. An example:
| li | jo'i | paboi | reboi | te'u | su'i | jo'i | ciboi | voboi | |
| The-number | array( | one, | two | ) | plus | array( | three, | four | ) |
| du | li | jo'i | voboi | xaboi | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| equals | the-number | array( | four, | six | ). | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
(1,2) + (3,4) = (4,6)
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Vectors can be combined into matrices using either pi'a , the matrix row operator, or sa'i , the matrix column operator. The first combines vectors representing rows of the matrix, and the second combines vectors representing columns of the matrix. Both of them allow any number of arguments: additional arguments are tacked on with the null operator ge'a.
Therefore, the “magic square” matrix
| 8 | 1 | 6 |
| 3 | 5 | 7 |
| 4 | 9 | 2 |
can be represented either as:
| jo'i | biboi | paboi | xa | pi'a | jo'i | ciboi | muboi | ze |
| the-vector | (8 | 1 | 6) | matrix-row | the-vector | (3 | 5 | 7), |
| ge'a | jo'i | voboi | soboi | re |
| the-vector | (4 | 9 | 2) |
or as
| jo'i | biboi | ciboi | vo | sa'i | jo'i | paboi | muboi | so |
| the-vector | (8 | 3 | 4) | matrix-column | the-vector | (1 | 5 | 9), |
| ge'a | jo'i | xaboi | zeboi | re |
| the-vector | (6 | 7 | 2) |
The regular mekso operators can be applied to vectors and to matrices, since grammatically both of these are expressions. It is usually necessary to parenthesize matrices when used with operators in order to avoid incorrect groupings. There are no VUhU operators for the matrix operators of inner or outer products, but appropriate operators can be created using a suitable symbolic lerfu word or string prefixed by ma'o.
Matrices of more than two dimensions can be built up using either pi'a or sa'i with an appropriate subscript labeling the dimension. When subscripted, there is no difference between pi'a and sa'i. Labels can be any anything that xi supports, e.g. pa or mlatu bu.
The following cmavo is discussed in this section:
|
fu'a |
FUhA |
reverse Polish flag |
So far, the Lojban notational conventions have mapped fairly familiar kinds of mathematical discourse. The use of forethought operators may have seemed odd when applied to “+” , but when applied to “f” they appear as the usual functional notation. Now comes a sharp break. Reverse Polish (RP) notation represents something completely different; even mathematicians don't use it much. (The only common uses of RP, in fact, are in some kinds of calculators and in the implementation of some programming languages.)
In RP notation, the operator follows the operands. (Polish notation, where the operator precedes its operands, is another name for forethought mekso of the kind explained in Section 18.6.) The number of operands per operator is always fixed. No parentheses are required or permitted. In Lojban, RP notation is always explicitly marked by a fu'a at the beginning of the expression; there is no terminator. Here is a simple example:
The operands are re and ci ; the operator is su'i.
Here is a more complex example:
| li | fu'a | reboi | ci | pi'i | voboi | mu | pi'i | su'i |
| the-number | (RP!) | (two, | three, | times), | (four, | five, | times), | plus |
| du | li | rexa |
| equals | the-number | two-six |
Here the operands of the first pi'i are re and ci ; the operands of the second pi'i are vo and mu (with boi inserted where needed), and the operands of the su'i are reboi ci pi'i , or 6, and voboi mu pi'i , or 20. As you can see, it is easy to get lost in the world of reverse Polish notation; on the other hand, it is especially easy for a mechanical listener (who has a deep mental stack and doesn't get lost) to comprehend.
The operands of an RP operator can be any legal mekso operand, including parenthesized mekso that can contain any valid syntax, whether more RP or something more conventional.
In Lojban, RP operators are always parsed with exactly two operands. What about operators which require only one operand, or more than two operands? The null operand tu'o and the null operator ge'a provide a simple solution. A one-operand operator like va'a always appears in a reverse Polish context as tu'o va'a. The tu'o provides the second operand, which is semantically ignored but grammatically necessary. Likewise, the three-operand version of gei appears in reverse Polish as ge'a gei , where the ge'a effectively merges the 2nd and 3rd operands into a single operand. Here are some examples:
| li | fu'a | ciboi | muboi | vu'u |
| The-number | (RP!) | (three, | five, | minus) |
| du | li | fu'a | reboi | tu'o | va'a | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| equals | the-number | (RP!) | two, | null, | negative-of. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
3 − 5 = -2
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| li | cinonoki'oki'o | du |
| The-number | 300-comma-comma | equals |
| li | fu'a | biboi | ciboi | panoboi | ge'a | gei | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| the-number | (RP!) | 8, | (3, | 10, | null-op), | exponential-notation. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
300,000,000 = 3 × 10 ^ 8
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
The following cmavo are discussed in this section:
|
.abu |
BY |
letter “a” |
|
by |
BY |
letter “b” |
|
cy |
BY |
letter “c” |
|
fe'a |
VUhU |
nth root of (default square root) |
|
lo'o |
LOhO |
terminator for LI |
As befits a logical language, Lojban has extensive provision for logical connectives within both operators and operands. Full details on logical and non-logical connectives are provided in Chapter 14. Operands are connected in afterthought with selma'o A and in forethought with selma'o GA, just like sumti. Operators are connected in afterthought with selma'o JA and in forethought with selma'o GUhA, just like tanru components. This parallelism is no accident.
In addition, A+BO and A+KE constructs are allowed for grouping logically connected operands, and ke … ke'e is allowed for grouping logically connected operators, although there are no analogues of tanru among the operators.
Despite the large number of rules required to support this feature, it is of relatively minor importance in the mekso scheme of things. Example 18.114 exhibits afterthought logical connection between operands:
Example 18.115 is equivalent in meaning, but uses forethought connection:
Note that the mekso here are being used as quantifiers. Lojban requires that any mekso other than a simple number be enclosed in parentheses when used as a quantifier. This rule prevents ambiguities that do not exist when using li.
By the way, li has an elidable terminator, lo'o , which is needed when a li sumti is followed by a logical connective that could seem to be within the mekso. For example:
| li | re | su'i | re | du |
| The-number | two | plus | two | equals |
| li | vo | lo'o | .onai | lo | nalseldjuno | namcu |
| the-number | four | or-else | a | non-known | number. |
Omitting the lo'o would cause the parser to assume that another operand followed the .onai and reject lo as an invalid operand.
Simple examples of logical connection between operators are hard to come by. A contrived example is:
| li | re | su'i | je | pi'i | re | du | li | vo | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| The-number | two | plus | and | times | two | equals | the-number | four. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
2 + 2 = 4 and 2 × 2 = 4.
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
The forethought-connection form of Example 18.117 is:
| li | re | gu'e | su'i | gi | pi'i | re | du | li | vo | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| the-number | two | both | plus | and | times | two | equals | the-number | four. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Both 2 + 2 = 4 and 2 × 2 = 4.
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Here is a classic example of operand logical connection:
| go | li | .abu | bi'epi'i | vei | xy. | te'a | re | ve'o | su'i |
| If-and-only-if | the-number | “a” | times | ( | “x” | power | two | ) | plus |
| by. | bi'epi'i | xy. | su'i | cy. | du | li | no |
| “b” | times | “x” | plus | “c” | equals | the-number | zero |
| gi | li | xy. | du | li | vei | va'a | by. | ku'e |
| then | the-number | x | equals | the-number | [ | the-negation-of( | b | ) |
| su'i | ja | vu'u | fe'a |
| plus | or | minus | the-root-of |
| vei | by. | bi'ete'a | re | vu'u | vo | bi'epi'i | .abu | bi'epi'i | cy. |
| ( | “b” | power | 2 | minus | four | times | “a” | times | “c” |
| ve'o | [ku'e] | ve'o | fe'i | re | bi'epi'i | .abu | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ) | ] | divided-by | two | times | “a” | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Note the mixture of styles in Example 18.119 : the negation of b and the square root are represented by forethought and most of the operator precedence by prefixed bi'e , but explicit parentheses had to be added to group the numerator properly. In addition, the square root parentheses cannot be removed here in favor of simple fe'a and ku'e bracketing, because infix operators are present in the operand. Getting Example 18.119 to parse perfectly using the current parser took several tries: a more relaxed style would dispense with most of the bi'e cmavo and just let the standard precedence rules be understood.
Non-logical connection with JOI and BIhI is also permitted between operands and between operators. One use for this construct is to connect operands with bi'o to create intervals:
| li | no | ga'o | bi'o | ke'i | pa | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| the-number | zero | (inclusive) | from-to | (exclusive) | one | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
[0,1)
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
the numbers from zero to one, including zero but not including one |
Intervals defined by a midpoint and range rather than beginning and end points can be expressed by mi'i :
which expresses the same interval as Example 18.120. Note that the ga'o and ke'i still refer to the endpoints, although these are now implied rather than expressed. Another way of expressing the same thing:
| li | pimu | su'i | ni'upimu | ga'o | bi'o | ke'i | ma'upimu |
| the-number | 0.5 | plus | [-0.5 | (inclusive) | from-to | (exclusive) | +0.5] |
Here we have the sum of a number and an interval, which produces another interval centered on the number. As Example 18.122 shows, non-logical (or logical) connection of operands has higher precedence than any mekso operator.
You can also combine two operands with ce'o , the sequence connective of selma'o JOI, to make a compound subscript:
The following cmavo are discussed in this section:
|
na'u |
NAhU |
selbri to operator |
|
ni'e |
NIhE |
selbri to operand |
|
mo'e |
MOhE |
sumti to operand |
|
te'u |
TEhU |
terminator for all three |
One of the mekso design goals requires the ability to make use of Lojban's vocabulary resources within mekso to extend the built-in cmavo for operands and operators. There are three relevant constructs: all three share the elidable terminator te'u (which is also used to terminate vectors marked with jo'i)
The cmavo na'u makes a selbri into an operator. In general, the first place of the selbri specifies the result of the operator, and the other unfilled places specify the operands:
| li | na'u | tanjo | te'u |
| The-number | the-operator | tangent | [end-operator] |
| vei | pai | fe'i | re | [ve'o] | du | li | ci'i | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ( | π | / | 2 | ) | = | the-number | infinity. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
tan(π/2) = ∞
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
tanjo is the gismu for “x1 is the tangent of x2” , and the na'u here makes it into an operator which is then used in forethought
The cmavo ni'e makes a selbri into an operand. The x1 place of the selbri generally represents a number, and therefore is often a ni abstraction, since ni abstractions represent numbers. The ni'e makes that number available as a mekso operand. A common application is to make equations relating pure dimensions:
| li | ni'e | ni | clani | [te'u] |
| The-number | quantity-of | length |
| pi'i | ni'e | ni | ganra | [te'u] |
| times | quantity-of | width |
| pi'i | ni'e | ni | condi | te'u |
| times | quantity-of | depth |
| du | li | ni'e | ni | canlu | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| equals | the-number | quantity-of | volume. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Length × Width × Depth = Volume
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
The cmavo mo'e operates similarly to ni'e , but makes a sumti (rather than a selbri) into an operand. This construction is useful in stating equations involving dimensioned numbers:
| li | mo'e | re | ratcu | su'i | mo'e | re | ractu |
| The-number | two | rats | plus | two | rabbits |
| du | li | mo'e | vo | danlu | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| equals | the-number | four | animals. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
2 rats + 2 rabbits = 4 animals.
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Another use is in constructing Lojbanic versions of so-called “folk quantifiers” , such as “a pride of lions” :
| mi | viska | vei | mo'e | lo'e | lanzu | ve'o | cinfo |
| I | see | ( | the-typical | family | )-number-of | lions. |
|
I see a pride of lions. |
The following cmavo are discussed in this section:
|
me'o |
LI |
the mekso |
|
nu'a |
NUhA |
operator to selbri |
|
mai |
MAI |
utterance ordinal |
|
mo'o |
MAI |
higher order utterance ordinal |
|
roi |
ROI |
quantified tense |
So far we have seen mekso used as sumti (with li), as quantifiers (often parenthesized), and in MOI and ME-MOI selbri. There are a few other minor uses of mekso within Lojban.
The cmavo me'o has the same grammatical use as li but slightly different semantics. li means “the number which is the value of the mekso ...” , whereas me'o just means “the mekso ...” So it is true that:
but false that:
since the expressions “2 + 2” and “4” are not the same. The relationship between li and me'o is related to that between la .djan. , the person named John, and zo .djan. , the name “John”
The cmavo nu'a is the inverse of na'u , and allows a mekso operator to be used as a normal selbri, with the place structure:
x1 is the result of applying (operator) to x2, x3, ...
for as many places as may be required. For example:
uses nu'a to make the operator va'a into a two-place bridi
Used together, nu'a and na'u make it possible to ask questions about mekso operators, even though there is no specific cmavo for an operator question, nor is it grammatical to utter an operator in isolation. Consider Example 18.131 , to which Example 18.132 is one correct answer:
| li | re | na'u |
| The-number | two | applied-to-selbri |
| mo | re | du | li | vo | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| which-selbri? | two | equals | the-number | four. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
2 ? 2 = 4
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
In Example 18.131 , na'u mo is an operator question, because mo is the selbri question cmavo and na'u makes the selbri into an operator. Example 18.132 makes the true answer su'i into a selbri (which is a legal utterance) with the inverse cmavo nu'a. Mechanically speaking, inserting Example 18.132 into Example 18.131 produces:
| li | re | na'u | nu'a |
| The-number | two | (the-operator | the-selbri |
| su'i | re | du | li | vo |
| plus) | two | equals | the-number | four. |
where the na'u nu'a cancels out, leaving a truthful bridi
Numerical free modifiers, corresponding to English “firstly” , “secondly” , and so on, can be created by suffixing a member of selma'o MAI to a digit string or a lerfu string. (Digit strings are compound cmavo beginning with a cmavo of selma'o PA, and containing only cmavo of PA or BY; lerfu strings begin with a cmavo of selma'o BY, and likewise contain only PA or BY cmavo.) Here are some examples:
The difference between mai and mo'o is that mo'o enumerates larger subdivisions of a text. Each mo'o subdivision can then be divided into pieces and internally numbered with mai. If this chapter were translated into Lojban, each section would be numbered with mo'o. (See Section 19.7 for more on these words.)
A numerical tense can be created by suffixing a digit string with roi. This usage generates tenses corresponding to English “once” , “twice” , and so on. This topic belongs to a detailed discussion of Lojban tenses, and is explained further in Section 10.9.
Note: the elidable terminator boi is not used between a number and a member of MAI or ROI.
As mentioned earlier, Lojban does provide a way for the precedences of operators to be explicitly declared, although current parsers do not understand these declarations.
The declaration is made in the form of a metalinguistic comment using ti'o , a member of selma'o SEI. sei , the other member of SEI, is used to insert metalinguistic comments on a bridi which give information about the discourse which the bridi comprises. The format of a ti'o declaration has not been formally established, but presumably would take the form of mentioning a mekso operator and then giving it either an absolute numerical precedence on some preestablished scale, or else specifying relative precedences between new operators and existing operators.
In future, we hope to create an improved machine parser that can understand declarations of the precedences of simple operators belonging to selma'o VUhU. Originally, all operators would have the same precedence. Declarations would have the effect of raising the specified cmavo of VUhU to higher precedence levels. Complex operators formed with na'u , ni'e , or ma'o would remain at the standard low precedence; declarations with respect to them are for future implementation efforts. It is probable that such a parser would have a set of “commonly assumed precedences” built into it (selectable by a special ti'o declaration) that would match mathematical intuition: times higher than plus, and so on.
A few other points:
se can be used to convert an operator as if it were a selbri, so that its arguments are exchanged. For example:
| li | ci | se | vu'u | vo | du | li | pa |
| The-number | three | (inverse) | minus | four | equals | the-number | one. |
|
3 subtracted from 4 equals 1. |
The other converters of selma'o SE can also be used on operators with more than two operands, and they can be compounded to create (probably unintelligible) operators as needed.
Members of selma'o NAhE are also legal on an operator to produce a scalar negation of it. The implication is that some other operator would apply to make the bridi true:
The sense in which “plus” is the opposite of “minus” is not a mathematical but rather a linguistic one; negated operators are defined only loosely.
la'e and lu'e can be used on operands with the usual semantics to get the referent of or a symbol for an operand. Likewise, a member of selma'o NAhE followed by bo serves to scalar-negate an operand, implying that some other operand would make the bridi true:
| li | re | su'i | re | du | li | na'ebo | mu |
| The-number | 2 | plus | 2 | equals | the-number | non- | 5. |
|
2 + 2 = something other than 5. |
The digits 0-9 have rafsi, and therefore can be used in making lujvo. Additionally, all the rafsi have CVC form and can stand alone or together as names:
| la | .zel. | poi | gunta | la | .tebes. | pu | nanmu |
| Those-named | “Seven” | who | attack | that-named | “Thebes” | [past] | are-men. |
|
The Seven Against Thebes were men. |
Of course, there is no guarantee that the name .zel. is connected with the number rafsi: an alternative which cannot be misconstrued is:
| la | zemei | poi | gunta |
| Those-named-the | Sevensome | who | attack |
| la | .tebes. | pu | nanmu |
| that-named | Thebes | [past] | are-men. |
Certain other members of PA also have assigned rafsi: so'a , so'e , so'i , so'o , so'u , da'a , ro , su'e , su'o , pi , and ce'i. Furthermore, although the cmavo fi'u does not have a rafsi as such, it is closely related to the gismu frinu , meaning “fraction” ; therefore, in a context of numeric rafsi, you can use any of the rafsi for frinu to indicate a fraction slash.
A similar convention is used for the cmavo cu'o of selma'o MOI, which is closely related to cunso (probability); use a rafsi for cunso in order to create lujvo based on cu'o. The cmavo mei and moi of MOI have their own rafsi, two each in fact: mem / mei and mom / moi respectively.
The grammar of mekso as described so far imposes a rigid distinction between operators and operands. Some flavors of mathematics (lambda calculus, algebra of functions) blur this distinction, and Lojban must have a method of doing the same. An operator can be changed into an operand with ni'enu'a , which transforms the operator into a matching selbri and then the selbri into an operand.
To change an operand into an operator, we use the cmavo ma'o , already introduced as a means of changing a lerfu string such as fy. into an operator. In fact, ma'o can be followed by any mekso operand, using the elidable terminator te'u if necessary.
There is a potential semantic ambiguity in ma'o fy. [te'u] if fy. is already in use as a variable: it comes to mean “ the function whose value is always f ”. However, mathematicians do not normally use the same lerfu words or strings as both functions and variables, so this case should not arise in practice.
Abraham Lincoln's Gettysburg Address begins with the words “Four score and seven years ago”. This section exhibits several different ways of saying the number “four score and seven”. (A “score” , for those not familiar with the term, is 20; it is analogous to a “dozen” for 12.) The trivial way:
Example 18.145 is mathematically correct, but sacrifices the spirit of the English words, which are intended to be complex and formal.
Example 18.146 is also mathematically correct, but still misses something. “Score” is not a word for 20 in the same way that “ten” is a word for 10: it contains the implication of 20 objects. The original may be taken as short for “Four score years and seven years ago”. Thinking of a score as a twentysome rather than as 20 leads to:
| li | mo'e | voboi | renomei |
| the-number | [sumti-to-mex] | four | twentysomes |
| te'u | su'i | ze |
| [end-sumti-to-mex] | plus | seven |
In Example 18.147 , voboi renomei is a sumti signifying four things each of which are groups of twenty; the mo'e and te'u then make this sumti into a number in order to allow it to be the operand of su'i.
Another approach is to think of “score” as setting a representation base. There are remnants of base-20 arithmetic in some languages, notably French, in which 87 is “quatre-vingt-sept” , literally “four-twenties-seven”. (This fact makes the Gettysburg Address hard to translate into French!) If “score” is the representation base, then we have:
Overall, Example 18.147 probably captures the flavor of the English best. Example 18.145 and Example 18.146 are too simple, and Example 18.148 is too tricky. Nevertheless, all four examples are good Lojban. Pedagogically, these examples illustrate the richness of lojbau mekso: anything that can be said at all, can probably be said in more than one way.
Except as noted, each selma'o has only one cmavo.
|
BOI |
elidable terminator for numerals and lerfu strings |
|
BY |
lerfu for variables and functions (see Section 17.11) |
|
FUhA |
reverse-Polish flag |
|
GOhA |
includes du (mathematical equality) and other non-mekso cmavo |
|
JOhI |
array flag |
|
KUhE |
elidable terminator for forethought mekso |
|
LI |
|
|
MAhO |
make operand into operator |
|
MOI |
creates mekso selbri ( moi , mei , si'e , and cu'o , see Section 18.11) |
|
MOhE |
make sumti into operand |
|
NAhU |
make selbri into operator |
|
NIhE |
make selbri into operand |
|
NUhA |
make operator into selbri |
|
PA |
numbers (see Section 18.25) |
|
PEhO |
optional forethought mekso marker |
|
TEhU |
elidable terminator for NAhU, NIhE, MOhE, MAhO, and JOhI |
|
VEI |
left parenthesis |
|
VEhO |
right parenthesis |
|
VUhU |
operators (see Section 18.24) |
|
XI |
subscript flag |
The operand structures specify what various operands (labeled a, b, c, ...) mean. The implied context is forethought, since only forethought operators can have a variable number of operands; however, the same rules apply to infix and RP uses of VUhU.
|
su'i |
plus |
(((a + b) + c) + ...) |
|
pi'i |
times |
(((a × b) × c) × ...) |
|
vu'u |
minus |
(((a − b) − c) − ...) |
|
fe'i |
divided by |
(((a / b) / c) / ...) |
|
ju'u |
number base |
numeral string a interpreted in the base b |
|
pa'i |
ratio |
the ratio of a to b a:b |
|
fa'i |
reciprocal of/multiplicative inverse |
1 / a |
|
gei |
scientific notation |
b × (c [default 10] to the a power) |
|
ge'a |
null operator |
(no operands) |
|
de'o |
logarithm |
log a to base b (default 10 or e as appropriate) |
|
te'a |
to the power/exponential |
a to the b power |
|
fe'a |
nth root of/inverse power |
b th root of a (default square root: b = 2) |
|
cu'a |
absolute value/norm |
| a | |
|
ne'o |
factorial |
a! |
|
pi'a |
matrix row vector combiner |
(all operands are row vectors) |
|
sa'i |
matrix column vector combiner |
(all operands are column vectors) |
|
ri'o |
integral |
integral of a with respect to b over range c |
|
sa'o |
derivative |
derivative of a with respect to b of degree c (default 1) |
|
fu'u |
non-specific operator |
(variable) |
|
si'i |
sigma (Σ) summation |
summation of a using variable b over range c |
|
va'a |
negation of/additive inverse |
-a |
|
re'a |
matrix transpose/dual |
a T |
-
-
-
-
Table 18.4. Number punctuation
cmavo rafsi description pi
piz
decimal point
ce'i
cez
percentage
fi'u
fi'u (from frinu; see Section 18.20)
fraction (not division)
pi'e
mixed-base point
ma'u
plus sign (not addition)
ni'u
minus sign (not subtraction)
ki'o
thousands comma
ra'e
repeating-decimal indicator
ji'i
approximation sign
ka'o
complex number separator
-
Table 18.5. Indefinite numbers
cmavo rafsi description ro
rol
all
so'a
soj
almost all
so'e
sop
most
so'i
sor , so'i
many
so'o
sos
several
so'u
sot
few
da'a
daz
all but
-
-
| cmavo | rafsi | description |
|
mei |
mem , mei |
x1 is a mass formed from a set x2 of n members, one or more of which is/are x3, [measured relative to the set x4/by standard x4] |
|
moi |
mom , moi |
x1 is the (n)th member of set x2 when ordered by rule x3 [by standard x4] |
|
si'e |
x1 is an (n)th portion of mass x2 [by standard x3] |
|
|
cu'o |
cu'o |
event x1 has probability (n) of occurring under conditions x2 [by standard x3]; the rafsi is borrowed from cunso ; see Section 18.20 |
|
va'e |
x1 is at scale position (n) on the scale x2 [by standard x3] |
This chapter is incurably miscellaneous. It describes the cmavo that specify the structure of Lojban texts, from the largest scale (paragraphs) to the smallest (single words). There are fewer examples than are found in other chapters of this book, since the linguistic mechanisms described are generally made use of in conversation or else in long documents.
This chapter is also not very self-contained. It makes passing reference to a great many concepts which are explained in full only in other chapters. The alternative would be a chapter on text structure which was as complex as all the other chapters put together. Lojban is a unified language, and it is not possible to understand any part of it (in full) before understanding every part of it (to some degree).
The following cmavo is discussed in this section:
|
.i |
I |
sentence separator |
Since Lojban is audio-visually isomorphic, there needs to be a spoken and written way of signaling the end of a sentence and the start of the following one. In written English, a period serves this purpose; in spoken English, a tone contour (rising or falling) usually does the job, or sometimes a long pause. Lojban uses a single separator: the cmavo .i (of selma'o I):
The word “separator” should be noted. .i is not normally used after the last sentence nor before the first one, although both positions are technically grammatical. .i signals a new sentence on the same topic, not necessarily by the same speaker. The relationship between the sentences is left vague, except in stories, where the relationship usually is temporal, and the following sentence states something that happened after the previous sentence.
Note that although the first letter of an English sentence is capitalized, the cmavo .i is never capitalized. In writing, it is appropriate to place extra space before .i to make it stand out better for the reader. In some styles of Lojban writing, every .i is placed at the beginning of a line, possibly leaving space at the end of the previous line.
An .i cmavo may or may not be used when the speaker of the following sentence is different from the speaker of the preceding sentence, depending on whether the sentences are felt to be connected or not.
An .i cmavo can be compounded with a logical or non-logical connective (a jek or joik), a modal or tense connective, or both: these constructs are explained in Section 9.8 , Section 10.16 , and Section 14.4. In all cases, the .i comes first in the compound. Attitudinals can also be attached to an .i if they are meant to apply to the whole sentence: see Section 13.9.
There exist a pair of mechanisms for binding a sequence of sentences closely together. If the .i (with or without connectives) is followed by bo (of selma'o BO), then the two sentences being separated are understood to be more closely grouped than sentences connected by .i alone.
Similarly, a group of sentences can be preceded by tu'e (of selma'o TUhE) and followed by tu'u (of selma'o TUhU) to fuse them into a single unit. A common use of tu'e … tu'u is to group the sentences which compose a poem: the title sentence would precede the group, separated from it by .i. Another use might be a set of directions, where each numbered direction might be surrounded by tu'e … tu'u and contain one or more sentences separated by .i. Grouping with tu'e and tu'u is analogous to grouping with ke and ke'e to establish the scope of logical or non-logical connectives (see Section 14.8).
The following cmavo are discussed in this section:
|
ni'o |
NIhO |
new topic |
|
no'i |
NIhO |
old topic |
|
da'o |
DAhO |
cancel cmavo assignments |
The paragraph is a concept used in writing systems for two purposes: to indicate changes of topic, and to break up the hard-to-read appearance of large blocks of text on the page. The former function is represented in both spoken and written Lojban by the cmavo ni'o and no'i , both of selma'o NIhO. Of these two, ni'o is the more common. By convention, written Lojban is broken into paragraphs just before any ni'o or no'i , but a very long passage on a single topic might be paragraphed before an .i. On the other hand, it is conventional in English to start a new paragraph in dialogue when a new speaker starts, but this convention is not commonly observed in Lojban dialogues. Of course, none of these conventions affect meaning in any way.
A ni'o can take the place of an .i as a sentence separator, and in addition signals a new topic or paragraph. Grammatically, any number of ni'o cmavo can appear consecutively and are equivalent to a single one; semantically, a greater number of ni'o cmavo indicates a larger-scale change of topic. This feature allows complexly structured text, with topics, subtopics, and sub-subtopics, to be represented clearly and unambiguously in both spoken and written Lojban. However, some conventional differences do exist between ni'o in writing and in conversation.
In written text, a single ni'o is a mere discursive indicator of a new subject, whereas ni'oni'o marks a change in the context. In this situation, ni'oni'o implicitly cancels the definitions of all pro-sumti of selma'o KOhA as well as pro-bridi of selma'o GOhA. (Explicit cancelling is expressed by the cmavo da'o of selma'o DAhO, which has the free grammar of an indicator – it can appear almost anywhere.) The use of ni'oni'o does not affect indicators (of selma'o UI) or tense references, but ni'oni'oni'o , indicating a drastic change of topic, would serve to reset both indicators and tenses. (See Section 19.8 for a discussion of indicator scope.)
In spoken text, which is inherently less structured, these levels are reduced by one, with ni'o indicating a change in context sufficient to cancel pro-sumti and pro-bridi assignment. On the other hand, in a book, or in stories within stories such as “The Arabian Nights” , further levels may be expressed by extending the ni'o string as needed. Normally, a written text will begin with the number of ni'o cmavo needed to signal the largest scale division which the text contains. ni'o strings may be subscripted to label each context of discourse: see Section 19.6.
no'i is similar in effect to ni'o , but indicates the resumption of a previous topic. In speech, it is analogous to (but much shorter than) such English discursive phrases as “But getting back to the point ...”. By default, the topic resumed is that in effect before the last ni'o. When subtopics are nested within topics, then no'i would resume the previous subtopic and no'ino'i the previous topic. Note that no'i also resumes tense and pro-sumti assignments dropped at the previous ni'o.
If a ni'o is subscripted, then a no'i with the same subscript is assumed to be a continuation of it. A no'i may also have a negative subscript, which would specify counting backwards a number of paragraphs and resuming the topic found thereby.
The following cmavo is discussed in this section:
|
zo'u |
ZOhU |
topic/comment separator |
The normal Lojban sentence is just a bridi, parallel to the normal English sentence which has a subject and a predicate:
In Chinese, the normal sentence form is different: a topic is stated, and a comment about it is made. (Japanese also has the concept of a topic, but indicates it by attaching a suffix; other languages also distinguish topics in various ways.) The topic says what the sentence is about:
-
这消息我知道了。
-
Zhè xiāoxī wǒ zhīdàole.
-
this news : I know [perfective]
-
As for this news, I knew it.
-
I've heard this news already.
The colon in the first two versions of Example 19.3 separate the topic ( “this news”) from the comment ( “I know already”).
Lojban uses the cmavo zo'u (of selma'o ZOhU) to separate topic (a sumti) from comment (a bridi):
Example 19.4 is the literal Lojban translation of Example 19.3. Of course, the topic-comment structure can be changed to a straightforward bridi structure:
Example 19.5 means the same as Example 19.4 , and it is simpler. However, often the position of the topic in the place structure of the selbri within the comment is vague:
Is the fish eating or being eaten? The sentence doesn't say. The Chinese equivalent of Example 19.6 is:
which is vague in exactly the same way.
Grammatically, it is possible to have more than one sumti before zo'u. This is not normally useful in topic-comment sentences, but is necessary in the other use of zo'u : to separate a quantifying section from a bridi containing quantified variables. This usage belongs to a discussion of quantifier logic in Lojban (see Section 16.2), but an example would be:
| ro | da | poi | prenu | ku'o |
| For-all | X | which | are-persons, |
| su'o | de | zo'u | de | patfu | da |
| there-exists-a | Y | such-that | Y | is-the-father-of | X. |
|
Every person has a father. |
The string of sumti before zo'u (called the “prenex” : see Section 16.2) may contain both a topic and bound variables:
| loi | patfu | ro | da | poi | prenu | ku'o |
| For-the-mass-of | fathers | for-all | X | which | are-persons, |
| su'o | de | zo'u | de | patfu | da |
| there-exists-a | Y | such-that | Y | is-the-father-of | X. |
|
As for fathers, every person has one. |
To specify a topic which affects more than one sentence, wrap the sentences in tu'e … tu'u brackets and place the topic and the zo'u directly in front. This is the exception to the rule that a topic attaches directly to a sentence:
| loi | jdini | zo'u | tu'e | do | ponse | .inaja | do | djica | [tu'u] | |
| The-mass-of | money | : | ( | [if] | you | possess, | then | you | want | ) |
|
Money: if you have it, you want it. |
Note: In Lojban, you do not “want money” ; you “want to have money” or something of the sort, as the x2 place of djica demands an event. As a result, the straightforward rendering of Example 19.9 without a topic is not:
where ri means loi jdini and is interpreted as “the mere existence of money” , but rather:
namely, the possession of money. But topic-comment sentences like Example 19.10 are inherently vague, and this difference between ponse (which expects a physical object in x2) and djica is ignored. See Example 19.45 for another topic/comment sentence.
The subject of an English sentence is often the topic as well, but in Lojban the sumti in the x1 place is not necessarily the topic, especially if it is the normal (unconverted) x1 for the selbri. Thus Lojban sentences don't necessarily have a “subject” in the English sense.
The following cmavo are discussed in this section:
|
xu |
UI |
truth question |
|
ma |
KOhA |
sumti question |
|
mo |
GOhA |
bridi question |
|
xo |
PA |
number question |
|
ji |
A |
sumti connective question |
|
ge'i |
GA |
forethought connective question |
|
gi'i |
GIhA |
bridi-tail connective question |
|
gu'i |
GUhA |
tanru forethought connective question |
|
je'i |
JA |
tanru connective question |
|
pei |
UI |
attitude question |
|
fi'a |
FA |
place structure question |
|
cu'e |
CUhE |
tense/modal question |
|
pau |
UI |
question premarker |
Lojban questions are not at all like English questions. There are two basic types: truth questions, of the form “Is it true that ...” , and fill-in-the-blank questions. Truth questions are marked by preceding the bridi, or following any part of it specifically questioned, with the cmavo xu (of selma'o UI):
| xu | do | klama | le | zarci |
| [True-or-false?] | You | go-to | the | store |
|
Are you going to the store/Did you go to the store? |
(Since the Lojban is tenseless, either colloquial translation might be correct.) Truth questions are further discussed in Section 15.8.
Fill-in-the-blank questions have a cmavo representing some Lojban word or phrase which is not known to the questioner, and which the answerer is to supply. There are a variety of cmavo belonging to different selma'o which provide different kinds of blanks.
Where a sumti is not known, a question may be formed with ma (of selma'o KOhA), which is a kind of pro-sumti:
Of course, the ma need not be in the x1 place:
The answer is a simple sumti:
A sumti, then, is a legal utterance, although it does not by itself constitute a bridi – it does not claim anything, but merely completes the open-ended claim of the previous bridi.
There can be two ma cmavo in a single question:
and the answer would be two sumti, which are meant to fill in the two ma cmavo in order:
An even more complex example, depending on the non-logical connective fa'u (of selma'o JOI), which is like the English “and ... respectively” :
An answer might be
| la | .djan. | la | .marcas. | le | zarci | le | briju |
| John, | Marsha, | the | store, | the | office. |
|
John and Marsha go to the store and the office, respectively. |
(Note: A mechanical substitution of Example 19.20 into Example 19.19 produces an ungrammatical result, because * ... le zarci fa'u le briju is ungrammatical Lojban: the first le zarci has to be closed with its proper terminator ku , for reasons explained in Section 14.14. This effect is not important: Lojban behaves as if all elided terminators have been supplied in both question and answer before inserting the latter into the former. The exchange is grammatical if question and answer are each separately grammatical.)
Questions to be answered with a selbri are expressed with mo of selma'o GOhA, which is a kind of pro-bridi:
Here the answerer is to supply some predicate which is true of Lojban. Such questions are extremely open-ended, due to the enormous range of possible predicate answers. The answer might be just a selbri, or might be a full bridi, in which case the sumti in the answer override those provided by the questioner. To limit the range of a mo question, make it part of a tanru.
Questions about numbers are expressed with xo of selma'o PA:
The answer would be a simple number, another kind of non-bridi utterance:
Fill-in-the-blank questions may also be asked about: logical connectives (using cmavo ji of A, ge'i of GA, gi'i of GIhA, gu'i of GUhA, or je'i of JA, and receiving an ek, gihek, ijek, or ijoik as an answer) – see Section 14.13 ; attitudes (using pei of UI, and receiving an attitudinal as an answer) – see Section 13.10 ; place structures (using fi'a of FA, and receiving a cmavo of FA as an answer) – see Section 9.3 ; tenses and modals (using cu'e of CUhE, and receiving any tense or BAI cmavo as an answer) – see Section 9.6 and Chapter 10.
Questions can be marked by placing pau (of selma'o UI) before the question bridi. See Section 13.13 for details.
The full list of non-bridi utterances suitable as answers to questions is:
-
any number of sumti (with elidable terminator vau , see Chapter 6)
-
an ek or gihek (logical connectives, see Chapter 14)
-
a number, or any mathematical expression placed in parentheses (see Chapter 18)
-
a bare na negator (to negate some previously expressed bridi), or corresponding ja'a affirmer (see Chapter 15)
-
a relative clause (to modify some previously expressed sumti, see Chapter 8)
-
a prenex/topic (to modify some previously expressed bridi, see Chapter 16)
-
linked arguments (beginning with be or bei and attached to some previously expressed selbri, often in a description, see Section 5.7)
At the beginning of a text, the following non-bridi are also permitted:
-
one or more cmevla (to indicate direct address without doi , see Chapter 6)
-
indicators (to express a prevailing attitude, see Chapter 13)
-
nai (to vaguely negate something or other, see Section 15.7)
Where not needed for the expression of answers, most of these are made grammatical for pragmatic reasons: people will say them in conversation, and there is no reason to rule them out as ungrammatical merely because most of them are vague.
The following cmavo is discussed in this section:
|
xi |
XI |
subscript |
The cmavo xi (of selma'o XI) indicates that a subscript (a number, a lerfu string, or a parenthesized mekso) follows. Subscripts can be attached to almost any construction and are placed following the construction (or its terminator word, which is generally required). When attached to cmavo they are useful either to extend the finite cmavo list to infinite length, or to make more refined distinctions than the standard cmavo list permits. The remainder of this section mentions some places where subscripts might naturally be used.
Lojban gismu have at most five places:
| mi | cu | klama | le | zarci | le | zdani | le | dargu | le | karce | ||||
| I | go | to | the | market | from | the | house | via | the | road | using | the | car. |
Consequently, selma'o SE (which operates on a selbri to change the order of its places) and selma'o FA (which provides place number tags for individual sumti) have only enough members to handle up to five places. Conversion of Example 19.24 , using xe to swap the x1 and x5 places, would produce:
| le | karce | cu | xe-klama | le | zarci | |
| The | car | is-a-transportation-means | to | the | market |
| le | zdani | le | dargu | mi | |||
| from | the | house | via | the | road | for | me. |
And reordering of the place structures might produce:
| fo | le | dargu | fi | le | zdani | fa | mi |
| Via | the | road, | from | the | house, | I, |
| fe | le | zarci | fu | le | karce | cu | klama |
| to | the | market, | using | the | car, | go. |
Example 19.24 to Example 19.26 all mean the same thing. But consider the lujvo nunkla , formed by applying the abstraction operator nu to klama :
| la'e | di'u | cu | nunkla | mi | |
| The-referent-of | the-previous-sentence | is-an-event-of-going | by | me |
| le | zarci | le | zdani | le | dargu | le | karce | ||||
| to | the | market | from | the | house | via | the | road | using | the | car. |
Example 19.27 shows that nunkla has six places: the five places of klama plus a new one (placed first) for the event itself. Performing transformations similar to that of Example 19.25 requires an additional conversion cmavo that exchanges the x1 and x6 places. The solution is to use any cmavo of SE with a subscript "6" ( Section 19.6):
| le | karce | cu | sexixa nunkla | mi | |
| The | car | is-a-transportation-means-in-the-event-of-going | by | me |
| le | zarci | le | zdani | ||
| to | the | market | from | the | house |
| le | dargu | la'edi'u | |
| via | the | road | is-an-event-which-is-referred-to-by-the-last-sentence. |
Likewise, a sixth place tag can be created by using any cmavo of FA with a subscript:
| fu | le | dargu | fo | le | zdani | fe | mi |
| Via | the | road, | from | the | house, | by | me, |
| fa | la'edi'u | |
| is-an-event-which | is-referred-to-by-the-last-sentence, |
| fi | le | zarci | faxixa | le | karce | cu | nunkla |
| to | the | market, | using | the | car, | is-an-event-of-going. |
Example 19.27 to Example 19.29 also all mean the same thing, and each is derived straightforwardly from any of the others, despite the tortured nature of the English glosses. In addition, any other member of SE or FA could be substituted into sexixa and faxixa without change of meaning: vexixa means the same thing as sexixa.
Lojban provides two groups of pro-sumti, both belonging to selma'o KOhA. The ko'a-series cmavo are used to refer to explicitly specified sumti to which they have been bound using goi. The da-series, on the other hand, are existentially or universally quantified variables. (These concepts are explained more fully in Chapter 16.) There are ten ko'a-series cmavo and 3 da-series cmavo available.
If more are required, any cmavo of the ko'a-series or the da-series can be subscripted:
is the 4th bound variable of the 1st sequence of the da-series, and
is the 19th free variable of the 3rd sequence of the ko'a-series. This convention allows 10 sequences of ko'a-type pro-sumti and 3 sequences of da-type pro-sumti, each with as many members as needed. Note that daxivo and dexivo are considered to be distinct pro-sumti, unlike the situation with sexixa and vexixa above. Exactly similar treatment can be given to the bu'a-series of selma'o GOhA and to the gismu pro-bridi broda , brode , brodi , brodo , and brodu.
Subscripts on lerfu words are used in the standard mathematical way to extend the number of variables:
| li | xy.boixipa | du | li | xy.boixire | su'i | xy.boixici | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| The-number | x-sub-1 | equals | the-number | x-sub-2 | plus | x-sub-3 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
x
1
= x
2
+ x
3
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
and can be used to extend the number of pro-sumti as well, since lerfu strings outside mathematical contexts are grammatically and semantically equivalent to pro-sumti of the ko'a-series. (In Example 19.32 , note the required terminator boi after each xy. cmavo; this terminator allows the subscript to be attached without ambiguity.)
Names, which are similar to pro-sumti, can also be subscripted to distinguish two individuals with the same name:
| la | .djan. | xipa | cusku | lu | mi'enai | do | li'u | la | .djan. | xire |
| John1 | expresses | [quote] | I-am-not | you | [unquote] | to | John2 | . |
Subscripts on tenses allow talking about more than one time or place that is described by the same general cmavo. For example, puxipa could refer to one point in the past, and puxire a second point (earlier or later).
You can place a subscript on the word ja'a , the bridi affirmative of selma'o NA, to express so-called fuzzy truths. The usual machinery for fuzzy logic (statements whose truth value is not merely “true” or “false” , but is expressed by a number in the range 0 to 1) in Lojban is the abstractor jei :
However, by convention we can attach a subscript to ja'a to indicate fuzzy truth (or to na if we change the amount):
Finally, as mentioned in Section 19.2 , ni'o and no'i cmavo with matching subscripts mark the start and the continuation of a given topic respectively. Different topics can be assigned to different subscripts.
Other uses of subscripts will doubtless be devised in future.
The following cmavo are discussed in this section:
|
mai |
MAI |
utterance ordinal, -thly |
|
mo'o |
MAI |
higher order utterance ordinal |
Numerical free modifiers, corresponding to English “firstly” , “secondly” , and so on, can be created by suffixing mai or mo'o of selma'o MAI to a number or a lerfu string. Here are some examples:
This does not imply that I go to the store before I go to the house: that meaning requires a tense. The sumti are simply numbered for convenience of reference. Like other free modifiers, the utterance ordinals can be inserted almost anywhere in a sentence without affecting its grammar or its meaning.
Any of the Lojban numbers can be used with MAI: romai , for example, means “all-thly” or “lastly”. Likewise, if you are enumerating a long list and have forgotten which number is wanted next, you can say ny.mai , or “Nthly”.
The difference between mai and mo'o is that mo'o enumerates larger subdivisions of a text; mai was designed for lists of numbered items, whereas mo'o was intended to subdivide structured works. If this chapter were translated into Lojban, it might number each section with mo'o : this section would then be introduced with zemo'o , or “Section 7.”
The following cmavo are discussed in this section:
|
fu'e |
FUhE |
open attitudinal scope |
|
fu'o |
FUhO |
close attitudinal scope |
Lojban has a complex system of “attitudinals” , words which indicate the speaker's attitude to what is being said. The attitudinals include indicators of emotion, intensity markers, discursives (which show the structure of discourse), and evidentials (which indicate “how the speaker knows”). Most of these words belong to selma'o UI; the intensity markers belong to selma'o CAI for historical reasons, but the two selma'o are grammatically identical. The individual cmavo of UI and CAI are discussed in Chapter 13 ; only the rules for applying them in discourse are presented here.
Normally, an attitudinal applies to the preceding word only. However, if the preceding word is a structural cmavo which begins or ends a whole construction, then that whole construction is affected by the attitudinal:
| mi | viska | le | blanu | .ia | zdani | [ku] |
| I | see | the | blue | [belief] | house. |
|
I see the house, which I believe to be blue. |
| mi | viska | le | blanu | zdani | .ia | [ku] |
| I | see | the | blue | house | [belief]. |
|
I see the blue thing, which I believe to be a house. |
| mi | viska | le | .ia | blanu | zdani | [ku] |
| I | see | the | [belief] | blue | house |
|
I see what I believe to be a blue house. |
| mi | viska | le | blanu | zdani | ku | .ia |
| I | see | (the | blue | house) | [belief] |
|
I see what I believe to be a blue house. |
An attitudinal meant to cover a whole sentence can be attached to the preceding .i , expressed or understood:
or to an explicit vau placed at the end of a bridi.
Likewise, an attitudinal meant to cover a whole paragraph can be attached to ni'o or no'i. An attitudinal at the beginning of a text applies to the whole text.
However, sometimes it is necessary to be more specific about the range of one or more attitudinals, particularly if the range crosses the boundaries of standard Lojban syntactic constructions. The cmavo fu'e (of selma'o FUhE) and fu'o (of selma'o FUhO) provide explicit scope markers. Placing fu'e in front of an attitudinal disconnects it from what precedes it, and instead says that it applies to all following words until further notice. The notice is given by fu'o , which can appear anywhere and cancels all in-force attitudinals. For example:
| mi | viska | le | fu'e | .ia | blanu | zdani | fu'o | ponse |
| I | see | the | [start] | [belief] | blue | house | [end] | possessor |
|
I see the owner of what I believe to be a blue house. |
Here, only the blanu zdani portion of the three-part tanru blanu zdani ponse is marked as a belief of the speaker. Naturally, the attitudinal scope markers do not affect the rules for interpreting multi-part tanru: blanu zdani groups first because tanru group from left to right unless overridden with ke or bo.
Other attitudinals of more local scope can appear after attitudinals marked by FUhE; these attitudinals are added to the globally active attitudinals rather than superseding them.
The following cmavo are discussed in this section:
|
lu |
LU |
begin quotation |
|
li'u |
LIhU |
end quotation |
|
lo'u |
LOhU |
begin error quotation |
|
le'u |
LEhU |
end error quotation |
Grammatically, quotations are very simple in Lojban: all of them are sumti, and they all mean something like “the piece of text here quoted” :
But in fact there are four different flavors of quotation in the language, involving six cmavo of six different selma'o. This being the case, quotation deserves some elaboration.
The simplest kind of quotation, exhibited in Example 19.43 , uses the cmavo lu (of selma'o LU) as the opening quotation mark, and the cmavo li'u (of selma'o LIhU) as the closing quotation mark. The text between lu and li'u must be a valid, parseable Lojban text. If the quotation is ungrammatical, so is the surrounding expression. The cmavo li'u is technically an elidable terminator, but it's almost never possible to elide it except at the end of text.
The cmavo lo'u (of selma'o LOhU) and le'u (of selma'o LEhU) are used to surround a quotation that is not necessarily grammatical Lojban. However, the text must consist of morphologically correct Lojban words (as defined in Chapter 4), so that the le'u can be picked out reliably. The words need not be meaningful, but they must be recognizable as cmavo, brivla, or cmevla. Quotation with lo'u is essential to quoting ungrammatical Lojban for teaching in the language, the equivalent of the * that is used in English to mark such errors:
| lo'u | mi du do du la .djan. | le'u |
| [quote] | mi du do du la djan. | [unquote] |
| na | tergerna | la | .lojban. |
| is-not | a-grammatical-structure | in | Lojban. |
Example 19.44 is grammatical even though the embedded quotation is not. Similarly, lo'u quotation can quote fragments of a text which themselves do not constitute grammatical utterances:
| lu | le mlatu cu viska le finpe | li'u | zo'u |
| [quote] | le mlatu cu viska le finpe | [unquote] | : |
| lo'u | viska le | le'u | cu | selbasti |
| [quote] | viska le | [unquote] | is-replaced-by |
| .ei | lo'u | viska lo | le'u |
| [obligation!] | [quote] | viska lo | [unquote]. |
Note the topic-comment formulation ( Section 19.4) and the indicator applying to the selbri only ( Section 19.8). Neither viska le nor viska lo is a valid Lojban utterance, and both require lo'u quotation.
Additionally, pro-sumti or pro-bridi in the quoting sentence can refer to words appearing in the quoted sentence when lu … li'u is used, but not when lo'u ... le'u is used:
| la | .tcarlis. | cusku | lu | le | ninmu | cu | morsi | li'u |
| Charlie | says | [quote] | the | woman | is-dead | [unquote]. |
| .iku'i | ri | jmive |
| However, | the-last-mentioned | is-alive. |
|
Charlie says “The woman is dead” , but she is alive. |
In Example 19.46 , ri is a pro-sumti which refers to the most recent previous sumti, namely le ninmu. Compare:
In Example 19.47 , ri cannot refer to the referent of the alleged sumti le ninmu , because le ninmu cu morsi is a mere uninterpreted sequence of Lojban words. Instead, ri ends up referring to the referent of the sumti la .tcarlis. , and so it is Charlie who is alive.
The metalinguistic erasers si , sa , and su , discussed in Section 19.13 , do not operate in text between lo'u and le'u. Since the first le'u terminates a lo'u quotation, it is not directly possible to have a lo'u quotation within another lo'u quotation. However, it is possible for a le'u to occur within a lo'u ... le'u quotation by preceding it with the cmavo zo , discussed in Section 19.10. Note that le'u is not an elidable terminator; it is required.
The following cmavo are discussed in this section:
|
zo |
ZO |
quote single word |
|
zoi |
ZOI |
non-Lojban quotation |
|
la'o |
ZOI |
non-Lojban name |
The cmavo zo (of selma'o ZO) is a strong quotation mark for the single following word, which can be any Lojban word whatsoever. Among other uses, zo allows a metalinguistic word to be referenced without having it act on the surrounding text. The word must be a morphologically legal (but not necessarily meaningful) single Lojban word; compound cmavo are not permitted. For example:
Since zo acts on a single word only, there is no corresponding terminator. Brevity, then, is a great advantage of zo , since the terminators for other kinds of quotation are rarely or never elidable.
The cmavo zoi (of selma'o ZOI) is a quotation mark for quoting non-Lojban text. Its syntax is zoi .X. text .X , where X is a Lojban word (called the delimiting word) which is separated from the quoted text by pauses, and which is not found in the written text or spoken phoneme stream. It is common, but not required, to use the lerfu word (of selma'o BY) which corresponds to the Lojban name of the language being quoted:
where gy. stands for glico. Other popular choices of delimiting words are .kuot. , a cmevla which sounds like the English word “quote” , and the word zoi itself. Another possibility is a Lojban word suggesting the topic of the quotation.
Within written text, the Lojban written word used as a delimiting word may not appear, whereas within spoken text, the sound of the delimiting word may not be uttered. This leads to occasional breakdowns of audio-visual isomorphism: Example 19.50 is fine in speech but ungrammatical as written, whereas Example 19.51 is correct when written but ungrammatical in speech.
The text gy. appears in the written word “gyrations” , whereas the sound represented in Lojban by jai appears in the spoken word “gyrations”. Such borderline cases should be avoided as a matter of good style.
It should be noted particularly that zoi quotation is the only way to quote rafsi, specifically CCV rafsi, because they are not Lojban words, and zoi quotation is the only way to quote things which are not Lojban words. (CVC and CVV rafsi look like cmevla and cmavo respectively, and so can be quoted using other methods.) For example:
(A minor note on interaction between lo'u ... le'u and zoi : The text between lo'u and le'u should consist of Lojban words only. In fact, non-Lojban material in the form of a zoi quotation may also appear. However, if the word le'u is used either as the delimiting word for the zoi quotation, or within the quotation itself, the outer lo'u quotation will be prematurely terminated. Therefore, le'u should be avoided as the delimiting word in any zoi quotation.)
Lojban strictly avoids any confusion between things and the names of things:
In Example 19.53 , zo .bab. is the word, whereas la .bab. is the thing named by the word. The cmavo la'e and lu'e (of selma'o LAhE) convert back and forth between references and their referents:
Example 19.53 through Example 19.55 all mean approximately the same thing, except for differences in emphasis. Example 19.56 is different:
and says that Bob is both the name and the thing named, an unlikely situation. People are not names.
(In Example 19.53 through Example 19.54 , the name .bab. was separated from a preceding zo by a pause, thus: zo .bab.. The reason for this extra pause is that all Lojban names must be separated by pause from any preceding word. There are numerous other cmavo that may precede a name: of these, zo is one of the most common.)
The cmavo la'o also belongs to selma'o ZOI, and is mentioned here for completeness, although it does not signal the beginning of a quotation. Instead, la'o serves to mark non-Lojban names, especially the Linnaean binomial names (such as “Homo sapiens”) which are the internationally standardized names for species of animals and plants. Internationally known names which can more easily be recognized by spelling rather than pronunciation, such as “Goethe” , can also appear in Lojban text with la'o :
Using la'o for all names rather than Lojbanizing, however, makes for very cumbersome text. A rough equivalent of la'o might be la me zoi.
The following cmavo are discussed in this section:
|
ba'e |
BAhE |
emphasize next word |
|
za'e |
BAhE |
next word is nonce |
English often uses strong stress on a word to single it out for contrastive emphasis, thus
is quite different from
The heavy stress on “George” (represented in writing by italics) indicates that I saw George rather than someone else. Lojban does not use stress in this way: stress is used only to help separate words (because every brivla is stressed on the penultimate syllable) and in names to match other languages' stress patterns. Note that many other languages do not use stress in this way either; typically word order is rearranged, producing something like
In Lojban, the cmavo ba'e (of selma'o BAhE) precedes a single word which is to be emphasized:
Note the pause before the cmevla djordj. , which serves to separate it unambiguously from the ba'e. Alternatively, the ba'e can be moved to a position before the la , which in effect emphasizes the whole construct la .djordj. :
Marking a word with a cmavo of BAhE does not change the word's grammar in any way. Any word in a bridi can receive contrastive emphasis marking:
Emphasis on one of the structural components of a Lojban bridi can also be achieved by rearranging it into an order that is not the speaker's or writer's usual order. Any sumti moved out of place, or the selbri when moved out of place, is emphatic to some degree.
For completeness, the cmavo za'e should be mentioned, also of selma'o BAhE. It marks a word as possibly irregular, non-standard, or nonce (created for the occasion):
marks a Lojbanization of an English name, where a more appropriate standard form might be something like la .ckiipyris. , reflecting the country's name in Albanian.
Before a lujvo or fu'ivla, za'e indicates that the word has been made up on the spot and may be used in a sense that is not found in the unabridged dictionary (when we have an unabridged dictionary!).
The following cmavo are discussed in this section:
|
to |
TO |
open parenthesis |
|
to'i |
TO |
open editorial parenthesis |
|
toi |
TOI |
close parenthesis |
|
sei |
SEI |
metalinguistic bridi marker |
The cmavo to and toi are discursive (non-mathematical) parentheses, for inserting parenthetical remarks. Any text whatsoever can go within the parentheses, and it is completely invisible to its context. It can, however, refer to the context by the use of pro-sumti and pro-bridi: any that have been assigned in the context are still assigned in the parenthetical remarks, but the reverse is not true.
| doi | .lisas. | mi | djica | le | nu | to | doi | .frank. |
| O | Lisa, | I | desire | the | event-of | ( | O | Frank, |
| ko | sisti | toi | do | viska | le | mlatu |
| [imperative] | stop! | ) | you | see | the | cat. |
|
Lisa, I want you to (Frank! Stop!) see the cat. |
Example 19.66 implicitly redefines do within the parentheses: the listener is changed by doi .frank. When the context sentence resumes, however, the old listener, Lisa, is automatically restored.
There is another cmavo of selma'o TO: to'i. The difference between to and to'i is the difference between parentheses and square brackets in English prose. Remarks within to ... toi cmavo are implicitly by the same speaker, whereas remarks within to'i ... toi are implicitly by someone else, perhaps an editor:
|
la .frank. cusku lu mi prami do to'isa'a do du la .djein. toi li'u |
|
Frank expresses “I love you [you = Jane]” |
The sa'a suffix is a discursive cmavo (of selma'o UI) meaning “editorial insertion” , and indicating that the marked word or construct (in this case, the entire bracketed remark) is not part of the quotation. It is required whenever the to'i ... toi remark is physically within quotation marks, at least when speaking to literal-minded listeners; the convention may be relaxed if no actual confusion results.
Note: The parser believes that parentheses are attached to the previous word or construct, because it treats them as syntactic equivalents of subscripts and other such so-called “free modifiers”. Semantically, however, parenthetical remarks are not necessarily attached either to what precedes them or what follows them.
The cmavo sei (of selma'o SEI) begins an embedded discursive bridi. Comments added with sei are called “metalinguistic” , because they are comments about the discourse itself rather than about the subject matter of the discourse. This sense of the term “metalinguistic” is used throughout this chapter, and is not to be confused with the sense “language for expressing other languages”.
When marked with sei , a metalinguistic utterance can be embedded in another utterance as a discursive. In this way, discursives which do not have cmavo assigned in selma'o UI can be expressed:
Using the happiness attitudinal, .ui , would imply that the speaker was happy. Instead, the speaker attributes happiness to Frank. It would probably be safe to elide the one who is happy, and say:
The grammar of the bridi following sei has an unusual limitation: the sumti must either precede the selbri, or must be glued into the selbri with be and bei :
This restriction allows the terminator cmavo se'u to almost always be elided.
Since a discursive utterance is working at a “higher” level of abstraction than a non-discursive utterance, a non-discursive utterance cannot refer to a discursive utterance. Specifically, the various back-counting, reciprocal, and reflexive constructs in selma'o KOhA ignore the utterances at “higher” metalinguistic levels in determining their referent. It is possible, and sometimes necessary, to refer to lower metalinguistic levels. For example, the English “he said” in a conversation is metalinguistic. For this purpose, quotations are considered to be at a lower metalinguistic level than the surrounding context (a quoted text cannot refer to the statements of the one who quotes it), whereas parenthetical remarks are considered to be at a higher level than the context.
Lojban works differently from English in that the “he said” can be marked instead of the quotation. In Lojban, you can say:
which literally claims that John uttered the quoted text. If the central claim is that John made the utterance, as is likely in conversation, this style is the most sensible. However, in written text which quotes a conversation, you don't want the “he said” or “she said” to be considered part of the conversation. If unmarked, it could mess up the anaphora counting. Instead, you can use:
| lu | mi | klama | le | zarci | seisa'a |
| [quote] | I | go-to | the | store | ( |
| la | .djan. | cusku | be | dei | li'u |
| John | expresses | this-sentence | )[unquote] |
|
“I go to the store” , said John. |
And of course other orders are possible:
Note the sa'a following each sei , marking the sei and its attached bridi as an editorial insert, not part of the quotation. In a more relaxed style, these sa'a cmavo would probably be dropped.
The elidable terminator for sei is se'u (of selma'o SEhU); it is rarely needed, except to separate a selbri within the sei comment from an immediately following selbri (or component) outside the comment.
The following cmavo are discussed in this section:
|
si |
SI |
erase word |
|
sa |
SA |
erase phrase |
|
su |
SU |
erase discourse |
The cmavo si (of selma'o SI) is a metalinguistic operator that erases the preceding word, as if it had never been spoken:
means the same thing as ti mlatu. Multiple si cmavo in succession erase the appropriate number of words:
In order to erase the word zo , it is necessary to use three si cmavo in a row:
| zo | .bab. | se | cmene | zo | si | si | si | la | .bab. |
| The-word | “Bob” | is-the-name-of | the | word | si | , | er, | er, | Bob. |
The first use of si does not erase anything, but completes the zo quotation. Two more si cmavo are then necessary to erase the first si and the zo.
Incorrect names can likewise cause trouble with si :
| mi | tavla | fo | la | .esperanto |
| I | talk | in-language | that-named | and-speranto, |
| si | si | .esperanton. |
| er, | er, | Esperanto. |
The Lojbanized spelling .esperanto breaks up, as a consequence of the Lojban morphology rules (see Chapter 4) into two Lojban words, the cmavo .e and the undefined lujvo speranto. Therefore, two si cmavo are needed to erase them. Of course, .e speranto is not grammatical after la , but recognition of si is done before grammatical analysis.
Even more messy is the result of an incorrect zoi :
| mi | cusku | zoi | fy. | gy. | .fy. | si | si | si | si | zo .djan | |
| I | express | [foreign] | [quote] | gy. | [unquote], | er, | er, | er, | er, | “John” | . |
In Example 19.79 , the first fy. is taken to be the delimiting word. The next word must be different from the delimiting word, and gy. , the Lojban name for the letter g , was chosen arbitrarily. Then the delimiting word must be repeated. For purposes of si erasure, the entire quoted text is taken to be a word, so four words have been uttered, and four more si cmavo are needed to erase them altogether. Similarly, a stray lo'u quotation mark must be erased with fy. le'u si si si , by completing the quotation and then erasing it all with three si cmavo.
What if less than the entire zo or zoi construct is erased? The result is something which has a loose zo or zoi in it, without its expected sequels, and which is incurably ungrammatical. Thus, to erase just the word quoted by zo , it turns out to be necessary to erase the zo as well:
The parser will reject zo .djan. si .djordj. , because in that context djordj. is a bare cmevla rather than a quoted word.
Note: The current machine parser does not implement si erasure.
As the above examples plainly show, precise erasures with si can be extremely hard to get right. Therefore, the cmavo sa (of selma'o SA) is provided for erasing more than one word. The cmavo following sa should be the starting marker of some grammatical construct. The effect of the sa is to erase back to and including the last starting marker of the same kind. For example:
Since the word following sa is .i , the sentence separator, its effect is to erase the preceding sentence. So Example 19.81 is equivalent to:
Another example, erasing a partial description rather than a partial sentence:
In Example 19.83 , le blanu .zdan. is ungrammatical, but clearly reflects the speaker's original intention to say le blanu zdani. However, the zdani was cut off before the end and changed into a cmevla. The entire ungrammatical le construct is erased and replaced by le xekri zdani.
Note: The current machine parser does not implement sa erasure. Getting sa right is even more difficult (for a computer) than getting si right, as the behavior of si is defined in terms of words rather than in terms of grammatical constructs (possibly incorrect ones) and words are conceptually simpler entities. On the other hand, sa is generally easier for human beings, because the rules for using it correctly are less finicky.
The cmavo su (of selma'o SU) is yet another metalinguistic operator that erases the entire text. However, if the text involves multiple speakers, then su will only erase the remarks made by the one who said it, unless that speaker has said nothing. Therefore susu is needed to eradicate a whole discussion in conversation.
Note: The current machine parser does not implement either su or susu erasure.
The following cmavo is discussed in this section:
|
.y. |
Y |
hesitation noise |
Speakers often need to hesitate to think of what to say next or for some extra-linguistic reason. There are two ways to hesitate in Lojban: to pause between words (that is, to say nothing) or to use the cmavo .y. (of selma'o Y). This resembles in sound the English hesitation noise written “uh” (or “er”), but differs from it in the requirement for pauses before and after. Unlike a long pause, it cannot be mistaken for having nothing more to say: it holds the floor for the speaker. Since vowel length is not significant in Lojban, the y sound can be dragged out for as long as necessary. Furthermore, the sound can be repeated, provided the required pauses are respected.
Since the hesitation sound in English is outside the formal language, English-speakers may question the need for a formal cmavo. Speakers of other languages, however, often hesitate by saying (or, if necessary, repeating) a word ( “este” in some dialects of Spanish, roughly meaning “that is”), and Lojban's audio-visual isomorphism requires a written representation of all meaningful spoken behavior. Of course, .y. has no grammatical significance: it can appear anywhere at all in a Lojban sentence except in the middle of a word.
The following cmavo is discussed in this section:
|
fa'o |
FAhO |
end of text |
The cmavo fa'o (of selma'o FAhO) is the usually omitted marker for the end of a text; it can be used in computer interaction to indicate the end of input or output, or for explicitly giving up the floor during a discussion. It is outside the regular grammar, and the machine parser takes it as an unconditional signal to stop parsing unless it is quoted with zo or with lo'u ... le'u. In particular, it is not used at the end of subordinate texts quoted with lu … li'u or parenthesized with to ... toi.
The following list gives the cmavo and selma'o that are recognized by the earliest stages of the parser, and specifies exactly which of them interact with which others. All of the cmavo are at least mentioned in this chapter. The cmavo are written in lower case, and the selma'o in UPPER CASE.
-
zo quotes the following word, no matter what it is.
-
sa erases the preceding word and other words, unless the preceding word is a zo.
-
lo'u quotes all following words up to a le'u (but not a zo le'u).
-
le'u is ungrammatical except at the end of a “lo'u quotation.
-
ZOI cmavo use the following word as a delimiting word, no matter what it is, but using le'u may create difficulties.
-
zei combines the preceding and the following word into a lujvo, but does not affect zo , si , sa , su , lo'u , ZOI cmavo, fa'o , and zei.
-
BAhE cmavo mark the following word, unless it is si , sa , or su , or unless it is preceded by zo. Multiple BAhE cmavo may be used in succession.
-
bu makes the preceding word into a lerfu word, except for zo , si , sa , su , lo'u , ZOI cmavo, fa'o , zei , BAhE cmavo, and bu. Multiple bu cmavo may be used in succession.
-
UI and CAI cmavo mark the previous word, except for zo , si , sa , su , lo'u , ZOI, fa'o , zei , BAhE cmavo, and bu. Multiple UI cmavo may be used in succession. A following nai is made part of the UI.
-
.y. , da'o , fu'e , and fu'o are the same as UI, but do not absorb a following nai.
The following list shows all the elidable terminators of Lojban. The first column is the terminator, the second column is the selma'o that starts the corresponding construction, and the third column states what kinds of grammatical constructs are terminated. Each terminator is the only cmavo of its selma'o, which naturally has the same name as the cmavo.
|
be'o |
BE |
sumti attached to a tanru unit |
|
boi |
PA/BY |
number or lerfu string |
|
do'u |
COI/DOI |
vocative phrases |
|
fe'u |
FIhO |
ad-hoc modal tags |
|
ge'u |
GOI |
relative phrases |
|
kei |
NU |
abstraction bridi |
|
ke'e |
KE |
groups of various kinds |
|
ku |
LE/LA |
description sumti |
|
ku'e |
PEhO |
forethought mekso |
|
ku'o |
NOI |
relative clauses |
|
li'u |
LU |
quotations |
|
lo'o |
LI |
number sumti |
|
lu'u |
LAhE/NAhE+BO |
sumti qualifiers |
|
me'u |
ME |
tanru units formed from sumti |
|
nu'u |
NUhI |
forethought termsets |
|
se'u |
SEI/SOI |
metalinguistic insertions |
|
te'u |
various |
mekso conversion constructs |
|
toi |
TO |
parenthetical remarks |
|
tu'u |
TUhE |
multiple sentences or paragraphs |
|
vau |
(none) |
simple bridi or bridi-tails |
|
ve'o |
VEI |
mekso parentheses |

The following paragraphs list all the selma'o of Lojban, with a brief explanation of what each one is about, and reference to the chapter number where each is explained more fully. As usual, all selma'o names are given in capital letters (with “h” serving as the capital of “'”) and are the names of a representative cmavo, often the most important or the first in alphabetical order. One example is given of each selma'o: for selma'o which have several uses, the most common use is shown.
selma'o A ( Section 14.6)
Specifies a logical connection (e.g. “and”, “or”, “if”), usually between sumti.
| la .djan. | a | la .djein. | klama | le | zarci |
| John | and/or | Jane | goes-to | the | store |
Also used to create vowel lerfu words when followed with “bu”.
selma'o BAI ( Section 9.6)
May be prefixed to a sumti to specify an additional place, not otherwise present in the place structure of the selbri, and derived from a single place of some other selbri.
| mi | tavla | bau | la .lojban. |
| I | speak | in-language | Lojban. |
selma'o BAhE ( Section 19.11)
Emphasizes the next single word, or marks it as a nonce word (one invented for the occasion).
| la ba'e .djordj. | klama | le | zarci |
| George | goes-to | the | store. |
|
It is George who goes to the store. |
selma'o BE ( Section 5.7)
Attaches sumti which fill the place structure of a single unit making up a tanru. Unless otherwise indicated, the sumti fill the x2, x3, and successive places in that order. BE is most useful in descriptions formed with LE. See BEI , BEhO.
| mi | klama | be | ta | troci | ||
| I | am-a | (goer | to | that) | type-of | trier. |
|
I try to go to that place. |
selma'o BEI ( Section 5.7)
Separates multiple sumti attached by BE to a tanru unit.
| mi | klama | be | le | zarci | bei | le | zdani | be'o | troci | ||
| I | am-a | (goer | to | the | store | from | the | home | ) | type-of | trier. |
|
I try to go from the home to the market. |
selma'o BEhO ( Section 5.7)
Elidable terminator for BE. Terminates sumti that are attached to a tanru unit.
| mi | klama | be | le | zarci | be'o | troci | ||
| I | am-a | (goer | to | the | market | ) | type-of | trier. |
|
I try to go to the market. |
selma'o BIhE ( Section 18.5)
Prefixed to a mathematical operator to mark it as higher priority than other mathematical operators, binding its operands more closely.
| li | ci | bi'e | pi'i | vo | su'i | mu | du | li | paze |
| The-number | 3 | [priority] | times | 4 | plus | 5 | equals | the-number | 17. |
|
3 × 4 + 5 = 17
|
selma'o BIhI ( Section 14.16)
Joins sumti or tanru units (as well as some other things) to form intervals. See GAhO.
| mi | ca | sanli | la .drezdn. | bi'i | la .frankfurt. |
| I | [present] | stand-on-surface | Dresden | [interval] | Frankfurt. |
|
I am standing between Dresden and Frankfurt. |
selma'o BO ( Section 5.3 , Section 15.6 , Section 18.17)
Joins tanru units, binding them together closely. Also used to bind logically or non-logically connected phrases, sentences, etc. BO is always high precedence and right-grouping.
| ta | cmalu | nixli | bo | ckule | |
| That | is-a-small | type-of | (girl | type-of | school). |
|
That is a small school for girls. |
selma'o BOI ( Section 18.6)
Elidable terminator for PA or BY. Used to terminate a number (string of numeric cmavo) or lerfu string (string of letter words) when another string immediately follows.
| li | re | du | li | vu'u | vo boi | re | |
| The-number | two | equals | the-number | the-difference-of | four | and | two. |
selma'o BU ( Section 17.4)
A suffix which can be attached to any word, typically a word representing a letter of the alphabet or else a name, to make a word for a symbol or a different letter of the alphabet. In particular, attached to single-vowel cmavo to make words for vowel letters.
| .abu | .ebu | .ibu | .obu | .ubu | .ybu |
| a, | e, | i, | o, | u, | y. |
selma'o BY ( Section 17.2)
Words representing the letters of the Lojban alphabet, plus various shift words which alter the interpretation of other letter words. Terminated by BOI.
| .abu | tavla | by | le | la .ibymym. | skami | ||
| A | talks-to | B | about | the | of- | IBM | computers. |
|
A talks to B about IBM computers. |
selma'o CAI ( Section 13.4)
Indicates the intensity of an emotion: maximum, strong, weak, or not at all. Typically follows another particle which specifies the emotion.
| .ei | cai | mi | klama | le | zarci |
| [Obligation!] | [Intense!] | I | go-to | the | market. |
|
I must go to the market. |
selma'o CAhA ( Section 10.19)
Specifies whether a bridi refers to an actual fact, a potential (achieved or not), or merely an innate capability.
| ro | datka | ka'e | flulimna |
| All | ducks | [capability] | are-float-swimmers. |
|
All ducks have the capability of swimming by floating. |
selma'o CEI ( Section 7.5)
Assigns a selbri definition to one of the five pro-bridi gismu: “broda”, “brode”, “brodi”, “brodo”, or “brodu”, for later use.
|
ti slasi je mlatu bo cidja lante gacri cei broda |
|
This is a plastic cat-food can cover, or thingy. |
|
.i le crino broda cu barda .i le xunre broda cu cmalu |
|
The green thingy is large. The red thingy is small. |
selma'o CEhE ( Section 14.11 , Section 16.7)
Joins multiple terms into a termset. Termsets are used to associate several terms for logical connectives, for equal quantifier scope, or for special constructs in tenses.
| mi | ce'e | do | pe'e | je | la .djan. | ce'e | la .djeimyz. | cu | pendo |
| I | [,] | you | [joint] | and | John | [,] | James | are-friends-of. |
|
I am a friend of you, and John is a friend of James. |
selma'o CO ( Section 5.8)
When inserted between the components of a tanru, inverts it, so that the following tanru unit modifies the previous one.
| mi | troci | co | klama | le | zarci | le | zdani | |
| I | am-a-trier | of-type | (goer-to | the | market | from | the | house). |
|
I try to go to the market from the house. |
selma'o COI ( Section 6.11 , Section 13.14)
When prefixed to a cmevla, description, or sumti, produces a vocative: a phrase which indicates who is being spoken to (or who is speaking). Vocatives are used in conversational protocols, including greeting, farewell, and radio communication. Terminated by DOhU. See DOI.
| coi | .djan. |
| Greetings, | John. |
selma'o CU ( Section 9.2)
Separates the selbri of a bridi from any sumti which precede it. Never strictly necessary, but often useful to eliminate various elidable terminators.
| le | gerku | cu | klama | le | zarci |
| The | dog | goes-to | the | store. |
selma'o CUhE ( Section 10.24)
Forms a question which asks when, where, or in what mode the rest of the bridi is true. See PU , CAhA , TAhE , and BAI.
| do | cu'e | klama | le | zarci |
| You | [When/Where?] | go-to | the | store? |
|
When are you going to the store? |
selma'o DAhO ( Section 7.13)
Cancels the assigned significance of all sumti cmavo (of selma'o KOhA) and bridi cmavo (of selma'o GOhA).
selma'o DOI ( Section 13.14)
The non-specific vocative indicator. See DOhU.
| doi | .frank. | mi | tavla | do |
| O | Frank, | I | speak-to | you. |
|
Frank, I'm talking to you. |
selma'o DOhU ( Section 13.14)
Elidable terminator for COI or DOI. Signals the end of a vocative.
| coi | do'u |
| Greetings | [terminator] |
|
Greetings, O unspecified one! |
selma'o FA ( Section 9.3)
Prefix for a sumti, indicating which numbered place in the place structure the sumti belongs in; overrides word order.
| fa | mi | cu | klama | fi | la .atlantas. |
| x1= | I | go | x3= | Atlanta |
| fe | la .bastn. | fo | le | dargu | fu | le | karce |
| x2= | Boston | x4= | the | road | x5= | the | car. |
|
I go from Atlanta to Boston via the road using the car. |
selma'o FAhA ( Section 10.2)
Specifies the direction in which, or toward which (when marked with MOhI) or along which (when prefixed by VEhA or VIhA) the action of the bridi takes place.
| le | nanmu | zu'a | batci | le | gerku |
| The | man | [left] | bites | the | dog. |
|
To my left, the man bites the dog. |
selma'o FAhO ( Section 19.15)
A mechanical signal, outside the grammar, indicating that there is no more text. Useful in talking to computers.
selma'o FEhE ( Section 10.11)
Indicates that the following interval modifier (using TAhE , ROI , or ZAhO) refers to space rather than time.
| ko | vi'i | fe'e | di'i | sombo | le | gurni |
| You-imperative | [1-dimensional] | [space] | [regularly] | sow | the | grain. |
|
Sow the grain in a line and evenly! |
selma'o FEhU ( Section 9.5)
Elidable terminator for FIhO. Indicates the end of an ad hoc modal tag: the tagged sumti immediately follows.
| mi | viska | do | fi'o | kanla | [fe'u] | le | zunle |
| I | see | you | [modal] | eye | : | the | left-thing |
|
I see you with the left eye. |
selma'o FIhO ( Section 9.5)
When placed before a selbri, transforms the selbri into a modal tag, grammatically and semantically equivalent to a member of selma'o BAI. Terminated by FEhU.
| mi | viska | do | fi'o | kanla | le | zunle |
| I | see | you | with | eye | the | left-thing |
|
I see you with my left eye. |
selma'o FOI ( Section 17.6)
Signals the end of a compound alphabet letter word that begins with TEI. Not an elidable terminator.
| tei | .ebu | .akut. bu | foi |
| ( | “e” | “acute” | ) |
|
the letter “e” with an acute accent |
selma'o FUhA ( Section 18.16)
Indicates that the following mathematical expression is to be interpreted as reverse Polish (RP), a mode in which mathematical operators follow their operands.
| li | fu'a | reboi | re[boi] | su'i | du | li | vo |
| the-number | [RP!] | two, | two, | plus | equals | the-number | four |
|
2 + 2 = 4
|
selma'o FUhE ( Section 19.8)
Indicates that the following indicator(s) of selma'o UI affect not the preceding word, as usual, but rather all following words until a FUhO.
| mi | viska | le | fu'e | .ia | blanu | zdani | fu'o | ponse |
| I | see | the | [start] | [belief] | blue | house | [end] | possessor |
|
I see the owner of a blue house, or what I believe to be one. |
selma'o FUhO ( Section 19.8)
Cancels all indicators of selma'o UI which are in effect.
| mi | viska | le | fu'e | .ia | blanu | zdani | fu'o | ponse |
| I | see | the | [start] | [belief] | blue | house | [end] | possessor. |
|
I see the owner of what I believe to be a blue house. |
selma'o GA ( Section 14.5)
Indicates the beginning of two logically connected sumti, bridi-tails, or various other things. Logical connections include “both ... and”, “either ... or”, “if ... then”, and so on. See GI.
|
ga la .djan. nanmu gi la .djeimyz. ninmu |
|
Either John is a man or James is a woman (or both). |
selma'o GAhO ( Section 14.16)
Specifies whether an interval specified by BIhI includes or excludes its endpoints. Used in pairs before and after the BIhI cmavo, to specify the nature of both the left- and the right-hand endpoints.
| mi | ca | sanli | la .drezdn. |
| I | [present] | stand | Dresden |
| ga'o | bi'i | ga'o | la .frankfurt. |
| [inclusive] | [interval] | [inclusive] | Frankfurt. |
|
I am standing between Dresden and Frankfurt, inclusive of both. |
selma'o GEhU ( Section 8.3)
Elidable terminator for GOI. Marks the end of a relative phrase. See KUhO.
| la .djan. | goi | ko'a | ge'u | blanu |
| John | (referred to as | it-1 | ) | is-blue. |
selma'o GI ( Section 14.5)
Separates two logically or non-logically connected sumti, tanru units, bridi-tails, or other things, when the prefix is a forethought connective involving GA , GUhA , or JOI.
|
ge la .djan. nanmu gi la .djeimyz. ninmu |
|
(It is true that) both John is a man and James is a woman. |
selma'o GIhA ( Section 14.3)
Specifies a logical connective (e.g. “and”, “or”, “if”) between two bridi-tails: a bridi-tail is a selbri with any associated following sumti, but not including any preceding sumti.
| mi | klama | le | zarci | gi'e | nelci | la .djan. |
| I | go-to | the | market | and | like | John. |
selma'o GOI ( Section 8.3)
Specifies the beginning of a relative phrase, which associates a subordinate sumti (following) to another sumti (preceding). Terminated by GEhU See NOI.
| la .djan. | goi | ko'a | cu | blanu |
| John | (referred to as | it-1) | is-blue. |
selma'o GOhA ( Section 7.6)
A general selma'o for all cmavo which can take the place of brivla. There are several groups of these.
|
A: mi klama le zarci |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
B: mi go'i |
|
A: I'm going to the market. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
B: Me, too. |
selma'o GUhA ( Section 14.3)
Indicates the beginning of two logically connected tanru units. Takes the place of GA when forming logically-connected tanru. See GI.
| la .alis. | gu'e | ricfu | gi | blanu |
| Alice | is both | rich | and | blue. |
selma'o I ( Section 19.2)
Separates two sentences from each other.
| mi | klama | le | zarci | .i | mi | klama | le | zdani |
| I | go-to | the | market | . | I | go-to | the | house. |
selma'o JA ( Section 14.3)
Specifies a logical connection (e.g. “and”, “or”, “if”) between two tanru units, mathematical operands, tenses, or abstractions.
| ti | blanu | je | zdani |
| This | is-blue | and | a-house. |
selma'o JAI ( Section 9.12)
When followed by a tense or modal, creates a conversion operator attachable to a selbri which exchanges the modal place with the x1 place of the selbri. When alone, is a conversion operator exchanging the x1 place of the selbri (which should be an abstract sumti) with one of the places of the abstracted-over bridi.
| mi | jai gau | galfi | le | bitmu | se skari |
| I | am-the-actor-in | modifying | the | wall | color. |
|
I act so as to modify the wall color. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
I change the color of the wall. |
selma'o JOI ( Section 14.14)
Specifies a non-logical connection (e.g. together-with-as-mass, -set, or -sequence) between two sumti, tanru units, or various other things. When immediately followed by GI , provides forethought non-logical connection analogous to GA.
| la .djan. | joi | la .alis. | cu | bevri | le | pipno |
| John | massed-with | Alice | carry | the | piano. |
selma'o JOhI ( Section 18.15)
Indicates that the following mathematical operands (a list terminated by TEhU) form a mathematical vector (one-dimensional array).
| li | jo'i | paboi | reboi | te'u | su'i | jo'i | ciboi | voboi | du |
| The-number | array( | one, | two | ) | plus | array( | three, | four) | equals |
| li | jo'i | voboi | xaboi |
| the-number | array( | four, | six). |
|
(1,2) + (3,4) = (4,6)
|
selma'o KE ( Section 5.5)
Groups everything between itself and a following KEhE for purposes of logical connection, tanru construction, or other purposes. KE and KEhE are not used for mathematical (see VEI and VEhO) or discursive (see TO and TOI) purposes.
| ta | ke | melbi | cmalu | ke'e | nixli | ckule |
| That | is-a-( | pretty | little | ) | girl | school. |
|
That is a school for girls who are pretty in their littleness. |
selma'o KEI ( Section 11.1)
Elidable terminator for NU. Marks the end of an abstraction bridi.
| la .djan. | cu | nu | sonci | kei | djica | |
| John | is-an-(event-of | being-a-soldier | ) | type-of | desirer. |
|
John wants to be a soldier. |
selma'o KEhE ( Section 5.5)
Elidable terminator for KE. Marks the end of a grouping.
| ta | ke | melbi | cmalu | ke'e | nixli | ckule |
| That | is-a-( | pretty | little | ) | girl | school. |
|
That is a school for girls who are pretty in their littleness. |
selma'o KI ( Section 10.13)
When preceded by a tense or modal, makes it “sticky”, so that it applies to all further bridi until reset by another appearance of KI. When alone, eliminates all sticky tenses.
selma'o KOhA ( Section 7.1)
A general selma'o which contains all cmavo which can substitute for sumti. These cmavo are divided into several groups.
| le | blanu | zdani | goi | ko'a | cu | barda |
| The | blue | house | (referred to as | it-1) | is-big. |
| .i | ko'a | na | cmamau | ti |
| It-1 | is-not | smaller-than | this-thing. |
selma'o KU ( Section 6.2 , Section 10.1)
Elidable terminator for LE and some uses of LA. Indicates the end of a description sumti. Also used after a tense or modal to indicate that no sumti follows, and in the compound NA + KU to indicate natural language-style negation.
| le | prenu | ku | le | zdani | ku | klama | |
| The | person | , | to | the | house | , | goes. |
|
The person goes to the house. |
selma'o KUhE ( Section 18.6)
Elidable terminator for PEhO : indicates the end of a forethought mathematical expression (one in which the operator precedes the operands).
| li | pe'o | su'i | reboi | reboi | re[boi] | ku'e |
| The-number | [forethought] | the-sum-of | two | two | two | [end] |
| du | li | xa |
| equals | the-number | six. |
selma'o KUhO ( Section 8.1)
Elidable terminator for NOI. Indicates the end of a relative clause.
| le | zdani | poi | blanu | ku'o | barda |
| The | house | that( | is-blue | ) | is-big. |
selma'o LA ( Section 6.2)
Descriptors which change name words (or selbri) into sumti which identify people or things by name. Similar to LE. May be terminated with KU if followed by a description selbri.
| la .kikeros. | du | la .tulis. |
| Cicero | is | Tully. |
selma'o LAU ( Section 17.14)
Combines with the following alphabetic letter to represent a single marker: change from lower to upper case, change of font, punctuation, etc.
| tau | sy | .ibu |
| [single-shift] | “s” | “i” |
|
Si (chemical symbol for silicon) |
selma'o LAhE ( Section 6.10)
Qualifiers which, when prefixed to a sumti, change it into another sumti with related meaning. Qualifiers can also consist of a cmavo from selma'o NAhE plus BO. Terminated by LUhU.
| mi | viska | la'e | zoi | .kuot. | A Tale of Two Cities | .kuot |
| I | see | that-represented-by | the-text | “ | A Tale of Two Cities | ”. |
|
I see the book “A Tale of Two Cities”. |
selma'o LE ( Section 6.2)
Descriptors which make selbri into sumti which describe or specify things that fit into the x1 place of the selbri. Terminated by KU. See LA.
| le | gerku | cu | klama | le | zdani |
| The | dog | goes-to | the | house. |
selma'o LEhU ( Section 19.9)
Indicates the end of a quotation begun with LOhU. Not an elidable terminator.
| lo'u | mi du do du mi | le'u | cu | na | lojbo | drani |
| [quote] | mi du do du mi | [unquote] | is-not | Lojbanically | correct. |
|
“mi du do du mi” is not correct Lojban. |
selma'o LI ( Section 18.5)
Descriptors which change numbers or other mathematical expressions into sumti which specify numbers or numerical expressions. Terminated by LOhO.
| li | re | vu'u | re | na | du | li | vo | su'i | vo |
| The-number | 2 | minus | 2 | not | equals | the-number | 4 | plus | 4. |
|
2 - 2 ≠ 4 + 4
|
selma'o LIhU ( Section 19.9)
Elidable terminator for LU. Indicates the end of a text quotation.
| mi | cusku | lu | mi | klama | le | zarci | li'u |
| I | express | [quote] | I | go-to | the | market | [end-quote]. |
selma'o LOhO ( Section 18.17)
Elidable terminator for LI. Indicates the end of a mathematical expression used in a LI description.
| li | vo | lo'o | li | ci | lo'o | cu | zmadu |
| The-number | 4 | [end-number], | the-number | 3 | [end-number], | is-greater. |
|
4 > 3 |
selma'o LOhU ( Section 19.9)
Indicates the beginning of a quotation (a sumti) which is grammatical as long as the quoted material consists of Lojban words, whether they form a text or not. Terminated by LEhU.
| do | cusku | lo'u | mi du do du ko'a | le'u |
| You | express | [quote] | mi du do du ko'a | [end-quote]. |
|
You said, “mi du do du ko'a”. |
selma'o LU ( Section 19.9)
Indicates the beginning of a quotation (a sumti) which is grammatical only if the quoted material also forms a grammatical Lojban text. Terminated by LIhU.
| mi | cusku | lu | mi | klama | le | zarci | li'u |
| I | express | [quote] | I | go-to | the | market | [end-quote]. |
selma'o LUhU ( Section 6.10)
Elidable terminator for LAhE and NAhE + BO. Indicates the end of a qualified sumti.
| mi | viska | la'e | lu | barda | gerku | li'u | lu'u |
| I | see | the-referent-of | [quote] | big | dog | [end-quote] | [end-ref] |
|
I saw “Big Dog” [not the words, but a book or movie]. |
selma'o MAI ( Section 18.19 , Section 19.1)
When suffixed to a number or string of letter words, produces a free modifier which serves as an index number within a text.
| pamai | mi | pu | klama | le | zarci |
| 1-thly, | I | [past] | go-to | the | market. |
|
First, I went to the market. |
selma'o MAhO ( Section 18.6)
Produces a mathematical operator from a letter or other operand. Terminated by TEhU. See VUhU.
| ma'o | fy. | boi | xy. |
| [operator] | f | x |
|
f(x) |
selma'o ME ( Section 5.10 , Section 18.1)
Produces a tanru unit from a sumti, which is applicable to the things referenced by the sumti. Terminated by MEhU.
| ta | me la .ford. | karce |
| That | is-a-Ford-type | car |
|
That's a Ford car. |
selma'o MEhU ( Section 5.11)
The elidable terminator for ME. Indicates the end of a sumti converted to a tanru unit.
|
ta me mi me'u zdani |
|
That's a me type of house. |
selma'o MOI ( Section 5.11 , Section 18.18)
Suffixes added to numbers or other quantifiers to make various numerically-based selbri.
| la .djan. | joi | la .frank. | cu | bruna | remei | |
| John | in-a-mass-with | Frank | are-a-brother | type-of | twosome. |
|
John and Frank are two brothers. |
selma'o MOhE ( Section 18.18)
Produces a mathematical operand from a sumti; used to make dimensioned units. Terminated by TEhU.
| li | mo'e | re | ratcu | su'i | mo'e | re | ractu |
| The-number | [operand] | two | rats | plus | [operand] | two | rabbits |
| cu | du | li | mo'e | vo | danlu |
| equals | the-number | [operand] | four | animals. |
|
2 rats + 2 rabbits = 4 animals. |
selma'o MOhI ( Section 10.8)
A tense flag indicating movement in space, in a direction specified by a following FAhA cmavo.
| le | verba | mo'i | ri'u | cadzu | le | bisli |
| The | child | [movement] | [right] | walks-on | the | ice. |
|
The child walks toward my right on the ice. |
selma'o NA ( Section 14.3 , Section 15.7)
Contradictory negators, asserting that a whole bridi is false (or true).
|
mi na klama le zarci |
|
It is not true that I go to the market. |
Also used to construct logical connective compound cmavo.
selma'o NAI ( Section 14.3 , Section 15.7)
Negates the previous word, but can only be used with certain selma'o as specified by the grammar.
selma'o NAhE ( Section 15.4)
Scalar negators, modifying a selbri or a sumti to a value other than the one stated, the opposite of the one stated, etc. Also used with following BO to construct a sumti qualifier; see LAhE.
| ta | na'e | blanu | zdani |
| That | is-a-non- | blue | house. |
|
That is a house which is other than blue. |
selma'o NAhU ( Section 18.18)
Creates a mathematical operator from a selbri. Terminated by TEhU. See VUhU.
| li | na'u | tanjo | te'u |
| The-number | the-operator( | tangent | ) |
| vei | pai | fe'i | re | [ve'o] | du | li | ci'i |
| ( | π | / | 2 | ) | = | the-number | infinity. |
|
tan(π/2) = ∞ |
selma'o NIhE ( Section 18.18)
Creates a mathematical operand from a selbri, usually a “ ni ” abstraction. Terminated by TEhU.
| li | ni'e | ni | clani | [te'u] | pi'i |
| The-number | quantity-of | length | times |
| ni'e | ni | ganra | [te'u] | pi'i |
| quantity-of | width | times |
| ni'e | ni | condi | te'u | du | li | ni'e | ni | canlu |
| quantity-of | depth | equals | the-number | quantity-of | volume. |
|
Length × Width × Depth = Volume |
selma'o NIhO ( Section 19.3)
Marks the beginning of a new paragraph, and indicates whether it contains old or new subject matter.
selma'o NOI ( Section 8.1)
Introduces relative clauses. The following bridi modifies the preceding sumti. Terminated by KUhO. See GOI.
| le | zdani | poi | blanu | cu | cmalu |
| The | house | which | is-blue | is-small. |
selma'o NU ( Section 11.1)
Abstractors which, when prefixed to a bridi, create abstraction selbri. Terminated by KEI.
| la .djan. | cu | djica | le | nu | sonci | [kei] |
| John | desires | the | event-of | being-a-soldier. |
selma'o NUhA ( Section 18.19)
Creates a selbri from a mathematical operator. See VUhU.
| li | ni'umu | cu | nu'a va'a | li | ma'umu |
| The-number | -5 | is-the-negation-of | the-number | +5 |
selma'o NUhI ( Section 14.11 , Section 16.7)
Marks the beginning of a termset, which is used to make simultaneous claims involving two or more different places of a selbri. Terminated by NUhU.
| mi | klama | nu'i | ge | le | zarci | le | briju | ||
| I | go | [start] | both | to | the | market | from | the | office |
| nu'u | gi | le | zdani | le | ckule | [nu'u] | ||
| [joint] | and | to | the | house | from | the | school. |
selma'o NUhU ( Section 14.11)
Elidable terminator for NUhI. Marks the end of a termset.
| mi | klama | nu'i | ge | le | zarci | le | briju | ||
| I | go | [start] | both | to | the | market | from | the | office |
| nu'u | gi | le | zdani | le | ckule | [nu'u] | ||
| [joint] | and | to | the | house | from | the | school. |
selma'o PA ( Section 18.2)
Digits and related quantifiers (some, all, many, etc.). Terminated by BOI.
| mi | speni | re | ninmu |
| I | am-married-to | two | women. |
selma'o PEhE ( Section 14.11)
Precedes a logical or non-logical connective that joins two termsets. Termsets (see CEhE) are used to associate several terms for logical connectives, for equal quantifier scope, or for special constructs in tenses.
| mi | ce'e | do | pe'e | je | la .djan. | ce'e | la .djeimyz. | cu | pendo |
| I | [,] | you | [joint] | and | John | [,] | James | are-friends-of. |
|
I am a friend of you, and John is a friend of James. |
selma'o PEhO ( Section 18.6)
An optional signal of forethought mathematical operators, which precede their operands. Terminated by KUhE.
| li | vo | du | li | pe'o | su'i | reboi | re |
| The-number | four | equals | the-number | [forethought] | sum-of | two | two. |
selma'o PU ( Section 10.4)
Specifies simple time directions (future, past, or neither).
| mi | pu | klama | le | zarci |
| I | [past] | go-to | the | market. |
|
I went to the market. |
selma'o RAhO ( Section 7.6)
The pro-bridi update flag: changes the meaning of sumti implicitly attached to a pro-bridi (see GOhA) to fit the current context rather than the original context.
|
A: mi ba lumci le mi karce |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
B: mi go'i |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
A: mi ba lumci le mi karce |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
B: mi go'i ra'o |
|
A: I [future] wash my car. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
B: I do-the-same-thing (i.e. wash A's car). |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
A: I [future] wash my car. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
B: I do-the-corresponding-thing (i.e. wash B's car). |
selma'o ROI ( Section 10.9)
When suffixed to a number, makes an extensional tense (e.g. once, twice, many times).
| mi | reroi | klama | le | zarci |
| I | twice | go-to | the | market. |
selma'o SA ( Section 19.13)
Erases the previous phrase or sentence.
| mi | klama | sa | do | klama | le | zarci |
| I | go, | er, | you | go-to | the | market. |
selma'o SE ( Section 5.11 , Section 9.4)
Converts a selbri, rearranging the order of places by exchanging the x1 place with a specified numbered place.
| le | zarci | cu | se klama | mi |
| The | market | is-gone-to-by | me. |
Also used in constructing connective and modal compound cmavo.
selma'o SEI ( Section 19.12)
Marks the beginning of metalinguistic insertions which comment on the main bridi. Terminated by SEhU.
| la .frank. | prami | sei | gleki | [se'u] | la .djein. | |
| Frank | loves | ( | [he] | is-happy | ) | Jane. |
selma'o SEhU ( Section 19.12)
Elidable terminator for SEI and SOI. Ends metalinguistic insertions.
| la .frank. | prami | sei | gleki | se'u | la .djein. | |
| Frank | loves | ( | [he] | is-happy | ) | Jane. |
selma'o SI ( Section 19.13)
Erases the previous single word.
| mi | si | do | klama | le | zarci |
| I, | er, | you | go-to | the | market. |
selma'o SOI ( Section 7.8)
Marks reciprocity between two sumti (like “vice versa” in English).
| mi | prami | do | soi | mi |
| I | love | you | [reciprocally] | me. |
|
I love you and vice versa. |
selma'o SU ( Section 19.13)
Closes and erases the entire previous discourse.
selma'o TAhE ( Section 10.9)
A tense modifier specifying frequencies within an interval of time or space (regularly, habitually, etc.).
| le | verba | ta'e | klama | le | ckule |
| The | child | habitually | goes-to | the | school. |
selma'o TEI ( Section 17.6)
Signals the beginning of a compound letter word, which acts grammatically like a single letter. Compound letter words end with the non-elidable selma'o FOI.
| tei | .ebu | .akut. bu | foi |
| ( | “e” | “acute” | ) |
|
the letter “e” with an acute accent |
selma'o TEhU ( Section 18.15)
Elidable terminator for JOhI , MAhO , MOhE , NAhU , or NIhE. Marks the end of a mathematical conversion construct.
| li | jo'i | paboi | reboi | te'u | su'i | jo'i | ciboi | voboi | du |
| The-number | array( | one, | two | ) | plus | array( | three, | four) | equals |
| li | jo'i | voboi | xaboi |
| the-number | array( | four, | six). |
|
(1,2) + (3,4) = (4,6)
|
selma'o TO ( Section 19.12)
Left discursive parenthesis: allows inserting a digression. Terminated by TOI.
| doi | .lisas. | mi | djica | le | nu |
| O | Lisa, | I | desire | the | event-of |
| to | doi | .frank. | ko | sisti | toi | do | viska | le | mlatu |
| ( | O | Frank, | [imperative] | stop! | ) | you | see | the | cat. |
|
Lisa, I want you to (Frank! Stop!) see the cat. |
selma'o TOI ( Section 19.12)
Elidable terminator for TO. The right discursive parenthesis.
| doi | .lisas. | mi | djica | le | nu |
| O | Lisa, | I | desire | the | event-of |
| to | doi | .frank. | ko | sisti | toi | do | viska | le | mlatu |
| ( | O | Frank, | [imperative] | stop! | ) | you | see | the | cat. |
|
Lisa, I want you to (Frank! Stop!) see the cat. |
selma'o TUhE ( Section 19.2)
Groups multiple sentences or paragraphs into a logical unit. Terminated by TUhU.
| lo | xagmau | zo'u | tu'e | ganai | cidja | gi | citno |
| Some | best | : | [start] | If | food, | then | new. |
| .i | ganai | vanju | gi | tolci'o | [tu'u] |
| If | wine, | then | old. |
|
As for what is best: if food, then new [is best]; if wine, then old [is best]. |
selma'o TUhU ( Section 19.2)
Elidable terminator for TUhE. Marks the end of a multiple sentence group.
selma'o UI ( Section 13.1)
Particles which indicate the speaker's emotional state or source of knowledge, or the present stage of discourse.
| .ui | la .djan. | klama |
| [Happiness!] | John | is-coming. |
|
Hurrah! John is coming! |
selma'o VA ( Section 10.2)
A tense indicating distance in space (near, far, or neither).
| le | nanmu | va | batci | le | gerku |
| The | man | [medium-distance] | bites | the | dog. |
|
Over there the man is biting the dog. |
selma'o VAU ( Section 14.9)
Elidable terminator for a simple bridi, or for each bridi-tail of a GIhA logical connection.
| mi | dunda | le | cukta | [vau] | gi'e |
| I | (give | the | book | ) | and |
| lebna | lo | jdini | vau | do | [vau] | |
| (take | some | money | ) | to/from | you. |
selma'o VEI ( Section 18.5)
Left mathematical parenthesis: groups mathematical operations. Terminated by VEhO.
| li | vei | ny. | su'i | pa | ve'o |
| The-number | ( | “n” | plus | one | ) |
| pi'i | vei | ny. | su'i | pa | [ve'o] | du |
| times | ( | “n” | plus | one | ) | equals |
| li | ny. | [bi'e] | te'a | re |
| the-number | n | [priority] | power | two |
| su'i | re | bi'e | pi'i | ny. | su'i | pa |
| plus | two | [priority] | times | “n” | plus | 1. |
|
(n + 1)(n + 1) = n
2
+ 2n + 1
|
selma'o VEhA ( Section 10.5)
A tense indicating the size of an interval in space (long, medium, or short).
selma'o VEhO ( Section 19.5)
Elidable terminator for VEI : right mathematical parenthesis.
| li | vei | ny. | su'i | pa | ve'o | pi'i |
| The-number | ( | “n” | plus | one | ) | times |
| vei | ny. | su'i | pa | [ve'o] | du |
| ( | “n” | plus | one | ) | equals |
| li | ny. | [bi'e] | te'a | re | su'i |
| the-number | n | [priority] | power | two | plus |
| re | bi'e | pi'i | ny. | su'i | pa |
| two | [priority] | times | “n” | plus | 1. |
|
(n + 1)(n + 1) = n
2
+ 2n + 1
|
selma'o VIhA ( Section 10.7)
A tense indicating dimensionality in space (line, plane, volume, or space-time interval).
| le | verba | ve'a |
| The | child | [medium-space-interval] |
| vi'a | cadzu | le | bisli |
| [2-dimensional] | walks-on | the | ice. |
|
In a medium-sized area, the child walks on the ice. |
selma'o VUhO ( Section 8.8)
Attaches relative clauses or phrases to a whole (possibly connected) sumti, rather than simply to the leftmost portion of the sumti.
| la .frank. | ce | la .djordj. | vu'o | noi | gidva | cu | zvati | le | kumfa |
| Frank | [in-set-with] | George | , | which | are-guides | , | are-in | the | room. |
|
Frank and George, who are guides, are in the room. |
selma'o VUhU ( Section 18.5)
Mathematical operators (e.g. +, −). See MAhO.
| li | mu | vu'u | re | du | li | ci |
| The-number | 5 | minus | 2 | equals | the-number | 3. |
|
5 − 2 = 3
|
selma'o XI ( Section 18.13)
The subscript marker: the following number or lerfu string is a subscript for whatever precedes it.
| xy. | xi | re |
| x | sub | 2 |
|
x
2
|
selma'o Y ( Section 19.14)
Hesitation noise: content-free, but holds the floor or continues the conversation. It is different from silence in that silence may be interpreted as having nothing more to say.
| doi | .y. | .y. | .djan |
| O, | uh, | uh, | John! |
selma'o ZAhO ( Section 10.10)
A tense modifier specifying the contour of an event (e.g. beginning, ending, continuing).
| mi | pu'o | damba |
| I | [prospective] | fight. |
|
I'm on the verge of fighting. |
selma'o ZEI ( Section 4.6)
A morphological glue word, which joins the two words it stands between into the equivalent of a lujvo.
| ta | xy. | zei | kantu | kacma |
| That | is-an-(X | ray) | camera. |
|
That is an X-ray camera. |
selma'o ZEhA ( Section 10.5)
A tense indicating the size of an interval in time (long, medium, or short).
| mi | pu | ze'i | citka |
| I | [past] | [short-interval] | eat. |
|
I ate for a little while. |
selma'o ZI ( Section 10.4)
A tense indicating distance in time (a long, medium or short time ago or in the future).
| mi | pu | zi | citka |
| I | [past] | [short-distance] | eat. |
|
I ate a little while ago. |
selma'o ZIhE ( Section 8.4)
Joins multiple relative phrases or clauses which apply to the same sumti. Although generally translated with “and”, it is not considered a logical connective.
| mi | ponse | pa | gerku | ku | poi | blabi |
| I | own | one | dog | such-that | it-is-white |
| zi'e | noi | mi | prami | ke'a |
| and | such-that-incidentally | I | love | it. |
|
I own a dog that is white and which, incidentally, I love. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
I own a white dog, which I love. |
selma'o ZO ( Section 19.10)
Single-word quotation: quotes the following single Lojban word.
| zo | si | cu | lojbo | valsi |
| The-word | “si” | is-a-Lojbanic | word. |
selma'o ZOI ( Section 19.10)
Non-Lojban quotation: quotes any text using a delimiting word (which can be any single Lojban word) placed before and after the text. The delimiting word must not appear in the text, and must be separated from the text by pauses.
| zoi | .kuot. | Socrates is mortal | .kuot. | cu | glico | jufra |
| The-text | “ | Socrates is mortal | ” | is-an-English | sentence. |
selma'o ZOhU ( Section 16.2 , Section 19.4)
Separates a logical prenex from a bridi or group of sentences to which it applies. Also separates a topic from a comment in topic/comment sentences.
| su'o | da | poi | remna |
| For-at-least-one | X | which | is-a-human, |
| ro | de | poi | finpe | zo'u | da | prami | de |
| for-all | Ys | which | are-fish | : | X | loves | Y |
|
There is someone who loves all fish. |

Lojban Machine Grammar, EBNF Version, Final Baseline
This EBNF document is explicitly dedicated to the public domain by its author, The Logical Language Group, Inc. Contact that organization at: 2904 Beau Lane, Fairfax VA 22031 USA 703-385-0273 (intl: +1 703 385 0273)
Explanation of notation: All rules have the form:
name number = bnf-expression
which means that the grammatical construct “name” is defined by “bnf-expression”.
-
Names in lower case are grammatical constructs.
-
Names in UPPER CASE are selma'o (lexeme) names, and are terminals.
-
Concatenation is expressed by juxtaposition with no operator symbol.
-
| represents alternation (choice).
-
[] represents an optional element.
-
& represents and/or. “A & B” is the same as “A | B | A B” but not “B A”. Furthermore, “A & B & C & D” permits one or more of A, B, C, and/or D, but only in that order.
-
... represents optional repetition of the construct to the left. Left-grouping is implied; right-grouping is shown by explicit self-referential recursion with no “...”
-
() serves to indicate the grouping of the other operators. Otherwise, “...” binds closer than &, which binds closer than |.
-
# is shorthand for “[free ...]” , a construct which appears in many places.
-
// encloses an elidable terminator, which may be omitted (without change of meaning) if no grammatical ambiguity results.
- text 0 =
-
[NAI ...] [CMEVLA ... # | (indicators & free ...)] [joik-jek] text-1
- text-1 2 =
-
[(I [jek | joik] [[stag] BO] #) ... | NIhO ... #] [paragraphs]
- paragraphs 4 =
- paragraph 10 =
- statement 11 =
- statement-1 12 =
- statement-2 13 =
- statement-3 14 =
- fragment 20 =
-
ek # | gihek # | quantifier | NA # | terms /VAU#/ | prenex | relative-clauses | links | linkargs
- prenex 30 =
- sentence 40 =
- subsentence 41 =
- bridi-tail 50 =
-
bridi-tail-1 [gihek [stag] KE # bridi-tail /KEhE#/ tail-terms]
- bridi-tail-1 51 =
- bridi-tail-2 52 =
- bridi-tail-3 53 =
- gek-sentence 54 =
-
gek subsentence gik subsentence tail-terms | [tag] KE # gek-sentence /KEhE#/ | NA # gek-sentence
- tail-terms 71 =
- terms 80 =
- terms-1 81 =
- terms-2 82 =
- term 83 =
- termset 85 =
-
NUhI # gek terms /NUhU#/ gik terms /NUhU#/ | NUhI # terms /NUhU#/
- sumti 90 =
- sumti-1 91 =
- sumti-2 92 =
- sumti-3 93 =
- sumti-4 94 =
- sumti-5 95 =
-
[quantifier] sumti-6 [relative-clauses] | quantifier selbri /KU#/ [relative-clauses]
- sumti-6 97 =
-
(LAhE # | NAhE BO #) [relative-clauses] sumti /LUhU#/ | KOhA # | lerfu-string /BOI#/ | LA # [relative-clauses] CMEVLA ... # | (LA | LE) # sumti-tail /KU#/ | LI # mex /LOhO#/ | ZO any-word # | LU text /LIhU#/ | LOhU any-word ... LEhU # | ZOI any-word anything any-word #
- sumti-tail 111 =
-
[sumti-6 [relative-clauses]] sumti-tail-1 | relative-clauses sumti-tail-1
- sumti-tail-1 112 =
- relative-clauses 121 =
- relative-clause 122 =
- selbri 130 =
- selbri-1 131 =
- selbri-2 132 =
- selbri-3 133 =
- selbri-4 134 =
-
selbri-5 [joik-jek selbri-5 | joik [stag] KE # selbri-3 /KEhE#/] ...
- selbri-5 135 =
- selbri-6 136 =
-
tanru-unit [BO # selbri-6] | [NAhE #] guhek selbri gik selbri-6
- tanru-unit 150 =
- tanru-unit-1 151 =
- tanru-unit-2 152 =
-
BRIVLA # | GOhA [RAhO] # | KE # selbri-3 /KEhE#/ | ME # sumti /MEhU#/ [MOI #] | (number | lerfu-string) MOI # | NUhA # mex-operator | SE # tanru-unit-2 | JAI # [tag] tanru-unit-2 | any-word (ZEI any-word) ... | NAhE # tanru-unit-2 | NU [NAI] # [joik-jek NU [NAI] #] ... subsentence /KEI#/
- linkargs 160 =
- links 161 =
- quantifier 300 =
- mex 310 =
- mex-1 311 =
- mex-2 312 =
- rp-expression 330 =
- rp-operand 332 =
- operator 370 =
-
operator-1 [joik-jek operator-1 | joik [stag] KE # operator /KEhE#/] ...
- operator-1 371 =
-
operator-2 | guhek operator-1 gik operator-2 | operator-2 (jek | joik) [stag] BO # operator-1
- operator-2 372 =
- mex-operator 374 =
-
SE # mex-operator | NAhE # mex-operator | MAhO # mex /TEhU#/ | NAhU # selbri /TEhU#/ | VUhU #
- operand 381 =
- operand-1 382 =
- operand-2 383 =
- operand-3 385 =
-
quantifier | lerfu-string /BOI#/ | NIhE # selbri /TEhU#/ | MOhE # sumti /TEhU#/ | JOhI # mex-2 ... /TEhU#/ | gek operand gik operand-3 | (LAhE # | NAhE BO #) operand /LUhU#/
- number 812 =
- lerfu-string 817 =
- lerfu-word 987 =
- ek 802 =
- gihek 818 =
- jek 805 =
- joik 806 =
- interval 932 =
- joik-ek 421 =
- joik-jek 422 =
- gek 807 =
- guhek 808 =
- gik 816 =
- tag 491 =
- stag 971 =
- tense-modal 815 =
- simple-tense-modal 972 =
-
[NAhE] [SE] BAI [NAI] [KI] | [NAhE] (time [space] | space [time]) & CAhA [KI] | KI | CUhE
- time 1030 =
-
ZI & time-offset ... & (ZEhA [PU [NAI]]) & interval-property ...
- time-offset 1033 =
- space 1040 =
-
VA & space-offset ... & space-interval & (MOhI space-offset)
- space-offset 1045 =
- space-interval 1046 =
- space-int-props 1049 =
- interval-property 1051 =
- free 32 =
-
SEI # [terms [CU #]] selbri /SEhU/ | SOI # sumti [sumti] /SEhU/ | vocative [relative-clauses] selbri [relative-clauses] /DOhU/ | vocative [relative-clauses] CMEVLA ... # [relative-clauses] /DOhU/ | vocative [sumti] /DOhU/ | (number | lerfu-string) MAI | TO text /TOI/ | XI # (number | lerfu-string) /BOI/ | XI # VEI # mex /VEhO/
- vocative 415 =
- indicators 411 =
- indicator 413 =
-
(UI | CAI) [NAI] | Y | DAhO | FUhO
The following rules are non-formal:
FAhO is a universal terminator and signals the end of parsable input.
.alf. .alis. .can.duv. .dinas. .elis. .kublaXAN. .lu,is.karol. .maikl.turnianskis. .mulis. .saras.tizdeil. .tamtam. .teris. .zois. .a'o .a'u .a .abu .ai .ainai .au .e'a .e'o .e .ei .i .ia .ianai .ibabo .ibazabo .ibazibo .icabo .ie .iesai .iicai .ija'ebo .ije .iki'ubo .ini'ibo .iseju .iseki'ubo .isemu'ibo .o'e .o'ocu'i .oi .u'a .u'o .u'u .ua .ue .uesai .uinai .uisai .uisaidai .uo .uu ba'e ba'o ba badri bajra baku banfi banli banzu barda bartu bazi baziku bazu be'o be bebna bei bernanjudri bersa berti bi'unai bilga bitmu blabi blaci bo botpi bradi brife bu'o bu'u bu by.by. ca'o ca cabdei cabna cadzu cafne caku canci canko canlu carmi carna cartu carvi casnu catlu ce'u ce cedra censa cerni certu ci ciblu cidni cikna cilce cilre cimoi cinla cipni ciska citka cizra ckaji ckiku ckule cladu clani clira cliva cmacma cmalu cmana cmene cnebo cnita co'a co'e co'i co'u co condi cpana crane crepu crino ctuca cu'i cu cukta culno cumki cupra curmi cusku cuxna da'i da dai dakfu dandu danlu darsi darvistci daski dasni degji degygutci denpa dertu derxi di'a di'e di'u dirba dirce dizlo djedi djica djuno do'anai do doi donri drani drata drudi du'e du'u du fa'a fa'u fa facki fadni fagri fai fanmo fanza farlu fasnu fau fe'u fe ferti fi'o fi finpe finti flaume flecu fo foldi fu'e fu'o ga'u ga ganai ganlo ganse gapru gaskre gasnu gau ge genxu gi'a gi'e gi'i gi gidva glare gleki go'i goi grana grutrxananase gugde gundi gunse gusni ja'e ja'o ja jai jalge jamfu jamna janco jarco javni jbini jdari jdice jduli je'a je'e je'u je jei jenai jersi jetce jetnu jgari ji'a ji'asai ji'i jibni jinto jinvi jo'u joi ju'a ju'i ju'o jubme jukpa junla ka'e ka'u ka kabri kajna kakne kalri kanla kansa kau kavbu ke'a ke kei kelci kerlo kevna ki'u ki kilto klama ko kojna korbi korcu kosta krefu krixa krorinsa kruji ku'i ku kucli kumfa kunti la'a la'asai la'e la'edi'e la'edi'u la ladru lanzu le'e le'i le ledu'u lego'i lei leka lenei lenku lenu lerci lerfu lesi'o li'u li lifri lindi linji linsi lisri litru lo'e lo'i lo loi loldi lonu lu'a lu'i lu lubu ma mai makau mamta manci manku mapti marji masno matne me'e me mei melbi menli mensi mi'a mi'o mi midju milxe minde minli mintu mixre mlana mlatu mo'i mo'o mo'u morji morsi mu'a mu'anai mu'i mu mukti mulno murta mutce muvdu my. na'e na nai najnimre naku nanba nanla ne'a ne'i ne ni'a ni'o nicte ninmu nixli no noi noroi nu'o nu nupre nuzlo pa'o pa pacna pagre palta pamai pamoi panci pare'uku pau pe'a pe'i pe pei pelji pendo penmi pensi pezli pi'i pimlu pinta pinxe pixra plipe pluka pluta po'o poi polje porsi prali prenu preti prije prina pu'i pu'o pu pulji punji purdi ractu rai raktu ranji rarna ratcu re'o re remai remei remna rere'u retsku ri'a ri rigni rinka rirxe ro'a ro roi ru'u ru rutrceraso sai sakta salpo sampu sance sanga sanji sanli sanmi savru se'i se sedu'u sei seja'eku sela'u semu'ibo senva serti siclu sidju simlu simsa simxu sipna sirji skicu slabu sligu smacu smudukti smuni snada so'i so'o so'u solji solri sovda spaji spati spuda spusku sraji sraku sralo sruri stedu stela stuzi su'e su'o su'oroi sudga suksa sunsicyjudri sutra ta'e ta'eku ta'i ta'o tadji tagji tai tatpi tavla tcadu tcidu tcika tcita te terdi terpa ti tirna tirxu tisna to'isa'a to'o to toi tolcanci tolpu'i tordu traji tricu trixe troci tu'a tubnu tugni tumla tunta tuple va'e va'o va'u va vacri vajni valsi vanci vasru vau ve'a vensa verba vi'i vi vikmi vindu vinji virnu viska vlipa vo vofli voi vorme vreji vrusi vu'i vu'o vu vy. xabju xajmi xalbo xamgu xamsi xance xanka xanri xanto xarci xirnzebra xo xokau xrani xruki xrula xu xunblabi xunre za'a za'o za'ure'u za zarci zbasu zdani za'u ze'a ze'e ze'i zenba zgana zi'e zi zifre zmadu zo'u zo zu'e zu'u zukte zutse zvafa'i zvati
An Aesop's fable
| ni'o la berti brife jo'u la solri | The North Wind and the Sun |
| .i la berti brife jo'u la solri pu troci leka djuno ledu'u makau traji leka vlipa vau fo le'i me lenei .icabo le pa litru noi dasni lo glare kosta cu mo'u klama | The North Wind and the Sun were disputing which was the stronger, when a traveler came along wrapped in a warm cloak. |
| .i lu'i le remei pu simxu leka tugni fi lo nu traji leka vlipa vau fa le traji be leka clira fa lonu ce'u snada leka gasnu lo nu le pa litru co'u dasni le kosta | They agreed that the one who first succeeded in making the traveler take his cloak off should be considered stronger than the other. |
| .i baku la berti brife co'a traji cupra le brife .i ku'i lonu by.by. zenba leka cupra le xokau brife cu rinka lonu le pa litru cu zukte leka zenba leka sela'u li xokau se tagji le kosta .ibazabo la berti brife co'u troci | Then the North Wind blew as hard as he could, but the more he blew the more closely did the traveler fold his cloak around him; and at last the North Wind gave up the attempt. |
| .i baku la solri co'a dirce lo milxe glare .ibazibo le pa litru co'u dasni le kosta | Then the Sun shined out warmly, and immediately the traveler took off his cloak. |
| .iseki'ubo la berti brife co'a bilga tugni fi lonu la solri cu traji leka vlipa vau fo la berti brife ce la solri | And so the North Wind was obliged to confess that the Sun was the stronger of the two. |
The text in Lojban here uses non-standard with additional punctuation marks that do not add any meaning but serve the purpose of a visual guide.
| .i le tirxu be me'e zo .teris. cu klama le barda tcadu | Terry the Tiger Visits the Big City. |
|---|---|
| ni'o la .maikl.turnianskis. di'e finti | created by Michael Turniansky |
| ni'o le pa tirxu be me'e zo .teris. pu ki kansa le za'u pendo be lenei leka xabju le foldi be loi spati .i me le bi'unai pendo fa le pa xanto be me'e zo .elis. fa le pa xirnzebra be me'e zo .zois. i la .teris. ze'e ta'e djica lenu lenei cu litru klama le pa barda tcadu noi fa'a ke'a ta'eku le'e vinji ga'u vofli klama .isemu'ibo ca pa donri la .teris. co'a cadzu klama le bi'unai barda tcadu | Terry the Tiger lived with his friends in the jungle. His friends were Elly the Elephant and Zoe the Zebra. Terry always wanted to visit the big city, where the planes flew overhead to. So one day, Terry started to walk to the big city. |
| .i baziku la .teris. co'a klama le pa rirxe gi'e retsku fi le pa finpe pe ne'i le rirxe fe le sedu'u makau pluta le tcadu .i le finpe fi la .teris. cu spusku fe lu «ko cadzu ne'a le bu'u rirxe ze'a le djedi be li ci .ibabo do viska ru li'u» .i la .teris. co'a se gidva tu'a lubu .ije ca le fanmo be le cimoi be le'i donri la .teris. cu viska le so'o te gusni pe le bi'unai .uisaidai tcadu .isemu'ibo la .teris. co'i cuxna lo ka ba cadzu ze'a le nicte | Soon, Terry came to a river, and asked a fish in it the way to the city. The fish told Terry "Walk along the river for three days, and then you will see it". Terry followed that advice. At the end of the third day, Terry saw several lights of the city (Hooray!). So Terry decided to continue walking the whole night long. |
| ni'o ca le cerni la .teris. mo'u klama le pa zarci noi se stuzi le korbi be le tcadu .i le pa nanla cu zvati le stuzi .i «lu .iicai tirxu li'u» se cusku le bi'unai nanla .i «lu .iicai nanla li'u» se cusku la .teris. (to .i le bi'unai nanla fa'u la .teris. pu no roi zgana lo tirxu fa'u lo nanla toi) .i le nanla noi se cmene zo .mulis. goi my. ganse lenu la .teris. na bradi .iseki'ubo preti fi le nanla fe lenu la .teris. cu djica lenu ri gau my. se slabu le tcadu | In the morning, Terry arrived at a marketplace, which was at the edge of the city. There was a boy there. "Aiee! A tiger!" said the boy. "Aiee! A boy!" said Terry (for the boy had never seen a tiger before, and Terry had never seen a boy before). The boy, who was Mooli, could tell that Terry was friendly, so he asked Terry if he would like to be shown the city. |
| .i «lu .iesai .i ku'i ca je'a se djica mi fa lonu mi ze'a sipna .i mi mutce leka tatpi li'u» se cusku la .teris. | "Oh, yes! But what I really want right now is some sleep. I'm very tired," said Terry. |
| .i «lu je'e do .i mi'o zifre leka klama le zdani be mi li'u» se cusku la .mulis. | "Okay, we can go to my house," said Mooli. |
| .iseki'ubo le remei cu cadzu klama le zdani be la .mulis. | So the two of them walked to Mooli's house. |
| ni'o ca lenu le remei mo'u klama le zdani vau la .mulis. cu retsku fi le mamta be ri fe «lu gau mi .e'o .e'a pei le tirxu cu kansa mi leka klama le zdani li'u» | When they got to his house, Mooli asked his mother, "Is it okay if I bring a tiger home?". |
| .i «lu .e'a doi la .mulis. li'u» se cusku le mamta .iki'ubo ri jinvi ledu'u la .mulis. cu xalbo | "Sure, Mooli" said his mother, because she thought he was just pretending. |
| .i seja'eku gau la .mulis. zvati fa la .teris. le kumfa ne my. .ije la .teris. co'a sipna ga'u je re'o le loldi .icabo la .mulis. cu zukte leka klama le bartu vau lenu my. kelci | So he brought Terry to his room, and Terry went to sleep on the floor, while Mooli went oustide to play. |
| ni'o le mamta za krixa cusku lu «doi la .mulis. ca tcika lenu vanci sanmi .i ju'i la .mulis. li'u» .i le mamta cu klama le kumfa pe la .mulis. gi'e viska la .teris. ca lenu ri sipna .i le mamta co'a krixa cusku «lu .iicai le tirxu co'i citka le bersa be mi .i doi pulji ko sidju .i ko sidju .i doi pulji .i tirxu .i tirxu .i ko sidju li'u» gi'e to'o bajra | A while later, his mother called, "Mooli, time for dinner... Mooli?" She went to Mooli's room and saw Terry, who was sleeping. She cried out, "Aaaah! A tiger has eaten my son! Police, help! Help! Police! Tiger! Tiger! Help!" and ran out. |
| .i le savru cu mukti le ka co'a cikna vau la .teris. i ri plipe pa'o le canko gi'e bajra klama le zdani be lenei bei ne'i le foldi be loi spati gi'e nupre fi lenei fe leka noroi ba cliva le bi'unai foldi | The noise woke Terry, who leaped through the window, and ran back to his home in the jungle, promising never again to leave it. |
A short story by the Bulgarian writer Elin Pelin translated to Lojban and English.
| le ricfoi crida | Forest nymph |
|---|---|
| .i penmi fa mi fi le noi condi ku'o fenra be lo ricfoi .i ra ca'o zutse fau lo nu ra badri gi'e ba'o klaku vau ne'a le crino korbi be le klina rirxe be ve'i .i le murta taxfu noi klina gi'e kluza tai lo nu cerni bumru ne'a lo rirxe cu gacri le pluka xadni be ra .i lei kerfu ku noi viknu cu tcena le snime blabi janco be le birka be ra tai lo nu lo citno dalgidva cu jai gau muvdu fa lo dalgunma be lo co'a ruble lo salpo lo salpo .i le mutce cmalu jamfu be ra ca'o se lumci le flecu be le klina rirxe be ve'i .i ne'a ra zvati fa le noi se renro gi'e ba'o vifne ku'o za'u ricfoi xrula e le pa se jivbu be fi lo pelxu primula | My encounter happened in the deep forest ravines. She was sitting, sad and tearful, by the verdant bank of a clear stream. Transparent and mottled like river morning mist, a veil covered her enchanting figure. Luxuriant, golden hair cascaded down her snow-white shoulders, like a young shepherd spreading a feeble flock from slope to slope. Her tiny marble-like feet were being washed by the currents of the clear stream. Beside her lay discarded wilted forest flowers and a wreath of yellow primroses. |
| .i ra fau gi mi zgana gi co'i suksa muvdu gi'e ba bo toldarsi jai gau jmaji fai le'i korbi be le banli murta pe ra fau lo nu ra bredi lo ka ba bajra klama fi | Upon seeing me, she flinched and shyly gathered the edges of her marvelous veil, ready to flee. |
| .i fe lu e'o do stali doi pluka ninmu cu cladu cusku fa mi fau lo nu mi manci gi'e prami | «Wait, enchanting maiden,» I exclaimed, captivated and in love. |
| .i ra terpa zgana mi lo ka se kanla lo skari be lo ka bluueta .i je ra zi mipri le kanla le nenri be le kalgaikre noi xekri gi'e viknu .i ba bo ra jai gau dizlo fai le stedu .i ra frati lo ka se molmla nu'i ge co'u ku lo blabi gi co'a ku lo xunre ne tai lo rozgu .i le re zabna cinje noi cmalu lo ka simsa lo punli be lo dizlo be lo pezli be le'e spatirusku cu xanka slilu ti'a le korbi be le xunre je cmalu moklu be ra .i le blabi cnebo be ra cu kelci minra lo carmi fo le cpana be le lunbe tatru be ra tai lo nu le nei cu vinmirtci | She looked at me fearfully with her cornflower-blue eyes and instantly hid them under thick, black lashes. Then she bowed her head. Maidenly shyness bloomed like magnificent roses on her pale cheeks. Two nimble dimples, tiny as a stipule of butcher's-broom, quivered nervously behind the corners of her small, crimson lips. From her white neck, a light reflection, as if from a mirror, played upon her bare, virgin chest. |
| .i mi co'a sanli ca'u ra tai da'i lo nu mi manci .i ra na zgana mi .i mo'u ciska lu'e lo nu ze'e badri kei fi le flira be ra ije fi le viknu kalgaikre be ra cu porsi farlu le se klaku noi barda gi'e klina ku'o tai le nu le nei cu jemna .i je le flecu cu bevri le go'i le cnita .i le ricfoi cu lenku gi'e smaji .i fa le noi renvi fi le nanca be li pa no no ku'o tricu cu na'e muvdu stali gi'e ca'o pensi su'o da .i'u nai | I stood before her as if amazed. She wasn't looking at me. Endless sorrow was written on her face; one after another, large bright tears dripped from her thick lashes, like pearls, and a stream carried them away. The forest was cold and silent. The centuries-old trees stood motionless, contemplating something. |
| .i fe lu ko skicu fi mi doi pluka ninmu cu cladu cusku fa mi fau lo nu nu mi manci .i ba bo go'i lu do klesi ma li'u | «Tell me, lovely maiden,» I cried out in awe, «who are you?» |
| .i ra stodi lo ka smaji | She remained silent. |
| .i lu do klesi ma .i je ki'u ma do badri be tai klaku .i xu do co'a cirko tu'a le farna .i pei do co'u djuno fi le farna be fi le bu'u mabla ricfoi li'u co'e | «Who are you, and why do you cry so bitterly? Are you lost? Have you lost your way in this dreadful forest?» |
| .i ra zukte lo ka zgana mi lo ka se kanla be le blabi blanu gi'e cusku bai le nu klaku kei | She looked at me with her light blue eyes and said through tears: |
| fe lu mi ricfoi crida li'u | «I am a forest nymph.» |
| .i le valsi be ra cu se bacru ta'i lo nu tolycladu gi'e kukte pe'a tai lo nu le nei cu se sanga .i ra co'a ku sanli gi'e jai gau muvdu le trixe fai le korbi be le murta taxfu poi ra dasni | Her words sounded quietly and sweetly, like a song. She stood up and again pulled back the edges of her veil. |
| .i fe lu .e'o sai doi do'u .e'o .e'o doi le ricfoi ninmu do'u .e'o mi catlu do cu pikci cusku fa mi .i ba bo go'i lu pu ki ca le po'o nai nu mi zvati le ckana be fi lo'e cifnu cu skicu fi mi fe lo zabna ranmi be do fe la'e lo se sanga poi jufra do .i je mi manci gi'e audji lo ka co'a zgana do .i mi ca le nu mi verba kei so'i roi ku ca lo nicte cu senva tu'a do fe lo nu do sanga fi mi fe lo jai se manci gi'e punji fi le stedu be mi fe lo xrula noi ja'e jadni ri | «Please, wait, wait, beautiful forest maiden, wait for me to gaze upon you,» I implored and continued, «Ever since my poor cradle, I have heard wondrous tales and songs of you, and I have been enchanted, longing to see you. In many nights of my childhood, you appeared in my dreams, singing me enchanting songs, adorning my head with flowers. |
| .i ca le nu mi cilce verba be pu zi ku do ca'o raktu mi lo ka senva ma kau gi'e jai se senva mi fai lo nu do fagri gi'e kavbu gi'e jgari mi le ka se xance lo milxe glare kei tai lo nu do ralci gi'e milxe satre gi'e se panci lo ricfoi xrula gi'e vindu ja'e lo nu de'a sanji .i mi pu ta'e senva lo nu mi jersi do ije le risna be mi pu ku audji tu'a do gi'e prami do .i pu ta'e ku ca lo nicte mi di'a cikna tai lo da'i nu mi tirna lo nicte se sanga be do gi'e viska lo nu do vofli ni'a lei cizra tsani .i ku'i do .i do pu zvati ma ja'e lo nu mi tu'a do na ku ka'e ku viska gi'a tirna .i ba'e nau ku mi ta'e catlu le ricfoi gi'e zgana ri fau lo nu mi pacna gi'e djica lo nu mi cliva le cladu tcadu te zu'e lo nu mi klama gi'e penmi do li'u | When I was a turbulent youth, you still disturbed my nights and appeared fiery and captivating, embracing me passionately in your warm embrace, tender, caressing, smelling of forest flowers and intoxicating to oblivion. Long have you haunted my dreams, long has my heart desired and loved you. At night in secret hours, I have awoke to hear your nocturnal songs, to see you soaring under mysterious skies! But you? Where were you, that I could neither see you nor hear you? Even now, I turn my eyes to the forests and look at them with hope and desire to leave the noisy city, to go and search for you...» |
| .i fe lu do xabju lo tcadu vau je'u pei li'u se spaji je cladu cusku fa le ricfoi ninmu gi'e catlu mi ta'i lo nu ra se rigni ije le moklu be ra co'a se cinje ije cusku lu lo je'u pei tcadu .i do me le jai gau cliva fai mi'a le za'u ricfoi .i zabna .i mi mo'u kavbu do .i .ai mi venfu do tu'a ro do'o .i ko ciksi .i mu'i ma do'o pu ku lebna tu'a le dalgidva gi'e jmina le te rirxe le naxle gi'e katna le za'u ricfoi pe mi'a gi'e jai gau bilma fai le za'u cmana pe mi'a fi lo ka se savru le se cupra be le do'o trene .i mu'i ma do'o pu jai gau zandi fai le vacri le danmo be lo fanri .i mu'i ma do gasnu le nu le prenu co'u gleki gi'e co'u zifre lo ka na kurji kei gi'e co'u ka'e prami .i mu'i ma li'u | «You are from the cities, aren't you?» the forest maiden exclaimed incredulously, looking at me disdainfully. Her lips curled with malice. «From the cities, aren't you? You are one of those people who drove us out of the forests? Well then! You've fallen into my hands... I will take revenge on you for all of us. Speak! Why did you take away our shepherds, why did you divert the forest rivers into canals, why did you cut down our forests, why do you deafen our mountains with the screams of railways, why did you spoil the air with factory smoke, why did you take away joy and carefreeness from people's hearts, why did you make them unable to love? Why?» |
| .i le ricfoi ninmu cu fengu darxi le loldi le jamfu gi'e melbi pilno le lunbe xance lo nu cnici fa le cilce kerfa be ra .i je ja'e le nu ra fengu kei ra co'a klaku cusku | The forest maiden stamped her foot angrily, gracefully adjusted her wild hair with her bare hands, and cried out with a voice full of anger: |
| lu .ia nai .i mi ba'o xlura ke ricfoi crida .i mi'a ba'o simxu lo ka kansa fi lo ka vofli bu'u lo ricfoi .i mi'a ba'o zukte lo ka gleki jinru lo ve'i rirxe .i mi'a ba'o cilce kelci ca lo nu le lunra cu te gusni .i mi'a ca cu spofu gi'e badri .i do'o pu lebna tu'a le citno dalgidva pe loi cmana zi'e noi se prami mi'a gi'e na'e dunku gi'e zifre .i le zgike poi sance lo flani pe le dalgidva pu je ca nai se minra fo le se stuzi be lo jbini be lo'i su'o cmana .i je le sance be le nu le dalgidva cu cinmo vasxu cu pu je ca nai se bevri ni'a le klina tsani ca lo nicte .i ba'o ku le dalgidva cu klaku fi tu'a mi'a gi'a senva tu'a mi'a gi'a zenba lo ka kandi ri'a tu'a mi'a | «Ah! I am no longer the enchanting forest nymph! We no longer fly together through the forests, we no longer happily bathe in the streams, we no longer play wildly in the moonlight. We are scattered and sad. You have taken from us the young mountain shepherds, our carefree and free-spirited lovers. In the groves, no longer do their loving flutes echo, under the clear night skies, no longer do their passionate sighs carry, they no longer wail for us, they do not yearn, they do not fade away for us... |
| .i do'o ne le za'u tcadu cu gasnu le cnino nabmi e le daspo be ge mi'a gi le dalgidva .i le dalgidva cu canci gi'e canci fau le nu ri te prina fi no da kei gi'e me le na'e cando virnu noi klama fo lu'i le foldi e le cmana fu lo ka se marce lo cilce xirma zi'e noi gasnu lo banli zi'e noi ta'e ku su'o me ke'a co'a morsi gi'a jinga .i nauku so'u roi ku su'o remna cu klama fo lu'i le klaji pe le ricfoi .i ro go'i cu ruble gi'e dunku gi'e du'e va'e pensi gi'e na'e cinmo gi'e to'e ckire gi'e badri .i le'e remna mo'u cliva mi'a gi'e na'e gleki fau le nu le nei na kansa mi'a .i le banli tcadu ku voi cpana le terdi cu cpana le spofu risna be lo remna .i le nurma tcadu cu simsa lo'e muzga be lo morsi .i bu'u le do'o banli malsi ba'o ku su'o da pikci .i mi pu prami le pa citno pe le cmana .i je ku'i ba bo le se go'i co'u prami mi gi'e cliva .i mi badri gi'e spofu .i ca le'e nicte e le'e donri mi klama fo lu'i le za'u ricfoi gi'e lausku le cmene be ra .i ku'i fliba .i le lastu flani be ra no roi se sance to'o su'o da li'u | You, from the cities, created new worries for them and destroyed us, and them... They were lost, lost without a trace, those restless heroes, who once rode wild horses over fields and mountains, performing feats, dying and winning victories. Now, scarcely will a man pass through the forest paths. And he — weak, concerned, thoughtful, soulless, embittered and sad! People left us, and they are unhappy without us. Those great cities, towering above the earth, rose above broken human hearts. Villages resemble cemeteries. In your magnificent temples, no one prays anymore. I loved a young mountaineer, but he fell out of love with me and is gone. I am sad and broken. Day and night I wander through the woods, calling out to him, crying, but in vain — his brass flute never sounds from anywhere...» |
| .i ba le nu le nei cu cusku di'u kei le crida co'a klaku | As the nymph said this, she began to cry again. |
| .i fe lu smaji .e'o .i smaji .e'o doi pindi ke ricfoi ninmu .i ko na klaku li'u cladu cusku fa mi .i ba bo go'i fe lu .i ti risna mi gi'e audji lo ka prami kei gi'e simsa le risna be do ka bu .i gau mi'o .e'ei lei nu lifri lo xlali cu pamei | «Hush, hush, poor forest maiden, do not cry,» I cried out. «Here is my heart, longing for love like yours. Come, let us unite our sufferings!» |
| .i le crida cu fengu zgana mi lo ka se kanla | The forest nymph glared at me angrily. |
| .i to'i cusku toi do xu .i do me le tcaxa'u .i va'i me le se gugde sei sa'a se cusku co masno .i te zu'e lo nu basti le dalgidva .i tai kecti do | «You? A citizen... a city-dweller? To replace my shepherd? How pitiful you are!» |
| .i ra melbi je se rigni cmila | And with disdainful beauty, she laughed at me. |
| .i ko klama doi cilce je ricfoi ninmu .i ko klama .i mi prami do .i .au mi skicu fi le prenu noi ke'a fi do co'u morji ce'e fe le nu do ca'o renvi gi'e ca'o melbi ce'e fe le nu le risna be do ca'o ka'e prami ce'e fe le nu do badri gi'e se betri | «Come, wild forest maiden, come! I love you! I want to call out to the people who have forgotten you, to remind them that you are alive, that you are still beautiful, that your heart still knows how to love, that you are sad and unhappy...» |
| .i mi co'a sanli fi le ka se tupcidni kei gi'e punji le xance le crane mu'i lo nu mi jgari ra .i fi le dakli pe mi cu farlu so'o le slecku noi mi bevri ke'a mu'i lo nu mi tcidu fi ke'a | I fell to my knees and stretched out my arms to embrace her. Out of my bag fell several volumes of books, which I was carrying for reading... |
| .i fe lu .oi li'u terpa cusku fa le crida | «Ah,» exclaimed the forest nymph in horror. |
| .i je ba le nu ra co'a jgari le klina bumru murta pe ra kei ra co'a bajra cliva | And gathering her transparent-foggy veil, she ran away. |
An extract.
| la .alis. cu zvati la se manci tumla .i finti fa la .lu,is.karol. | Alice in Wonderland. Written by Lewis Carroll. |
| ni'o ni'o pa mo'o mo'i ni'a le kevna pe le ractu | CHAPTER I. Down the Rabbit-Hole |
| ni'o la .alis. co'a tatpi lenu ri zutse re'o le mensi be .a bu goi la .alis. le korbi be le rirxe gi'e zukte fi no da .i mu'a .a bu cu so'u roi sutra catlu le cukta poi le mensi cu tcidu .i ku'i le cukta cu cukta no pixra .e no vreji be lonu casnu .i lu ja'o ma prali fi le cukta to'isa'a pensi cusku fa .abu toi fi le cukta poi cukta no pixra .e no vreji be lonu casnu li'u | Alice was beginning to get very tired of sitting by her sister on the bank, and of having nothing to do: once or twice she had peeped into the book her sister was reading, but it had no pictures or conversations in it, 'and what is the use of a book,' thought Alice 'without pictures or conversations?' |
| ni'o la .alis. ca'o se menli jdice fu'e ta'o se rai leka kakne poi se curmi le glare donri noi rinka lonu la .alis. cu lifri leka djica lonu ri sipna kei gi'e bebna fu'o fi le jei lonu pluka fa lonu zbasu lo xrula linsi cu naku naku jalge lo raktu poi nu co'a sanli gi'e crepu lo xrula .icabo suksa fa lonu le pa blabi ractu ku noi se kanla lo xunblabi cu bajra ne'a la .alis. | So she was considering in her own mind (as well as she could, for the hot day made her feel very sleepy and stupid), whether the pleasure of making a daisy-chain would be worth the trouble of getting up and picking the daisies, when suddenly a White Rabbit with pink eyes ran close by her. |
| ni'o la'edi'u na'e ba'e mutce leka cizra .i ji'a jenai la .alis. cu jinvi ledu'u ba'e mutce leka na'e fadni vau fa lonu tirna lonu ju'a le ractu cu cusku fi lenei fe lu .oi ro'a .oi ro'a mi jai lerci li'u to baku la .alis. ca lonu ri pensi la'edi'u co'a jinvi fi ri fe ledu'u da'i pu rarna fa lonu la .alis. cu manci .i ku'i caku le fasnu cu simlu leka rarna toi .i ku'i ca lonu le ractu fu'e .uesai co'a jgari le junla le daski be le kosta fu'o gi'e catlu le junla gi'e di'a sutra kei la .alis. co'a spaji sanli ki'u lonu ke pe'a lindi pagre le menli be la .alis. fa lesi'o ri pu noroi viska lo ractu poi dasni lo kosta poi se daski .a lo junla pe lonu punji to'o ri .ije la .alis. ri'a lonu ri kucli cu bajra pagre le foldi gi'e jersi le ractu gi'e .u'a viska lonu le ractu cu canci mo'i ne'i le pa barda ke kevna pe lo'e ractu zi'e noi cnita le spati bitmu | There was nothing so VERY remarkable in that; nor did Alice think it so VERY much out of the way to hear the Rabbit say to itself, 'Oh dear! Oh dear! I shall be late!' (when she thought it over afterwards, it occurred to her that she ought to have wondered at this, but at the time it all seemed quite natural); but when the Rabbit actually TOOK A WATCH OUT OF ITS WAISTCOAT-POCKET, and looked at it, and then hurried on, Alice started to her feet, for it flashed across her mind that she had never before seen a rabbit with either a waistcoat-pocket, or a watch to take out of it, and burning with curiosity, she ran across the field after it, and fortunately was just in time to see it pop down a large rabbit-hole under the hedge. |
| ni'o baziku la .alis. mo'i ne'i jersi le ractu gi'e no roi pensi lonu ta'i ba'e ma kau lenei ba di'a bartu | In another moment down went Alice after it, never once considering how in the world she was to get out again. |
| ni'o le kevna ve'a tubnu sirji gi'e suksa salpo fi lo cnita .i tai suksa .ija'ebo la .alis. na zifre leka ze'i su'o da pensi lonu ri zukte leka co'u klama vau pu lonu ju'a la .alis. ca'o farlu bu'u le pa mutce condi jinto | The rabbit-hole went straight on like a tunnel for some way, and then dipped suddenly down, so suddenly that Alice had not a moment to think about stopping herself before she found herself falling down a very deep well. |
| ni'o ga le jinto cu mutce leka condi gi la .alis. cu mutce leka masno leka farlu .ini'ibo le se ranji be lenu farlu cu banzu lonu catlu lei sruri gi'e kucli ledu'u bazi fasnu .i pamai la .alis. cu troci leka catlu le cnita gi'e facki ledu'u lenei makau klama .i ku'i manku ja'e lenu na ka'e viska .i remai la .alis. cu catlu le mlana be le jinto gi'e facki ledu'u le mlana cu culno le se kajna be fi tu'a lo kabri .a lo cukta .i la .alis. cu viska tu'a le so'o cartu .e le so'o pixra vu'o noi dandu fi le so'o genxu .i la .alis. co'a tolpu'i le pa botpi pa le kajna ca lonu lenei ne'a muvdu .i le botpi cu se tcita lu najnimre jduli li'u gi'e ku'i .u'a nai kunti .i la .alis. mu'i lonu ri terpa lonu da'i ri jai gau morsi fai su'o da cu na djica lonu ri curmi lonu le botpi cu farlu .iseki'ubo la .alis. cu sutra leka punji le botpi le pa me le se kajna ca lonu lenei ne'a farlu | Either the well was very deep, or she fell very slowly, for she had plenty of time as she went down to look about her and to wonder what was going to happen next. First, she tried to look down and make out what she was coming to, but it was too dark to see anything; then she looked at the sides of the well, and noticed that they were filled with cupboards and book-shelves; here and there she saw maps and pictures hung upon pegs. She took down a jar from one of the shelves as she passed; it was labelled 'ORANGE MARMALADE', but to her great disappointment it was empty: she did not like to drop the jar for fear of killing somebody, so managed to put it into one of the cupboards as she fell past it. |
| ni'o lu .uo to'isa'a pensi cusku fa la .alis. fi lenei toi da'i ca lonu mi ba'o farlu tai ti vau mi ba'o xanka lonu mi farlu fo lo serti .i fe lu .ua virnu li'u fa le se lanzu ba cusku co jinvi be fi mi .i .u'o mi no da cusku ba ji'asai lonu mi farlu fi lo drudi be lo zdani to'isa'a la'edi'u la'asai jetnu toi li'u | Well!' thought Alice to herself, 'after such a fall as this, I shall think nothing of tumbling down stairs! How brave they'll all think me at home! Why, I wouldn't say anything about it, even if I fell off the top of the house!' (Which was very likely true.) |
| ni'o mo'i ni'a je ni'a je ni'a .i xu lenu farlu cu noroi mulno .i lu mi farlu vi'i le minli be li xo .a'u to'isa'a cladu cusku fa la .alis. toi .i .ia mi pu'o jibni le midju be le terdi .i ka'u kilto leka minli li vo vau leka sraji to'isa'a .o'e dai bu'o la .alis. pu cilre so'o da la'edi'u le ckule .i zu'u le cabna ki'u lonu no da tirna la .alis. cu na ba'e mutce le ka mapti lonu jarco leka djuno .i zu'u nai lonu za'ure'u cusku cu xamgu la .alis. leka cilre toi .i .ie se'i le se minli cu jibni drani .i ku'i .a'u ma ti bernanjudri gi'e sunsicyjudri to la .alis. na sai djuno ledu'u makau smuni ga zo bernanjudri gi zo sunsicyjudri .i ku'i lego'i cu jinvi ledu'u melbi je banli valsi toi li'u | Down, down, down. Would the fall NEVER come to an end! 'I wonder how many miles I've fallen by this time?' she said aloud. 'I must be getting somewhere near the centre of the earth. Let me see: that would be four thousand miles down, I think—' (for, you see, Alice had learnt several things of this sort in her lessons in the schoolroom, and though this was not a VERY good opportunity for showing off her knowledge, as there was no one to listen to her, still it was good practice to say it over) '—yes, that's about the right distance—but then I wonder what Latitude or Longitude I've got to?' (Alice had no idea what Latitude was, or Longitude either, but thought they were nice grand words to say.) |
| ni'o caku la .alis. cu za'ure'u di'a cusku .i lu .a'u mi ba farlu ba'e pagre le terdi .i ba xajmi fa lenu tolcanci ne'a lo prenu poi cadzu fau lonu le stedu be ke'a cu cnita vau fa ke'a .i lo'e tai prenu cu se cmene zo smudukti pe'i to'isa'a la .alis. ca gleki lonu no da tirna .i ki'u bo lo valsi na sai drani toi .i ku'i .ei mi retsku fi lo se gugde fe le se du'u ma kau cmene le gugde .i lu pau doi ninmu ti nuzlo gi'i sralo li'u to'isa'a .i la .alis. ca lonu ri tavla cu troci leka krorinsa .i ko se xanri leka krorinsa ca lonu do farlu .i xu do snada toi .i djuno be no da ke cmalu nixli sei le ninmu ba jinvi be ki'u lonu mi retsku .i .ei mi noroi retsku .i la'a cu'i je mi viska lo cmene noi pu'i se ciska bu'u da li'u | Presently she began again. 'I wonder if I shall fall right THROUGH the earth! How funny it'll seem to come out among the people that walk with their heads downward! The Antipathies, I think—' (she was rather glad there WAS no one listening, this time, as it didn't sound at all the right word) '—but I shall have to ask them what the name of the country is, you know. Please, Ma'am, is this New Zealand or Australia?' (and she tried to curtsey as she spoke—fancy CURTSEYING as you're falling through the air! Do you think you could manage it?) 'And what an ignorant little girl she'll think me for asking! No, it'll never do to ask: perhaps I shall see it written up somewhere.' |
| ni'o mo'i ni'a je mo'i ni'a je mo'i ni'a .i ka'e zukte no drata be la'edi'e .iseki'ubo la .alis. za'ure'u co'a tavla .i lu ju'o baku la .dinas. ca le vanci be le cabdei cu mutce badri lonu mi na kansa to'isa'a la .dinas. cu mlatu toi .i .a'o le se lanzu ba morji tu'a loi ladru pe ne'i lo palta zi'e pe se va'u la .dinas. ca le cedra be lonu sanmi .i doi la .dinas. noi dirba mi vau do mi kansa .au lenu vi cnita .i .u'u no smacu cu zvati lei vacri .i ku'i do ka'e kavbu lo ka'u vofli ratcu noi ka'u mutce leka simsa le'e smacu .i ku'i .a'u xu cafne fa lonu lo'e mlatu cu citka lo'e vofli ratcu li'u .i caku la .alis. co'a lifri leka pu'o sipna .i je .abu di'a je fi'o se senva fe'u cusku fi lenei lu xu lo'e mlatu cu citka lo'e vofli ratcu .i xu lo'e mlatu cu citka lo'e vofli ratcu li'u .e su'o roi bo lu xu lo'e vofli ratcu cu citka lo'e mlatu li'u .i ku'i le se porsi cu na mutce vajni ki'u lonu la .alis. na ka'e spuda su'o le re preti .i la .alis. cu lifri leka zenba leka sipna .i je .abu co'a senva lonu ri kansa la .dinas. gi'e jgari lo xance be ri gi'e cusku lu ju'i la .dinas. ko mi skicu lo jetnu .i xu do su'o roi citka lo vofli ratcu li'u .i ca bo sei sance be fa lo simsa zo .tamtam. la .alis. co'i klama lo cpana be lo derxi be lo grana jo'u lo sudga pezli .i je lenu farlu cu mulno | Down, down, down. There was nothing else to do, so Alice soon began talking again. 'Dinah'll miss me very much to-night, I should think!' (Dinah was the cat.) 'I hope they'll remember her saucer of milk at tea-time. Dinah my dear! I wish you were down here with me! There are no mice in the air, I'm afraid, but you might catch a bat, and that's very like a mouse, you know. But do cats eat bats, I wonder?' And here Alice began to get rather sleepy, and went on saying to herself, in a dreamy sort of way, 'Do cats eat bats? Do cats eat bats?' and sometimes, 'Do bats eat cats?' for, you see, as she couldn't answer either question, it didn't much matter which way she put it. She felt that she was dozing off, and had just begun to dream that she was walking hand in hand with Dinah, and saying to her very earnestly, 'Now, Dinah, tell me the truth: did you ever eat a bat?' when suddenly, thump! thump! down she came upon a heap of sticks and dry leaves, and the fall was over. |
| ni'o la .alis. no va'e leka se xrani kei gi'e bazi sanli fi le jamfu gi'e semu'ibo catlu lei gapru noi ku'i mulno leka manku .ije crane la .alis. fa le pa drata ke clani vorme .i le blabi ractu za'o se viska gi'e sutra leka litru le vorme .i .ei la .alis. na denpa .i la .alis. cu klama tai tu'a lo brife gi'e ge jai cabna gi snada lo ka tirna kei vau lonu le ractu cu cusku lu .oi doi le kerlo .e le gaskre vu'o pe mi co'a mutce leka lerci li'u .i la .alis. cu jibni trixe le ractu ca lonu ri carna ru'u le kojna .i ku'i le ractu ca ba'o se viska .i la .alis. cu facki ledu'u ri zvati le pa kumfa noi clani leka pinta kei gi'e tordu leka sraji zi'e noi se gusni fi le se linji noi dandu le drudi | Alice was not a bit hurt, and she jumped up on to her feet in a moment: she looked up, but it was all dark overhead; before her was another long passage, and the White Rabbit was still in sight, hurrying down it. There was not a moment to be lost: away went Alice like the wind, and was just in time to hear it say, as it turned a corner, 'Oh my ears and whiskers, how late it's getting!' She was close behind it when she turned the corner, but the Rabbit was no longer to be seen: she found herself in a long, low hall, which was lit up by a row of lamps hanging from the roof. |
| ni'o le kumfa cu se sruri lei so'i vorme .i ku'i ro me ri cu se stela ganlo .i la .alis. ca lonu ri ba'o ku litru le pamoi be le'i mlana .e le drata mlana gi'e troci tu'a ro vorme cu badri cadzu bu'u le midju gi'e kucli ledu'u ta'i makau lenei ba za'ure'u bartu | There were doors all round the hall, but they were all locked; and when Alice had been all the way down one side and up the other, trying every door, she walked sadly down the middle, wondering how she was ever to get out again. |
| ni'o fi'o suksa la .alis. cu penmi le cmalu jubme noi se tuple ci da gi'e marji lo sligu blaci .i cpana le jubme fa ke po'o le cmacma ke solji ckiku .i pare'uku la .alis. cu jinvi ledu'u le ckiku cu ckiku pa stela be le vorme pe le kumfa .i ku'i .uinai ro da poi me le stela zo'u ga da du'e va'e leka barda gi le ckiku cu du'e va'e leka cmalu .iseju le ckiku fai no vorme ka'e jai gau kalri .i ku'i la .alis. ca lenu ri rere'u ru'u litru cu penmi le dizlo murta noi la .alis. pu nu'o sanji .i le murta cu murta le cmalu vorme noi degygutci li ji'i pa mu .i la .alis. cu troci leka co'e le cmalu ke solji ckiku le stela .ije .uisai mapti | Suddenly she came upon a little three-legged table, all made of solid glass; there was nothing on it except a tiny golden key, and Alice's first thought was that it might belong to one of the doors of the hall; but, alas! either the locks were too large, or the key was too small, but at any rate it would not open any of them. However, on the second time round, she came upon a low curtain she had not noticed before, and behind it was a little door about fifteen inches high: she tried the little golden key in the lock, and to her great delight it fitted! |
| ni'o la .alis. cu jai gau kalri fai le vorme gi'e zgana lenu ri vorme le cmalu pluta voi na zmadu lo'e kevna pe lo ratcu leka barda .i .uo la .alis. co'a sanli fi le cidni gi'e catlu fa'a le fanmo be le pluta be'o noi .ue traji leka melbi vau lo'i purdi poi pu'i su'oroi viska lu'a ke'a .i caku la .alis. cu djica lonu ri co'a bartu le manku kumfa gi'e cadzu jbini le va zdani be le carmi xrula be'o jo'u le va lenku ke jetce jinto .i ku'i je la .alis. na ka'e jai zu'e pagre fai le ji'a stedu le kevna .i lu da'i lonu le .ianai mu'anai stedu be mi ka'e pagre to'isa'a se pensi la .uu .alis. toi cu so'u va'e leka prali vau fau lonu na co'e le janco be mi .i .au mi ne tai le'e darvistci ka'e se polje .i pe'i mi da'i ka'e go'i fau lonu mi djuno ledu'u mi ta'i ma kau co'a go'i li'u .i za'a dai so'i cizra pu ze'a ca fasnu .i ja'e bo la .alis. co'a jinvi ledu'u su'e so'u fasnu naku ka'e ku cumki | Alice opened the door and found that it led into a small passage, not much larger than a rat-hole: she knelt down and looked along the passage into the loveliest garden you ever saw. How she longed to get out of that dark hall, and wander about among those beds of bright flowers and those cool fountains, but she could not even get her head through the doorway; 'and even if my head would go through,' thought poor Alice, 'it would be of very little use without my shoulders. Oh, how I wish I could shut up like a telescope! I think I could, if I only knew how to begin.' For, you see, so many out-of-the-way things had happened lately, that Alice had begun to think that very few things indeed were really impossible. |
| ni'o simlu leka na prali fi lonu denpa ne'a le cmalu vorme .iseki'ubo la .alis. di'a klama le jubme fau lonu ri so'o va'e leka pacna lonu ri zvafa'i lo drata ckiku .a lo do'anai cukta be lo javni be lo tadji be lonu polje lo'e remna ne tai lo'e darvistci .i ca le ca krefu la .alis. cu zgana le cmalu botpi noi cpana le jubme (to lu ju'o pu na zvati ti li'u se cusku la .alis. toi) .i sruri le cnebo be le botpi fa le pa pelji tcita noi le valsi voi du lu ko mi pinxe cu ckaji leka le pixra be ce'u cu melbi prina ke'a gi'e me vu'i le barda lerfu | There seemed to be no use in waiting by the little door, so she went back to the table, half hoping she might find another key on it, or at any rate a book of rules for shutting people up like telescopes: this time she found a little bottle on it, ('which certainly was not here before,' said Alice,) and round the neck of the bottle was a paper label, with the words 'DRINK ME' beautifully printed on it in large letters. |
| ni'o .o'ocu'i xamgu fa lenu cusku lu ko mi pinxe li'u .i ku'i la .alis. noi prije cu na platu fi lonu ri bazi zukte la'e ba'e di'u .i lu .ainai .i .ai pa mai mi catlu to'isa'a la .alis. cu cusku toi gi'e facki ledu'u xu kau ru se tcita zo vindu li'u .i la .alis. pu tcidu le so'o vreji be lo melbi ke cmalu lisri be le verba voi se xrani tu'a loi fagri gi'a se citka le cilce danlu gi'a lifri le drata rigni vau fa ke'a ki'u lonu ke'a na ba'e morji le sampu javni voi le pendo be ke'a cu ctuca ke'a zi'e noi mu'a du ledu'u lo'e xunre glare tunta cu fagri jai xrani lo'e za'o jgari be ri zi'e noi mu'a du ledu'u nu lo'e degji va'o lonu ri ba'e mutce leka condi leka se sraku lo'e dakfu cu ta'e vikmi loi ciblu .i la .alis. noroi co'u morji ledu'u lo'e prenu ganai pinxe lo'e du'e se botpi be lo se tcita be zo vindu gi bazi ja bazu se fanza | It was all very well to say 'Drink me,' but the wise little Alice was not going to do THAT in a hurry. 'No, I'll look first,' she said, 'and see whether it's marked "poison" or not'; for she had read several nice little histories about children who had got burnt, and eaten up by wild beasts and other unpleasant things, all because they WOULD not remember the simple rules their friends had taught them: such as, that a red-hot poker will burn you if you hold it too long; and that if you cut your finger VERY deeply with a knife, it usually bleeds; and she had never forgotten that, if you drink much from a bottle marked 'poison,' it is almost certain to disagree with you, sooner or later. |
| ni'o ku'i ti voi botpi cu na se tcita zo vindu .iseki'ubo la .alis. cu darsi leka jai zu'e ganse le se vasru .ije le go'i fau lenu ri facki ledu'u pluka (to je'u vrusi lo mixre be lo tisna be loi rutrceraso be'o jo'u lo kruji be loi sovda be'o jo'u lo grutrxananase jo'u lo se jukpa xruki jo'u lo sakta matne jo'u lo glare ke nanba poi kansa lo matne toi) cu zi mo'u pinxe | However, this bottle was NOT marked 'poison,' so Alice ventured to taste it, and finding it very nice, (it had, in fact, a sort of mixed flavour of cherry-tart, custard, pine-apple, roast turkey, toffee, and hot buttered toast,) she very soon finished it off. |
An extract.
| la .kublaXAN. | Kubla Khan |
|---|---|
| .i la .samu,el.tailor.kolridj. di'e finti .i | written by Samuel Taylor Coleridge |
| vi la .can.duv. la .kublaXAN. | In Xanadu did Kubla Khan |
| cu minde fi le melbi vi | A stately pleasure dome decree: |
| la .alf. noi censa rirxe lei | Where Alph, the sacred river, ran |
| noi so'i mei vau kevna fo | Through caverns measureless to man |
| le nicte xamsi pe vu .i | Down to a sunless sea. |
| .uo li re pi'i mu se minli | So twice five miles of fertile ground |
| lei ferti dertu joi lei noi cinla | With walls and towers were girdled round: |
| vau korcu flecu joi lei purdi | And there were gardens bright with sinuous rills, |
| joi le se panci tricu .i lei foldi | Where blossomed many an incense-bearing tree; |
| be le cmana .e le tricu voi na se gundi | And here were forests ancient as the hills, |
| cu sruri le se gusni crino co condi | Enfolding sunny spots of greenery. |
All definitions in this glossary are brief and unofficial. Only the published dictionary is a truly official reference for word definitions. These definitions are here simply as a quick reference.
- .a
-
logical connective: sumti afterthought or.
- .abu
-
letteral for a.
- .a'e
-
attitudinal: alertness - exhaustion.
- .a'o
-
attitudinal: hope - despair.
- .a'u
-
attitudinal: interest - disinterest - repulsion.
- .ai
-
attitudinal: intent - indecision - rejection/refusal.
- .ainai
-
attitudinal: intent - indecision - rejection/refusal.
- .au
-
attitudinal: desire - indifference - reluctance.
- ba
-
time tense relation/direction: will [selbri]; after [sumti]; default future tense.
mi ba bevri — I will bring it.
le'e snuti ba fasnu — Accidents will happen.
mi pu na ku kufra ba le nu ra cinba mi — I felt uncomfortable after she kissed me.
- badri
-
x1 is sad/depressed/dejected/[unhappy/feels sorrow/grief] about x2 (abstraction).
- ba'a
-
evidential: I expect - I experience - I remember.
- ba'acu'i
-
evidential: I expect - I experience - I remember.
- ba'anai
-
evidential: I expect - I experience - I remember.
- ba'e
-
forethought emphasis indicator; indicates next word is especially emphasized.
mi djuno le du'u ma kau darxi ba'e la .alis. — I know who hit Alice specifically.
vajni ba'e mi — It's important to me (!)
- ba'o
-
interval event contour: in the aftermath of ...; since ...; retrospective/perfect | |----.
- bai
-
bapli modal, 1st place (forced by) forcedly; compelled by force ...
- bajra
-
x1 runs on surface x2 using limbs x3 with gait x4.
- bakrecpa'o
-
p1=r1 is a steak/beefsteak (flat cut of beef) from cow/cattle/kine/ox p2=r2=b1.
- bakri
-
x1 is a quantity of/contains/is made of chalk from source x2 in form x3.
- baku
-
after that, in future
- balsoi
-
s1=b1 is a great soldier of army s2 great in property b2 (ka) by standard b3.
- balvi
-
x1 is in the future of/later than/after x2 in time sequence; x1 is latter; x2 is former.
- banfi
-
x1 is an amphibian of species/breed x2.
- bangu
-
x1 is a/the language/dialect used by x2 to express/communicate x3 (si'o/du'u, not quote).
xu do se bangu la .lojban. — Do you speak Lojban?
ra tavla fo le bangu be fi le mabla — He used foul language.
- banli
-
x1 is great/grand in property x2 (ka) by standard x3.
- banzu
-
x1 (object) suffices/is enough/sufficient for purpose x2 under conditions x3.
- bapu
-
time tense: will have been; (tense/modal).
- barda
-
x1 is big/large in property/dimension(s) x2 (ka) as compared with standard/norm x3.
- bartu
-
x1 is on the outside of x2; x1 is exterior to x2.
- basti
-
x1 replaces/substitutes for/instead of x2 in circumstance x3; x1 is a replacement/substitute.
- basygau
-
g1 (agent) replaces/substitutes b1 for/instead of b2 in circumstance b3.
- batci
-
x1 bites/pinches x2 on/at specific locus x3 with x4.
- bau
-
bangu modal, 1st place in language ...
- bavla'i
-
b1=l1 is next after b2=l2 in sequence l3.
- bavlamdei
-
d1=b1=l1 is tomorrow; d1=b1=l1 is the day following b2=l2, day standard d3.
- baxso
-
x1 reflects Malay-Indonesian common language/culture in aspect x2.
- bazi
-
soon ...
- baziku
-
soon
- bazu
-
in a long time ..
- be
-
sumti link to attach sumti (default x2) to a selbri; used in descriptions.
le tixnu be mi cu melbi — My daughter is pretty.
- bebna
-
x1 is foolish/silly in event/action/property [folly] (ka) x2; x1 is a boob.
- be'a
-
location tense relation/direction; north of.
- be'o
-
elidable terminator: end linked sumti in specified description.
- be'u
-
attitudinal modifier: lack/need - presence/satisfaction - satiation.
- bei
-
separates multiple linked sumti within a selbri; used in descriptions.
- bemro
-
x1 reflects North American culture/nationality/geography in aspect x2.
- bengo
-
x1 reflects Bengali/Bangladesh culture/nationality/language in aspect x2.
- bernanjudri
-
j1 is the latitude/declination of j2 in system j3.
- bersa
-
x1 is a son of mother/father/parents x2 [not necessarily biological].
- berti
-
x1 is to the north/northern side [right-hand-rule pole] of x2 according to frame of reference x3.
- bi'e
-
prefixed to a mex operator to indicate high priority.
- bi'i
-
non-logical interval connective: unordered between ... and ...
- bi'o
-
non-logical interval connective: ordered from ... to ...
- bi'u
-
discursive: newly introduced information - previously introduced information.
- bi'unai
-
discursive: newly introduced information - previously introduced information.
- bilga
-
x1 is bound/obliged to/has the duty to do/be x2 in/by standard/agreement x3; x1 must do x2.
- bilma
-
x1 is ill/sick/diseased with symptoms x2 from disease x3.
- bindo
-
x1 reflects Indonesian culture/nationality/language in aspect x2.
- birka
-
x1 is a/the arm [body-part] of x2; [metaphor: branch with strength].
- bitmu
-
x1 is a wall/fence separating x2 and x3 (unordered) of/in structure x4.
- blabi
-
x1 is white/very-light colored [color adjective].
- blaci
-
x1 is a quantity of/is made of/contains glass of composition including x2.
- blakanla
-
x1 is an eye of x2 and has a blue iris
- blanu
-
x1 is blue [color adjective].
- blari'o
-
c1 is blue-green.
- blaselkanla
-
x1 has blue eyes
- blolei
-
k1 is a ship type/class within ships b1=k2, with features k3.
- bloti
-
x1 is a boat/ship/vessel [vehicle] for carrying x2, propelled by x3.
- bo
-
short scope joiner; joins various constructs with shortest scope and right grouping.
- boi
-
elidable terminator: terminate numeral or letteral string.
- botpi
-
x1 is a bottle/jar/urn/flask/closable container for x2, made of material x3 with lid x4.
- bradi
-
x1 is an enemy/opponent/adversary/foe of x2 in struggle x3.
- brazo
-
x1 reflects Brazilian culture/nationality/language in aspect x2.
- bredi
-
x1 is ready/prepared for x2 (event).
- bridi
-
x1 (du'u) is a predicate relationship with relation x2 among arguments (sequence/set) x3.
- brife
-
x1 is a breeze/wind/gale from direction x2 with speed x3; x1 blows from x2.
- brito
-
x1 reflects British/United Kingdom culture/nationality in aspect x2.
- brivla
-
v1 is a morphologically defined predicate word signifying relation b2 in language v3.
- broda
-
1st assignable variable predicate (context determines place structure).
- brode
-
2nd assignable variable predicate (context determines place structure).
- brodi
-
3rd assignable variable predicate (context determines place structure).
- brodo
-
4th assignable variable predicate (context determines place structure).
- brodu
-
5th assignable variable predicate (context determines place structure).
- bu
-
convert any single word to BY.
- budjo
-
x1 pertains to the Buddhist culture/religion/ethos in aspect x2.
- bu'a
-
logically quantified predicate variable: some selbri 1.
- bu'e
-
logically quantified predicate variable: some selbri 2.
- bu'i
-
logically quantified predicate variable: some selbri 3.
- bu'o
-
attitudinal contour: start emotion - continue emotion - end emotion.
- bu'ocu'i
-
attitudinal contour: start emotion - continue emotion - end emotion.
- bu'onai
-
attitudinal contour: start emotion - continue emotion - end emotion.
- bu'u
-
location tense relation/direction; coincident with/at the same place as; space equivalent of ca.
- by.
-
letteral for b.
- by.by.
-
letteral for BB
- ca
-
time tense relation/direction: is [selbri]; during/simultaneous with [sumti]; present tense.
lei rirni pu zvati le barja .i ca bo lei verba cu kansa no da bu'u le zdani — The parents were in the bar; meanwhile the children were alone at home.
ko smaji ca le nu mi tavla — Be quite while I'm talking.
ca le nu do steba le nu do kansa no da zo'u ko morji le se gleki be mi'o mokca — When you feel frustrated about being lonely, remember the happy moments we had together.
mi pu prami do .i mi ca prami do .i mi ba prami do — I loved you. I love you. I will love you.
- cabdei
-
d1=c1 is today; d1=c1 is the day occuring at the same time as c2, day standard d3.
- cabna
-
x1 is current at/in the present of/during/concurrent/simultaneous with x2 in time.
- cadzu
-
x1 walks/strides/paces on surface x2 using limbs x3.
- cafne
-
x1 (event) often/frequently/commonly/customarily occurs/recurs by standard x2.
- cagyce'u
-
x1 is a farming community with members x2.
- ca'a
-
modal aspect: actuality/ongoing event.
- ca'e
-
evidential: I define.
- ca'o
-
interval event contour: during ...; continuative |-----|.
- cai
-
attitudinal: strong intensity attitude modifier.
- cakcinki
-
x1 is a beetle of species x2.
- caku
-
Now. At the present time.
- calku
-
x1 is a shell/husk [hard, protective covering] around x2 composed of x3.
- canci
-
x1 vanishes/disappears from location x2; x1 ceases to be observed at x2 using senses/sensor x3.
- canko
-
x1 is a window/portal/opening [portal] in wall/building/structure x2.
- canlu
-
x1 is space/volume/region/room [at-least-3-dimensional area] occupied by x2.
- carmi
-
x1 is intense/bright/saturated/brilliant in property (ka) x2 as received/measured by observer x3.
- carna
-
x1 turns about vector x2 towards direction x3, turning angular distance / to face point x4
- cartu
-
x1 is a chart/diagram/map of/about x2 showing formation/data-points x3.
- carvi
-
x1 rains/showers/[precipitates] to x2 from x3; x1 is precipitation [not limited to 'rain'].
- casnu
-
x1(s) (mass normally, but 1 individual/jo'u possible) discuss(es)/talk(s) about topic/subject x2.
- catlu
-
x1 looks at/examines/views/inspects/regards/watches/gazes at x2.
- ce
-
non-logical connective: set link, unordered; "and also", but forming a set.
- cedra
-
x1 is an era/epoch/age characterized by x2 (event/property/interval/idea).
- ce'a
-
2-word letteral/shift: the word following indicates a new font (e.g. italics, manuscript).
- ce'e
-
links terms into an afterthought termset.
- ce'i
-
digit/number: % percentage symbol, hundredths.
- ce'o
-
non-logical connective: ordered sequence link; "and then", forming a sequence.
- ce'u
-
pseudo-quantifier binding a variable within an abstraction that represents an open place.
la .alis. la .an. cu zmadu le ka mi nelci ce'u — I like Alice more than Ann.
- cei
-
selbri variable assignment; assigns broda series pro-bridi to a selbri.
- censa
-
x1 is holy/sacred to person/people/culture/religion/cult/group x2.
- centi
-
x1 is a hundredth [1/100; 10-2] of x2 in dimension/aspect x3 (default is units).
- cerni
-
x1 is a morning [dawn until after typical start-of-work for locale] of day x2 at location x3.
- certu
-
x1 is an expert/pro/has prowess in/is skilled at x2 (event/activity) by standard x3.
- ci
-
digit/number: 3 (digit) [three].
- ciblu
-
x1 is blood/vital fluid of organism x2.
- cidja
-
x1 is food/feed/nutriment for x2; x1 is edible/gives nutrition to x2.
- cidjrspageti
-
x1 is a quantity of spaghetti (long, thin cylindrical pasta)
- cidni
-
x1 is a/the knee/elbow/knuckle [hinged joint, body-part] of limb x2 of body x3.
- ci'ajbu
-
j1 is a writing desk of material j2, supported by legs/base/pedestal j3, used by writer c1.
- ci'e
-
ciste modal, 1st place used in scalar negation in system/context ...
- ci'u
-
ckilu modal, 1st place on the scale ...
- cikna
-
(adjective:) x1 is awake/alert/conscious.
- cilce
-
(adjective:) x1 is wild/untamed.
- cilre
-
x1 learns x2 (du'u) about subject x3 from source x4 (obj./event) by method x5 (event/process).
- cimoi
-
quantified selbri: convert 3 to ordinal selbri; x1 is third among x2 ordered by rule x3.
- cinfo
-
x1 is a lion/[lioness] of species/breed x2.
- cinki
-
x1 is an insect/arthropod of species x2; [bug/beetle].
- cinla
-
x1 is thin in direction/dimension x2 by standard x3; [relatively short in smallest dimension].
- cipni
-
x1 is a bird/avian/fowl of species x2.
- cipnrstrigi
-
x1 is an owl of species x2
- cirla
-
x1 is a quantity of/contains cheese/curd from source x2.
- ciska
-
x1 inscribes/writes x2 on display/storage medium x3 with writing implement x4; x1 is a scribe.
- ciste
-
x1 (mass) is a system interrelated by structure x2 among components x3 (set) displaying x4 (ka).
- citka
-
x1 eats/ingests/consumes (transitive verb) x2.
mi mo'u citka le pa badna .e le re plise — I've eaten a banana and two apples.
- citmau
-
z1=c1 is younger than z2 by amount z4.
- citno
-
x1 is young/youthful [relatively short in elapsed duration] by standard x2.
- cizra
-
x1 is strange/weird/deviant/bizarre/odd to x2 in property x3 (ka).
le valsi cu cizra mi le ka se smuni ma kau — The word is strange to me in meaning.
cizra fa le nu la .tom. na zvati — It's strange that Tom is not present.
- ckaji
-
x1 has/is characterized by property/feature/trait/aspect/dimension x2 (ka); x2 is manifest in x1.
- ckiku
-
x1 is a key fitting/releasing/opening/unlocking lock x2, and having relevant properties x3.
- ckule
-
x1 is school/institute/academy at x2 teaching subject(s) x3 to audien./commun. x4 operated by x5.
- cladakfu
-
x1 is a long knife
- cladakyxa'i
-
x1=d1=c1 is a sword / long knife weapon for use against x2=d2 by x3 with blade of material d3 long by standard c3.
- cladu
-
x1 is loud/noisy at observation point x2 by standard x3.
- clani
-
x1 is long in dimension/direction x2 (default longest dimension) by measurement standard x3.
- clira
-
x1 (event) is early by standard x2.
- cliva
-
x1 leaves/goes away/departs/parts/separates from x2 via route x3.
- cmaci
-
x1 is a mathematics of type/describing x2.
- cmacma
-
c1 is tiny/miniature/diminutive/very small in property c2 with criterion c3.
- cmalu
-
x1 is small in property/dimension(s) x2 (ka) as compared with standard/norm x3.
- cmana
-
x1 is a mountain/hill/mound/[rise]/[peak]/[summit]/[highlands] projecting from land mass x2.
- cmaro'i
-
c1=r1 is a small rock of type r2 from location r3, small by standard c3. c1 is gravel.
- cmavo
-
x1 is a structure word of grammatical class x2, with meaning/function x3 in usage (language) x4.
- cmene
-
x1 (quoted word(s)) is a/the name/title/tag of x2 to/used-by namer/name-user x3 (person).
ma cmene do — What is your name?
mi se cmene zo .bab. — My name is Bob.
le bruna be mi mi te cmene zo ractu — My brother calls me "Rabbit"
le kamni pu xusra le du'u le prenu pu zukte no le se cmene be lu na'e drani li'u bei le kamni — The committee asserted that the person had done nothing "incorrect" (quoting the committee's words).
- cmevla
-
x1 is a morphologically defined name word meaning x2 in language x3.
- cmima
-
x1 is a member/element of set x2; x1 belongs to group x2; x1 is amid/among/amongst group x2.
- cnebo
-
x1 is a/the neck [body-part] of x2; [metaphor: a relatively narrow point].
- cnita
-
x1 is directly/vertically beneath/below/under/underneath/down from x2 in frame of reference x3.
- co
-
tanru inversion operator; "... of type ..."; allows modifier trailing sumti without sumti links.
- co'a
-
interval event contour: at the starting point of ...; initiative >|< |.
pu co'a ru'i carvi — It started raining.
le plise co'a fusra — The apple has begun to decay.
co'a pelxu — It's turning yellow.
do pu co'a lazni — You became lazy.
- co'e
-
elliptical/unspecified bridi relationship.
mu'i ma do co'e mi — Why are you doing this to me?
za'o co'e — It's going on for too long.
.ei do troci le ka co'e bu'u lo drata — You should try it somewhere else.
- co'i
-
interval event contour: at the instantaneous point of ...; achievative/perfective; point event >|<.
- co'o
-
vocative: partings/good-bye.
co'o le tumla pe mi — Goodbye, my land!
co'o ro do — Goodbye to all of you!
- co'u
-
interval event contour: at the ending point of ... even if not done; cessative | >< |.
- coi
-
vocative: greetings/hello.
coi le munje — Hello, world!
coi ro do — Hello, everyone!
- coico'o
-
vocative: greetings in passing.
- condi
-
x1 is deep in extent in direction/property x2 away from reference point x3 by standard x4.
- cpana
-
x1 is upon/atop/resting on/lying on [the upper surface of] x2 in frame of reference/gravity x3.
- cpumi'i
-
l1=m1 is a tractor pulling l2.
- crane
-
x1 is anterior/ahead/forward/(in/on) the front of x2 which faces/in-frame-of-reference x3.
- crepu
-
x1 (agent) harvests/reaps/gathers crop/product/objects x2 from source/area x3.
- cribe
-
x1 is a bear/ursoid of species/breed x2.
- crino
-
x1 is green/verdant [color adjective].
- ctigau
-
g1 feeds c1 with food c2.
- ctuca
-
x1 teaches audience x2 ideas/methods/lore x3 (du'u) about subject(s) x4 by method x5 (event).
- cu
-
elidable marker: separates selbri from preceding sumti, allows preceding terminator elision.
lei rirni cu zvati ti ca — The parents are here now.
- cu'e
-
tense/modal question.
- cu'i
-
attitudinal: neutral scalar attitude modifier.
- cu'o
-
convert number to probability selbri; event x1 has probability (n) of occurring under cond. x2.
- cu'u
-
cusku modal, 1st place (attribution/quotation) as said by source ...; used for quotation.
- cukta
-
x1 is a book containing work x2 by author x3 for audience x4 preserved in medium x5.
- culno
-
x1 is full/completely filled with x2.
- cumki
-
x1 (event/state/property) is possible under conditions x2; x1 may/might occur; x1 is a maybe.
cumki fa le nu la .alis. ba jai lerci — It's possible that Alice will be late.
- cunso
-
x1 is random/fortuitous/unpredictable under conditions x2, with probability distribution x3.
- cupra
-
x1 produces x2 [product] by process x3.
- curmi
-
x1 (agent) lets/permits/allows x2 (event) under conditions x3; x1 grants privilege x2.
- cusku
-
x1 (agent) expresses/says x2 (sedu'u/text/lu'e concept) for audience x3 via expressive medium x4.
ba ku mi cusku fi ra fe lu do mutce le ka xendo li'u — And then I said to her: "You are very kind."
do pu cusku le se du'u do ba gasnu le katna be le nanba — You said that you would cut the bread.
- cutci
-
x1 is a shoe/boot/sandal for covering/protecting [feet/hooves] x2, and of material x3.
- cuxna
-
x1 chooses/selects x2 [choice] from set/sequence of alternatives x3 (complete set).
- cy.
-
letteral for c.
- da
-
logically quantified existential pro-sumti: there exists something 1 (usually restricted).
mi se bruna da — I have a brother.
- dadgreku
-
x1 is a rack used to hang x2.
- dadjo
-
x1 pertains to the Taoist culture/ethos/religion in aspect x2.
- dadysli
-
s1=d1 is a pendulum oscillating at rate/frequency s2, suspended from d2 by/at/with joint d3.
- da'a
-
digit/number: all except n; all but n; default 1.
- da'e
-
pro-sumti: remote future utterance; "He'll tell you tomorrow. IT will be a doozy.".
- da'i
-
discursive: supposing - in fact.
da'i mi ricfu — I could be rich.
da'i nai mi se zdani le daplu — I do live on an island.
- da'inai
-
discursive: supposing - in fact.
- da'o
-
discursive: cancel pro-sumti/pro-bridi assignments.
- da'u
-
pro-sumti: a remote past utterance; "She couldn't have known that IT would be true.".
- dai
-
attitudinal modifier: marks empathetic use of preceding attitudinal; shows another's feelings.
- dakfu
-
x1 is a knife (tool) for cutting x2, with blade of material x3.
- dalmikce
-
m1 is a doctor for animal m2=d1 of species d2 for ailment m3 using treatment m4.
- dandu
-
x1 hangs/dangles/is suspended from x2 by/at/with joint x3.
- danlu
-
x1 is an animal/creature of species x2; x1 is biologically animate.
- darsi
-
x1 shows audacity/chutzpah in behavior x2 (event/activity); x1 dares to do/be x2 (event/ka).
- darvistci
-
t1 is a telescope for seeing v2=d1 which is far from d2.
- daski
-
x1 is a pocket/pouch of/in garment/item x2.
- dasni
-
x1 wears/is robed/garbed in x2 as a garment of type x3.
- de
-
logically quantified existential pro-sumti: there exists something 2 (usually restricted).
- decti
-
x1 is a tenth [1/10; 10-1] of x2 in dimension/aspect x3 (default is units).
- degji
-
x1 is a/the finger/digit/toe [body-part] on limb/body site x2 of body x3; [metaphor: peninsula].
- degygutci
-
g1 is g2 inch/inches (length unit).
- de'a
-
event contour for a temporary halt and ensuing pause in a process.
- de'e
-
pro-sumti: a near future utterance.
- de'i
-
detri modal, 1st place (for letters) dated ... ; attaches date stamp.
- de'u
-
pro-sumti: a recent utterance.
- dei
-
pro-sumti: this utterance.
- dejni
-
x1 owes x2 in debt/obligation to creditor x3 in return for x4 [service, loan]; x1 is a debtor.
- dekto
-
x1 is ten [10; 101 ] of x2 in dimension/aspect x3 (default is units).
- delno
-
x1 is x2 candela [metric unit] in luminosity (default is 1) by standard x3.
- denci
-
x1 is a/the tooth [body-part] of x2; (adjective:) x1 is dental.
- denpa
-
x1 awaits/waits/pauses for/until x2 at state x3 before starting/continuing x4 (activity/process).
- dertu
-
x1 is a quantity of/contains/is made of dirt/soil/earth/ground from source x2 of composition x3.
- derxi
-
x1 is a heap/pile/stack/mound/hill of materials x2 at location x3.
- di
-
logically quantified existential pro-sumti: there exists something 3 (usually restricted).
- di'a
-
event contour for resumption of a paused process.
- di'e
-
pro-sumti: the next utterance.
- di'i
-
tense interval modifier: regularly; subjective tense/modal; defaults as time tense.
- di'inai
-
tense interval modifier: irregularly/aperiodically; tense/modal; defaults as time tense.
- di'u
-
pro-sumti: the last utterance.
- dinju
-
x1 is a building/edifice for purpose x2.
- dirba
-
x1 is dear/precious/darling to x2; x1 is emotionally valued by x2.
- dirce
-
x1 radiates/emits x2 under conditions x3.
- dizlo
-
x1 is low/down/downward in frame of reference x2 as compared with baseline/standard height x3.
- djedi
-
x1 is x2 full days in duration (default is 1 day) by standard x3; (adjective:) x1 is diurnal.
- djica
-
x1 desires/wants/wishes x2 (event/state) for purpose x3.
mi djica le nu mi cusku le xajmi vau le nu do cisma — I want to tell something funny to make you smile.
mi djica tu'a le plise — I want the apples.
mi djica le nu do smadi — I want you to guess.
- djine
-
x1 is a ring/annulus/torus/circle [shape/form] of material x2, inside diam. x3, outside diam. x4.
- djuno
-
x1 knows fact(s) x2 (du'u) about subject x3 by epistemology x4.
mi djuno le du'u mi zasti vau fo le du'u mi pensi — I know that I exist since I think.
- do
-
pro-sumti: you listener(s); identified by vocative.
xu do djica le nu mi sidju do — Do you want me to help you?
- do'a
-
discursive: generously - parsimoniously.
- do'anai
-
discursive: generously - parsimoniously.
- do'e
-
elliptical/unspecified modal.
- do'i
-
pro-sumti: elliptical/unspecified utterance variable.
- do'o
-
pro-sumti: you the listener & others unspecified.
- do'u
-
elidable terminator: end vocative (often elidable).
- doi
-
generic vocative marker; identifies intended listener; elidable after COI.
doi le nobli do co'u morji fi le ckiku pe do — Oh, sir! You forgot your keys.
- donma'o
-
c1 is a second person pronoun in language c4.
- donri
-
x1 is the daytime of day x2 at location x3; (adjective:) x1 is diurnal (vs. nocturnal).
- donta'a
-
x1 talks to you (i.e. whoever x1 is addressing) about x2 in language x3
- dotco
-
x1 reflects German/Germanic culture/nationality/language in aspect x2.
- drani
-
x1 is correct/proper/right/perfect in property/aspect x2 (ka) in situation x3 by standard x4.
- drata
-
x1 isn't the-same-thing-as/is different-from/other-than x2 by standard x3; x1 is something else.
- drudi
-
x1 is a roof/top/ceiling/lid of x2.
- du
-
identity selbri; = sign; x1 identically equals x2, x3, etc.; attached sumti refer to same thing.
- dubjavmau
-
x1 is greater than or equal to x2.
- dubjavme'a
-
x1 is less than or equal to x2
- du'e
-
digit/number: too many; subjective.
- du'i
-
dunli modal, 1st place (equalled by) equally; as much as ...
- du'u
-
abstractor: predication/bridi abstractor; x1 is predication [bridi] expressed in sentence x2.
mi djuno le du'u do na fuzme — I know that you are not responsible.
- dunda
-
x1 [donor] gives/donates gift/present x2 to recipient/beneficiary x3 [without payment/exchange].
- dunli
-
x1 is equal/congruent to/as much as x2 in property/dimension/quantity x3.
- dy.
-
letteral for d.
- dzipo
-
x1 reflects Antarctican culture/nationality/geography in aspect x2.
- dzukla
-
c1=k1 walks to k2 from k3 via route k4 using limbs k5=c3 on surface c2
- .e
-
logical connective: sumti afterthought and.
- .ebu
-
letteral for e.
- .e'a
-
attitudinal: granting permission - prohibiting.
- .e'e
-
attitudinal: competence - incompetence/inability.
- .e'o
-
attitudinal: request - negative request.
- .e'u
-
attitudinal: suggestion - abandon suggest - warning.
- .ei
-
attitudinal: obligation - freedom.
- fa
-
sumti place tag: tag 1st sumti place.
fe zo coi cusku fa mi — Hello, said I.
fe ma fa mi zukte .ei — What should I do?
sarcu fa le nu do zvati — It's required that you are present.
- facki
-
x1 discovers/finds out x2 (du'u) about subject/object x3; x1 finds (fi) x3 (object).
- fadni
-
x1 [member] is ordinary/common/typical/usual in property x2 (ka) among members of x3 (set).
- fagri
-
x1 is a fire/flame in fuel x2 burning-in/reacting-with oxidizer x3 (default air/oxygen).
- fagyfesti
-
x1=fe1 is the ashes of x3=fa2, combusted by fire x2=fa1.
- fa'a
-
location tense relation/direction; arriving at/directly towards ...
- fa'o
-
unconditional end of text; outside regular grammar; used for computer input.
- fa'u
-
non-logical connective: respectively; unmixed ordered distributed association.
- fai
-
sumti place tag: tag a sumti moved out of numbered place structure; used in modal conversions.
- fanmo
-
x1 is an end/finish/termination of thing/process x2; [not necessarily implying completeness].
- fanza
-
x1 (event) annoys/irritates/bothers/distracts x2.
- farlu
-
x1 falls/drops to x2 from x3 in gravity well/frame of reference x4.
- fasnu
-
x1 (event) is an event that happens/occurs/takes place; x1 is an incident/happening/occurrence.
- fau
-
fasnu modal, 1st place (non-causal) in the event of ...
- fe
-
sumti place tag: tag 2nd sumti place.
- fe'a
-
binary mathematical operator: nth root of; inverse power [a to the 1/b power].
- fe'e
-
mark space interval distributive aspects; labels interval tense modifiers as location-oriented.
- fe'o
-
vocative: over and out (end discussion).
- fe'u
-
elidable terminator: end nonce conversion of selbri to modal; usually elidable.
- femti
-
x1 is 10-15 of x2 in dimension/aspect x3 (default is units).
- ferti
-
x1 is fertile/conducive for supporting the growth/development of x2; x1 is fruitful/prolific.
- festi
-
x1(s) is/are waste product(s) [left to waste] by x2 (event/activity).
- fi
-
sumti place tag: tag 3rd sumti place.
mi dunda fe tu'a ti fi do — I give this to you.
mi co'i klama fi le tsani — I came from the sky.
- fi'a
-
sumti place tag: place structure number/tag question.
- fi'e
-
finti modal, 1st place (creator) created by ...
- fi'i
-
vocative: hospitality - inhospitality; you are welcome/ make yourself at home.
- fi'o
-
convert selbri to nonce modal/sumti tag.
- fi'u
-
digit/number: fraction slash; default "/n" => 1/n, "n/" => n/1, or "/" alone => golden ratio.
- filso
-
x1 reflects Palestinian culture/nationality in aspect x2.
- finpe
-
x1 is a fish of species x2 [metaphorical extension to sharks, non-fish aquatic vertebrates].
- finti
-
x1 invents/creates/composes/authors x2 for function/purpose x3 from existing elements/ideas x4.
mi pu finti le lisri le ka zdile le verba vau le se lifri be mi — I created a story out of my real experience to amuse the child.
- firgai
-
g1 is a mask covering the face of g2=f2.
- flalu
-
x1 is a law specifying x2 (state/event) for community x3 under conditions x4 by lawgiver(s) x5.
- flaume
-
x1 is a plum of variety x2.
- flecu
-
x1 is a current/flow/river of/in x2 flowing in direction to/towards x3 from direction/source x4.
- fo
-
sumti place tag: tag 4th sumti place.
- fo'a
-
pro-sumti: he/she/it/they #6 (specified by goi).
- fo'e
-
pro-sumti: he/she/it/they #7 (specified by goi).
- fo'i
-
pro-sumti: he/she/it/they #8 (specified by goi).
- fo'o
-
pro-sumti: he/she/it/they #9 (specified by goi).
- fo'u
-
pro-sumti: he/she/it/they #10 (specified by goi).
- foi
-
terminator: end composite lerfu; never elidable.
- foldi
-
x1 is a field [shape/form] of material x2; x1 is a broad uniform expanse of x2.
- fraso
-
x1 reflects French/Gallic culture/nationality/language in aspect x2.
- friko
-
x1 reflects African culture/nationality/geography in aspect x2.
- frinu
-
x1 is a fraction, with numerator x2, denominator x3 (x2/x3).
- fu
-
sumti place tag: tag 5th sumti place.
- fu'a
-
reverse Polish mathematical expression (mex) operator flag.
- fu'e
-
begin indicator long scope.
- fu'i
-
attitudinal modifier: easy - difficult.
- fu'ivla
-
x1=v1=f1 is a loanword meaning x2=v2 in language x3=v3, based on word x4=f2 in language x5.
- fu'o
-
end indicator long scope; terminates scope of all active indicators.
- fy.
-
letteral for f.
- ga
-
logical connective: forethought all but tanru-internal or (with gi).
- gadri
-
x1 is an article/descriptor labelling description x2 (text) in language x3 with semantics x4.
- ga'e
-
upper-case letteral shift.
- ga'i
-
attitudinal modifier/honorific: hauteur - equal rank - meekness; used with one of lower rank.
- ga'icu'i
-
attitudinal modifier/honorific: hauteur - equal rank - meekness; used with one of equal rank.
- ga'inai
-
attitudinal modifier/honorific: hauteur - equal rank - meekness; used with one of higher rank.
- ga'o
-
closed interval bracket marker; mod. intervals in non-logical connectives; include boundaries.
- ga'u
-
location tense relation/direction; upwards/up from ...
- galfi
-
x1 (event) modifies/alters/changes/transforms/converts x2 into x3.
- galtu
-
x1 is high/up/upward in frame of reference x2 as compared with baseline/standard height x3.
- ganai
-
logical connective: forethought all but tanru-internal conditional/only if (with gi).
- ganlo
-
x1 (portal/passage/entrance-way) is closed/shut/not open, preventing passage/access to x2 by x3 (something being blocked).
- ganse
-
x1 [observer] senses/detects/notices stimulus x2 (object/nu) by means x3 under conditions x4.
- gapru
-
x1 is directly/vertically above/upwards-from x2 in gravity/frame of reference x3.
- gaskre
-
k1=g3 is a/are the whisker(s)/sensory hair(s) /vibrissa(e) attached to k2=g1 at body part k3 for the detection of stimuli g2 under conditions g4.
- gasnu
-
x1 [person/agent] is an agentive cause of event x2; x1 does/brings about x2.
- gau
-
gasnu modal, 1st place agent/actor case tag with active agent ...
- ge
-
logical connective: forethought all but tanru-internal and (with gi).
- ge'a
-
mathematical operator: null mathematical expression (mex) operator (used in >2-ary ops).
- ge'e
-
attitudinal: elliptical/unspecified/non-specific emotion; no particular feeling.
- ge'i
-
logical connective: forethought all but tanru-internal connective question (with gi).
- ge'o
-
shift letterals to Greek alphabet.
- ge'u
-
elidable terminator: end GOI relative phrases; usually elidable in non-complex phrases.
- gei
-
trinary mathematical operator: order of magnitude/value/base; [b * (c to the a power)].
- gekmau
-
x1 is happier than x2 about x3 by amount x4
- gento
-
x1 reflects Argentinian culture/nationality in aspect x2.
- genxu
-
x1 is a hook/crook [shape/form] of material x2.
- gerku
-
x1 is a dog/canine/[bitch] of species/breed x2.
- gerzda
-
z1 is a doghouse for dog z2=g1.
- gi
-
logical connective: all but tanru-internal forethought connective medial marker.
ge do gi mi nelci le'e perli — Both you and I like pears.
- gidva
-
x1 (person/object/event) guides/conducts/pilots/leads x2 (active participants) in/at x3 (event).
- gigdo
-
x1 is a billion [British milliard] [109] of x2 in dimension/aspect x3 (default is units).
- gi'a
-
logical connective: bridi-tail afterthought or.
- gi'e
-
logical connective: bridi-tail afterthought and.
.ai mi lumci le kumfa gi'e jukpa le nanba — I'm going to clean the room and cook bread.
- gi'i
-
logical connective: bridi-tail afterthought conn question.
- gi'o
-
logical connective: bridi-tail afterthought biconditional/iff/if-and-only-if.
- gi'u
-
logical connective: bridi-tail afterthought whether-or-not.
- girzu
-
x1 is group/cluster/team showing common property (ka) x2 due to set x3 linked by relations x4.
- gismu
-
x1 is a (Lojban) root word expressing relation x2 among argument roles x3, with affix(es) x4.
- glare
-
x1 is hot/[warm] by standard x2.
- gleki
-
x1 is happy/merry/glad/gleeful about x2 (event/state).
mi gleki le nu do jinga — I am happy that you won.
- glico
-
x1 is English/pertains to English-speaking culture in aspect x2.
- go
-
logical connective: forethought all but tanru internal biconditional/iff/if-and-only-if(with gi).
- gocti
-
x1 is 10-24 of x2 in dimension/aspect x3 (default is units).
- go'a
-
pro-bridi: repeats a recent bridi (usually not the last 2).
- go'e
-
pro-bridi: repeats the next to last bridi.
- go'i
-
pro-bridi: preceding bridi; in answer to a yes/no question, repeats the claim, meaning yes.
.au mi penmi do .i xu le nu go'i cu cumki — I'd like to meet you. Is this possible?
- go'o
-
pro-bridi: repeats a future bridi, normally the next one.
- go'u
-
pro-bridi: repeats a remote past bridi.
- goi
-
sumti assignment; used to define/assign ko'a/fo'a series pro-sumti; Latin 'sive'.
- gotro
-
x1 is 1024 of x2 in dimension/aspect x3 (default is units).
- grana
-
x1 is a rod/pole/staff/stick/cane [shape/form] of material x2.
- grutrxananase
-
x1 is a pineapple of species/variety x2.
- gu
-
logical connective: forethought all but tanru-internal whether-or-not (with gi).
- gugde
-
x1 is the country of peoples x2 with land/territory x3; (people/territory relationship).
- gu'a
-
logical connective: tanru-internal forethought or (with gi).
- gu'e
-
logical connective: tanru-internal forethought and (with gi).
- gu'i
-
logical connective: tanru-internal forethought question (with gi).
- gu'o
-
logical connective: tanru-internal forethought biconditional/iff/if-and-only-if (with gi).
- gu'u
-
logical connective: tanru-internal forethought whether-or-not (with gi).
- gundi
-
x1 is industry/industrial/systematic manufacturing activity producing x2 by process/means x3.
- gunse
-
x1 is a goose/[gander] of species/breed x2.
- gusni
-
x1 [energy] is light/illumination illuminating x2 from light source x3.
- gy.
-
letteral for g.
- .i
-
sentence link/continuation; continuing sentences on same topic; normally elided for new speakers.
- .ia
-
attitudinal: belief - skepticism - disbelief.
- .ianai
-
attitudinal: belief - skepticism - disbelief.
- .ibabo
-
And after that ...
- .ibazabo
-
And after a while after that ...
- .ibazibo
-
And soon after that ...
- .ibu
-
letteral for i.
- .icabo
-
And at the same time ...
- .ie
-
attitudinal: agreement - disagreement.
- .ienai
-
attitudinal: agreement - disagreement.
- .iesai
-
attitudinal: "I fully agree"
- .i'a
-
attitudinal: acceptance - blame.
- .i'e
-
attitudinal: approval - non-approval - disapproval.
- .i'inai
-
attitudinal: togetherness - privacy.
- .ii
-
attitudinal: fear - security.
- .iicai
-
attitudinal: "Eek!"; utmost fear
- .ija
-
logical connective: sentence afterthought or.
- .ija'ebo
-
And as the result ...
- .ije
-
logical connective: sentence afterthought and.
- .iki'ubo
-
And it's true or happens because of the reason ...
- .ini'ibo
-
And it is logically because of ...
- .io
-
attitudinal: respect - disrespect.
- .iseju
-
whether or not that is tor happens rue it's true or happens that ...
- .iseki'ubo
-
And because of that reasonit's true or happens that ...
- .isemu'ibo
-
And that is the motive for the event ...
- .iu
-
attitudinal: love - no love lost - hatred.
- ja
-
logical connective: tanru-internal afterthought or.
- ja'a
-
bridi logical affirmer; scope is an entire bridi.
- ja'e
-
jalge modal, 1st place resultingly; therefore result ...
- ja'o
-
evidential: I conclude.
- jai
-
convert tense/modal (tagged) place to 1st place; 1st place moves to extra FA place (fai).
lei ckiku cu jai nandu fai le nu ri se zva-fa'i .i va'i le nu zva-fa'i lei ckiku cu nandu — The keys are hard to find. In other words, to find the keys is difficult.
le'e bangu cu jai nandu .i le'e bangu cu jai nandu fai le nu cilre fi ri — Languages are difficult. Languages are difficult in learning things about them.
ko cusku le jai se djica be do — Say what you want.
do ro roi cusku su'o da poi nandu fa le nu jimpe fi ke'a — You always say something hard to understand.
- jalge
-
x1 (action/event/state) is a result/outcome/conclusion of antecedent x2 (event/state/process).
- jamfu
-
x1 is a/the foot [body-part] of x2; [metaphor: lowest portion] (adjective:) x1 is pedal.
- jamna
-
x1 (person/mass) wars against x2 over territory/matter x3; x1 is at war with x2.
- janco
-
x1 is a/the shoulder/hip/joint [body-part] attaching limb/extremity x2 to body x3.
- jarco
-
x1 (agent) shows/exhibits/displays/[reveals]/demonstrates x2 (property) to audience x3.
- javni
-
x1 is a rule prescribing/mandating/requiring x2 (event/state) within system/community x3.
- jbena
-
x1 is born to x2 at time x3 [birthday] and place x4 [birthplace]; x1 is native to (fo) x4.
- jbini
-
x1 is between/among set of points/bounds/limits x2 (set)/amidst mass x2 in property x3 (ka).
- jdari
-
x1 is firm/hard/resistant/unyielding to force x2 under conditions x3.
- jdaselsku
-
c2 is a prayer of believer c1=l2 for deity c3 in medium c4 according to religion l3.
- jdice
-
x1 (person) decides/makes decision x2 (du'u) about matter x3 (event/state).
- jdika
-
x1 (experiencer) decreases/contracts/is reduced/diminished in property/quantity x2 by amount x3.
- jduli
-
x1 is a quantity of jelly/semisolid [texture] of material/composition including x2.
- je
-
logical connective: tanru-internal afterthought and.
do pu je ca je ba pendo mi — You were, are and will be my friend.
- jegvo
-
x1 pertains to the common Judeo-Christian-Moslem (Abrahamic) culture/religion/nationality in aspect x2.
- je'a
-
scalar affirmer; denies scalar negation: Indeed!.
- je'e
-
vocative: roger (ack) - negative acknowledge; used to acknowledge offers and thanks.
lu ki'e do li'u lu je'e do li'u — "Thank you!" "You are welcome!"
- je'enai
-
vocative: roger (ack) - negative acknowledge; I didn't hear you.
- je'i
-
logical connective: tanru-internal afterthought conn question.
- je'o
-
shift letterals to Hebrew alphabet.
- je'u
-
discursive: truth - falsity.
- je'unai
-
discursive: truth - falsity.
- jei
-
abstractor: truth-value abstractor; x1 is truth value of [bridi] under epistemology x2.
- jelca
-
x1 burns/[ignites/is flammable/inflammable] at temperature x2 in atmosphere x3.
- jenai
-
logical connective: tanru-internal afterthought x but not y.
- jersi
-
x1 chases/pursues/(physically) follows after x2; volition is not implied for x1 or x2.
- jerxo
-
x1 reflects Algerian culture/nationality in aspect x2.
- jetce
-
x1 is a jet [expelled stream] of material x2 expelled from x3.
- jetnu
-
x1 (du'u) is true/truth by standard/epistemology/metaphysics x2.
- jgari
-
x1 grasps/holds/clutches/seizes/grips/[hugs] x2 with x3 (part of x1) at locus x4 (part of x2).
- ji
-
logical connective: sumti afterthought connective question.
- jibni
-
x1 is near/close to/approximates x2 in property/quantity x3 (ka/ni).
- ji'a
-
discursive: additionally.
mi ji'a je'a nelci — I like it too.
lo'e xagji cribe cu citka lo'e cinki ku ji'a sai — A hungry bear will eat even insects.
ji'a mi pu citka le'e titla — Additionally, I ate the sweet.
mi pu citka le titla ji'a — I ate what is additionally a sweet.
mi pu citka le ji'a titla — I eat the sweet among other things.
- ji'asai
-
even
- ji'i
-
digit/number: approximately (default the typical value in this context) (number).
- ji'u
-
jicmu modal, 1st place (assumptions); given that ...; based on ...
- jinto
-
x1 is a well/spring of fluid x2 at location x3.
- jinvi
-
x1 thinks/opines x2 [opinion] (du'u) is true about subject/issue x3 on grounds x4.
- jitro
-
x1 has control over/harnesses/manages/directs/conducts x2 in x3 (activity/event/performance).
- jo
-
logical connective: tanru-internal afterthought biconditional/iff/if-and-only-if.
- jo'a
-
discursive: metalinguistic affirmer.
- jo'e
-
non-logical connective: union of sets.
- jo'i
-
join mathematical expression (mex) operands into an array.
- jo'o
-
shift letterals to Arabic alphabet.
- jo'u
-
non-logical connective: in common with; along with (unmixed).
- joi
-
non-logical connective: mixed conjunction; "and" meaning "mixed together", forming a mass.
- jordo
-
x1 reflects Jordanian culture/nationality in aspect x2.
- ju
-
logical connective: tanru-internal afterthought whether-or-not.
- jubme
-
x1 is a table/flat solid upper surface of material x2, supported by legs/base/pedestal x3.
- ju'a
-
evidential: I state - (default) elliptical/non-specific basis.
- ju'i
-
vocative: attention - at ease - ignore me.
- ju'o
-
attitudinal modifier: certainty - uncertainty - impossibility.
- ju'u
-
binary mathematical operator: number base; [a interpreted in the base b].
- jukpa
-
x1 cooks/prepares food-for-eating x2 by recipe/method x3 (process).
- jundi
-
x1 is attentive towards/attends/tends/pays attention to object/affair x2.
- jungo
-
x1 reflects Chinese [Mandarin, Cantonese, Wu, etc.] culture/nationality/language in aspect x2.
- junla
-
x1 is clock/watch/timer measuring time units x2 to precision x3 with timing mechanism/method x4.
- jy.
-
letteral for j.
- ka
-
abstractor: property/quality abstractor (-ness); x1 is quality/property exhibited by [bridi].
ta'i ku do ba cirko le ka sinma ce'u — This way you will lose respect.
- kabri
-
x1 is a cup/glass/tumbler/mug/vessel/[bowl] containing contents x2, and of material x3.
- kadno
-
x1 reflects Canadian culture/nationality in aspect x2.
- ka'a
-
klama modal, 1st place gone to by ...
- ka'e
-
modal aspect: innate capability; possibly unrealized.
ro da ka'e te tavla — Everything can be talked about.
- ka'o
-
digit/number: imaginary i; square root of -1.
- ka'u
-
evidential: I know by cultural means (myth or custom).
- kai
-
ckaji modal, 1st place characterizing ...
- kajna
-
x1 is a shelf/counter/bar in/on/attached to supporting object x2, for purpose x3.
- kakne
-
x1 is able to do/be/capable of doing/being x2 (event/state) under conditions x3 (event/state).
mi na kakne le nu sipna — I can't sleep.
- kalri
-
x1 (portal/passage/entrance-way) is open/ajar/not shut permitting passage/access to x2 by x3.
- kalselvi'i
-
x1=v2 is a tear/tear fluid of x2=v1.
- kambla
-
x1 is blueness
- kanji
-
x1 calculates/reckons/computes x2 [value (ni)/state] from data x3 by process x4.
- kanla
-
x1 is a/the eye [body-part] of x2; [metaphor: sensory apparatus]; (adjective:) x1 is ocular.
- kanro
-
x1 is healthy/fit/well/in good health by standard x2.
- kansa
-
x1 is with/accompanies/is a companion of x2, in state/condition/enterprise x3 (event/state).
- karce
-
x1 is a car/automobile/truck/van [a wheeled motor vehicle] for carrying x2, propelled by x3
- karcykla
-
x1 comes/goes to x2 from x3 via route x4 using car x5
- kau
-
discursive: marks word serving as focus of indirect question: "I know WHO went to the store".
mi djuno le du'u ma kau darxi ba'e la .alis. — I know who hit Alice (not someone else).
- kavbu
-
x1 captures/catches/apprehends/seizes/nabs x2 with trap/restraint x3.
- ke
-
start grouping of tanru, etc; ... type of ... ; overrides normal tanru left grouping.
- ke'a
-
pro-sumti: relativized sumti (object of relative clause).
- ke'e
-
elidable terminator: end of tanru left grouping override (usually elidable).
- ke'i
-
open interval bracket marker; modifies intervals in non-logical connectives; exclude boundaries.
- ke'o
-
vocative: please repeat.
- ke'u
-
discursive: repeating - continuing.
- ke'unai
-
discursive: repeating - continuing.
- kei
-
elidable terminator: end abstraction bridi (often elidable).
- kelci
-
x1 [agent] plays with plaything/toy x2.
- kelvo
-
x1 is x2 degree(s) Kelvin [metric unit] in temperature (default is 1) by standard x3.
- kerlo
-
x1 is a/the ear [body-part] of x2; [metaphor: sensory apparatus, information gathering].
- ketco
-
x1 reflects South American culture/nationality/geography in aspect x2.
- kevna
-
x1 is a cavity/hole/hollow/cavern in x2; x1 is concave within x2; x2 is hollow at locus x1.
- ki
-
tense/modal: set/use tense default; establishes new open scope space/time/modal reference base.
- ki'a
-
attitudinal question: confusion about something said.
- ki'o
-
digit/number: number comma; thousands.
- ki'u
-
krinu modal, 1st place (justified by) justifiably; because of reason ...
- kilto
-
x1 is a thousand [1000; 103] of x2 in dimension/aspect x3 (default is units).
- kisto
-
x1 reflects Pakistani/Pashto culture/nationality/language in aspect x2.
- klama
-
x1 comes/goes to destination x2 from origin x3 via route x4 using means/vehicle x5.
xu do klama fi la .nipon. — Are you from Japan?
le dargu cu se kruca lu'a le pu ve klama be le ractu — The road crossed what was the rabbit's track.
mi'a pu klama fu le ka se marce le bloti vau fo lu'a le lalxu fi le zdani fe le daplu — We sailed on the boat along the lake from the home to an island.
mi pu klama fi la .nipon. fu le ka se marce le vinji — I flew from Japan.
ra pu klama le nenri — He came in.
- klesi
-
x1 (mass/si'o) is a class/category/subgroup/subset within x2 with defining property x3 (ka).
- ko
-
pro-sumti: you (imperative); make it true for you, the listener.
ko kurji ko — Take care of yourself.
ko sisti — Stop it!
kukte ko — Enjoy your meal.
ko dasni le taxfu — Get dressed.
- ko'a
-
pro-sumti: he/she/it/they #1 (specified by goi).
- ko'e
-
pro-sumti: he/she/it/they #2 (specified by goi).
- ko'i
-
pro-sumti: he/she/it/they #3 (specified by goi).
- ko'o
-
pro-sumti: he/she/it/they #4 (specified by goi).
- ko'u
-
pro-sumti: he/she/it/they #5 (specified by goi).
- kojna
-
x1 is a corner/point/at-least-3-dimensional [solid] angle [shape/form] in/on x2, of material x3.
- korbi
-
x1 is an edge/margin/border/curb/boundary of x2 next-to/bordering-on x3.
- korcu
-
(adjective:) x1 is bent/crooked/not straight or direct/[twisted]/folded.
- kosta
-
x1 is a coat/jacket/sweater/cloak/[cape/shawl/pullover] [extra outer garment] of material x2.
- krasi
-
x1 (site/event) is a source/start/beginning/origin of x2 (object/event/process).
- krecau
-
x1 (body or body part) is hairless
- krefu
-
x1 (event) is the x3'rd recurrence/repetition of x2 (abstract); x2 happens again in [form] x1.
- krici
-
x1 believes [regardless of evidence/proof] belief/creed x2 (du'u) is true/assumed about subject x3.
- krinu
-
x1 (event/state) is a reason/justification/explanation for/causing/permitting x2 (event/state).
- krixa
-
x1 cries out/yells/howls sound x2; x1 is a crier.
- krorinsa
-
r1=k1 curtseys in front of r2.
- kruji
-
x1 is made of/contains/is a quantity of cream/emulsion/puree [consistency] of composition x2.
- ku
-
elidable terminator: end description, modal, or negator sumti; often elidable.
- kuarka
-
x1 is a quark with flavor x2.
- kucli
-
x1 is curious/wonders about/is interested in/[inquisitive about] x2 (object/abstract).
- ku'a
-
non-logical connective: intersection of sets.
- ku'e
-
elidable terminator: end mathematical (mex) forethought (Polish) expression; often elidable.
- ku'i
-
discursive: however/but/in contrast.
- ku'o
-
elidable terminator: end NOI relative clause; always elidable, but preferred in complex clauses.
- kuldi'u
-
d1 is a building housing school c1 teaching subject c3 to audience c4.
- kumfa
-
x1 is a room of/in structure x2 surrounded by partitions/walls/ceiling/floor x3 (mass/jo'u).
- kunti
-
x1 [container] is empty/vacant of x2 [material]; x1 is hollow.
- kurji
-
x1 takes-care-of/looks after/attends to/provides for/is caretaker for x2 (object/event/person).
- ky.
-
letteral for k.
- la
-
name descriptor: the one(s) called ... ; takes name or selbri description.
zo bruna cmene la .kevin. le pa pendo be mi — Brother is how friends call Kevin.
- ladru
-
x1 is made of/contains/is a quantity of milk from source x2; (adjective:) x1 is lactic/dairy.
- la'a
-
discursive: probability - improbability.
la'a ti traji le ka misno — Probably, this is the most popular one.
ba'a ra ba zi mo'u zukte — He ought to finish soon.
- la'asai
-
discursive: most likely
- la'e
-
the referent of (indirect pointer); uses the referent of a sumti as the desired sumti.
- la'edi'e
-
pro-sumti: the referent of the next utterance; the state to be describe: "WHAT was fun is ...".
- la'edi'u
-
pro-sumti: the referent of the last utterance; the state described: "IT was fun".
- la'i
-
name descriptor: the set of those named ... ; takes name or selbri description.
- la'o
-
delimited non-Lojban name; the resulting quote sumti is treated as a name.
- la'u
-
klani modal, 1st place (amount) quantifying ...; being a quantity of ...
- lai
-
name descriptor: the mass of individual(s) named ... ; takes name or selbri description.
- lanme
-
x1 is a sheep/[lamb/ewe/ram] of species/breed x2 of flock x3.
- lantro
-
x1 shepherds flock x2 composed of sheep x3
- lanzu
-
x1 (mass) is a family with members including x2 bonded/tied/joined according to standard x3.
- latmo
-
x1 reflects Latin/Roman/Romance culture/empire/language in aspect x2.
- lau
-
2-word letteral/shift: punctuation mark or special symbol follows.
- le
-
non-veridical descriptor: the one(s) described as ...
mi pu viska le pa fetsi .i ri melbi — I saw a female. She is pretty.
le pa sazri ca denpa — A driver waits.
- lebna
-
x1 takes/gets/gains/obtains/seizes/[removes] x2 (object/property) from x3 (possessor).
- ledu'u
-
bridi descriptor: that I describe as a proposition ...
- lego'i
-
description pro-sumti: reuses the value of the x1 of the previous bridi
- le'a
-
klesi modal, 1st place (scalar set) in/of category ...
- le'e
-
non-veridical descriptor: the stereotype of those described as ...
- le'i
-
non-veridical descriptor: the set of those described as ..., treated as a set.
- le'o
-
attitudinal modifier: aggressive - passive - defensive.
- le'u
-
end quote of questionable or out-of-context text; not elidable.
- lei
-
non-veridical descriptor: the mass of individual(s) described as ...
- leka
-
property descriptor: that I describe as ...-ness
- lenei
-
description pro-sumti: reuses the value of the x1 of the current bridi
- lenku
-
x1 is cold/cool by standard x2.
- lenu
-
specific event descriptor: contraction of {le nu} and identical in meaning.
- lerci
-
x1 (event) is late by standard x2.
- lerfu
-
x1 (la'e zo BY/word-bu) is a letter/digit/symbol in alphabet/character-set x2 representing x3.
- lervla
-
v1 is a word which stands for the letter/digit/symbol v2=l1 in language v3.
- lesi'o
-
idea descriptor: that I describe as a concept ...
- li
-
the number/evaluated expression; convert number/operand/evaluated math expression to sumti.
li vo cu sumji li re li re — 4 is the sum of 2 and 2.
- libjo
-
x1 reflects Libyan culture/nationality in aspect x2.
- lifri
-
x1 [person/passive/state] undergoes/experiences x2 (event/experience); x2 happens to x1.
- li'i
-
abstractor: experience abstractor; x1 is x2's experience of [bridi] (participant or observer).
- li'o
-
discursive: omitted text (quoted material).
- li'u
-
elidable terminator: end grammatical quotation; seldom elidable except at end of text.
- lijda
-
x1 is a religion of believers including x2 sharing common beliefs/practices/tenets including x3.
- lijgri
-
g1 is a row (group) showing common property (ka) g2 due to set g3 linked by relations g4.
- lindi
-
x1 is lightning/electrical arc/thunderbolt striking at/extending to x2 from x3.
- linji
-
x1 is a line/among lines [1-dimensional shape/form] defined by set of points x2.
- linsi
-
x1 is a length of chain/links of material x2 with link properties x3.
- lisri
-
x1 is a story/tale/yarn/narrative about plot/subject/moral x2 by storyteller x3 to audience x4.
- liste
-
x1 (physical object) is a list/catalog/register of sequence/set x2 in order x3 in medium x4.
- litki
-
x1 is liquid/fluid, of composition/material including x2, under conditions x3.
- litru
-
x1 travels/journeys/goes/moves via route x2 using means/vehicle x3; x1 is a traveller.
- lo
-
descriptor: the one, which (is / does) ... / those, which (are / do) ...
- logji
-
x1 [rules/methods] is a logic for deducing/concluding/inferring/reasoning to/about x2 (du'u).
- lo'a
-
shift letterals to Lojban (Roman) alphabet.
- lo'e
-
veridical descriptor: the typical one(s) who really is(are) ...
- lo'i
-
veridical descriptor: the set of those that really are ..., treated as a set.
- lo'o
-
elidable terminator: end math express.(mex) sumti; end mex-to-sumti conversion; usually elidable.
- lo'u
-
start questionable/out-of-context quote; text should be Lojban words, but needn't be grammatical.
- loi
-
veridical descriptor: the mass of individual(s) that is(are) ...
- .lojban.
-
Lojban.
- lojbangirz
-
Logical Language Group (LLG)
- lojbaugri
-
x1 is the Logical Language Group (LLG).
- lojbo
-
x1 reflects [Loglandic]/Lojbanic language/culture/nationality/community in aspect x2.
mi lojbo le ka se cinri la .lojban. vau .i je mi na se bangu la .lojban. — I'm a Lojbanic person in that I'm interested in Lojban; I don't speak it.
- loldi
-
x1 is a floor/bottom/ground of x2.
- lonu
-
event descriptor: contraction of {lo nu} and identical in meaning.
- lu
-
start grammatical quotation; quoted text should be grammatical on its own.
mi pu cusku lu coi le pendo li'u — I said "Hello, friends!"
- lubno
-
x1 reflects Lebanese culture/nationality in aspect x2.
- lubu
-
letteral for a quotation
- lu'a
-
the members of the set/components of the mass; converts another description type to individuals.
- lu'e
-
the symbol for (indirect discourse); uses the symbol/word(s) for a sumti as the desired sumti.
- lu'i
-
the set with members; converts another description type to a set of the members.
- lu'o
-
the mass composed of; converts another description type to a mass composed of the members.
- lu'u
-
elidable terminator: end of sumti qualifiers; usually elidable except before a sumti.
- lujvo
-
x1 (text) is a compound predicate word with meaning x2 and arguments x3 built from metaphor x4.
- ly.
-
letteral for l.
- ma
-
pro-sumti: sumti question (what/who/how/why/etc.); appropriately fill in sumti blank.
do djica ma — What do you want?
ma prenu gi'e pu zvati ti — Who was here?
ma dacti gi'e pu zvati ti — What object was here?
- mabla
-
x1 is execrable/deplorable/wretched/shitty/awful/rotten/miserable/contemptible/crappy/inferior/low-quality in property x2 by standard x3; x1 stinks/sucks in aspect x2 according to x3.
- ma'a
-
pro-sumti: me/we the speaker(s)/author(s) & you the listener(s) & others unspecified.
- ma'i
-
manri modal, 1st place (by standard 2) in reference frame ...
- ma'o
-
convert letteral string or other mathematical expression (mex) operand to mex operator.
- ma'u
-
digit/number: plus sign; positive number; default any positive.
- mai
-
utterance ordinal suffix; converts a number to an ordinal, such as an item or paragraph number.
- makau
-
indirect question as in "I know WHO she was"
- mamta
-
x1 is a mother of x2; x1 bears/mothers/acts maternally toward x2; [not necessarily biological].
- manci
-
x1 feels wonder/awe/marvels about x2.
- manku
-
x1 is dark/lacking in illumination.
- mapti
-
x1 fits/matches/suits/is compatible/appropriate/corresponds to/with x2 in property/aspect x3.
- marji
-
x1 is material/stuff/matter of type/composition including x2 in shape/form x3.
- masno
-
x1 is slow/sluggish at doing/being/bringing about x2 (event/state).
- matne
-
x1 is a quantity of/contains butter/oleo/margarine/shortening from source x2.
- mau
-
zmadu modal, 1st place (a greater) exceeded by ... ; usually a sumti modifier.
- me
-
convert sumti to selbri/tanru element; x1 is specific to [sumti] in aspect x2.
ti me le titla vanju — This is an example of sweet wine.
xu do me le ctuca — Are you one of the teachers?
- megdo
-
x1 is a million [106] of x2 in dimension/aspect x3 (default is units).
- me'a
-
mleca modal, 1st place (a lesser) undercut by ... ; usually a sumti modifier.
- me'e
-
cmene modal, 1st place (requires quote) with name ...; so-called ...
- me'i
-
digit/number: less than.
- me'o
-
the mathematical expression (unevaluated); convert unevaluated mathematical expression to sumti.
- me'u
-
elidable terminator: end sumti that was converted to selbri; usually elidable.
- mei
-
convert number to cardinality selbri; x1 is a mass formed from a set x2 of n members, one or more of which is/are x3, measured relative to the set x4.
- mekso
-
x1 [quantifier/expression] is a mathematical expression interpreted under rules/convention x2.
- melbi
-
x1 is beautiful/pleasant to x2 in aspect x3 (ka) by aesthetic standard x4.
- meljo
-
x1 reflects Malaysian/Malay culture/nationality/language in aspect x2.
- menli
-
x1 is a mind/intellect/psyche/mentality/[consciousness] of body x2.
- mensi
-
x1 is a sister of/sororal to x2 by bond/tie/standard/parent(s) x3; [not necessarily biological].
- merko
-
x1 pertains to USA/American culture/nationality/dialect in aspect x2.
- mexno
-
x1 reflects Mexican culture/nationality in aspect x2.
- mi
-
pro-sumti: me/we the speaker(s)/author(s); identified by self-vocative.
mi gleki — I'm happy.
- midju
-
x1 is in/at the middle/center/midpoint/[is a focus] of x2; (adjective:) x1 is central.
- mi'a
-
pro-sumti: me/we the speaker(s)/author(s) & others unspecified, but not you, the listener.
- mi'e
-
self vocative: self-introduction - denial of identity; identifies speaker.
- mi'i
-
non-logical interval connective: ordered components: ... center, ... range surrounding center.
- mi'o
-
pro-sumti: me/we the speaker(s)/author(s) & you the listener(s).
- mi'u
-
discursive: ditto.
- mikce
-
x1 doctors/treats/nurses/[cures]/is physician/midwife to x2 for ailment x3 by treatment/cure x4.
- mikri
-
x1 is a millionth [10-6] of x2 in dimension/aspect x3 (default is units).
- milti
-
x1 is a thousandth [1/1000; 10-3] of x2 in dimension/aspect x3 (default is units).
- milxe
-
x1 is mild/non-extreme/gentle/middling/somewhat in property x2 (ka); x1 is not very x2.
- minde
-
x1 issues commands/orders to x2 for result x3 (event/state) to happen; x3 is commanded to occur.
- minli
-
x1 is x2 (default 1) long local distance unit(s) [non-metric], x3 subunits, standard x4.
- mintu
-
x1 is the same/identical thing as x2 by standard x3; (x1 and x2 interchangeable).
- misro
-
x1 reflects Egyptian culture/nationality in aspect x2.
- mixre
-
x1 (mass) is a mixture/blend/colloid/commingling with ingredients including x2.
- mlana
-
x1 is to the side of/lateral to x2 and facing x3 from point of view/in-frame-of-reference x4.
- mlatu
-
x1 is a cat/[puss/pussy/kitten] [feline animal] of species/breed x2; (adjective:) x1 is feline.
- mleca
-
x1 is less than x2 in property/quantity x3 (ka/ni) by amount x4.
- mo
-
pro-bridi: bridi/selbri/brivla question.
do mo — How are you?
la .lojban. cu mo — What is Lojban?
- mo'a
-
digit/number: too few; subjective.
- mo'e
-
convert sumti to mex operand; sample use in story arithmetic: [3 apples] + [3 apples] = what.
- mo'i
-
mark motions in space-time.
- mo'o
-
higher-order utterance ordinal suffix; converts a number to ordinal, usually a section/chapter.
- mo'u
-
interval event contour: at the natural ending point of ...; completive | >|<.
- moi
-
convert number to ordinal selbri; x1 is (n)th member of set x2 ordered by rule x3.
- mojysu'a
-
s1 is a structure of parts s2 as a monument/memorial to m3.
- mokca
-
x1 is a point/instant/moment [0-dimensional shape/form] in/on/at time/place x2.
- molro
-
x1 is x2 mole(s) [metric unit] in substance (default is 1) by standard x3.
- morji
-
x1 remembers/recalls/recollects fact(s)/memory x2 (du'u) about subject x3.
- morko
-
x1 reflects Moroccan culture/nationality in aspect x2.
- morsi
-
x1 is dead/has ceased to be alive.
- mrostu
-
s1 is the grave/tomb of m1=s2.
- mu
-
digit/number: 5 (digit) [five].
- mu'a
-
discursive: for example - omitting - end examples.
- mu'anai
-
discursive: for example - omitting - end examples.
- mu'e
-
abstractor: achievement (event) abstractor; x1 is the event-as-a-point/achievement of [bridi].
- mu'i
-
mukti modal, 1st place because of motive ...
- mu'onai
-
vocative: over (response OK) - more to come.
- mukti
-
x1 (action/event/state) motivates/is a motive/incentive for action/event x2, per volition of x3.
- mulgri
-
g1=m1 is a complete set showing common property (ka) g2, complete by standard m3.
- mulno
-
x1 (event) is complete/done/finished; x1 (object) has become whole in property x2 by standard x3.
- murta
-
x1 is a curtain/blinds/drapes for covering/obscuring aperture x2, and made of material x3.
- muslo
-
x1 pertains to the Islamic/Moslem/Koranic [Quranic] culture/religion/nation in aspect x2.
- mutce
-
x1 is much/extreme in property x2 (ka), towards x3 extreme/direction; x1 is, in x2, very x3.
ti mutce le ka kargu — This is very expensive.
mi mutce le ka senpi — I highly doubt that.
- muvdu
-
x1 (object) moves to destination/receiver x2 [away] from origin x3 over path/route x4.
- my.
-
letteral for m.
- na
-
bridi contradictory negator; scope is an entire bridi; logically negates in some cmavo compounds.
na ku le speni be mi cu citno — It's not true that my wife is young.
- na'a
-
cancel all letteral shifts.
- na'e
-
contrary scalar negator: other than ...; not ...; a scale or set is implied.
na'e vajni mi — It's not important to me.
do ba na'e snada — You won't make it (won't succeed).
na'e bo mi pu zukte — Not I did it.
- na'i
-
discursive: metalinguistic negator.
- na'o
-
tense interval modifier: characteristically/typically; tense/modal; defaults as time tense.
- na'u
-
convert selbri to mex operator; used to create less-used operators using fu'ivla, lujvo, etc.
- na'ujbi
-
x1 is approximately equal to x2.
- nai
-
attached to cmavo to negate them; various negation-related meanings.
.ui .i .ui nai — Yay! Alas!
- naja
-
logical connective: tanru-internal afterthought conditional/only if.
- najnimre
-
x1 is an orange of variety x2.
- naku
-
(adverbial) bridi contradictory negator; "it is not true that...."; negates the bridi as well as any other adverbial or quantifier located on its right.
- nakykemcinctu
-
x1 is a male teacher of sexuality to audience x2.
- namcu
-
x1 (li) is a number/quantifier/digit/value/figure (noun); refers to the value and not the symbol.
- nanba
-
x1 is a quantity of/contains bread [leavened or unleavened] made from grains x2.
- nanla
-
x1 is a boy/lad [young male person] of age x2 immature by standard x3.
- nanmu
-
x1 is a man/men; x1 is a male humanoid person [not necessarily adult].
- nanvi
-
x1 is a billionth/thousand-millionth [10-9] of x2 in dimension/aspect x3 (default is units).
- nau
-
tense: refers to current space/time reference absolutely.
- ne
-
non-restrictive relative phrase marker: which incidentally is associated with ...
- ne'a
-
location tense relation/direction; approximating/next to ...
- ne'i
-
location tense relation/direction; within/inside of/into ...
- nei
-
pro-bridi: repeats the current bridi.
- ni
-
abstractor: quantity/amount abstractor; x1 is quantity/amount of [bridi] measured on scale x2.
- nibli
-
x1 logically necessitates/entails/implies action/event/state x2 under rules/logic system x3.
- nicte
-
x1 is a nighttime of day x2 at location x3; (adjective:) x1 is at night/nocturnal.
- ni'a
-
location tense relation/direction; downwards/down from ...
- ni'e
-
convert selbri to mex operand; used to create new non-numerical quantifiers; e.g. "herd" of oxen.
- ni'i
-
nibli modal, 1st place logically; logically because ...
- ni'o
-
discursive: paragraph break; introduce new topic.
- ni'u
-
digit/number: minus sign; negative number); default any negative.
- nimre
-
x1 is a quantity of citrus [fruit/tree, etc.] of species/strain x2.
- ninmu
-
x1 is a woman/women; x1 is a female humanoid person [not necessarily adult].
- nitcu
-
x1 needs/requires/is dependent on/[wants] necessity x2 for purpose/action/stage of process x3.
- nixli
-
x1 is a girl [young female person] of age x2 immature by standard x3.
- no
-
digit/number: 0 (digit) [zero].
- nobli
-
x1 is noble/aristocratic/elite/high-born/titled in/under culture/society/standard x2.
- noda
-
logically quantified sumti: nothing at all (unless restricted).
- no'a
-
pro-bridi: repeats the bridi in which this one is embedded.
- no'e
-
midpoint scalar negator: neutral point between je'a and to'e; "not really".
- no'i
-
discursive: paragraph break; resume previous topic.
- no'o
-
digit/number: typical/average value.
- no'u
-
non-restrictive appositive phrase marker: which incidentally is the same thing as ...
- noi
-
non-restrictive relative clause; attaches subordinate bridi with incidental information.
mi tavla do noi mi prami ke'a — I'm talking to you whom I love.
- nolraitru
-
t1=n1 is a regent/monarch of t2 by standard n2.
- noroi
-
tense interval modifier: never; objectively quantified tense; defaults as time tense.
- nu
-
abstractor: generalized event abstractor; x1 is state/process/achievement/activity of [bridi].
la .alis. cu nitcu le nu su'o da bevri le birje le nei — Alice needs to be given beer.
mi gleki le nu do klama — I am happy that you came.
le nu prami cu nu gunka — Loving is working.
- nu'a
-
convert mathematical expression (mex) operator to a selbri/tanru component.
- nu'e
-
vocative: promise - promise release - un-promise.
- nu'i
-
start forethought termset construct; marks start of place structure set with logical connection.
- nu'o
-
modal aspect: can but has not; unrealized potential.
mi pu pu'o je nu'o pencu — I almost touched it.
- nu'u
-
elidable terminator: end forethought termset; usually elidable except with following sumti.
- nuncti
-
n1 is an event at which c1 eat(s) c2.
- nunctu
-
x1 (nu) is an event in which x2 teaches x3 facts x4 (du'u) about x5 by means x6; x1 is a lesson given by x2 to x3.
- nunkla
-
n1 is a passage where goer k1 comes/goes to destination k2 from origin k3 via route k4 using means/vehicle k5.
- nupre
-
x1 (agent) promises/commits/assures/threatens x2 (event/state) to x3 [beneficiary/victim].
- nuzlo
-
x1 reflects New Zealand culture/nationality/geography/dialect in aspect x2.
- ny.
-
letteral for n.
- .o
-
logical connective: sumti afterthought biconditional/iff/if-and-only-if.
- .obu
-
letteral for o.
- .o'e
-
attitudinal: closeness - distance.
- .o'ocu'i
-
attitudinal: patience - mere tolerance - anger.
- .o'u
-
attitudinal: relaxation - composure - stress.
- .oi
-
attitudinal: complaint - pleasure.
- .oinai
-
attitudinal: complaint - pleasure.
- .onai
-
logical connective: sumti afterthought exclusive or; Latin 'aut'.
- pa
-
digit/number: 1 (digit) [one].
pa smoka cu cpana le jubme — There is exactly one sock on the table.
- pacna
-
x1 hopes/wishes for/desires x2 (event), expected likelihood x3 (0-1); x1 hopes that x2 happens.
- pacru'i
-
x1 is an evil spirit / demon
- pagbu
-
x1 is a part/component/piece/portion/segment of x2 [where x2 is a whole/mass]; x2 is partly x1.
- pagre
-
x1 passes through/penetrates barrier/medium/portal x2 to destination side x3 from origin side x4.
- pa'e
-
discursive: justice - prejudice.
- pa'enai
-
discursive: justice - prejudice.
- pa'o
-
location tense relation/direction; transfixing/passing through ...
- pai
-
digit/number: pi (approximately 3.1416...); the constant defined by the ratio of the circumference to the diameter of all circles.
- palta
-
x1 is a plate/dish/platter/saucer [flat/mildly concave food service bed] made of material x2.
- pamai
-
discursive: first utterance ordinal.
- pamoi
-
quantified selbri: convert 1 to ordinal selbri; x1 is first among x2 ordered by rule x3.
- panci
-
x1 is an odor/fragrance/scent/smell emitted by x2 and detected by observer/sensor x3.
- pare'uku
-
for the first time
- paso
-
number/quantity: 19 [nineteen].
- patyta'a
-
p1=t1 complains verbally to p3=t2 about p2=t3 in language t4
- pau
-
discursive: optional question premarker.
- paunai
-
discursive: unreal/rhetorical question follows.
- pe
-
restrictive relative phrase marker: which is associated with ...; loosest associative/possessive.
ti du le pa karce pe la .alis. — This is a car of my friend.
le pendo be mi cu jai fenki .i le pendo pe mi cu jai fenki — My friend is crazy.
ti me le karce pe mi — This is my car.
- pe'a
-
marks a construct as figurative (non-literal/metaphorical) speech/text.
- pe'e
-
marks the following connective as joining termsets.
- pe'i
-
evidential: I opine (subjective claim).
- pe'o
-
forethought flag for mathematical expression (mex) Polish (forethought) operator.
- pei
-
attitudinal: attitudinal question; how do you feel about it? with what intensity?.
.au pei mi kansa do — Do you want me to accompany you?
pei mi'o zvati le nu salci — What about going to the party?
- pelji
-
x1 is paper from source x2.
- pelnimre
-
x1 is a lemon of variety x2.
- pelxu
-
x1 is yellow/golden [color adjective].
- pendo
-
x1 is/acts as a friend of/to x2 (experiencer); x2 befriends x1.
- penmi
-
x1 meets/encounters x2 at/in location x3.
- pensi
-
x1 thinks/considers/cogitates/reasons/is pensive about/reflects upon subject/concept x2.
- petso
-
x1 is 1015 of x2 in dimension/aspect x3 (default is units).
- pezli
-
x1 is a leaf of plant x2; x1 is foliage of x2.
- pi
-
digit/number: radix (number base) point; default decimal.
- picti
-
x1 is a trillionth [10-12] of x2 in dimension/aspect x3 (default is units).
- pi'a
-
n-ary mathematical operator: operands are vectors to be treated as matrix rows.
- pi'e
-
digit/number:separates digits for base >16, not current standard, or variable (e.g. time, date).
- pi'i
-
n-ary mathematical operator: times; multiplication operator; [(((a * b) * c) * ...)].
- pi'o
-
pilno modal, 1st place used by ...
- pi'u
-
non-logical connective: cross product; Cartesian product of sets.
- pilno
-
x1 uses/employs x2 [tool, apparatus, machine, agent, acting entity, material] for purpose x3.
ra pu pilno le skami le nu facki le se nitcu — He used a computer to get the necessary information.
- pimlu
-
x1 is a/the feather/plume(s)/plumage [body-part] of animal/species x2.
- pinta
-
x1 is flat/level/horizontal in gravity/frame of reference x2.
- pinxe
-
x1 (agent) drinks/imbibes beverage/drink/liquid refreshment x2 from/out-of container/source x3.
- piro
-
number: all of.
- piso'a
-
number: almost all of.
- piso'u
-
number: a little of.
- pisu'o
-
number: at least some of.
- pixra
-
x1 is a picture/illustration representing/showing x2, made by artist x3 in medium x4.
- plipe
-
x1 (agent/object) leaps/jumps/springs/bounds to x2 from x3 reaching height x4 propelled by x5.
- pluka
-
x1 (event/state) seems pleasant to/pleases x2 under conditions x3.
- pluta
-
x1 is a route/path/way/course/track to x2 from x3 via/defined by points including x4 (set).
- po
-
restrictive relative phrase marker: which is specific to ...; normal possessive physical/legal.
- po'e
-
restrictive relative phrase marker: which belongs to ... ; inalienable possession.
- po'o
-
discursive: uniquely, only, solely: the only relevant case.
mi pu te vecnu le jisra ku po'o — I bought only some juice.
- po'u
-
restrictive appositive phrase marker: which is the same thing as.
- poi
-
restrictive relative clause; attaches subordinate bridi with identifying information to a sumti.
- polje
-
x1 (force) folds/creases x2 at locus/loci/forming crease(s)/bend(s) x3.
- polno
-
x1 reflects Polynesian/Oceanian (geographic region) culture/nationality/languages in aspect x2.
- ponjo
-
x1 reflects Japanese culture/nationality/language in aspect x2.
- ponse
-
x1 possesses/owns/has x2 under law/custom x3; x1 is owner/proprietor of x2 under x3.
- porsi
-
x1 [ordered set] is sequenced/ordered/listed by comparison/rules x2 on unordered set x3.
- porto
-
x1 reflects Portuguese culture/nationality/language in aspect x2.
- prali
-
x1 is a profit/gain/benefit/advantage to x2 accruing/resulting from activity/process x3.
- prenu
-
x1 is a person/people (noun) [not necessarily human]; x1 displays personality/a persona.
le xo prenu ca zvati ti voi kumfa — How many people are in this room now?
- preti
-
x1 (quoted text) is a question/query about subject x2 by questioner x3 to audience x4.
- prije
-
x1 is wise/sage about matter x2 (abstraction) to observer x3.
- prina
-
x1 is a print/impression/image on/in surface x2 of/made by/using tool/press/implement/object x3.
- pritu
-
x1 is to the right/right-hand side of x2 which faces/in-frame-of-reference x3.
- pu
-
time tense relation/direction: did [selbri]; before/prior to [sumti]; default past tense.
mi pu na ku viska le mlatu — I didn't see the cat.
mi pu prami le pa nanmu — I loved one man.
mi ba tavla do pu le nu do cliva — I will talk to you before you leave.
- puba
-
time tense: was going to; (tense/modal).
- pu'i
-
modal aspect: can and has; demonstrated potential.
- pu'o
-
interval event contour: in anticipation of ...; until ... ; inchoative ----| |.
- pu'u
-
abstractor: process (event) abstractor; x1 is process of [bridi] proceeding in stages x2.
- pulji
-
x1 is a police officer/[enforcer/vigilante] enforcing law(s)/rule(s)/order x2.
- punji
-
x1 (agent) puts/places/sets x2 on/at surface/locus x3.
- purci
-
x1 is in the past of/earlier than/before x2 in time sequence; x1 is former; x2 is latter.
- purdi
-
x1 is a garden/tended/cultivated field of family/community/farmer x2 growing plants/crop x3.
- py.
-
letteral for p.
- ra
-
pro-sumti: a recent sumti before the last one, as determined by back-counting rules.
- ractu
-
x1 is a rabbit/hare/[doe] of species/breed x2.
- radno
-
x1 is x2 radian(s) [metric unit] in angular measure (default is 1) by standard x3.
- rafsi
-
x1 is an affix/suffix/prefix/combining-form for word/concept x2, form/properties x3, language x4.
- ra'a
-
srana modal, 1st place pertained to by ... (generally more specific).
- ra'e
-
digit/number: repeating digits (of a decimal) follow.
- ra'i
-
krasi modal, 1st place from source/origin/starting point ...
- ra'o
-
flag GOhA to indicate pro-assignment context updating for all pro-assigns in referenced bridi.
- ra'u
-
discursive: chiefly - equally - incidentally.
- ra'ucu'i
-
discursive: chiefly - equally - incidentally.
- ra'unai
-
discursive: chiefly - equally - incidentally.
- rai
-
traji modal, 1st place with superlative ...
- rakso
-
x1 reflects Iraqi culture/nationality in aspect x2.
- raktu
-
x1 (object/person/event/situation) troubles/disturbs x2 (person) causing problem(s) x3.
- ralju
-
x1 is principal/chief/leader/main/[staple], most significant among x2 (set) in property x3 (ka).
- ranji
-
x1 (event/state) continues/persists over interval x2; x1 (property - ka) is continuous over x2.
- rarna
-
x1 is natural/spontaneous/instinctive, not [consciously] caused by person(s).
- ratcu
-
x1 is a rat of species/breed x2.
- rau
-
digit/number: enough; subjective.
- re
-
digit/number: 2 (digit) [two].
re cribe ca cpana le bisli — There are two bears on the ice.
- re'i
-
vocative: ready to receive - not ready to receive.
- re'inai
-
vocative: ready to receive - not ready to receive.
- re'o
-
location tense relation/direction; adjacent to/touching/contacting ...
- re'u
-
converts number to an objectively quantified ordinal tense interval modifier; defaults to time.
- remai
-
discursive: second utterance ordinal.
- remei
-
quantified selbri: convert 2 to cardinal selbri; x1 is a set with the pair of members x2.
- remna
-
x1 is a human/human being/man (non-specific gender-free sense); (adjective:) x1 is human.
- rere'u
-
for the second time ...
- reroi
-
tense interval modifier: twice; objectively quantified tense; defaults as time tense.
- retsku
-
c1=p3 asks/puts question c2=p1 (sedu'u/text/lu'e concept) of/to c3=p4 via expressive medium c4 about subject p2.
- ri
-
pro-sumti: the last sumti, as determined by back-counting rules.
- ricfu
-
x1 is rich/wealthy in goods/possessions/property/aspect x2.
- rigni
-
x1 is repugnant to/causes disgust to x2 under conditions x3.
- ri'a
-
rinka modal, 1st place (phys./mental) causal because ...
- ri'e
-
attitudinal modifier: release of emotion - emotion restraint.
- rinka
-
x1 (event/state) effects/physically causes effect x2 (event/state) under conditions x3.
- rirxe
-
x1 is a river of land mass x2, draining watershed x3 into x4/terminating at x4.
- risna
-
x1 is a/the heart [body-part] of x2; [emotional/shape metaphors are NOT culturally neutral].
- ro
-
digit/number: each, all.
ro mlatu cu danlu — Cats are animals.
le ro pendo be mi cu cusku le se du'u mi simlu le ka tatpi — All of my friends say that I look tired.
- ro'a
-
emotion category/modifier: social - antisocial.
- ro'anai
-
emotion category/modifier: social - antisocial.
- ro'e
-
emotion category/modifier: mental - mindless.
- ro'o
-
emotion category/modifier: physical - denying physical.
- ro'u
-
emotion category/modifier: sexual - sexual abstinence.
- roi
-
converts number to an objectively quantified tense interval modifier; defaults to time tense.
- romai
-
discursive utterance ordinal: finally; last utterance ordinal.
- ropno
-
x1 reflects European culture/nationality/geography/Indo-European languages in aspect x2.
- ru
-
pro-sumti: a remote past sumti, before all other in-use backcounting sumti.
- ruble
-
x1 is weak/feeble/frail in property/quality/aspect x2 (ka) by standard x3.
- ru'a
-
evidential: I postulate.
- ru'e
-
attitudinal: weak intensity attitude modifier.
.ui ru'e do snada — Yay, you won.
- ru'i
-
tense interval modifier: continuously; subjective tense/modal; defaults as time tense.
- ru'inai
-
tense interval modifier: occasional/intermittent/discontinuous; defaults as time tense.
- ru'o
-
shift letterals to Cyrillic alphabet.
- ru'u
-
location tense relation/direction; surrounding/annular ...
- rusko
-
x1 reflects Russian culture/nationality/language in aspect x2.
- rutrceraso
-
x1 is a cherry of species x2.
- ry.
-
letteral for r.
- sa
-
erase complete or partial utterance; next word shows how much erasing to do.
- sadjo
-
x1 reflects Saudi Arabian culture/nationality in aspect x2.
- sa'a
-
discursive: material inserted by editor/narrator (bracketed text).
- sa'enai
-
discursive: precisely speaking - loosely speaking.
- sa'i
-
n-ary mathematical operator: operands are vectors to be treated as matrix columns.
- sa'unai
-
discursive: simply - elaborating.
- sai
-
attitudinal: moderate intensity attitude modifier.
.ui sai do snada — Yay, you won!
- sakli
-
x1 slides/slips/glides on x2.
- sakta
-
x1 is made of/contains/is a quantity of sugar [sweet edible] from source x2 of composition x3.
- salci
-
x1 celebrates/recognizes/honors x2 (event/abstract) with activity/[party] x3.
- salpo
-
x1 is sloped/inclined/slanted/aslant with angle x2 to horizon/frame x3.
- sampu
-
x1 is simple/unmixed/uncomplicated in property x2 (ka).
- sance
-
x1 is sound produced/emitted by x2.
- sanga
-
x1 sings/chants x2 [song/hymn/melody/melodic sounds] to audience x3.
- sanji
-
x1 is conscious/aware of x2 (object/abstract); x1 discerns/recognizes x2 (object/abstract).
- sanli
-
x1 stands [is vertically oriented] on surface x2 supported by limbs/support/pedestal x3.
- sanmi
-
x1 (mass) is a meal composed of dishes including x2.
- saske
-
x1 (mass of facts) is science of/about subject matter x2 based on methodology x3.
- savru
-
x1 is a noise/din/clamor [sensory input without useful information] to x2 via sensory channel x3.
- se
-
2nd conversion; switch 1st/2nd places.
mi se slabu le ctuca .i va'i le ctuca cu slabu mi — I am familiar with the teacher. In other words, the teacher is familiar to me.
- seba'i
-
basti modal, 2nd place instead of ...
- sedu'u
-
compound abstractor: sentence/equation abstract; x1 is text expressing [bridi] which is x2.
- se'a
-
attitudinal modifier: self-sufficiency - dependency.
- se'e
-
following digits code a character (in ASCII, Unicode, etc.).
- se'i
-
attitudinal modifier: self-oriented - other-oriented.
- se'o
-
evidential: I know by internal experience (dream, vision, or personal revelation).
- se'u
-
elidable terminator: end discursive bridi or mathematical precedence;usually elidable.
- sei
-
start discursive (metalinguistic) bridi.
sei mi morji do ctuca — As I remember, you are a teacher.
sei mi bebna le zarci cu se stuzi le drata — Silly me, the store is in another place.
- seja'e
-
jalge modal, 2nd place (event causal) results because of ...
- seja'eku
-
therefore, resultingly
- seka'a
-
klama modal, 2nd place with destination ...
- sela'u
-
klani modal, 2nd place in quantity ...; measured as ...
- selbri
-
x2=b1 (du'u) is a predicate relationship with relation x1=b2 among arguments x3=b3 (ordered set).
- selkla
-
To destination x1 does x2 go from x3 via route x4 by means x5.
- selma'o
-
x1 is the class of structure word x2, which means or has function x3 in language x4.
- selsku
-
c2 is said by c1 to audience c3 via expressive medium c4.
- seltau
-
x1 is the modifying part of binary metaphor x2 with modified part/modificand x3 giving meaning x4 in usage/instance x5
- selti'i
-
x1 is a suggestion made by x2 to audience x3
- selti'ifla
-
f1=s2 is a bill specifying f2 (state/event) for community f3 under conditions f4, proposed/drafted by s1.
- semau
-
zmadu modal, 2nd place (relative!) more than ...; usually a sumti modifier.
- seme'a
-
mleca modal, 2nd place (relative!) less than ...; usually a sumti modifier.
- semto
-
x1 reflects Semitic [metaphor: Middle-Eastern] language/culture/nationality in aspect x2.
- semu'ibo
-
that is the motive for the event ...
- senva
-
x1 dreams about/that x2 (fact/idea/event/state); x2 is a dream/reverie of x1.
- sepi'o
-
pilno modal, 2nd place (instrumental) tool/machine/apparatus/acting entity; using (tool) ...
- seri'a
-
rinka modal, 2nd place (phys./mental) causal therefore ...
- serti
-
x1 are stairs/stairway/steps for climbing structure x2 with steps x3.
- sfofa
-
x1 is a sofa/couch (noun).
- si
-
erase the last Lojban word, treating non-Lojban text as a single word.
.au mi citka le pa plise si perli — I'd like to eat an apple, no, pear!
- siclu
-
x1 [sound source] whistles/makes whistling sound/note/tone/melody x2.
- sidju
-
x1 helps/assists/aids object/person x2 do/achieve/maintain event/activity x3.
- si'a
-
discursive: similarly.
- si'e
-
convert number to portion selbri; x1 is an (n)th portion of mass/totality x2; (cf. gunma).
- si'o
-
abstractor: idea/concept abstractor; x1 is x2's concept of [bridi].
- simlu
-
x1 seems/appears to have property(ies) x2 to observer x3 under conditions x4.
- simsa
-
x1 is similar/parallel to x2 in property/quantity x3 (ka/ni); x1 looks/appears like x2.
le skapi be ra pu simsa le snime le ka blabi — Her skin was white as snow.
mi simsa le'e cipni le ka zifre — I am free as a bird.
- simxu
-
x1 (set) has members who mutually/reciprocally x2 (event [x1 should be reflexive in 1+ sumti]).
- since
-
x1 is a snake/serpent of species/breed x2.
- sinso
-
x1 is the trigonometric sine of angle/arcsine x2.
- sinxa
-
x1 is a sign/symbol/signal representing/referring/signifying/meaning x2 to observer x3.
- sipna
-
x1 is asleep (adjective); x1 sleeps/is sleeping.
- sirji
-
x1 is straight/direct/line segment/interval between x2 and x3; (adjective:) x1 is linear.
- sirxo
-
x1 reflects Syrian culture/nationality in aspect x2.
- sisti
-
x1 [agent] ceases/stops/halts/ends activity/process/state x2 [not necessarily completing it].
- skari
-
x1 is/appears to be of color/hue x2 as perceived/seen by x3 under conditions x4.
- skicu
-
x1 tells about/describes x2 (object/event/state) to audience x3 with description x4 (property).
- skoto
-
x1 reflects Gaelic/Scottish culture/nationality/language in aspect x2.
- slabu
-
x1 is old/familiar/well-known to observer x2 in feature x3 (ka) by standard x4.
- slaka
-
x1 is a syllable in language x2.
- sligu
-
x1 is solid, of composition/material including x2, under conditions x3.
- slovo
-
x1 reflects Slavic language/culture/ethos in aspect x2.
- smacu
-
x1 is a mouse of species/breed x2.
- smudukti
-
d1 and d2=s2 are antonyms of each other.
- smuni
-
x1 is a meaning/interpretation of x2 recognized/seen/accepted by x3.
- snada
-
x1 [agent] succeeds in/achieves/completes/accomplishes x2 as a result of effort/attempt/try x3.
- softo
-
x1 reflects Russian empire/USSR/ex-USSR (Soviet]/CIS culture/nationality in aspect x2.
- so'a
-
digit/number: almost all (digit/number).
- so'e
-
digit/number: most.
- so'i
-
digit/number: many.
- so'imei
-
quantified selbri: convert many to cardinal; x1 is a set with many members x2 of total set x3.
- so'o
-
digit/number: several.
- so'u
-
digit/number: few.
- soi
-
discursive: reciprocal sumti marker; indicates a reciprocal relationship between sumti.
- solji
-
x1 is a quantity of/contains/is made of gold (Au); [metaphor: valuable, heavy, non-reactive].
- solri
-
x1 is the sun of home planet x2 (default Earth) of race x3; (adjective:) x1 is solar.
- solxrula
-
x1 is a sunflower of species/variety x2.
- sonci
-
x1 is a soldier/warrior/fighter of army x2.
- sovda
-
x1 is an egg/ovum/sperm/pollen/gamete of/from organism [mother/father] x2.
- spageti
-
x1 - is spaghetti made out of/containing x2.
- spaji
-
x1 (event/action abstract) surprises/startles/is unexpected [and generally sudden] to x2.
- spano
-
x1 reflects Spanish-speaking culture/nationality/language in aspect x2.
- spati
-
x1 is a plant/herb/greenery of species/strain/cultivar x2.
- spuda
-
x1 answers/replies to/responds to person/object/event/situation/stimulus x2 with response x3.
- spusku
-
x1 gives reply/answer/responds with x2 (sedu'u/text/lu'e concept) to x3 via expressive medium x4, about subject x5.
- sraji
-
x1 is vertical/upright/erect/plumb/oriented straight up and down in reference frame/gravity x2.
- sraku
-
x1 [abrasive/cutting/scratching object/implement] scratches/[carves]/erodes/cuts [into] x2.
- sralo
-
x1 reflects Australian culture/nationality/geography/dialect in aspect x2.
- srana
-
x1 pertains to/is germane/relevant to/concerns/is related/associated with/is about x2.
do .e'o ciska le srana be le se lifri be do — Please write about your experience.
xu le nu do litru cu srana le jibri be do — Is your journey related to your job?
- srito
-
x1 reflects Sanskrit language/Sanskritic/Vedic culture/nationality in aspect x2.
- sruri
-
x1 encircles/encloses/is surrounding x2 in direction(s)/dimension(s)/plane x3.
- stali
-
x1 remains/stays at/abides/lasts with x2.
- steci
-
x1 (ka) is specific/particular/specialized/[special]/a defining property of x2 among x3 (set).
- stedu
-
x1 is a/the head [body-part] of x2; [metaphor: uppermost portion].
- stela
-
x1 is a lock/seal of/on/for sealing x2 with/by locking mechanism x3.
- stero
-
x1 is x2 steradian(s) [metric unit] in solid angle (default is 1) by standard x3.
- stidi
-
x1 (agent) suggests/proposes idea/action x2 to audience x3; x1 (event) inspires x2 in/among x3.
- stura
-
x1 is a structure/arrangement/organization of x2 [set/system/complexity].
- stuzi
-
x1 is an inherent/inalienable site/place/position/situation/spot/location of x2 (object/event).
- su
-
erase to start of discourse or text; drop subject or start over.
- sudga
-
x1 is dry of liquid x2; (adjective:) x1 is arid.
- sudysrasu
-
x1 is hay of species x2
- su'a
-
evidential: I generalize - I particularize; discursive: abstractly - concretely.
- su'anai
-
evidential: I generalize - I particularize; discursive: abstractly - concretely.
- su'e
-
digit/number: at most (all); no more than.
- su'i
-
n-ary mathematical operator: plus; addition operator; [(((a + b) + c) + ...)].
- su'o
-
digit/number: at least (some); no less than.
su'o ci prenu pu cliva le dinju — At least three people left the building.
- su'oroi
-
at least once ...
- su'u
-
abstractor: generalized abstractor (how); x1 is [bridi] as a non-specific abstraction of type x2.
- suksa
-
x1 (event/state) is sudden/sharply changes at stage/point x2 in process/property/function x3.
- sumti
-
x1 is a/the argument of predicate/function x2 filling place x3 (kind/number).
- sunsicyjudri
-
j1 is the longitude/right ascension of j2 in system j3
- sutra
-
x1 is fast/swift/quick/hastes/rapid at doing/being/bringing about x2 (event/state).
- sy.
-
letteral for s.
- ta
-
pro-sumti: that there; nearby demonstrative it; indicated thing/place near listener.
- tadji
-
x1 [process] is a method/technique/approach/means for doing x2 (event) under conditions x3.
- tagji
-
x1 is snug/tight on x2 in dimension/direction x3 at locus x4.
- ta'e
-
tense interval modifier: habitually; subjective tense/modal; defaults as time tense.
- ta'eku
-
habitually
- ta'i
-
tadji modal, 1st place (in manner 3) methodically; by method ...
- ta'o
-
discursive: by the way - returning to main point.
- ta'onai
-
discursive: by the way - returning to main point.
- ta'u
-
discursive: expanding the tanru - making a tanru.
- ta'unai
-
discursive: making a tanru - expanding the tanru.
- tai
-
tamsmi modal, 1st place (like)/(in manner 2) resembling ...; sharing ideal form ...
- tamdu'i
-
d1 is/are geometrically similar/has the same shape as d2.
- tamsmi
-
x1 has form x2, similar in form to x3 in property/quality x4.
- tanjo
-
x1 is the trigonometric tangent of angle/arctangent x2.
- tanru
-
x1 is a binary metaphor formed with x2 modifying x3, giving meaning x4 in usage/instance x5.
- tarmi
-
x1 [ideal] is the conceptual shape/form of object/abstraction/manifestation x2 (object/abstract).
- tatpi
-
x1 is tired/fatigued by effort/situation x2 (event); x1 needs/wants rest.
- tau
-
2-word letteral/shift: change case for next letteral only.
- tavla
-
x1 talks/speaks to x2 about subject x3 in language x4.
ko smaji ca le nu mi tavla la .alis. fo la .lojban. fi le nu prami — Keep silence when I'm talking to Alice in Lojban about love.
- tcadu
-
x1 is a town/city of metropolitan area x2, in political unit x3, serving hinterland/region x4.
- tcidu
-
x1 [agent] reads x2 [text] from surface/document/reading material x3; x1 is a reader.
mi mo'u tcidu le se ciska le bitmu — I have read what is written on the wall.
- tcika
-
x1 [hours, minutes, seconds] is the time/hour of state/event x2 on day x3 at location x4.
- tcita
-
x1 is a label/tag of x2 showing information x3.
- te
-
3rd conversion; switch 1st/3rd places.
mi pu te vecnu le karce le pendo be mi .i va'i le pendo be mi pu vecnu le karce mi — I bought a car from my friend. In other words, my friend sold a car to me.
- teci'e
-
ciste modal, 3rd place of system components ...
- te'a
-
binary mathematical operator: to the power; exponential; [a to the b power].
- te'o
-
digit/number: exponential e (approx 2.71828...).
- te'u
-
elidable terminator: end conversion between non-mex and mex; usually elidable.
- tei
-
composite letteral follows; used for multi-character letterals.
- teka'a
-
klama modal, 3rd place with origin ...
- terbi'a
-
x3=b1 is ill/sick/diseased with symptoms x2=b2 from disease x1=b3.
- terdi
-
x1 is the Earth/the home planet of race x2; (adjective:) x1 is terrestrial/earthbound.
- tergu'i
-
x1 is a light source which illuminates x2 with light x3.
- terkavbu
-
x1 is a trap/restraint with x2 being captured/restrained by x3 (object/event).
- terpa
-
x1 fears x2; x1 is afraid/scared/frightened by/fearful of x2 (event/tu'a object).
- tertau
-
x1 is the modified part/modificand of binary metaphor x2 with modifying part x3, giving meaning x4 in usage/instance x5
- terto
-
x1 is a trillion [1012] of x2 in dimension/aspect x3 (default is units).
- tezu'e
-
zukte modal, 3rd place purposefully; (as an action) with goal ...
- ti
-
pro-sumti: this here; immediate demonstrative it; indicated thing/place near speaker.
- ti'e
-
evidential: I hear (hearsay).
- ti'o
-
mathematical expression (mex) operator precedence (discursive).
- ti'otci
-
t1=c2 is a shade/blind for blocking light coming from/through c3
- tinju'i
-
t1=j1 listens to/pays attention to sound t2=j2 with ambient background t3.
- tirna
-
x1 hears x2 against background/noise x3; x2 is audible; (adjective:) x1 is aural.
- tirxu
-
x1 is a tiger/leopard/jaguar/[tigress] of species/breed x2 with coat markings x3.
- tisna
-
x1 (object) fills/becomes stuffed [up]/inflates/blows up with material x2; x2 pours into x1.
- to
-
left parenthesis; start of parenthetical note which must be grammatical Lojban text.
lei verba to lei rirni pu zvati le zarci toi pu klama le bartu — The children (the parents were at the store) went outside.
- to'a
-
lower-case letteral shift.
- to'e
-
polar opposite scalar negator.
- to'i
-
open editorial unquote (within a quote); contains grammatical text; mark with editorial insert.
- to'isa'a
-
remarks within {to'isa'a} ... {toi} inside quotations are implicitly by someone else (other than the speaker of the quotation), perhaps an editor
- to'o
-
location tense relation/direction; departing from/directly away from ...
- to'u
-
discursive: in brief - in detail.
- toi
-
elidable terminator: right parenthesis/end unquote; seldom elidable except at end of text.
- tolcanci
-
c1 materializes/suddenly appears at location c2 according to senses/sensor c3.
- tolmle
-
x1 is ugly to x2 in aspect x3 (ka) by aesthetic standard x4.
- tolpu'i
-
p1 picks-up, picks up p2 from surface p3
- tolvri
-
x1 is a coward in activity x2 (event) by standard x3.
- tordu
-
x1 is short in dimension/direction x2 (default longest dimension) by measurement standard x3.
- traji
-
x1 is superlative in property x2 (ka), the x3 extreme (ka; default ka zmadu) among set/range x4.
- tricu
-
x1 is a tree of species/cultivar x2.
- trixe
-
x1 is posterior/behind/back/in the rear of x2 which faces/in-frame-of-reference x3.
- troci
-
x1 tries/attempts/makes an effort to do/attain x2 (event/state/property) by actions/method x3.
mi ba troci le ka cpare le tricu — I will try to climb the tree.
- tsali
-
x1 is strong/powerful/[tough] in property/quality x2 (ka) by standard x3.
- tu
-
pro-sumti: that yonder; distant demonstrative it; indicated thing far from speaker&listener.
- tubnu
-
x1 is a length of tubing/pipe/hollow cylinder [shape/form] of material x2, hollow of material x3.
- tugni
-
x1 [person] agrees with person(s)/position/side x2 that x3 (du'u) is true about matter x4.
- tu'a
-
extracts a concrete sumti from an unspecified abstraction; equivalent to le nu/su'u [sumti] co'e.
mi djica tu'a le pa plise — I want an apple. I want something to happen with an apple (maybe, I want to eat it).
- tu'e
-
start of multiple utterance scope; used for logical/non-logical/ordinal joining of sentences.
- tu'o
-
null operand (used in unary mekso operations).
- tu'u
-
elidable terminator: end multiple utterance scope; seldom elidable.
- tumla
-
x1 is a parcel/expanse of land at location x2; x1 is terrain.
- tunta
-
x1 (object, usually pointed) pokes/jabs/stabs/prods x2 (experiencer).
- tuple
-
x1 is a/the leg [body-part] of x2; [metaphor: supporting branch].
- ty.
-
letteral for t.
- .u
-
logical connective: sumti afterthought whether-or-not.
- .ua
-
attitudinal: discovery - confusion/searching.
- .uanai
-
attitudinal: discovery - confusion/searching.
- .ubu
-
letteral for u.
- .ue
-
attitudinal: surprise - not really surprised - expectation.
- .uesai
-
attitudinal: "Wow! Wow!"; strong surprise
- .u'a
-
attitudinal: gain - loss.
- .u'e
-
attitudinal: wonder - commonplace.
- .u'o
-
attitudinal: courage - timidity - cowardice.
- .u'u
-
attitudinal: repentance - lack of regret - innocence.
- .u'unai
-
attitudinal: repentance - lack of regret - innocence.
- .ui
-
attitudinal: happiness - unhappiness.
- .uinai
-
attitudinal: happiness - unhappiness.
- .uisai
-
attitudinal: "Yay!"; strong happiness
- .uisaidai
-
attitudinal: empathetic description of someone else's strong happiness
- .uo
-
attitudinal: completion - incompleteness.
- .uu
-
attitudinal: pity - cruelty.
- va
-
location tense distance: near to ... ; there at ...; a medium/small distance from ...
- vacri
-
x1 is a quantity of air/normally-gaseous atmosphere of planet x2, of composition including x3.
- va'a
-
unary mathematical operator: additive inverse; [- a].
- va'e
-
convert number to scalar selbri; x1 is at (n)th position on scale x2.
mi pu so'u va'e le ka pencu — I barely touched it.
- va'i
-
discursive: in other words - in the same words.
- va'inai
-
discursive: in other words - in the same words.
- va'o
-
vanbi modal, 1st place (conditions 1) under conditions ...; in environment ...
- va'u
-
xamgu modal, 1st place beneficiary case tag complement benefiting from ...
- vajni
-
x1 (object/event) is important/significant to x2 (person/event) in aspect/for reason x3 (nu/ka).
- valsi
-
x1 is a word meaning/causing x2 in language x3; (adjective: x1 is lexical/verbal).
- vanci
-
x1 is an evening [from end-of-work until sleep typical for locale] of day x2 at location x3.
- vasru
-
x1 contains/holds/encloses/includes contents x2 within; x1 is a vessel containing x2.
- vau
-
elidable: end of sumti in simple bridi; in compound bridi, separates common trailing sumti.
mi jinga vau .ui — I won, yay!
- ve
-
4th conversion; switch 1st/4th places.
- vecnu
-
x1 [seller] sells/vends x2 [goods/service/commodity] to buyer x3 for amount/cost/expense x4.
- ve'a
-
location tense interval: a small/medium region of space.
- ve'e
-
location tense interval: the whole of space.
- ve'o
-
right mathematical bracket.
- vei
-
left mathematical bracket.
- veka'a
-
klama modal, 4th place via route ...
- veljvo
-
x1 is a metaphor [of affix compound] with meaning [of affix compound] x2 with argument [of affix compound] x3 with affix compound x4; x1 is the tanru/metaphor construct of complex word/affix compound/lujvo x4
- vemau
-
zmadu modal, 4th place (relative!) more than/exceeding by amount ...
- veme'a
-
mleca modal, 4th place (relative!) less than by amount ...
- vensa
-
x1 is spring/springtime [warming season] of year x2 at location x3; (adjective:) x1 is vernal.
- verba
-
x1 is a child/kid/juvenile [a young person] of age x2, immature by standard x3.
- vi
-
location tense distance: here at ... ; at or a very short/tiny distance from ...
- vi'a
-
dimensionality of space interval tense: 2-space interval; throughout an area.
- vi'e
-
dimensionality of space interval tense: 4-space interval; throughout a spacetime.
- vi'i
-
dimensionality of space interval tense: 1-space interval; along a line.
- vi'u
-
dimensionality of space interval tense: 3-space interval; throughout a space.
- vikmi
-
x1 [body] excretes waste x2 from source x3 via means/route x4.
- vindu
-
x1 is poisonous/venomous/toxic/a toxin to x2.
- vinji
-
x1 is an airplane/aircraft [flying vehicle] for carrying passengers/cargo x2, propelled by x3.
- virnu
-
x1 is brave/valiant/courageous in activity x2 (event) by standard x3.
- viska
-
x1 sees/views/perceives visually x2 under conditions x3.
- vlipa
-
x1 has the power to bring about x2 under conditions x3; x1 is powerful in aspect x2 under x3.
le mamta be mi ku po'o cu vlipa le nu mi cliva — Only my mother has power to make me leave.
- vo
-
digit/number: 4 (digit) [four].
- vofli
-
x1 flies [in air/atmosphere] using lifting/propulsion means x2.
- vo'a
-
pro-sumti: repeats 1st place of main bridi of this sentence.
- vo'e
-
pro-sumti: repeats 2nd place of main bridi of this sentence.
- vo'i
-
pro-sumti: repeats 3rd place of main bridi of this sentence.
- vo'o
-
pro-sumti: repeats 4th place of main bridi of this sentence.
- vo'u
-
pro-sumti: repeats 5th place of main bridi of this sentence.
- voi
-
non-veridical restrictive clause used to form complicated le-like descriptions using "ke'a".
- vorme
-
x1 is a doorway/gateway/access way between x2 and x3 of structure x4.
- vreji
-
x1 is a record of x2 (data/facts/du'u) about x3 (object/event) preserved in medium x4.
- vrusi
-
x1 (ka) is a taste/flavor of/emitted by x2; x2 tastes of/like x1.
- vu
-
location tense distance: far from ... ; yonder at ... ; a long distance from ...
- vu'e
-
attitudinal modifier: virtue - sin.
- vu'i
-
sumti qualifier: the sequence made from set or composed of elements/components; order is vague.
- vu'o
-
joins relative clause/phrase to complete complex or logically connected sumti in afterthought.
- vu'u
-
n-ary mathematical operator: minus; subtraction operator; [(((a - b) - c) - ...)].
- vukro
-
x1 reflects Ukrainian language/culture/nationality in aspect x2.
- vy.
-
letteral for v.
- xabju
-
x1 dwells/lives/resides/abides at/inhabits/is a resident of location/habitat/nest/home/abode x2.
- xagmau
-
xa1=z1 is better than z2 for xa2 by standard xa3, by amount z4.
- xagrai
-
t1=x1 is the best among set/range t4 for x2 by standard x3.
- xajmi
-
x1 is funny/comical to x2 in property/aspect x3 (nu/ka); x3 is what is funny about x1 to x2.
- xalbo
-
x1 uses levity/is non-serious/frivolous about x2 (abstraction).
- xamgu
-
x1 (object/event) is good/beneficial/nice/[acceptable] for x2 by standard x3.
le'e plise cu xamgu le nu kanro .i ji'a le'e plise cu kukte — Apples are good for your health. And, in addition, they taste great.
- xampo
-
x1 is x2 ampere(s) [metric unit] in current (default is 1) by standard x3.
- xamsi
-
x1 is a sea/ocean/gulf/[atmosphere] of planet x2, of fluid x3; (adjective:) x1 is marine.
- xance
-
x1 is a/the hand [body-part] of x2; [metaphor: manipulating tool, waldo].
- xanka
-
x1 is nervous/anxious about x2 (abstraction) under conditions x3.
- xanri
-
x1 [concept] exists in the imagination of/is imagined by/is imaginary to x2.
- xanto
-
x1 is an elephant of species/breed x2.
- xarci
-
x1 is a weapon/arms for use against x2 by x3.
- xatsi
-
x1 is 10-18 of x2 in dimension/aspect x3 (default is units).
- xazdo
-
x1 reflects Asiatic culture/nationality/geography in aspect x2.
- xe
-
5th conversion; switch 1st/5th places.
- xebro
-
x1 reflects Hebrew/Jewish/Israeli culture/nationality/language in aspect x2.
- xecto
-
x1 is a hundred [100; 102] of x2 in dimension/aspect x3 (default is units).
- xeka'a
-
klama modal, 5th place by transport mode ...
- xekri
-
x1 is black/extremely dark-colored [color adjective].
- xelso
-
x1 reflects Greek/Hellenic culture/nationality/language in aspect x2.
- xexso
-
x1 is 1018 of x2 in dimension/aspect x3 (default is units).
- xi
-
subscript; attaches a number of letteral string following as a subscript onto grammar structures.
- xindo
-
x1 reflects Hindi language/culture/religion in aspect x2.
- xirnzebra
-
x1 is a mountain zebra (scientific term: “Equus zebra”).
- xispo
-
x1 reflects Hispano-American culture/nationalities in aspect x2.
- xo
-
digit/number: number/digit/lerfu question.
- xokau
-
number/digit/lerfu indirect question; "how many" in indirect questions like in "I know HOW MANY of them came"
- xrabo
-
x1 reflects Arabic-speaking culture/nationality in aspect x2.
- xrani
-
x1 (event) injures/harms/damages victim x2 in property x3 (ka) resulting in injury x4 (state).
- xriso
-
x1 pertains to the Christian religion/culture/nationality in aspect x2.
- xruki
-
x1 is a turkey [food/bird] of species/breed x2.
- xrula
-
x1 is a/the flower/blossom/bloom [body-part] of plant/species x2; (adjective:) x1 is floral.
- xu
-
discursive: true-false question.
xu do pu djuno — Did you know?
- xunblabi
-
b1=x1 is pink.
- xunre
-
x1 is red/crimson/ruddy [color adjective].
- xurdo
-
x1 reflects Urdu language/culture/nationality in aspect x2.
- xy.
-
letteral for x.
- za
-
time tense distance: medium distance in time.
- zabna
-
x1 is favorable/great/superb/fabulous/dandy/outstanding/swell/admirable/nice/commendable/delightful/desirable/enjoyable/laudable/likable/lovable/wonderful/praiseworthy/high-quality/cool in property x2 by standard x3; x1 rocks in aspect x2 according to x3
xu zabna fa le nu da'i mi skicu le pu zi se zukte be mi la .alis. — I wonder if I should tell Alice what I just did.
- za'a
-
evidential: I observe.
.oi nai za'a melbi tcima — Oh, what a nice weather.
za'a cladu bu'u le bartu — I can hear the loud sound outside.
ja'o carmi carvi — So it must be raining heavily.
- za'e
-
forethought nonce-word indicator; indicates next word is nonce-creation and may be nonstandard.
- za'i
-
abstractor: state (event) abstractor; x1 is continuous state of [bridi] being true.
- za'o
-
interval event contour: continuing too long after natural end of ...; superfective | ---->.
- za'u
-
digit/number: greater than.
le za'u sazri ca denpa — The drivers wait.
- za'ure'u
-
again; in addition to the first time; for the "more"-th time
- zai
-
2-word letteral/shift: alternate alphabet selector follows.
- zarci
-
x1 is a market/store/exchange/shop(s) selling/trading (for) x2, operated by/with participants x3.
- zbasu
-
x1 makes/assembles/builds/manufactures/creates x2 out of materials/parts/components x3.
- zdani
-
x1 is a nest/house/lair/den/[home] of/for x2.
- ze'a
-
time tense interval: a medium length of time.
- ze'e
-
time tense interval: the whole of time.
- ze'i
-
time tense interval: an instantaneous/tiny/short amount of time.
- ze'o
-
location tense relation/direction; beyond/outward/receding from ...
- zei
-
joins preceding and following words into a lujvo.
- zenba
-
x1 (experiencer) increases/is incremented/augmented in property/quantity x2 by amount x3.
- zepti
-
x1 is 10-21 of x2 in dimension/aspect x3 (default is units).
- zerle'a
-
l1 steals l2 from l3, which is a crime according to z2.
- zernerkla
-
x1 trespasses (illegally enters) into x2, which is a crime according to x3
- zetro
-
x1 is 1021 of x2 in dimension/aspect x3 (default is units).
- zgana
-
x1 observes/[notices]/watches/beholds x2 using senses/means x3 under conditions x4.
- zi
-
time tense distance: instantaneous-to-short distance in time.
- zifre
-
x1 is free/at liberty to do/be x2 (event/state) under conditions x3.
- zi'e
-
joins relative clauses which apply to the same sumti.
- zi'o
-
pro-sumti: fills a sumti place, deleting it from selbri place structure;changes selbri semantics.
- zmadu
-
x1 exceeds/is more than x2 in property/quantity x3 (ka/ni) by amount/excess x4.
- zo
-
quote next word only; quotes a single Lojban word (not a cmavo compound or tanru).
zo rozgu cmene mi — "Rose" is my name.
- zo'e
-
pro-sumti: an elliptical/unspecified value; has some value which makes bridi true.
zo'e carvi — It's raining.
mi ca'o tavla zo'e la .lojban. — I'm talking about Lojban.
- zo'i
-
location tense relation/direction; nearer than .../inward/approaching from ...
- zo'o
-
attitudinal modifier: humorously - dully - seriously.
zo'o pei — Are you kidding?
.e'u zo'o renro la .kevin. ti voi kevna — Let's throw Kevin into this hole (kidding ...).
mi kakne le ka plipe fi le ve'i cmana vau zo'o cu'i — I might be able to jump from the hill.
zo'o nai gau do fanza — Seriously, you are annoying.
- zo'u
-
marks end of logical prenex quantifiers/topic identification and start of sentence bridi.
lo'e danlu zo'u mi nelci lo'e mlatu — As for animals, I like cats.
- zoi
-
delimited non-Lojban quotation; the result treated as a block of text.
- zu'a
-
location tense relation/direction; leftwards/to the left of ...
- zu'e
-
zukte modal, 1st place (purposed agent) with goal-seeking actor ...
- zu'i
-
pro-sumti: the typical sumti value for this place in this relationship; affects truth value.
- zu'o
-
abstractor: activity (event) abstractor; x1 is abstract activity of [bridi] composed of x2.
- zu'u
-
discursive: on the one hand - on the other hand.
- zukte
-
x1 is a volitional entity employing means/taking action x2 for purpose/goal x3/to end x3.
- zuljma
-
j1=z1 is/are the left foot/feet of j2=z2.
- zunle
-
x1 is to the left/left-hand side of x2 which faces/in-frame-of-reference x3.
- zutse
-
x1 sits [assumes sitting position] on surface x2.
- zvafa'i
-
x1=facki1 finds/locates x2=zvati1=facki3 (object) at x3=zvati2 (event/location)
- zvati
-
x1 (object/event) is at/attending/present at x2 (event/location).
- zy.
-
letteral for z.
Symbols
- .a: cmavo, The six types of logical connectives, The six types of logical connectives, sumti connection, sumti connection, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, bridi negation and logical connectives, bridi negation and logical connectives, The North Wind and the Sun
- .a'a: Propositional attitude indicators
- .a'e: Propositional attitude indicators
- .a'enai: Propositional attitude indicators
- .a'i: Propositional attitude indicators
- .a'o: What are attitudinal indicators?, Propositional attitude indicators, The North Wind and the Sun
- .a'u: Propositional attitude indicators, More about non-logical connectives, The North Wind and the Sun
- .a'ucu'i: Propositional attitude indicators
- .abu: A to Z in Lojban, plus one, The universal bu, lerfu words as pro-sumti, References to lerfu, References to lerfu, References to lerfu, References to lerfu, References to lerfu, Proposed lerfu words for the Greek alphabet, Proposed lerfu words for the Cyrillic alphabet, Proposed lerfu words for the Hebrew alphabet, The North Wind and the Sun
- .ai: Quotation summary, What are attitudinal indicators?, Propositional attitude indicators, Vocative scales, Non-decimal and compound bases, The North Wind and the Sun
- .ainai: The North Wind and the Sun
- .au: cmavo, What are attitudinal indicators?, Attitudinal modifiers, Non-decimal and compound bases, The North Wind and the Sun
- .ause'i: Attitudinal modifiers
- .ause'inai: Attitudinal modifiers
- .e: cmavo, sumti connection, Truth questions and connective questions, Non-logical connectives, Non-logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, bridi negation and logical connectives, bridi negation and logical connectives, Erasure: SI, SA, SU, The North Wind and the Sun
-
- contrasted with "fa'u": Non-logical connectives
- contrasted with "pi'u": More about non-logical connectives
- .e'a: Propositional attitude indicators, Propositional attitude indicators, The North Wind and the Sun
- .e'e: Propositional attitude indicators, Attitudinal modifiers
- .e'enaise'a: Attitudinal modifiers
- .e'enaise'anai: Attitudinal modifiers
- .e'ese'a: Attitudinal modifiers
- .e'ese'anai: Attitudinal modifiers
- .e'u: Syllabication and stress, Syllabication and stress, Evidentials
-
- compared with "ru'a": Evidentials
- .ebu: A to Z in Lojban, plus one, Accent marks and compound lerfu words, Proposed lerfu words for the Greek alphabet, Proposed lerfu words for the Cyrillic alphabet, Proposed lerfu words for the Hebrew alphabet
- .ei: cmavo, What are attitudinal indicators?, Propositional attitude indicators, Non-decimal and compound bases, The North Wind and the Sun
- .eicai: Attitudes as scales, Attitudes as scales
- .eicu'i: Attitudes as scales, Attitudes as scales
- .einai: Attitudes as scales, Attitudes as scales
- .eiru'e: Attitudes as scales, Attitudes as scales
- .eisai: Attitudes as scales, Attitudes as scales
- .i: The basic structure of longer utterances, The basic structure of longer utterances, The basic structure of longer utterances, The basic structure of longer utterances, The basic structure of longer utterances, Oddball orthographies, cmavo, Modal sentence connection: the causals, Other modal connections, Tense relations between sentences, Tense relations between sentences, Evidentials, Discursives, The six types of logical connectives, The six types of logical connectives, Logical connection of bridi, Logical connection of bridi, Logical connection of bridi, Forethought bridi connection, Forethought bridi connection, Grouping of afterthought connectives, Grouping of afterthought connectives, Truth questions and connective questions, Truth questions and connective questions, More about non-logical connectives, More about non-logical connectives, More about non-logical connectives, More about non-logical connectives, Tenses, modals, and logical connection, Tenses, modals, and logical connection, Tenses, modals, and logical connection, Truth functions and corresponding logical connectives, Rules for making logical and non-logical connectives, bridi negation and logical connectives, bridi negation and logical connectives, bridi negation and logical connectives, bridi negation and logical connectives, A few notes on variables, A few notes on variables, Sentences: I, Sentences: I, Sentences: I, Sentences: I, Sentences: I, Sentences: I, Sentences: I, Sentences: I, Sentences: I, Sentences: I, Sentences: I, Sentences: I, Sentences: I, Sentences: I, Paragraphs: NIhO, Paragraphs: NIhO, Attitude scope markers: FUhE/FUhO, Erasure: SI, SA, SU, The North Wind and the Sun
-
- regarding forethought bridi connection: Forethought bridi connection
- .i'a: Pure emotion indicators
- .i'anai: Propositional attitude indicators, Propositional attitude indicators
- .i'e: Pure emotion indicators, Propositional attitude indicators, Propositional attitude indicators
- .i'enai: Propositional attitude indicators, Propositional attitude indicators
- .i'inai: Attitude questions; empathy; attitude contours
- .ia: cmavo, cmavo, What are attitudinal indicators?, What are attitudinal indicators?, Pure emotion indicators, The North Wind and the Sun
- .ianai: What are attitudinal indicators?, What are attitudinal indicators?, Propositional attitude indicators, Propositional attitude indicators, Discursives, The North Wind and the Sun
- .ibabo: The North Wind and the Sun
- .ibazabo: The North Wind and the Sun
- .ibazibo: The North Wind and the Sun
- .ibu: cmavo, A to Z in Lojban, plus one, Accent marks and compound lerfu words, Proposed lerfu words for the Greek alphabet, Proposed lerfu words for the Cyrillic alphabet, Proposed lerfu words for the Hebrew alphabet
- .icabo: The North Wind and the Sun
- .ice'o
-
- contrasted with ".ibabo": More about non-logical connectives
- .ie: cmavo, What are attitudinal indicators?, Pure emotion indicators, Propositional attitude indicators, Vocative scales, The North Wind and the Sun
- .ienai: Negation of minor grammatical constructs
- .iesai: The North Wind and the Sun
- .ii: cmavo, What are attitudinal indicators?, Attitudes as scales
- .iicai: The North Wind and the Sun
- .ija: bridi negation and logical connectives
- .ija'ebo: The North Wind and the Sun
- .ije: bridi negation and logical connectives, A few notes on variables, A few notes on variables, The North Wind and the Sun
- .ijebabo: Tenses, modals, and logical connection
- .iki'ubo: The North Wind and the Sun
- .ini'ibo: The North Wind and the Sun
- .io: cmavo, What are attitudinal indicators?, Attitudinal modifiers
- .iseju: The North Wind and the Sun
- .iseki'ubo: The North Wind and the Sun
- .isemu'ibo: The North Wind and the Sun
- .iu: cmavo, What are attitudinal indicators?
- .iucai: Propositional attitude indicators
- .lojban.: brivla
- .o: cmavo, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives
- .o'e: The North Wind and the Sun
- .o'ocu'i: The North Wind and the Sun
- .o'u: cmavo, Emotional categories, Emotional categories
- .obu: A to Z in Lojban, plus one, Proposed lerfu words for the Greek alphabet, Proposed lerfu words for the Cyrillic alphabet, Proposed lerfu words for the Hebrew alphabet
- .oi: What are attitudinal indicators?, Pure emotion indicators, Attitudes as scales, Compound indicators, The North Wind and the Sun
- .oicai: Propositional attitude indicators
- .oinai: Compound indicators
- .onai: Logical and non-logical connectives within mekso
- .u: cmavo, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives
- .u'a: The North Wind and the Sun
- .u'e: cmavo, cmavo
- .u'o: The North Wind and the Sun
- .u'u: Pure emotion indicators, Propositional attitude indicators, The North Wind and the Sun
- .u'unai: Attitudinal modifiers
- .ua: cmavo, What are attitudinal indicators?, The North Wind and the Sun
- .uanai: Miscellaneous indicators
- .ubu: A to Z in Lojban, plus one, Proposed lerfu words for the Greek alphabet, Proposed lerfu words for the Cyrillic alphabet, Proposed lerfu words for the Hebrew alphabet
- .ue: cmavo, What are attitudinal indicators?, The North Wind and the Sun
- .uesai: The North Wind and the Sun
- .ui: cmavo, What are attitudinal indicators?, What are attitudinal indicators?, The universal bu, Parenthesis and metalinguistic commentary: TO, TOI, SEI
- .uinai: Negation of minor grammatical constructs, The North Wind and the Sun
- .uiro'obe'unai: Attitudinal modifiers
- .uisai: The North Wind and the Sun
- .uisaidai: The North Wind and the Sun
- .uo: cmavo, What are attitudinal indicators?, Pure emotion indicators, The North Wind and the Sun
- .uu: cmavo, What are attitudinal indicators?, Pure emotion indicators, Pure emotion indicators, The North Wind and the Sun
- .y'y.: Vowel pairs, A to Z in Lojban, plus one, A to Z in Lojban, plus one, A to Z in Lojban, plus one, Proposed lerfu words for the Greek alphabet, Proposed lerfu words for the Hebrew alphabet
- .y.: cmavo, Hesitation: Y, Hesitation: Y, List of cmavo interactions
- .ybu: A to Z in Lojban, plus one, Acronyms, Proposed lerfu words for the Cyrillic alphabet, Proposed lerfu words for the Hebrew alphabet
A
- A selma'o
-
- in mekso: Logical and non-logical connectives within mekso
- introduction: sumti connection
- opposed to JOI: Non-logical connectives
- transformation to I + JA: sumti connection
- usage in mekso: Logical and non-logical connectives within mekso
- usage in tensed connectives: Tenses, modals, and logical connection
- usage with BO: Tenses, modals, and logical connection
B
- ba: Tenses, cmavo, Anaphoric pro-sumti and pro-bridi: the ri-series and the go'i-series, Temporal tenses: PU and ZI, Interval sizes: VEhA and ZEhA, Event contours: ZAhO and re'u, Sticky and multiple tenses: KI, Tensed logical connectives, Logical and non-logical connections between tenses, Tenses versus modals, Tenses, modals, and logical connection, Tenses, modals, and logical connection, Tenses, modals, and logical connection, Tenses, modals, and logical connection, The North Wind and the Sun
- ba'a: Evidentials, Evidentials
- ba'acu'i: Evidentials
- ba'anai: Evidentials
- ba'e: The universal bu, Contrastive emphasis: BAhE, Contrastive emphasis: BAhE, Contrastive emphasis: BAhE, The North Wind and the Sun
-
- interaction with "bu": The universal bu
- ba'i: Modal sentence connection: the causals
- ba'o: Event contours: ZAhO and re'u, Event contours: ZAhO and re'u, Event contours: ZAhO and re'u, Event contours: ZAhO and re'u, Sticky and multiple tenses: KI, Sticky and multiple tenses: KI, Event-type abstractors and event contour tenses, Event-type abstractors and event contour tenses, Event-type abstractors and event contour tenses, Event-type abstractors and event contour tenses, Event-type abstractors and event contour tenses, The North Wind and the Sun
-
- as futureward of event: Event contours: ZAhO and re'u
- derivation of word: Event contours: ZAhO and re'u
- explanation of derivation: Event contours: ZAhO and re'u
- badri: The North Wind and the Sun
- bai: Modal sentence connection: the causals, Modal selbri, Modal selbri, Modal selbri, Sticky modals, Termset logical connection
- bai ke: Modal selbri
- BAI selma'o
-
- as short forms for "fi'o"-constructs: Modal tags: BAI
- causals: Modal sentence connection: the causals
- cmavo having irregular forms: CV'V cmavo of selma'o BAI with irregular forms
- complete table: Complete table of BAI cmavo with rough English equivalents
- effect of conversion on: Modal tags: BAI
- for comparisons: Modal relative phrases; Comparison
- forethought and afterthought: Other modal connections
- form of cmavo in: Modal tags: BAI
- in modal selbri: Modal selbri
- introduction: Modal tags: BAI
- logical and non-logical connection: Logical and non-logical connection of modals
- mix logical and modal connections: Mixed modal connection
- negation of: Modal negation
- rationale for modal tags: Modal tags: BAI
- rationale for selection of BAI cmavo: Modal tags: BAI
- with conversion: Modal conversion: JAI
- bajra: Some words used to indicate selbri relations, The North Wind and the Sun
- bakrecpa'o: Eliding KE and KEhE rafsi from lujvo
- bakri: rafsi
- baku: The North Wind and the Sun
- balsoi: Symmetrical and asymmetrical lujvo, Symmetrical and asymmetrical lujvo, Symmetrical and asymmetrical lujvo, Ordering lujvo places., Ordering lujvo places., Implicit-abstraction lujvo
- balvi: Temporal tenses: PU and ZI, Tenses versus modals, Tenses versus modals, Tenses versus modals
- banfi: The North Wind and the Sun
- bangu: Lojban names
- banli: Symmetrical and asymmetrical lujvo, Symmetrical and asymmetrical lujvo, Ordering lujvo places., The North Wind and the Sun
- banzu: The North Wind and the Sun
- bapu: Tenses, modals, and logical connection
- barda: Simple tanru, The North Wind and the Sun
- bartu: The North Wind and the Sun
- basti: Implicit-abstraction lujvo, Implicit-abstraction lujvo, Implicit-abstraction lujvo
- basygau: Implicit-abstraction lujvo, Implicit-abstraction lujvo
- batci: Dropping the prenex
- bau: Modal sentence connection: the causals, Modal selbri, Modal conversion: JAI, Sticky modals
- bavla'i: lujvo with more than two parts., lujvo with more than two parts.
- bavlamdei: lujvo with more than two parts., lujvo with more than two parts., lujvo with more than two parts.
- baxso: Cultural and other non-algorithmic gismu
- bazi: The North Wind and the Sun
- baziku: The North Wind and the Sun
- bazu: The North Wind and the Sun
- be: Linked sumti: be - bei - be'o, Linked sumti: be - bei - be'o, Linked sumti: be - bei - be'o, Linked sumti: be - bei - be'o, Inversion of tanru: co, Inversion of tanru: co, Inversion of tanru: co, Scalar negation of selbri, Scalar negation of selbri, Scalar negation of selbri, Modal tags: BAI, Modal tags: BAI, Why have lujvo?, selbri and tanru negation, Expressing scales in selbri negation, Using naku outside a prenex, Questions and answers, Parenthesis and metalinguistic commentary: TO, TOI, SEI, The North Wind and the Sun
- be'a: Space interval modifiers: FEhE, List of spatial directions and direction-like relations
- be'i: Modal sentence connection: the causals
- be'o: Linked sumti: be - bei - be'o, Linked sumti: be - bei - be'o, Linked sumti: be - bei - be'o, Linked sumti: be - bei - be'o, Linked sumti: be - bei - be'o, Linked sumti: be - bei - be'o, Linked sumti: be - bei - be'o, Inversion of tanru: co, Inversion of tanru: co, selbri based on sumti: me, Scalar negation of selbri, Why have lujvo?, The North Wind and the Sun
-
- effect of "ku" on elidability of: Linked sumti: be - bei - be'o
- effect of relative clauses on elidability of: Linked sumti: be - bei - be'o
- elidability of: Linked sumti: be - bei - be'o
- be'u: Attitudinal modifiers, Attitudinal modifiers, Attitudinal modifiers
- be'unai: Attitudinal modifiers
- bebna: The North Wind and the Sun
- bei: Linked sumti: be - bei - be'o, Linked sumti: be - bei - be'o, Inversion of tanru: co, Inversion of tanru: co, Scalar negation of selbri, Why have lujvo?, selbri and tanru negation, Using naku outside a prenex, Questions and answers, Parenthesis and metalinguistic commentary: TO, TOI, SEI, The North Wind and the Sun
- bemro: Cultural and other non-algorithmic gismu
- bengo: Cultural and other non-algorithmic gismu
- bernanjudri: The North Wind and the Sun
- bersa: The North Wind and the Sun
- berti: The North Wind and the Sun
- bi'e: Simple infix expressions and equations, Simple infix expressions and equations, Simple infix expressions and equations, Simple infix expressions and equations, Logical and non-logical connectives within mekso, Logical and non-logical connectives within mekso
-
- effect on following operator: Simple infix expressions and equations
- bi'i: Interval connectives and forethought non-logical connection, Interval connectives and forethought non-logical connection, Interval connectives and forethought non-logical connection, Interval connectives and forethought non-logical connection, Interval connectives and forethought non-logical connection, Interval connectives and forethought non-logical connection, Logical and non-logical connectives within mekso
- bi'o: Logical and non-logical connections between tenses, Interval connectives and forethought non-logical connection, Interval connectives and forethought non-logical connection, Interval connectives and forethought non-logical connection, Interval connectives and forethought non-logical connection, Interval connectives and forethought non-logical connection, Interval connectives and forethought non-logical connection, Logical and non-logical connectives within mekso
- bi'u: Miscellaneous indicators, Miscellaneous indicators
- bi'unai: Miscellaneous indicators, Miscellaneous indicators, The North Wind and the Sun
- BIhI selma'o
-
- grammar of: Interval connectives and forethought non-logical connection
- usage with JOI in forethought connectives: Interval connectives and forethought non-logical connection
- bilga: The North Wind and the Sun
- bilma: rafsi
- bindo: Cultural and other non-algorithmic gismu
- birka: Relative phrases
- bitmu: The North Wind and the Sun
- blabi: Relative clauses and descriptors, The North Wind and the Sun
- blaci: rafsi, rafsi, The North Wind and the Sun
- blakanla: Eliding SE rafsi from tertau, Eliding SE rafsi from tertau
- blanu: Linked sumti: be - bei - be'o, Linked sumti: be - bei - be'o, Linked sumti: be - bei - be'o, Inversion of tanru: co, Miscellaneous indicators, Metalinguistic negation forms
- blari'o: Some words used to indicate selbri relations, Description sumti
- blaselkanla: Eliding SE rafsi from tertau
- blolei: lujvo-making examples, lujvo-making examples, lujvo-making examples
- bloti: lujvo-making examples, Demonstrative pro-sumti: the ti-series
- bo: Three-part tanru grouping with bo, Three-part tanru grouping with bo, Three-part tanru grouping with bo, Three-part tanru grouping with bo, Complex tanru grouping, Complex tanru grouping, Complex tanru grouping, Complex tanru grouping, Complex tanru grouping, Complex tanru grouping, Complex tanru with ke and ke'e, Logical connection within tanru, Logical connection within tanru, Logical connection within tanru, Logical connection within tanru, Logical connection within tanru, Logical connection within tanru, Logical connection within tanru, Logical connection within tanru, Logical connection within tanru, Inversion of tanru: co, Inversion of tanru: co, Scalar negation of selbri, Scalar negation of selbri, Scalar negation of selbri, “Pretty little girls' school” : forty ways to say it, “Pretty little girls' school” : forty ways to say it, sumti qualifiers, sumti qualifiers, Modal sentence connection: the causals, Modal sentence connection: the causals, Tense relations between sentences, Tense relations between sentences, Tensed logical connectives, Tensed logical connectives, Tensed logical connectives, Why have lujvo?, Grouping of afterthought connectives, Grouping of afterthought connectives, Grouping of afterthought connectives, Grouping of afterthought connectives, Grouping of afterthought connectives, Grouping of afterthought connectives, Grouping of afterthought connectives, Grouping of afterthought connectives, Grouping of afterthought connectives, Grouping of afterthought connectives, Grouping of afterthought connectives, Grouping of afterthought connectives, Grouping of afterthought connectives, Multiple compound bridi, Logical connection within tanru, More about non-logical connectives, Logical and non-logical connectives within mekso, Logical and non-logical connectives within mekso, Tenses, modals, and logical connection, Tenses, modals, and logical connection, Tenses, modals, and logical connection, Tenses, modals, and logical connection, Tenses, modals, and logical connection, Tenses, modals, and logical connection, Tenses, modals, and logical connection, Tenses, modals, and logical connection, Tenses, modals, and logical connection, Tenses, modals, and logical connection, selbri and tanru negation, Miscellany, Sentences: I, Attitude scope markers: FUhE/FUhO, The North Wind and the Sun
-
- and forethought connectives : Grouping of afterthought connectives
- contrasted with "ke" for tensed logical connection: Tenses, modals, and logical connection
- contrasted with "tu'e" for tensed logical connection: Tenses, modals, and logical connection
- in jeks for operators: Logical and non-logical connectives within mekso
- in joiks for operators: Logical and non-logical connectives within mekso
- in logical connectives: Grouping of afterthought connectives
- right-grouping: Grouping of afterthought connectives
- BO selma'o
- boi: Logical and non-logical connectives within mekso, lerfu words as pro-sumti, lerfu words as pro-sumti, lerfu words as pro-sumti, lerfu words as pro-sumti, Mathematical uses of lerfu strings, Forethought operators (Polish notation, functions), Forethought operators (Polish notation, functions), Forethought operators (Polish notation, functions), Special mekso selbri, Special mekso selbri, Subscripts, Subscripts, Reverse Polish notation, Other uses of mekso, Subscripts: XI
-
- effect on elidability of "me'u": Special mekso selbri
- eliding from lerfu strings: lerfu words as pro-sumti
- exception before MAI: Other uses of mekso
- exception before MOI: Special mekso selbri
- exception before ROI: Other uses of mekso
- required between pro-sumti lerfu string and quantifier: lerfu words as pro-sumti
- botpi: The North Wind and the Sun
- bradi: The gismu creation algorithm, The North Wind and the Sun
- brazo: Cultural and other non-algorithmic gismu
- bredi: The gismu creation algorithm
- bridi: The concept of the bridi, The concept of the bridi, Lojban grammatical terms, Syllabication and stress, The gismu creation algorithm, Property abstractions, Property abstractions
- brife: The North Wind and the Sun
- brito: Cultural and other non-algorithmic gismu
- brivla: Examples of brivla, Lojban grammatical terms, Syllabication and stress, brivla, lujvo, rafsi
- broda: gismu, Cultural and other non-algorithmic gismu, Assignable pro-sumti and pro-bridi: the ko'a-series and the broda-series, Assignable pro-sumti and pro-bridi: the ko'a-series and the broda-series, Assignable pro-sumti and pro-bridi: the ko'a-series and the broda-series, Assignable pro-sumti and pro-bridi: the ko'a-series and the broda-series, Assignable pro-sumti and pro-bridi: the ko'a-series and the broda-series, Subscripts: XI
- broda-series
-
- for pro-bridi as compared with ko'a-series for pro-sumti: Assignable pro-sumti and pro-bridi: the ko'a-series and the broda-series
- pro-bridi: Assignable pro-sumti and pro-bridi: the ko'a-series and the broda-series
- pro-bridi and assigning with "cei": Assignable pro-sumti and pro-bridi: the ko'a-series and the broda-series
- pro-bridi use as abstract pattern: Assignable pro-sumti and pro-bridi: the ko'a-series and the broda-series
- pro-bridi use as sample gismu: Assignable pro-sumti and pro-bridi: the ko'a-series and the broda-series
- pro-bridi with no assignment: Assignable pro-sumti and pro-bridi: the ko'a-series and the broda-series
- word-form rationale: Assignable pro-sumti and pro-bridi: the ko'a-series and the broda-series
- brode: gismu, Cultural and other non-algorithmic gismu, Assignable pro-sumti and pro-bridi: the ko'a-series and the broda-series, Assignable pro-sumti and pro-bridi: the ko'a-series and the broda-series, Subscripts: XI
- brodi: gismu, The gismu creation algorithm, Cultural and other non-algorithmic gismu, Subscripts: XI
- brodo: gismu, Cultural and other non-algorithmic gismu, Subscripts: XI
- brodu: gismu, Cultural and other non-algorithmic gismu, Subscripts: XI
- bu: A to Z in Lojban, plus one, A to Z in Lojban, plus one, A to Z in Lojban, plus one, The universal bu, The universal bu, The universal bu, The universal bu, The universal bu, The universal bu, The universal bu, The universal bu, The universal bu, The universal bu, The universal bu, The universal bu, The universal bu, Alien alphabets, Alien alphabets, Alien alphabets, Alien alphabets, Alien alphabets, Alien alphabets, Alien alphabets, Alien alphabets, Punctuation marks, Punctuation marks, Punctuation marks, Punctuation marks, Acronyms, Acronyms, List of all auxiliary lerfu-word cmavo, List of cmavo interactions, List of cmavo interactions, List of cmavo interactions, List of cmavo interactions, The North Wind and the Sun
-
- and compound cmavo: The universal bu
- effect of multiple: The universal bu
- effect on preceding word: A to Z in Lojban, plus one
- for extension of lerfu word set: The universal bu
- grammar of: The universal bu
- interaction with "ba'e": The universal bu
- interaction with language shift: Alien alphabets
- omitting in acronyms names based on lerfu words: Acronyms
- bu'a: lujvo based on pro-sumti, selbri variables, selbri variables, selbri variables, A few notes on variables
- bu'a-series
-
- pro-sumti for bound variables: Bound variable pro-sumti and pro-bridi: the da-series and the bu'a-series
- bu'e: selbri variables, selbri variables, A few notes on variables
- bu'i: selbri variables, selbri variables, A few notes on variables
- bu'o: Attitude questions; empathy; attitude contours, Attitude questions; empathy; attitude contours, The North Wind and the Sun
- bu'ocu'i: Attitude questions; empathy; attitude contours
- bu'onai: Attitude questions; empathy; attitude contours
- bu'u: Temporal tenses: PU and ZI, List of spatial directions and direction-like relations, The North Wind and the Sun
-
- compared with "ca": Temporal tenses: PU and ZI
- bubu: The universal bu
- budjo: Cultural and other non-algorithmic gismu
- by.: rafsi, A to Z in Lojban, plus one, A to Z in Lojban, plus one, lerfu words as pro-sumti, Proposed lerfu words for the Greek alphabet, Proposed lerfu words for the Cyrillic alphabet, Proposed lerfu words for the Hebrew alphabet
- by.by.: The North Wind and the Sun
C
- ca: Tenses, Temporal tenses: PU and ZI, Interval sizes: VEhA and ZEhA, Tenses as sumtcita, Tenses as sumtcita, Tenses in subordinate bridi, Tenses in subordinate bridi, Tenses in subordinate bridi, Actuality, potentiality, capability: CAhA, Tenses, modals, and logical connection, The North Wind and the Sun
-
- compared with "bu'u": Temporal tenses: PU and ZI
- meaning as a sumtcita: Tenses as sumtcita
- meaning when following interval specification: Interval sizes: VEhA and ZEhA
- rational for: Temporal tenses: PU and ZI
- ca'a: Actuality, potentiality, capability: CAhA
- ca'e: Evidentials, Evidentials
- ca'i: Modal sentence connection: the causals
- ca'o: Event contours: ZAhO and re'u, Event contours: ZAhO and re'u, Event contours: ZAhO and re'u, Event-type abstractors and event contour tenses, Event-type abstractors and event contour tenses, Event-type abstractors and event contour tenses, Event-type abstractors and event contour tenses, The North Wind and the Sun
-
- derivation of word: Event contours: ZAhO and re'u
- ca'u: List of spatial directions and direction-like relations
- cabdei: The North Wind and the Sun
- cabna: Temporal tenses: PU and ZI, The North Wind and the Sun
- cadzu: Conversion of simple selbri, Conversion of simple selbri, Scalar negation of selbri, Scalar negation of selbri, Scalar negation of selbri, Eliding KE and KEhE rafsi from lujvo, The North Wind and the Sun
- cafne: Lojban sumti raising, The North Wind and the Sun
- cagyce'u: Some types of asymmetrical tanru
- CAhA selma'o
-
- making sticky: Actuality, potentiality, capability: CAhA
- order in tense construct: Actuality, potentiality, capability: CAhA
- cai: Attitudes as scales, Attitudes as scales
- cakcinki: Dependent places, Dependent places, Dependent places
- caku: The North Wind and the Sun
- calku: Dependent places, Dependent places
- canci: The North Wind and the Sun
- canko: The North Wind and the Sun
- canlu: The North Wind and the Sun
- carmi: Attitudes as scales, The North Wind and the Sun
- carna: The North Wind and the Sun
- cartu: The North Wind and the Sun
- carvi: The North Wind and the Sun
- casnu: More about non-logical connectives, More about non-logical connectives, The North Wind and the Sun
- catlu: The North Wind and the Sun
- cau: Modal sentence connection: the causals
- ce: cmavo, Non-logical connectives, Non-logical connectives, Non-logical connectives, The North Wind and the Sun
- ce'a: Alien alphabets, Punctuation marks
- ce'e: Logical and non-logical connection of modals, Termset logical connection, Grouping of quantifiers
- ce'i: Signs and numerical punctuation, Miscellany
- ce'o: Non-logical connectives, Non-logical connectives, Non-logical connectives, Non-logical connectives, More about non-logical connectives, Logical and non-logical connectives within mekso, Logical and non-logical connectives within mekso
-
- ".ice'o" contrasted with ".ibabo": More about non-logical connectives
- ce'u: Abstraction focus pro-sumti: ce'u, Abstraction focus pro-sumti: ce'u, Abstraction focus pro-sumti: ce'u, Property abstractions, Property abstractions, The North Wind and the Sun
-
- use in specifying sumti place of property in abstraction: Abstraction focus pro-sumti: ce'u
- cedra: The North Wind and the Sun
- cei: Assignable pro-sumti and pro-bridi: the ko'a-series and the broda-series, Anaphoric pro-sumti and pro-bridi: the ri-series and the go'i-series, Pro-sumti and pro-bridi cancelling
-
- for broda-series assignment; compared with "goi" for ko'a-series assignment: Assignable pro-sumti and pro-bridi: the ko'a-series and the broda-series
- for broda-series pro-bridi assignment: Assignable pro-sumti and pro-bridi: the ko'a-series and the broda-series
- censa: The North Wind and the Sun
- centi: Cultural and other non-algorithmic gismu
- cerni: The North Wind and the Sun
- certu: The North Wind and the Sun
- ci: Quantified sumti, Quantified descriptions, Quantified descriptions, Simple infix expressions and equations, Simple infix expressions and equations, Forethought operators (Polish notation, functions), Reverse Polish notation, Reverse Polish notation, The North Wind and the Sun
- ci'ajbu: Some types of asymmetrical tanru
- ci'e: Modal sentence connection: the causals, Metalinguistic negation forms
- ci'o: Modal sentence connection: the causals
- ci'u: Modal sentence connection: the causals, Modal relative phrases; Comparison, Notes on gismu place structures, Expressing scales in selbri negation, Expressing scales in selbri negation, Metalinguistic negation forms
- ciblu: The North Wind and the Sun
- cidja: fu'ivla
- cidjrspageti: fu'ivla
- cidni: The North Wind and the Sun
- cikna: The North Wind and the Sun
- cilce: The North Wind and the Sun
- cilre: The North Wind and the Sun
- cimoi: The North Wind and the Sun
- cinfo: Notes on gismu place structures, Notes on gismu place structures
- cinki: Dependent places, Notes on gismu place structures
- cinla: The North Wind and the Sun
- cipni: The North Wind and the Sun
- cipnrstrigi: Some types of symmetrical tanru
- cirla: fu'ivla
- ciska: The North Wind and the Sun
- ciste: Expressing scales in selbri negation, Expressing scales in selbri negation, Metalinguistic negation forms
- citka: Implicit-abstraction lujvo, The North Wind and the Sun
- citmau: Comparatives and superlatives, Comparatives and superlatives
- citno: Comparatives and superlatives, Comparatives and superlatives
- cizra: The North Wind and the Sun
- ckaji: The North Wind and the Sun
- ckiku: The North Wind and the Sun
- ckule: Three-part tanru grouping with bo, Three-part tanru grouping with bo, Linked sumti: be - bei - be'o, Linked sumti: be - bei - be'o, Linked sumti: be - bei - be'o, Linked sumti: be - bei - be'o, Dependent places, The North Wind and the Sun
- cladakfu: lujvo with more than two parts.
- cladakyxa'i: Some types of asymmetrical tanru, lujvo with more than two parts., lujvo with more than two parts., lujvo with more than two parts.
- cladu: The North Wind and the Sun
- clani: lujvo with more than two parts., The North Wind and the Sun
- clira: The North Wind and the Sun
- cliva: Dependent places, Dependent places, The North Wind and the Sun
- cmaci: fu'ivla
- cmacma: The North Wind and the Sun
- cmalu: Simple tanru, Three-part tanru grouping with bo, Complex tanru grouping, Linked sumti: be - bei - be'o, The North Wind and the Sun
- cmana: The North Wind and the Sun
- cmaro'i: Some types of asymmetrical tanru
- cmavo: Variant bridi structure, Lojban grammatical terms, Syllabication and stress, gismu, Cultural and other non-algorithmic gismu, Cultural and other non-algorithmic gismu
- cmene: The North Wind and the Sun
- cmevla: Syllabication and stress, cmevla
- cmima: Other useful selbri for mekso bridi
- cnebo: The North Wind and the Sun
- cnita: The North Wind and the Sun
- co: Inversion of tanru: co, Inversion of tanru: co, Inversion of tanru: co, Inversion of tanru: co, Inversion of tanru: co, Inversion of tanru: co, Inversion of tanru: co, Inversion of tanru: co, Inversion of tanru: co, selbri and tanru negation, The North Wind and the Sun
- co'a: Event contours: ZAhO and re'u, Event contours: ZAhO and re'u, Space interval modifiers: FEhE, Event-type abstractors and event contour tenses, Event-type abstractors and event contour tenses, The North Wind and the Sun
- co'e: Indefinite pro-sumti and pro-bridi: the zo'e-series and the co'e-series, Indefinite pro-sumti and pro-bridi: the zo'e-series and the co'e-series, Indefinite pro-sumti and pro-bridi: the zo'e-series and the co'e-series, lujvo based on pro-sumti, GOhA and other pro-bridi by series, The North Wind and the Sun
-
- as selbri place-holder: Indefinite pro-sumti and pro-bridi: the zo'e-series and the co'e-series
- rationale for word form: Indefinite pro-sumti and pro-bridi: the zo'e-series and the co'e-series
- co'e-series
- co'i: Event contours: ZAhO and re'u, Event-type abstractors and event contour tenses, Event-type abstractors and event contour tenses, Event-type abstractors and event contour tenses, Event-type abstractors and event contour tenses, The North Wind and the Sun
- co'o: Vocatives and commands, Negation of minor grammatical constructs
- co'u: Event contours: ZAhO and re'u, Event contours: ZAhO and re'u, Event-type abstractors and event contour tenses, Event-type abstractors and event contour tenses, Event-type abstractors and event contour tenses, The North Wind and the Sun
- coi: Vocatives and commands, cmavo, The syntax of vocative phrases
- COI selma'o
-
- effect on referent of "do": Personal pro-sumti: the mi-series
- effect on referent of "mi": Personal pro-sumti: the mi-series
- introduction: Personal pro-sumti: the mi-series
- ordering multiple with "mi'e": Vocative scales
- vocative scales: Vocative scales
- with relative clauses: Relative clauses in vocative phrases
- coico'o: Vocative scales
- condi: The North Wind and the Sun
- cpana: The North Wind and the Sun
- cpumi'i: Some types of asymmetrical tanru
- crane: The North Wind and the Sun
- crepu: The North Wind and the Sun
- cribe: The three basic description types
- crino: The North Wind and the Sun
- ctigau: Implicit-abstraction lujvo, Implicit-abstraction lujvo
- ctuca: The North Wind and the Sun
- cu: Some simple Lojban bridi, Variant bridi structure, Variant bridi structure, Variant bridi structure, Variant bridi structure, Variant bridi structure, Description sumti, Description sumti, Description sumti, Questions, Tenses, Tenses, The three basic description types, Standard bridi form: cu, Standard bridi form: cu, Tagging places: FA, Tagging places: FA, Modal selbri, Modal selbri, Introductory, Introductory, The syntax of abstraction, bridi negation, Truth questions, The North Wind and the Sun
-
- as selbri separator: Standard bridi form: cu
- effect of selbri-first bridi on: Tagging places: FA
- effect of tense specification: Introductory
- effect on elidability of "ku": The three basic description types
- effect on elidable terminators: Standard bridi form: cu
- necessity of: Standard bridi form: cu
- need for
-
- quick-tour version: Description sumti
- omission of
-
- quick-tour version: Some simple Lojban bridi
- use of
-
- quick-tour version: Some simple Lojban bridi
- usefulness of: Standard bridi form: cu
- cu'e: Tense questions: cu'e, Tense questions: cu'e, Questions and answers
-
- combining with other tense cmavo: Tense questions: cu'e
- cu'i: What are attitudinal indicators?, Pure emotion indicators, Attitudes as scales, Attitudes as scales, The space of emotions, The North Wind and the Sun
- cu'o: Special mekso selbri, Miscellany, Miscellany, mekso selma'o summary
- cu'u: cmavo, Modal sentence connection: the causals, Modal relative phrases; Comparison
- cukta: The North Wind and the Sun
- culno: The North Wind and the Sun
- cumki: Attitudes as scales, The North Wind and the Sun
- cunso: Miscellany, Miscellany, Table of MOI cmavo, with associated rafsi and place structures
- cupra: The North Wind and the Sun
- curmi: The North Wind and the Sun
- cusku: Modal relative phrases; Comparison, Anomalous lujvo, Anomalous lujvo, More on quotations: ZO, ZOI, The North Wind and the Sun
- cutci: Some words used to indicate selbri relations
- cuxna: Non-logical connectives, The North Wind and the Sun
- cy.: cmavo, A to Z in Lojban, plus one, A to Z in Lojban, plus one, Proposed lerfu words for the Cyrillic alphabet, Proposed lerfu words for the Hebrew alphabet
D
- da: Pro-sumti summary, Indirect questions, Indirect questions, Compound bridi, bridi negation, Existential claims, prenexes, and variables, Existential claims, prenexes, and variables, Existential claims, prenexes, and variables, Universal claims, Universal claims, Restricted claims: da poi, Restricted claims: da poi, Restricted claims: da poi, Dropping the prenex, Dropping the prenex, Variables with generalized quantifiers, Variables with generalized quantifiers, Grouping of quantifiers, The problem of “any”, bridi negation and logical connectives, bridi negation and logical connectives, bridi negation and logical connectives, bridi negation and logical connectives, Using naku outside a prenex, Using naku outside a prenex, selbri variables, A few notes on variables, A few notes on variables, A few notes on variables, A few notes on variables, A few notes on variables, A few notes on variables, Subscripts: XI, The North Wind and the Sun
-
- as a translation for "something": Existential claims, prenexes, and variables
- contrasted with "zo'e": Existential claims, prenexes, and variables
- da prami da
-
- contrasted with "da prami de": Existential claims, prenexes, and variables
- da prami de
-
- contrasted with "da prami da": Existential claims, prenexes, and variables
- da'a: Indefinite numbers, Indefinite numbers, Indefinite numbers, Indefinite numbers, Miscellany
- da'e: Pro-sumti summary, Utterance pro-sumti: the di'u-series
- da'i: Discursives, Discursives, The North Wind and the Sun
- da'inai: Discursives
- da'o: Pro-sumti and pro-bridi cancelling, Pro-sumti and pro-bridi cancelling, Paragraphs: NIhO, List of cmavo interactions
-
- for cancellation of pro-sumti/pro-bridi assignment: Pro-sumti and pro-bridi cancelling
- syntax of: Pro-sumti and pro-bridi cancelling
- da'u: Pro-sumti summary
- da-series
-
- after third: Subscripts: XI
- more than three variables under one scope: Subscripts: XI
- pro-sumti for bound variables: Bound variable pro-sumti and pro-bridi: the da-series and the bu'a-series
- dadgreku: Some types of asymmetrical tanru
- dadjo: Cultural and other non-algorithmic gismu
- dadysli: Some types of asymmetrical tanru, Some types of asymmetrical tanru
- dai: Attitude questions; empathy; attitude contours, Attitude questions; empathy; attitude contours, Attitude questions; empathy; attitude contours, Attitude questions; empathy; attitude contours, The North Wind and the Sun
- dakfu: lujvo with more than two parts., The North Wind and the Sun
- dalmikce: Ordering lujvo places.
- dandu: The North Wind and the Sun
- danlu: Ordering lujvo places., The North Wind and the Sun
- darsi: The North Wind and the Sun
- darvistci: The North Wind and the Sun
- daski: The North Wind and the Sun
- dasni: The North Wind and the Sun
- de: Pro-sumti summary, bridi negation, Existential claims, prenexes, and variables, Existential claims, prenexes, and variables, Universal claims, Restricted claims: da poi, Dropping the prenex, Variables with generalized quantifiers, Grouping of quantifiers, bridi negation and logical connectives, Using naku outside a prenex, Using naku outside a prenex, selbri variables, A few notes on variables
- de'a: Event contours: ZAhO and re'u, Event-type abstractors and event contour tenses, Event-type abstractors and event contour tenses
- de'e: Pro-sumti summary, Utterance pro-sumti: the di'u-series
- de'i: Modal sentence connection: the causals, Modal relative phrases; Comparison
- de'u: Pro-sumti summary
- decti: Cultural and other non-algorithmic gismu
- degji: The North Wind and the Sun
- degygutci: The North Wind and the Sun
- dei: Pro-sumti summary, Utterance pro-sumti: the di'u-series, Utterance pro-sumti: the di'u-series
- dejni: Multiple compound bridi, Multiple compound bridi
- dekto: Cultural and other non-algorithmic gismu
- delno: Cultural and other non-algorithmic gismu
- denci: Some types of asymmetrical tanru
- denpa: The universal bu, The universal bu, The North Wind and the Sun
- dertu: The North Wind and the Sun
- derxi: The North Wind and the Sun
- di: cmavo, Pro-sumti summary, bridi negation, Existential claims, prenexes, and variables, Restricted claims: da poi, Dropping the prenex, Variables with generalized quantifiers, bridi negation and logical connectives, selbri variables, A few notes on variables
- di'a: Event contours: ZAhO and re'u, Event-type abstractors and event contour tenses, Event-type abstractors and event contour tenses, The North Wind and the Sun
- di'e: Pro-sumti summary, Utterance pro-sumti: the di'u-series, Utterance pro-sumti: the di'u-series, More about non-logical connectives, The North Wind and the Sun
-
- effect of "tu'e"/"tu'u" on: More about non-logical connectives
- di'i: Interval properties: TAhE and roi
- di'inai: Interval properties: TAhE and roi
- di'o: Modal sentence connection: the causals
- di'u: The sumti di'u and la'e di'u, Pro-sumti summary, Utterance pro-sumti: the di'u-series, Utterance pro-sumti: the di'u-series, Utterance pro-sumti: the di'u-series, Utterance pro-sumti: the di'u-series, The North Wind and the Sun
-
- contrasted with "la'edi'u": Utterance pro-sumti: the di'u-series
- contrasted with "ta": Utterance pro-sumti: the di'u-series
- di'u-series: Utterance pro-sumti: the di'u-series
- dinju: fu'ivla
- dirba: The North Wind and the Sun
- dirce: The North Wind and the Sun
- dizlo: The North Wind and the Sun
- djedi: lujvo with more than two parts., lujvo with more than two parts., The North Wind and the Sun
- djica: Eliding SE rafsi from tertau, Topic-comment sentences: ZOhU, Topic-comment sentences: ZOhU, The North Wind and the Sun
- djine: Proposed lerfu words for some accent marks and multiple letters
- djuno: Predication/sentence abstraction, Predication/sentence abstraction, Indirect questions, The North Wind and the Sun
- do: Vocatives and commands, Vocatives and commands, Vocatives and commands, Questions, Linked sumti: be - bei - be'o, Quantified descriptions, sumti-based descriptions, Pro-sumti summary, Personal pro-sumti: the mi-series, Personal pro-sumti: the mi-series, Personal pro-sumti: the mi-series, Personal pro-sumti: the mi-series, Personal pro-sumti: the mi-series, Demonstrative pro-sumti: the ti-series, Assignable pro-sumti and pro-bridi: the ko'a-series and the broda-series, Anaphoric pro-sumti and pro-bridi: the ri-series and the go'i-series, lujvo based on pro-sumti, lujvo based on pro-sumti, Tagging places: FA, Implicit-abstraction lujvo, Propositional attitude indicators, Vocative scales, Compound bridi, Parenthesis and metalinguistic commentary: TO, TOI, SEI, The North Wind and the Sun
- do'a: Discursives
- do'anai: Discursives, The North Wind and the Sun
- do'e: Indefinite pro-sumti and pro-bridi: the zo'e-series and the co'e-series, Modal tags: BAI, Modal sentence connection: the causals, CV'V cmavo of selma'o BAI with irregular forms, Complete table of BAI cmavo with rough English equivalents
-
- compared with English "of": Modal tags: BAI
- do'i: Pro-sumti summary, Utterance pro-sumti: the di'u-series, Indefinite pro-sumti and pro-bridi: the zo'e-series and the co'e-series
-
- compared with zo'e-series as indefinite pro-sumti: Indefinite pro-sumti and pro-bridi: the zo'e-series and the co'e-series
- do'o: Pro-sumti summary, Pro-sumti summary, Personal pro-sumti: the mi-series, Personal pro-sumti: the mi-series
- do'u: The syntax of vocative phrases, Vocative scales
- doi: Vocatives and commands, Vocatives and commands, The syntax of vocative phrases, The syntax of vocative phrases, The syntax of vocative phrases, sumti and bridi questions: ma and mo, KOhA cmavo by series, Vocative scales, Vocative scales, Vocative scales, Vocative scales, Questions and answers, The North Wind and the Sun
- DOI selma'o
-
- with relative clauses: Relative clauses in vocative phrases
- donma'o: lujvo based on pro-sumti
- donri: The North Wind and the Sun
- donta'a: lujvo based on pro-sumti
- dotco: Cultural and other non-algorithmic gismu
- drani: The North Wind and the Sun
- drata: The North Wind and the Sun
- drudi: The North Wind and the Sun
- du: Other kinds of simple selbri, selbri based on sumti: me, The identity predicate: du, The identity predicate: du, The identity predicate: du, The identity predicate: du, The identity predicate: du, The identity predicate: du, lujvo based on pro-sumti, Space interval modifiers: FEhE, Simple infix expressions and equations, Simple infix expressions and equations, Simple infix expressions and equations, Other useful selbri for mekso bridi, Other useful selbri for mekso bridi, Other useful selbri for mekso bridi, Other useful selbri for mekso bridi, Other useful selbri for mekso bridi, Other useful selbri for mekso bridi, Other useful selbri for mekso bridi, mekso selma'o summary, The North Wind and the Sun
-
- compared with "me" in effect: selbri based on sumti: me
- contrasted with "dunli": The identity predicate: du
- contrasted with "mintu": The identity predicate: du
- derivation of: The identity predicate: du
- grammar of: Simple infix expressions and equations
- meaning of: The identity predicate: du
- rationale for selection of selma'o for: The identity predicate: du
- with complex mekso on both sides: Simple infix expressions and equations
- du'a: List of spatial directions and direction-like relations
- du'e: Attitudinal modifiers, Indefinite numbers, Indefinite numbers, Special mekso selbri, The North Wind and the Sun
- du'i: Modal sentence connection: the causals, Modal relative phrases; Comparison
- du'o: Modal sentence connection: the causals
- du'u: Predication/sentence abstraction, Predication/sentence abstraction, Predication/sentence abstraction, Indirect questions, The North Wind and the Sun
-
- se du'u: Predication/sentence abstraction
- dubjavmau: Other useful selbri for mekso bridi
- dubjavme'a: Other useful selbri for mekso bridi
- dunda: Tagging places: FA, Tagging places: FA, Compound bridi, Multiple compound bridi
- dunli: The identity predicate: du, The identity predicate: du, Other useful selbri for mekso bridi, Other useful selbri for mekso bridi, Other useful selbri for mekso bridi, Other useful selbri for mekso bridi, Other useful selbri for mekso bridi
-
- contrasted with "du": The identity predicate: du
- dy.: A to Z in Lojban, plus one, Proposed lerfu words for the Greek alphabet, Proposed lerfu words for the Cyrillic alphabet, Proposed lerfu words for the Hebrew alphabet
- dzipo: Cultural and other non-algorithmic gismu
- dzukla: Eliding KE and KEhE rafsi from lujvo, Eliding KE and KEhE rafsi from lujvo, Termset logical connection
F
- fa: Tagging places: FA, Tagging places: FA, Tagging places: FA, Tagging places: FA, The North Wind and the Sun
- FA selma'o
-
- after 5th place: Subscripts: XI
- as a reminder of place in place structure: Tagging places: FA
- avoidance of complex usage of: Tagging places: FA
- compared with "zo'e" for omitting places: Tagging places: FA
- effect on place structure: Tagging places: FA
- effect on place structure order: Tagging places: FA
- effect on subsequent non-tagged places: Tagging places: FA
- for accessing a selbri place explicitly by relative number: Tagging places: FA
- for putting more than one sumti in a single place: Tagging places: FA
- in selbri; compared with converted selbri in meaning: Conversion: SE
- in selbri; contrasted converted selbri with in structure: Conversion: SE
- introduction: Tagging places: FA
- syntax of: Tagging places: FA
- fa'a: List of spatial directions and direction-like relations, List of spatial directions and direction-like relations, List of spatial directions and direction-like relations, List of spatial directions and direction-like relations, List of spatial directions and direction-like relations, The North Wind and the Sun
-
- special note on direction orientation: List of spatial directions and direction-like relations
- fa'e: Modal sentence connection: the causals
- fa'o: Vocative scales, The universal bu, No more to say: FAhO, List of cmavo interactions, List of cmavo interactions, List of cmavo interactions
-
- contrasted with "fe'o": Vocative scales
- interaction with "bu": The universal bu
- fa'u: Non-logical connectives, Non-logical connectives, Non-logical connectives, Non-logical connectives, Non-logical connectives, Non-logical connectives, Questions and answers, The North Wind and the Sun
-
- compared to termsets: Non-logical connectives
- contrasted with ".e": Non-logical connectives
- facki: The North Wind and the Sun
- fadni: Masses and sets, Masses and sets, Masses and sets, The North Wind and the Sun
- fagri: Why have lujvo?, The North Wind and the Sun
- fagyfesti: Why have lujvo?, Why have lujvo?
- FAhA selma'o
-
- and direction: Spatial tenses: FAhA and VA
- contradictory negation of: Tense negation
- negation with NAhE: Tense negation
- use in specifying space/time mapping direction: Space interval modifiers: FEhE
- fai: Tagging places: FA, Modal conversion: JAI, Modal conversion: JAI, Modal conversion: JAI, Conversion of sumtcita: JAI, Conversion of sumtcita: JAI, Abstract lujvo, Abstract lujvo, Abstract lujvo, The North Wind and the Sun
-
- as allowing access to original first place in modal conversion: Modal conversion: JAI
- effect on numbering of place structure places: Modal conversion: JAI
- fanmo: The North Wind and the Sun
- fanza: The North Wind and the Sun
- farlu: The North Wind and the Sun
- fasnu: Modal sentence connection: the causals, Complete table of BAI cmavo with rough English equivalents, The North Wind and the Sun
- fau: Modal sentence connection: the causals, Complete table of BAI cmavo with rough English equivalents, The North Wind and the Sun
- fe: Linked sumti: be - bei - be'o, Linked sumti: be - bei - be'o, Tagging places: FA, Tagging places: FA, Tagging places: FA, The North Wind and the Sun
- fe'a: Logical and non-logical connectives within mekso
- fe'e: Space interval modifiers: FEhE, Space interval modifiers: FEhE, Space interval modifiers: FEhE, Space interval modifiers: FEhE, Tenses as sumtcita
-
- effect of TAhE/ROI with ZAhO on: Space interval modifiers: FEhE
- fe'o: Vocative scales, Vocative scales
-
- contrasted with "fa'o": Vocative scales
- fe'u: Modal places: FIhO, FEhU, Modal places: FIhO, FEhU, Modal selbri, The North Wind and the Sun
- femti: Cultural and other non-algorithmic gismu
- ferti: The North Wind and the Sun
- festi: Why have lujvo?, Why have lujvo?
- fi: Linked sumti: be - bei - be'o, Linked sumti: be - bei - be'o, Tagging places: FA, Tagging places: FA, Tagging places: FA, Tagging places: FA, Compound bridi, The North Wind and the Sun
- fi'a: Tagging places: FA, Tagging places: FA, Tagging places: FA, Modal conversion: JAI, Questions and answers
-
- effect on subsequent untagged sumti: Tagging places: FA
- fi'e: Modal sentence connection: the causals, Modal relative phrases; Comparison
- fi'i: Vocative scales, Vocative scales, Vocative scales
- fi'o: Modal places: FIhO, FEhU, Modal places: FIhO, FEhU, Modal selbri, Modal negation, Sticky modals, The North Wind and the Sun
-
- "fi'o"-constructs ; short forms as BAI cmavo: Modal tags: BAI
- and modal conversion: Modal conversion: JAI
- as modal tag: Modal places: FIhO, FEhU
- effect on following selbri: Modal places: FIhO, FEhU
- in tag; relation of modal sumti following to selbri: Modal places: FIhO, FEhU
- meaning with selbri: Modal places: FIhO, FEhU
- mixed modal connection with: Mixed modal connection
- negation of modals by negating selbri: Modal negation
- proscribed for sticky modals: Sticky modals
- restriction on use: Other modal connections
- usage of modals in relative phrases: Modal relative phrases; Comparison
- use in adding places to place structure: Modal places: FIhO, FEhU
- fi'o modal followed by selbri
-
- effect on eliding "fe'u" in "fi'o"-modal followed by selbri: Modal selbri
- fi'u: Signs and numerical punctuation, Miscellany
- filso: Cultural and other non-algorithmic gismu
- finpe: The North Wind and the Sun
- finti: Modal relative phrases; Comparison, The North Wind and the Sun
- firgai: Some types of asymmetrical tanru
- flalu: Eliding SE rafsi from seltau
- flaume: The North Wind and the Sun
- flecu: The North Wind and the Sun
- fo: cmavo, Linked sumti: be - bei - be'o, Tagging places: FA, Tagging places: FA, Special mekso selbri, The North Wind and the Sun
- fo'a: Pro-sumti summary, lujvo based on pro-sumti, KOhA cmavo by series
- fo'e: Pro-sumti summary, KOhA cmavo by series
- fo'i: Pro-sumti summary, KOhA cmavo by series
- fo'o: Pro-sumti summary
- fo'u: Pro-sumti summary
- foi: Accent marks and compound lerfu words, Accent marks and compound lerfu words, Accent marks and compound lerfu words, What about Chinese characters?, List of all auxiliary lerfu-word cmavo
- foldi: The North Wind and the Sun
- fraso: Cultural and other non-algorithmic gismu
- friko: Cultural and other non-algorithmic gismu
- frinu: Miscellany, Miscellany
- fu: Linked sumti: be - bei - be'o, Tagging places: FA, Tagging places: FA, Tagging places: FA
- fu'a: Reverse Polish notation
- fu'e: Attitude scope markers: FUhE/FUhO, Attitude scope markers: FUhE/FUhO, List of cmavo interactions, The North Wind and the Sun
- fu'i: Attitudinal modifiers
- fu'ivla: Lojban grammatical terms
- fu'o: Attitude scope markers: FUhE/FUhO, Attitude scope markers: FUhE/FUhO, List of cmavo interactions, The North Wind and the Sun
- fy.: A to Z in Lojban, plus one, Mathematical uses of lerfu strings, Proposed lerfu words for the Cyrillic alphabet, Forethought operators (Polish notation, functions), Miscellany, Miscellany, Erasure: SI, SA, SU
G
- ga: Forethought bridi connection, Forethought bridi connection, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Logical connectives and DeMorgan's law, Logical connectives and DeMorgan's law, Logical connectives and DeMorgan's law, The North Wind and the Sun
- GA selma'o
-
- conversion and negation: Forethought bridi connection
- in mekso: Logical and non-logical connectives within mekso
- in sumti connection: sumti connection
- usage in mekso: Logical and non-logical connectives within mekso
- ga'a: Modal sentence connection: the causals
- ga'e: Upper and lower cases, Upper and lower cases
- ga'i: Attitudinal modifiers, Attitudinal modifiers, Attitudinal modifiers, Attitudinal modifiers, Attitudinal modifiers, Attitudinal modifiers, Attitudinal modifiers, Attitudinal modifiers
- ga'icu'i: Attitudinal modifiers, Attitudinal modifiers
- ga'inai: Attitudinal modifiers, Attitudinal modifiers
- ga'o: Interval connectives and forethought non-logical connection, Interval connectives and forethought non-logical connection, Interval connectives and forethought non-logical connection, Logical and non-logical connectives within mekso, Logical and non-logical connectives within mekso
- ga'u: List of spatial directions and direction-like relations, The North Wind and the Sun
- gadri: The five kinds of simple sumti
- GAhO selma'o
-
- between tenses: Logical and non-logical connections between tenses
- grammar of: Interval connectives and forethought non-logical connection
- position in forethought intervals: Interval connectives and forethought non-logical connection
- usage with JOI: Interval connectives and forethought non-logical connection
- usage with JOI in forethought connectives: Interval connectives and forethought non-logical connection
- galfi: Implicit-abstraction lujvo
- galtu: Proposed lerfu words for some accent marks and multiple letters, Proposed lerfu words for some accent marks and multiple letters, Proposed lerfu words for some accent marks and multiple letters
- ganai: Forethought bridi connection, Forethought bridi connection, The North Wind and the Sun
- ganlo: Interval connectives and forethought non-logical connection, The North Wind and the Sun
- ganse: The North Wind and the Sun
- gapru: Proposed lerfu words for some accent marks and multiple letters, Proposed lerfu words for some accent marks and multiple letters, The North Wind and the Sun
- gaskre: The North Wind and the Sun
- gasnu: Implicit-abstraction lujvo, Implicit-abstraction lujvo, Implicit-abstraction lujvo, Implicit-abstraction lujvo, Implicit-abstraction lujvo, Implicit-abstraction lujvo, Implicit-abstraction lujvo, Implicit-abstraction lujvo, Notes on gismu place structures, The North Wind and the Sun
- gau: Modal sentence connection: the causals, Modal sentence connection: the causals, The North Wind and the Sun
- ge: lujvo-making examples, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Logical connectives and DeMorgan's law, Logical connectives and DeMorgan's law, Logical connectives and DeMorgan's law, The North Wind and the Sun
- ge'a: Infix operators revisited, Infix operators revisited, Vectors and matrices, Reverse Polish notation, Reverse Polish notation
-
- for infix operations with too many operands: Infix operators revisited
- ge'e: Compound indicators, Compound indicators, Compound indicators, Attitude questions; empathy; attitude contours, Miscellaneous indicators, Miscellaneous indicators
- ge'i: Truth questions and connective questions, Questions and answers
- ge'o: Alien alphabets
- ge'u: Assignable pro-sumti and pro-bridi: the ko'a-series and the broda-series, Relative phrases, Relative phrases
-
- effect of following logical connective on elidability: Relative phrases
- elidability of from relative phrases: Relative phrases
- gei: Infix operators revisited, Infix operators revisited, Infix operators revisited, Infix operators revisited, Infix operators revisited, Reverse Polish notation
-
- as a binary operator: Infix operators revisited
- as a ternary operator: Infix operators revisited
- rationale for order of places: Infix operators revisited
- gekmau: Eliding KE and KEhE rafsi from lujvo
- gento: Cultural and other non-algorithmic gismu
- genxu: The North Wind and the Sun
- gerku: Some words used to indicate selbri relations, lujvo-making examples, lujvo-making examples, Assignable pro-sumti and pro-bridi: the ko'a-series and the broda-series, Relative clauses and descriptors, The meaning of tanru: a necessary detour, The meaning of tanru: a necessary detour, The meaning of tanru: a necessary detour, The meaning of tanru: a necessary detour, The meaning of tanru: a necessary detour, The meaning of lujvo, The meaning of lujvo, The meaning of lujvo, The meaning of lujvo, Symmetrical and asymmetrical lujvo, Dependent places, Anomalous lujvo, Anomalous lujvo, Anomalous lujvo, Logical connection within tanru
- gerzda: lujvo-making examples, lujvo-making examples, lujvo-making examples, The meaning of lujvo, The meaning of lujvo, The meaning of lujvo, Symmetrical and asymmetrical lujvo, Symmetrical and asymmetrical lujvo, Symmetrical and asymmetrical lujvo, Dependent places, Dependent places, Dependent places, Ordering lujvo places., Eliding SE rafsi from tertau, Eliding SE rafsi from tertau
- gi: Logical connection within tanru, Logical connection within tanru, Logical connection within tanru, Logical connection within tanru, Logical connection within tanru, Logical connection within tanru, Logical connection within tanru, Logical connection within tanru, Logical connection within tanru, Scalar negation of selbri, Other modal connections, Other modal connections, Tense relations between sentences, Tense relations between sentences, Forethought bridi connection, Forethought bridi connection, Forethought bridi connection, Forethought bridi connection, Forethought bridi connection, Forethought bridi connection, Forethought bridi connection, Forethought bridi connection, Truth questions and connective questions, Interval connectives and forethought non-logical connection, Interval connectives and forethought non-logical connection, Interval connectives and forethought non-logical connection, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Rules for making logical and non-logical connectives, Rules for making logical and non-logical connectives, Logical connectives and DeMorgan's law, Logical connectives and DeMorgan's law, Logical connectives and DeMorgan's law, Logical connectives and DeMorgan's law, Logical connectives and DeMorgan's law, The North Wind and the Sun
- GI selma'o
-
- as opposed to GA: The six types of logical connectives
- gi'a: Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, The North Wind and the Sun
- gi'e: Ordering lujvo places., The six types of logical connectives, Compound bridi, Truth questions and connective questions, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, The North Wind and the Sun
- gi'i: Questions and answers, The North Wind and the Sun
- gi'o: Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives
- gi'u: Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives
- gidva: The North Wind and the Sun
- gigdo: Cultural and other non-algorithmic gismu
- GIhA selma'o
-
- conversion and negation: Compound bridi
- introduction: Compound bridi
- usage in tensed connectives: Tenses, modals, and logical connection
- usage in tensed connectives with KE: Tenses, modals, and logical connection
- girzu: lujvo-making examples, Other useful selbri for mekso bridi
- gismu: The concept of the bridi, Lojban grammatical terms, gismu, gismu, The gismu creation algorithm
- glare: The North Wind and the Sun
- gleki: Eliding KE and KEhE rafsi from lujvo, The North Wind and the Sun
- glico: Cultural and other non-algorithmic gismu, More on quotations: ZO, ZOI
- go: Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives
- go'a: Anaphoric pro-sumti and pro-bridi: the ri-series and the go'i-series, Anaphoric pro-sumti and pro-bridi: the ri-series and the go'i-series
- go'a-series
-
- referring to individual sumti of a bridi: Inversion of tanru: co
- go'e: Anaphoric pro-sumti and pro-bridi: the ri-series and the go'i-series, Anaphoric pro-sumti and pro-bridi: the ri-series and the go'i-series
- go'i: Examples of brivla, Questions, Questions, Other kinds of simple selbri, Other kinds of simple selbri, Anaphoric pro-sumti and pro-bridi: the ri-series and the go'i-series, Anaphoric pro-sumti and pro-bridi: the ri-series and the go'i-series, Anaphoric pro-sumti and pro-bridi: the ri-series and the go'i-series, Anaphoric pro-sumti and pro-bridi: the ri-series and the go'i-series, Anaphoric pro-sumti and pro-bridi: the ri-series and the go'i-series, Anaphoric pro-sumti and pro-bridi: the ri-series and the go'i-series, Discursives, Truth questions and connective questions, Truth questions and connective questions, Truth questions and connective questions, Truth questions and connective questions, Affirmations, The North Wind and the Sun
-
- as affirmative answer to yes/no question: Anaphoric pro-sumti and pro-bridi: the ri-series and the go'i-series
- compared with "mo" in overriding of arguments: sumti and bridi questions: ma and mo
- contrasted with "mi'u": Discursives
- with xu; quick-tour version: Questions
- go'i ra'o
-
- contrasted with "go'i": Anaphoric pro-sumti and pro-bridi: the ri-series and the go'i-series
- go'i-series
-
- assigning pro-bridi for permanent reference: Anaphoric pro-sumti and pro-bridi: the ri-series and the go'i-series
- effect of sub-clauses on pro-bridi: Anaphoric pro-sumti and pro-bridi: the ri-series and the go'i-series
- effect of sumti of referent bridi on pro-bridi: Anaphoric pro-sumti and pro-bridi: the ri-series and the go'i-series
- pro-bridi as main-bridi anaphora only: Anaphoric pro-sumti and pro-bridi: the ri-series and the go'i-series
- pro-bridi compared with ri-series pro-sumti in rules of reference: Anaphoric pro-sumti and pro-bridi: the ri-series and the go'i-series
- pro-bridi in narrative about quotation: Anaphoric pro-sumti and pro-bridi: the ri-series and the go'i-series
- pro-bridi in quotation series: Anaphoric pro-sumti and pro-bridi: the ri-series and the go'i-series
- pro-bridi in quotations: Anaphoric pro-sumti and pro-bridi: the ri-series and the go'i-series
- referent of pro-bridi: Anaphoric pro-sumti and pro-bridi: the ri-series and the go'i-series
- go'o: Anaphoric pro-sumti and pro-bridi: the ri-series and the go'i-series
- go'u: Anaphoric pro-sumti and pro-bridi: the ri-series and the go'i-series, Anaphoric pro-sumti and pro-bridi: the ri-series and the go'i-series
- gocti: Cultural and other non-algorithmic gismu
- GOhA selma'o
-
- as component in tanru: Other kinds of simple selbri
- as selbri: Other kinds of simple selbri
- introduction: What are pro-sumti and pro-bridi? What are they for?
- goi: Pro-sumti summary, Assignable pro-sumti and pro-bridi: the ko'a-series and the broda-series, Assignable pro-sumti and pro-bridi: the ko'a-series and the broda-series, Assignable pro-sumti and pro-bridi: the ko'a-series and the broda-series, Assignable pro-sumti and pro-bridi: the ko'a-series and the broda-series, Assignable pro-sumti and pro-bridi: the ko'a-series and the broda-series, Assignable pro-sumti and pro-bridi: the ko'a-series and the broda-series, Assignable pro-sumti and pro-bridi: the ko'a-series and the broda-series, Anaphoric pro-sumti and pro-bridi: the ri-series and the go'i-series, Pro-sumti and pro-bridi cancelling, lerfu words as pro-sumti, Subscripts: XI, The North Wind and the Sun
-
- assignment of ko'a-series pro-sumti; use in speech contrasted with writing: Assignable pro-sumti and pro-bridi: the ko'a-series and the broda-series
- for ko'a-series assignment; compared with "cei" for broda-series assignment: Assignable pro-sumti and pro-bridi: the ko'a-series and the broda-series
- rationale for non-inclusion in relative clause chapter: Relative phrases
- use in assigning lerfu as pro-sumti: Assignable pro-sumti and pro-bridi: the ko'a-series and the broda-series
- use in assigning name: Assignable pro-sumti and pro-bridi: the ko'a-series and the broda-series
- GOI selma'o
-
- for comparisons: Modal relative phrases; Comparison
- gotro: Cultural and other non-algorithmic gismu
- grana: The North Wind and the Sun
- grutrxananase: The North Wind and the Sun
- gu: cmavo, The six types of logical connectives, Forethought bridi connection, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives
- gu'a: Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives
- gu'e: Logical connection within tanru, Logical connection within tanru, Logical connection within tanru, Logical connection within tanru, Logical connection within tanru, Logical connection within tanru, Scalar negation of selbri, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives
- gu'i: Truth questions and connective questions, Questions and answers
- gu'o: Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives
- gu'u: Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives
- gugde: The North Wind and the Sun
- GUhA selma'o
-
- compared with JA: Logical connection within tanru
- conversion and negation: Logical connection within tanru
- usage in mekso: Logical and non-logical connectives within mekso
- gundi: The North Wind and the Sun
- gunse: The North Wind and the Sun
- gusni: The North Wind and the Sun
- gy.: Assignable pro-sumti and pro-bridi: the ko'a-series and the broda-series, A to Z in Lojban, plus one, Proposed lerfu words for the Greek alphabet, Proposed lerfu words for the Cyrillic alphabet, Proposed lerfu words for the Hebrew alphabet, More on quotations: ZO, ZOI, More on quotations: ZO, ZOI, Erasure: SI, SA, SU, Erasure: SI, SA, SU
I
- I selma'o
-
- usage in tensed connectives: Tenses, modals, and logical connection
- usage in tensed connectives with TUhE: Tenses, modals, and logical connection
- with JA: Logical connection of bridi
J
- ja: Logical connection within tanru, Logical connection within tanru, Logical connection within tanru, Logical connection within tanru, Logical connection within tanru, Logical connection within tanru, Logical connection within tanru, Some types of symmetrical tanru, Logical connection of bridi, Forethought bridi connection, Grouping of afterthought connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, bridi negation and logical connectives, Other useful selbri for mekso bridi, Other useful selbri for mekso bridi, The North Wind and the Sun
- JA selma'o
-
- as a part of Lojban connective system: The six types of logical connectives
- as opposed to forethought connectives: Forethought bridi connection
- between tenses: Logical and non-logical connections between tenses
- compared with GUhA: Logical connection within tanru
- connecting abstractions: Abstractor connection and connection within abstractions
- conversion and negation: Logical connection within tanru
- introduction: The six types of logical connectives
- opposed to JOI: Non-logical connectives
- places in grammar where used: The six types of logical connectives
- usage in mekso: Logical and non-logical connectives within mekso
- usage in tensed connectives: Tenses, modals, and logical connection, Tenses, modals, and logical connection
- usage in tensed connectives with TUhE: Tenses, modals, and logical connection
- with I: Logical connection of bridi
- with negation: Logical connection of bridi
- ja'a: Affirmations, Affirmations, Questions and answers, Subscripts: XI, Subscripts: XI
- ja'e: Modal sentence connection: the causals, Modal sentence connection: the causals, The North Wind and the Sun
- ja'i: Modal sentence connection: the causals
- ja'o: Evidentials, Evidentials, Evidentials, Evidentials, The North Wind and the Sun
- jai: Conversion of simple selbri, Modal conversion: JAI, Modal conversion: JAI, Modal conversion: JAI, Conversion of sumtcita: JAI, Lojban sumti raising, Lojban sumti raising, Lojban sumti raising, Lojban sumti raising, Abstract lujvo, Abstract lujvo, More on quotations: ZO, ZOI, The North Wind and the Sun
-
- for modal conversion: Conversion of simple selbri
- meaning withut modal: Modal conversion: JAI
- used with tense as equivalent of SE in grammar: Conversion of sumtcita: JAI
- jalge: The North Wind and the Sun
- jamfu: The North Wind and the Sun
- jamna: The North Wind and the Sun
- janco: The North Wind and the Sun
- jarco: The North Wind and the Sun
- javni: The North Wind and the Sun
- jbena: Notes on gismu place structures, Notes on gismu place structures
- jbini: The North Wind and the Sun
- jdari: The North Wind and the Sun
- jdaselsku: Ordering lujvo places., Anomalous lujvo, Anomalous lujvo, Anomalous lujvo, Anomalous lujvo, Anomalous lujvo
- jdice: The North Wind and the Sun
- jdika: Comparatives and superlatives, Comparatives and superlatives
- jduli: The North Wind and the Sun
- je: Logical connection within tanru, Logical connection within tanru, Logical connection within tanru, Logical connection within tanru, Logical connection within tanru, Logical connection within tanru, Logical connection within tanru, Logical connection within tanru, Logical connection within tanru, Logical connection within tanru, Some types of symmetrical tanru, “Pretty little girls' school” : forty ways to say it, “Pretty little girls' school” : forty ways to say it, “Pretty little girls' school” : forty ways to say it, “Pretty little girls' school” : forty ways to say it, “Pretty little girls' school” : forty ways to say it, Mixed modal connection, Logical and non-logical connection of modals, Tense questions: cu'e, Why have lujvo?, Grouping of afterthought connectives, Truth questions and connective questions, Tenses, modals, and logical connection, Tenses, modals, and logical connection, Tenses, modals, and logical connection, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, bridi negation and logical connectives, The North Wind and the Sun
- je'a: Affirmations, Affirmations, The North Wind and the Sun
- je'e: Vocative scales, Vocative scales, Vocative scales, Vocative scales, Vocative scales, The North Wind and the Sun
-
- contrasted with "vi'o": Vocative scales
- je'enai: Vocative scales, Vocative scales, Negation of minor grammatical constructs
- je'i: Questions and answers
- je'o: Alien alphabets
- je'u: Discursives, Discursives, Discursives, The North Wind and the Sun
- je'unai: Discursives, Discursives, Discursives, Discursives
- jegvo: Cultural and other non-algorithmic gismu
- jei: Truth-value abstraction: jei, Truth-value abstraction: jei, Truth-value abstraction: jei, Truth-value abstraction: jei, Truth-value abstraction: jei, Truth-value abstraction: jei, Truth-value abstraction: jei, Predication/sentence abstraction, Subscripts: XI, The North Wind and the Sun
-
- place structure: Truth-value abstraction: jei
- jelca: Miscellaneous indicators
- jenai: Tense questions: cu'e, The North Wind and the Sun
- jersi: The North Wind and the Sun
- jerxo: Cultural and other non-algorithmic gismu
- jetce: The North Wind and the Sun
- jetnu: The North Wind and the Sun
- jgari: The North Wind and the Sun
- ji: Questions and answers
- ji'a: Discursives, The North Wind and the Sun
- ji'asai: The North Wind and the Sun
- ji'e: Modal sentence connection: the causals
- ji'i: Approximation and inexact numbers, Approximation and inexact numbers, Approximation and inexact numbers, Approximation and inexact numbers, The North Wind and the Sun
-
- effect of placement: Approximation and inexact numbers
- with elided number: Approximation and inexact numbers
- ji'o: Modal sentence connection: the causals
- ji'u: Modal sentence connection: the causals, Metalinguistic negation forms
- jibni: Other useful selbri for mekso bridi, The North Wind and the Sun
- jinto: The North Wind and the Sun
- jinvi: Abstractor connection and connection within abstractions, The North Wind and the Sun
- jitro: Anomalous lujvo
- jo: Logical connection within tanru, “Pretty little girls' school” : forty ways to say it, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives
- jo'a: Miscellaneous indicators, Miscellaneous indicators, Miscellaneous indicators, Metalinguistic negation forms, Metalinguistic negation forms
- jo'e: Non-logical connectives, More about non-logical connectives
- jo'i: Vectors and matrices, Using Lojban resources within mekso
-
- precedence of: Vectors and matrices
- jo'o: Alien alphabets
- jo'u: Non-logical connectives, Non-logical connectives, Non-logical connectives, More about non-logical connectives, The North Wind and the Sun
-
- contrasted with "ce": Non-logical connectives
- contrasted with "ce'o": Non-logical connectives
- contrasted with "joi": Non-logical connectives
- result of connection with: Non-logical connectives
- joi: Logical connection within tanru, Non-logical connectives, Non-logical connectives, Non-logical connectives, Non-logical connectives, Non-logical connectives, Non-logical connectives, More about non-logical connectives, More about non-logical connectives, More about non-logical connectives, The universal bu, The North Wind and the Sun
-
- grammar of "joi" contrasted with eks: Non-logical connectives
- grammar of "joi" contrasted with jeks: Non-logical connectives
- JOI selma'o
-
- as opposed to JA: The six types of logical connectives
- between tenses: Logical and non-logical connections between tenses
- compared to logical connectives: More about non-logical connectives
- conversion and negation: Interval connectives and forethought non-logical connection
- conversion and negation in forethought connectives: Interval connectives and forethought non-logical connection
- in forethought connectives: Interval connectives and forethought non-logical connection
- in mekso: Logical and non-logical connectives within mekso
- usage in mekso: Logical and non-logical connectives within mekso
- usage in tensed connectives: Tenses, modals, and logical connection, Tenses, modals, and logical connection
- usage in tensed connectives with TUhE: Tenses, modals, and logical connection
- usage with I: More about non-logical connectives
- jordo: Cultural and other non-algorithmic gismu
- ju: Logical connection within tanru, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives
- ju'a: Evidentials, Evidentials, The North Wind and the Sun
- ju'i: The North Wind and the Sun
- ju'o: Discursives, The North Wind and the Sun
- ju'u: Non-decimal and compound bases, Non-decimal and compound bases, Non-decimal and compound bases
-
- grammar of: Non-decimal and compound bases
- jubme: The North Wind and the Sun
- jukpa: The North Wind and the Sun
- jundi: Symmetrical and asymmetrical lujvo, Symmetrical and asymmetrical lujvo
- jungo: Cultural and other non-algorithmic gismu
- junla: The North Wind and the Sun
- jy.: A to Z in Lojban, plus one, Proposed lerfu words for the Cyrillic alphabet
K
- ka: cmevla, Abstraction focus pro-sumti: ce'u, Property abstractions, Property abstractions, Property abstractions, Abstract lujvo, The North Wind and the Sun
- ka'a: Modal tags: BAI, Modal tags: BAI, Modal sentence connection: the causals
- ka'e: Actuality, potentiality, capability: CAhA, The North Wind and the Sun
- ka'i: Modal sentence connection: the causals
- ka'o: Special numbers
-
- as special number compared with as numerical punctuation: Special numbers
- ka'u: Evidentials, Evidentials, The North Wind and the Sun
- kabri: The North Wind and the Sun
- kadno: Cultural and other non-algorithmic gismu
- kai: Modal sentence connection: the causals, Metalinguistic negation forms
- kajna: The North Wind and the Sun
- kakne: The North Wind and the Sun
- kalri: Interval connectives and forethought non-logical connection, The North Wind and the Sun
- kalselvi'i: Some types of asymmetrical tanru
- kambla: Abstract lujvo
- kanji: What about Chinese characters?
- kanla: Modal places: FIhO, FEhU, Modal places: FIhO, FEhU, Modal places: FIhO, FEhU, Modal places: FIhO, FEhU, Modal places: FIhO, FEhU, Eliding SE rafsi from tertau, The North Wind and the Sun
- kanro: Some words used to indicate selbri relations
- kansa: The North Wind and the Sun
- karce: Symmetrical and asymmetrical lujvo
- karcykla: Symmetrical and asymmetrical lujvo, Symmetrical and asymmetrical lujvo
- kau: Indirect questions, Indirect questions, Indirect questions, Indirect questions, Indirect questions, The North Wind and the Sun
-
- "ma kau" contrasted with "la djan. kau": Indirect questions
- kavbu: The North Wind and the Sun
- ke: lujvo-making examples, lujvo-making examples, Complex tanru with ke and ke'e, Complex tanru with ke and ke'e, Complex tanru with ke and ke'e, Complex tanru with ke and ke'e, Complex tanru with ke and ke'e, Complex tanru with ke and ke'e, Logical connection within tanru, Logical connection within tanru, Logical connection within tanru, Inversion of tanru: co, Conversion of simple selbri, Scalar negation of selbri, Scalar negation of selbri, Scalar negation of selbri, Scalar negation of selbri, “Pretty little girls' school” : forty ways to say it, Conversion: SE, Mixed modal connection, Mixed modal connection, Tensed logical connectives, Why have lujvo?, Eliding KE and KEhE rafsi from lujvo, Eliding KE and KEhE rafsi from lujvo, Eliding KE and KEhE rafsi from lujvo, Eliding KE and KEhE rafsi from lujvo, Eliding KE and KEhE rafsi from lujvo, Grouping of afterthought connectives, Grouping of afterthought connectives, Grouping of afterthought connectives, Grouping of afterthought connectives, Grouping of afterthought connectives, Multiple compound bridi, Multiple compound bridi, Logical connection within tanru, Logical connection within tanru, More about non-logical connectives, Logical and non-logical connectives within mekso, Logical and non-logical connectives within mekso, Tenses, modals, and logical connection, Tenses, modals, and logical connection, Tenses, modals, and logical connection, Tenses, modals, and logical connection, Tenses, modals, and logical connection, selbri and tanru negation, selbri and tanru negation, selbri and tanru negation, selbri and tanru negation, selbri and tanru negation, Truth questions, Logical and non-logical connectives within mekso, Sentences: I, Attitude scope markers: FUhE/FUhO, The North Wind and the Sun
-
- contrasted with "bo" for tensed logical connection: Tenses, modals, and logical connection
- for conversion of tanru: Conversion of simple selbri
- for expanding scope of scalar negation: Scalar negation of selbri
- in sumti grouping where allowed: Grouping of afterthought connectives
- ke'a: Pro-sumti summary, Relativized pro-sumti: ke'a, Relativized pro-sumti: ke'a, Relativized pro-sumti: ke'a, Relativized pro-sumti: ke'a, Relativized pro-sumti: ke'a, Pro-sumti and pro-bridi cancelling, What are you pointing at?, What are you pointing at?, What are you pointing at?, What are you pointing at?, What are you pointing at?, What are you pointing at?, What are you pointing at?, Relative clauses within relative clauses, Relative clauses within relative clauses, Relative clauses within relative clauses, Relative clauses within relative clauses, The North Wind and the Sun
-
- ambiguity when omitted: Relativized pro-sumti: ke'a
- and abstract descriptions: Relativized pro-sumti: ke'a
- as referent for relativized sumti: What are you pointing at?
- contrasted with "ri" in relative clauses: Relativized pro-sumti: ke'a
- effect of omission of: What are you pointing at?
- for relativized sumti in relative clauses: Relativized pro-sumti: ke'a
- meaning in relative clause inside relative clause: Relative clauses within relative clauses
- non-initial place use in relative clause: What are you pointing at?
- subscripting for nested relative clauses: Relativized pro-sumti: ke'a
- with subscript; use for outer sumti reference: Relative clauses within relative clauses
- ke'e: Complex tanru with ke and ke'e, Complex tanru with ke and ke'e, Complex tanru with ke and ke'e, Complex tanru with ke and ke'e, Complex tanru with ke and ke'e, Complex tanru with ke and ke'e, Complex tanru with ke and ke'e, Complex tanru with ke and ke'e, Logical connection within tanru, Logical connection within tanru, Logical connection within tanru, Inversion of tanru: co, Inversion of tanru: co, Conversion of simple selbri, Scalar negation of selbri, Scalar negation of selbri, Scalar negation of selbri, Scalar negation of selbri, “Pretty little girls' school” : forty ways to say it, Conversion: SE, Mixed modal connection, Mixed modal connection, Tensed logical connectives, Why have lujvo?, Eliding KE and KEhE rafsi from lujvo, Eliding KE and KEhE rafsi from lujvo, Eliding KE and KEhE rafsi from lujvo, Grouping of afterthought connectives, Grouping of afterthought connectives, Multiple compound bridi, Multiple compound bridi, Logical connection within tanru, Logical connection within tanru, Logical and non-logical connectives within mekso, Logical and non-logical connectives within mekso, selbri and tanru negation, selbri and tanru negation, selbri and tanru negation, selbri and tanru negation, selbri and tanru negation, selbri and tanru negation, Truth questions, Logical and non-logical connectives within mekso, Sentences: I
- ke'i: Interval connectives and forethought non-logical connection, Interval connectives and forethought non-logical connection, Interval connectives and forethought non-logical connection, Logical and non-logical connectives within mekso, Logical and non-logical connectives within mekso
- ke'o: Vocative scales
-
- compared to "ki'a": Vocative scales
- ke'u: Discursives, Discursives, Discursives, Discursives
-
- contrasted with "va'i": Discursives
- ke'unai: Discursives, Discursives, Discursives
- kei: Other kinds of simple selbri, The syntax of abstraction, The syntax of abstraction, The syntax of abstraction, The syntax of abstraction, The syntax of abstraction, The syntax of abstraction, Minor abstraction types, Abstract lujvo, Abstract lujvo, The North Wind and the Sun
- KEI selma'o
-
- eliding: The syntax of abstraction
- kelci: The North Wind and the Sun
- kelvo: Cultural and other non-algorithmic gismu
- kerlo: The North Wind and the Sun
- ketco: Cultural and other non-algorithmic gismu
- kevna: The North Wind and the Sun
- ki: Sticky modals, Sticky modals, Sticky modals, Sticky and multiple tenses: KI, Sticky and multiple tenses: KI, Sticky and multiple tenses: KI, Sticky and multiple tenses: KI, Sticky and multiple tenses: KI, Sticky and multiple tenses: KI, Story time, Actuality, potentiality, capability: CAhA, Summary of tense selma'o , Summary of tense selma'o , The North Wind and the Sun
-
- with no tense: Sticky and multiple tenses: KI
- KI selma'o
-
- introduction: Sticky modals
- ki'a: cmavo, Miscellaneous indicators, Miscellaneous indicators, Vocative scales, Metalinguistic negation forms
-
- compared to "ke'o": Vocative scales
- ki'i: Modal sentence connection: the causals
- ki'o: Signs and numerical punctuation, Signs and numerical punctuation, Signs and numerical punctuation
- ki'u: Modal sentence connection: the causals, Modal sentence connection: the causals, Mixed modal connection, The North Wind and the Sun
- kilto: Cultural and other non-algorithmic gismu, The North Wind and the Sun
- kisto: Cultural and other non-algorithmic gismu
- klama: Some words used to indicate selbri relations, tanru, Conversion of simple selbri, Scalar negation of selbri, Scalar negation of selbri, Introductory, Introductory, Introductory, Standard bridi form: cu, Standard bridi form: cu, Standard bridi form: cu, Tagging places: FA, Tagging places: FA, Tagging places: FA, Conversion: SE, Conversion: SE, Conversion: SE, Modal tags: BAI, Modal tags: BAI, Event abstraction, The meaning of tanru: a necessary detour, Dependent places, Dependent places, Eliding KE and KEhE rafsi from lujvo, Abstract lujvo, Notes on gismu place structures, Termset logical connection, Termset logical connection, Termset logical connection, selbri and tanru negation, selbri and tanru negation, The problem of “any”, Subscripts: XI, Subscripts: XI, The North Wind and the Sun
-
- place structure of: Introductory
- place structure of "se klama": Conversion: SE
- klesi: lujvo-making examples
- ko: Vocatives and commands, Vocatives and commands, Vocatives and commands, Questions, The five kinds of simple sumti, Quantified sumti, Pro-sumti summary, Personal pro-sumti: the mi-series, Personal pro-sumti: the mi-series, Personal pro-sumti: the mi-series, Personal pro-sumti: the mi-series, Personal pro-sumti: the mi-series, Truth questions and connective questions, The North Wind and the Sun
-
- in later selbri place in imperative: Personal pro-sumti: the mi-series
- in sub-clause of main bridi: Personal pro-sumti: the mi-series
- use for commands: Personal pro-sumti: the mi-series
- use for imperatives: Personal pro-sumti: the mi-series
- ko'a: Pro-sumti summary, Assignable pro-sumti and pro-bridi: the ko'a-series and the broda-series, Assignable pro-sumti and pro-bridi: the ko'a-series and the broda-series, Assignable pro-sumti and pro-bridi: the ko'a-series and the broda-series, Assignable pro-sumti and pro-bridi: the ko'a-series and the broda-series, Anaphoric pro-sumti and pro-bridi: the ri-series and the go'i-series, Anaphoric pro-sumti and pro-bridi: the ri-series and the go'i-series, The identity predicate: du, The identity predicate: du, The identity predicate: du, Relative clauses within relative clauses, lerfu words as pro-sumti
- ko'a-series: Assignable pro-sumti and pro-bridi: the ko'a-series and the broda-series
-
- after tenth: Subscripts: XI
- for pro-sumti as compared with broda-series for pro-bridi: Assignable pro-sumti and pro-bridi: the ko'a-series and the broda-series
- more than three variables under one scope: Subscripts: XI
- pro-sumti contrasted with lerfu as pro-sumti in explicit assignment of: Assignable pro-sumti and pro-bridi: the ko'a-series and the broda-series
- ko'e: Pro-sumti summary, Relative clauses within relative clauses, lerfu words as pro-sumti
- ko'i: Pro-sumti summary
- ko'o: Pro-sumti summary
- ko'u: Pro-sumti summary
- koi: Modal sentence connection: the causals
- kojna: The North Wind and the Sun
- korbi: The North Wind and the Sun
- korcu: The North Wind and the Sun
- kosta: The North Wind and the Sun
- krasi: Modal sentence connection: the causals, Complete table of BAI cmavo with rough English equivalents
- krecau: selbri and tanru negation
- krefu: The North Wind and the Sun
- krici: Abstractor connection and connection within abstractions
- krinu: Modal sentence connection: the causals
- krixa: The North Wind and the Sun
- krorinsa: The North Wind and the Sun
- kruji: The North Wind and the Sun
- ku: Description sumti, Description sumti, Linked sumti: be - bei - be'o, Linked sumti: be - bei - be'o, Linked sumti: be - bei - be'o, selbri based on sumti: me, The three basic description types, The three basic description types, The three basic description types, Indefinite descriptions, Relative clauses and descriptors, Relative clauses and descriptors, Relative clauses and descriptors, Relative clauses and descriptors, Relative clauses and descriptors, Relative clauses and descriptors, Relative clauses and descriptors, Relative clauses and descriptors, Relative clauses and descriptors, Relative clauses and descriptors, Relative clauses and descriptors, Relative clauses and descriptors, Relative clauses and descriptors, Possessive sumti, Possessive sumti, Modal selbri, Modal selbri, Modal selbri, Introductory, Introductory, Spatial tenses: FAhA and VA, Tenses as sumtcita, Tenses as sumtcita, Non-logical connectives, Non-logical connectives, Questions and answers, The North Wind and the Sun
-
- as elidable terminator for descriptions: The three basic description types
- effect of following selbri on elidability of: The three basic description types
- effect of possessive sumti on elidability of: Possessive sumti
- effect on elidability of "be'o": Linked sumti: be - bei - be'o
- effect on of omitting descriptor: Indefinite descriptions
- quick-tour version: Description sumti
- uses of: The three basic description types
- with tense: Introductory
- KU selma'o
-
- quick-tour version: Description sumti
- ku'a: Non-logical connectives, More about non-logical connectives
- ku'e: Forethought operators (Polish notation, functions), Forethought operators (Polish notation, functions), Forethought operators (Polish notation, functions), Forethought operators (Polish notation, functions), Forethought operators (Polish notation, functions), Logical and non-logical connectives within mekso
- ku'i: Discursives, Truth questions and connective questions, The North Wind and the Sun
- ku'o: What are you pointing at?, What are you pointing at?, What are you pointing at?, What are you pointing at?, Relative clauses and descriptors, Relative clauses and descriptors, Relative clauses and descriptors, Possessive sumti, Possessive sumti, Restricted claims: da poi
-
- effect of "vau" on elidability: Possessive sumti
- elidability for relative clauses: What are you pointing at?
- ku'u: Modal sentence connection: the causals
- kuarka: fu'ivla
- kucli: The North Wind and the Sun
- kuldi'u: Dependent places
- kumfa: The North Wind and the Sun
- kunti: The North Wind and the Sun
- kurji: Some words used to indicate selbri relations
- ky.: Syllabication and stress, A to Z in Lojban, plus one, Proposed lerfu words for the Greek alphabet, Proposed lerfu words for the Cyrillic alphabet, Proposed lerfu words for the Hebrew alphabet
L
- la: Words that can act as sumti, selbri based on sumti: me, The five kinds of simple sumti, The three basic description types, The three basic description types, The three basic description types, Individuals and masses, Individuals and masses, Quantified descriptions, Quantified descriptions, Quantified descriptions, Lojban names, Lojban names, Lojban names, Lojban names, Relative clauses and descriptors, Vocative scales, Vocative scales, Acronyms, Contrastive emphasis: BAhE, Erasure: SI, SA, SU, The North Wind and the Sun
-
- compared with "le" in specificity: The three basic description types
- contrasted with "lai" in implications: Individuals and masses
- contrasted with "le" in implications: The three basic description types
- contrasted with "lo" in implications: The three basic description types
- contrasted with vocatives: Vocative scales
- implications of: The three basic description types
- use with descriptions contrasted with use before Lojbanized names: The three basic description types
- LA selma'o
-
- contrasted with LE in use of name-words: Lojban names
- introduction: Conversion: SE
- la'a: The North Wind and the Sun
- la'asai: The North Wind and the Sun
- la'e: sumti qualifiers, sumti qualifiers, Utterance pro-sumti: the di'u-series, Relative clauses and complex sumti: vu'o, Relative clauses and complex sumti: vu'o, References to lerfu, Miscellany, More on quotations: ZO, ZOI, The North Wind and the Sun
-
- as short for le selsinxa be : sumti qualifiers
- effect of on meaning: sumti qualifiers
- la'e lu
-
- compared with "me'o": References to lerfu
- la'edi'e: The North Wind and the Sun
- la'edi'u: The sumti di'u and la'e di'u, Utterance pro-sumti: the di'u-series, Utterance pro-sumti: the di'u-series, The North Wind and the Sun
-
- contrasted with "di'u": Utterance pro-sumti: the di'u-series
- la'i: Masses and sets, Quantified descriptions, Quantified descriptions, Lojban names
-
- as set counterpart of "lai": Masses and sets
- la'o: fu'ivla, cmevla, The universal bu, More on quotations: ZO, ZOI, More on quotations: ZO, ZOI, More on quotations: ZO, ZOI, More on quotations: ZO, ZOI, More on quotations: ZO, ZOI
-
- interaction with "bu": The universal bu
- la'u: Modal sentence connection: the causals, Explicit magnitudes, Metalinguistic negation forms
- la-series
-
- descriptors compared with le-series in implicit quantification: Quantified descriptions
- ladru: Some types of asymmetrical tanru, The North Wind and the Sun
- LAhE selma'o: sumti qualifiers
-
- effect of relative clause placement with: Relative clauses and complex sumti: vu'o
- lai: Individuals and masses, Individuals and masses, Individuals and masses, Individuals and masses, Masses and sets, Quantified descriptions, Quantified descriptions, Lojban names, Lojban names
-
- as mass counterpart of "lai": Individuals and masses
- contrasted with "la" in implications: Individuals and masses
- lanme: Anomalous lujvo, Anomalous lujvo
- lantro: Anomalous lujvo, Anomalous lujvo
- lanzu: The North Wind and the Sun
- latmo: Cultural and other non-algorithmic gismu
- lau: Punctuation marks, Punctuation marks, Punctuation marks, Punctuation marks, Punctuation marks
-
- effect on following lerfu word: Punctuation marks
- LAU selma'o
-
- grammar of following BY cmavo: List of all auxiliary lerfu-word cmavo
- le: Description sumti, Possession, cmavo, Linked sumti: be - bei - be'o, The five kinds of simple sumti, The five kinds of simple sumti, The three basic description types, The three basic description types, The three basic description types, The three basic description types, The three basic description types, The three basic description types, The three basic description types, Individuals and masses, Individuals and masses, Quantified descriptions, Quantified descriptions, Quantified descriptions, Quantified descriptions, Quantified descriptions, Quantified descriptions, Quantified descriptions, Quantified descriptions, The syntax of vocative phrases, Anaphoric pro-sumti and pro-bridi: the ri-series and the go'i-series, Non-veridical relative clauses: voi, Relative clauses and descriptors, Relative clauses and descriptors, Relative clauses and descriptors, Relative clauses and descriptors, The syntax of abstraction, Event abstraction, Event abstraction, Vocative scales, Non-logical connectives, Non-logical connectives, selbri and tanru negation, selbri and tanru negation, Metalinguistic negation forms, What's wrong with this picture?, Grouping of quantifiers, Simple infix expressions and equations, Erasure: SI, SA, SU, The North Wind and the Sun
-
- and specificity: The three basic description types
- and truth of selbri: The three basic description types
- compared with "la" in specificity: The three basic description types
- compared with English "the": The three basic description types
- contrasted with "lo" in implications: The three basic description types
- contrasted with "lo" in implicit quantification: Quantified descriptions
- contrasted with "lo" in specificity: The three basic description types
- contrasted with "lo" in truth requirement: The three basic description types
- implications of: The three basic description types
- implicit outer quantifier for: Quantified descriptions
- in false-to-fact descriptions: The three basic description types
- meaning of in the plural: Individuals and masses
- le nu
-
- definition: Event abstraction
- LE selma'o
-
- contrasted with LA in use of name-words: Lojban names
- introduction: Conversion: SE
- usage with selbri with JAI: Conversion of sumtcita: JAI
- le'a: Modal sentence connection: the causals, Expressing scales in selbri negation, Metalinguistic negation forms
- le'e: Descriptors for typical objects, Descriptors for typical objects, Descriptors for typical objects, Quantified descriptions, Quantified descriptions, Quantified descriptions, The North Wind and the Sun
-
- relationship to "le'i": Descriptors for typical objects
- le'i: Masses and sets, Descriptors for typical objects, Quantified descriptions, Quantified descriptions, The North Wind and the Sun
-
- as set counterpart of "lei": Masses and sets
- relationship to "le'e": Descriptors for typical objects
- le'o: Attitudinal modifiers, Attitudinal modifiers
- le'u: Quotation summary, Quotations: LU, LIhU, LOhU, LEhU, Quotations: LU, LIhU, LOhU, LEhU, Quotations: LU, LIhU, LOhU, LEhU, Quotations: LU, LIhU, LOhU, LEhU, Quotations: LU, LIhU, LOhU, LEhU, Quotations: LU, LIhU, LOhU, LEhU, More on quotations: ZO, ZOI, More on quotations: ZO, ZOI, More on quotations: ZO, ZOI, List of cmavo interactions, List of cmavo interactions, List of cmavo interactions
- le-series
-
- as encompassing le-series and la-series descriptors for quantification discussion: Quantified descriptions
- definition: Quantified descriptions
- descriptors compared with la-series in implicit quantification: Quantified descriptions
- rationale for implicit inner quantifier: Quantified descriptions
- rule for implicit inner quantifier: Quantified descriptions
- lebna: Compound bridi, Multiple compound bridi
- ledu'u: The North Wind and the Sun
- lego'i: The North Wind and the Sun
- lei: Individuals and masses, Individuals and masses, Masses and sets, Quantified descriptions, Quantified descriptions, The North Wind and the Sun
-
- contrasted with "loi" in specificity: Individuals and masses
- leka: The North Wind and the Sun
- lenei: The North Wind and the Sun
- lenku: The North Wind and the Sun
- lenu: The North Wind and the Sun
- lerci: The North Wind and the Sun
- lerfu: fu'ivla, What's a letteral, anyway?, What's a letteral, anyway?, The North Wind and the Sun
- lervla: What's a letteral, anyway?
- lesi'o: The North Wind and the Sun
- li: The five kinds of simple sumti, The five kinds of simple sumti, Number summary, Number summary, Number summary, Simple infix expressions and equations, Simple infix expressions and equations, Simple infix expressions and equations, Simple infix expressions and equations, Simple infix expressions and equations, Special mekso selbri, Logical and non-logical connectives within mekso, Logical and non-logical connectives within mekso, Logical and non-logical connectives within mekso, Other uses of mekso, Other uses of mekso, Other uses of mekso, Other uses of mekso, mekso selma'o summary, The North Wind and the Sun
-
- as converter of mekso into sumti: Simple infix expressions and equations
- contrasted with "me'o": Other uses of mekso
- relation to "me'o" compared with "la"/"zo" relation: Other uses of mekso
- terminator for: Logical and non-logical connectives within mekso
- LI selma'o: Number summary
- li'e: Modal sentence connection: the causals
- li'i: Minor abstraction types, Minor abstraction types, Minor abstraction types
- li'o: Miscellaneous indicators, Miscellaneous indicators, Miscellaneous indicators, Miscellaneous indicators
- li'u: The five kinds of simple sumti, Quotation summary, References to lerfu, Quotations: LU, LIhU, LOhU, LEhU, Quotations: LU, LIhU, LOhU, LEhU, Quotations: LU, LIhU, LOhU, LEhU, Quotations: LU, LIhU, LOhU, LEhU, No more to say: FAhO, The North Wind and the Sun
- libjo: Cultural and other non-algorithmic gismu
- lifri: The North Wind and the Sun
- lijda: Anomalous lujvo, Anomalous lujvo
- lijgri: Some types of asymmetrical tanru
- lindi: The North Wind and the Sun
- linji: The North Wind and the Sun
- linsi: The North Wind and the Sun
- lisri: The North Wind and the Sun
- liste: Non-logical connectives
- litki: Implicit-abstraction lujvo
- litru: Dependent places, Dependent places, The North Wind and the Sun
- lo: The three basic description types, The three basic description types, The three basic description types, The three basic description types, The three basic description types, Individuals and masses, Masses and sets, Masses and sets, Quantified descriptions, Quantified descriptions, Quantified descriptions, Quantified descriptions, Quantified descriptions, Quantified descriptions, Quantified descriptions, Indefinite descriptions, Indefinite descriptions, Indefinite descriptions, Pro-sumti summary, Quotation summary, Number summary, Non-veridical relative clauses: voi, Relative clauses and descriptors, Relative clauses and descriptors, Relative clauses and descriptors, Relative clauses and descriptors, selbri and tanru negation, selbri and tanru negation, Metalinguistic negation forms, Grouping of quantifiers, Logical and non-logical connectives within mekso, The North Wind and the Sun
-
- and truth of selbri: The three basic description types
- contrasted with "le" in implications: The three basic description types
- contrasted with "le" in implicit quantification: Quantified descriptions
- contrasted with "le" in specificity: The three basic description types
- contrasted with "le" in truth requirement: The three basic description types
- contrasted with "loi" and "lo'i": Masses and sets
- implications of: The three basic description types
- implicit outer quantifier for: Quantified descriptions
- omission of: Indefinite descriptions
- lo'a: Alien alphabets, Alien alphabets
-
- contrasted with "na'a": Alien alphabets
- lo'e: Descriptors for typical objects, Descriptors for typical objects, Quantified descriptions, Quantified descriptions, Quantified descriptions, The North Wind and the Sun
-
- relationship to "lo'i": Descriptors for typical objects
- lo'i: Masses and sets, Masses and sets, Masses and sets, Quantified descriptions, Quantified descriptions, Special mekso selbri, The North Wind and the Sun
-
- as set counterpart of "loi": Masses and sets
- contrasted with "lo" and "loi": Masses and sets
- relationship to "lo'e": Descriptors for typical objects
- with elided quantifiers: Special mekso selbri
- lo'o: Logical and non-logical connectives within mekso, Logical and non-logical connectives within mekso
-
- effect of logical connective on elidability of: Logical and non-logical connectives within mekso
- lo'u: The five kinds of simple sumti, Quotation summary, The universal bu, Quotations: LU, LIhU, LOhU, LEhU, Quotations: LU, LIhU, LOhU, LEhU, Quotations: LU, LIhU, LOhU, LEhU, Quotations: LU, LIhU, LOhU, LEhU, Quotations: LU, LIhU, LOhU, LEhU, Quotations: LU, LIhU, LOhU, LEhU, Quotations: LU, LIhU, LOhU, LEhU, Quotations: LU, LIhU, LOhU, LEhU, More on quotations: ZO, ZOI, More on quotations: ZO, ZOI, Erasure: SI, SA, SU, List of cmavo interactions, List of cmavo interactions, List of cmavo interactions, List of cmavo interactions
-
- interaction with "bu": The universal bu
- lo-series
-
- caution on exact numbers as inner quantifiers: Quantified descriptions
- rationale for implicit inner quantifier: Quantified descriptions
- rule for implicit inner quantifier: Quantified descriptions
- logji: Lojban names
- loi: Individuals and masses, Individuals and masses, Individuals and masses, Individuals and masses, Individuals and masses, Masses and sets, Masses and sets, Quantified descriptions, Quantified descriptions, Non-veridical relative clauses: voi, The North Wind and the Sun
-
- as mass counterpart of "lo": Individuals and masses
- contrasted with "lei" in specificity: Individuals and masses
- contrasted with "lo" and "lo'i": Masses and sets
- lojbangirz: lujvo-making examples
- lojbaugri: lujvo-making examples
- lojbo: Cultural and other non-algorithmic gismu, Cultural and other non-algorithmic gismu
- loldi: The North Wind and the Sun
- lonu: The North Wind and the Sun
- lu: The five kinds of simple sumti, The five kinds of simple sumti, Quotation summary, References to lerfu, Quotations: LU, LIhU, LOhU, LEhU, Quotations: LU, LIhU, LOhU, LEhU, Quotations: LU, LIhU, LOhU, LEhU, No more to say: FAhO, The North Wind and the Sun
-
- contrasted with "me'o" for representing lerfu: References to lerfu
- lu'a: Quantified descriptions, sumti qualifiers, The North Wind and the Sun
-
- effect of on meaning: sumti qualifiers
- lu'e: sumti qualifiers, Predication/sentence abstraction, Predication/sentence abstraction, Miscellany, More on quotations: ZO, ZOI
-
- as short for "le sinxa be": sumti qualifiers
- effect of on meaning: sumti qualifiers
- lu'i: sumti qualifiers, The North Wind and the Sun
-
- effect of on meaning: sumti qualifiers
- lu'o: sumti qualifiers
-
- effect of on meaning: sumti qualifiers
- lu'u: sumti qualifiers, Relative clauses and complex sumti: vu'o, Lojban sumti raising
-
- as elidable terminator for qualified sumti: sumti qualifiers
- lubno: Cultural and other non-algorithmic gismu
- lubu: The North Wind and the Sun
- lujvo: Lojban grammatical terms, lujvo, Cultural and other non-algorithmic gismu, Cultural and other non-algorithmic gismu
- ly.: Some simple Lojban bridi, A to Z in Lojban, plus one, Proposed lerfu words for the Greek alphabet, Proposed lerfu words for the Cyrillic alphabet, Proposed lerfu words for the Hebrew alphabet
M
- ma: Questions, Questions, Questions, Questions, Questions, Questions, Pro-sumti summary, sumti and bridi questions: ma and mo, sumti and bridi questions: ma and mo, sumti and bridi questions: ma and mo, Tense questions: cu'e, Indirect questions, Indirect questions, Indirect questions, Indirect questions, Indirect questions, Questions and answers, Questions and answers, Questions and answers, Questions and answers, The North Wind and the Sun
-
- as sumti question: sumti and bridi questions: ma and mo
- for tense questions: Tense questions: cu'e
- ma'a: Pro-sumti summary, Pro-sumti summary, Personal pro-sumti: the mi-series, Personal pro-sumti: the mi-series, Personal pro-sumti: the mi-series
- ma'e: Modal sentence connection: the causals
- ma'i: Modal sentence connection: the causals, Movement in space: MOhI, Special mekso selbri
- ma'o: Mathematical uses of lerfu strings, Forethought operators (Polish notation, functions), Forethought operators (Polish notation, functions), Forethought operators (Polish notation, functions), Vectors and matrices, Explicit operator precedence, Miscellany, Miscellany
-
- potential ambiguity caveat: Miscellany
- ma'u: Signs and numerical punctuation, Signs and numerical punctuation, Simple infix expressions and equations, Indefinite numbers, Approximation and inexact numbers
-
- with elided number: Indefinite numbers
- mabla: Attitudinal modifiers
- mai: Other uses of mekso, Other uses of mekso, Utterance ordinals: MAI, Utterance ordinals: MAI, Utterance ordinals: MAI, The North Wind and the Sun
-
- contrasted with "mo'o": Other uses of mekso
- MAI selma'o
-
- exception on use of "boi" before: Other uses of mekso
- makau: The North Wind and the Sun
- mamta: rafsi, Linked sumti: be - bei - be'o, The North Wind and the Sun
- manci: The North Wind and the Sun
- manku: The North Wind and the Sun
- mapti: The North Wind and the Sun
- marji: The North Wind and the Sun
- masno: The North Wind and the Sun
- matne: Individuals and masses, The North Wind and the Sun
- mau: Modal sentence connection: the causals, Modal relative phrases; Comparison, Modal relative phrases; Comparison, Modal relative phrases; Comparison
-
- avoiding in favor of "seme'a": Modal relative phrases; Comparison
- me: selbri based on sumti: me, selbri based on sumti: me, selbri based on sumti: me, selbri based on sumti: me, selbri based on sumti: me, selbri based on sumti: me, selbri based on sumti: me, selbri based on sumti: me, Acronyms, Special mekso selbri, Special mekso selbri, Special mekso selbri, Special mekso selbri, The North Wind and the Sun
-
- compared with "du" in effect: selbri based on sumti: me
- effect of MOI on: Special mekso selbri
- explicitly specifying: Vocative scales
- place structure of: selbri based on sumti: me
- used with names: selbri based on sumti: me
- me'a: Modal sentence connection: the causals, Modal relative phrases; Comparison, Modal relative phrases; Comparison, Modal relative phrases; Comparison
-
- avoiding in favor of "semau": Modal relative phrases; Comparison
- me'e: Modal sentence connection: the causals, The North Wind and the Sun
- me'i: Approximation and inexact numbers
-
- with elided number: Approximation and inexact numbers
- me'o: Number summary, Number summary, Number summary, The universal bu, References to lerfu, References to lerfu, References to lerfu, Other uses of mekso, Other uses of mekso, Other uses of mekso, mekso selma'o summary
-
- as a prefix for logograms: The universal bu
- compared with "la'e lu": References to lerfu
- contrasted with "li": Other uses of mekso
- contrasted with "lu…li'u" for representing lerfu: References to lerfu
- contrasted with quotation for representing lerfu: References to lerfu
- relation to "li" compared with "l"a/"zo" relation: Other uses of mekso
- me'u: selbri based on sumti: me, selbri based on sumti: me, selbri based on sumti: me, selbri based on sumti: me, selbri based on sumti: me, selbri based on sumti: me, selbri based on sumti: me, Special mekso selbri, Special mekso selbri
-
- elidability: selbri based on sumti: me
- relative precedence with logical connectives: selbri based on sumti: me
- megdo: Cultural and other non-algorithmic gismu
- mei: Non-logical connectives, Special mekso selbri, Miscellany, mekso selma'o summary, The North Wind and the Sun
- mekso: Cultural and other non-algorithmic gismu
- melbi: Some words used to indicate selbri relations, Complex tanru grouping, Complex tanru grouping, The North Wind and the Sun
- meljo: Cultural and other non-algorithmic gismu
- menli: The North Wind and the Sun
- mensi: The North Wind and the Sun
- merko: Cultural and other non-algorithmic gismu, Acronyms
- mexno: Cultural and other non-algorithmic gismu
- mi: Description sumti, Questions, Linked sumti: be - bei - be'o, Inversion of tanru: co, The five kinds of simple sumti, The five kinds of simple sumti, The five kinds of simple sumti, The five kinds of simple sumti, Quantified sumti, Pro-sumti summary, Personal pro-sumti: the mi-series, Personal pro-sumti: the mi-series, Personal pro-sumti: the mi-series, Personal pro-sumti: the mi-series, Personal pro-sumti: the mi-series, Personal pro-sumti: the mi-series, Demonstrative pro-sumti: the ti-series, Assignable pro-sumti and pro-bridi: the ko'a-series and the broda-series, Anaphoric pro-sumti and pro-bridi: the ri-series and the go'i-series, Anaphoric pro-sumti and pro-bridi: the ri-series and the go'i-series, Anaphoric pro-sumti and pro-bridi: the ri-series and the go'i-series, Anaphoric pro-sumti and pro-bridi: the ri-series and the go'i-series, Anaphoric pro-sumti and pro-bridi: the ri-series and the go'i-series, Anaphoric pro-sumti and pro-bridi: the ri-series and the go'i-series, Pro-sumti and pro-bridi cancelling, Incidental relative clauses, Possessive sumti, Standard bridi form: cu, Tagging places: FA, Tagging places: FA, Tagging places: FA, Conversion: SE, Conversion: SE, Modal conversion: JAI, Attitudinal modifiers, Attitudinal modifiers, Vocative scales, Multiple compound bridi, Termset logical connection, selbri and tanru negation, Special mekso selbri, The North Wind and the Sun
- mi'a: Pro-sumti summary, Pro-sumti summary, Personal pro-sumti: the mi-series, Personal pro-sumti: the mi-series, Personal pro-sumti: the mi-series, Personal pro-sumti: the mi-series, The North Wind and the Sun
- mi'e: Personal pro-sumti: the mi-series, Vocative scales, Vocative scales, Vocative scales, Vocative scales, Vocative scales, Vocative scales
-
- contrasted with other members of COI: Vocative scales
- effect of ordering multiple COI: Vocative scales
- mi'enai: Vocative scales
- mi'i: Interval connectives and forethought non-logical connection, Interval connectives and forethought non-logical connection, Logical and non-logical connectives within mekso
- mi'o: cmavo, Quantified sumti, Pro-sumti summary, Pro-sumti summary, Personal pro-sumti: the mi-series, Personal pro-sumti: the mi-series, Personal pro-sumti: the mi-series, Personal pro-sumti: the mi-series, Personal pro-sumti: the mi-series, The North Wind and the Sun
- mi'u: Discursives
-
- contrasted with "go'i": Discursives
- mi-series
-
- pro-sumti: Personal pro-sumti: the mi-series
- pro-sumti and lack of pro-bridi equivalent: Personal pro-sumti: the mi-series
- midju: Proposed lerfu words for some accent marks and multiple letters, The North Wind and the Sun
- mikce: Ordering lujvo places.
- mikri: Cultural and other non-algorithmic gismu
- milti: Cultural and other non-algorithmic gismu
- milxe: The North Wind and the Sun
- minde: Anomalous lujvo, The North Wind and the Sun
- minli: The North Wind and the Sun
- mintu: The North Wind and the Sun
-
- contrasted with "du": The identity predicate: du
- misro: Cultural and other non-algorithmic gismu
- mixre: The North Wind and the Sun
- mlana: The North Wind and the Sun
- mlatu: Logical connection within tanru, Logical connection within tanru, The North Wind and the Sun
- mleca: Modal relative phrases; Comparison, Modal relative phrases; Comparison, Comparatives and superlatives, Comparatives and superlatives, Comparatives and superlatives, Comparatives and superlatives, Comparatives and superlatives, Comparatives and superlatives, Other useful selbri for mekso bridi, Other useful selbri for mekso bridi
- mo: Questions, Questions, Questions, Questions, Questions, Questions, sumti and bridi questions: ma and mo, sumti and bridi questions: ma and mo, sumti and bridi questions: ma and mo, sumti and bridi questions: ma and mo, selbri and tanru negation, Other uses of mekso, Questions and answers, Questions and answers
-
- as selbri question: sumti and bridi questions: ma and mo
- compared with "go'i" in overriding of arguments: sumti and bridi questions: ma and mo
- mo'a: Attitudinal modifiers, Indefinite numbers, Indefinite numbers, Special mekso selbri
- mo'e: Amount abstractions, Using Lojban resources within mekso, Four score and seven: a mekso problem
-
- terminator for: Using Lojban resources within mekso
- mo'i: Movement in space: MOhI, Movement in space: MOhI, Movement in space: MOhI, Movement in space: MOhI, List of spatial directions and direction-like relations, List of spatial directions and direction-like relations, List of spatial directions and direction-like relations, The North Wind and the Sun
- mo'o: Other uses of mekso, Other uses of mekso, Other uses of mekso, Other uses of mekso, Utterance ordinals: MAI, Utterance ordinals: MAI, Utterance ordinals: MAI, Utterance ordinals: MAI, Utterance ordinals: MAI, The North Wind and the Sun
-
- contrasted with "mai": Other uses of mekso
- mo'u: Event-type abstractors and event contour tenses, Event-type abstractors and event contour tenses, The North Wind and the Sun
- moi: Special mekso selbri, Special mekso selbri, Special mekso selbri, Miscellany, mekso selma'o summary
- MOI selma'o
-
- in mathematical expressions: Other kinds of simple selbri
- use of "boi" before: Special mekso selbri
- mojysu'a: Some types of asymmetrical tanru
- mokca: Proposed lerfu words for some accent marks and multiple letters, Proposed lerfu words for some accent marks and multiple letters
- molro: Cultural and other non-algorithmic gismu
- morji: The North Wind and the Sun
- morko: Cultural and other non-algorithmic gismu
- morsi: The North Wind and the Sun
- mrostu: Some types of asymmetrical tanru
- mu: Quantified sumti, Relative clauses and descriptors, Number questions, Reverse Polish notation, The North Wind and the Sun
- mu'a: The North Wind and the Sun
- mu'anai: The North Wind and the Sun
- mu'e: Types of event abstractions, Types of event abstractions, Event-type abstractors and event contour tenses, Event-type abstractors and event contour tenses
-
- place structure: Types of event abstractions
- mu'i: Modal sentence connection: the causals, Modal sentence connection: the causals, Tenses versus modals, The North Wind and the Sun
- mu'onai: Vocative scales
- mu'u: Modal sentence connection: the causals
- mukti: Modal sentence connection: the causals, Tenses versus modals, Tenses versus modals, Tenses versus modals, The North Wind and the Sun
- mulgri: Some types of asymmetrical tanru
- mulno: The North Wind and the Sun
- murta: The North Wind and the Sun
- muslo: Cultural and other non-algorithmic gismu
- mutce: The North Wind and the Sun
- muvdu: The North Wind and the Sun
- my.: A to Z in Lojban, plus one, Proposed lerfu words for the Greek alphabet, Proposed lerfu words for the Cyrillic alphabet, Proposed lerfu words for the Hebrew alphabet, The North Wind and the Sun
N
- na: Questions, Tenses and bridi negation, Tenses and bridi negation, Tenses and bridi negation, Tenses and bridi negation, The six types of logical connectives, Logical connection of bridi, Logical connection of bridi, Logical connection of bridi, Logical connection of bridi, Forethought bridi connection, sumti connection, sumti connection, sumti connection, Compound bridi, Multiple compound bridi, Logical connection within tanru, Truth questions and connective questions, Truth questions and connective questions, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Rules for making logical and non-logical connectives, Rules for making logical and non-logical connectives, Rules for making logical and non-logical connectives, bridi negation, bridi negation, bridi negation, bridi negation, bridi negation, bridi negation, bridi negation, bridi negation, bridi negation, bridi negation, selbri and tanru negation, Truth questions, Truth questions, Affirmations, Affirmations, Affirmations, Affirmations, Metalinguistic negation forms, Negation boundaries, Negation boundaries, Negation boundaries, bridi negation and logical connectives, bridi negation and logical connectives, bridi negation and logical connectives, bridi negation and logical connectives, bridi negation and logical connectives, Using naku outside a prenex, Using naku outside a prenex, Using naku outside a prenex, Using naku outside a prenex, Using naku outside a prenex, Using naku outside a prenex, Logical connectives and DeMorgan's law, Logical connectives and DeMorgan's law, Logical connectives and DeMorgan's law, Logical connectives and DeMorgan's law, Other useful selbri for mekso bridi, Questions and answers, Subscripts: XI, The North Wind and the Sun
-
- and negation boundary: Logical connectives and DeMorgan's law
- multiple "na" and tense: Tenses and bridi negation
- order in logical connectives with "se": Logical connection of bridi
- writing convention in eks: sumti connection
- na'a: Alien alphabets
-
- contrasted with "lo'a": Alien alphabets
- na'e: Scalar negation of selbri, Scalar negation of selbri, Scalar negation of selbri, Scalar negation of selbri, Modal negation, Eliding KE and KEhE rafsi from lujvo, Eliding KE and KEhE rafsi from lujvo, selbri and tanru negation, selbri and tanru negation, selbri and tanru negation, selbri and tanru negation, selbri and tanru negation, selbri and tanru negation, selbri and tanru negation, selbri and tanru negation, selbri and tanru negation, selbri and tanru negation, selbri and tanru negation, selbri and tanru negation, selbri and tanru negation, selbri and tanru negation, selbri and tanru negation, selbri and tanru negation, selbri and tanru negation, selbri and tanru negation, selbri and tanru negation, selbri and tanru negation, selbri and tanru negation, selbri and tanru negation, selbri and tanru negation, selbri and tanru negation, selbri and tanru negation, Expressing scales in selbri negation, Expressing scales in selbri negation, Expressing scales in selbri negation, Expressing scales in selbri negation, Truth questions, Affirmations, Metalinguistic negation forms, The North Wind and the Sun
-
- before "gu'e": Scalar negation of selbri
- contrasted with "na'e ke": Scalar negation of selbri
- na'i: Miscellaneous indicators, Miscellaneous indicators, Miscellaneous indicators, Metalinguistic negation forms, Metalinguistic negation forms, Metalinguistic negation forms, Metalinguistic negation forms, Metalinguistic negation forms, Metalinguistic negation forms, Metalinguistic negation forms, Metalinguistic negation forms, Metalinguistic negation forms, Metalinguistic negation forms, Metalinguistic negation forms, Metalinguistic negation forms
- na'o: Interval properties: TAhE and roi
- na'u: Using Lojban resources within mekso, Using Lojban resources within mekso, Other uses of mekso, Other uses of mekso, Other uses of mekso, Explicit operator precedence
-
- terminator for: Using Lojban resources within mekso
- use in asking operator questions: Other uses of mekso
- na'ujbi: Other useful selbri for mekso bridi
- NAhE selma'o: sumti qualifiers
-
- effect of relative clause placement with: Relative clauses and complex sumti: vu'o
- for negating PU: Tense negation
- in mekso: Miscellany
- NAhE+BO construct
-
- explanation of sumti negation: sumti negation
- introduction: sumti qualifiers
- nai: Pure emotion indicators, Attitudes as scales, Attitudes as scales, Attitudes as scales, Emotional categories, Compound indicators, Compound indicators, Compound indicators, Compound indicators, Compound indicators, Compound indicators, Compound indicators, Compound indicators, Compound indicators, Compound indicators, Vocative scales, Vocative scales, The six types of logical connectives, Logical connection of bridi, Forethought bridi connection, Forethought bridi connection, Forethought bridi connection, Forethought bridi connection, Forethought bridi connection, Forethought bridi connection, Compound bridi, Logical connection within tanru, Logical connection within tanru, More about non-logical connectives, More about non-logical connectives, Interval connectives and forethought non-logical connection, Interval connectives and forethought non-logical connection, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Rules for making logical and non-logical connectives, Rules for making logical and non-logical connectives, Rules for making logical and non-logical connectives, Rules for making logical and non-logical connectives, Rules for making logical and non-logical connectives, Negation of minor grammatical constructs, Negation of minor grammatical constructs, Negation of minor grammatical constructs, Negation of minor grammatical constructs, Negation of minor grammatical constructs, Negation of minor grammatical constructs, Negation of minor grammatical constructs, Negation of minor grammatical constructs, Negation of minor grammatical constructs, bridi negation and logical connectives, bridi negation and logical connectives, bridi negation and logical connectives, bridi negation and logical connectives, Logical connectives and DeMorgan's law, Logical connectives and DeMorgan's law, Logical connectives and DeMorgan's law, Questions and answers, List of cmavo interactions, List of cmavo interactions, The North Wind and the Sun
-
- effect on joiks: More about non-logical connectives
- placement in afterthought bridi connection contrasted with forethought: Forethought bridi connection
- placement in forethought bridi connection contrasted with afterthought: Forethought bridi connection
- naja: Logical connection within tanru, “Pretty little girls' school” : forty ways to say it
- najnimre: The North Wind and the Sun
- naku: The North Wind and the Sun
-
- as creating a negation boundary: Using naku outside a prenex
- compared with sumti in grammar: Using naku outside a prenex
- effect on conversion with "se" on negation boundary: Using naku outside a prenex
- effect on moving quantifiers: Using naku outside a prenex
- in linked sumti places: Using naku outside a prenex
- multiple in sentence: Using naku outside a prenex
- negation; rationale for considering an advanced technique: Using naku outside a prenex
- outside of prenex: Using naku outside a prenex
- naku su'oda
-
- as expansion of "noda": Negation boundaries
- naku zo'u
-
- and negation boundary: Logical connectives and DeMorgan's law
- nakykemcinctu: lujvo-making examples, lujvo-making examples
- namcu: Other useful selbri for mekso bridi
- nanba: The North Wind and the Sun
- nanla: The North Wind and the Sun
- nanmu: Relative clauses and complex sumti: vu'o, Relative clauses and complex sumti: vu'o, Modal tags: BAI, selbri variables
- nanvi: Cultural and other non-algorithmic gismu
- nau: Tenses in subordinate bridi, Tenses in subordinate bridi, Tenses in subordinate bridi, Tenses in subordinate bridi
-
- effect on sticky tenses: Tenses in subordinate bridi
- syntax: Tenses in subordinate bridi
- ne: Relative phrases, Modal relative phrases; Comparison, Modal relative phrases; Comparison, The North Wind and the Sun
-
- compared with "pe": Relative phrases
- ne'a: List of spatial directions and direction-like relations, The North Wind and the Sun
- ne'i: List of spatial directions and direction-like relations, The North Wind and the Sun
- ne'u: List of spatial directions and direction-like relations
- nei: Anaphoric pro-sumti and pro-bridi: the ri-series and the go'i-series, Anaphoric pro-sumti and pro-bridi: the ri-series and the go'i-series
- ni: Amount abstractions, Amount abstractions, Truth-value abstraction: jei, Truth-value abstraction: jei, Truth-value abstraction: jei, Using Lojban resources within mekso, Using Lojban resources within mekso, A catalogue of selma'o
- ni'a: List of spatial directions and direction-like relations, The North Wind and the Sun
- ni'e: Using Lojban resources within mekso, Using Lojban resources within mekso, Using Lojban resources within mekso, Explicit operator precedence
-
- terminator for: Using Lojban resources within mekso
- ni'i: Modal sentence connection: the causals, Modal sentence connection: the causals
- ni'o: The basic structure of longer utterances, The basic structure of longer utterances, The basic structure of longer utterances, The basic structure of longer utterances, Pro-sumti and pro-bridi cancelling, Paragraphs: NIhO, Paragraphs: NIhO, Paragraphs: NIhO, Paragraphs: NIhO, Paragraphs: NIhO, Paragraphs: NIhO, Paragraphs: NIhO, Paragraphs: NIhO, Paragraphs: NIhO, Paragraphs: NIhO, Paragraphs: NIhO, Paragraphs: NIhO, Paragraphs: NIhO, Paragraphs: NIhO, Paragraphs: NIhO, Paragraphs: NIhO, Subscripts: XI, Attitude scope markers: FUhE/FUhO, The North Wind and the Sun
-
- effect on pro-sumti/pro-bridi assignments: Pro-sumti and pro-bridi cancelling
- ni'u: Signs and numerical punctuation, Signs and numerical punctuation, Forethought operators (Polish notation, functions), Indefinite numbers, Approximation and inexact numbers
-
- with elided number: Indefinite numbers
- nibli: Modal sentence connection: the causals
- nicte: The North Wind and the Sun
- nimre: Simple tanru
- ninmu: The North Wind and the Sun
- nitcu: The problem of “any”
- nixli: Three-part tanru grouping with bo, Linked sumti: be - bei - be'o, The North Wind and the Sun
- no: Syllabication and stress, IPA for English speakers, Pro-sumti summary, Pro-sumti summary, Truth questions and connective questions, Negation boundaries, Negation boundaries, Negation boundaries, Lojban numbers, Indefinite numbers, Non-decimal and compound bases, The North Wind and the Sun
-
- expanding quantifier: Negation boundaries
- no'a: Anaphoric pro-sumti and pro-bridi: the ri-series and the go'i-series, Anaphoric pro-sumti and pro-bridi: the ri-series and the go'i-series, Anaphoric pro-sumti and pro-bridi: the ri-series and the go'i-series
- no'e: Expressing scales in selbri negation, Expressing scales in selbri negation, Expressing scales in selbri negation
- no'i: Pro-sumti and pro-bridi cancelling, Paragraphs: NIhO, Paragraphs: NIhO, Paragraphs: NIhO, Paragraphs: NIhO, Paragraphs: NIhO, Paragraphs: NIhO, Paragraphs: NIhO, Subscripts: XI, Attitude scope markers: FUhE/FUhO
-
- effect on pro-sumti/pro-bridi assignments: Pro-sumti and pro-bridi cancelling
- no'o: Indefinite numbers, Indefinite numbers
- no'u: Relative phrases, Relative phrases
-
- compared with "po'u": Relative phrases
- contrasted with po'u: Relative phrases
- nobli: cmevla
- noda: Negation boundaries
-
- expanding to "naku su'oda": Negation boundaries
- noi: What are you pointing at?, Incidental relative clauses, Incidental relative clauses, Relative phrases, Multiple relative clauses: zi'e, Relative clauses and descriptors, Modal relative phrases; Comparison, Modal relative phrases; Comparison, The North Wind and the Sun
- nolraitru: Some types of asymmetrical tanru
- noroi: The North Wind and the Sun
- nu: The syntax of abstraction, Event abstraction, Event abstraction, Event abstraction, Event abstraction, Types of event abstractions, Types of event abstractions, Property abstractions, Why have lujvo?, Abstract lujvo, Abstract lujvo, Abstract lujvo, Abstract lujvo, Implicit-abstraction lujvo, Implicit-abstraction lujvo, Implicit-abstraction lujvo, Subscripts: XI, The North Wind and the Sun
-
- definition: Event abstraction
- place structure: Event abstraction
- NU selma'o
-
- event-type abstractors: Event-type abstractors and event contour tenses
- introduction: Other kinds of simple selbri
- with connectives: Abstractor connection and connection within abstractions
- nu'a: Other kinds of simple selbri, Other uses of mekso, Other uses of mekso, Other uses of mekso, Other uses of mekso
-
- use in answering operator questions: Other uses of mekso
- nu'e: Vocative scales
- nu'i: Other modal connections, Explicit magnitudes, Termset logical connection, Termset logical connection, Termset logical connection, Grouping of quantifiers
- nu'o: Actuality, potentiality, capability: CAhA, Actuality, potentiality, capability: CAhA, The North Wind and the Sun
- nu'u: Other modal connections, Explicit magnitudes, Termset logical connection, Termset logical connection, Grouping of quantifiers, Grouping of quantifiers
- nuncti: Some types of symmetrical tanru, Implicit-abstraction lujvo, Implicit-abstraction lujvo
- nunctu: Some types of asymmetrical tanru
- nunkla: Abstract lujvo, Subscripts: XI, Subscripts: XI
- nupre: The North Wind and the Sun
- nuzlo: The North Wind and the Sun
- ny.: A to Z in Lojban, plus one, Mathematical uses of lerfu strings, Proposed lerfu words for the Greek alphabet, Proposed lerfu words for the Cyrillic alphabet, Proposed lerfu words for the Hebrew alphabet, Simple infix expressions and equations, Forethought operators (Polish notation, functions)
P
- pa: cmevla, Quantified sumti, Variables with generalized quantifiers, Signs and numerical punctuation, Forethought operators (Polish notation, functions), Indefinite numbers, Indefinite numbers, Approximation and inexact numbers, Special mekso selbri, Special mekso selbri, Vectors and matrices, The North Wind and the Sun
- PA selma'o
-
- exception on use of "boi" with MOI: Special mekso selbri
- members with rafsi: Miscellany
- pa'a: Modal sentence connection: the causals
- pa'e: Discursives
- pa'enai: Discursives
- pa'o: List of spatial directions and direction-like relations, The North Wind and the Sun
- pa'u: Modal sentence connection: the causals
- pacna: The North Wind and the Sun
- pacru'i: Some types of symmetrical tanru
- pagbu: Other useful selbri for mekso bridi
- pagre: The North Wind and the Sun
- pai: Special numbers
- palta: The North Wind and the Sun
- pamai: The North Wind and the Sun
- pamoi: Scalar negation of selbri, Special mekso selbri, The North Wind and the Sun
- panci: The North Wind and the Sun
- pare'uku: The North Wind and the Sun
- paso: Non-decimal and compound bases
- patyta'a: rafsi
- pau: Miscellaneous indicators, Miscellaneous indicators, Questions and answers, The North Wind and the Sun
-
- placement in sentence: Miscellaneous indicators
- paunai: Miscellaneous indicators
- pe: Relative phrases, Relative phrases, Possessive sumti, Possessive sumti, Possessive sumti, Modal relative phrases; Comparison, The North Wind and the Sun
-
- as loose association: Relative phrases
- compared with "ne": Relative phrases
- compared with poi ke'a srana : Relative phrases
- contrasted with "po": Relative phrases
- pe'a: Miscellaneous indicators, Miscellaneous indicators, Miscellaneous indicators, The North Wind and the Sun
- pe'e: Termset logical connection, Termset logical connection, Logical connection within tanru
- pe'i: Indicators, Evidentials, Evidentials, The North Wind and the Sun
- pe'o: Forethought operators (Polish notation, functions), Forethought operators (Polish notation, functions), Forethought operators (Polish notation, functions)
- pe'u
-
- contrasted with ".e'o": Vocative scales
- pei: cmavo, Attitudes as scales, Attitude questions; empathy; attitude contours, Attitude questions; empathy; attitude contours, Attitude questions; empathy; attitude contours, Attitude questions; empathy; attitude contours, Attitude questions; empathy; attitude contours, Attitude questions; empathy; attitude contours, Questions and answers, The North Wind and the Sun
- pelji: The North Wind and the Sun
- pelnimre: Simple tanru
- pelxu: Simple tanru
- pendo: The North Wind and the Sun
- penmi: The North Wind and the Sun
- pensi: The North Wind and the Sun
- petso: Cultural and other non-algorithmic gismu
- pezli: The North Wind and the Sun
- pi: Quantified descriptions, Signs and numerical punctuation, Signs and numerical punctuation, Indefinite numbers, Indefinite numbers, Approximation and inexact numbers, Non-decimal and compound bases, Non-decimal and compound bases, Miscellany
- pi'a: Vectors and matrices, Vectors and matrices, Vectors and matrices
- pi'e: Non-decimal and compound bases, Non-decimal and compound bases, Non-decimal and compound bases, Non-decimal and compound bases, Non-decimal and compound bases, Non-decimal and compound bases
- pi'i: Simple infix expressions and equations, Simple infix expressions and equations, Reverse Polish notation, Reverse Polish notation, The North Wind and the Sun
- pi'o: Modal tags: BAI, Modal tags: BAI, Modal sentence connection: the causals
- pi'u: Sub-events, Non-logical connectives, Non-logical connectives, More about non-logical connectives
-
- contrasted with ".e": More about non-logical connectives
- use in connecting tenses: Sub-events
- picti: Cultural and other non-algorithmic gismu
- pilno: Modal places: FIhO, FEhU, Modal places: FIhO, FEhU, Modal places: FIhO, FEhU, Modal places: FIhO, FEhU, Modal tags: BAI, Modal tags: BAI, Modal tags: BAI, Modal tags: BAI, Anomalous lujvo, Anomalous lujvo
- pimlu: The North Wind and the Sun
- pinta: The North Wind and the Sun
- pinxe: The North Wind and the Sun
- piro: Quantified sumti, Quantified descriptions, Quantified descriptions, Indefinite numbers, Approximation and inexact numbers
- piso'a: Indefinite numbers
- piso'u: Indefinite numbers
- pisu'o: Quantified sumti, Quantified descriptions, Pro-sumti summary, Approximation and inexact numbers, Approximation and inexact numbers
- pixra: The North Wind and the Sun
- plipe: The North Wind and the Sun
- pluka: Some words used to indicate selbri relations, The North Wind and the Sun
- pluta: Conversion: SE, The North Wind and the Sun
-
- contrasted with "ve klama": Conversion: SE
- po: Relative phrases, Relative phrases, Relative phrases
-
- as restrictive possession: Relative phrases
- compared with poi ke'a se steci srana : Relative phrases
- contrasted with "pe": Relative phrases
- contrasted with "po'e": Relative phrases
- contrasted with English possession : Relative phrases
- po'e: Relative phrases, Relative phrases
-
- as intrinsic possession: Relative phrases
- compared with poi ke'a jinzi ke se steci srana : Relative phrases
- contrasted with "po": Relative phrases
- po'i: Modal sentence connection: the causals
- po'o: Discursives, Discursives, The North Wind and the Sun
-
- placement in sentence: Discursives
- po'u: Relative phrases, Relative phrases, Relative phrases, Relative phrases, Relative phrases
-
- as identity: Relative phrases
- compared with "no'u": Relative phrases
- compared with poi ke'a du : Relative phrases
- contrasted with no'u: Relative phrases
- relative phrase of contrasted with relativized sumti of: Relative phrases
- poi: What are you pointing at?, What are you pointing at?, What are you pointing at?, Incidental relative clauses, Incidental relative clauses, Incidental relative clauses, Multiple relative clauses: zi'e, Non-veridical relative clauses: voi, Non-veridical relative clauses: voi, Non-veridical relative clauses: voi, Relative clauses and descriptors, Modal relative phrases; Comparison, Modal relative phrases; Comparison, Metalinguistic negation forms, Restricted claims: da poi, Restricted claims: da poi, Dropping the prenex, Dropping the prenex, The North Wind and the Sun
-
- discussion of translation: What are you pointing at?
- dropping from multiple appearances on logical variables: Dropping the prenex
- syntax of: What are you pointing at?
- polje: The North Wind and the Sun
- polno: Cultural and other non-algorithmic gismu
- ponjo: Cultural and other non-algorithmic gismu
- ponse: Topic-comment sentences: ZOhU
- porsi: The North Wind and the Sun
- porto: Cultural and other non-algorithmic gismu
- prali: The North Wind and the Sun
- prenu: Simple tanru, Simple tanru, Individuals and masses, Simple infix expressions and equations, The North Wind and the Sun
- preti: The North Wind and the Sun
- prije: The North Wind and the Sun
- prina: The North Wind and the Sun
- pritu: Proposed lerfu words for some accent marks and multiple letters
- pu: Tenses, Tenses and bridi negation, Introductory, Introductory, Temporal tenses: PU and ZI, Vague intervals and non-specific tenses, Event contours: ZAhO and re'u, Tenses as sumtcita, Tenses as sumtcita, Sticky and multiple tenses: KI, Sticky and multiple tenses: KI, Sticky and multiple tenses: KI, Sticky and multiple tenses: KI, Sticky and multiple tenses: KI, Tenses in subordinate bridi, Termset logical connection, Tenses, modals, and logical connection, Tenses, modals, and logical connection, Tenses, modals, and logical connection, The North Wind and the Sun
-
- meaning as a sumtcita: Tenses as sumtcita
- meaning when following interval specification: Interval sizes: VEhA and ZEhA
- pu ge: Tenses, modals, and logical connection
- PU selma'o
-
- compared with FAhA: Temporal tenses: PU and ZI
- contradictory negation of: Tense negation
- for forethought tense connection of sentences: Tense relations between sentences
- negation with NAhE: Tense negation
- PU tenses contrasted with ZAhO tenses in viewpoint: Event contours: ZAhO and re'u
- with "ze'e": Interval properties: TAhE and roi
- pu'a: Modal sentence connection: the causals
- pu'e: Modal sentence connection: the causals
- pu'i: Actuality, potentiality, capability: CAhA, Actuality, potentiality, capability: CAhA, The North Wind and the Sun
- pu'o: Event contours: ZAhO and re'u, Event contours: ZAhO and re'u, Event contours: ZAhO and re'u, Event contours: ZAhO and re'u, Event contours: ZAhO and re'u, Event contours: ZAhO and re'u, Event-type abstractors and event contour tenses, Event-type abstractors and event contour tenses, Event-type abstractors and event contour tenses, Event-type abstractors and event contour tenses, The North Wind and the Sun
-
- as pastward of event: Event contours: ZAhO and re'u
- derivation of word: Event contours: ZAhO and re'u
- explanation of derivation: Event contours: ZAhO and re'u
- pu'u: Types of event abstractions, Types of event abstractions, Event-type abstractors and event contour tenses
-
- place structure: Types of event abstractions
- puba: Sticky and multiple tenses: KI
- pulji: The North Wind and the Sun
- punji: The North Wind and the Sun
- purci: Temporal tenses: PU and ZI
- purdi: The North Wind and the Sun
- py.: A to Z in Lojban, plus one, Proposed lerfu words for the Greek alphabet, Proposed lerfu words for the Cyrillic alphabet, Proposed lerfu words for the Hebrew alphabet
R
- ra: sumti qualifiers, Pro-sumti summary, Anaphoric pro-sumti and pro-bridi: the ri-series and the go'i-series, Anaphoric pro-sumti and pro-bridi: the ri-series and the go'i-series, Anaphoric pro-sumti and pro-bridi: the ri-series and the go'i-series, Anaphoric pro-sumti and pro-bridi: the ri-series and the go'i-series, Anaphoric pro-sumti and pro-bridi: the ri-series and the go'i-series, Anaphoric pro-sumti and pro-bridi: the ri-series and the go'i-series, Anaphoric pro-sumti and pro-bridi: the ri-series and the go'i-series, Anaphoric pro-sumti and pro-bridi: the ri-series and the go'i-series, Anaphoric pro-sumti and pro-bridi: the ri-series and the go'i-series, Anaphoric pro-sumti and pro-bridi: the ri-series and the go'i-series, Anaphoric pro-sumti and pro-bridi: the ri-series and the go'i-series, Anaphoric pro-sumti and pro-bridi: the ri-series and the go'i-series
- ra'a: Modal sentence connection: the causals, Complete table of BAI cmavo with rough English equivalents
- ra'e: Signs and numerical punctuation
- ra'i: Modal sentence connection: the causals, Complete table of BAI cmavo with rough English equivalents
- ra'o: Anaphoric pro-sumti and pro-bridi: the ri-series and the go'i-series, Anaphoric pro-sumti and pro-bridi: the ri-series and the go'i-series, Anaphoric pro-sumti and pro-bridi: the ri-series and the go'i-series
- ra'u: Discursives, Discursives, Discursives
-
- scale of importance: Discursives
- ra'ucu'i: Discursives
- ra'unai: Discursives
- ractu: The North Wind and the Sun
- radno: Cultural and other non-algorithmic gismu
- rafsi: Lojban grammatical terms, gismu, lujvo
- rai: Modal sentence connection: the causals, The North Wind and the Sun
- rakso: Cultural and other non-algorithmic gismu
- raktu: The North Wind and the Sun
- ralju: cmevla
- ranji: The North Wind and the Sun
- rarna: The North Wind and the Sun
- ratcu: The North Wind and the Sun
- rau: Attitudinal modifiers, Indefinite numbers, Indefinite numbers, Special mekso selbri
- re: cmavo, cmavo, cmavo, Quantified sumti, Quantified sumti, Quantified sumti, Quantified sumti, sumti-based descriptions, Relative clauses and descriptors, Other modal connections, Non-logical connectives, Proposed lerfu words for some accent marks and multiple letters, Forethought operators (Polish notation, functions), Approximation and inexact numbers, Reverse Polish notation, Reverse Polish notation, The North Wind and the Sun
- re'i: Vocative scales
- re'inai: Vocative scales
- re'o: List of spatial directions and direction-like relations, The North Wind and the Sun
- re'u: Event contours: ZAhO and re'u
- remai: The North Wind and the Sun
- remei: The North Wind and the Sun
- remna: The North Wind and the Sun
- rere'u: The North Wind and the Sun
- reroi: Sub-events
- retsku: The North Wind and the Sun
- ri: sumti qualifiers, sumti qualifiers, sumti qualifiers, sumti qualifiers, Pro-sumti summary, Anaphoric pro-sumti and pro-bridi: the ri-series and the go'i-series, Anaphoric pro-sumti and pro-bridi: the ri-series and the go'i-series, Anaphoric pro-sumti and pro-bridi: the ri-series and the go'i-series, Anaphoric pro-sumti and pro-bridi: the ri-series and the go'i-series, Anaphoric pro-sumti and pro-bridi: the ri-series and the go'i-series, Anaphoric pro-sumti and pro-bridi: the ri-series and the go'i-series, Anaphoric pro-sumti and pro-bridi: the ri-series and the go'i-series, Anaphoric pro-sumti and pro-bridi: the ri-series and the go'i-series, Anaphoric pro-sumti and pro-bridi: the ri-series and the go'i-series, Anaphoric pro-sumti and pro-bridi: the ri-series and the go'i-series, Anaphoric pro-sumti and pro-bridi: the ri-series and the go'i-series, Anaphoric pro-sumti and pro-bridi: the ri-series and the go'i-series, Anaphoric pro-sumti and pro-bridi: the ri-series and the go'i-series, Anaphoric pro-sumti and pro-bridi: the ri-series and the go'i-series, Anaphoric pro-sumti and pro-bridi: the ri-series and the go'i-series, Anaphoric pro-sumti and pro-bridi: the ri-series and the go'i-series, Anaphoric pro-sumti and pro-bridi: the ri-series and the go'i-series, Anaphoric pro-sumti and pro-bridi: the ri-series and the go'i-series, Anaphoric pro-sumti and pro-bridi: the ri-series and the go'i-series, Anaphoric pro-sumti and pro-bridi: the ri-series and the go'i-series, Anaphoric pro-sumti and pro-bridi: the ri-series and the go'i-series, Relativized pro-sumti: ke'a, Topic-comment sentences: ZOhU, Quotations: LU, LIhU, LOhU, LEhU, Quotations: LU, LIhU, LOhU, LEhU, Quotations: LU, LIhU, LOhU, LEhU, The North Wind and the Sun
-
- contrasted with "ke'a" in relative clauses: Relativized pro-sumti: ke'a
- ri'a: Modal sentence connection: the causals, Modal sentence connection: the causals, Modal sentence connection: the causals, Modal sentence connection: the causals, Modal negation, The North Wind and the Sun
- ri'e: Attitudinal modifiers, Attitudinal modifiers
- ri'enai: Attitudinal modifiers
- ri'i: Modal sentence connection: the causals
- ri'u: List of spatial directions and direction-like relations
- ri-series
-
- pro-sumti: Anaphoric pro-sumti and pro-bridi: the ri-series and the go'i-series
- pro-sumti in narrative about quotation: Anaphoric pro-sumti and pro-bridi: the ri-series and the go'i-series
- pro-sumti in quotation series: Anaphoric pro-sumti and pro-bridi: the ri-series and the go'i-series
- pro-sumti in quotations: Anaphoric pro-sumti and pro-bridi: the ri-series and the go'i-series
- ricfu: Compound bridi
- rigni: The North Wind and the Sun
- rinka: Modal sentence connection: the causals, Modal sentence connection: the causals, Other modal connections, Lojban sumti raising, Implicit-abstraction lujvo, Implicit-abstraction lujvo, Notes on gismu place structures, Notes on gismu place structures, Forethought bridi connection, The North Wind and the Sun
- rirxe: The North Wind and the Sun
- risna: Miscellaneous indicators
- ro: Quantified sumti, Quantified sumti, Quantified sumti, Quantified sumti, Quantified descriptions, Quantified descriptions, Quantified descriptions, sumti-based descriptions, Pro-sumti summary, Pro-sumti summary, Pro-sumti summary, Pro-sumti summary, Pro-sumti summary, Relative clauses and descriptors, Relative clauses and descriptors, Universal claims, Universal claims, Universal claims, Dropping the prenex, Dropping the prenex, Dropping the prenex, Variables with generalized quantifiers, Variables with generalized quantifiers, Variables with generalized quantifiers, Grouping of quantifiers, Grouping of quantifiers, Grouping of quantifiers, Negation boundaries, bridi negation and logical connectives, lerfu words as pro-sumti, Indefinite numbers, Indefinite numbers, Indefinite numbers, Indefinite numbers, Indefinite numbers, Approximation and inexact numbers, Miscellany, The North Wind and the Sun
-
- dropping from multiple appearances on logical variables: Dropping the prenex
- effect of order when multiple in sentence: Grouping of quantifiers
- ro'a: The North Wind and the Sun
- ro'anai: Emotional categories
-
- example: Emotional categories
- ro'e: Emotional categories
- ro'o: Attitudinal modifiers, More about non-logical connectives
- ro'u: Compound indicators
- roi: Interval properties: TAhE and roi, Interval properties: TAhE and roi, Other uses of mekso, The North Wind and the Sun
- ROI selma'o
-
- effect of ZAhO on "fe'e" flag: Space interval modifiers: FEhE
- exception on use of "boi" before: Other uses of mekso
- scalar negation of: Tense negation
- romai: Utterance ordinals: MAI
- ropno: Cultural and other non-algorithmic gismu
- ru: Pro-sumti summary, Anaphoric pro-sumti and pro-bridi: the ri-series and the go'i-series, Anaphoric pro-sumti and pro-bridi: the ri-series and the go'i-series, Anaphoric pro-sumti and pro-bridi: the ri-series and the go'i-series, Anaphoric pro-sumti and pro-bridi: the ri-series and the go'i-series, Anaphoric pro-sumti and pro-bridi: the ri-series and the go'i-series, Anaphoric pro-sumti and pro-bridi: the ri-series and the go'i-series, Anaphoric pro-sumti and pro-bridi: the ri-series and the go'i-series, Anaphoric pro-sumti and pro-bridi: the ri-series and the go'i-series, Anaphoric pro-sumti and pro-bridi: the ri-series and the go'i-series, The North Wind and the Sun
- ru'a: Indicators, Evidentials
-
- compared with ".e'u": Evidentials
- ru'e: Attitudes as scales
- ru'i: Interval properties: TAhE and roi, Interval properties: TAhE and roi
- ru'inai: Interval properties: TAhE and roi
- ru'o: Alien alphabets
- ru'u: List of spatial directions and direction-like relations, The North Wind and the Sun
- ruble: Attitudes as scales
- rusko: Cultural and other non-algorithmic gismu
- rutrceraso: The North Wind and the Sun
- ry.: A to Z in Lojban, plus one, Proposed lerfu words for the Greek alphabet, Proposed lerfu words for the Cyrillic alphabet, Proposed lerfu words for the Hebrew alphabet
S
- sa: The uses of indicators, The universal bu, Quotations: LU, LIhU, LOhU, LEhU, Erasure: SI, SA, SU, Erasure: SI, SA, SU, Erasure: SI, SA, SU, Erasure: SI, SA, SU, Erasure: SI, SA, SU, Erasure: SI, SA, SU, Erasure: SI, SA, SU, List of cmavo interactions, List of cmavo interactions, List of cmavo interactions, List of cmavo interactions, List of cmavo interactions, List of cmavo interactions
-
- interaction with "bu": The universal bu
- sa'a: Miscellaneous indicators, Miscellaneous indicators, Metalinguistic negation forms, Parenthesis and metalinguistic commentary: TO, TOI, SEI, Parenthesis and metalinguistic commentary: TO, TOI, SEI, Parenthesis and metalinguistic commentary: TO, TOI, SEI
-
- editorial insertion of text already containing "sa'a": Miscellaneous indicators
- interaction with "li'o": Miscellaneous indicators
- interaction with "sei": Miscellaneous indicators
- interaction with "to'i": Miscellaneous indicators
- sa'enai: Discursives
- sa'i: Vectors and matrices, Vectors and matrices, Vectors and matrices
- sa'unai: Discursives
- sadjo: Cultural and other non-algorithmic gismu
- sai: More about non-logical connectives, The North Wind and the Sun
- sakli: rafsi, rafsi
- sakta: The North Wind and the Sun
- salci: rafsi
- salpo: The North Wind and the Sun
- sampu: The North Wind and the Sun
- sance: The North Wind and the Sun
- sanga: The North Wind and the Sun
- sanji: The North Wind and the Sun
- sanli: Interval connectives and forethought non-logical connection, Interval connectives and forethought non-logical connection, The North Wind and the Sun
- sanmi: The North Wind and the Sun
- saske: fu'ivla
- sau: Modal sentence connection: the causals
- savru: The North Wind and the Sun
- se: Varying the order of sumti, Varying the order of sumti, Description sumti, Orthography, Conversion of simple selbri, Conversion of simple selbri, Conversion: SE, Modal tags: BAI, Modal tags: BAI, Modal selbri, Modal relative phrases; Comparison, Complete table of BAI cmavo with rough English equivalents, Why have lujvo?, Eliding SE rafsi from tertau, Eliding SE rafsi from tertau, Eliding KE and KEhE rafsi from lujvo, Eliding KE and KEhE rafsi from lujvo, Eliding KE and KEhE rafsi from lujvo, The six types of logical connectives, Logical connection of bridi, Logical connection of bridi, Logical connection of bridi, Logical connection of bridi, Forethought bridi connection, sumti connection, Compound bridi, Logical connection within tanru, Logical connection within tanru, Non-logical connectives, Non-logical connectives, Non-logical connectives, Non-logical connectives, Interval connectives and forethought non-logical connection, Interval connectives and forethought non-logical connection, Interval connectives and forethought non-logical connection, Interval connectives and forethought non-logical connection, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Truth functions and corresponding logical connectives, Rules for making logical and non-logical connectives, Rules for making logical and non-logical connectives, Rules for making logical and non-logical connectives, Rules for making logical and non-logical connectives, Dropping the prenex, Dropping the prenex, Using naku outside a prenex, Using naku outside a prenex, Using naku outside a prenex, Logical connectives and DeMorgan's law, Logical connectives and DeMorgan's law, Special mekso selbri, Miscellany, Subscripts: XI, The North Wind and the Sun
-
- as grammatical in JOI compounds: Non-logical connectives
- in logical connective to exchange sentences: Logical connection of bridi
- order in logical connectives with "na": Logical connection of bridi
- use with operators: Miscellany
- using to re-order logical variables: Dropping the prenex
- writing convention in eks: sumti connection
- se du'u: Predication/sentence abstraction
- se klama
-
- place structure of: Conversion: SE
- SE selma'o
-
- after 5th place: Subscripts: XI, Subscripts: XI
- compared with JAI and "fai": Conversion of sumtcita: JAI
- effect on place structure numbering: Conversion: SE
- effect on selbri place structure: Conversion: SE
- extending scope of: Conversion: SE
- for BAI selma'o: Modal conversion: JAI
- for converting place structure: Conversion: SE
- introduction to conversion: Conversion of simple selbri
- ordering of multiple SE and effect on a selbri: Conversion: SE
- rationale for no 1st place conversion: Conversion: SE
- scope of: Conversion: SE
- word formation of cmavo in: Conversion: SE
- se te: Conversion: SE
- se'a: Attitudinal modifiers
- se'e: Computerized character codes, Computerized character codes, Computerized character codes
-
- and number base convention: Computerized character codes
- se'i: Attitudinal modifiers, The North Wind and the Sun
- se'o: Evidentials, Evidentials
- se'u: Reflexive and reciprocal pro-sumti: the vo'a-series, Reflexive and reciprocal pro-sumti: the vo'a-series, Parenthesis and metalinguistic commentary: TO, TOI, SEI, Parenthesis and metalinguistic commentary: TO, TOI, SEI
-
- as elidable terminator for "soi": Reflexive and reciprocal pro-sumti: the vo'a-series
- elidability considerations: Reflexive and reciprocal pro-sumti: the vo'a-series
- seba'i: Modal relative phrases; Comparison
- sedu'u: The North Wind and the Sun
- sei: Miscellaneous indicators, Tentative conclusion, Explicit operator precedence, Parenthesis and metalinguistic commentary: TO, TOI, SEI, Parenthesis and metalinguistic commentary: TO, TOI, SEI, Parenthesis and metalinguistic commentary: TO, TOI, SEI, Parenthesis and metalinguistic commentary: TO, TOI, SEI, Parenthesis and metalinguistic commentary: TO, TOI, SEI, Parenthesis and metalinguistic commentary: TO, TOI, SEI, Parenthesis and metalinguistic commentary: TO, TOI, SEI, Parenthesis and metalinguistic commentary: TO, TOI, SEI, The North Wind and the Sun
- seja'e: Modal sentence connection: the causals
- seja'eku: The North Wind and the Sun
- seka'a: Modal tags: BAI
- sela'u: The North Wind and the Sun
- selbri: The concept of the bridi, The concept of the bridi, Lojban grammatical terms, Introductory
- selkla: Eliding KE and KEhE rafsi from lujvo, Eliding KE and KEhE rafsi from lujvo
- selma'o: Lojban grammatical terms, cmavo
- selsku: Anomalous lujvo
- seltau: Simple tanru, The meaning of tanru: a necessary detour, The meaning of tanru: a necessary detour
- selti'i: Eliding SE rafsi from seltau, Eliding SE rafsi from seltau
- selti'ifla: Eliding SE rafsi from seltau, Eliding SE rafsi from seltau
- semau: Modal relative phrases; Comparison, Modal relative phrases; Comparison, Modal relative phrases; Comparison
- seme'a: Modal relative phrases; Comparison, Modal relative phrases; Comparison
- semto: Cultural and other non-algorithmic gismu
- semu'ibo: The North Wind and the Sun
- senva: The North Wind and the Sun
- sepi'o: Modal tags: BAI, Modal tags: BAI
- seri'a: Modal sentence connection: the causals
- serti: The North Wind and the Sun
- sfofa: IPA for English speakers
- si: The uses of indicators, The universal bu, Quotations: LU, LIhU, LOhU, LEhU, More on quotations: ZO, ZOI, Erasure: SI, SA, SU, Erasure: SI, SA, SU, Erasure: SI, SA, SU, Erasure: SI, SA, SU, Erasure: SI, SA, SU, Erasure: SI, SA, SU, Erasure: SI, SA, SU, Erasure: SI, SA, SU, Erasure: SI, SA, SU, Erasure: SI, SA, SU, Erasure: SI, SA, SU, Erasure: SI, SA, SU, Erasure: SI, SA, SU, Erasure: SI, SA, SU, Erasure: SI, SA, SU, Erasure: SI, SA, SU, Erasure: SI, SA, SU, List of cmavo interactions, List of cmavo interactions, List of cmavo interactions, List of cmavo interactions, List of cmavo interactions
-
- interaction with "bu": The universal bu
- si'a: Discursives
- si'e: Special mekso selbri, mekso selma'o summary
- si'o: Minor abstraction types, Minor abstraction types, Minor abstraction types
- si'u: Modal sentence connection: the causals
- siclu: The North Wind and the Sun
- sidju: The North Wind and the Sun
- simlu: The North Wind and the Sun
- simsa: The North Wind and the Sun
- simxu: The North Wind and the Sun
- since: fu'ivla
- sinso: Cultural and other non-algorithmic gismu, Cultural and other non-algorithmic gismu
- sinxa: sumti qualifiers, sumti qualifiers
- sipna: The North Wind and the Sun
- sirji: The North Wind and the Sun
- sirxo: Cultural and other non-algorithmic gismu
- sisti: Metalinguistic negation forms
- skari: Metalinguistic negation forms
- skicu: The North Wind and the Sun
- skoto: Cultural and other non-algorithmic gismu
- slabu: The North Wind and the Sun
- slaka: The universal bu, The universal bu
- sligu: The North Wind and the Sun
- slovo: Cultural and other non-algorithmic gismu
- smacu: The North Wind and the Sun
- smudukti: The North Wind and the Sun
- smuni: The North Wind and the Sun
- snada: The North Wind and the Sun
- so'a: Indefinite numbers, Indefinite numbers, Miscellany
- so'e: Indefinite numbers, Indefinite numbers, Miscellany
- so'i: Indefinite numbers, Miscellany, The North Wind and the Sun
- so'imei: Some types of symmetrical tanru
- so'o: Indefinite numbers, Miscellany, The North Wind and the Sun
- so'u: Indefinite numbers, Miscellany, The North Wind and the Sun
- softo: Cultural and other non-algorithmic gismu
- soi: Reflexive and reciprocal pro-sumti: the vo'a-series, Reflexive and reciprocal pro-sumti: the vo'a-series, Reflexive and reciprocal pro-sumti: the vo'a-series, Reflexive and reciprocal pro-sumti: the vo'a-series, Reflexive and reciprocal pro-sumti: the vo'a-series, Reflexive and reciprocal pro-sumti: the vo'a-series, Reflexive and reciprocal pro-sumti: the vo'a-series
-
- use in expressing reciprocity: Reflexive and reciprocal pro-sumti: the vo'a-series
- use in expressing reciprocity with vo'a-series pro-sumti: Reflexive and reciprocal pro-sumti: the vo'a-series
- with one following sumti; convention: Reflexive and reciprocal pro-sumti: the vo'a-series
- solji: The North Wind and the Sun
- solri: cmevla, The North Wind and the Sun
- solxrula: Some types of asymmetrical tanru
- sonci: Symmetrical and asymmetrical lujvo, Symmetrical and asymmetrical lujvo
- sovda: The North Wind and the Sun
- spageti: fu'ivla
- spaji: The North Wind and the Sun
- spano: Cultural and other non-algorithmic gismu
- spati: The North Wind and the Sun
- spuda: The North Wind and the Sun
- spusku: The North Wind and the Sun
- sraji: The North Wind and the Sun
- sraku: The North Wind and the Sun
- sralo: Cultural and other non-algorithmic gismu, The North Wind and the Sun
- srana: Modal sentence connection: the causals, Complete table of BAI cmavo with rough English equivalents
- srito: Cultural and other non-algorithmic gismu
- sruri: The North Wind and the Sun
- stali: Some words used to indicate selbri relations
- steci: Relative phrases
- stedu: The North Wind and the Sun
- stela: The North Wind and the Sun
- stero: Cultural and other non-algorithmic gismu
- stidi: Eliding SE rafsi from seltau
- stura: Other useful selbri for mekso bridi
- stuzi: The North Wind and the Sun
- su: The uses of indicators, The universal bu, Quotations: LU, LIhU, LOhU, LEhU, Erasure: SI, SA, SU, Erasure: SI, SA, SU, Erasure: SI, SA, SU, List of cmavo interactions, List of cmavo interactions, List of cmavo interactions, List of cmavo interactions, List of cmavo interactions
-
- interaction with "bu": The universal bu
- su'a: Evidentials, Evidentials, Evidentials, Evidentials, Discursives
- su'anai: Evidentials, Evidentials
- su'e: Approximation and inexact numbers, Miscellany, The North Wind and the Sun
-
- with elided number: Approximation and inexact numbers
- su'i: Other kinds of simple selbri, Simple infix expressions and equations, Reverse Polish notation, Reverse Polish notation, Other uses of mekso, Four score and seven: a mekso problem
- su'o: Quantified sumti, Quantified sumti, Quantified sumti, Quantified descriptions, Quantified descriptions, Lojban names, Pro-sumti summary, Pro-sumti summary, Pro-sumti summary, Pro-sumti summary, Quotation summary, Number summary, Relative clauses and descriptors, Variables with generalized quantifiers, Variables with generalized quantifiers, Variables with generalized quantifiers, Variables with generalized quantifiers, Variables with generalized quantifiers, Grouping of quantifiers, Grouping of quantifiers, Negation boundaries, selbri variables, selbri variables, Approximation and inexact numbers, Approximation and inexact numbers, Miscellany, The North Wind and the Sun
-
- as implicit quantifier for quotations: Quantified sumti
- with elided number: Approximation and inexact numbers
- su'oroi: The North Wind and the Sun
- su'u: Minor abstraction types, Minor abstraction types, Minor abstraction types, Minor abstraction types, Minor abstraction types, Minor abstraction types
- sudga: The North Wind and the Sun
- sudysrasu: Some types of asymmetrical tanru, Some types of symmetrical tanru
- suksa: The North Wind and the Sun
- sumti: The concept of the bridi, The concept of the bridi, Lojban grammatical terms, Introductory
- sunsicyjudri: The North Wind and the Sun
- sutra: Some words used to indicate selbri relations, Simple tanru, Simple tanru, Inversion of tanru: co, Scalar negation of selbri, Scalar negation of selbri, The North Wind and the Sun
- sy.: brivla, A to Z in Lojban, plus one, Proposed lerfu words for the Greek alphabet, Proposed lerfu words for the Cyrillic alphabet
T
- ta: Words that can act as sumti, Pro-sumti summary, Demonstrative pro-sumti: the ti-series, Demonstrative pro-sumti: the ti-series, Demonstrative pro-sumti: the ti-series, Demonstrative pro-sumti: the ti-series, Utterance pro-sumti: the di'u-series, Utterance pro-sumti: the di'u-series, What are you pointing at?, Spatial tenses: FAhA and VA
-
- contrasted with "di'u": Utterance pro-sumti: the di'u-series
- ta'e: Interval properties: TAhE and roi, bridi negation, The North Wind and the Sun
- ta'eku: The North Wind and the Sun
- ta'i: Modal sentence connection: the causals, The North Wind and the Sun
- ta'o: The North Wind and the Sun
- ta'onai: Discursives
- ta'u: Discursives, Discursives, Discursives
- ta'unai: Discursives
- tadji: The North Wind and the Sun
- tagji: The North Wind and the Sun
- TAhE selma'o
-
- effect of ZAhO on "fe'e" flag: Space interval modifiers: FEhE
- scalar negation of: Tense negation
- tai: Modal sentence connection: the causals, Complete table of BAI cmavo with rough English equivalents, The North Wind and the Sun
- tamdu'i: Other useful selbri for mekso bridi
- tamsmi: Complete table of BAI cmavo with rough English equivalents, Complete table of BAI cmavo with rough English equivalents
- tanjo: Cultural and other non-algorithmic gismu, Cultural and other non-algorithmic gismu, Using Lojban resources within mekso
- tanru: tanru, Lojban grammatical terms, Simple tanru
- tarmi: fu'ivla, Complete table of BAI cmavo with rough English equivalents, Other useful selbri for mekso bridi
- tatpi: The North Wind and the Sun
- tau: Upper and lower cases, Upper and lower cases, Upper and lower cases
- tavla: Some words used to indicate selbri relations, Some simple Lojban bridi, tanru, Description sumti, The North Wind and the Sun
- tcadu: The North Wind and the Sun
- tcidu: The North Wind and the Sun
- tcika: The North Wind and the Sun
- tcita: The North Wind and the Sun
- te: Varying the order of sumti, Varying the order of sumti, Description sumti, Conversion of simple selbri, Complete table of BAI cmavo with rough English equivalents, The North Wind and the Sun
- te'a: Simple infix expressions and equations
- te'e: List of spatial directions and direction-like relations
- te'o: Special numbers, Approximation and inexact numbers
- te'u: Vectors and matrices, Using Lojban resources within mekso, Miscellany, Four score and seven: a mekso problem
- teci'e: Expressing scales in selbri negation
- tei: Accent marks and compound lerfu words, Accent marks and compound lerfu words, Accent marks and compound lerfu words, What about Chinese characters?, List of all auxiliary lerfu-word cmavo
- teka'a: Modal tags: BAI
- tense selma'o
-
- summary of: Summary of tense selma'o
- terbi'a: Some types of asymmetrical tanru
- terdi: The North Wind and the Sun
- tergu'i: Some types of asymmetrical tanru
- terkavbu: Some types of asymmetrical tanru
- terpa: The North Wind and the Sun
- tertau: Simple tanru, The meaning of tanru: a necessary detour, The meaning of tanru: a necessary detour
- terto: Cultural and other non-algorithmic gismu
- tezu'e: Modal sentence connection: the causals
- ti: Words that can act as sumti, Tenses, The five kinds of simple sumti, Pro-sumti summary, Demonstrative pro-sumti: the ti-series, Demonstrative pro-sumti: the ti-series, Demonstrative pro-sumti: the ti-series, Utterance pro-sumti: the di'u-series, Anaphoric pro-sumti and pro-bridi: the ri-series and the go'i-series, What are you pointing at?, What are you pointing at?, What are you pointing at?, What are you pointing at?, Non-veridical relative clauses: voi, Spatial tenses: FAhA and VA, The North Wind and the Sun
-
- as pronoun expression for English this: Demonstrative pro-sumti: the ti-series
- ti noi
-
- as adjective expression for this: Demonstrative pro-sumti: the ti-series
- ti'a: List of spatial directions and direction-like relations
- ti'e: Evidentials, Evidentials
- ti'i: Modal sentence connection: the causals
- ti'o: Explicit operator precedence, Explicit operator precedence, Explicit operator precedence
- ti'otci: Some types of asymmetrical tanru
- ti'u: Modal sentence connection: the causals
- ti-series
-
- 3 degrees of distance with pro-sumti: Demonstrative pro-sumti: the ti-series
- contrasted with di'u-series pro-sumti: Utterance pro-sumti: the di'u-series
- conversational convention for pro-sumti: Demonstrative pro-sumti: the ti-series
- pro-sumti and lack of pro-bridi equivalent: Demonstrative pro-sumti: the ti-series
- pro-sumti as pointing referents only: Demonstrative pro-sumti: the ti-series
- pro-sumti compared with English this/that: Demonstrative pro-sumti: the ti-series
- problems in written text: Demonstrative pro-sumti: the ti-series
- tinju'i: Symmetrical and asymmetrical lujvo
- tirna: Symmetrical and asymmetrical lujvo, Symmetrical and asymmetrical lujvo, The North Wind and the Sun
- tirxu: The North Wind and the Sun
- tisna: The North Wind and the Sun
- to: Parenthesis and metalinguistic commentary: TO, TOI, SEI, Parenthesis and metalinguistic commentary: TO, TOI, SEI, The North Wind and the Sun
- to'a: Upper and lower cases, Upper and lower cases
- to'e: Eliding KE and KEhE rafsi from lujvo, Eliding KE and KEhE rafsi from lujvo, Expressing scales in selbri negation, Expressing scales in selbri negation, Expressing scales in selbri negation, Expressing scales in selbri negation, sumti negation
- to'i: Miscellaneous indicators, Parenthesis and metalinguistic commentary: TO, TOI, SEI, Parenthesis and metalinguistic commentary: TO, TOI, SEI
- to'isa'a: The North Wind and the Sun
- to'o: List of spatial directions and direction-like relations, List of spatial directions and direction-like relations, List of spatial directions and direction-like relations, List of spatial directions and direction-like relations, List of spatial directions and direction-like relations, The North Wind and the Sun
-
- special note on direction orientation: List of spatial directions and direction-like relations
- to'u: Discursives
- toi: Parenthesis and metalinguistic commentary: TO, TOI, SEI, The North Wind and the Sun
- tolcanci: The North Wind and the Sun
- tolmle: Expressing scales in selbri negation
- tolpu'i: The North Wind and the Sun
- tolvri: Some types of symmetrical tanru
- tordu: The North Wind and the Sun
- traji: Comparatives and superlatives, Comparatives and superlatives, Comparatives and superlatives, Comparatives and superlatives, Comparatives and superlatives, Comparatives and superlatives, Comparatives and superlatives, Comparatives and superlatives, The North Wind and the Sun
- tricu: fu'ivla, The North Wind and the Sun
- trixe: The North Wind and the Sun
- troci: Inversion of tanru: co, Inversion of tanru: co, The North Wind and the Sun
- tsali: Attitudes as scales
- tu: Words that can act as sumti, Pro-sumti summary, Demonstrative pro-sumti: the ti-series, Demonstrative pro-sumti: the ti-series, Demonstrative pro-sumti: the ti-series, Utterance pro-sumti: the di'u-series, What are you pointing at?, Spatial tenses: FAhA and VA
-
- archaic English yon as equivalent of: Demonstrative pro-sumti: the ti-series
- tu'a: sumti qualifiers, Lojban sumti raising, Lojban sumti raising, Lojban sumti raising, Lojban sumti raising, Lojban sumti raising, Lojban sumti raising, The North Wind and the Sun
-
- as being deliberately vague: sumti qualifiers
- effect of on meaning: sumti qualifiers
- use for forming abstractions: sumti qualifiers
- tu'e: Modal selbri, Mixed modal connection, Mixed modal connection, Mixed modal connection, Tensed logical connectives, Grouping of afterthought connectives, Grouping of afterthought connectives, Grouping of afterthought connectives, Grouping of afterthought connectives, More about non-logical connectives, Tenses, modals, and logical connection, Tenses, modals, and logical connection, Tenses, modals, and logical connection, A few notes on variables, Sentences: I, Sentences: I, Sentences: I, Sentences: I, Topic-comment sentences: ZOhU
-
- contrasted with "bo" for tensed logical connection: Tenses, modals, and logical connection
- effect on "di'e": More about non-logical connectives
- use in lists: More about non-logical connectives
- tu'i: Modal sentence connection: the causals
- tu'o: Infix operators revisited, Infix operators revisited, Reverse Polish notation, Reverse Polish notation
-
- for infix operations with too few operands: Infix operators revisited
- tu'u: Modal selbri, Mixed modal connection, Mixed modal connection, Mixed modal connection, Tensed logical connectives, Grouping of afterthought connectives, Grouping of afterthought connectives, Grouping of afterthought connectives, Grouping of afterthought connectives, More about non-logical connectives, A few notes on variables, A few notes on variables, Sentences: I, Sentences: I, Sentences: I, Sentences: I, Topic-comment sentences: ZOhU
- tubnu: The North Wind and the Sun
- tugni: The North Wind and the Sun
- tumla: The North Wind and the Sun
- tunta: The North Wind and the Sun
- tuple: The North Wind and the Sun
- ty.: A to Z in Lojban, plus one, Alien alphabets, Alien alphabets, Proposed lerfu words for the Greek alphabet, Proposed lerfu words for the Cyrillic alphabet, Proposed lerfu words for the Hebrew alphabet
U
- UI selma'o
-
- introduction: What are attitudinal indicators?
- scope of: Attitude scope markers: FUhE/FUhO
V
- va: Spatial tenses: FAhA and VA, Spatial tenses: FAhA and VA, The North Wind and the Sun
- VA selma'o
-
- and distance: Spatial tenses: FAhA and VA
- relation of words to "ti"
-
- ta, tu: Spatial tenses: FAhA and VA
- va'a: Forethought operators (Polish notation, functions), Forethought operators (Polish notation, functions), Forethought operators (Polish notation, functions), Forethought operators (Polish notation, functions), Forethought operators (Polish notation, functions), Infix operators revisited, Infix operators revisited, Reverse Polish notation, Other uses of mekso
- va'e: Special mekso selbri, The North Wind and the Sun
- va'i: Discursives, Discursives, Discursives, Discursives, Discursives, Discursives
-
- contrasted with "ke'u": Discursives
- va'inai: Discursives, Discursives, Discursives
- va'o: Modal sentence connection: the causals, The North Wind and the Sun
- va'u: Modal sentence connection: the causals, The North Wind and the Sun
- vacri: The North Wind and the Sun
- vajni: The North Wind and the Sun
- valsi: The North Wind and the Sun
- vanci: The North Wind and the Sun
- vasru: The North Wind and the Sun
- vau: Relative clauses and descriptors, Possessive sumti, Other modal connections, Other modal connections, The syntax of abstraction, Compound bridi, Compound bridi, Compound bridi, Compound bridi, Compound bridi, Restricted claims: da poi, Questions and answers, Attitude scope markers: FUhE/FUhO, The North Wind and the Sun
-
- avoiding for shared bridi-tail sumti: Other modal connections
- effect on elidability of "ku'o": Possessive sumti
- ve: Varying the order of sumti, Varying the order of sumti, Conversion of simple selbri, Complete table of BAI cmavo with rough English equivalents
- ve klama: Conversion: SE
-
- contrasted with "pluta": Conversion: SE
- ve'a: Interval sizes: VEhA and ZEhA, The North Wind and the Sun
- ve'e: Interval properties: TAhE and roi
- ve'i: Interval sizes: VEhA and ZEhA
- ve'o: Other modal connections, Other modal connections, Logical and non-logical connectives within mekso, Logical and non-logical connectives within mekso, Mathematical uses of lerfu strings, Mathematical uses of lerfu strings, Simple infix expressions and equations, Simple infix expressions and equations, Forethought operators (Polish notation, functions), Forethought operators (Polish notation, functions)
- ve'u: Interval sizes: VEhA and ZEhA
- vecnu: Some words used to indicate selbri relations, Description sumti, Modal tags: BAI
- vei: Other modal connections, Logical and non-logical connectives within mekso, Mathematical uses of lerfu strings, Simple infix expressions and equations, Forethought operators (Polish notation, functions), Forethought operators (Polish notation, functions)
- veka'a: Modal tags: BAI
- veljvo: The meaning of tanru: a necessary detour
- vemau: Comparatives and superlatives
- veme'a: Comparatives and superlatives
- vensa: The North Wind and the Sun
- verba: The North Wind and the Sun
- vi: Tenses, Tenses, Spatial tenses: FAhA and VA, Compound spatial tenses, The North Wind and the Sun
-
- as adjective expression for English this: Demonstrative pro-sumti: the ti-series
- vi'a: Dimensionality: VIhA
- vi'e: Dimensionality: VIhA, Dimensionality: VIhA
- vi'i: The North Wind and the Sun
- vi'o
-
- contrasted with "je'e": Vocative scales
- vi'u: Dimensionality: VIhA
- vikmi: The North Wind and the Sun
- vindu: The North Wind and the Sun
- vinji: The North Wind and the Sun
- virnu: The North Wind and the Sun
- viska: Modal places: FIhO, FEhU, Modal places: FIhO, FEhU, Modal places: FIhO, FEhU, Modal places: FIhO, FEhU, The North Wind and the Sun
- vlipa: The North Wind and the Sun
- vo: Quantified sumti, What about Chinese characters?, Reverse Polish notation, The North Wind and the Sun
- vo'a: Pro-sumti summary, Reflexive and reciprocal pro-sumti: the vo'a-series
- vo'a-series
-
- pro-sumti use in expressing reciprocity with "soi": Reflexive and reciprocal pro-sumti: the vo'a-series
- referring to individual sumti of a bridi: Inversion of tanru: co
- vo'e: Pro-sumti summary, Reflexive and reciprocal pro-sumti: the vo'a-series
- vo'i: Pro-sumti summary
- vo'o: Pro-sumti summary
- vo'u: Pro-sumti summary
- vofli: The North Wind and the Sun
- voi: Non-veridical relative clauses: voi, Non-veridical relative clauses: voi, Non-veridical relative clauses: voi, Non-veridical relative clauses: voi, The North Wind and the Sun
- vorme: Lojban sumti raising, The North Wind and the Sun
- vreji: The North Wind and the Sun
- vrusi: The North Wind and the Sun
- vu: Tenses, Spatial tenses: FAhA and VA, The North Wind and the Sun
- vu'a: List of spatial directions and direction-like relations
- vu'e: Attitudinal modifiers
- vu'i: sumti qualifiers, The North Wind and the Sun
-
- effect of on meaning: sumti qualifiers
- use for creating sequence: sumti qualifiers
- vu'o: Relative clauses and complex sumti: vu'o, Relative clauses and complex sumti: vu'o, The North Wind and the Sun
- vu'u: Forethought operators (Polish notation, functions), Forethought operators (Polish notation, functions)
- VUhU selma'o
-
- operands: Simple infix expressions and equations
- vukro: Cultural and other non-algorithmic gismu
- vy.: A to Z in Lojban, plus one, Proposed lerfu words for the Cyrillic alphabet, Proposed lerfu words for the Hebrew alphabet, The North Wind and the Sun
X
- xabju: The North Wind and the Sun
- xagmau: Comparatives and superlatives
- xagrai: Comparatives and superlatives
- xajmi: The North Wind and the Sun
- xalbo: The North Wind and the Sun
- xamgu: Linked sumti: be - bei - be'o, Linked sumti: be - bei - be'o, Linked sumti: be - bei - be'o, Comparatives and superlatives, The North Wind and the Sun
- xampo: Cultural and other non-algorithmic gismu
- xamsi: The North Wind and the Sun
- xance: Anomalous lujvo, The North Wind and the Sun
- xanka: The North Wind and the Sun
- xanri: The North Wind and the Sun
- xanto: The North Wind and the Sun
- xarci: lujvo with more than two parts., The North Wind and the Sun
- xatsi: Cultural and other non-algorithmic gismu
- xazdo: Cultural and other non-algorithmic gismu
- xe: Varying the order of sumti, Varying the order of sumti, Conversion of simple selbri, Complete table of BAI cmavo with rough English equivalents, Subscripts: XI
- xebro: Cultural and other non-algorithmic gismu
- xecto: Cultural and other non-algorithmic gismu
- xeka'a: Modal tags: BAI
- xekri: Notes on gismu place structures, Notes on gismu place structures
- xelso: Cultural and other non-algorithmic gismu
- xexso: Cultural and other non-algorithmic gismu
- xi: Logical and non-logical connectives within mekso, A few notes on variables, Mathematical uses of lerfu strings, Subscripts, Subscripts, Vectors and matrices, Subscripts: XI
- xindo: Cultural and other non-algorithmic gismu
- xirnzebra: The North Wind and the Sun
- xispo: Cultural and other non-algorithmic gismu
- xo: Number questions, Number questions, Number questions, Questions and answers, The North Wind and the Sun
- xokau: The North Wind and the Sun
- xrabo: Cultural and other non-algorithmic gismu
- xrani: The North Wind and the Sun
- xriso: Cultural and other non-algorithmic gismu
- xruki: The North Wind and the Sun
- xrula: The North Wind and the Sun
- xu: The basic structure of longer utterances, Questions, Questions, Miscellaneous indicators, Miscellaneous indicators, Miscellaneous indicators, Truth questions and connective questions, Truth questions and connective questions, Truth questions, Metalinguistic negation forms, Questions and answers, The North Wind and the Sun
- xu go'i
-
- quick-tour version: Questions
- xunblabi: The North Wind and the Sun
- xunre: Logical connection within tanru, Expressing scales in selbri negation, The North Wind and the Sun
- xurdo: Cultural and other non-algorithmic gismu
- xy.: A to Z in Lojban, plus one, lerfu words as pro-sumti, Mathematical uses of lerfu strings, Proposed lerfu words for the Cyrillic alphabet, Forethought operators (Polish notation, functions), Forethought operators (Polish notation, functions), Subscripts: XI
Z
- za: The North Wind and the Sun
- za'a: Indicators, Evidentials, The North Wind and the Sun
- za'e: Considerations for making lujvo, The universal bu, Contrastive emphasis: BAhE, Contrastive emphasis: BAhE
-
- interaction with "bu": The universal bu
- use to avoid lujvo misunderstandings: Considerations for making lujvo
- za'i: Types of event abstractions, Types of event abstractions, Event-type abstractors and event contour tenses
-
- place structure: Types of event abstractions
- za'o: Event contours: ZAhO and re'u, Event-type abstractors and event contour tenses, Event-type abstractors and event contour tenses, The North Wind and the Sun
- za'u: Approximation and inexact numbers, The North Wind and the Sun
-
- with elided number: Approximation and inexact numbers
- za'ure'u: The North Wind and the Sun
- zabna: Attitudinal modifiers
- ZAhO selma'o: Tenses as sumtcita
-
- contradictory negation of: Tense negation
- effect on "fe'e" flag for TAhE and ROI: Space interval modifiers: FEhE
- for expressing spatial contours: Space interval modifiers: FEhE
- zai: Alien alphabets, Punctuation marks
- zarci: Some words used to indicate selbri relations, The three basic description types, The three basic description types, The North Wind and the Sun
- zau: Modal sentence connection: the causals
- zbasu: Indefinite pro-sumti and pro-bridi: the zo'e-series and the co'e-series, The North Wind and the Sun
- zdani: lujvo-making examples, lujvo-making examples, Linked sumti: be - bei - be'o, Linked sumti: be - bei - be'o, Inversion of tanru: co, Inversion of tanru: co, Conversion: SE, Conversion: SE, Conversion: SE, The meaning of tanru: a necessary detour, The meaning of tanru: a necessary detour, The meaning of tanru: a necessary detour, The meaning of tanru: a necessary detour, The meaning of tanru: a necessary detour, The meaning of tanru: a necessary detour, The meaning of tanru: a necessary detour, The meaning of tanru: a necessary detour, The meaning of lujvo, The meaning of lujvo, The meaning of lujvo, The meaning of lujvo, The meaning of lujvo, Symmetrical and asymmetrical lujvo, Dependent places, Eliding SE rafsi from tertau, Erasure: SI, SA, SU, The North Wind and the Sun
- ze'a: Interval sizes: VEhA and ZEhA, The North Wind and the Sun
- ze'e: Interval properties: TAhE and roi, Interval properties: TAhE and roi, Interval properties: TAhE and roi, The North Wind and the Sun
-
- effect on following PU direction: Interval properties: TAhE and roi
- ze'eba
-
- meaning of: Interval properties: TAhE and roi
- ze'eca
-
- meaning of: Interval properties: TAhE and roi
- ze'epu
-
- meaning of: Interval properties: TAhE and roi
- ze'i: Interval sizes: VEhA and ZEhA, Interval sizes: VEhA and ZEhA, The North Wind and the Sun
- ze'o: List of spatial directions and direction-like relations, List of spatial directions and direction-like relations, List of spatial directions and direction-like relations, List of spatial directions and direction-like relations, List of spatial directions and direction-like relations
-
- special note on direction orientation: List of spatial directions and direction-like relations
- ze'u: Interval sizes: VEhA and ZEhA
- zei: rafsi, rafsi, rafsi, rafsi, rafsi, rafsi fu'ivla: a proposal, The universal bu, List of cmavo interactions, List of cmavo interactions, List of cmavo interactions, List of cmavo interactions
-
- interaction with "bu": The universal bu
- zenba: Comparatives and superlatives, Comparatives and superlatives, Comparatives and superlatives, The North Wind and the Sun
- zepti: Cultural and other non-algorithmic gismu
- zerle'a: Some types of asymmetrical tanru
- zernerkla: Eliding KE and KEhE rafsi from lujvo
- zetro: Cultural and other non-algorithmic gismu
- zgana: The North Wind and the Sun
- zi: Temporal tenses: PU and ZI, The North Wind and the Sun
- ZI selma'o
-
- compared with VA: Temporal tenses: PU and ZI
- zi'e: Multiple relative clauses: zi'e, Multiple relative clauses: zi'e, Multiple relative clauses: zi'e, Multiple relative clauses: zi'e, Multiple relative clauses: zi'e, Multiple relative clauses: zi'e, The North Wind and the Sun
-
- compared with English and : Multiple relative clauses: zi'e
- contrasted with logical connectives: Multiple relative clauses: zi'e
- use in connecting relative phrase/clause to relative phrase/clause: Multiple relative clauses: zi'e
- zi'o: Pro-sumti summary, Indefinite pro-sumti and pro-bridi: the zo'e-series and the co'e-series, Indefinite pro-sumti and pro-bridi: the zo'e-series and the co'e-series, Indefinite pro-sumti and pro-bridi: the zo'e-series and the co'e-series, Indefinite pro-sumti and pro-bridi: the zo'e-series and the co'e-series, Indefinite pro-sumti and pro-bridi: the zo'e-series and the co'e-series, Indefinite pro-sumti and pro-bridi: the zo'e-series and the co'e-series, lujvo based on pro-sumti, lujvo based on pro-sumti
-
- as creating new selbri: Indefinite pro-sumti and pro-bridi: the zo'e-series and the co'e-series
- rafsi of "zi'o"; effect of on place structure of lujvo: lujvo based on pro-sumti
- zifre: The North Wind and the Sun
- zmadu: rafsi, rafsi, rafsi, Modal relative phrases; Comparison, Modal relative phrases; Comparison, Modal relative phrases; Comparison, Comparatives and superlatives, Comparatives and superlatives, Comparatives and superlatives, Comparatives and superlatives, Comparatives and superlatives, Comparatives and superlatives, Comparatives and superlatives, Comparatives and superlatives, Other useful selbri for mekso bridi, Other useful selbri for mekso bridi, The North Wind and the Sun
- zo: The five kinds of simple sumti, Lojban names, The uses of indicators, The universal bu, References to lerfu, Quotations: LU, LIhU, LOhU, LEhU, More on quotations: ZO, ZOI, More on quotations: ZO, ZOI, More on quotations: ZO, ZOI, More on quotations: ZO, ZOI, More on quotations: ZO, ZOI, More on quotations: ZO, ZOI, Erasure: SI, SA, SU, Erasure: SI, SA, SU, Erasure: SI, SA, SU, Erasure: SI, SA, SU, Erasure: SI, SA, SU, Erasure: SI, SA, SU, Erasure: SI, SA, SU, No more to say: FAhO, List of cmavo interactions, List of cmavo interactions, List of cmavo interactions, List of cmavo interactions, List of cmavo interactions, List of cmavo interactions, List of cmavo interactions, The North Wind and the Sun
-
- interaction with "bu": The universal bu
- zo'a: List of spatial directions and direction-like relations
- zo'e: Some simple Lojban bridi, Some simple Lojban bridi, Variant bridi structure, Pro-sumti summary, Indefinite pro-sumti and pro-bridi: the zo'e-series and the co'e-series, Indefinite pro-sumti and pro-bridi: the zo'e-series and the co'e-series, Indefinite pro-sumti and pro-bridi: the zo'e-series and the co'e-series, Standard bridi form: cu, Standard bridi form: cu, Tagging places: FA, Indirect questions, Indirect questions, Compound bridi, Existential claims, prenexes, and variables, Existential claims, prenexes, and variables
-
- as a translation for "something": Existential claims, prenexes, and variables
- as place-holder for sumti: Indefinite pro-sumti and pro-bridi: the zo'e-series and the co'e-series
- as place-holder for unspecified sumti: Standard bridi form: cu
- compared with FA for omitting places: Tagging places: FA
- contrasted with "da": Existential claims, prenexes, and variables
- zo'e-series
-
- compared with "do'i" as indefinite pro-sumti: Indefinite pro-sumti and pro-bridi: the zo'e-series and the co'e-series
- pro-sumti: Indefinite pro-sumti and pro-bridi: the zo'e-series and the co'e-series
- zo'i: List of spatial directions and direction-like relations, List of spatial directions and direction-like relations, List of spatial directions and direction-like relations, List of spatial directions and direction-like relations, List of spatial directions and direction-like relations
-
- special note on direction orientation: List of spatial directions and direction-like relations
- zo'o: Discursives, Discursives
- zo'u: Relative clauses within relative clauses, Existential claims, prenexes, and variables, Topic-comment sentences: ZOhU, Topic-comment sentences: ZOhU, Topic-comment sentences: ZOhU, Topic-comment sentences: ZOhU, Topic-comment sentences: ZOhU, The North Wind and the Sun
- zoi: The five kinds of simple sumti, The universal bu, More on quotations: ZO, ZOI, More on quotations: ZO, ZOI, More on quotations: ZO, ZOI, More on quotations: ZO, ZOI, More on quotations: ZO, ZOI, More on quotations: ZO, ZOI, More on quotations: ZO, ZOI, More on quotations: ZO, ZOI, Erasure: SI, SA, SU, Erasure: SI, SA, SU, Erasure: SI, SA, SU
-
- interaction with "bu": The universal bu
- zu'a: Spatial tenses: FAhA and VA, Compound spatial tenses, Tense relations between sentences, Tense relations between sentences, Tense relations between sentences, Explicit magnitudes, List of spatial directions and direction-like relations
-
- derivation of word: Spatial tenses: FAhA and VA
- zu'e: Modal sentence connection: the causals, The North Wind and the Sun
- zu'i: Pro-sumti summary, Indefinite pro-sumti and pro-bridi: the zo'e-series and the co'e-series, Indefinite pro-sumti and pro-bridi: the zo'e-series and the co'e-series, Indefinite pro-sumti and pro-bridi: the zo'e-series and the co'e-series, Indefinite pro-sumti and pro-bridi: the zo'e-series and the co'e-series, Indefinite pro-sumti and pro-bridi: the zo'e-series and the co'e-series
- zu'o: Types of event abstractions, Types of event abstractions, Event-type abstractors and event contour tenses
-
- place structure: Types of event abstractions
- zu'u: The North Wind and the Sun
- zukte: Notes on gismu place structures, The North Wind and the Sun
- zuljma: rafsi, rafsi
- zunle: Spatial tenses: FAhA and VA, Proposed lerfu words for some accent marks and multiple letters
- zutse: The North Wind and the Sun
- zvafa'i: The North Wind and the Sun
- zvati: The North Wind and the Sun
- zy.: A to Z in Lojban, plus one, Proposed lerfu words for the Greek alphabet, Proposed lerfu words for the Cyrillic alphabet, Proposed lerfu words for the Hebrew alphabet, Forethought operators (Polish notation, functions)
Symbols
- "a" is letteral: References to lerfu, References to lerfu
- $: Computerized character codes
- &
-
- word for "&": The universal bu
- '
-
- "'" and consonant cluster determination in lujvo: lujvo
- definition of symbol "'" (see also apostrophe): The special Lojban characters
- (n + 1)(n + 1) = n² + 2n + 1: Simple infix expressions and equations
- (n+1)-th rat: Special mekso selbri
- +1 + -1 = 0: Simple infix expressions and equations
- -1: Signs and numerical punctuation
- -ek
-
- in name for logical connectives: The six types of logical connectives
- -er
-
- use of zmadu in forming: rafsi
- -ity: Property abstractions
- -ness: Property abstractions
- -ng
-
- Lojban contrasted with English: Syllabication and stress
- .
-
- word for ".": The universal bu
- .e'o: Propositional attitude indicators
- 1 + 1 = 2: Simple infix expressions and equations
- 10²⁰: Infix operators revisited
- 12-point: Alien alphabets
- 123: Lojban numbers
- 2 + 2: Truth-value abstraction: jei
- 2 rats + 2 rabbits = 4 animals: Using Lojban resources within mekso
- 2/7: Signs and numerical punctuation
- 3 grams: Simple infix expressions and equations
- 3 × 10⁸: Infix operators revisited
- 3.1415: Signs and numerical punctuation
- 4-letter rafsi
-
- definition: rafsi
- 5-letter rafsi
-
- definition: rafsi
- 9 out of 10: Special mekso selbri
- ℵ₀: Special numbers
A
- A
-
- notation convention for logical connectives: The four basic vowels
- A gives B to C: lerfu words as pro-sumti
- A gives BC: lerfu words as pro-sumti
- A loves B: lerfu words as pro-sumti
- a/an
-
- contrasted with English "the": Miscellaneous indicators
- abbreviated lujvo and plausibility: Eliding SE rafsi from seltau
- ABC base 16: Non-decimal and compound bases
- abduction
-
- example: Evidentials
- Abraham Lincoln: Truth questions and connective questions
- absolute laws: Why have lujvo?
- abstract description: Lojban sumti raising
- abstract lujvo: Abstract lujvo
- abstraction bridi
-
- contrasted with component non-abstraction bridi in meaning: Other kinds of simple selbri
- effect on claim of bridi: Modal sentence connection: the causals
- abstraction conversion: Lojban sumti raising
- abstraction of sentences
-
- contrasted with quotation: Predication/sentence abstraction
- abstractions
-
- achievement: Types of event abstractions
- activity: Types of event abstractions
- concept: Minor abstraction types
- creating new types: Minor abstraction types
- event: Event abstraction
- experience: Minor abstraction types
- forethought connection in: Abstractor connection and connection within abstractions
- grammatical uses: The syntax of abstraction
- grouping of connectives in: Abstractor connection and connection within abstractions
- idea: Minor abstraction types
- implicit in sumti: Event abstraction
- logical connection of: Abstractor connection and connection within abstractions
- making concrete: Lojban sumti raising
- mental activity: Predication/sentence abstraction
- place structure: The syntax of abstraction
- point-event: Types of event abstractions
- process: Types of event abstractions
- simplification to sumti with "jai": Lojban sumti raising
- simplification to sumti with "tu'a": Lojban sumti raising
- speaking
-
- writing, etc.: Predication/sentence abstraction
- state: Types of event abstractions
- sumti ellipsis in: Event abstraction
- truth-value and fuzzy logic: Truth-value abstraction: jei
- vague: Minor abstraction types
- with knowing
-
- believing, etc.: Predication/sentence abstraction
- with wonder
-
- doubt, etc.: Indirect questions
- accent mark
-
- a diacritical mark: Accent marks and compound lerfu words
- example: Accent marks and compound lerfu words
- accent marks
-
- proposed lerfu words for: Proposed lerfu words for some accent marks and multiple letters
- accented letters
-
- considered as distinct from unaccented: Accent marks and compound lerfu words
- Acer: fu'ivla
- achievative event contour: Event contours: ZAhO and re'u
- achievement abstraction
-
- place structure: Types of event abstractions
- achievement abstractions
-
- definition: Types of event abstractions
- related tense contours: Event-type abstractors and event contour tenses
- achievement event
-
- described: Types of event abstractions
- acronym
-
- definition: Acronyms
- acronym names from lerfu words
-
- assigning final consonant: Acronyms
- acronyms
- acronyms names based on lerfu words
- activity abstraction
-
- place structure: Types of event abstractions
- activity abstractions
-
- definition: Types of event abstractions
- related tense contours: Event-type abstractors and event contour tenses
- activity abstractor: Types of event abstractions
- activity event
-
- described: Types of event abstractions
- actual events
-
- explicitly expressing: Actuality, potentiality, capability: CAhA
- actual stop
-
- contrasted with natural end: Event contours: ZAhO and re'u
- actuality
-
- expressing in past/future: Actuality, potentiality, capability: CAhA
- Lojban contrasted with English in implying: Actuality, potentiality, capability: CAhA
- addition
-
- a mathematical operator: Simple infix expressions and equations
- addition operator
-
- contrasted with positive sign: Simple infix expressions and equations
- addition problems: Other kinds of simple selbri
- adjective ordering: Logical connection within tanru
- adjective-noun combination
-
- with tanru: Simple tanru
- adjectives
-
- brivla as Lojban equivalents: brivla
- adverb-verb combination
-
- with tanru: Simple tanru
- adverbs
-
- brivla as Lojban equivalents: brivla
- affirmative answer
-
- quick-tour version: Questions
- afraid of horse: Relative clauses and descriptors
- afterthought bridi connectives
-
- contrasted with forethought bridi connectives: Forethought bridi connection
- afterthought connection
-
- contrasted with forethought for grammatical utterances: Truth questions and connective questions
- definition: Other modal connections
- of operands: Logical and non-logical connectives within mekso
- of operators: Logical and non-logical connectives within mekso
- afterthought connectives
-
- as complete grammatical utterance: Truth questions and connective questions
- contrasted with forethought connectives: Forethought bridi connection
- afterthought sentence connection
-
- modal contrasted with tense: Tenses versus modals
- afterthought tense connection
-
- contrasted with forethought in likeness to modal connection: Tenses versus modals
- ailment: Ordering lujvo places.
- Alexander Pavlovitch Kuznetsov: lerfu words as pro-sumti
- algebra of functions
-
- operator and operand distinction in: Miscellany
- alienable possession
-
- definition: Relative phrases
- aliens
-
- communication with: Tentative conclusion
- all-th: Special mekso selbri
- allowable diphthongs
- alpha
-
- example: Alien alphabets
- alphabet
-
- Latin used for Lojban: What's a letteral, anyway?
- Lojban: Orthography
- words for letters in
-
- rationale: What's a letteral, anyway?
- alphabetic order: Orthography
- alphabets
-
- words for non-Lojban letters
-
- rationale: What's a letteral, anyway?
- alternative guidelines: Why have lujvo?
- always and everywhere: Space interval modifiers: FEhE
- ambiguity of tanru: Simple tanru
- American dollars: Computerized character codes
- American Indian languages and evidentials: Evidentials
- Amharic writing: What about Chinese characters?
- ampersand
-
- example: The universal bu
- ampersand character
-
- word for: The universal bu
- Amsterdam: Buffering of consonant clusters
- anaphora
-
- definition: Anaphoric pro-sumti and pro-bridi: the ri-series and the go'i-series
- pro-bridi go'i-series as: Anaphoric pro-sumti and pro-bridi: the ri-series and the go'i-series
- pro-sumti ri-series as: Anaphoric pro-sumti and pro-bridi: the ri-series and the go'i-series
- pro-sumti vo'a-series as: Reflexive and reciprocal pro-sumti: the vo'a-series
- anaphoric pro-bridi
-
- stability of: Pro-sumti and pro-bridi cancelling
- anaphoric pro-sumti
-
- stability of: Pro-sumti and pro-bridi cancelling
- and
-
- as non-logical connective: Non-logical connectives
- compared with but: Truth questions and connective questions
- contrasted with cross-product: More about non-logical connectives
- and earlier: Tenses, modals, and logical connection
- and simultaneously: Tenses, modals, and logical connection
- and then: Tensed logical connectives, Tensed logical connectives, Tensed logical connectives, Tenses, modals, and logical connection, Tenses, modals, and logical connection, Tenses, modals, and logical connection
- animal doctor
-
- example: Ordering lujvo places.
- animal patient: Ordering lujvo places.
- animals
-
- use of fu'ivla for specific: fu'ivla
- anomalous ordering of lujvo places: lujvo with more than two parts.
- answers
-
- "go'i" for yes/no questions: Anaphoric pro-sumti and pro-bridi: the ri-series and the go'i-series
- to operator questions: Other uses of mekso
- to place structure questions: Tagging places: FA
- to tense-or-modal questions: Tense questions: cu'e
- antecedent
-
- for pro-bridi: Assignable pro-sumti and pro-bridi: the ko'a-series and the broda-series
- for pro-bridi as full bridi: Assignable pro-sumti and pro-bridi: the ko'a-series and the broda-series
- antecedent of pro-bridi
- antecedent of pro-sumti
- anticipated
-
- example: Evidentials
- any
-
- as a restricted universal claim: The problem of “any”
- as a translation problem: The problem of “any”
- as a universal claim
-
- later restricted: The problem of “any”
- as an existential claim: The problem of “any”
- expressing as existential by variable in subordinate bridi: The problem of “any”
- any box: The problem of “any”
- anyone
-
- contrasted with everyone in assumption of existence: The problem of “any”
- anyone who goes
-
- walks: The problem of “any”
- aorist
-
- definition: Vague intervals and non-specific tenses
- apostrophe
-
- and consonant cluster determination in lujvo: lujvo
- as not a consonant for morphological discussions: Introductory
- as preferable over comma in Lojbanized names: The special Lojban characters
- definition of: The special Lojban characters
- example of: The special Lojban characters
- purpose of: The special Lojban characters
- quick-tour version: Pronunciation
- type of letter in word-formation: The special Lojban characters
- use in vowel pairs: Vowel pairs
- variant of: The special Lojban characters
- Appassionata: Modal relative phrases; Comparison, Modal relative phrases; Comparison, Modal relative phrases; Comparison, Modal relative phrases; Comparison
- approximate numbers
-
- expressing: Approximation and inexact numbers
- expressing some exactness of: Approximation and inexact numbers
- approximately 40: Approximation and inexact numbers
- Arabian Nights: Paragraphs: NIhO
- Arabic alphabet
-
- language shift word for: Alien alphabets
- argument tags
-
- based on tenses (see also sumtcita): Tenses as sumtcita
- Armstrong: Syllabication and stress
- Arnold: cmevla
- arthropod: Dependent places
- article
- articles
-
- cmavo as Lojban equivalents: cmavo
- Artur Rubenstein: Modal relative phrases; Comparison, Modal relative phrases; Comparison, Modal relative phrases; Comparison
- ASCII
-
- application to lerfu words: Computerized character codes
- aspect
-
- expressing: Event contours: ZAhO and re'u
- natural languages compared with respect to: Event contours: ZAhO and re'u
- assignable pro-sumti
-
- explicit cancellation of by rebinding: Pro-sumti and pro-bridi cancelling
- stability of: Pro-sumti and pro-bridi cancelling
- assumption: Evidentials
- asymmetrical tanru: Some types of asymmetrical tanru
-
- definition: Some types of asymmetrical tanru
- asymmetrical tanru types
-
- activity + implement-used: Some types of asymmetrical tanru
- cause + effect: Some types of asymmetrical tanru
- characteristic-time + event: Some types of asymmetrical tanru
- characteristic/detail + object: Some types of asymmetrical tanru
- effect + causative agent: Some types of asymmetrical tanru
- elements-in-set + set: Some types of asymmetrical tanru
- energy-source + powered: Some types of asymmetrical tanru
- general-class + sub-class: Some types of asymmetrical tanru
- inhabitant + habitat: Some types of asymmetrical tanru
- locus-of-application + object: Some types of asymmetrical tanru
- miscellaneous: Some types of asymmetrical tanru
- object + component/detail: Some types of asymmetrical tanru
- object + place-sold: Some types of asymmetrical tanru
- object + usual-container: Some types of asymmetrical tanru
- object-giving-characteristic + other-object: Some types of asymmetrical tanru
- object-measured + standard-object: Some types of asymmetrical tanru
- object-of-action + action: Some types of asymmetrical tanru
- object-of-purpose-of-instrument + instrument: Some types of asymmetrical tanru
- overriding-property + object-with-implicit-properties: Some types of asymmetrical tanru
- possessor + object: Some types of asymmetrical tanru
- product + producer: Some types of asymmetrical tanru
- product + source: Some types of asymmetrical tanru
- purpose-of-instrument + instrument: Some types of asymmetrical tanru
- set + element-of-set: Some types of asymmetrical tanru
- similar-appearance-object + object: Some types of asymmetrical tanru
- source + product: Some types of asymmetrical tanru
- source-material + object: Some types of asymmetrical tanru
- typical-place + object: Some types of asymmetrical tanru
- undesired-object + protection-object: Some types of asymmetrical tanru
- whole + part: Some types of asymmetrical tanru
- at least: Approximation and inexact numbers
-
- contrasted with more than
-
- less than, at most: Approximation and inexact numbers
- at least two: Approximation and inexact numbers
- at most: Approximation and inexact numbers
-
- contrasted with more than
-
- at least, less than: Approximation and inexact numbers
- at most two: Approximation and inexact numbers
- Athens: Types of event abstractions
- attend school: Interval properties: TAhE and roi
- attitude
-
- avoidance of expression: Miscellaneous indicators
- scalar: Attitudes as scales
- attitudes
-
- beginning: Attitude questions; empathy; attitude contours
- ceasing: Attitude questions; empathy; attitude contours
- continuing: Attitude questions; empathy; attitude contours
- empathy contrasted with sympathy: Attitude questions; empathy; attitude contours
- expressing changes in: Attitude questions; empathy; attitude contours
- attitudinal
-
- example of scale effect: Attitudes as scales
- signaling as non-propositional: Propositional attitude indicators
- attitudinal answers
-
- plausibility: Attitude questions; empathy; attitude contours
- attitudinal categories: Emotional categories
-
- example of effect: Emotional categories
- mnemonic for: Emotional categories
- rationale: Emotional categories
- attitudinal indicator
-
- unspecified: Compound indicators
- attitudinal indicators: What are attitudinal indicators?
-
- conventions of interpretation: Compound indicators
- placement of "nai" in: Compound indicators
- placement of scale in: Compound indicators
- quick-tour version: Indicators
- attitudinal modifiers: Attitudinal modifiers
- attitudinal questions: Attitude questions; empathy; attitude contours
-
- asking about specific attitude: Attitude questions; empathy; attitude contours
- asking intensity: Attitude questions; empathy; attitude contours
- attitudinal scale
-
- as axis in emotion-space: The space of emotions
- neutral compared with positive + negative: The space of emotions
- seven-position: Attitudes as scales
- stand-alone usage: Attitudes as scales
- usage: Attitudes as scales
- attitudinal scales
-
- rationale for assignment: Attitudes as scales
- attitudinals
-
- a- series: Propositional attitude indicators
- affecting whole grammatical structures: The uses of indicators
- and logic: What's wrong with this picture?
- at beginning of text: The uses of indicators
- attributing emotion to others: Attitude questions; empathy; attitude contours
- benefit in written expression: The uses of indicators
- categories with nai: Emotional categories
- categories with scale markers: Emotional categories
- complexity: Attitudinal modifiers
- compound: What are attitudinal indicators?
- contours: Attitude questions; empathy; attitude contours
- contrasted with bridi: Propositional attitude indicators, The space of emotions
- contrasted with discursives: Discursives
- contrasted with rationalizations of emotion: The space of emotions
- design benefit: The space of emotions
- e- series: Propositional attitude indicators
- emotional contrasted with propositional: Propositional attitude indicators
- emotional/propositional caveat: Propositional attitude indicators
- exceptions: Attitude questions; empathy; attitude contours
- external grammar: The uses of indicators
- grammar of internal compounding: Compound indicators
- grammar of placement in bridi: The uses of indicators
- i- series: Propositional attitude indicators
- internal grammar
-
- complete: Compound indicators
- logical language and: Propositional attitude indicators
- negative: Attitudes as scales
- neutral: Attitudes as scales
- non-speaker attitudes: Attitude questions; empathy; attitude contours
- order of: The space of emotions
- placement for prevailing attitude: What are attitudinal indicators?
- placement in sentences with "nai": Compound indicators
- positive: Attitudes as scales
- prevailing attitude: What are attitudinal indicators?
- propositional contrasted with emotional: Propositional attitude indicators
- propositional effect on claim: Propositional attitude indicators
- propositional/emotional caveat: Propositional attitude indicators
- rationale for: Propositional attitude indicators
- referent uncertainty: The uses of indicators
- scale of: Attitudes as scales
- stand-alone categories: Emotional categories
- word-form for primary: What are attitudinal indicators?
- audio-visual isomorphism: Orthography
- audio-visually isomorphic: Sentences: I
- auditoriums: Dependent places
- author of this book: Acknowledgements and credits
- Avon: Modal tags: BAI
B
- back-counting pro-sumti: Pro-sumti summary
- background noise: Symmetrical and asymmetrical lujvo
- base
-
- assumed: Non-decimal and compound bases
- changing permanently: Non-decimal and compound bases
- non-constant: Non-decimal and compound bases
- specifying: Non-decimal and compound bases
- vague: Non-decimal and compound bases
- base greater than 16
-
- compound single-digits contrasted with two digits: Non-decimal and compound bases
- expressing numbers in: Non-decimal and compound bases
- two digits contrasted with compound single-digits: Non-decimal and compound bases
- base point
-
- in bases other than 10: Non-decimal and compound bases
- base varying for each digit
-
- separator for: Non-decimal and compound bases
- base-20 arithmetic
-
- remnants of: Four score and seven: a mekso problem
- basis
-
- example: Evidentials
- beach
-
- example: Property abstractions
- bear wrote story: The three basic description types
- Bears wrote book: Individuals and masses
- beautiful dog: The sumti di'u and la'e di'u
- because
-
- four varieties of English word "because": Modal sentence connection: the causals
- beefsteak: Eliding KE and KEhE rafsi from lujvo, Eliding KE and KEhE rafsi from lujvo
- Beethoven: Modal relative phrases; Comparison, Modal relative phrases; Comparison, Modal relative phrases; Comparison
- beetle: Dependent places
- beetles: Dependent places
- begin
-
- contrasted with resume: Event contours: ZAhO and re'u
- beginning point
-
- spatial: Space interval modifiers: FEhE
- being alive: Types of event abstractions
- better: Comparatives and superlatives
- between Dresden and Frankfurt: Interval connectives and forethought non-logical connection, Interval connectives and forethought non-logical connection, Interval connectives and forethought non-logical connection
- beverage
-
- example: lujvo based on pro-sumti
- bibliography: Informal bibliography
- bicycle race: Minor abstraction types
- big boat: lujvo
- big nose: What are you pointing at?
- big nose-pores: What are you pointing at?
- big person: What are you pointing at?
- big red dog: Logical connection within tanru
- Bill Clinton: The meaning of tanru: a necessary detour
- binary system
-
- specifying numbers in (see also base): Non-decimal and compound bases
- blue
-
- as sad: Miscellaneous indicators
- blue and red: Non-logical connectives
- blue house: Conversion: SE, Logical connection within tanru, Logical connection within tanru
- blue-eyed: Eliding SE rafsi from tertau
- bo
-
- for right-grouping in tanru: Complex tanru grouping
- boat class
-
- example: lujvo-making examples
- boat sailed: Tenses as sumtcita
- bold
-
- example: Alien alphabets
- bomb destroyed fifty miles: Interval connectives and forethought non-logical connection
- bone bread: Buffering of consonant clusters
- books about Lojban: Informal bibliography
- borrowing
-
- four stages of: fu'ivla
- borrowing from other language
-
- fu'ivla as: brivla
- borrowings
-
- fu'ivla form with categorizing rafsi: fu'ivla
- fu'ivla form without categorizing rafsi: fu'ivla
- most common form for: fu'ivla
- Stage 1: fu'ivla
- Stage 2: fu'ivla
- Stage 3: fu'ivla
- Stage 3 contrasted with Stage 4 in ease of construction: fu'ivla
- Stage 4: fu'ivla
- using foreign-language name: fu'ivla
- using lojbanized name: fu'ivla
- Boston from Atlanta: Standard bridi form: cu
- both dogs: Indefinite numbers
- bound variable pro-sumti
-
- stability of: Pro-sumti and pro-bridi cancelling
- bovine: Eliding KE and KEhE rafsi from lujvo
- bracketed remark: Parenthesis and metalinguistic commentary: TO, TOI, SEI
- brackets
-
- use in IPA notation: Basic phonetics
- breathe: Tenses, modals, and logical connection
- bridi
-
- building from selbri and sumti: Standard bridi form: cu
- compared with predication: The concept of the bridi
- concept of: The concept of the bridi
- definition: Lojban content words: brivla
-
- quick-tour version: Lojban grammatical terms
- effect of alternate form on sumti order: Standard bridi form: cu
- effect of using non-standard form: Standard bridi form: cu
- exception to sumti place structure in: Standard bridi form: cu
- leaving a sumti place unspecified in with zo'e: Standard bridi form: cu
- leaving end sumti places unspecified in: Standard bridi form: cu
- logical connection with negation: Logical connection of bridi
- logical connective for: Logical connection of bridi
- non-standard form: Standard bridi form: cu
- omitting the first sumti place: Standard bridi form: cu
- quick-tour version: Some simple Lojban bridi
- relation to selbri: Lojban content words: brivla
- selbri-first as exceptional: Standard bridi form: cu
- standard form of: Standard bridi form: cu
- bridi connection
-
- use of imperatives in: Truth questions and connective questions
- use of truth questions in: Truth questions and connective questions
- bridi logical connection
-
- compared with sumti logical connections: sumti connection
- bridi negation
-
- and DeMorgan's Law: Logical connectives and DeMorgan's law
- and negation boundary: Logical connectives and DeMorgan's law
- compared with negation between sentences: bridi negation and logical connectives
- multiple: Tenses and bridi negation
- na before selbri compared to naku in prenex: Negation boundaries
- naku in prenex compared to na before selbri: Negation boundaries
- relative order with tense: Tenses and bridi negation
- two forms of: Negation boundaries
- bridi negation and logical connectives: bridi negation and logical connectives
- bridi questions
-
- quick-tour version: Questions
- bridi-based comparison
-
- contrasted with comparison with relative phrase
-
- in claims about parts: Modal relative phrases; Comparison
- bridi-tail
-
- definition: Compound bridi
- bridi-tail logical connection
-
- and DeMorgan's Law: Logical connectives and DeMorgan's law
- bridi-tail modal connection: Other modal connections
- bridi-tails
-
- eliding "vau" in: Compound bridi
- forethought tense connection of: Tense relations between sentences
- brie: fu'ivla
- brivla
-
- as one of the 3 basic word classes: Introductory
- consonant pairs in: brivla
- definition: brivla
-
- quick-tour version: Lojban grammatical terms
- from tanru: lujvo
- properties of: brivla
- recognition of: brivla
- relation to bridi: The concept of the bridi
- stress on: Syllabication and stress
- subtypes of: brivla
- types: Lojban content words: brivla
- types of
-
- quick-tour version: Examples of brivla
- brivla as selbri: Lojban content words: brivla
- brivla equivalents: Other kinds of simple selbri
- brivla form
- Brooklyn: Linked sumti: be - bei - be'o
- brothers: Non-logical connectives, Non-logical connectives, Non-logical connectives, Non-logical connectives
- Brown
-
- James Cooke: Acknowledgements and credits
-
- and "letteral": What's a letteral, anyway?
- John: cmevla, cmevla
- buffer vowel: Buffering of consonant clusters
-
- and stress: Buffering of consonant clusters
- shortening of: Buffering of consonant clusters
- Bulgarian: fu'ivla, fu'ivla, fu'ivla
- but
-
- compared with and: Truth questions and connective questions
- example: Discursives
- but/and equivalence: Indicators
- butter is soft: Individuals and masses
- butterfly
-
- social: tanru
C
- C string
-
- as a symbol for a single consonant: Introductory
- C/C string
-
- as a symbol for a permissible consonant pair: Introductory
- C/CC string
-
- as a symbol for a consonant triple: Introductory
- calculator mathematics
-
- as default in Lojban: Simple infix expressions and equations
- can see: Actuality, potentiality, capability: CAhA
- canceling letter shifts: Alien alphabets
- cancellation of pro-sumti/pro-bridi assignment
-
- with "da'o": Pro-sumti and pro-bridi cancelling
- capital letters
-
- use in Lojban: Upper and lower cases
- use of: Orthography
- capitalization
- car goer: Symmetrical and asymmetrical lujvo
- cardinal selbri
-
- definition: Special mekso selbri
- place structure: Special mekso selbri
- place structure effect from subjective numbers: Special mekso selbri
- cardinality
-
- definition: Masses and sets
- property of sets: Masses and sets
- carried piano: Non-logical connectives
- carry sack: Mixed modal connection
- carry sack and dog: Tensed logical connectives, Tensed logical connectives, Tensed logical connectives
- carry the piano: Interval connectives and forethought non-logical connection
- Cartesian product
-
- with tenses: Sub-events
- Carthage destroyed: Evidentials
- case
-
- upper/lower specification: Upper and lower cases
- cat of plastic: Relativized pro-sumti: ke'a
- Catherine: cmevla
- Cathy: cmevla
- causals
-
- claiming the relation contrasted with claiming cause and/or effect and/or relation: Modal sentence connection: the causals
- gismu: Modal sentence connection: the causals
- modal: Modal sentence connection: the causals
- cause death: Lojban sumti raising
- cave: Story time
- CC string
-
- as a symbol for a permissible initial consonant pair: Introductory
- CCVVCV fu'ivla
-
- and rafsi fu'ivla proposal: Cultural and other non-algorithmic gismu
- cedilla
-
- a diacritical mark: Accent marks and compound lerfu words
- cessitive event contour: Event contours: ZAhO and re'u
- ch-sound in English
-
- representation in Lojban: Basic phonetics
- chapter numbering: Other uses of mekso
- chapter titles
-
- intent of: What is this book?
- character codes
-
- definition: Computerized character codes
- character encoding schemes
-
- application to lerfu words: Computerized character codes
- characters
-
- definition: Computerized character codes
- special: The special Lojban characters
- Chelsea Clinton: The meaning of tanru: a necessary detour
- chemical elements
-
- use of single-letter shift for: Upper and lower cases
- Chief: cmevla
- child on ice: Interval sizes: VEhA and ZEhA
- Chilean desert
-
- example: rafsi fu'ivla: a proposal
- Chinese characters
-
- contrasted with alphabets and syllabaries: What about Chinese characters?
- representing based on pinyin spelling: What about Chinese characters?
- representing based on strokes: What about Chinese characters?
- choose from: Non-logical connectives
- Chrysler: selbri based on sumti: me
- CIA: Acronyms
- circumflex
-
- a diacritical mark: Accent marks and compound lerfu words
- clamshells: Eliding KE and KEhE rafsi from lujvo
- clarity of sounds: Basic phonetics
- Classical Greek aorist tense
-
- compared with Lojban tense: Vague intervals and non-specific tenses
- closed interval: Interval connectives and forethought non-logical connection
-
- expressed with "mi'i": Logical and non-logical connectives within mekso
- closings
-
- letter: Vocative scales
- cmavo
-
- as one of the 3 basic word classes: Introductory
- compound: cmavo
- contrasted with rafsi in usage: rafsi
- contrasted with same-form rafsi in meaning: lujvo
- definition: cmavo
-
- quick-tour version: Lojban grammatical terms
- diphthongs in: cmavo
- experimental: cmavo
- for experimental use: cmavo
- lack of relation of form to grammatical use: cmavo
- rules for pause after Cy-form: Rules for inserting pauses
- simple: cmavo
- stress on: Syllabication and stress, cmavo
- structure of: cmavo
- cmavo and gismu
-
- major: gismu
- cmavo as selbri
-
- quick-tour version: Examples of brivla
- cmavo form
-
- contrasted with brivla form: brivla
- cmavo without rafsi
-
- method of including in lujvo: rafsi
- cmevla
-
- algorithm for: cmevla
- and analyzability of speech stream: cmevla
- as one of the 3 basic word classes: Introductory
- authority for: cmevla
- avoiding impermissible consonant clusters in: cmevla
- consonant clusters permitted in: cmevla
- definition: cmevla
- dot side: cmevla
- examples of: cmevla
- from Lojban words: cmevla
- method of including in lujvo: rafsi
- purpose of: cmevla
- rationale for lojbanizing: cmevla
- requirement for pauses around: cmevla
- rules for: cmevla
- rules for formation: cmevla
- rules for pause before: Rules for inserting pauses
- stress in: cmevla, cmevla
- stress on: Syllabication and stress
- unusual stress in: cmevla
- cmevla form
-
- contrasted with brivla form: brivla
- cobra: fu'ivla
- coffee mixed with tea: More about non-logical connectives
- coffee or tea: Truth questions and connective questions
- coin heads: Special mekso selbri
- Coleoptera: Dependent places
- color standards: Notes on gismu place structures
- Comic font: Alien alphabets
- comma
-
- definition of: The special Lojban characters
- effect on relative clause in English: Incidental relative clauses
- example of: The special Lojban characters
- main use of: The special Lojban characters
- optional: The special Lojban characters
- quick-tour version: Pronunciation
- variant of: The special Lojban characters
- command
-
- contrasted with observative form: Standard bridi form: cu
- commands
-
- quick-tour version: Vocatives and commands
- with "ko": Personal pro-sumti: the mi-series
- commas in numbers
-
- as numerical punctuation: Signs and numerical punctuation
- effect of other notation conventions: Signs and numerical punctuation
- with elided digits: Signs and numerical punctuation
- common abstractor: Event abstraction
- commutative truth functions: The four basic vowels
- comparative lujvo
-
- against former state: Comparatives and superlatives
- and seltau presupposition: Comparatives and superlatives
- potential ambiguity in: Comparatives and superlatives
- standardized meanings: Comparatives and superlatives
- comparatives
-
- use of zmadu in forming: rafsi
- comparison
-
- claims related to based on form: Modal relative phrases; Comparison
- comparison with relative phrase
-
- contrasted with bridi-based comparison
-
- in claims about parts: Modal relative phrases; Comparison
- completitive event contour: Event contours: ZAhO and re'u
- complex logical connection
-
- grouping strategies contrasted: Grouping of afterthought connectives
- complex logical connectives
-
- grouping with bo: Grouping of afterthought connectives
- grouping with parentheses: Grouping of afterthought connectives, Grouping of afterthought connectives
- complex movements
-
- expressing: Movement in space: MOhI
- complex negation
-
- examples: Scalar negation of selbri
- complex numbers
-
- expressing: Special numbers
- components contrasted with mass
-
- in properties of: Non-logical connectives
- compound base
-
- definition: Non-decimal and compound bases
- expressing digits in: Non-decimal and compound bases
- separator for: Non-decimal and compound bases
- compound bridi
-
- definition: Compound bridi
- logical connection of: Compound bridi
- more than one sumti in common: Compound bridi
- multiple with "bo": Multiple compound bridi
- multiple with "ke…ke'e": Multiple compound bridi
- one sumti in common: Compound bridi
- separate tail-terms for bridi-tails: Multiple compound bridi
- separate tail-terms for forethought-connected bridi-tails: Multiple compound bridi
- compound bridi with more than one sumti in common
-
- with common sumti first: Compound bridi
- with vau: Compound bridi
- compound cmavo
- compound emotions: The space of emotions
- compound letters
-
- native language
-
- representing as distinct letters: Accent marks and compound lerfu words
- compound logical connectives
-
- components: The six types of logical connectives
- naming convention: The six types of logical connectives
- compound of gismu
-
- lujvo as: brivla
- compound spatial tense
-
- as direction with-or-without distance: Compound spatial tenses
- beginning with distance only: Compound spatial tenses
- effect of different ordering: Compound spatial tenses
- explanation of: Compound spatial tenses
- with direction and distance: Compound spatial tenses
- compound subscript: Logical and non-logical connectives within mekso, Logical and non-logical connectives within mekso
- compound temporal tense
-
- beginning with distance only: Temporal tenses: PU and ZI
- compound tense
-
- compared with multiple tenses in sentence: Sticky and multiple tenses: KI
- compared with tense in scope of sticky tense: Sticky and multiple tenses: KI
- definition: Compound spatial tenses
- Lojban contrasted with English in order of specification: Compound spatial tenses
- compound tense ordering
-
- Lojban contrasted with English: Compound spatial tenses
- computer interaction: No more to say: FAhO
- concept abstraction: Minor abstraction types
- concept abstractions
-
- place structure: Minor abstraction types
- concept abstractor: Minor abstraction types
- concrete terms
-
- use of fu'ivla for: fu'ivla
- condescension: Attitudinal modifiers
- confusion
-
- metalinguistic: Miscellaneous indicators
- confusion about what was said: Miscellaneous indicators
- conjunctions
-
- cmavo as Lojban equivalents: cmavo
- connected tenses
-
- negation of compared with negation in connective: Logical and non-logical connections between tenses
- connecting operands
-
- with "bo" in connective: Logical and non-logical connectives within mekso
- with "ke" in connective: Logical and non-logical connectives within mekso
- connecting operators
-
- with "bo" in connective: Logical and non-logical connectives within mekso
- with "ke" in connective: Logical and non-logical connectives within mekso
- connection
-
- non-distributed: Non-logical connectives
- simultaneously modal and logical: Mixed modal connection
- connection of operands
-
- grouping: Logical and non-logical connectives within mekso
- precedence over operator: Logical and non-logical connectives within mekso
- connection of operators
- connective answers
-
- non-logical: More about non-logical connectives
- connective question answers
-
- contrasted with other languages: Truth questions and connective questions
- connective question cmavo
-
- departure from regularity of: Truth questions and connective questions
- connective questions
-
- answering: Truth questions and connective questions
- compared with other languages: Truth questions and connective questions
- non-logical: More about non-logical connectives
- connectives
-
- as complete grammatical utterance: Truth questions and connective questions
- as ungrammatical utterance: Truth questions and connective questions
- table by constructs connected: Constructs and appropriate connectives
- consonant
-
- definition: Consonant clusters
- effect on syllable count: Consonant clusters
- consonant clusters
-
- buffering of: Buffering of consonant clusters
- contrasted with doubled consonants: Consonant clusters
- contrasted with single consonants: Consonant clusters
- definition of: Consonant clusters
- more than three consonants in: Initial consonant pairs
- consonant pairs
-
- in brivla: brivla
- initial: Initial consonant pairs
- letter "y" within: brivla
- restrictions on: Consonant clusters
- consonant triples: Initial consonant pairs
-
- restrictions on: Initial consonant pairs
- consonant-final words
-
- necessity for pause after: Rules for inserting pauses
- consonants
-
- contrasted with vowels: Diphthongs and syllabic consonants
- final: Consonant clusters
- position of: Consonant clusters
- pronunciation of
-
- quick-tour version: Pronunciation
- restrictions on: Consonant clusters
- syllabic: Diphthongs and syllabic consonants
- voiced/unvoiced equivalents: Consonant clusters
- voicing of: Consonant clusters
- continents
-
- gismu for: Cultural and other non-algorithmic gismu
- continues: Event contours: ZAhO and re'u
- continuitive event contour: Event contours: ZAhO and re'u
- continuous
-
- of tense intervals: Interval properties: TAhE and roi
- contradictory negation
-
- using "naku" before selbri: Using naku outside a prenex
- contradictory negation of modals
-
- explanation of meaning: Modal negation
- contributors to this book: Acknowledgements and credits
- conversion
-
- accessing tense of bridi with "jai": Conversion of sumtcita: JAI
- definition: Conversion of simple selbri, Conversion of sumtcita: JAI
- effect of multiple on a selbri: Conversion: SE
- effect on BAI: Modal tags: BAI
- extending scope of: Conversion: SE
- modal: Modal conversion: JAI
- of BAI cmavo: Modal tags: BAI
- of operator places: Miscellany
- scope of: Conversion: SE
- swapping non-first places: Conversion: SE
- swapping with modal place: Modal conversion: JAI
- conversion and tanru: Conversion of simple selbri
- conversion into sumti from mekso: Simple infix expressions and equations
- conversion of mekso into sumti: Simple infix expressions and equations
- conversion of operand into operator: Miscellany
- conversion of operator into operand: Miscellany
- conversion of operator into selbri: Other uses of mekso
- conversion of selbri into operand: Using Lojban resources within mekso
- conversion of selbri into operator: Using Lojban resources within mekso
- conversion of sentence with quantified variables
-
- technique: Using naku outside a prenex
- conversion of sumti into operand: Using Lojban resources within mekso
- conversion of sumti into selbri: selbri based on sumti: me
- conversion with "se"
-
- effect of "naku" negation boundary on conversion: Using naku outside a prenex
- conversion with ke: Conversion of simple selbri
- converted selbri
-
- as different selbri from unconverted: Conversion: SE
- as resetting standard order: Conversion: SE
- compared with selbri with FA in meaning: Conversion: SE
- contrasted with other similar selbri: Conversion: SE
- contrasted with selbri with FA in structure: Conversion: SE
- definition: Conversion: SE
- forming with SE: Conversion: SE
- in descriptions: Conversion: SE
- place structure of: Conversion: SE
- retention of basic meaning in: Conversion: SE
- to access non-first place in description: Conversion: SE
- creative understanding: Why have lujvo?
- credits for pictures: Acknowledgements and credits
- credits for this book: Acknowledgements and credits
- cross product
-
- with tenses: Sub-events
- cross-dependency: Dependent places
- cross-product
-
- contrasted with "and": More about non-logical connectives
- of sets: More about non-logical connectives
- cultural knowledge
-
- example: Evidentials
- cultural words
-
- rafsi fu'ivla proposal for: Cultural and other non-algorithmic gismu
- culturally dependent lujvo: Miscellaneous indicators
- cup's friend: Relative phrases
- curious: Predication/sentence abstraction, Predication/sentence abstraction
- Cy-form cmavo
-
- rules for pause after: Rules for inserting pauses
- cycles: Event contours: ZAhO and re'u
- Cyrillic alphabet
-
- language shift word for: Alien alphabets
- proposed lerfu words for: Proposed lerfu words for the Cyrillic alphabet
D
- da'a
-
- default number for: Indefinite numbers
- decimal point
-
- as numerical punctuation: Signs and numerical punctuation
- effect of different notations: Signs and numerical punctuation
- in bases other than 10: Non-decimal and compound bases
- deduction
-
- example: Evidentials
- default operator precedence
-
- contrasted with mekso goal: Simple infix expressions and equations
- deference: Attitudinal modifiers
- definable pro-sumti: Pro-sumti summary
-
- sequences of lerfu words as: Pro-sumti summary
- definite numbers
-
- combined with indefinite: Indefinite numbers
- demonstrated potential
-
- expressing: Actuality, potentiality, capability: CAhA
- demonstrative pro-sumti: Pro-sumti summary, Demonstrative pro-sumti: the ti-series
-
- stability of: Pro-sumti and pro-bridi cancelling
- DeMorgan's Law
-
- and bridi-tail logical connection: Logical connectives and DeMorgan's law
- and distributing a negation: Logical connectives and DeMorgan's law
- and internal "naku" negations: Logical connectives and DeMorgan's law
- and logically connected sentences: Logical connectives and DeMorgan's law
- and moving a logical connective relative to "naku": Logical connectives and DeMorgan's law
- sample applications: Logical connectives and DeMorgan's law
- dereferencing a pointer
-
- with "la'e": sumti qualifiers
- derivational morphology
-
- definition: Introductory
- derogatory terms: The meaning of tanru: a necessary detour
- descriptions
-
- and abstractions: The syntax of abstraction
- as based on first place of following selbri: Conversion: SE
- as possessive sumti: Possessive sumti
- components of: The three basic description types
- importance of selbri first place in: The three basic description types
- non-specific: The three basic description types
- quick-tour version: Description sumti
- specific: The three basic description types
- types of: The three basic description types, The three basic description types
- use of SE in: Conversion: SE
- descriptions with lo
-
- teddy bear contrasted with real bear: The three basic description types
- descriptor
-
- as part of description: The three basic description types
- descriptors
-
- implicit quantifiers for: Quantified descriptions
- omission of: Indefinite descriptions
- purpose of: The three basic description types
- destination: Conversion: SE
- Devanagari: Alien alphabets
- diacritic marks
-
- proposed lerfu words for: Proposed lerfu words for some accent marks and multiple letters
- diacritical marks
-
- as lerfu: Accent marks and compound lerfu words
- considered as forming distinct letters: Accent marks and compound lerfu words
- order of specification within "tei…foi": Accent marks and compound lerfu words
- problem of position: Accent marks and compound lerfu words
- problem with multiple on one lerfu: Accent marks and compound lerfu words
- specifying with "tei…foi": Accent marks and compound lerfu words
- dictionary
-
- superior authority of: Disclaimers
- die after living: Tenses as sumtcita
- digit questions: Number questions
- digit string
-
- definition of: Other uses of mekso
- digits
-
- cmavo for: Lojban numbers
- list of decimal: Complete table of PA cmavo: digits, punctuation, and other numbers
- list of hexadecimal: Complete table of PA cmavo: digits, punctuation, and other numbers
- names from: Miscellany
- rafsi for: Miscellany
- rationale for having 16: Non-decimal and compound bases
- digits beyond 9
-
- word pattern: Non-decimal and compound bases
- dimension
-
- meaning as sumtcita: Tenses as sumtcita
- dimensionality
-
- of walking: Dimensionality: VIhA
- order with size in spatial tense intervals: Dimensionality: VIhA
- dimensionality of interval
-
- as subjective: Dimensionality: VIhA
- dimensioned numbers
-
- expressing: Using Lojban resources within mekso
- diphthongs
-
- classification of: Diphthongs and syllabic consonants
- contrasted with vowel pairs: Vowel pairs
- definition of: Diphthongs and syllabic consonants
- English analogues of: English analogues for Lojban diphthongs
- in fu'ivla: fu'ivla
- IPA for: Diphthongs and syllabic consonants
- list of: Diphthongs and syllabic consonants
- pronunciation of
-
- quick-tour version: Pronunciation
- specific to cmevla: cmevla
- specific to names: cmevla
- direct address: Vocative scales
- direction
-
- following interval in tense construct: Interval sizes: VEhA and ZEhA
- interaction with movement specification in tenses: Movement in space: MOhI
- order of relative to distance in spatial tenses: Spatial tenses: FAhA and VA
- reference frame for: Movement in space: MOhI
- specification with FAhA: Spatial tenses: FAhA and VA
- directions
-
- multiple with movement: Movement in space: MOhI
- disambiguated instance: The meaning of lujvo
- disclaimers: Disclaimers
- discourse
-
- commentary on: Discursives
- expressing utterance relation to: Discursives
- gesture markers: Discursives
- tone of voice markers: Discursives
- discrete
-
- of tense intervals: Interval properties: TAhE and roi
- discursive indicator: Paragraphs: NIhO
- discursives
-
- "su'a" as: Evidentials
- as metalinguistic claims: Discursives
- contrasted with attitudinals: Discursives
- definition: Discursives
- discourse commentary: Discursives
- discourse management: Discursives
- embedded: Parenthesis and metalinguistic commentary: TO, TOI, SEI
- expressing how things are said: Discursives
- knowledge: Discursives
- placement in sentence: Discursives
- quick-tour version: Indicators
- word-level: Discursives
- discursives for consecutive discourse: Discursives
-
- contrasted: Discursives
- discursives for managing discourse flow: Discursives
- discuss in language: More about non-logical connectives
- distance
-
- order of relative to direction in spatial tenses: Spatial tenses: FAhA and VA
- specification with VA: Spatial tenses: FAhA and VA
- distributing a negation: Logical connectives and DeMorgan's law
- distribution of quantified sumti: Grouping of quantifiers
- ditto
-
- example: Discursives
- diversified species: Notes on gismu place structures
- DNA: Acronyms
- doctor and then rich: Tenses, modals, and logical connection
- dog bites: Dropping the prenex
- dog breathes: Restricted claims: da poi
- dog house
- dog or cat: Truth questions and connective questions, Truth questions and connective questions, Truth questions and connective questions
- doghouse: The meaning of lujvo
-
- example: lujvo-making examples
- dogs bite: Grouping of quantifiers
- Dong: Ordering lujvo places., Ordering lujvo places., Ordering lujvo places.
- double negation
-
- and "naku": Using naku outside a prenex
- double negatives
-
- effect of interactions between quantifiers and negation on: Negation boundaries
- double underscore notation convention for Quick Tour chapter: The concept of the bridi
- doubled consonants
-
- contrasted with consonant clusters: Consonant clusters
- contrasted with single consonants: Consonant clusters
- dream
-
- example: Evidentials
- du
-
- as an exception within GOhA selma'o: Other kinds of simple selbri
- ducks swim: Actuality, potentiality, capability: CAhA
E
- E
-
- notation convention for logical connectives: The four basic vowels
- Earl
-
- example: Diphthongs and syllabic consonants
- eat in airplane: Movement in space: MOhI
- eat themselves: Indefinite numbers
- editorial commentary: Parenthesis and metalinguistic commentary: TO, TOI, SEI
- editorial insertion: Parenthesis and metalinguistic commentary: TO, TOI, SEI
-
- of text already containing "sa'a": Miscellaneous indicators
- with "sa'a": Miscellaneous indicators
- Einsteinian
-
- space-time intervals with 4 dimensions: Dimensionality: VIhA
- ek
-
- definition: The six types of logical connectives
- eks
-
- connecting operands: Logical and non-logical connectives within mekso
- in sumti forethought logical connection: sumti connection
- elementary schools: Dependent places
- Elgin
-
- Suzette Haden and evidentials: Evidentials
- elided tense
-
- meaning of: Introductory
- elimination process: Ordering lujvo places.
- ellipsis
-
- quick-tour version: Some simple Lojban bridi
- elliptical pro-bridi: Indefinite pro-sumti and pro-bridi: the zo'e-series and the co'e-series
- elliptical pro-sumti: Indefinite pro-sumti and pro-bridi: the zo'e-series and the co'e-series
- elliptical sumti: Indefinite pro-sumti and pro-bridi: the zo'e-series and the co'e-series
- elliptical value
-
- contrasted with typical value for sumti: Indefinite pro-sumti and pro-bridi: the zo'e-series and the co'e-series
- embarrassment
-
- example: Emotional categories
- embedded bridi tenses
-
- effect of main bridi tense on: Sticky and multiple tenses: KI
- embedded discursive: Parenthesis and metalinguistic commentary: TO, TOI, SEI
- emotional categories: Emotional categories
- emotional indicators
-
- noticeable effects of: Tentative conclusion
- emotional scale: Attitudes as scales
- emotions
-
- compound: The space of emotions
- cultural bias of expression: Tentative conclusion
- insights: The space of emotions
- recording using indicators: Tentative conclusion
- research using indicators: Tentative conclusion
- when expressed: The space of emotions
- empathy: Attitude questions; empathy; attitude contours
- emphasis
-
- changing by using non-standard form of bridi: Standard bridi form: cu
- end of file: No more to say: FAhO
- endpoints
-
- inclusion in interval: Interval connectives and forethought non-logical connection
- engineering: Some simple Lojban bridi
- English "we"
-
- contrasted with Lojban pro-sumti for "we": Personal pro-sumti: the mi-series
- English prepositions
-
- contrasted with modal tags in preciseness: Modal tags: BAI
- Englishman in Africa: Individuals and masses
- enough currency: Indefinite numbers
- enough-th: Special mekso selbri
- equivalents to brivla: Other kinds of simple selbri
- erasure
-
- multiple word: Erasure: SI, SA, SU
- names: Erasure: SI, SA, SU
- of quotations with "zo": Erasure: SI, SA, SU
- quotes: Erasure: SI, SA, SU
- total: Erasure: SI, SA, SU
- word: Erasure: SI, SA, SU
- error marking
-
- metalinguistic: Miscellaneous indicators
- ete: Accent marks and compound lerfu words
- event abstractions: Event abstraction
-
- types: Types of event abstractions
- event contours
-
- achievative: Event contours: ZAhO and re'u
- as characteristic portions of events: Event contours: ZAhO and re'u
- as sumtcita: Tenses as sumtcita
- as timeless in perspective: Event contours: ZAhO and re'u
- cessative: Event contours: ZAhO and re'u
- completitive: Event contours: ZAhO and re'u
- continuitive: Event contours: ZAhO and re'u
- contrasted with tense direction in implication of extent: Event contours: ZAhO and re'u
- definition: Event contours: ZAhO and re'u
- division of the event into: Event contours: ZAhO and re'u
- implications on scope of event: Event contours: ZAhO and re'u
- inchoative: Event contours: ZAhO and re'u
- initiative: Event contours: ZAhO and re'u
- interruption: Event contours: ZAhO and re'u
- order with respect to TAhE and ROI: Event contours: ZAhO and re'u
- pausative: Event contours: ZAhO and re'u
- points associated with: Event contours: ZAhO and re'u
- resumption: Event contours: ZAhO and re'u
- resumptive: Event contours: ZAhO and re'u
- retrospective: Event contours: ZAhO and re'u
- strings of: Sub-events
- superfective: Event contours: ZAhO and re'u
- syntax of: Event contours: ZAhO and re'u
- temporal contrasted with spatial: Space interval modifiers: FEhE
- event contours as sumtcita
-
- contrasted with direction and distance: Tenses as sumtcita
- event types
-
- described: Types of event abstractions
- event-relative viewpoint
-
- contrasted with speaker-relative viewpoint: Event contours: ZAhO and re'u
- events
-
- considered as a process: Event contours: ZAhO and re'u
- duration: Event abstraction
- place structure: Event abstraction
- everybody loves something: Negation boundaries
- everyone
-
- contrasted with anyone in assumption of existence: The problem of “any”
- everyone bitten by dog: Dropping the prenex
- everything
-
- expressing with "ro da": Universal claims
- everything breathes: Restricted claims: da poi
- everything loves everything: Universal claims
- everything sees me: Universal claims
- everything sees something: Universal claims
- evidentials
-
- "ba'a" scale: Evidentials
- "ja'o" contrasted with "su'a": Evidentials
- "ka'u" contrasted with "se'o": Evidentials
- "se'o" contrasted with "ka'u": Evidentials
- "su'a" contrasted with "ja'o": Evidentials
- definition: Evidentials
- grammar: Evidentials
- in English: Evidentials
- indisputable bridi: Evidentials
- inspiration for: Evidentials
- placement in bridi: Evidentials
- quick-tour version: Indicators
- rhetorical flavor: Evidentials
- scales: Evidentials
- exact number
-
- expressing: Approximation and inexact numbers
- example of examples: What are the typographical conventions of this book?
- examples
-
- structure of: What are the typographical conventions of this book?
- examples in this book: What are the typographical conventions of this book?
- except from 10 to 12: Interval connectives and forethought non-logical connection
- existential
-
- mixed claim with universal: Universal claims
- existential claims
-
- definition: Existential claims, prenexes, and variables
- restricting: Restricted claims: da poi
- existential variable
-
- in abstraction contrasted with in main bridi: The problem of “any”
- in main bridi contrasted with in abstraction: The problem of “any”
- experience abstraction: Minor abstraction types
- experience abstractions
-
- place structure: Minor abstraction types
- experience abstractor: Minor abstraction types
- experienced: Evidentials
- experimental cmavo
- exponential notation
-
- with "gei": Infix operators revisited
- with base other than 10: Infix operators revisited
- exporting negation to prenex
-
- "naku" contrasted with internal bridi negation: Using naku outside a prenex
- internal bridi negation contrasted with "naku": Using naku outside a prenex
- external bridi negation
-
- compared to internal bridi negation: Negation boundaries
- definition: Negation boundaries
- extrinsic possession
-
- definition: Relative phrases
F
- F.8 base 16: Non-decimal and compound bases
- FA tags and linked sumti: Linked sumti: be - bei - be'o
- face
-
- specifying for letters: Alien alphabets
- false statement
-
- implications of: Logical connection of bridi
- far away from the nearby park: Tenses as sumtcita
- fast talker: tanru
- fast-talker shoe: tanru
- father: The concept of the bridi
- father mother: lujvo
- fewsome: Special mekso selbri
- Fido: Dropping the prenex
- field rations: lujvo
- figurative lujvo: Miscellaneous indicators
-
- place structure: Miscellaneous indicators
- figurative speech: Miscellaneous indicators
- final syllable stress
-
- rules for pause after: Rules for inserting pauses
- finish
-
- contrasted with stop: Event contours: ZAhO and re'u
- finished: Event contours: ZAhO and re'u
- first rat: Special mekso selbri
- firstly: Other uses of mekso
- fish eat: Topic-comment sentences: ZOhU, Topic-comment sentences: ZOhU
- fish on right: Interval sizes: VEhA and ZEhA
- flashbacks in story time: Story time
- fleas: The meaning of tanru: a necessary detour
- flexible vocabulary: brivla
- floating point numbers
-
- expressing: Infix operators revisited
- flow of discourse
-
- managing with discursives: Discursives
- folk quantifiers
-
- expressing: Using Lojban resources within mekso
- font: Alien alphabets, Alien alphabets, Alien alphabets
-
- specifying for letters: Alien alphabets
- food
-
- use of fu'ivla for specific: fu'ivla
- foreman of a jury
-
- example: Personal pro-sumti: the mi-series
- forethought bridi connection
-
- as grammatically one sentence: Forethought bridi connection
- forethought bridi connectives
-
- contrasted with afterthought bridi connectives: Forethought bridi connection
- forethought bridi-tail connection
-
- special rule for tense: Tenses, modals, and logical connection
- forethought connection
-
- contrasted with afterthought for grammatical utterances: Truth questions and connective questions
- definition: Other modal connections
- in abstractions: Abstractor connection and connection within abstractions
- in tenses: Tenses, modals, and logical connection
- observatives: Multiple compound bridi
- of operands: Logical and non-logical connectives within mekso
- of operators: Logical and non-logical connectives within mekso
- forethought connections
-
- modal compared with tense in semantics: Tenses versus modals
- forethought connectives
-
- as ungrammatical utterance: Truth questions and connective questions
- contrasted with afterthought connectives: Forethought bridi connection
- with tense: Tenses, modals, and logical connection
- forethought connectives and bo: Grouping of afterthought connectives
- forethought intervals
-
- GAhO position: Interval connectives and forethought non-logical connection
- forethought logical connectives
-
- within tanru: Logical connection within tanru
- forethought logical connectives in tanru
-
- effect on tanru grouping: Logical connection within tanru
- forethought modal sentence connection: Other modal connections
-
- relation to modal of first bridi in: Other modal connections
- relation to modal of second bridi in: Other modal connections
- forethought modal sentence connection for causals
-
- order of cause and effect: Other modal connections
- forethought tanru connection: Logical connection within tanru
- forethought tense connection
-
- contrasted with afterthought in likeness to modal connection: Tenses versus modals
- forethought tense connection of bridi-tails
-
- order of: Tense relations between sentences
- forethought tense connection of sentences
-
- order of: Tense relations between sentences
- forethought tense connection of sumti
-
- order of: Tense relations between sentences
- forethought termsets
-
- logical connection of: Termset logical connection
- formal requirement: Attitudes as scales, Attitudes as scales, Attitudes as scales, Attitudes as scales, Attitudes as scales, Attitudes as scales
- former market: Sticky and multiple tenses: KI
- former state: Comparatives and superlatives
- formulae
-
- expressing based on pure dimensions: Using Lojban resources within mekso
- four "e"s: References to lerfu
- Four score and seven: Four score and seven: a mekso problem
- fourteen "e"s: What's a letteral, anyway?
- fraction
-
- meaning with elided numerator and denominator: Special numbers
- fractions
-
- expressing with numerical punctuation: Signs and numerical punctuation
- numerator default: Signs and numerical punctuation
- fragmentary text: Miscellaneous indicators
- Frank is a fool: Predication/sentence abstraction, Predication/sentence abstraction
- free modifiers
-
- effects on elidability of terminators: Subscripts
- friend's cup: Relative phrases
- from one to two o'clock: Interval connectives and forethought non-logical connection
- fu'ivla
-
- algorithm for constructing: fu'ivla
- as a subtype of brivla: brivla
- as Stage 3 borrowings: fu'ivla
- as Stage 4 borrowings: fu'ivla
- categorized contrasted with uncategorized in ease of construction: fu'ivla
- considerations for choosing basis word: fu'ivla
- consonant clusters in: fu'ivla
- construction of: fu'ivla
- definition
-
- quick-tour version: Lojban grammatical terms
- diphthongs in: fu'ivla
- disambiguation of: fu'ivla
- form for rafsi fu'ivla proposal: Cultural and other non-algorithmic gismu
- form of: fu'ivla
- initial consonant cluster in: fu'ivla
- method of including in lujvo: rafsi
- quick-tour version: Examples of brivla
- rules for formation of: fu'ivla
- stress in: fu'ivla
- uniqueness of meaning in: fu'ivla
- use of: fu'ivla
- with invalid diphthongs: fu'ivla
- fu'ivla categorizer: fu'ivla
- fully reduced lujvo
-
- definition: rafsi
- function f of x: Mathematical uses of lerfu strings
- function name
-
- lerfu string as: Mathematical uses of lerfu strings
- future event
-
- possible extension into present: Vague intervals and non-specific tenses
- futureward
-
- as a spatial tense: Dimensionality: VIhA
- fuzzy logic and truth-value abstraction: Truth-value abstraction: jei
G
- gadri
-
- definition: The five kinds of simple sumti
- gek
-
- definition: Forethought bridi connection
- gek bridi connectives
-
- contrasted with ijeks: Forethought bridi connection
- geks
-
- connecting operands: Logical and non-logical connectives within mekso
- in forethought sumti connection: sumti connection
- syntax of: Forethought bridi connection
- General American: IPA for English speakers
- general sumti
-
- contrasted with operands: Simple infix expressions and equations
- general terms: Notes on gismu place structures
- German rich man: Grouping of afterthought connectives
- Gettysburg Address: Four score and seven: a mekso problem
- gihek
-
- definition: Compound bridi
- giheks
-
- syntax of: Compound bridi
- gik
-
- as name for compound cmavo: The six types of logical connectives
- definition: Forethought bridi connection
- giks
-
- syntax of: Forethought bridi connection
- girls' school
- gismu
-
- algorithm for: lujvo-making examples
- and cmavo
-
- major: gismu
- as a subtype of brivla: brivla
- as partitioning semantic space: gismu
- basic rafsi for: rafsi
- coined: The gismu creation algorithm
- conflicts between: gismu
- creation
-
- and transcription blunders: The gismu creation algorithm
- considerations for selection after scoring: The gismu creation algorithm
- proscribed gismu pairs: The gismu creation algorithm
- scoring rules: The gismu creation algorithm
- cultural: Cultural and other non-algorithmic gismu
- definition: gismu
-
- quick-tour version: Lojban grammatical terms
- ethnic: Cultural and other non-algorithmic gismu
- examples of: gismu
- exceptions to gismu creation by algorithm: The gismu creation algorithm
- for countries: Cultural and other non-algorithmic gismu
- for languages: Cultural and other non-algorithmic gismu
- for Lojban source languages: Cultural and other non-algorithmic gismu
- geographical: Cultural and other non-algorithmic gismu
- length of: gismu
- level of uniqueness of rafsi relating to: rafsi
- Lojban-specific: The gismu creation algorithm
- place order
-
- rationale: Notes on gismu place structures
- place structures: Notes on gismu place structures
-
- rationale: Notes on gismu place structures
- quick-tour version: Examples of brivla
- rationale for choice of: gismu
- religious: Cultural and other non-algorithmic gismu
- rules for: gismu
- scientific-mathematical: Cultural and other non-algorithmic gismu
- selection of: gismu
- source of: gismu
- source-language weights for: The gismu creation algorithm
- special: gismu
- too-similar: The gismu creation algorithm
- give: The concept of the bridi, The concept of the bridi, The concept of the bridi
- give or receive: Tagging places: FA
- giving the horse: Property abstractions
- glottal stop
-
- as pause in Lojban: The special Lojban characters
- glue in lujvo
- go: Standard bridi form: cu
- go to Boston from Atlanta: Standard bridi form: cu
- go to market: Introductory
- go to Paris or Rome: Logical connectives and DeMorgan's law
- go to the store: What are the typographical conventions of this book?
- go-er: Conversion: SE
- goal of this book: What is this book?
- goer table: Simple tanru
- goer-house
- good house: Linked sumti: be - bei - be'o
- grammatical categories
-
- use of upper case for: What are the typographical conventions of this book?
- grammatical terms
-
- quick-tour version: Lojban grammatical terms
- grasp water: Other modal connections
- great soldier: Symmetrical and asymmetrical lujvo, Ordering lujvo places.
- Greek alphabet
-
- language shift word for: Alien alphabets
- Greek aorist tense
-
- compared with Lojban tense: Vague intervals and non-specific tenses
- Greek-Americans own restaurants: Descriptors for typical objects
- grouping
-
- of connection in abstractions: Abstractor connection and connection within abstractions
- of connection in tenses: Tenses, modals, and logical connection
- grouping parentheses: Complex tanru with ke and ke'e
- guhek
-
- definition: Logical connection within tanru
- guheks
-
- connecting operators: Logical and non-logical connectives within mekso
- syntax of: Logical connection within tanru
- guheks for tanru connection
-
- rationale: Logical connection within tanru
H
- had earlier: Sticky and multiple tenses: KI
- hands in pockets: Relative phrases
- handwriting: Alien alphabets
- hanzi: What about Chinese characters?
- happiness: Abstraction focus pro-sumti: ce'u
- happy face
-
- example: The universal bu
- has a heart: Property abstractions
- have never: Interval properties: TAhE and roi
- having
-
- of properties: Property abstractions
- healthy: Questions, Questions, Questions, Questions, Questions
- hearsay
-
- example: Evidentials
- heartburn
-
- example: Miscellaneous indicators
- Hebrew alphabet
-
- language shift word for: Alien alphabets
- hepatitis: rafsi, rafsi
- hereafter known as
- hesitation sound: Hesitation: Y
- hexadecimal system
-
- specifying numbers in (see also base): Non-decimal and compound bases
- hierarchy of priorities for selecting lujvo form: The lujvo scoring algorithm
- hiragana: Alien alphabets
-
- contrasted with kanji: What about Chinese characters?
- hit cousin: Discursives, Discursives, Discursives, Discursives
- hit nose: Discursives, Discursives, Discursives, Discursives
- hits: The concept of the bridi
- Hollywood: Descriptors for typical objects
- hospitality
-
- example: Vocative scales
- hours
-
- example of timestamp: Non-decimal and compound bases
- huh?: Miscellaneous indicators
- hundred
-
- expressing as number: Lojban numbers
- husband and wife: Evidentials
- hyphen letter
-
- definition: rafsi
- hyphens
-
- use of: rafsi
- hyphens in lujvo
-
- proscribed where not required: The lujvo-making algorithm
- hypothetical world: Propositional attitude indicators
-
- contrasted with real world
-
- example: Discursives
- hypothetical world point of view: Discursives
I
- IBM: Acronyms
- ICAO Phonetic Alphabet
-
- proposed lerfu words for: Proposed lerfu words for radio communication
- idea abstraction: Minor abstraction types
- idea abstractions
-
- place structure: Minor abstraction types
- identity
-
- expressing with "po'u": Relative phrases
- identity predicate: The identity predicate: du
- if
-
- English usage contrasted with Lojban logical connective: Logical connection of bridi
- expressing hypothetical world: Discursives
- expressing real world: Discursives
- meaning in logical connections: Logical connection of bridi
- if coffee
-
- bring tea: Truth questions and connective questions
- if … then
-
- compared with English "only if": Logical connection of bridi
- logical connectives contrasted with other translations: Forethought bridi connection
- ijek
-
- definition: The six types of logical connectives
- ijek bridi connectives
-
- contrasted with geks: Forethought bridi connection
- ijek logical connectives
-
- connecting bridi: Logical connection of bridi
- ijeks
-
- syntax of: Logical connection of bridi
- ijoik
-
- as name for compound cmavo: The six types of logical connectives
- definition: More about non-logical connectives
- imaginary journey
-
- and spatial tense: Spatial tenses: FAhA and VA
- ending point: Spatial tenses: FAhA and VA
- origin in tense forethought bridi-tail connection: Tense relations between sentences
- origin in tense forethought sentence connection: Tense relations between sentences
- origin in tense forethought sumti connection: Tense relations between sentences
- origin of in tense-connected sentences: Tense relations between sentences
- stages of in compound tenses: Compound spatial tenses
- starting at a different point: Tenses as sumtcita
- starting point: Spatial tenses: FAhA and VA, Tenses as sumtcita
- with interval direction: Interval sizes: VEhA and ZEhA
- imaginary journey origin
-
- with sticky tenses: Sticky and multiple tenses: KI
- imperatives
-
- and truth: Truth questions and connective questions
- attitude: Attitudinal modifiers
- English contrasted with Lojban in presence of subject of command: Personal pro-sumti: the mi-series
- quick-tour version: Vocatives and commands
- with "ko": Personal pro-sumti: the mi-series
- implausible: Eliding SE rafsi from seltau
- implicit quantifier
-
- for quotations: Quantified sumti
- on quotations
-
- discussion of: Quantified sumti
- importance of point
-
- scale with "ra'u": Discursives
- in the aftermath: Tenses as sumtcita
- inalienable
-
- distinguishing from alienable: Relative phrases
- inalienable possession
-
- definition: Relative phrases
- expressing with "po'e": Relative phrases
- inchoative event contour: Event contours: ZAhO and re'u
- incidental association
-
- expressing with "ne": Relative phrases
- incidental identification
-
- expressing with "no'u": Relative phrases
- incidental relative clause
-
- as a parenthetical device: Incidental relative clauses
- definition: Incidental relative clauses
- inclusion
-
- property of sets: Masses and sets
- indefinite description
-
- as needing explicit outer quantifier: Indefinite descriptions
- as prohibiting explicit inner quantifier: Indefinite descriptions
- compared with restricted variable: Variables with generalized quantifiers
- definition: Indefinite descriptions, Variables with generalized quantifiers
- indefinite numbers
-
- combined with definite: Indefinite numbers
- indefinite portions
-
- subjective: Indefinite numbers
- indefinite pro-bridi: Indefinite pro-sumti and pro-bridi: the zo'e-series and the co'e-series
-
- stability of: Pro-sumti and pro-bridi cancelling
- indefinite pro-sumti: Pro-sumti summary, Indefinite pro-sumti and pro-bridi: the zo'e-series and the co'e-series
-
- implicit quantifier for: Pro-sumti summary
- stability of: Pro-sumti and pro-bridi cancelling
- indefinite sumti
-
- as implicit quantification: Using naku outside a prenex
- compared to sumti with "lo": Grouping of quantifiers
- meaning when multiple in sentence: Grouping of quantifiers
- multiple in sentence: Grouping of quantifiers
- indefinite values
-
- subjective: Indefinite numbers
- indicator scope: Paragraphs: NIhO
- indicators: What are attitudinal indicators?
-
- evolutionary development of: Tentative conclusion
- grammar for compounding: Compound indicators
- meaning when compounded: Compound indicators
- placement of: Propositional attitude indicators
- quick-tour version: Indicators
- ramifications: Tentative conclusion
- rationale for selection: Tentative conclusion
- scope effect of new paragraph: Paragraphs: NIhO
- types of: What are attitudinal indicators?
- indirect question: Miscellaneous indicators
- indirect question involving sumti: Indirect questions
- indirect questions
-
- "ma kau" contrasted with "la .djan. kau": Indirect questions
- indirect questions without "kau": Indirect questions
- indisputable bridi: Evidentials
- individual: Special mekso selbri
- individual descriptors
-
- different implicit outer quantifiers among: Quantified descriptions
- individual objects
-
- multiple: Individuals and masses
- individuals
-
- expressing relation with mass formed: Special mekso selbri
- expressing relation with set formed: Special mekso selbri
- individuals into mass
-
- by non-logical connection: Non-logical connectives
- individuals into set
-
- by non-logical connection: Non-logical connectives
- individuals of set
-
- expressing measurement standard for indefinites: Special mekso selbri
- indivisible: Types of event abstractions
- induction
-
- example: Evidentials
- inexact numbers with bounds: Approximation and inexact numbers
- inexact portions with bounds: Approximation and inexact numbers
- infant ducks: Actuality, potentiality, capability: CAhA
- inferior: Attitudinal modifiers
- infinity: Special numbers
- infix notation mixed with Polish: Logical and non-logical connectives within mekso
- inflammable: Actuality, potentiality, capability: CAhA
- initial consonant pairs
-
- list of: Initial consonant pairs
- initiative event contour: Event contours: ZAhO and re'u
- innate capabilities
-
- expressing implicitly: Actuality, potentiality, capability: CAhA
- innate capability
-
- expressing explicitly: Actuality, potentiality, capability: CAhA
- innate properties
-
- extension of from mass to individuals: Actuality, potentiality, capability: CAhA
- extension to individuals not actually capable: Actuality, potentiality, capability: CAhA
- inner product: Vectors and matrices
- inner quantifier
-
- contrasted with outer quantifier: Quantified descriptions
- definition: Quantified descriptions
- effect of on meaning: Quantified descriptions
- explicit: Quantified descriptions
- implicit on descriptors: Quantified descriptions
- in indefinite description: Indefinite descriptions
- inner sumti
-
- referring to from within relative clause within relative clause: Relative clauses within relative clauses
- integral
- interactions between quantifiers and negation
-
- effect: Negation boundaries
- interjections
-
- quick-tour version: Indicators
- intermediate abstraction: Lojban sumti raising
- intermittently: Interval properties: TAhE and roi
- internal bridi negation
-
- compared to external bridi negation: Negation boundaries
- definition: Negation boundaries
- internal naku negations
-
- and DeMorgan's Law: Logical connectives and DeMorgan's law
- internal world: Propositional attitude indicators
- International Phonetic Alphabet (see also IPA): Basic phonetics
- intersect: Minor abstraction types
- intersection
-
- of sets: More about non-logical connectives
- intersection of sets
-
- compared with English "and": More about non-logical connectives
- interval
-
- closed: Interval connectives and forethought non-logical connection
- followed by direction in tense construct: Interval sizes: VEhA and ZEhA
- inclusion of endpoints: Interval connectives and forethought non-logical connection
- open: Interval connectives and forethought non-logical connection
- relation to point specified by direction and distance: Interval sizes: VEhA and ZEhA
- relative order with direction and distance in tense: Interval sizes: VEhA and ZEhA
- specifying relation to point specified by direction and distance: Interval sizes: VEhA and ZEhA
- interval continuousness
-
- meaning as sumtcita: Tenses as sumtcita
- interval direction
-
- specifying: Interval sizes: VEhA and ZEhA
- interval properties
-
- meaning as sumtcita: Tenses as sumtcita
- strings of: Sub-events
- interval size
-
- as context-dependent: Interval sizes: VEhA and ZEhA
- meaning as sumtcita: Tenses as sumtcita
- unspecified: Vague intervals and non-specific tenses
- vague: Vague intervals and non-specific tenses
- interval spread
-
- expressing English "intermittently": Interval properties: TAhE and roi
- mutually contrasted: Interval properties: TAhE and roi
- negation with "nai": Interval properties: TAhE and roi
- with unspecified interval: Interval properties: TAhE and roi
- intervals
-
- effect of "nai" on: Interval connectives and forethought non-logical connection
- expressed as center and distance: Interval connectives and forethought non-logical connection
- expressed as endpoints: Interval connectives and forethought non-logical connection
- expressing by endpoints with "bi'o": Logical and non-logical connections between tenses
- forethought: Interval connectives and forethought non-logical connection
- spread of actions over: Interval properties: TAhE and roi
- intrinsic possession
-
- definition: Relative phrases
- expressing by using place in some selbri: Relative phrases
- expressing with "po'e": Relative phrases
- introduce oneself: Vocative scales
- invalid diphthongs
-
- in fu'ivla: fu'ivla
- invalid speech
-
- marking as error with "na'i": Miscellaneous indicators
- inversion of quantifiers
-
- definition: Negation boundaries
- in moving negation boundary: Negation boundaries
- inversion of quantifiers on passing negation boundary
-
- rationale for: Negation boundaries
- invertebrate: Eliding KE and KEhE rafsi from lujvo
- inverted tanru
-
- effect on sumti after the selbri: Inversion of tanru: co
- effect on sumti before the selbri: Inversion of tanru: co
- inverting quantifiers
-
- with movement relative to "naku": Using naku outside a prenex
- with movement relative to fixed negation: Using naku outside a prenex
- IPA: Basic phonetics
- IPA pronunciation
-
- description: IPA for English speakers
- irony
-
- example: Discursives
- expressing: Discursives
- irrational number: Relative clauses and complex sumti: vu'o
- irrelevant
-
- specifying of sumti place: Indefinite pro-sumti and pro-bridi: the zo'e-series and the co'e-series
- isomorphism
-
- audio-visual: Orthography
- IT
-
- as notation convention in relative clause chapter: What are you pointing at?
- italic
-
- example: Alien alphabets
- iy diphthong
-
- in cmevla: cmevla
J
- j-sound in English
-
- representation in Lojban: Basic phonetics
- James: Consonant clusters
- Jane: cmevla
- Japanese hiragana: Alien alphabets
- Japanese katakana: Alien alphabets
- jargon
-
- use of fu'ivla for: fu'ivla
- jek
-
- definition: The six types of logical connectives
- jeks
-
- connecting abstractors: Abstractor connection and connection within abstractions
- connecting operators: Logical and non-logical connectives within mekso
- syntax of: Logical connection within tanru
- Jesus: Minor abstraction types, Minor abstraction types
- Jim: cmevla
- John and Sam: The concept of the bridi, The concept of the bridi, The concept of the bridi
- John Brown: cmevla, cmevla
- John is coming: What are attitudinal indicators?, What are attitudinal indicators?, What are attitudinal indicators?, What are attitudinal indicators?, What are attitudinal indicators?
- John Paul Jones: Lojban names
- John says that George goes to market: Tenses in subordinate bridi
- joigik
-
- as name for compound cmavo: The six types of logical connectives
- definition: Interval connectives and forethought non-logical connection
- joigiks
-
- connection types: Interval connectives and forethought non-logical connection
- syntax of: Interval connectives and forethought non-logical connection
- joik
-
- as name for compound cmavo: The six types of logical connectives
- definition: Non-logical connectives
- joiks
-
- effect of "nai" on: More about non-logical connectives
- grouping: More about non-logical connectives
- syntax of: Interval connectives and forethought non-logical connection
- use of "se" in: Non-logical connectives
- jokes: What is this book?
- Jupiter life: Abstractor connection and connection within abstractions
- juror number 5: Possessive sumti
K
- kanji
-
- contrasted with alphabets and syllabaries: What about Chinese characters?
- representing based on romaji spelling: What about Chinese characters?
- representing based on strokes: What about Chinese characters?
- katakana: Alien alphabets
- Kate: cmevla
- Katrina: cmevla
- kept on too long: Event contours: ZAhO and re'u
- killing Jim: Types of event abstractions, Types of event abstractions
- kissing Jane: Event abstraction
- know: Predication/sentence abstraction
- know who: Indirect questions
-
- contrasted with know that: Indirect questions
- knowledge discursives: Discursives
-
- compared with propositional attitudes: Discursives
- Korean: fu'ivla, fu'ivla
- Kzinti
-
- communication with: Tentative conclusion
L
- l-hyphen
-
- use of: fu'ivla
- Láadan evidentials: Evidentials
- Lady: cmevla
- lambda calculus
-
- operator and operand distinction in: Miscellany
- language shift
-
- based on name + "bu": Alien alphabets
- choice of Lojban-lerfu-word counterpart: Alien alphabets
- compound: Alien alphabets
- effect on following words: Alien alphabets
- formation of shift alphabet name: Alien alphabets
- interaction with "bu": Alien alphabets
- rationale for: Alien alphabets
- standardization of: Alien alphabets
- large meal: Attitudinal modifiers
- large-base decimal fraction
-
- expressing: Non-decimal and compound bases
- latent component: Anomalous lujvo
- Latin
-
- alphabet of Lojban: What's a letteral, anyway?
- Latin alphabet: Orthography
-
- language shift word for: Alien alphabets
- learning Lojban
-
- magnitude of task: gismu
- left-grouping rule
-
- definition of: Three-part tanru grouping with bo
- legal jargon
- legal system: Truth-value abstraction: jei
- lemon tree: Simple tanru
- Length × Width × Depth = Volume: Using Lojban resources within mekso
- Lepidoptera: tanru
- lerfu
-
- as assignable pro-sumti: Assignable pro-sumti and pro-bridi: the ko'a-series and the broda-series
- contrasted with lerfu word: What's a letteral, anyway?
- definition: What's a letteral, anyway?
- reference to: References to lerfu
- referring to with "me'o": References to lerfu
- lerfu as pro-sumti
-
- contrasted with ko'a-series in explicit assignment of: Assignable pro-sumti and pro-bridi: the ko'a-series and the broda-series
- explicit assignment of antecedent: Assignable pro-sumti and pro-bridi: the ko'a-series and the broda-series
- implicit assignment of antecedent: Assignable pro-sumti and pro-bridi: the ko'a-series and the broda-series
- lerfu juxtaposition interpretation
-
- contrasted with mathematical interpretation: Mathematical uses of lerfu strings
- lerfu shift scope
-
- exception for mathematical texts: Mathematical uses of lerfu strings
- lerfu string
-
- as function name: Mathematical uses of lerfu strings
- as mathematical variable: Mathematical uses of lerfu strings
- as pro-sumti: lerfu words as pro-sumti
-
- assumption of reference: lerfu words as pro-sumti
- as pro-sumti assigned by "goi": lerfu words as pro-sumti
- as quantifier: Mathematical uses of lerfu strings
- as selbri: Mathematical uses of lerfu strings
- as subscript: Mathematical uses of lerfu strings
- as utterance ordinal: Mathematical uses of lerfu strings
- definition: lerfu words as pro-sumti
- interpretation
-
- contrasted with mathematical interpretation: Mathematical uses of lerfu strings
- lerfu strings
-
- as acronyms using "me": Acronyms
- as pro-sumti
-
- for multiple sumti separated by boi: lerfu words as pro-sumti
- as quantifiers
-
- avoiding interaction with sumti quantified: Mathematical uses of lerfu strings
- in mathematical expressions: Simple infix expressions and equations
- interpretation of contrasted with normal mathematical interpretation: Simple infix expressions and equations
- uses in mathematics: Mathematical uses of lerfu strings
- with numerical selbri: Special mekso selbri
- lerfu word
-
- contrasted with lerfu: What's a letteral, anyway?
- for "'": A to Z in Lojban, plus one
- lerfu word cmavo
-
- list of auxiliary: List of all auxiliary lerfu-word cmavo
- lerfu word set extension
-
- with bu: The universal bu
- lerfu words
-
- as a basis for acronym names: Acronyms
- composed of compound cmavo: A to Z in Lojban, plus one
- composed of single cmavo: A to Z in Lojban, plus one
- consonant words contrasted with vowel words: A to Z in Lojban, plus one
- effect of systematic formulation: A to Z in Lojban, plus one
- for consonants: A to Z in Lojban, plus one
- for vowels: A to Z in Lojban, plus one
- formation rules: A to Z in Lojban, plus one
- forming new for non-Lojban letters using "bu": Accent marks and compound lerfu words
- list of proposed
-
- notation convention: Proposed lerfu words – introduction
- Lojban coverage requirement: A to Z in Lojban, plus one
- proposed for accent marks: Proposed lerfu words for some accent marks and multiple letters
- proposed for Cyrillic alphabet: Proposed lerfu words for the Cyrillic alphabet
- proposed for diacritic marks: Proposed lerfu words for some accent marks and multiple letters
- proposed for multiple letters: Proposed lerfu words for some accent marks and multiple letters
- proposed for noisy environments: Proposed lerfu words for radio communication
- proposed for radio communication: Proposed lerfu words for radio communication
- table of Lojban: A to Z in Lojban, plus one
- using computer encoding schemes with "se'e": Computerized character codes
- vowel words contrasted with consonant words: A to Z in Lojban, plus one
- lerfu words ending with "y"
-
- pause after
-
- rationale: A to Z in Lojban, plus one
- lerfu words for vowels
-
- pause requirement before: A to Z in Lojban, plus one
- lerfu words with numeric digits
-
- grammar considerations: What about Chinese characters?
- lervla
-
- contrasted with lerfu: What's a letteral, anyway?
- less
-
- English word "less"
-
- expressing with relative phrases: Modal relative phrases; Comparison
- importance of relative phrase to: Modal relative phrases; Comparison
- less than: Approximation and inexact numbers
-
- contrasted with more than
-
- at least, at most: Approximation and inexact numbers
- less than two: Approximation and inexact numbers
- letter
-
- alphabet: What's a letteral, anyway?
- contrasted with word for the letter: What's a letteral, anyway?
- letter encoding schemes
-
- application to lerfu words: Computerized character codes
- letteral
-
- definition: What's a letteral, anyway?
- letters
-
- non-Lojban
-
- representation of diacritical marks on: Accent marks and compound lerfu words
- representation with consonant-word + bu: Alien alphabets
- representation with consonant-word + bu, drawback: Alien alphabets
- representation with language-shift: Alien alphabets
- representation with names: Alien alphabets
- sound contrasted with symbol for spelling: Alien alphabets
- symbol contrasted with sound for spelling: Alien alphabets
- likes more than: Modal relative phrases; Comparison, Modal relative phrases; Comparison, Modal relative phrases; Comparison, Modal relative phrases; Comparison
- lined up: Eliding SE rafsi from seltau
- linguistic behavior: Predication/sentence abstraction
- linguistic drift: What is this book?
- linguistic drift in Lojban
-
- possible source of: Considerations for making lujvo
- linked arguments: Questions and answers
- linked sumti
-
- definition: Linked sumti: be - bei - be'o
- in tanru: Linked sumti: be - bei - be'o
- linked sumti and FA tags: Linked sumti: be - bei - be'o
- linked sumti and sumtcita: Linked sumti: be - bei - be'o
- Linnaean names
-
- rules for: cmevla
- lion in Africa: Descriptors for typical objects
- lions in Africa: Individuals and masses
- list: Non-logical connectives
-
- as a physical object: Non-logical connectives
- contrasted with sequence: Non-logical connectives
- list of things to do: More about non-logical connectives
- listen attentively: Symmetrical and asymmetrical lujvo
- lists
-
- use of "tu'e"/"tu'u" in: More about non-logical connectives
- literally: Miscellaneous indicators
- living things: Indefinite pro-sumti and pro-bridi: the zo'e-series and the co'e-series
- Livingston: Evidentials
- LLG: Acknowledgements and credits
- logic
-
- and attitudinals: What's wrong with this picture?
- limits of: What's wrong with this picture?
- resolving ambiguities of "nobody": What's wrong with this picture?
- logic and Lojban
-
- more aspects: Conclusion
- logical connection
-
- effect on elidability of "lo'o": Logical and non-logical connectives within mekso
- grouping strategies for complex cases contrasted: Grouping of afterthought connectives
- in abstractions
-
- inner bridi contrasted with outer bridi: Abstractor connection and connection within abstractions
- in mathematical expressions: Logical and non-logical connectives within mekso
- in tanru
-
- contrasted with unconnected version: Logical connection within tanru
- expandability of: Logical connection within tanru
- grouping with bo: Logical connection within tanru
- grouping with ke: Logical connection within tanru
- inside abstractions
-
- contrasted with outside: Abstractor connection and connection within abstractions
- interaction with tenses: Tenses, modals, and logical connection
- negation in connecting more than 2 sentences: More than two propositions
- of bridi-tail as opposed to tanru: Logical connection within tanru
- of bridi-tails
-
- forethought: Multiple compound bridi
- restriction on ke: Multiple compound bridi
- of forethought termsets: Termset logical connection
- of modals: Logical and non-logical connection of modals
- of more than 2 sentences
-
- all or none: More than two propositions
- forethought: More than two propositions
- things to avoid: More than two propositions
- of observatives
-
- relation of first places: Compound bridi
- of selbri: Compound bridi
- of sumti
-
- grouping with parentheses: Grouping of afterthought connectives
- restriction on ke: Grouping of afterthought connectives
- of tanru
-
- caveat: Logical connection within tanru
- of tanru as opposed to bridi-tail: Logical connection within tanru
- termsets: Termset logical connection
- transformation between forms: sumti connection
- with "bo"
-
- precedence: Grouping of afterthought connectives
- logical connection of abstractors: Abstractor connection and connection within abstractions
- logical connection of more than 2 sentences
-
- mixed "and" and "or": More than two propositions
- logical connectives: Logical connection and truth tables
-
- associative: More than two propositions
- bridi-tail connection: Compound bridi
- cmavo
-
- format for each selma'o: The six types of logical connectives
- effect on elidability of "ge'u" from preceding relative phrase: Relative phrases
- equivalence relation on 3 sentences: More than two propositions
- grouping with "bo": Grouping of afterthought connectives
- in tanru: Logical connection within tanru
- more than 2 sentences: More than two propositions
- negated first sentence as a potential problem for understanding: Forethought bridi connection
- non-associative: More than two propositions
- observative sentence connection: Compound bridi
- pairing from left: More than two propositions
- rationale for multiple sets in grammar: The six types of logical connectives
- recipes
-
- simplified for logic chapter discussion: bridi negation and logical connectives
- relation to truth functions: The four basic vowels
- relative precedence with "me'u": selbri based on sumti: me
- right-grouping with bo: Grouping of afterthought connectives
- selma'o
-
- enumerated: The six types of logical connectives
- syntax rules summary: Rules for making logical and non-logical connectives
- table by truth function value: Truth functions and corresponding logical connectives
- tensed: Tensed logical connectives
- logical connectives and bridi negation: bridi negation and logical connectives
- logical connectives and negation
-
- caveat for logic chapter discussions: bridi negation and logical connectives
- logical connectives in tanru: Logical connection within tanru
-
- ambiguity of: Logical connection within tanru
- effect on formal logical manipulations: Logical connection within tanru
- effect on tanru grouping: Logical connection within tanru
- usefulness of: Logical connection within tanru
- logical connectives within negation
-
- effects of expansion on: Logical connectives and DeMorgan's law
- logical language
-
- truth functions: Logical connection and truth tables
- Logical Language Group
-
- example: lujvo-making examples
- relation to Lojban: What is Lojban?
- logical variables
-
- creating more by subscripting: A few notes on variables
- effect of global substitution: Existential claims, prenexes, and variables
- effect of order in prenex: Universal claims
- effect of using multiple different: Existential claims, prenexes, and variables
- explicitly placing in outer prenex: The problem of “any”
- for selbri: selbri variables
- implicit placement in smallest enclosing bridi prenex: The problem of “any”
- notation convention: Existential claims, prenexes, and variables
- when not in main bridi: Existential claims, prenexes, and variables
- with "poi"
-
- in multiple appearances: Dropping the prenex
- with "ro"
-
- in multiple appearances: Dropping the prenex
- with multiple appearances in bridi: Existential claims, prenexes, and variables
- logically connected sentences
-
- and DeMorgan's Law: Logical connectives and DeMorgan's law
- logically connected tenses
-
- definition: Tenses, modals, and logical connection
- expansion to sentences: Logical and non-logical connections between tenses
- with JA: Logical and non-logical connections between tenses
- Loglan: Informal bibliography
- logograms
-
- words for: The universal bu
- Lojban
-
- features of: What is Lojban?
- history of: What is Lojban?
- stability of: What is this book?
- Lojban alphabet: Orthography
- Lojban letters
-
- IPA for pronouncing: Basic phonetics
- list with IPA pronunciation: Basic phonetics
- Lojbanistan: What is this book?
- long ago and far away: Temporal tenses: PU and ZI
- long rafsi
-
- definition: rafsi
- long rafsi form
-
- compared with short form in effect on lujvo meaning: lujvo
- long-sword: lujvo with more than two parts.
- loose association
-
- expressing with "pe": Relative phrases
- Lord: cmevla
- love more: Property abstractions
- lower case letters
-
- use in Lojban: Upper and lower cases
- lower-case
-
- lerfu word for: Upper and lower cases
- lower-case letters
-
- English usage contrasted with Lojban: Upper and lower cases
- Lojban usage contrasted with English: Upper and lower cases
- lower-case word
-
- effect on following lerfu words: Upper and lower cases
- lujvo
-
- "zi'o" rafsi effect on place structure of: lujvo based on pro-sumti
- abbreviated: Eliding SE rafsi from seltau
- abstract: Abstract lujvo
- algorithm for: The lujvo-making algorithm
- and consonant pairs: rafsi
- and plausibility: Considerations for making lujvo
- and seltau/tertau relationship: The meaning of lujvo
- and the listener: Considerations for making lujvo
- as a subtype of brivla: brivla
- as suppliers of agent place: Notes on gismu place structures
- asymmetrical: Symmetrical and asymmetrical lujvo
- based on multiple tanru: Considerations for making lujvo
- cmavo incorporation: Why have lujvo?
- comparatives: Comparatives and superlatives
- compared with tanru: Why have lujvo?
- consideration in choosing meaning for: Considerations for making lujvo
- considerations for retaining elements of: Considerations for making lujvo
- construction of: lujvo
- definition
-
- quick-tour version: Lojban grammatical terms
- design consideration for relationship: The meaning of lujvo
- dropping elements of: Considerations for making lujvo
- dropping SE rafsi: Eliding SE rafsi from seltau
- examples of making: The lujvo scoring algorithm
- from cmavo with no rafsi: rafsi
- from tanru: lujvo
- fully reduced: rafsi
- guidelines for place structure: Why have lujvo?
- interpreting: The meaning of lujvo
- invention of: lujvo
- meaning drift of: Considerations for making lujvo
- meaning of: lujvo
- multiple forms of: lujvo
- place structure of figurative lujvo: Miscellaneous indicators
- pro-sumti rafsi effect on place structure of: lujvo based on pro-sumti
- quick-tour version: Examples of brivla
- rationale for: Why have lujvo?
- recognizing: rafsi
- rules for formation of: lujvo
- scored examples of: The lujvo scoring algorithm
- scoring of: The lujvo-making algorithm
- selection of best form of: The lujvo-making algorithm
- shorter for more general concepts: Considerations for making lujvo
- summary of form characteristics: rafsi
- superlatives: Comparatives and superlatives
- symmetrical: Symmetrical and asymmetrical lujvo
- ultimate guideline for choice of meaning/place-structure: Considerations for making lujvo
- unambiguity of: Considerations for making lujvo
- unambiguous decomposition of: lujvo
- unreduced: rafsi
- unsuitability of for concrete/specific terms and jargon: fu'ivla
- with zei: rafsi
- lujvo creation
-
- interaction of KE with NAhE: Eliding KE and KEhE rafsi from lujvo
- interaction of KE with SE: Eliding KE and KEhE rafsi from lujvo
- use of multiple SE in: Eliding KE and KEhE rafsi from lujvo
- lujvo form
-
- consonant cluster requirement in: rafsi
- final letter of: rafsi
- hierarchy of priorities for selection of: The lujvo scoring algorithm
- number of letters in: rafsi
- requirements for hyphen insertion in: rafsi
- requirements for n-hyphen insertion in: rafsi
- requirements for r-hyphen insertion in: rafsi
- requirements for y-hyphen insertion in: rafsi
- lujvo place order: Ordering lujvo places.
-
- asymmetrical lujvo: Ordering lujvo places.
- based on 3-or-more part veljvo: lujvo with more than two parts.
- comparatives: Comparatives and superlatives
- rationale for standardization: Ordering lujvo places.
- superlatives: Comparatives and superlatives
- superlatives as exceptions: Comparatives and superlatives
- symmetrical lujvo: Ordering lujvo places.
- lujvo place structure
-
- "ni" lujvo: Abstract lujvo
- "nu" lujvo: Abstract lujvo
- basis of: Selecting places
- comparative lujvo: Comparatives and superlatives
- cross-dependent places: Dependent places
- dependent places: Dependent places
- dropping "KE": Eliding KE and KEhE rafsi from lujvo
- dropping "KEhE": Eliding KE and KEhE rafsi from lujvo
- dropping cross-dependent places: Dependent places
- dropping dependent places
-
- caveat: Dependent places
- dropping dependent seltau places: Dependent places
- dropping dependent tertau places: Dependent places
- dropping redundant places: The meaning of lujvo
- effect of "SE": Symmetrical and asymmetrical lujvo
- effect of "SE"-dropping in tertau: Eliding SE rafsi from tertau
- explicated walk-through: The meaning of lujvo
- guidelines: Why have lujvo?
- multi-place abstraction lujvo: Abstract lujvo
- notation conventions: The meaning of lujvo
- rationale for standardization: Selecting places
- selecting tertau: Dependent places
- superlatives: Comparatives and superlatives
- when first place redundant with non-first: Symmetrical and asymmetrical lujvo
- when first places redundant: Symmetrical and asymmetrical lujvo
- when first places redundant plus others: Symmetrical and asymmetrical lujvo
- lukewarm food: sumti qualifiers
M
- magic square: Vectors and matrices
- male sexual teacher
-
- example: lujvo-making examples
- man biting dog: Spatial tenses: FAhA and VA
- man or woman: Logical connection and truth tables
- man-woman: Logical connection within tanru
- manhole: Compound spatial tenses
- manysome: Special mekso selbri
- maple sugar: fu'ivla
- maple trees: fu'ivla
- marathon: Types of event abstractions
- Mars road
-
- example: Conversion: SE
- mass
-
- compared with set as abstract of multiple individuals: Masses and sets
- contrasted with ordered sequence: Non-logical connectives
- contrasted with set in attribution of component properties: Masses and sets
- contrasted with set in distribution of properties: Non-logical connectives
- expressing measurement standard for indefinites: Special mekso selbri
- expressing relation with individuals forming: Special mekso selbri
- expressing relation with set forming: Special mekso selbri
- joining elements into a mass: Non-logical connectives
- mass contrasted with components
-
- in properties of: Non-logical connectives
- mass name
-
- use of: Individuals and masses
- mass object
-
- and logical reasoning: Individuals and masses
- as dependent on intention: Individuals and masses
- contrasted with multiple individual objects: Individuals and masses
- properties of: Individuals and masses
- mass objects
-
- peculiarities of English translation of: Individuals and masses
- masses
-
- rule for implicit outer quantifier: Quantified descriptions
- mathematical equality
-
- expressing: Simple infix expressions and equations
- mathematical expression
-
- referring to: Other uses of mekso
- mathematical expressions
-
- connectives in: Logical and non-logical connectives within mekso
- implicit quantifier for: Number summary
- tensed connection in: Tenses, modals, and logical connection
- mathematical expressions in tanru: Other kinds of simple selbri
- mathematical intervals: Logical and non-logical connectives within mekso
- mathematical notation
-
- and omitted operators: Introductory
- and operator precedence: Simple infix expressions and equations
- infix: Simple infix expressions and equations
- international uniqueness of: Introductory
- mathematical operators: Simple infix expressions and equations
- mathematical texts
-
- effect on lerfu shift scope: Mathematical uses of lerfu strings
- mathematical variables
-
- lerfu strings as: Mathematical uses of lerfu strings
- mathematics
-
- use of lerfu strings in: Mathematical uses of lerfu strings
- matrices
-
- use as operands: Vectors and matrices
- use of parentheses with: Vectors and matrices
- matrix
-
- as combination of vectors: Vectors and matrices
- definition: Vectors and matrices
- with "ge'a" for more than 2 rows/columns: Vectors and matrices
- with more than 2 dimensions: Vectors and matrices
- matrix column operator: Vectors and matrices
- matrix row operator: Vectors and matrices
- Mayan mathematics
-
- as a system with base larger than 16: Non-decimal and compound bases
- measurements
-
- expressing: Simple infix expressions and equations
- meat slice: Eliding KE and KEhE rafsi from lujvo
- medieval weapon: lujvo with more than two parts.
- mei
-
- place structure formed for objective indefinites: Special mekso selbri
- mekso
-
- and literary translation: Four score and seven: a mekso problem
- complex used as quantifier: Logical and non-logical connectives within mekso
- design goals: Introductory
- mekso chapter
-
- completeness: Introductory
- table notation convention: Introductory
- mekso goal
-
- coverage: Introductory
- expandable: Introductory
- for common use: Introductory
- for mathematical writing: Introductory
- precision: Introductory
- unambiguous: Introductory
- mekso goals
-
- and ambiguity: Introductory
- and non-mathematical expression: Introductory
- mathematical notation form: Introductory
- melting: Notes on gismu place structures
- membership
-
- property of sets: Masses and sets
- mental activity: Predication/sentence abstraction
- mental discomfort
-
- example: Emotional categories
- metalinguistic comment
-
- with embedded discursive: Parenthesis and metalinguistic commentary: TO, TOI, SEI
- metalinguistic levels: Parenthesis and metalinguistic commentary: TO, TOI, SEI
- metalinguistic levels or reference: Parenthesis and metalinguistic commentary: TO, TOI, SEI
- metalinguistic pro-sumti: Pro-sumti summary
-
- implicit quantifier for: Pro-sumti summary
- metalinguistic words
-
- quick-tour version: Indicators
- mice: Minor abstraction types
- minutes
-
- example of timestamp: Non-decimal and compound bases
- misinterpretation: Eliding KE and KEhE rafsi from lujvo
- Mitsubishi: What about Chinese characters?
- mixed claim
-
- definition: Universal claims
- mixed modal connection
-
- afterthought: Mixed modal connection
- as proscribed in forethought: Mixed modal connection
- definition: Mixed modal connection
- of bridi-tails: Mixed modal connection
- of sentences: Mixed modal connection
- of sumti: Mixed modal connection
- mixed with: Non-logical connectives
- modal bridi-tail connection: Other modal connections
- modal causals
-
- implication differences: Modal sentence connection: the causals
- modal cmavo
-
- basis in gismu place structure: Complete table of BAI cmavo with rough English equivalents
- position relative to selbri: Tenses and bridi negation
- regular form for derivation: CV'V cmavo of selma'o BAI with irregular forms
- table with English equivalents: Complete table of BAI cmavo with rough English equivalents
- modal cmavo table
- modal connection
-
- simultaneous with logical: Mixed modal connection
- modal connection of selbri
-
- using bridi-tail modal connection: Other modal connections
- modal connectives
-
- fi'o prohibited in: Other modal connections
- modal conversion
-
- access to original first place with fai: Modal conversion: JAI
- grammar of: Modal conversion: JAI
- place structure of: Modal conversion: JAI
- with no modal specified: Modal conversion: JAI
- modal conversion with fi'o: Modal conversion: JAI
- modal conversion without modal
-
- as vague: Modal conversion: JAI
- modal conversions
-
- in descriptions: Modal conversion: JAI
- modal followed by selbri
-
- compared with tanru modification in meaning: Modal selbri
- contrasted with tanru modification in grammar: Modal selbri
- effect on eliding cu: Modal selbri
- modal operand connection: Other modal connections
- modal place
-
- definition: Modal places: FIhO, FEhU
- on description selbri: Modal tags: BAI
- rationale for term name: Modal places: FIhO, FEhU
- relation of to selbri: Modal places: FIhO, FEhU
- modal place relation
-
- importance of first place in: Modal places: FIhO, FEhU
- modal sentence connection: Modal sentence connection: the causals
-
- condensing: Other modal connections
- effect on modal: Modal sentence connection: the causals
- forethought: Other modal connections
- relation to modal of first sentence in: Modal sentence connection: the causals
- relation to modal of second sentence in: Modal sentence connection: the causals
- table of equivalent schemata: Tenses versus modals
- with other than causals: Modal sentence connection: the causals
- modal sumti
-
- and FA marking: Modal places: FIhO, FEhU
- as first place of modal tag selbri: Modal places: FIhO, FEhU
- definition (see also seltcita sumti): Modal places: FIhO, FEhU
- effect on place structure: Modal places: FIhO, FEhU
- leaving vague: Modal selbri
- position in bridi: Modal places: FIhO, FEhU
- unspecified: Modal selbri
- modal sumti connection: Other modal connections
- modal tag
-
- definition (see also sumtcita): Modal places: FIhO, FEhU
- fi'o with selbri as: Modal places: FIhO, FEhU
- for vague relationship: Modal tags: BAI
- modal tags
-
- contrasted with English prepositions in preciseness: Modal tags: BAI
- short forms as BAI cmavo: Modal tags: BAI
- modal tags and sumtcita: Linked sumti: be - bei - be'o
- modal-or-tense question
-
- with "cu'e": Tense questions: cu'e
- modal-or-tense questions
-
- pre-specifying some information: Tense questions: cu'e
- modals
-
- compared with tenses in syntax: Tenses versus modals
- contradictory negation of: Modal negation
- contrasted with tenses in semantics: Tenses versus modals
- expanding scope over inner modal connection: Modal selbri
- expanding scope over logical connection with ke ... ke'e: Modal selbri
- expanding scope over multiple sentences with tu'e…tu'u: Modal selbri
- expanding scope over non-logical connection: Modal selbri
- for causal gismu: Modal sentence connection: the causals
- importance of 1st sumti place for sumtcita use: Tenses versus modals
- improving relative phrase preciseness with : Modal relative phrases; Comparison
- making long-scope: Sticky modals
- making sticky: Sticky modals
- negation of: Modal negation
- scalar negation of: Modal negation
- termset connection: Other modal connections
- modals often attached with relative phrases
- modifier
-
- seltau as: Simple tanru
- modifying brivla (see also seltau): lujvo
- Mon Repos: Dependent places
- more
-
- English word "more"
-
- expressing with relative phrases: Modal relative phrases; Comparison
- importance of relative phrase to: Modal relative phrases; Comparison
- more than: Approximation and inexact numbers
-
- contrasted with less than
-
- at least, at most: Approximation and inexact numbers
- more than two: Approximation and inexact numbers
- morphology
-
- conventions for: Introductory
- definition: Introductory
- derivational: Introductory
- simplicity of: Introductory
- symbolic conventions for discussing: Introductory
- mother father: lujvo
- movement
-
- order in tense constructs: Movement in space: MOhI
- time: Movement in space: MOhI
- with multiple directions: Movement in space: MOhI
- movement specification
-
- interaction with direction in tenses: Movement in space: MOhI
- movie
-
- example of going to
-
- office: example: Tagging places: FA
- multiple "ma"
-
- as multiple questions: sumti and bridi questions: ma and mo
- multiple "mo"
-
- as multiple questions: sumti and bridi questions: ma and mo
- multiple compound bridi
-
- restriction on "ke": Multiple compound bridi
- multiple conversion
-
- avoiding: Conversion: SE
- effect of ordering: Conversion: SE
- multiple indefinite sumti
-
- effect of re-ordering in sentence: Grouping of quantifiers
- expressing with equal scope: Grouping of quantifiers
- meaning: Grouping of quantifiers
- multiple indefinite sumti scope
-
- in termset: Grouping of quantifiers
- multiple indicators: The uses of indicators
- multiple individual objects
-
- contrasted with mass object: Individuals and masses
- meaning of: Individuals and masses
- multiple letters
-
- proposed lerfu words for: Proposed lerfu words for some accent marks and multiple letters
- multiple logical connectives
-
- within tanru: Logical connection within tanru
- multiple quantification
-
- effect on selbri placement among sumti: Using naku outside a prenex
- multiple questions in one bridi
-
- expressing: sumti and bridi questions: ma and mo
- multiple relative clauses
-
- attaching with "zi'e": Multiple relative clauses: zi'e
- connecting different kinds with "zi'e": Multiple relative clauses: zi'e
- multiple speakers: Erasure: SI, SA, SU
- multiple sumti in one place
-
- avoiding: Tagging places: FA
- multiple tanru inversion
-
- effect on grouping: Inversion of tanru: co
- multiple tenses
-
- effect of order in sentence: Sticky and multiple tenses: KI
- my: Possessive sumti
- my chair: Multiple relative clauses: zi'e
- myth
-
- example: Evidentials
N
- n people: Mathematical uses of lerfu strings
- n-hyphen
- nai
-
- effect on intervals: Interval connectives and forethought non-logical connection
- name equivalent for typical
-
- rationale for lack of: Descriptors for typical objects
- name words
-
- recognition of: Lojban names
- name-words
-
- permissible consonant combinations: Lojban names
- names
-
- algorithm for: cmevla
- as possessive sumti: Possessive sumti
- assigning with "goi": Assignable pro-sumti and pro-bridi: the ko'a-series and the broda-series
- authority for: cmevla
- borrowing from other languages: Lojban names
- examples of: cmevla
- from Lojban words: cmevla
- in vocative phrase: Lojban names
- multiple: Lojban names
- pause requirement in lerfu words: The universal bu
- purpose of: cmevla
- quick-tour version: Words that can act as sumti
- rationale for lojbanizing: cmevla
- rules for: cmevla
- rules for formation: cmevla
- stress in: cmevla, cmevla
- two kinds of: Lojban names
- unusual stress in: cmevla
- uses of: Lojban names
- using rafsi: Lojban names
- with LA descriptor: Lojban names
- names from vowel-final base
-
- commonly used consonant endings: Lojban names
- names in Lojban (see also cmevla): cmevla
- names with la
-
- implicit quantifier for: Lojban names
- naming predicate: The three basic description types
- NATO: Acronyms
- natural end
-
- continuing beyond: Event contours: ZAhO and re'u
- contrasted with actual stop: Event contours: ZAhO and re'u
- Navajo
-
- example: fu'ivla
- near the faraway park: Tenses as sumtcita
- near the park: Tenses as sumtcita
- nearby in time: Temporal tenses: PU and ZI
- need any box: The problem of “any”
- negated intervals
- negating a forethought-connected bridi-tail pair: Multiple compound bridi
- negating a forethought-connected sentence pair: Multiple compound bridi
- negating a sentence
-
- and truth value: Logical connection and truth tables
- negation
-
- complex examples: Scalar negation of selbri
- form for emulating natural language negation: Using naku outside a prenex
- of operand: Miscellany
- of operator: Miscellany
- of tenses: Tense negation
- negation and logical connectives
-
- caveat for logic chapter discussions: bridi negation and logical connectives
- negation between sentences
-
- compared with bridi negation: bridi negation and logical connectives
- meaning of: bridi negation and logical connectives
- negation boundary
-
- and zero: Negation boundaries
- effect of moving: Negation boundaries
- negation cmavo
-
- position relative to selbri: Tenses and bridi negation
- negation in prenex
-
- effects of position: Negation boundaries
- negation manipulation
-
- "na" contrasted with "naku" in difficulty of: Using naku outside a prenex
- "naku" contrasted with "na" in difficulty of: Using naku outside a prenex
- negation of 'fi'o'-modals
-
- by negating selbri: Modal negation
- negation of modals: Modal negation
-
- contradictory: Modal negation
- scalar: Modal negation
- negation of tenses
-
- meaning of: Tense negation
- negation sumti qualifiers
-
- meanings of: sumti qualifiers
- negations with logical connectives
-
- effects on expansion of sentence: Logical connectives and DeMorgan's law
- negative answer
-
- quick-tour version: Questions
- negative numbers
-
- expressing: Signs and numerical punctuation
- negative sign
-
- contrasted with subtraction operator: Special numbers
- negator
-
- movement from bridi to sumti: Logical connectives and DeMorgan's law
- new notation: The meaning of lujvo
- New York city: Relative phrases, Relative phrases
- New York state: Relative phrases
- Newport News: Lojban names
- news: Topic-comment sentences: ZOhU, Topic-comment sentences: ZOhU
- nobody
-
- ambiguous interpretations of: What's wrong with this picture?
- interpretation of: What's wrong with this picture?
- Lojban contrasted with English: What's wrong with this picture?
- noisy environments
-
- proposed lerfu words for: Proposed lerfu words for radio communication
- non-logical connection
-
- and elidability of terminators: Non-logical connectives
- in mathematical expressions: Logical and non-logical connectives within mekso
- in tanru
-
- distinguishing from connection of sumti: Non-logical connectives
- of individuals into mass: Non-logical connectives
- of individuals into set: Non-logical connectives
- of modals: Logical and non-logical connection of modals
- of operands: Logical and non-logical connectives within mekso
- of operators: Logical and non-logical connectives within mekso
- of sumti
-
- distinguishing from connection in tanru: Non-logical connectives
- of termsets: More about non-logical connectives
- non-logical connectives
-
- effect of "nai" on: More about non-logical connectives
- grouping: More about non-logical connectives
- including tense: Tenses, modals, and logical connection
- intervals: Interval connectives and forethought non-logical connection
- ordered intervals: Interval connectives and forethought non-logical connection
- sentence: More about non-logical connectives
- syntax rules summary: Rules for making logical and non-logical connectives
- un-ordered intervals: Interval connectives and forethought non-logical connection
- within tanru: Logical connection within tanru
- non-logical forethought termsets
-
- connecting tagged sumti: More about non-logical connectives
- non-logically connected tenses: Tenses, modals, and logical connection
- non-Lojban quotation: Quotation summary
- non-Lojban text
-
- rules for pause with: Rules for inserting pauses
- non-restrictive relative clause
-
- definition (see also incidental relative clause): Incidental relative clauses
- non-specific descriptions: The three basic description types
- non-standard orthographies
-
- caveat: Oddball orthographies
- Cyrillic: Oddball orthographies
- Tengwar: Oddball orthographies
- zbalermorna: Oddball orthographies
- nonagenarian: Comparatives and superlatives
- normal circumstances: Event abstraction
- notation conventions
-
- for Quick Tour chapter: The concept of the bridi
- nothing sits: Negation boundaries
- nouns
-
- brivla as Lojban equivalents: brivla
- Nth rat: Mathematical uses of lerfu strings
- nth rat: Special mekso selbri
- Nthly: Mathematical uses of lerfu strings
- null operand
-
- for infix operations with too few operands: Infix operators revisited
- null operator
-
- for infix operations with too many operands: Infix operators revisited
- number article
-
- explanation of use: Simple infix expressions and equations
- number questions: Number questions
-
- answers to: Number questions
- number sumti
-
- syntax of: Number summary
- with "li": Number summary
- with "li" contrasted with "me'o": Number summary
- with "me'o": Number summary
- with "me'o" contrasted with "li": Number summary
- number words
-
- pattern in: Lojban numbers
- numbers
-
- as compound cmavo: Lojban numbers
- as grammatically complete utterances: Number questions
- as possessive sumti: Possessive sumti
- cmavo as Lojban equivalents: cmavo
- English contrasted with Lojban on exactness: Variables with generalized quantifiers
- expressing simple: Lojban numbers
- greater than 9: Lojban numbers
- implicit quantifier for: Number summary
- list of indefinite: Complete table of PA cmavo: digits, punctuation, and other numbers
- list of special: Complete table of PA cmavo: digits, punctuation, and other numbers
- Lojban contrasted with English on exactness: Variables with generalized quantifiers
- on logical variables: Variables with generalized quantifiers
- rafsi for: rafsi
- special: Special numbers
- talking about contrasted with using for quantification: Simple infix expressions and equations
- using for quantification contrasted with talking about: Simple infix expressions and equations
- numeric digits in lerfu words
-
- grammar considerations: What about Chinese characters?
- numerical punctuation: Signs and numerical punctuation
-
- undefined: Special numbers
- numerical selbri
-
- alternative to compensate for restriction on numbers: Special mekso selbri
- based on non-numerical sumti: Special mekso selbri
- complex: Special mekso selbri
- grammar: Special mekso selbri
- restriction on numbers used for: Special mekso selbri
- special: Special mekso selbri
-
- with lerfu strings: Special mekso selbri
- use of "me" with: Special mekso selbri
- numerical tenses
-
- effect on use of "boi": Other uses of mekso
- NYC: Acronyms
O
- O
-
- notation convention for logical connectives: The four basic vowels
- observation: Evidentials
- observation evidential
-
- contrasted with observative : Evidentials
- observative
-
- contrasted with observation evidential: Evidentials
- definition: Standard bridi form: cu
- observative form
-
- contrasted with command: Standard bridi form: cu
- observative with elided CAhA
-
- convention: Actuality, potentiality, capability: CAhA
- observatives
-
- and abstractions: The syntax of abstraction
- quick-tour version: Variant bridi structure
- ocean shell: Eliding KE and KEhE rafsi from lujvo
- octal system
-
- specifying numbers in (see also base): Non-decimal and compound bases
- octogenarian: Comparatives and superlatives
- of
-
- English word "of"
-
- compared with "do'e": Modal tags: BAI
- Old McDonald: The special Lojban characters
- old topic: Paragraphs: NIhO
- omission of descriptor
-
- effect on ku: Indefinite descriptions
- omitting terminators
-
- perils of: Scalar negation of selbri
- on right
-
- contrasted with toward right: Movement in space: MOhI
- on two occasions: Sub-events
- on verge: Event contours: ZAhO and re'u
- once: Interval properties: TAhE and roi
- once and future king: Tenses, modals, and logical connection, Tenses, modals, and logical connection
- One
-
- the: cmevla
- one-third of food: Special mekso selbri
- only: Discursives, Discursives, Discursives, Discursives
- only if
-
- compared with English "if … then": Logical connection of bridi
- only once: Interval properties: TAhE and roi
- open interval: Interval connectives and forethought non-logical connection
-
- expressed with "mi'i": Logical and non-logical connectives within mekso
- operand
-
- converting from operator: Miscellany
- converting into operator: Miscellany
- converting selbri into: Using Lojban resources within mekso
- converting sumti into: Using Lojban resources within mekso
- operand connection
-
- afterthought: Logical and non-logical connectives within mekso
- forethought: Logical and non-logical connectives within mekso
- operand modal connection: Other modal connections
- operands
-
- connecting: Logical and non-logical connectives within mekso
- contrasted with general sumti: Simple infix expressions and equations
- too few for infix operation: Infix operators revisited
- too many for infix operation: Infix operators revisited
- operator
-
- converting from operand: Miscellany
- converting into operand: Miscellany
- converting into selbri: Other uses of mekso
- converting selbri into: Using Lojban resources within mekso
- operator connection
-
- afterthought: Logical and non-logical connectives within mekso
- forethought: Logical and non-logical connectives within mekso
- operator derived from selbri
-
- effect of selbri place structure on: Using Lojban resources within mekso
- operator left-right grouping
-
- as Lojban default: Simple infix expressions and equations
- operator precedence
-
- and mathematical notation: Simple infix expressions and equations
- effect of pragmatic convention: Simple infix expressions and equations
- generalized explicit specification: Simple infix expressions and equations
- in Lojban default: Simple infix expressions and equations
- plans for future: Explicit operator precedence
- rationale for default left-grouping: Simple infix expressions and equations
- scope modification with "bi'e": Simple infix expressions and equations
- specifying by parenthesis: Simple infix expressions and equations
- operator precedence in other languages: Simple infix expressions and equations
- operators
-
- analogue of tanru in: Logical and non-logical connectives within mekso
- connecting: Logical and non-logical connectives within mekso
- list of simple: Complete table of VUhU cmavo, with operand structures
- operators of VUhU
-
- grammar of operands: Simple infix expressions and equations
- opinion: Evidentials
- opposite-of-minus: Miscellany
- or
-
- English "and/or" contrasted with "either … or … but not both": Logical connection and truth tables
- order of variables
-
- in moving to prenex: Variables with generalized quantifiers
- ordered sequence
-
- by listing members: Non-logical connectives
- contrasted with mass: Non-logical connectives
- contrasted with set: Non-logical connectives
- ordinal selbri
-
- definition: Special mekso selbri
- place structure: Special mekso selbri
- place structure effect from subjective numbers: Special mekso selbri
- ordinal tense: Event contours: ZAhO and re'u
- orthography
-
- non-standard: Oddball orthographies
- relation to pronunciation: Orthography
- outer product: Vectors and matrices
- outer quantifier
-
- contrasted with inner quantifier: Quantified descriptions
- definition: Quantified descriptions
- effect of on meaning: Quantified descriptions
- implicit on descriptors: Quantified descriptions
- in indefinite description: Indefinite descriptions
- outer quantifiers
-
- for expressing subsets: Quantified descriptions
- rationale for differences in implicit quantifier on descriptors: Quantified descriptions
- outer sumti
-
- prenex for referring to from within relative clause within relative clause: Relative clauses within relative clauses
- referring to from within relative clause within relative clause: Relative clauses within relative clauses
- owe money: Multiple compound bridi
P
- paragraph separation
-
- spoken text: Paragraphs: NIhO
- written text: Paragraphs: NIhO
- paragraphs
-
- effects on scope: Paragraphs: NIhO
- separator: Paragraphs: NIhO
- parasitic worms
-
- example: Eliding KE and KEhE rafsi from lujvo
- parentheses
-
- for complex mekso used as quantifier: Logical and non-logical connectives within mekso
- parenthesis
-
- mathematical: Simple infix expressions and equations
- partial quotation: Miscellaneous indicators
- parts of speech: Introductory
- passive voice: Varying the order of sumti
- past event
-
- possible extension into present: Vague intervals and non-specific tenses
- pastward
-
- as a spatial tense: Dimensionality: VIhA
- paternal grandmother
-
- example: lujvo
- pausative event contour: Event contours: ZAhO and re'u
- pause
-
- and cmevla: Rules for inserting pauses
- and consonant-final words: Rules for inserting pauses
- and Cy-form cmavo: Rules for inserting pauses
- and final-syllable stress: Rules for inserting pauses
- and non-Lojban text: Rules for inserting pauses
- and vowel-initial words: Rules for inserting pauses
- between words: Rules for inserting pauses
- contrasted with stop: Event contours: ZAhO and re'u
- contrasted with syllable break: The special Lojban characters
- proscribed within words: Rules for inserting pauses
- representation of in Lojban: The special Lojban characters
- requirement between stressed syllables: cmavo
- symbol for: The universal bu
- word for: The universal bu
- pauses
-
- before vowels: cmavo
- rules for: Rules for inserting pauses
- peace symbol: Computerized character codes
- percent
-
- as numerical punctuation: Signs and numerical punctuation
- perils of omitting terminators: Scalar negation of selbri
- period
-
- definition of: The special Lojban characters
- example of: The special Lojban characters
- optional: The special Lojban characters
- quick-tour version: Pronunciation
- within a word: The special Lojban characters
- Persian rug: rafsi
- person's arm: Relative phrases
- personal pro-sumti: Pro-sumti summary
-
- implicit cancellation of by change of speaker/listener: Pro-sumti and pro-bridi cancelling
- implicit quantifier for: Pro-sumti summary
- stability of: Pro-sumti and pro-bridi cancelling
- personal pronouns
-
- with ko'a-series for he/she/it/they: Assignable pro-sumti and pro-bridi: the ko'a-series and the broda-series
- with mi-series for I/you: Personal pro-sumti: the mi-series
- personal pronouns for he/she/it/they
-
- English contrasted with Lojban in organization: Assignable pro-sumti and pro-bridi: the ko'a-series and the broda-series
- Pete: cmevla
- Pheidippides: Types of event abstractions
- phonetic alphabet: Basic phonetics
- Phonetic Alphabet
-
- proposed lerfu words for: Proposed lerfu words for radio communication
- physical distress
-
- example: Emotional categories
- piano-moving: Individuals and masses
- pictures
-
- credits for: Acknowledgements and credits
- pinyin
-
- as a basis for Chinese characters in Lojban lerfu words: What about Chinese characters?
- piro
-
- explanation of meaning: Quantified descriptions
- pisu'o
-
- explanation of meaning: Quantified descriptions
- place of eating: Conversion of sumtcita: JAI
- place structure
-
- adding new places to with modal sumti: Modal places: FIhO, FEhU
- definition: Introductory
- definition of: The concept of the bridi
- effect of FA on: Tagging places: FA
- effect of modal conversion on: Modal conversion: JAI
- empty slots in: Introductory
- explicitly mapping sumti to place with FA: Tagging places: FA
- gismu: Notes on gismu place structures
- instability of: Introductory
- leaving a sumti place unspecified in with zo'e: Standard bridi form: cu
- notation conventions: Introductory
- re-ordering by conversion: Conversion of simple selbri
- place structure and tanru inversion: Inversion of tanru: co
- place structure of selbri
-
- determining: Introductory
- place structure order
-
- effect of FA on: Tagging places: FA
- place structure questions: Tagging places: FA
- place structures
-
- omitting places with FA: Tagging places: FA
- omitting places with zo'e: Standard bridi form: cu
- plant grows: Modal sentence connection: the causals, Modal sentence connection: the causals, Modal sentence connection: the causals, Modal sentence connection: the causals, Modal sentence connection: the causals, Modal negation
- plants
-
- use of fu'ivla for specific: fu'ivla
- plausibility
-
- in abbreviated lujvo: Eliding SE rafsi from seltau
- playgrounds: Dependent places
- pleases: The sumti di'u and la'e di'u
- plural
-
- Lojban equivalent of: Approximation and inexact numbers
- plural masses
-
- possible use for: Quantified descriptions
- plurals
-
- Lojban contrasted with English in necessity of marking: The three basic description types
- plurals with le
-
- meaning of: Individuals and masses
- point
-
- event considered as: Event contours: ZAhO and re'u
- point-event abstraction
-
- place structure: Types of event abstractions
- point-event abstractions
-
- definition: Types of event abstractions
- related tense contours: Event-type abstractors and event contour tenses
- point-event abstractor: Types of event abstractions
- pointing
-
- reference by: Demonstrative pro-sumti: the ti-series
- pointing cmavo
-
- quick-tour version: Words that can act as sumti
- police lineup: Number questions
- Polish notation
-
- and mekso goals: Introductory
- Polish notation mixed with infix: Logical and non-logical connectives within mekso
- politeness
-
- thank you and you're welcome: Vocative scales
- you're welcome: Vocative scales, Vocative scales
- portion
-
- on set contrasted with on individual: Quantified descriptions
- portion selbri
-
- definition: Special mekso selbri
- place structure: Special mekso selbri
- place structure effect from subjective numbers: Special mekso selbri
- positive numbers
-
- explicit expression: Signs and numerical punctuation
- positive sign
-
- contrasted with addition operator: Simple infix expressions and equations
- possessed in relative phrases
-
- compared with possessor: Relative phrases
- possession
-
- expressing with "po": Relative phrases
- intrinsic
-
- expressing with po'e: Relative phrases
- Lojban usage compared with French and German in omission/inclusion: Relative phrases
- Lojban usage contrasted with English in omission/inclusion: Relative phrases
- quick-tour version: Possession
- possession not ownership
-
- quick-tour version: Possession
- possessive sumti
-
- compared with relative phrase: Possessive sumti
- contrasted with relative phrases in complexity allowed: Possessive sumti
- definition: Possessive sumti
- effect on elidability of ku: Possessive sumti
- relative clauses on: Possessive sumti
- syntax allowed: Possessive sumti
- with relative clauses on possessive sumti: Possessive sumti
- possessive sumti and relative clauses
-
- development history: Possessive sumti
- possessive sumti with relative clauses
-
- effect of placement: Possessive sumti
- possessor in relative phrases
-
- compared with possessed: Relative phrases
- possessor sumti
-
- definition: Possessive sumti
- potential
-
- expressing in past/future: Actuality, potentiality, capability: CAhA
- potential events
-
- expressing implicitly: Actuality, potentiality, capability: CAhA
- prayer: Ordering lujvo places., Ordering lujvo places., Ordering lujvo places.
- precedence
-
- mathematical default: Simple infix expressions and equations
- precise erasures: Erasure: SI, SA, SU
- predicate answers: Questions and answers
- predication
-
- as a relationship: The concept of the bridi
- compared with bridi: The concept of the bridi
- Preem Palver: Other kinds of simple selbri
- pregnant sister: Discursives, Discursives
- prenex
-
- considerations for dropping: Dropping the prenex
- dropping for terseness: Dropping the prenex
- effect of order of variables in: Dropping the prenex
- explanation: Existential claims, prenexes, and variables
- internal to a bridi: The problem of “any”
- purpose of: Dropping the prenex
- removing when numeric quantifiers present: Variables with generalized quantifiers
- syntax of: Existential claims, prenexes, and variables
- use for outer sumti reference: Relative clauses within relative clauses
- prenex manipulation
-
- exporting "na" from left of prenex: bridi negation and logical connectives
- importing "na" from selbri: bridi negation and logical connectives
- moving "naku" past bound variable: bridi negation and logical connectives
- rules: bridi negation and logical connectives
- prenex scope
-
- for sentences joined by ".i": A few notes on variables
- for sentences joined by ijeks: A few notes on variables
- in abstractions: A few notes on variables
- in embedded bridi: A few notes on variables
- in relative clauses: A few notes on variables
- informal: A few notes on variables
- prepositions
-
- cmavo as Lojban equivalents: cmavo
- pretty
-
- English ambiguity of: Complex tanru grouping
- pretty little girls' school
- previous topic: Paragraphs: NIhO
- pride of lions: Using Lojban resources within mekso
- primitive roots
-
- gismu as: brivla
- principle of consistency
-
- of logical-if statements: Logical connection of bridi
- pro-bridi
-
- as abbreviation for bridi: Assignable pro-sumti and pro-bridi: the ko'a-series and the broda-series
- broda-series: Assignable pro-sumti and pro-bridi: the ko'a-series and the broda-series
- compared to pro-sumti as means of abbreviation: What are pro-sumti and pro-bridi? What are they for?
- definition: What are pro-sumti and pro-bridi? What are they for?
- overriding sumti of antecedent bridi for: Assignable pro-sumti and pro-bridi: the ko'a-series and the broda-series
- scope effect of new paragraph: Paragraphs: NIhO
- pro-bridi assignment
-
- "no'i" effect on: Pro-sumti and pro-bridi cancelling
- explicit cancellation of with "da'o": Pro-sumti and pro-bridi cancelling
- stability of: Pro-sumti and pro-bridi cancelling
- pro-bridi rafsi
-
- as producing context-dependent meanings: lujvo based on pro-sumti
- pro-sumti
-
- and discursive utterances: Parenthesis and metalinguistic commentary: TO, TOI, SEI
- as possessive sumti: Possessive sumti
- classes of: Pro-sumti summary
- compared to pro-bridi as means of abbreviation: What are pro-sumti and pro-bridi? What are they for?
- compared to pronouns in usage as abbreviations: What are pro-sumti and pro-bridi? What are they for?
- contrasted with description: The five kinds of simple sumti
- definition: What are pro-sumti and pro-bridi? What are they for?
- di'u-series: Utterance pro-sumti: the di'u-series
- for listener(s): Personal pro-sumti: the mi-series
- for listeners and/or speakers and/or others: Personal pro-sumti: the mi-series
- for relativized sumti in relative clauses: Relativized pro-sumti: ke'a
- for speaker(s): Personal pro-sumti: the mi-series
- implicit quantifier for: Pro-sumti summary
- ko'a-series: Assignable pro-sumti and pro-bridi: the ko'a-series and the broda-series
- lerfu as: Assignable pro-sumti and pro-bridi: the ko'a-series and the broda-series
- lerfu string
-
- effect on reference to lerfu itself: References to lerfu
- lerfu strings
-
- interaction with quantifiers and boi: lerfu words as pro-sumti
- mi-series: Personal pro-sumti: the mi-series
- quick-tour version: Words that can act as sumti
- rafsi for: lujvo based on pro-sumti
- referring to place of different bridi with go'i-series: Reflexive and reciprocal pro-sumti: the vo'a-series
- referring to place of same bridi with vo'a-series: Reflexive and reciprocal pro-sumti: the vo'a-series
- scope effect of new paragraph: Paragraphs: NIhO
- series: What are pro-sumti and pro-bridi? What are they for?
- ti-series: Demonstrative pro-sumti: the ti-series
- typical: Indefinite pro-sumti and pro-bridi: the zo'e-series and the co'e-series
- unspecified: Indefinite pro-sumti and pro-bridi: the zo'e-series and the co'e-series
- vo'a-series: Reflexive and reciprocal pro-sumti: the vo'a-series
- pro-sumti assignment
-
- "no'i" effect on: Pro-sumti and pro-bridi cancelling
- explicit cancellation of with "da'o": Pro-sumti and pro-bridi cancelling
- stability of: Pro-sumti and pro-bridi cancelling
- pro-sumti for "we"
-
- contrasted with English "we": Personal pro-sumti: the mi-series
- pro-sumti for speaker/listener/others
-
- as masses: Personal pro-sumti: the mi-series
- relation to "joi": Personal pro-sumti: the mi-series
- pro-sumti for utterances: Utterance pro-sumti: the di'u-series
- pro-sumti rafsi
-
- anticipated use of for abbreviating inconvenient forms: lujvo based on pro-sumti
- effect of on place structure of lujvo: lujvo based on pro-sumti
- probability .5: Special mekso selbri
- probability selbri
-
- definition: Special mekso selbri
- place structure: Special mekso selbri
- place structure effect from subjective numbers: Special mekso selbri
- values: Special mekso selbri
- process abstraction
-
- place structure: Types of event abstractions
- process abstractions
-
- definition: Types of event abstractions
- related tense contours: Event-type abstractors and event contour tenses
- process abstractor: Types of event abstractions
- process event
-
- described: Types of event abstractions
- pronouncement: Evidentials
- pronouns
-
- as anaphora: Anaphoric pro-sumti and pro-bridi: the ri-series and the go'i-series
- compared to pro-sumti in usage as abbreviations: What are pro-sumti and pro-bridi? What are they for?
- pronouns in English
-
- as independent of abbreviations: What are pro-sumti and pro-bridi? What are they for?
- as noun abbreviations: What are pro-sumti and pro-bridi? What are they for?
- pronunciation
-
- IPA for Lojban: Basic phonetics
- quick-tour version: Pronunciation
- relation to orthography: Orthography
- standard: Basic phonetics
- properties
-
- place structure: Property abstractions
- property abstraction
-
- specifying sumti place of property with "ce'u": Abstraction focus pro-sumti: ce'u
- property abstractions
-
- specifying determining place by sumti ellipsis: Property abstractions
- specifying determining place with "ce'u": Property abstractions
- sumti ellipsis in: Property abstractions
- use of multiple "ce'u" for relationship abstraction: Property abstractions
- property of loving: Property abstractions
- proposed law: Eliding SE rafsi from seltau
- proposed lerfu words
-
- as working basis: Proposed lerfu words – introduction
- propositional
-
- of attitudinals: Propositional attitude indicators
- propositional attitudes: Predication/sentence abstraction
-
- compared with knowledge discursives: Discursives
- protocol
-
- computer communications using COI: Vocative scales
- parliamentary using COI: Vocative scales
- using vocatives: Vocative scales
- punctuation
-
- in numbers: Signs and numerical punctuation
- list of numerical: Complete table of PA cmavo: digits, punctuation, and other numbers
- punctuation lerfu words
-
- interaction with different alphabet systems: Punctuation marks
- mechanism for creating: Punctuation marks
- rationale for "lau": Punctuation marks
- punctuation marks
-
- cmavo as Lojban equivalents: cmavo
Q
- quack: Alien alphabets
- quadratic formula: Logical and non-logical connectives within mekso
- qualified sumti
-
- contrasted with unqualified sumti: sumti qualifiers
- quantification
-
- before description sumti compared with before non-description sumti: Quantified descriptions
- quantificational pro-sumti: Pro-sumti summary
-
- implicit quantification rules: Pro-sumti summary
- quantified space: Interval properties: TAhE and roi
- quantified sumti
-
- different types contrasted for scope for distribution: Grouping of quantifiers
- quantified temporal tense
-
- definition: Interval properties: TAhE and roi
- negating with "nai": Interval properties: TAhE and roi
- quantified temporal tense with direction
-
- Lojban contrasted with English in implications: Interval properties: TAhE and roi
- quantified temporal tenses
-
- "once" contrasted with "only once": Interval properties: TAhE and roi
- caveat on implication of: Interval properties: TAhE and roi
- quantified tenses
-
- as sumtcita: Tenses as sumtcita
- quantifier
-
- lerfu string as: Mathematical uses of lerfu strings
- on previously quantified variable: A few notes on variables
- quantifier scope
-
- in multiple connected sentences: bridi negation and logical connectives
- quantifiers
-
- effect of moving "naku": Using naku outside a prenex
- with logical variables: Variables with generalized quantifiers
- with sumti: Quantified sumti
- quark: fu'ivla
- question pro-sumti: Pro-sumti summary
-
- implicit quantifier for: Pro-sumti summary
- questions
-
- answering with "go'i": Anaphoric pro-sumti and pro-bridi: the ri-series and the go'i-series
- connection: Truth questions and connective questions
- digit: Number questions
- fill-in-the-blank: Questions and answers
- marking in advance: Miscellaneous indicators
- multiple: Questions and answers
- number: Number questions, Questions and answers
- operator: Other uses of mekso
- place structure position: Tagging places: FA
- quick-tour version: Questions, Questions
- rhetorical: Miscellaneous indicators
- selbri: sumti and bridi questions: ma and mo, Questions and answers
- sumti: sumti and bridi questions: ma and mo, Questions and answers
- truth: Questions and answers
- with "xu": Miscellaneous indicators
- quick runner: Simple tanru
- quotation
-
- contrasted with "me'o" for representing lerfu: References to lerfu
- contrasted with sentence abstraction: Predication/sentence abstraction
- four kinds: Quotation summary
- implicit quantifier for: Quotation summary
- quotations
-
- as possessive sumti: Possessive sumti
- implicit quantifier for: Quantified sumti
R
- r-hyphen
- radio communication
-
- proposed lerfu words for: Proposed lerfu words for radio communication
- radix
-
- decimal (see also base): Non-decimal and compound bases
- rafsi
-
- as fu'ivla categorizer: fu'ivla
- based on pro-sumti: lujvo based on pro-sumti
- considerations restricting construction of: rafsi
- contrasted with cmavo in usage: rafsi
- contrasted with same-form cmavo in meaning: lujvo
- contrasted with words: rafsi
- conventional meaning for "cu'o": Miscellany
- conventional meaning for "frinu": Miscellany
- definition: lujvo
-
- quick-tour version: Lojban grammatical terms
- forms of: rafsi
- four-letter
-
- requirement for y-hyphen: rafsi
- lack of
-
- effect on forming lujvo: rafsi
- level of uniqueness of relation to gismu: rafsi
- long: rafsi
- multiple for each gismu: Considerations for making lujvo
- multiplicity of for single gismu: rafsi
- possible forms for construction of: rafsi
- rationale for assignments of: rafsi
- rules for combining to form lujvo: lujvo
- selection considerations in making lujvo: rafsi
- short: rafsi
- uniqueness in gismu referent of: rafsi
- use of: rafsi
- rafsi assignments
-
- non-reassignability of: rafsi
- rafsi for numbers: rafsi
- rafsi form
-
- effect of choice on meaning of lujvo: lujvo
- rafsi fu'ivla: Cultural and other non-algorithmic gismu
- rafsi space: rafsi
- Ralph: Existential claims, prenexes, and variables
- rat eats cheese: Interval properties: TAhE and roi, Tenses as sumtcita, Tenses as sumtcita, Tenses as sumtcita
- rat eats cheese in park: Conversion of sumtcita: JAI, Conversion of sumtcita: JAI
- rats are brown: Masses and sets
- rats in park: Special mekso selbri
- re-ordering logical variables with "se": Dropping the prenex
- real world
-
- contrasted with hypothetical world
-
- example: Discursives
- real world point of view: Discursives
- Received Pronunciation: IPA for English speakers
- reciprocal
-
- expression of mathematical: Signs and numerical punctuation
- reciprocal pro-sumti: Reflexive and reciprocal pro-sumti: the vo'a-series
- reciprocity
-
- expressing with "soi": Reflexive and reciprocal pro-sumti: the vo'a-series
- expressing with vo'a-series pro-sumti and "soi": Reflexive and reciprocal pro-sumti: the vo'a-series
- recital rooms: Dependent places
- Red Pony: sumti qualifiers, sumti qualifiers
- red pony: Relative clauses and complex sumti: vu'o, Relative clauses and complex sumti: vu'o
- redundancy
-
- effect on vocative design: Vocative scales
- reference
-
- ambiguity of "ti"/"ta"/"tu": What are you pointing at?
- and discursive utterances: Parenthesis and metalinguistic commentary: TO, TOI, SEI
- quick-tour version: The sumti di'u and la'e di'u
- to relativized sumti with "ke'a": What are you pointing at?
- use of relative clause for: What are you pointing at?
- reference frame
-
- specifying for direction tenses: Movement in space: MOhI
- reference frame for directions in tenses: Movement in space: MOhI
- reference grammar: What is this book?
- referent
-
- of operand: Miscellany
- referring to with "la'e": sumti qualifiers
- referent of pro-bridi
- referent of pro-sumti
- reflexive pro-sumti: Pro-sumti summary, Reflexive and reciprocal pro-sumti: the vo'a-series
-
- stability of: Pro-sumti and pro-bridi cancelling
- regularly: Interval properties: TAhE and roi
- relation of first places in logical connection of observatives
-
- rationale: Compound bridi
- relationship
-
- active/static/attributive compared: The concept of the bridi
- as basis of sentence: Introductory
- objects of: Introductory
- relationship abstraction: Property abstractions
- relative clause
-
- compared with tanru: Incidental relative clauses
- connecting to relative phrase with "zi'e": Multiple relative clauses: zi'e
- contrasted with tanru: Incidental relative clauses
- effect of omission of ke'a on : What are you pointing at?
- restrictive (see also restrictive relative clause): Incidental relative clauses
- use for reference: What are you pointing at?
- relative clause scope
-
- extending to preceding sumti with "vu'o": Relative clauses and complex sumti: vu'o, Relative clauses and complex sumti: vu'o
- relative clauses
-
- as part of name: Relative clauses and descriptors
- effect of commas in English: Incidental relative clauses
- effect on elidability of "be'o": Linked sumti: be - bei - be'o
- impact of indefinite sumti on placement: Relative clauses and descriptors
- impact of la on placement: Relative clauses and descriptors
- impact of LAhE on placement: Relative clauses and complex sumti: vu'o
- impact of NAhE on placement: Relative clauses and complex sumti: vu'o
- kinds of: Incidental relative clauses
- list of cmavo for: Index of relative clause cmavo
- on connected sumti: Relative clauses and complex sumti: vu'o
- on names: Relative clauses and descriptors
- on number: Relative clauses and complex sumti: vu'o
- on possessive sumti: Possessive sumti
- on quotation: Relative clauses and complex sumti: vu'o
- on vocative phrases: Relative clauses in vocative phrases
- placement with vocative phrases: Relative clauses in vocative phrases
- relative clauses within: Relative clauses within relative clauses
- restricted contrasted with incidental: Incidental relative clauses
- restricted contrasted with incidental in English expression: Incidental relative clauses
- syntax with indefinite sumti: Relative clauses and descriptors
- use in restricting existential claims: Restricted claims: da poi
- use in restricting universal claims: Restricted claims: da poi
- use of "ke'a" for referral to relativized sumti in: Relativized pro-sumti: ke'a
- relative clauses and indefinite sumti
-
- placement considerations: Relative clauses and descriptors
- relative clauses and LAhE
-
- placement considerations: Relative clauses and complex sumti: vu'o
- relative clauses and NAhE
-
- placement considerations: Relative clauses and complex sumti: vu'o
- relative clauses and names
-
- placement considerations: Relative clauses and descriptors
- relative clauses and possessive sumti
-
- development history: Possessive sumti
- relative clauses on "lo"
-
- syntax suggestion: Relative clauses and descriptors
- relative clauses on complex sumti
-
- Lojban contrasted with English: Relative clauses and complex sumti: vu'o
- relative clauses on indefinite sumti
-
- syntax considerations: Relative clauses and descriptors
- relative clauses with possessive sumti
-
- effect of placement: Possessive sumti
- relative phrase
-
- as an abbreviation of a common relative clause: Relative phrases
- compared with possessive sumti: Possessive sumti
- connecting to relative clause with "zi'e": Multiple relative clauses: zi'e
- rationale for: Relative phrases
- syntax of: Relative phrases
- relative phrases
-
- contrasted with possessive sumti in complexity allowed: Possessive sumti
- contrasted with relative clauses in preciseness: Modal relative phrases; Comparison
- improving preciseness with modals: Modal relative phrases; Comparison
- relative phrases with modals
-
- compared to relative clauses in preciseness: Modal relative phrases; Comparison
- relative pro-sumti: Pro-sumti summary
- relativity theory
-
- relation to Lojban tense system: Temporal tenses: PU and ZI
- relativized sumti
-
- definition: What are you pointing at?
- in relative clauses within relative clauses: Relative clauses within relative clauses
- remembered
-
- example: Evidentials
- repeating decimals
-
- expressing with numerical punctuation: Signs and numerical punctuation
- marking start of repeating portion: Signs and numerical punctuation
- representing lerfu
-
- "lu" contrasted with "me'o": References to lerfu
- respectively: Non-logical connectives
-
- specifying with "fa'u": Non-logical connectives
- with different relationships: More about non-logical connectives
- restricted claims
-
- definition: Restricted claims: da poi
- restricted variable
-
- compared with indefinite description: Variables with generalized quantifiers
- restrictive relative clause
-
- definition: Incidental relative clauses
- resume
-
- contrasted with begin: Event contours: ZAhO and re'u
- resumptive event contour: Event contours: ZAhO and re'u
- retrospective event contour: Event contours: ZAhO and re'u
- revelation
-
- example: Evidentials
- reverse Polish notation
-
- and mekso goals: Introductory
- definition: Reverse Polish notation
- marker: Reverse Polish notation
- number of operands: Reverse Polish notation
- operands of: Reverse Polish notation
- parentheses in operands of: Reverse Polish notation
- terminator: Reverse Polish notation
- use of parentheses in: Reverse Polish notation
- with too few operands: Reverse Polish notation
- with too many operands: Reverse Polish notation
- reviewers of this book: Acknowledgements and credits
- rhetorical question: Miscellaneous indicators
- rich and German: More about non-logical connectives, More about non-logical connectives
- right-grouping in tanru
-
- with "bo": Complex tanru grouping
- right-grouping rule
-
- definition of: Complex tanru grouping
- righteous indignation
-
- example: Attitudinal modifiers
- rock face: Space interval modifiers: FEhE
- roger
-
- example: Vocative scales
- romaji
-
- as a basis for kanji characters in Lojban lerfu words: What about Chinese characters?
- Roman Empire: Types of event abstractions, Types of event abstractions
- room which he built: Relative clauses within relative clauses, Relative clauses within relative clauses
- rounded down: Approximation and inexact numbers
- rounded numbers
-
- expressing: Approximation and inexact numbers
- rounded up: Approximation and inexact numbers
- rounded/unrounded vowels: Basic phonetics
- RP
-
- as abbreviation for reverse Polish notation: Reverse Polish notation
- rug
-
- Persian: rafsi
- runner shoe: tanru
S
- said John: Parenthesis and metalinguistic commentary: TO, TOI, SEI, Parenthesis and metalinguistic commentary: TO, TOI, SEI, Parenthesis and metalinguistic commentary: TO, TOI, SEI, Parenthesis and metalinguistic commentary: TO, TOI, SEI
- salad ingredients: Space interval modifiers: FEhE
- Sapir-Whorf effects
-
- and emotional indicators: Tentative conclusion
- sarcasm
-
- example: Discursives
- expressing: Discursives
- scalar attitude: Attitudes as scales
- scalar negation
-
- effect on selbri: Scalar negation of selbri
- scalar negation of modals
-
- explanation of meaning: Modal negation
- scalar negation of non-logical connective: More about non-logical connectives
- scale
-
- granular contrasted with continuous: Special mekso selbri
- scale of redness: Special mekso selbri
- scale selbri
-
- definition: Special mekso selbri
- place structure: Special mekso selbri
- place structure effect from subjective numbers: Special mekso selbri
- school building: Dependent places
- schooner: Lojban content words: brivla
- scientific names
-
- rules for: cmevla
- scientific notation
-
- rationale for order of places: Infix operators revisited
- with "gei": Infix operators revisited
- score
-
- as 20-year span: Four score and seven: a mekso problem
- as alternate base for years: Four score and seven: a mekso problem
- seconds
-
- example of timestamp: Non-decimal and compound bases
- section numbering: Other uses of mekso
- see with eye: Modal selbri
- see with left eye: Modal places: FIhO, FEhU
- selbri
-
- as part of description: The three basic description types
- brivla as: Lojban content words: brivla
- converting into an operand: Using Lojban resources within mekso
- converting into an operator: Using Lojban resources within mekso
- converting operator into: Other uses of mekso
- definition: Lojban content words: brivla, Introductory
-
- quick-tour version: Lojban grammatical terms
- lerfu string as: Mathematical uses of lerfu strings
- omitting with "co'e": Indefinite pro-sumti and pro-bridi: the zo'e-series and the co'e-series
- place structure of: Introductory
- place structure of converted operator: Other uses of mekso
- relation to bridi: Lojban content words: brivla
- scalar negation of: Scalar negation of selbri
- with GOhA: Other kinds of simple selbri
- selbri from sumti: selbri based on sumti: me
- selbri list for quick tour: Some words used to indicate selbri relations
- selbri logical variables: selbri variables
- selbri place structure
-
- effect on operator formed by: Using Lojban resources within mekso
- selbri placement among sumti
-
- effect of multiple quantification on: Using naku outside a prenex
- selbri questions
-
- quick-tour version: Questions
- selbri variables
-
- form when not in prenex: selbri variables
- prenex form as indefinite description: selbri variables
- quantified: selbri variables
- selbri-first bridi
-
- effect on sumti places: Standard bridi form: cu
- effect on use of cu: Tagging places: FA
- specifying first sumti place in with fa: Tagging places: FA
- self-orientation
-
- example: Attitudinal modifiers
- selma'o
-
- cross-reference list of
-
- selma'o catalog: A catalogue of selma'o
- definition: cmavo
-
- quick-tour version: Lojban grammatical terms
- seltau
-
- compared with English adjective: lujvo
- compared with English adverb: lujvo
- definition: Inversion of tanru: co
- definition of: Simple tanru
- effect on meaning of tanru: Simple tanru
- filling sumti places in: Linked sumti: be - bei - be'o
- seltcita sumti
-
- definition (see also modal sumti): Modal places: FIhO, FEhU
- sentence
-
- basic Lojban: Introductory
- sentences
-
- close grouping: Sentences: I
- connecting non-logically: More about non-logical connectives
- connecting with tense: Tense relations between sentences
- forethought tense connection of: Tense relations between sentences
- separator for joining: Sentences: I
- tenseless
-
- quick-tour version: Tenses
- separate questions
-
- quick-tour version: Questions
- separately tensed sentences
-
- contrasted with tense connected sentences: Tense relations between sentences
- sequence
-
- as an abstract list: Non-logical connectives
- contrasted with list: Non-logical connectives
- contrasted with set: sumti qualifiers
- sequence of events
-
- expressing non-time-related sequences: More about non-logical connectives
- sequence of tense rules
-
- Lojban contrasted with English: Tenses in subordinate bridi
- set
-
- as specified by members: Non-logical connectives
- by listing members with "ce": Non-logical connectives
- compared with mass as abstract of multiple individuals: Masses and sets
- contrasted with mass in attribution of component properties: Masses and sets
- contrasted with mass in distribution of properties: Non-logical connectives
- contrasted with ordered sequence: Non-logical connectives
- expressing measurement standard for indefinites: Special mekso selbri
- expressing relation with individuals forming set: Special mekso selbri
- expressing relation with mass formed from set: Special mekso selbri
- set of all rats: Special mekso selbri
- set of rats: sumti qualifiers, sumti qualifiers, sumti qualifiers
- set operations: More about non-logical connectives
- sets
-
- properties of: Masses and sets
- rule for implicit outer quantifier: Quantified descriptions
- use in Lojban place structure: Masses and sets
- sexual discomfort
-
- example: Emotional categories
- sexual teacher
-
- male
-
- example: lujvo-making examples
- shared bridi-tail sumti
-
- avoiding: Other modal connections
- shell worm: Eliding KE and KEhE rafsi from lujvo
- shellfish: Eliding KE and KEhE rafsi from lujvo, Eliding KE and KEhE rafsi from lujvo
- Sherman tank: rafsi
- shift
-
- single-letter
-
- grammar of: Upper and lower cases
- shift word
-
- for single letter: Upper and lower cases
- scope: Upper and lower cases
- shift words
-
- canceling effect: Alien alphabets
- for face: Alien alphabets
- for font: Alien alphabets
- ship sank: Attitude questions; empathy; attitude contours
- shoehorn: Dependent places
- shook stick: What are pro-sumti and pro-bridi? What are they for?, What are pro-sumti and pro-bridi? What are they for?
- short rafsi: rafsi
- short rafsi form
-
- compared with long form in effect on lujvo meaning: lujvo
- signed numbers
-
- expressing: Signs and numerical punctuation
- signs on numbers
-
- grammar: Signs and numerical punctuation
- Simon says: Utterance pro-sumti: the di'u-series
- simple sumti: The five kinds of simple sumti
- simultaneously: Tenses, modals, and logical connection
- sinful
-
- example: Attitudinal modifiers
- single consonants
-
- contrasted with consonant clusters: Consonant clusters
- contrasted with doubled consonants: Consonant clusters
- single-letter shift
-
- as toggle: Upper and lower cases
- single-word quotation: Quotation summary
- singular me: Special mekso selbri
- sister pregnant: Discursives, Discursives
- six-shooter: Sub-events
- size
-
- order with dimensionality in spatial tense intervals: Dimensionality: VIhA
- slinku'i test
-
- definition: fu'ivla
- slowdown: Types of event abstractions
- smiley face
-
- example: The universal bu
- word for: The universal bu
- sneak in: Eliding KE and KEhE rafsi from lujvo
- snow falls: Tenses as sumtcita
- snowball's chance: Special mekso selbri
- social butterfly: tanru
- Socrates: Modal sentence connection: the causals
- some do not go to school: Using naku outside a prenex
- some relationship: selbri variables
- somebody
-
- contrasted with somebody else: Existential claims, prenexes, and variables
- somebody loves self: Existential claims, prenexes, and variables
- somebody loves somebody: Existential claims, prenexes, and variables
- somebody's dog: Existential claims, prenexes, and variables
- something
-
- contrasted with someone: Restricted claims: da poi
- expressing using "su'o": Variables with generalized quantifiers
- unspecified definite with "zo'e": Existential claims, prenexes, and variables
- something is loved by everybody: Negation boundaries
- something sees everything: Universal claims
- something sees me: Existential claims, prenexes, and variables, Variables with generalized quantifiers
- sounds
-
- clarity of: Basic phonetics
- complex: Basic phonetics
- difficult: Basic phonetics
- sounds for letters
-
- Lojban contrasted with English: Basic phonetics
- source languages
-
- use in creating gismu: The gismu creation algorithm
- south face: Space interval modifiers: FEhE
- sow grain: Space interval modifiers: FEhE
- sowed grain: Tense questions: cu'e
- space
-
- as time-based metaphor: Space interval modifiers: FEhE
- contrasted with time in number of directions: Temporal tenses: PU and ZI
- space intervals
-
- compared with time intervals in continuity: Space interval modifiers: FEhE
- space location
-
- as part of tense system (see also tense
-
- spatial tense): Introductory
- space tenses
-
- quick-tour version: Tenses
- space/time metaphor
-
- expressing direction mapping for: Space interval modifiers: FEhE
- spaghetti: fu'ivla, fu'ivla
- Spanish ch
- Spanish ll
- spatial contours
-
- as sumtcita: Tenses as sumtcita
- contrasted with temporal event contours: Space interval modifiers: FEhE
- expressing: Space interval modifiers: FEhE
- spatial directions
- spatial information
-
- adding to a sentence with tense sumtcita: Tenses as sumtcita
- spatial interval modifiers
-
- order in tense: Space interval modifiers: FEhE
- spatial intervals
-
- expressing degree of continuity over: Space interval modifiers: FEhE
- spatial tense
-
- 4-dimensional interaction with temporal tense: Dimensionality: VIhA
- as an imaginary journey: Spatial tenses: FAhA and VA
- as optional in English: Spatial tenses: FAhA and VA
- compared with temporal tense in elidability: Spatial tenses: FAhA and VA
- contrasted with temporal in dimensionality: Dimensionality: VIhA
- definition: Spatial tenses: FAhA and VA
- direction: Spatial tenses: FAhA and VA
- distance: Spatial tenses: FAhA and VA
- four-dimensional: Dimensionality: VIhA
- linear: Dimensionality: VIhA
- one-dimensional: Dimensionality: VIhA
- order relative to temporal: Temporal tenses: PU and ZI
- planar: Dimensionality: VIhA
- reference frame: Spatial tenses: FAhA and VA
- referent of: Spatial tenses: FAhA and VA
- three-dimensional: Dimensionality: VIhA
- two-dimensional: Dimensionality: VIhA
- spatial tense intervals
-
- order of size and dimensionality in: Dimensionality: VIhA
- order of VEhA and VIhA in: Dimensionality: VIhA
- spatial tenses
-
- as sumtcita: Tenses as sumtcita
- order of direction and distance specifications: Spatial tenses: FAhA and VA
- speaker's state of knowledge: Discursives
- speaker-listener cooperation: Questions
- speaker-relative viewpoint
-
- contrasted with event-relative viewpoint: Event contours: ZAhO and re'u
- specific descriptions: The three basic description types
- specific terms
-
- use of fu'ivla for: fu'ivla
- specificity
-
- expressing with "po": Relative phrases
- speech rhythm
-
- for grouping in English: Three-part tanru grouping with bo
- spelling out words
-
- Lojban contrasted with English in usefulness: A to Z in Lojban, plus one
- spiritual discomfort
-
- example: Emotional categories
- SQL: Acronyms
- square brackets
-
- use of in notation: What are the typographical conventions of this book?
- standard bridi form
-
- definition: Standard bridi form: cu
- standard for subjective numbers
-
- specifying: Special mekso selbri
- standard pronunciation: Basic phonetics
- starting marker: Erasure: SI, SA, SU
- state abstraction
-
- place structure: Types of event abstractions
- state abstractions
-
- definition: Types of event abstractions
- related tense contours: Event-type abstractors and event contour tenses
- state abstractor: Types of event abstractions
- state event
-
- described: Types of event abstractions
- steady speed: Types of event abstractions
- stereotypical
-
- as not derogatory in Lojban: Descriptors for typical objects
- compared with typical: Descriptors for typical objects
- stereotypical objects: Descriptors for typical objects
- Steven Mark Jones: lerfu words as pro-sumti
- sticky modals
-
- 'fi'o' proscribed from: Sticky modals
- canceling: Sticky modals
- definition: Sticky modals
- sticky tenses
-
- and CAhA: Actuality, potentiality, capability: CAhA
- canceling: Sticky and multiple tenses: KI
- definition: Sticky and multiple tenses: KI
- effect of nau on: Tenses in subordinate bridi
- effect on future tense meaning: Sticky and multiple tenses: KI
- from part of a multiple tense: Sticky and multiple tenses: KI
- stop
-
- contrasted with finish: Event contours: ZAhO and re'u
- contrasted with pause: Event contours: ZAhO and re'u
- stories
-
- flow of time in: Story time
- story tense
-
- Lojban convention contrasted with English convention: Story time
- story time
-
- as a convention for inferring tense: Story time
- definition: Story time
- rationale for: Story time
- tenseless sentences in: Story time
- with no initial sticky time: Story time
- stress
-
- definition of: Syllabication and stress
- effect of buffer vowel on: Buffering of consonant clusters
- effect of syllabic consonants on: Diphthongs and syllabic consonants
- example: Emotional categories
- final syllable
-
- rules for pause after: Rules for inserting pauses
- irregular marked with upper-case: Upper and lower cases
- levels of: Syllabication and stress
- on cmavo: cmavo
- primary: Syllabication and stress
- quick-tour version: Pronunciation
- rules for: Syllabication and stress
- secondary: Syllabication and stress
- showing non-standard: Orthography
- stressed syllable
-
- compared with stressed vowel: Syllabication and stress
- stressed vowel
-
- compared with stressed syllable: Syllabication and stress
- stroke cat then rabbit: Tensed logical connectives, Tensed logical connectives, Tensed logical connectives
- structure of examples: What are the typographical conventions of this book?
- structure of this book: What is this book?
- structure words: cmavo
- sub-subscripts: Subscripts
- subjective amounts
-
- expressing: Indefinite numbers
- subjective numbers
-
- effect on place structure for cardinal selbri: Special mekso selbri
- effect on place structure for ordinal selbri: Special mekso selbri
- effect on place structure for portion selbri: Special mekso selbri
- effect on place structure for probability selbri: Special mekso selbri
- effect on place structure for scale selbri: Special mekso selbri
- rationale for effect on place structure: Special mekso selbri
- specifying standard for: Special mekso selbri
- subjective portions
-
- expressing: Indefinite numbers
- subordinate clause tense
-
- effect of main bridi tense on: Tenses in subordinate bridi
- Lojban compared with Esperanto: Tenses in subordinate bridi
- Lojban compared with Russian: Tenses in subordinate bridi
- Lojban contrasted with English: Tenses in subordinate bridi
- subordinate clauses
-
- tense usage rules in English: Tenses in subordinate bridi
- subscripted topics: Paragraphs: NIhO
- subscripting: Subscripts: XI
- subscripts
-
- and fuzzy truths: Subscripts: XI
- and names: Subscripts: XI
- and paragraph separators: Subscripts: XI
- and pro-sumti: Subscripts: XI
- and sumti re-ordering: Subscripts: XI
- and tense: Subscripts: XI
- before main expression: Subscripts
- effects on elidability of terminators: Subscripts
- external grammar of: Subscripts
- for sticky tense: Sticky and multiple tenses: KI
- internal grammar of: Subscripts
- lerfu string as: Mathematical uses of lerfu strings
- mathematical: Subscripts: XI
- multiple as sub-subscript: Subscripts
- multiple for same base word: Logical and non-logical connectives within mekso
- on "ke'a" for nested relative clauses: Relativized pro-sumti: ke'a
- terminator for: Subscripts
- to form matrices of more than 2 dimensions: Vectors and matrices
- use with "ke'a" for outer sumti reference: Relative clauses within relative clauses
- use with logical variables: A few notes on variables
- subscripts on lerfu words
-
- effect on elidability of "boi": Subscripts
- subsets
-
- expressing with outer quantifiers: Quantified descriptions
- subtraction operator
-
- contrasted with negative sign: Special numbers
- subtypes of words: brivla
- sumtcita
-
- based on event contours: Tenses as sumtcita
- based on spatial contours: Tenses as sumtcita
- based on tense direction: Tenses as sumtcita
- based on tense distance: Tenses as sumtcita
- based on tenses: Tenses as sumtcita
- definition (see also modal tag): Modal places: FIhO, FEhU
- event contours contrasted with direction/distance as basis for: Tenses as sumtcita
- sumtcita and linked sumti: Linked sumti: be - bei - be'o
- sumtcita and modal tags: Linked sumti: be - bei - be'o
- sumtcita and tense tags: Linked sumti: be - bei - be'o
- sumtcita based on dimension: Tenses as sumtcita
- sumtcita based on event contours
-
- relation of main bridi to sumti process in: Tenses as sumtcita
- sumtcita based on interval continuousness: Tenses as sumtcita
- sumtcita based on interval properties: Tenses as sumtcita
- sumtcita based on interval size: Tenses as sumtcita
- sumtcita based on quantified tenses: Tenses as sumtcita
- sumti
-
- as having implicit quantifiers: Quantified sumti
- as objects in place structure slots: Introductory
- beginning with "ke": Grouping of afterthought connectives
- between descriptor and description selbri: Possessive sumti
- classified by types of objects referred to: Individuals and masses
- converting into an operand: Using Lojban resources within mekso
- definition: The five kinds of simple sumti, Introductory
-
- quick-tour version: Lojban grammatical terms
- descriptions as: The five kinds of simple sumti
- dropping trailing unspecified: Standard bridi form: cu
- explicitly mapping into place structure with FA: Tagging places: FA
- for individual objects: Individuals and masses
- for mass objects: Individuals and masses
- for set objects: Individuals and masses
- forethought tense connection of: Tense relations between sentences
- irrelevant to relationship: Indefinite pro-sumti and pro-bridi: the zo'e-series and the co'e-series
- kinds of: The five kinds of simple sumti
- multiple in one place with FA: Tagging places: FA
- names as: The five kinds of simple sumti
- numbers as: The five kinds of simple sumti
- omitted first place in selbri-first bridi: Standard bridi form: cu
- order in selbri: Standard bridi form: cu
- order in selbri-first bridi: Standard bridi form: cu
- pro-sumti as: The five kinds of simple sumti
- quotations as: The five kinds of simple sumti
- re-ordering with FA: Tagging places: FA
- relation with bridi: The concept of the bridi
- sumti connection
-
- afterthought: sumti connection
- forethought: sumti connection
- sumti in one place
-
- multiple ones: Tagging places: FA
- sumti into selbri: selbri based on sumti: me
- sumti logical connection: sumti connection
-
- compared with bridi logical connections: sumti connection
- contrasted with tanru logical connection: Logical connection within tanru
- rationale for: sumti connection
- sumti modal connection: Other modal connections
- sumti placement
-
- variant
-
- quick-tour version: Variant bridi structure
- sumti qualifiers
-
- as short forms for common special cases: sumti qualifiers
- elidable terminator for qualified sumti: sumti qualifiers
- external syntax of: sumti qualifiers
- for negation: sumti qualifiers
- internal syntax of: sumti qualifiers
- list of: sumti qualifiers
- sumti questions
-
- quick-tour version: Questions
- sumti reordering
-
- quick-tour version: Varying the order of sumti
- sumti with "lo"
-
- compared to indefinite sumti: Grouping of quantifiers
- sumti with tense
-
- effect of main bridi tense on: Sticky and multiple tenses: KI
- sumti with tenses
-
- quick-tour version: Tenses
- sumti-based description
-
- definition: sumti-based descriptions
- inner quantifier on: sumti-based descriptions
- outer quantifier on: sumti-based descriptions
- sumti-based descriptions with le
-
- as increasing restricting to in-mind: sumti-based descriptions
- Sun
-
- the: cmevla
- sunburn
-
- example: Property abstractions
- superfective event contour: Event contours: ZAhO and re'u
- superscripts: Subscripts
- supervising
-
- as a contribution to mass action: Non-logical connectives
- supper: rafsi
- supplementary information: Dependent places
- Susan: Parenthesis and metalinguistic commentary: TO, TOI, SEI
- sword blade: lujvo with more than two parts.
- syllabaries
-
- lerfu word representation: What about Chinese characters?
- syllabic consonant
-
- effect on stress determination: cmevla
- syllabic consonants: Diphthongs and syllabic consonants
-
- effect on stress: Diphthongs and syllabic consonants
- final in word: Diphthongs and syllabic consonants
- syllabic l
-
- considered as a consonant for morphological discussions: Introductory
- syllabic m
-
- as a consonant for morphological discussions: Introductory
- syllabic n
-
- as a consonant for morphological discussions: Introductory
- syllabic pronunciations of consonants
- syllabic r
-
- as a consonant for morphological discussions: Introductory
- syllabication
-
- and names: Syllabication and stress
- definition of: Syllabication and stress
- examples of: Syllabication and stress
- rules for: Syllabication and stress
- variants of: Syllabication and stress
- syllable break
-
- contrasted with pause: The special Lojban characters
- representation in Lojban: The special Lojban characters
- symbol for: The universal bu
- word for: The universal bu
- symbol
-
- for operand: Miscellany
- referring to with "lu'e": sumti qualifiers
- symmetrical tanru: Some types of symmetrical tanru
- symmetrical tanru types
-
- both separately true: Some types of symmetrical tanru
- one or other true: Some types of symmetrical tanru
- using crucial/typical parts: Some types of symmetrical tanru
- using more inclusive class: Some types of symmetrical tanru
- symmetrical veljvo: Symmetrical and asymmetrical lujvo
- sympathy
T
- tables
- tagged sumti termsets
-
- connecting with non-logical forethought connectives: More about non-logical connectives
- tail-terms
-
- definition: Compound bridi
- Take care!: Vocatives and commands
- Talk!: Vocatives and commands
- talker: tanru
- taller: The concept of the bridi
- tan(pi/2) = infinity: Using Lojban resources within mekso
- tank
-
- Sherman: rafsi
- tanru
-
- ambiguity in: lujvo
- ambiguity of: lujvo, Simple tanru
- and abstractions: The syntax of abstraction
- and conversion
-
- quick-tour version: tanru
- and creativity: lujvo
- as ambiguous: Simple tanru
- asymmetrical: Some types of asymmetrical tanru
- combination of: lujvo
- containing mathematical expressions: Other kinds of simple selbri
- default left-grouping of: Three-part tanru grouping with bo
- definition: Simple tanru
-
- quick-tour version: Lojban grammatical terms
- expanding: Discursives
- explanation of: lujvo
- explicating: Discursives
- explicitly defining: Discursives
- expression of: lujvo
- meaning of: Simple tanru
- place structure of: The meaning of tanru: a necessary detour
-
- quick-tour version: tanru
- place structures of: Linked sumti: be - bei - be'o, Linked sumti: be - bei - be'o
- possible meanings of: The meaning of tanru: a necessary detour
- primary meaning of: Simple tanru
- purpose: The meaning of tanru: a necessary detour
- quick-tour version: tanru
- reducing logically connected sumti to
-
- caveat: Logical connection within tanru
- simple: Simple tanru
- to lujvo: lujvo
- with GOhA: Other kinds of simple selbri
- tanru and conversion: Conversion of simple selbri
- tanru connection
-
- connotation of non-logical: Non-logical connectives
- tanru connection grouping
-
- guheks unmarked tanru: Logical connection within tanru
- tanru conversion
-
- effect on place structure
-
- quick-tour version: tanru
- tanru default grouping
-
- quick-tour version: tanru
- tanru grouping
-
- complex: Complex tanru grouping
- effect of jeks: Logical connection within tanru
- effect of tanru inversion on: Inversion of tanru: co
- guheks compared with jeks: Logical connection within tanru
- three-part: Three-part tanru grouping with bo
- with "bo": Complex tanru grouping
- with "ke": Complex tanru with ke and ke'e
- with "ke" and "bo": Complex tanru with ke and ke'e
- tanru grouping with JA+BO
-
- effect on tanru grouping: Logical connection within tanru
- tanru inversion: Inversion of tanru: co
-
- definition: Inversion of tanru: co
- effect on tanru grouping: Inversion of tanru: co
- in complex tanru: Inversion of tanru: co
- multiple: Inversion of tanru: co
- rule for removing: Inversion of tanru: co
- where allowed: Inversion of tanru: co
- tanru inversion and place structure: Inversion of tanru: co
- tanru logical connection
-
- contrasted with sumti logical connection: Logical connection within tanru
- tanru nested within tanru: Three-part tanru grouping with bo
- technical terms: What are the typographical conventions of this book?
- telephone conversation
-
- hello: Vocative scales
- television: IPA for English speakers
- template: Minor abstraction types
- temporal direction
-
- exception in meaning when following "ze'e": Interval properties: TAhE and roi
- temporal information
-
- adding to a sentence with tense sumtcita: Tenses as sumtcita
- temporal tense
-
- as mandatory in English: Introductory
- compared with spatial tense in elidability: Spatial tenses: FAhA and VA
- historical definition: Introductory
- interaction with 4-dimensional spatial tense: Dimensionality: VIhA
- Lojban contrasted with English in necessity: Introductory
- order relative to spatial: Temporal tenses: PU and ZI
- quantified with direction: Interval properties: TAhE and roi
- real relationship to time in English: Introductory
- temporal tense elision
-
- compared with spatial tense elision in meaning: Spatial tenses: FAhA and VA
- temporal tenses
-
- compared with spatial tenses: Temporal tenses: PU and ZI
- ten
-
- expressing as number: Lojban numbers
- tense
-
- aorist: Vague intervals and non-specific tenses
- as observer-based: Temporal tenses: PU and ZI
- as subjective perception: Temporal tenses: PU and ZI
- connecting sentences in with: Tense relations between sentences
- contradictory negation contrasted with scalar negation of: Tense negation
- effect of different position in sentence: Introductory
- effect of sticky tense on: Sticky and multiple tenses: KI
- emphasizing by position in sentence: Introductory
- explanation of presentation method: Introductory
- expressing movement in: Movement in space: MOhI
- handling multiple episodes: Sticky and multiple tenses: KI
- in forethought bridi-tail connection
-
- special rule: Tenses, modals, and logical connection
- interval contrasted with point: Interval sizes: VEhA and ZEhA
- Lojban contrasted with English in implications of completeness: Vague intervals and non-specific tenses
- Lojban contrasted with English in implying actuality: Actuality, potentiality, capability: CAhA
- Lojban contrasted with native languages: Introductory
- numerical: Other uses of mekso
- on embedded bridi: Sticky and multiple tenses: KI
- order of direction
-
- distance and interval in: Interval sizes: VEhA and ZEhA
- order of direction specification in: Spatial tenses: FAhA and VA
- order of distance specification in: Spatial tenses: FAhA and VA
- order of movement specification in: Movement in space: MOhI
- order of spatial interval modifiers in: Space interval modifiers: FEhE
- order of temporal and spatial in: Temporal tenses: PU and ZI
- overriding to speaker's current: Tenses in subordinate bridi
- point contrasted with interval: Interval sizes: VEhA and ZEhA
- position in sentence alternative: Introductory
- position of in sentence: Introductory
- quantified: Interval properties: TAhE and roi
- rationale for relative order of temporal and spatial in: Temporal tenses: PU and ZI
- relation of interval to point specified by direction and distance: Interval sizes: VEhA and ZEhA
- relation of point specified by direction and distance to interval: Interval sizes: VEhA and ZEhA
- relative order with bridi negation: Tenses and bridi negation
- scalar negation contrasted with contradictory negation of: Tense negation
- scalar negation of with NAhE: Tense negation
- scope effect of new paragraph: Paragraphs: NIhO
- scope of: Sticky and multiple tenses: KI
- selbri types applicable to: Introductory
- space-time dimension for intervals: Dimensionality: VIhA
- speaker's current: Tenses in subordinate bridi
- specifying relation of interval to point specified by direction and distance: Interval sizes: VEhA and ZEhA
- static contrasted with moving: Movement in space: MOhI
- subscripting: Sticky and multiple tenses: KI
- sumtcita form contrasted with connected sentences: Tense relations between sentences
- with "ku": Introductory
- with both temporal and spatial: Temporal tenses: PU and ZI
- tense afterthought connection forms
-
- selma'o allowed: Tense relations between sentences
- tense and na
-
- multiple: Tenses and bridi negation
- tense as sumtcita
-
- contrasted with tense inside sumti: Tenses as sumtcita
- tense cmavo
-
- position relative to selbri: Tenses and bridi negation
- tense connected sentences
-
- contrasted with separately tensed sentences: Tense relations between sentences
- forethought mode: Tense relations between sentences
- importance of bo in: Tense relations between sentences
- tense connection
-
- equivalent meanings: Tense relations between sentences
- expansions of: Tense relations between sentences
- tense connection of bridi-tails
-
- meaning of: Tense relations between sentences
- tense connection of sentences
-
- contrasted with sumtcita form: Tense relations between sentences
- order of: Tense relations between sentences
- tense connection of sumti
-
- meaning of: Tense relations between sentences
- tense conversion
-
- accessing original first place with "fai": Conversion of sumtcita: JAI
- accessing tense of bridi with "jai": Conversion of sumtcita: JAI
- of temporal tenses: Conversion of sumtcita: JAI
- use in sumti descriptions: Conversion of sumtcita: JAI
- with "jai": Conversion of simple selbri
- tense direction
-
- as sumtcita: Tenses as sumtcita
- contrasted with event contours in implication of extent: Event contours: ZAhO and re'u
- implications on scope of event: Vague intervals and non-specific tenses
- tense direction/distance as sumtcita
-
- contrasted with event contours: Tenses as sumtcita
- tense distance
-
- as sumtcita: Tenses as sumtcita
- tense forethought connection forms
-
- selma'o allowed: Tense relations between sentences
- tense in scope of sticky tense
-
- compared with compound tense: Sticky and multiple tenses: KI
- tense inside sumti
-
- contrasted with tense as sumtcita: Tenses as sumtcita
- tense on main bridi
-
- effect on embedded bridi tenses: Sticky and multiple tenses: KI
- effect on embedded sumti with tenses: Sticky and multiple tenses: KI
- tense questions
-
- by using logical connective question: Tense questions: cu'e
- methods of asking: Tense questions: cu'e
- tense questions with "ma": Tense questions: cu'e
- tense sentence connection
-
- table of equivalent schemata: Tenses versus modals
- tense specification
-
- effect on "cu": Introductory
- effect on elidability of terminators: Introductory
- tense system
-
- and space location: Introductory, Introductory
- tense tags and sumtcita: Linked sumti: be - bei - be'o
- tense with sumtcita
-
- asymmetry of: Tense relations between sentences
- tense-or-modal questions
-
- pre-specifying some information: Tense questions: cu'e
- with "cu'e": Tense questions: cu'e
- tensed connectives
-
- in mathematical expressions: Tenses, modals, and logical connection
- tensed logical connection: Tenses, modals, and logical connection
- tensed logical connectives: Tensed logical connectives
-
- forethought: Tenses, modals, and logical connection
- in ek…"bo": Tenses, modals, and logical connection
- in ek…"ke": Tenses, modals, and logical connection
- in gihek…"bo": Tenses, modals, and logical connection
- in gihek…"ke": Tenses, modals, and logical connection
- in ijek…"bo": Tenses, modals, and logical connection
- in ijek…"tu'e": Tenses, modals, and logical connection
- in ijoik…"bo": Tenses, modals, and logical connection
- in ijoik…"tu'e": Tenses, modals, and logical connection
- in jek…"bo": Tenses, modals, and logical connection
- in joik…"bo": Tenses, modals, and logical connection
- in joik…"ke": Tenses, modals, and logical connection
- with "ke"…"ke'e": Tensed logical connectives
- with "tu'e"…"tu'u": Tensed logical connectives
- tensed logically connected bridi-tails: Tensed logical connectives
-
- with grouping: Tensed logical connectives
- tensed logically connected sentences: Tensed logical connectives
-
- with grouping: Tensed logical connectives
- tensed logically connected sumti: Tensed logical connectives
-
- with grouping: Tensed logical connectives
- tensed non-logical connectives: Tenses, modals, and logical connection
-
- forethought: Tenses, modals, and logical connection
- tenseless sentences in story time: Story time
- tenses
-
- compared with modals in syntax: Tenses versus modals
- connected
-
- with negation: Logical and non-logical connections between tenses
- contradictory negation of with "nai": Tense negation
- contrasted with modals in semantics: Tenses versus modals
- forethought connection in: Tenses, modals, and logical connection
- forethought logical connections: Logical and non-logical connections between tenses
- grouping of connectives in: Tenses, modals, and logical connection
- importance of 2nd sumti place for sumtcita use: Tenses versus modals
- logically connected with JA: Logical and non-logical connections between tenses
- multiple in sentence: Sticky and multiple tenses: KI
- multiple in sentence compared with compound tense: Sticky and multiple tenses: KI
- negating: Tense negation
- non-logical connection of: Logical and non-logical connections between tenses
- non-logical connection of for sub-events: Sub-events
- possible groupings of: Logical and non-logical connections between tenses
- quick-tour version: Tenses
- use as sumtcita: Tenses as sumtcita
- viewpoint of PU contrasted with viewpoint of ZAhO: Event contours: ZAhO and re'u
- tenses with elided CAhA
- term
-
- definition: Termset logical connection
- terminators
-
- eliding "ku" in non-logical connections: Non-logical connectives
- termset
-
- effect on scope of multiple indefinite sumti: Grouping of quantifiers
- formation: Termset logical connection
- termset logical connection
-
- unequal length: Termset logical connection
- termset modal connection: Other modal connections
- termsets
-
- compared to fa'u: Non-logical connectives
- non-logical connection of: More about non-logical connectives
- tertau
-
- definition: Inversion of tanru: co
- definition of: Simple tanru
- effect on meaning of tanru: Simple tanru
- text
-
- division numbering with "mai": Other uses of mekso
- sub-division numbering with "mai": Other uses of mekso
- text quotation
-
- as internally grammatical: Quotation summary
- syntax of: Quotation summary
- thank you
-
- example: Vocative scales
- the
-
- contrasted with English "a/an": Miscellaneous indicators
- for talking about numbers themselves: Simple infix expressions and equations
- The cats are dogs: The three basic description types
- the two of you: sumti-based descriptions, sumti-based descriptions
- there is a Y
-
- expression "there is a Y" in English
-
- notation convention: Negation boundaries
- thingy: Assignable pro-sumti and pro-bridi: the ko'a-series and the broda-series
- this
-
- adjective expression with "ti noi": Demonstrative pro-sumti: the ti-series
- adjective expression with "vi": Demonstrative pro-sumti: the ti-series
- adjective usage contrasted with pronoun usage: Demonstrative pro-sumti: the ti-series
- as utterance reference in English: Utterance pro-sumti: the di'u-series
- pronoun expression with ti: Demonstrative pro-sumti: the ti-series
- pronoun usage contrasted with adjective usage: Demonstrative pro-sumti: the ti-series
- this boat: Demonstrative pro-sumti: the ti-series, Demonstrative pro-sumti: the ti-series, Demonstrative pro-sumti: the ti-series
- this book
-
- author of: Acknowledgements and credits
- contributors to: Acknowledgements and credits
- credits for: Acknowledgements and credits
- examples of: What are the typographical conventions of this book?
- goal of: What is this book?
- reviewers of: Acknowledgements and credits
- structure of: What is this book?
- this/that in English
-
- compared with ti-series pro-sumti: Demonstrative pro-sumti: the ti-series
- three bears: sumti-based descriptions, sumti-based descriptions, sumti-based descriptions
- three cats white
-
- and two big: A few notes on variables
- three dogs bite two men: Grouping of quantifiers
- Three Kings: selbri based on sumti: me
- three of four people: Logical and non-logical connectives within mekso
- three or four people: Logical and non-logical connectives within mekso
- three rats: Special mekso selbri
- thus
-
- example: Evidentials
- tilde
-
- a diacritical mark: Accent marks and compound lerfu words
- time
-
- as part of tense system (see also tense
-
- temporal tense): Introductory
- as space-based metaphor: Space interval modifiers: FEhE
- contrasted with space in number of directions: Temporal tenses: PU and ZI
- time tenses
-
- quick-tour version: Tenses
- time travel: Movement in space: MOhI
- times
-
- explicit expression of: Indefinite numbers
- implicit expression of: Indefinite numbers
- title
-
- specifying with "tu'e…tu'u": Sentences: I
- title of book: sumti qualifiers, sumti qualifiers
- to the market from the office: Termset logical connection
- to-do list: More about non-logical connectives
- Tolkien
-
- and non-standard Lojban orthography: Oddball orthographies
- tomorrow: lujvo with more than two parts.
- too
-
- example: Discursives
- too long: Event contours: ZAhO and re'u, Tenses as sumtcita
- too many rats
-
- example: Special mekso selbri
- topic-comment
-
- description: Topic-comment sentences: ZOhU
- topic/comment
-
- multiple sentence: Topic-comment sentences: ZOhU
- tosmabru test: The lujvo-making algorithm
- toward her right: Movement in space: MOhI
- toward my right: Movement in space: MOhI
- toward right
-
- contrasted with on right: Movement in space: MOhI
- transfinite cardinal: Special numbers
- transformations with logical connectives
- traveling salesperson: Modal tags: BAI
- triumph: Types of event abstractions
- truncation of number
-
- expressing: Approximation and inexact numbers
- truth
-
- in imperative sentences: Truth questions and connective questions
- truth functions: Logical connection and truth tables
-
- 16 possible: Logical connection and truth tables
- commutative: The four basic vowels
- creating all 16 with Lojban's basic set: The four basic vowels
- fundamental 4 in Lojban: The four basic vowels
- relation to logical connectives: The four basic vowels
- table of logical connectives: Truth functions and corresponding logical connectives
- truth questions: Miscellaneous indicators
-
- answering in English with "no": Truth questions and connective questions
- answering in English with "yes": Truth questions and connective questions
- as yes-or-no questions: Truth questions and connective questions
- contrasted with connection questions: Truth questions and connective questions
- simple: Truth questions and connective questions
- truth table
-
- explanation: Logical connection and truth tables
- truth tables
-
- abbreviated format: Logical connection and truth tables
- for 4 fundamental Lojban truth functions: The four basic vowels
- list of 16 in abbreviated form: Logical connection and truth tables
- notation convention: Logical connection and truth tables
- truth-value abstractions
-
- place structure: Truth-value abstraction: jei, Predication/sentence abstraction
- try the door: Lojban sumti raising
- try to go: Inversion of tanru: co
- ts-sound in Russian
-
- representation in Lojban: Basic phonetics
- twice today: Tenses as sumtcita
- two brothers: Other kinds of simple selbri
- two dogs are white: Quantified descriptions
- types and subtypes of words: brivla
- typical
-
- compared with stereotypical: Descriptors for typical objects
- typical Englishman: Descriptors for typical objects
- typical Lojban user: Masses and sets
- typical objects
-
- and instantiation: Descriptors for typical objects
- determining characteristics of: Descriptors for typical objects
- typical Smith
-
- example: Descriptors for typical objects
- typical sumti: Indefinite pro-sumti and pro-bridi: the zo'e-series and the co'e-series
- typical value
-
- contrasted with elliptical value for sumti: Indefinite pro-sumti and pro-bridi: the zo'e-series and the co'e-series
U
- U
-
- notation convention for logical connectives: The four basic vowels
- ugh: More about non-logical connectives
- umlaut
-
- a diacritical mark: Accent marks and compound lerfu words
- unabridged dictionary: Contrastive emphasis: BAhE
- unconditional signal: No more to say: FAhO
- unconnected tanru
-
- contrasted with logically connected version: Logical connection within tanru
- undemonstrated potential
-
- expressing: Actuality, potentiality, capability: CAhA
- under compulsion: Modal selbri, Modal selbri, Modal selbri, Modal selbri
- under conditions: Event abstraction
- underscore notation for Quick Tour chapter: The concept of the bridi
- unequal termset connection
-
- compared with compound bridi connection with unequal separate bridi-tails: Termset logical connection
- unfilled places of inverted tanru: Inversion of tanru: co
- Unicode: Computerized character codes
- union
-
- of sets: More about non-logical connectives
- union of sets
-
- compared with English "or": More about non-logical connectives
- units of measurement
-
- expressing: Simple infix expressions and equations
- universal
-
- mixed claim with existential: Universal claims
- universal claims
-
- dangers of using: Dropping the prenex
- explanation: Universal claims
- restricting: Restricted claims: da poi, Restricted claims: da poi
- unqualified sumti
-
- contrasted with qualified sumti: sumti qualifiers
- unreduced fractions
-
- use in granular scales: Special mekso selbri
- unreduced lujvo
-
- definition: rafsi
- unspecified breed
-
- example: Dependent places
- unspecified direction
-
- temporal contrasted with in spatial: Temporal tenses: PU and ZI
- unspecified emotion: Compound indicators
- unspecified level of emotion: Compound indicators
- unspecified route: Standard bridi form: cu
- unspecified sumti
-
- non-trailing: Standard bridi form: cu
- using zo'e as place-holder for: Standard bridi form: cu
- unspecified trailing sumti
-
- dropping: Standard bridi form: cu
- unstated emotion: Compound indicators
- unusual characters
-
- words for: The universal bu
- unvoiced consonants
-
- contrasted with voiced in allowable consonant pairs: Initial consonant pairs
- unvoiced vowel glide
-
- apostrophe as: The special Lojban characters
- upper-case
-
- lerfu word for: Upper and lower cases
- upper-case letters
-
- English usage contrasted with Lojban: Upper and lower cases
- Lojban usage contrasted with English: Upper and lower cases
- utterance
-
- expressing relation to discourse: Discursives
- utterance ordinal
-
- lerfu string as: Mathematical uses of lerfu strings
- utterance pro-sumti: Utterance pro-sumti: the di'u-series
-
- stability of: Pro-sumti and pro-bridi cancelling
- utterances
-
- non-bridi: Questions and answers
- uy diphthong
-
- in cmevla: cmevla
V
- V
-
- as a symbol for a single vowel: Introductory
- vague abstraction: Minor abstraction types
- vague abstractions
-
- place structure: Minor abstraction types
- vague abstractor: Minor abstraction types
- vague relationship
-
- modal tag for: Modal tags: BAI
- valid speech
-
- marking as error with jo'a: Miscellaneous indicators
- variables
- vector
-
- components of: Vectors and matrices
- definition: Vectors and matrices
- vector indicator: Vectors and matrices
-
- terminator for: Vectors and matrices
- vectors
-
- use as operands: Vectors and matrices
- use of parentheses with: Vectors and matrices
- veljvo
-
- symmetrical: Symmetrical and asymmetrical lujvo
- verbs
-
- brivla as Lojban equivalents: brivla
- very: Special mekso selbri
- veterinarian: Ordering lujvo places.
- vice versa: Reflexive and reciprocal pro-sumti: the vo'a-series, Reflexive and reciprocal pro-sumti: the vo'a-series, Reflexive and reciprocal pro-sumti: the vo'a-series, Reflexive and reciprocal pro-sumti: the vo'a-series
-
- English
-
- expressing with vo'a-series pro-sumti and soi: Reflexive and reciprocal pro-sumti: the vo'a-series
- virtue
-
- example: Attitudinal modifiers
- vocative phrase
-
- effect of position on meaning: The syntax of vocative phrases
- elidable terminator for: The syntax of vocative phrases
- explicit quantifiers prohibited on: The syntax of vocative phrases
- forms of: The syntax of vocative phrases
- implicit descriptor on: The syntax of vocative phrases
- implicit quantifiers on: The syntax of vocative phrases
- purpose of: The syntax of vocative phrases
- with complete sumti: The syntax of vocative phrases
- with sumti without descriptor: The syntax of vocative phrases
- vocative phrase terminator
-
- elidability of: The syntax of vocative phrases
- vocative phrase with name
-
- placement of relative clause on: Relative clauses in vocative phrases
- vocative phrase with selbri
-
- placement of relative clause on: Relative clauses in vocative phrases
- vocative phrases
-
- as a free modifier : The syntax of vocative phrases
- relative clauses on: Relative clauses in vocative phrases
- vocative word
-
- phrase following: The syntax of vocative phrases
- vocatives
-
- and definition of English "you": Vocative scales
- contrasted with "la": Vocative scales
- definition: Vocative scales
- grammar overview: Vocative scales
- notation convention symbol "X": Vocative scales
- quick-tour version: Vocatives and commands
- rationale for redundancy: Vocative scales
- voiced consonants
-
- contrasted with unvoiced in allowable consonant pairs: Initial consonant pairs
- voiced/unvoiced consonants
-
- restrictions on: Consonant clusters
- vowel
-
- buffer: Buffering of consonant clusters
- vowel buffer
-
- contrasted with y sound: Buffering of consonant clusters
- vowel pairs
-
- contrasted with diphthongs: Vowel pairs
- definition of: Vowel pairs
- grouping of: Vowel pairs
- involving y: Vowel pairs
- list of: Vowel pairs
- use of apostrophe in: Vowel pairs
- vowel-initial words
-
- necessity for pause before: Rules for inserting pauses
- vowels
-
- contrasted with consonants: Diphthongs and syllabic consonants
- definition of: Diphthongs and syllabic consonants
- length of: Buffering of consonant clusters
- pronunciation of
-
- quick-tour version: Pronunciation
- VV string
-
- as a symbol for a double vowel: Introductory
W
- walk to market: Conversion of simple selbri
- want to be a soldier: The syntax of abstraction
- wash self: Reflexive and reciprocal pro-sumti: the vo'a-series
- weapon against self: Dropping the prenex
- went and bought: Tenses, modals, and logical connection, Tenses, modals, and logical connection
- what is your name: sumti and bridi questions: ma and mo
- when: Tense questions: cu'e
- when else: Tense questions: cu'e
- when/where/how: Tense questions: cu'e
- where: Tense questions: cu'e
- whether criminal: Truth-value abstraction: jei
- whole time interval
-
- expressing: Interval properties: TAhE and roi
- window: The six types of logical connectives
- wine-dark sea: The meaning of tanru: a necessary detour
- word classes: Introductory
- word forms
-
- as related to grammatical uses: Introductory
- in Lojban (see also morphology): Introductory
- word quotation
-
- as morphologically valid: Quotation summary
- internal grammar of: Quotation summary
- words not in the dictionary: Some words used to indicate selbri relations
- wrong concept: Dependent places
X
- X-ray: rafsi
- x1
-
- in place structure notation: Introductory
- notation convention
-
- quick-tour version: Some words used to indicate selbri relations
- x₃: Subscripts
- xₐ,ₑ: Logical and non-logical connectives within mekso
- xₖ: Mathematical uses of lerfu strings
Y
- y
-
- considered not to be a vowel for morphological discussions: Introductory
- letter
- use in avoiding forbidden consonant pairs: Consonant clusters
- y sound
-
- contrasted with vowel buffer: Buffering of consonant clusters
- y-hyphen
- yes/no questions: Miscellaneous indicators
-
- quick-tour version: Questions
- yielding the floor: No more to say: FAhO
- yon
-
- as archaic English equivalent of "tu": Demonstrative pro-sumti: the ti-series
- you
-
- defining: Vocative scales
- you're welcome
-
- "fi'i" contrasted with "je'e": Vocative scales
- "je'e" contrasted with "fi'i": Vocative scales
- you-cmavo
-
- example: lujvo based on pro-sumti
- you-talk
-
- example: lujvo based on pro-sumti
- younger: Comparatives and superlatives, Comparatives and superlatives
Z
- z
-
- "z" instead of "'" in acronyms names based on lerfu words: Acronyms
- zbalermorna
-
- non-standard Lojban orthography: Oddball orthographies
- zero
-
- relation to negation boundary: Negation boundaries
- zero to one: Logical and non-logical connectives within mekso
- Zipf's Law: Considerations for making lujvo